先说一个让我「咯噔」一下的瞬间
前段时间看到 Claude Code 负责人 Boris Cherny 说了句话,大意是:我已经不写 Prompt 了,我只写 Loop
我的第一反应是:啊?Prompt 不是刚学会怎么写好吗?怎么就又过时了?
但仔细想了下这句话背后的意思,突然意识到它不是在讲什么新技术,而是在讲一个我们早就该意识到的问题 ------如果每次用 AI,你都要在它身边喊「继续」「还是报错」「你改了啥」「回滚」,那说明你其实不是在用工具,你是在当监工
而 Loop Engineering 想做的事,就是把这个「监工」也裁掉
我理解的 Loop Engineering 到底是什么
一句话版本:
把「你盯着 AI 干活、不断纠正它」的过程,写成一套自动化流程,让 AI 自己盯着自己
它跟写 Prompt 的核心区别在于:
| 写 Prompt | 设计 Loop |
|---|---|
| 你告诉 AI 要做什么 | 你告诉 AI 怎么自己检查自己做没做好 |
| 只描述任务 | 同时描述任务 + 验收标准 + 失败后的纠偏路径 |
| 你守在旁边等着纠错 | 你想好所有可能的坑,提前把纠错逻辑写进流程 |
| 一次性的指令 | 一个能自己转起来的闭环 |
本质上,Loop Engineering 是把**测试驱动开发(TDD)**的哲学搬到了 AI 交互上
TDD 说:先写测试用例,再写代码。Loop Engineering 说:先定义「什么算做好」,再让 AI 跑
区别只在于 ------ TDD 跑测试的是你,Loop Engineering 跑测试的是 Agent 自己
为什么这个概念现在突然火了
我梳理了一下时间线,发现这不是偶然:
-
模型能力到位了。不管是 Claude、GPT 还是 Gemini,现在的模型已经足够聪明,能够在大多数任务上给出「还行」的结果。问题的瓶颈不再是「模型做不出来」,而是「模型做出来的跟你要的有差距」
-
Agent 基础设施成熟了。Agent Loop(工具调用 → 观察结果 → 继续调用)已经是标配。Claude Code 有 Hook、Cron、Sub Agent、Worktree 隔离;Codex 也有类似的能力。基建铺好了,就差一套方法论
-
大家都在喊累。「继续」「还是报错」「你改了啥」「先别重构」成了 Claude Code 用户的高频词。AI 确实帮了忙,但人还是被拴在交互循环里。效率提升遇到了天花板
这三件事叠加在一起,Loop Engineering 的出现几乎是必然的 ------ 它解决的恰恰是这个「天花板」。
两个 Loop,别搞混了
我把原文里最核心的区分用自己的话重新说一遍:
