本文梳理了 LLM API 的 4 种调用方式:原生HTTP、OpenAI SDK、Ollama SDK、ModelScope,从底层协议到高层封装逐一讲透,并从调用过程揭晓 AI 记忆力的真相,适合 Python 入门用户食用。
一、API是个啥玩意儿
开始调用之前,我们先说说 API 是个啥玩意儿?
你点外卖时打开 App 选个麻辣烫,付完钱,等会儿外卖小哥就把餐送到你手上了。
你不需要知道后厨灶台多大、厨师先放油还是先放盐,你只管下单,餐厅只管出餐,中间靠的就是一个「接单→制作→送达」的流程。
API 就是这个流程的数字化版本。
API 的全称是 Application Programming Interface,翻译过来叫「应用程序编程接口」。名字很唬人,但概念特别简单:它就是软件之间对话的窗口。你往窗口传递一个请求(Request),窗口那边处理后递回一个响应(Response),完事儿。
放到大模型调用的场景里:
- 用户:写代码发一条消息,说「帮我翻译这段话」
- LLM 服务器:收到消息,跑一遍模型推理,把翻译结果推回来
- API:就是用户和服务器之间那个「窗口」,规定了消息往哪传、格式是什么、能传什么内容
就这么简单,你不用操心模型有几亿参数、跑在什么显卡上,你只需要按照 API 规定的格式发请求、收结果。
那这个「格式」到底长什么样?核心就几个要素:
| 要素 | 通俗理解 | 例子 |
|---|---|---|