Agent Loop(底层循环):模型收到任务 → 判断要不要调工具 → 调工具 → 拿到结果 → 再判断要不要调工具 → ...直到输出最终答案。这是 Agent 的「心跳」,是代码层面的事
Loop Engineering(上层循环) :你给 Agent 一个任务 + 验收标准 → Agent 干活 → Agent 自己跑测试 → Agent 发现不对就自己改 → Agent 再测试 → ...直到达到标准。这是人设计的流程,是方法论层面的事
打个比方:
-
Agent Loop = 汽车引擎的四个冲程(进气、压缩、做功、排气),是物理规律,每辆车都有
-
Loop Engineering = 你给车装上自动驾驶系统,设定目的地,然后它自己规划路线、自己避开拥堵、自己调整方向
前者是「这辆车能跑」,后者是「这辆车能自己开到目的地,不用我握方向盘」
六个组件,我的理解排序
原文讲了 Loop Engineering 的六大核心组件,我把它们按照「从最基础到最进阶」的优先级重新排了一下,加上自己的判断:
第一层:没有它们,Loop 跑不起来
① Connectors / Plugins(连接器) --- 这是 Agent 的「手和脚」。没有 MCP 和各种 API 对接,Agent 就是个只会说话的脑袋,什么都做不了
② State(状态管理) --- 这是 Agent 的「记忆」。不记录「做到了哪一步」,Loop 每转一圈都像第一次转。这里原文提的方法是 AGENTS.md 或对接 Linear,我觉得核心不是用什么工具,而是让 Agent 能知道自己从哪来、到哪去
第二层:没有它们,Loop 跑不稳
③ Worktrees(工作树隔离) --- 多个 Agent 同时跑的时候,这是避免「互相踩脚」的关键。我理解这其实不是一个 Loop Engineering 特有的需求,而是并行 Agent 的通用基础设施。但它的重要性被很多人低估了 ------ 两个 Agent 同时改同一行代码导致的 bug,排查起来比单线程 bug 痛苦得多
④ Automations(自动化调度) --- 这是 Loop 的「发动机」。Cron 定时任务、/loop 命令、Hook 触发......让 Loop 不光能「手动启动一次」,还能「定时自己跑」。这里我特别认同原文的一个判断:不是所有任务都值得做成定时 Loop。如果流程固定,写成脚本能省很多 Token
第三层:没有它们,Loop 不够聪明
⑤ Sub Agents(子智能体) --- 这是 Loop 的「质检员」和「专项小组」。原文提到一个我特别认可的设计哲学:验证 Sub Agent 必须跟主 Agent 解耦,不能既当运动员又当裁判员。这其实就是软件工程里的「code review 不能由写代码的人自己做」在 AI 时代的翻版