| base_url | 餐厅链接 | https://api.deepseek.com |
| API Key | 你充值了的会员号 | sk-xxxxxxxxxxxx |
| model | 你想指定哪位主厨来料理 | deepseek-v4-flash |
| Request | 你递过去的菜单 | "翻译:Hello World" |
| Response | 窗口递回来的出品 | "你好世界" |
其中 API Key 值得多说一句,你的会员卡绑定你的账号,服务端靠它认人、计费、限流。所以千万别把 Key 硬编码在代码里或者发到公开仓库,不然别人拿你的卡刷,账单你来付 💸 下文再具体看怎么避免。
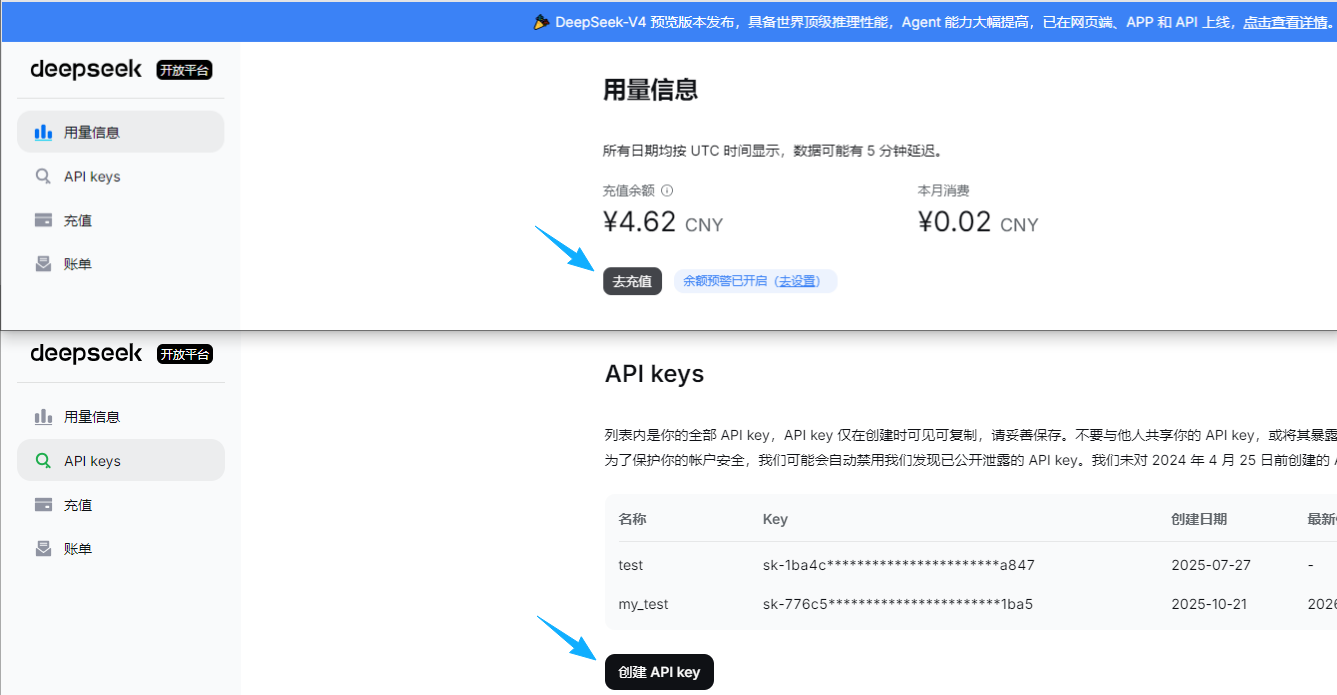
那么怎么拿到 Key 呢?以操作流程最简单的 D指导为例:
- 登录 DeepSeek 开放平台
- 充值,最低 10 块钱就能体验
- 创建 API key
地址:https://platform.deepseek.com
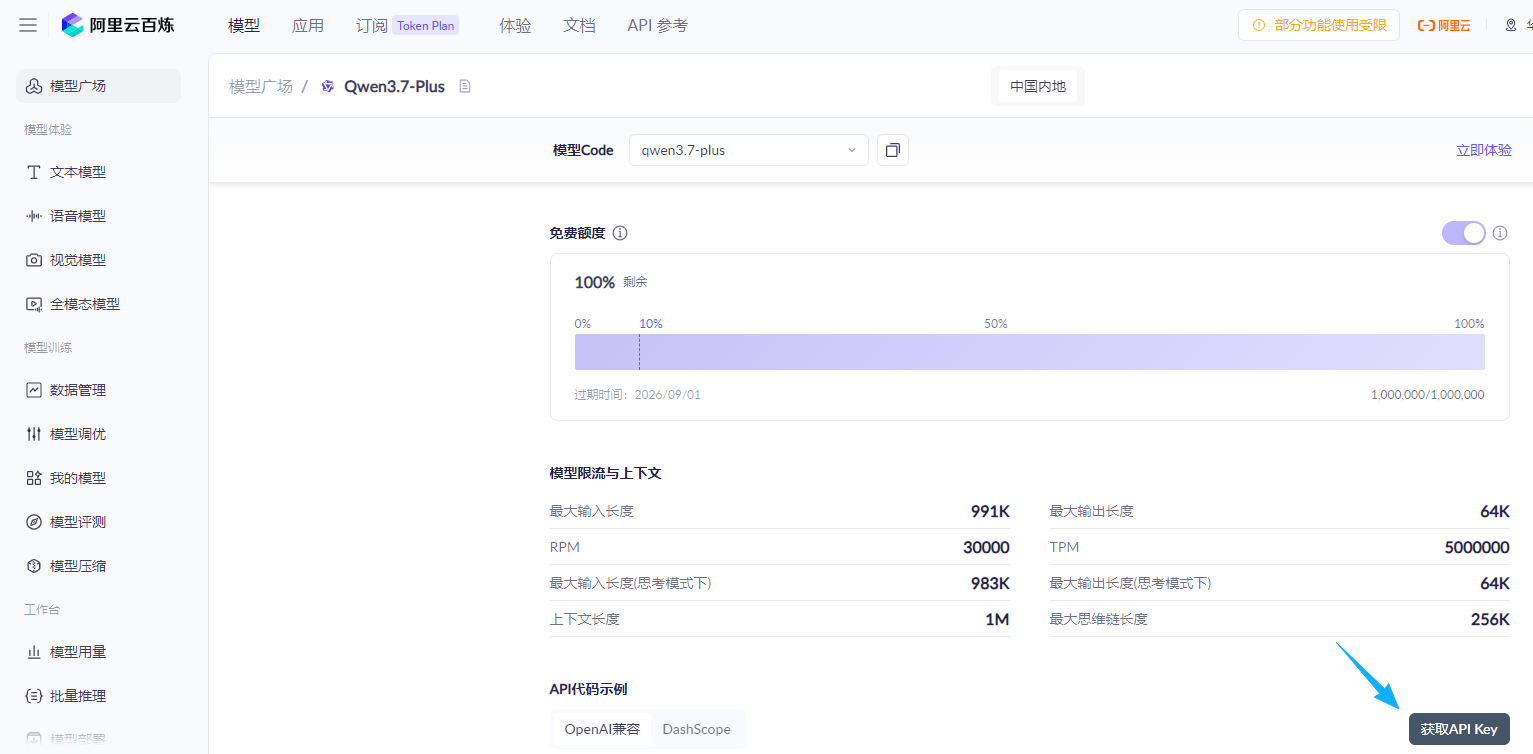
也可以在阿里云百炼平台获取免费额度进行体验,10 余个模型额度可以白嫖,总计千万 tokens,我就赶在过期之前赶紧蹭一波把数据跑了。
地址:https://bailian.console.aliyun.com
二、为什么要使用 API
你可能会想:我打开各大 AI 的官网,输入问题,得到回答,完事。干嘛还要写代码调 API?
确实,如果只是偶尔问个问题,网页聊天完全够用。但当你的需求从「我手动问一次」变成「让程序自动问一万次」,API 就成了唯一的选择。
具体来说,有这几个场景是网页聊天搞不定的:
🔄 批量处理
你有 500 条客户评论要分类情感、1000 封邮件要提取关键信息、一整个 Excel 的产品描述要翻译成英文,手动一条条复制粘贴?就算你手速惊人,眼睛也要看花。API 能让你写个循环遍历,扔在一边摸鱼等几分钟跑完。
⚡ 高并发调用
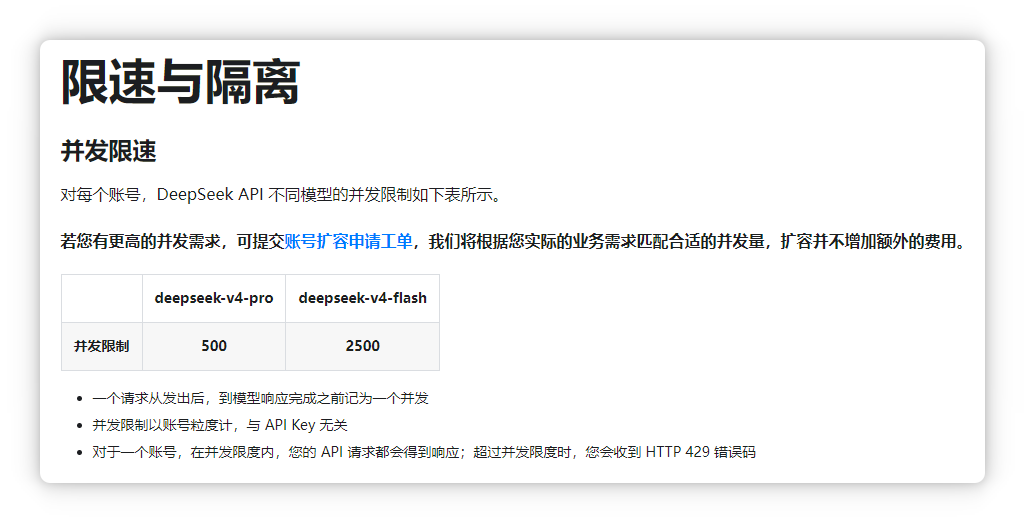
网页聊天你想同时开展多个对话,就要开一堆标签页,切换来切换去,但 API 可以同时发起上百甚至上千个请求。
像是D指导的快速版就支持 2500 的并发量,并行处理几万条数据也是刷刷的,但要小心 token 消耗。
🔗 系统集成
API 是给程序用的接口,这意味着 LLM 可以嵌入到任何系统里:你的客服机器人、你的数据分析流水线、你的 IDE 插件、你的自动化工作流......网页聊天是一个孤岛,API 是一条可以接遍四方的水管。
🛡️ 内容审核与风控
调 API 意味着请求经过你自己的服务器,你可以在转发给 LLM 之前做内容过滤、敏感词拦截、合规检查,响应回来之后还能再做一层审核。
💰 成本清晰
API 按 token 计费,花了多少一目了然,你可以设预算上限、对高成本调用加告警。
🧪 可复现、可版本化
API 调用是一段代码,代码可以进 Git、可以 Code Review、可以回滚。你调的是哪个模型、用的什么 prompt、传了什么参数,全都可以记录日志,有据可查。
网页聊天是「人问 AI 答」,API 是「程序问 AI 答」。 当你想让AI能力变成产品的一部分,而不是一个工具网站,API 就是那个从「用」到「造」的跨越。
三、如何调用 API
不同的调用方式,本质上就是用不同的「递单子」工具,往同一个窗口下单后等着取回就行。有的工具繁琐但让你看清每一步(requests),有的工具顺手而帮你包办了细节(SDK)。知道以上概念,我们就可以开始写代码了。
(一)requests:理解底层协议
实战中你很少需要用 requests 直接调 LLM API,有官方 SDK 的场景都应该用 SDK,但理解底层协议你才知道 SDK 背后在干什么。
用一个智谱AI开放平台的例子来说明,为什么选它?因为就它的接口文档保留了 HTTP 指引(噗),不过把 url 和 model 换成其他任意厂商、模型也是一样的,官方文档都会提供调用示例。
地址:https://docs.bigmodel.cn/cn/guide/develop/http/introduction

HTTP API 调用示例
python
import requests # 用于发送 HTTP 请求的库,常用于爬虫
def call_zhipu_api(messages, model="glm-5.2"):
# 智谱AI统一入口,所有模型共用同一个 URL,通过 body 中的 model 字段区分
url = "https://open.bigmodel.cn/api/paas/v4/chat/completions"
# 请求头
# - Authorization: 使用密钥鉴权
# - Content-Type: 声明请求体为 JSON 格式
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
# 请求体(JSON Body)
# - model: 指定调用的模型名称
# - messages: 多轮对话消息列表,按时间顺序排列
# - temperature: 采样温度,范围 0.0~1.0;值越大回复越随机/创造性,值越小越确定/保守;默认 1.0,适合一般对话场景
data = {
"model": model,
"messages": messages,
"temperature": 1.0
}
# 发送 POST 请求
# json=data 会自动序列化为 JSON 并设置 Content-Type
response = requests.post(url, headers=headers, json=data)
# 处理响应
# - 200 表示请求成功,解析并返回 JSON
# - 非 200 抛出异常,常见错误码:
# 401 - API Key 无效或过期
# 403 - 无权限访问该模型
# 429 - 请求频率超限
# 500 - 服务端内部错误
if response.status_code == 200:
return response.json()
else:
raise Exception(f"API调用失败: {response.status_code}, {response.text}")
# 使用示例
# 构建对话消息列表
# role="user" 表示用户的输入,"system" 为系统提示词
# 如需多轮对话,可追加 assistant 和 user 的交替消息,例如:
# [
# {"role": "system", "content": "你是一个专业的翻译助手"},
# {"role": "user", "content": "你好,请介绍一下自己"},
# {"role": "assistant", "content": "你好!我是AI助手..."},
# {"role": "user", "content": "帮我翻译一句话"},
# ]
messages = [
{"role": "user", "content": "你好,请介绍一下自己"}
]
# 调用 API
result = call_zhipu_api(messages)
# 提取并打印模型回复内容
# result['choices'] → 候选回复列表(通常取第一个)
# result['choices'][0]['message'] → 消息对象 {role, content}
# result['choices'][0]['message']['content'] → 模型回复的纯文本
# result['usage']['total_tokens'] → 本次消耗的 token 数量
print(result['choices'][0]['message']['content'])这就是手动拼请求的痛点,参数代码写得长,还要手动处理异常,每个厂商的格式还可能不一样。而用 SDK 的话,这些差异都被封装好了,你只管调。
💡 好消息:现在智谱AI等,几乎所有模型厂商或代理平台的接口都能兼容 OpenAI 格式,可以直接用 OpenAI SDK 调用。所以 requests 方式在实际开发中确实越来越不需要了。
(二)OpenAI SDK:一招鲜吃遍天
OpenAI 的 API 格式已经成为 LLM 领域的事实标准,官方也提供了SDK(Software Development Kit,软件开发工具包),在 Python 中就是 openai 库,它是调用 LLM 服务的统一入口。
安装
bash
pip install openai核心模式
所有 OpenAI 兼容服务的调用方式完全一样,唯一的区别就是 base_url 、 api_key 和模型名称:
python
from openai import OpenAI
# 同一套代码,只换这两行,就能切换不同服务
client = OpenAI(
api_key="your-api-key", # 各服务的API Key
base_url="https://..." # 各服务的接口地址
)
# 调用方式完全相同
response = client.chat.completions.create(
model="模型名称",
messages=[{"role": "user", "content": "哈哈嗨👋"}]
)
print(response.choices[0].message.content)流式输出
一个字一个字的吐,不用等全部推理完成才返回一整段内容:
python
from openai import OpenAI
client = OpenAI(api_key="your-key", base_url="https://api.deepseek.com")
stream = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": "脑袋被门夹了,吃被门夹过的核桃还能补脑吗"}],
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)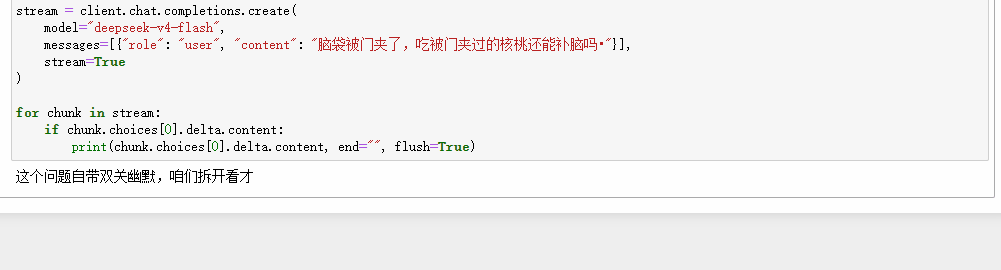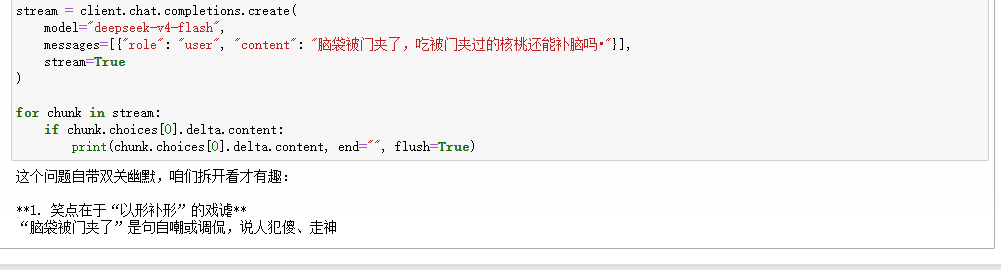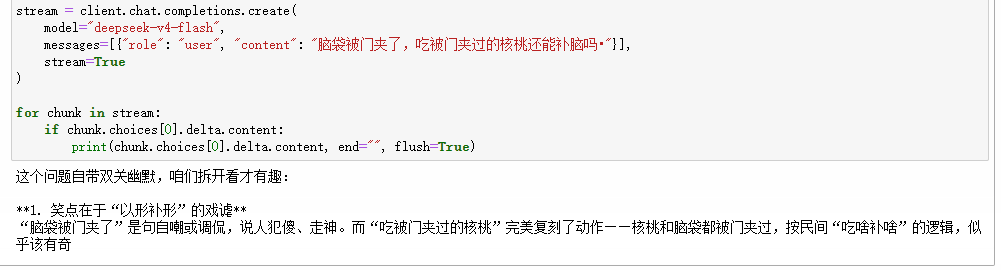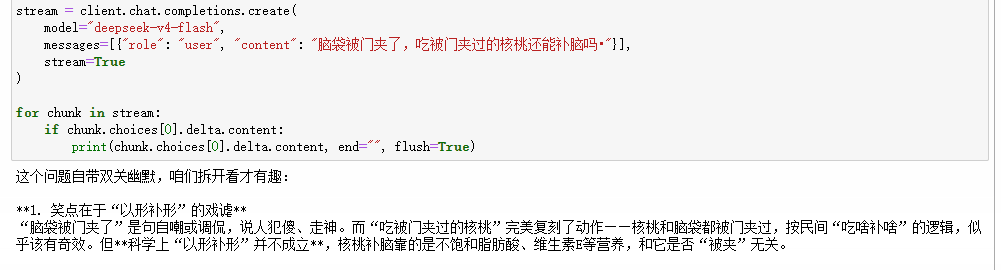
避免直接把 API Key 明文写入代码
至此,我们已经知道怎么拿到 key 和怎么使用 key,那要怎么保护 key 呢?
假如要将代码文件分享给朋友,或是上传 Github,就不能明文写入代码,我们有两种方式避免:
1.使用 python-dotenv 库
- 先安装:
pip install python-dotenv - 在
.py文件同目录新建一个.env文件,其中写入:DEEPSEEK_API_KEY=***** - 程序中实现:
python
import os
from dotenv import load_dotenv
# 加载 .env 文件中的环境变量
load_dotenv()
api_key = os.getenv("DEEPSEEK_API_KEY")- 但在 Git 提交时仍要注意将
.env文件排除。
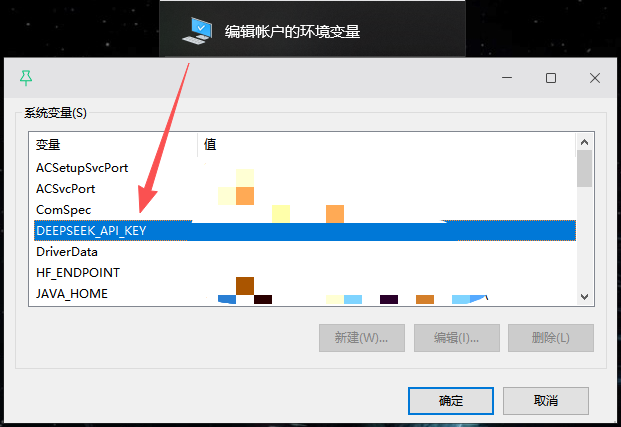
2.在电脑里直接建一个环境变量
load_dotenv 是在当前 python 环境中临时注入 .env 的变量,而我们还可以直接在电脑里建一个永久的。
LM Studio本地部署
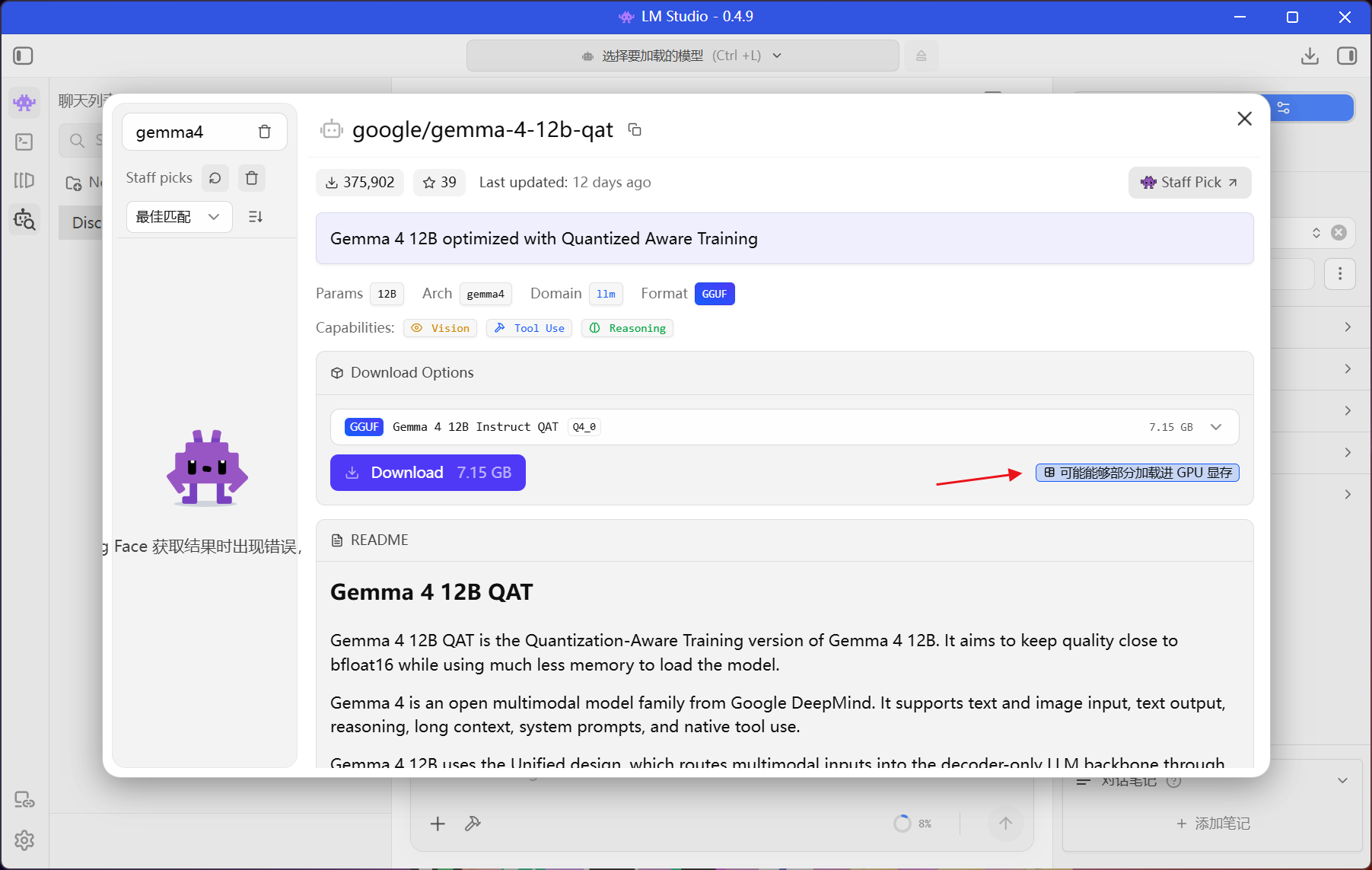
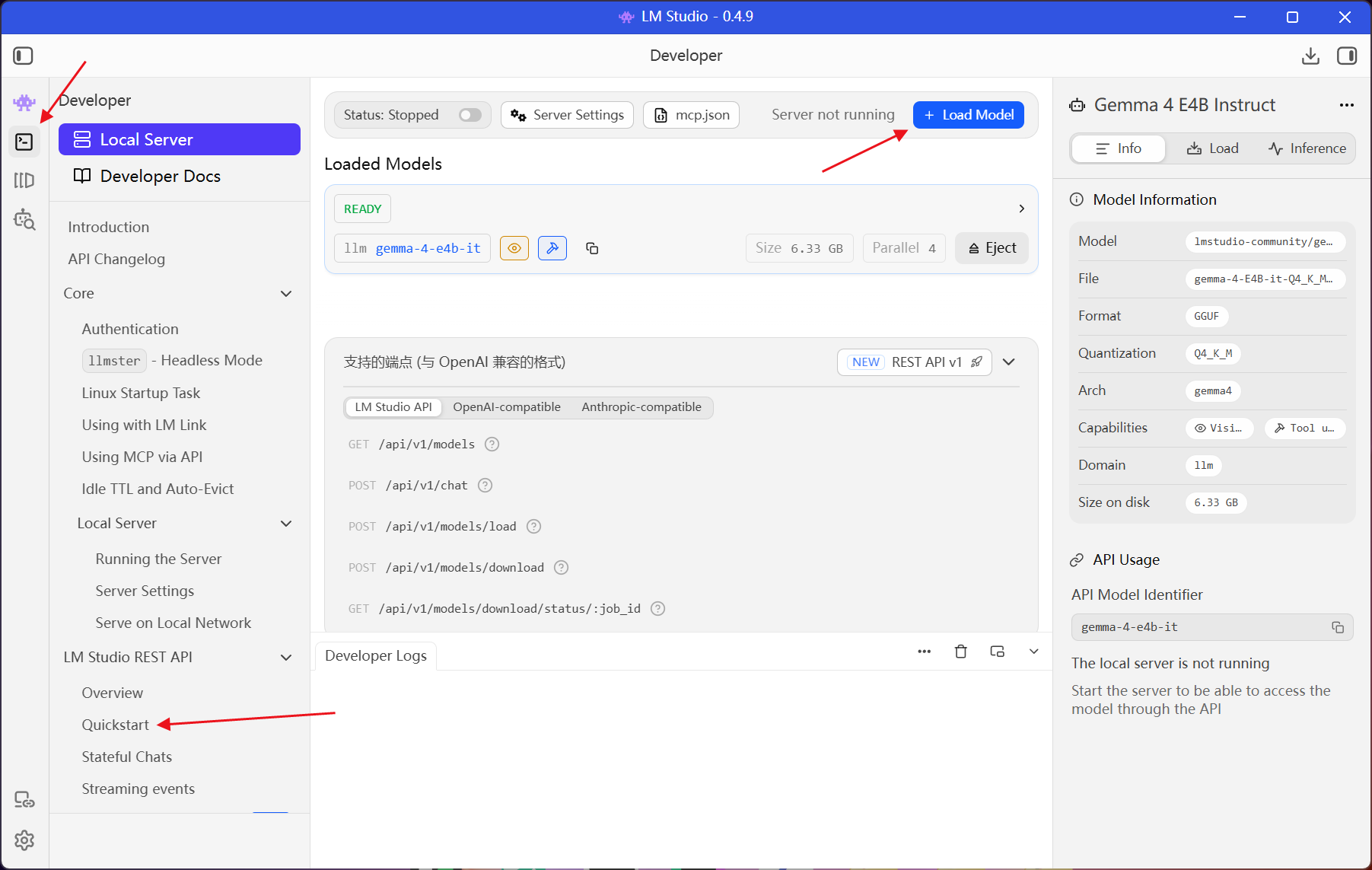
LM Studio 是最易用的本地 LLM 运行工具之一,有图形界面,一键加载模型、一键启动 API 服务。
使用步骤:
- 下载安装 LM Studio
- 在客户端界面中搜索并下载模型(会自动根据你电脑的配置提示是否能运行)
- 在开发者栏目中点击「Load Model」加载已下载的模型,在「Qucikstart」查阅接口文档
- 可在界面上按需对模型进行更多预设调整,如系统提示词、温度、上下文长度等
然后调用,无需输入 key :
python
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:1234/v1" # LM Studio本地地址
)
response = client.chat.completions.create(
model="gemma-4-e4b-it", # 使用LM Studio中加载的模型名称
messages=[{"role": "user", "content": "既然快递要 3 天才到为什么不提前 3 天发"}]
)
print(response.choices[0].message.content)当然也可以直接在界面上对话,进行快速测试后再调用 API。
(三)Ollama SDK:本地部署的最佳搭档
Ollama 是最流行的本地 LLM 运行工具,相比 LM Studio 的操作界面要简陋,更多是以 API 服务方式使用。
它也支持 OpenAI 兼容接口,但 Ollama 还有自己的官方 Python SDK,编码更简洁。
安装 Ollama 客户端并在命令行启动服务
下载地址:https://ollama.com/download
安装好并启动后,电脑右下角托盘会显示 ollama 的羊驼图标,可以鼠标右击后 open 打开对话界面。
也可以在命令行中操作。
bash
# 下载模型
ollama pull deepseek-r1:7b
# 运行模型(未下载的会先下载再运行)
ollama run qwen2.5:7b
# 启动服务(启动客户端后会同步启动服务,不用再输入命令)
ollama serve在 python 中操作前安装 ollama 库
bash
pip install ollama对话
python
import ollama
response = ollama.chat(
model="deepseek-r1:7b",
messages=[{"role": "user", "content": "去50米外的洗车店洗车,要开车去还是走路去"}]
)
print(response["message"]["content"])直接生成(非对话模式)
python
import ollama
response = ollama.generate(
model="qwen2.5:7b",
prompt="生鱼片其实是死鱼片,我最新的照片其实是我最老的照片"
)
print(response["response"])获取嵌入向量(用于RAG)
python
import ollama
response = ollama.embeddings(
model="nomic-embed-text",
prompt="皱纹是时间吹过身体时泛起的涟漪"
)
print(f"向量维度: {len(response['embedding'])}")
# >>> 向量维度: 768
# [0.09235624223947525, 0.9944853782653809, -4.030320644378662, -0.07801476866006851,...]流式输出
python
import ollama
stream = ollama.chat(
model="gemma3:270m",
messages=[{"role": "user", "content": "存在的星星不一定都发光,发光的星星不一定还存在"}],
stream=True
)
for chunk in stream:
if chunk["message"]["content"]:
print(chunk["message"]["content"], end="", flush=True)在个人电脑配置不高的情况下,可以选用 gemma3:270m 这个最小的模型来测试,速度还是蛮快的。

查看和管理本地模型
python
import ollama
# 拉取新模型
ollama.pull("gemma3:270m")
# 删除模型
ollama.delete("gemma3:270m")
# 列出已安装模型
models = ollama.list()
for model in models["models"]:
print(f"- {model['name']}")模型选用可浏览官网:https://ollama.com/library
不需要复杂推理的任务,如简单的图像识别、数据标注等,使用 14B 以下的模型即可获得较好的效果。
OpenAI SDK vs Ollama SDK?
- 如果你的项目完全本地化 → 用 Ollama SDK,API更简洁
- 如果你的项目可能还要调云端API → 统一用 OpenAI SDK,代码风格一致
附-本地部署模型所需配置:
| 模型参数量 | 推荐最小内存 | 推荐最小显存 | 推荐显卡型号 | 内存参考价 | 显卡参考价 |
|---|---|---|---|---|---|
| 1.5B ~ 3B | 8 GB | 4 GB | GTX 1060 6GB / RTX 3060 8GB | ~800 元 (8GB DDR5) | 500~1,500 元 (二手) |
| 7B ~ 8B | 16 GB | 8 GB | RTX 3060 12GB / RTX 4060 8GB | ~1,500 元 (16GB DDR5) | 2,000~2,500 元 |
| 14B | 32 GB | 16 GB | RTX 4070 Ti Super 16GB | ~2,500 元 (32GB DDR5套条) | 6,000~7,000 元 |
| 32B | 64 GB | 24 GB | RTX 3090 24GB(二手性价比王) | ~5,000 元 (64GB DDR5套条) | 6,000~8,000 元 (二手) |
| 70B | 128 GB | 48 GB | RTX 3090 ×2 / RTX 4090 ×2 | ~10,000 元 (128GB DDR5) | 13,000~26,000 元 (双卡) |
| 70B (单卡勉强) | 64 GB | 32 GB | RTX 5090 32GB | ~5,000 元 (64GB DDR5套条) | 28,000~32,000 元 |
(四)ModelScope:魔搭社区的调用方式
ModelScope(魔搭社区)是阿里达摩院推出的 AI 模型社区,汇聚了大量开源模型,并提供免费在线推理 API。

通过OpenAI兼容接口调用
ModelScope 的 API 推理服务同样兼容 OpenAI 格式:
python
from openai import OpenAI
client = OpenAI(
api_key="MODELSCOPE_ACCESS_TOKEN", # 魔搭的AccessToken
base_url="https://api-inference.modelscope.cn/v1" # 魔搭的接口地址
)
response = client.chat.completions.create(
model="qwen/Qwen2.5-72B-Instruct",
messages=[{"role": "user", "content": "人只有醒来后才知道自己睡了一觉"}]
)
print(response.choices[0].message.content)通过ModelScope SDK 使用模型
可以让开发者显式的控制模型的推理的每一步,所以官方示例看起来花里胡哨的:
python
from modelscope import AutoModelForCausalLM, AutoTokenizer
# AutoModelForCausalLM: 自动加载因果语言模型(Causal LM),适用于文本生成任务
# AutoTokenizer: 自动加载与模型配套的分词器,负责文本与token ID之间的相互转换
model_name = "Qwen/Qwen2.5-0.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # 自动选择合适的数据类型(通常为 float16 或 bfloat16),减少显存占用,同时保持推理精度
device_map="auto" # 自动将模型分配到可用的计算设备(优先GPU,无GPU则用CPU)
)
tokenizer = AutoTokenizer.from_pretrained(model_name) # 构建分词器
prompt = "魔搭还提供了很多复杂的功能,比如训练、微调"
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template( # 应用对话模板,将消息列表按照模型要求的模板格式拼接成完整的输入字符串
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device) # 对输入文本进行分词和编码
generated_ids = model.generate( # 模型根据输入的 token 序列,自回归地逐个生成后续 token
**model_inputs,
max_new_tokens=512
)
generated_ids = [ # 截取新生成的部分
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] # 将 token ID 解码为可读的文本官方文档的介绍还是很详细的,就不多做演示了。
地址:https://modelscope.cn/docs/intro/quickstart
ModelScope 的特点:
- ✅ 有免费额度,适合学习和测试
- ✅ 中文模型丰富,国内访问快
- ✅ 支持下载开源模型到本地,结合本地推理使用
- ✅ 功能强大,适合对模型进行精细的调整
四、调用方式对比小结
调大模型 API 这件事,看起来不复杂,发个 HTTP 请求,拿回结果。但不同场景该用什么调用方式呢?一表速览:
| 调用方式 | 定位 | 一句话总结 |
|---|---|---|
| requests | 理解底层 | 知道协议在干什么,出问题能排查 |
| OpenAI SDK | 实战主力 | 一次学会,通吃云端+本地 |
| Ollama SDK | 本地专用 | Ollama 部署场景的最简调用 |
| ModelScope | 社区生态 | 魔搭免费额度+模型管理 |
One more thing:大模型有记忆吗?
我们在网页上跟AI聊天,聊了二十个来回,它记得第一句话说了啥,记得中途改了主意,记得刚才开的玩笑,看起来它真的「记住了」一切。
但事实是:大模型根本没有任何记忆。
每一次API调用,模型都是从零开始的。它不记得上一秒我们问了什么,也不记得自己上一秒回答了什么。对它来说,每个请求都是全新的、独立的、跟之前毫无关联的。
那聊天界面里的「记忆」是怎么来的?靠拼接上下文。
我们看到的连续对话,在底层长这样:
第1轮 API 调用:
输入 → [User:今天天气怎么样?]
输出 → [AI:今天北京晴转多云......]
第2轮 API 调用:
输入 → [User:今天天气怎么样?] ← 上一轮的问题
[AI:今天北京晴转多云......] ← 上一轮的回答
[User:那明天呢?] ← 这一轮的新问题
输出 → [AI:明天预计有小雨......]
第3轮 API 调用:
输入 → [User:今天天气怎么样?] ← 第1轮的问题
[AI:今天北京晴转多云......] ← 第1轮的回答
[User:那明天呢?] ← 第2轮的问题
[AI:明天预计有小雨......] ← 第2轮的回答
[User:需要带伞吗?] ← 这一轮的新问题
输出 → [AI:建议带一把......]发现了吗?每一轮调用,程序都会把你之前的所有对话历史,连同新问题一起,打包塞进输入里。 聊了10轮,输入里就有10轮的完整内容;聊了100轮,输入里就有100轮,越聊越「厚实」,Token越烧越多,但模型本身始终是空白的。
这就是所谓的无状态(Stateless)。LLM 自己不会保存任何上下文,它只认当前请求里的内容。在聊天界面里感受到的「记忆」,是程序帮我们拼出来的幻觉。
用代码来说更直观,手动调API时,「记忆」就是这么拼的:
python
# 第一轮:从零开始
messages = [
{"role": "user", "content": "今天天气怎么样?"}
]
response1 = client.chat.completions.create(model="deepseek-v4-flash", messages=messages)
# "记住"AI的回答,追加到消息列表
messages.append({"role": "assistant", "content": response1.choices[0].message.content})
# 第二轮:把历史+新问题一起塞进去
messages.append({"role": "user", "content": "那明天呢?"})
response2 = client.chat.completions.create(model="deepseek-v4-flash", messages=messages)看到的 messages 列表越拼越长,这就是「记忆」的秘密。
理解了这一点,我们就知道为什么有时 AI 的表现会变糟糕了。
| 现象 | 根本原因 |
|---|---|
| 聊久了AI忘了开头说的话 | 上下文窗口有上限,拼不下了只能截断 |
| AI突然人格分裂 | 长上下文里信息相互干扰,模型被自己之前的回答带偏了 |
| 聊得越久响应越慢、费用越高 | 输入Token在累积增长,每轮都在重新处理全部历史 |
| 换个窗口就失忆 | 新会话=新的空消息列表,之前的历史没带过来 |
所以,当用API构建应用时,「记忆管理」不是可选项,而是必做题。 我们得自己决定:保留多少轮历史?超长了是截头还是摘要?重要信息要不要单独存一份放系统提示词里?这些策略直接决定了 AI 是「金鱼脑」还是「过目不忘」。
Agent产品里那些看起来很聪明的「长期记忆」,本质上也就是一套外部存储+检索拼接的系统:把关键信息存进数据库,每次调用时从库里捞出来拼进输入里。
模型本身,始终没有真正记住过你。
后记
这里是前数据分析师 Seon塞翁,想着写点老本行的内容,现在便利的 AI 产品越来越多了,我们还在多大程度上需要自己去设计呢?AI大人快点取代我吧!QAQ
那么那么,如何用 Python + LLM 进行批量数据分析 或图像识别 ,又如何利用端云结合的设计实现敏感数据本地处理、常规数据上云加速,限于篇幅,我们下一次再揭晓!~
谢谢阅读,
如果本文对你有帮助,
随手点赞、收藏、转发吧!