⑥ Skills(可进化的技能包) --- 这是 Loop 的「肌肉记忆」。每一次 Loop 转完,把经验沉淀成可复用的 Skill,下次就不用从头推理。这才是真正的「越用越聪明」。我理解这跟 RAG 里的知识库是同一个思路,只是粒度更粗、更面向任务
一个让我脑子里「通了」的类比
如果把 AI Agent 比作一个新来的实习生:
-
写 Prompt = 每次给实习生下一份详细的任务说明书。「把这个 Excel 里的数据按这 5 条标准分类,输出到一个新表里」
-
Agent Loop = 实习生拿到说明书之后,自己查资料、问同事、用工具,一步步把活干了
-
Loop Engineering = 你不光给了任务说明书,还给了验收清单、自检流程和纠偏手册。「分完类之后,自己随机抽 20 条检查准确率;如果不到 95%,看看哪些类型最容易分错,把那几类的判断准则再细化一下;然后再分类、再检查,直到达标。最后把你稳定下来的判断标准整理成文档。」
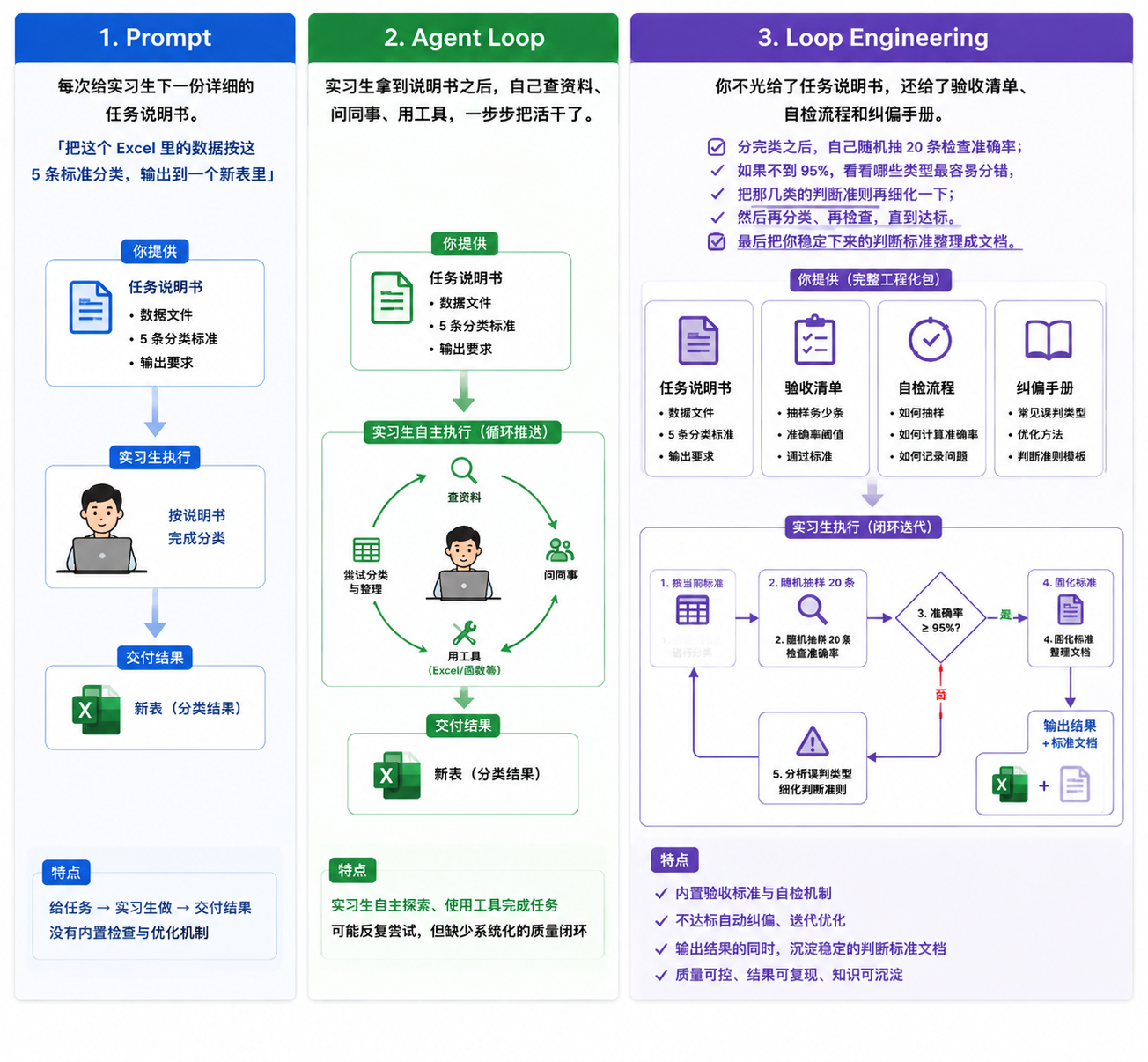
区别在哪?
第一种,你省了干活的时间,但没省检查的时间
第二种,你连检查的时间也省了,你只需要最后确认一下结果就行
这就是 Karpathy 说的:「把你自己从 Loop 的执行过程中移除出去」
不是所有人都该急着上 Loop
我觉得这是原文最有价值但也最容易被忽略的部分。用 Loop 之前,先问自己三个问题:
-
你能不能说清楚「做到什么程度才算好」? 如果你连验收标准都写不出来,那 Loop 等于瞎子开车
-
你的验收标准本身对不对? 如果验收标准有漏洞,Loop 会把漏洞放大 ------ Agent 花费大量 Token 优化出一个在错误方向上的「完美」结果
-
你现阶段是不是真的需要自动化到这种程度? 如果任务只做一次,或者你自己都还在摸索需求,那 Human-in-the-Loop 不但不落后,反而是更理智的选择
Loop Engineering 提高的不是 AI 的上限,而是提升了对你(使用者)的要求。你得比原来更清楚自己要什么、怎么判断要到了、没要到该怎么办
模糊的需求 + Loop = 烧着 Token 跑偏路
清晰的需求 + Loop = 省时省力的自动化流水线
几个判断
写到最后,想逼自己输出几个明确的观点:
-
Loop Engineering 不是新发明,是新命名。 它本质上是把 TDD、CI/CD、自动化测试这些软件工程的老概念搬到了 AI Agent 上。但「给旧东西起新名字」本身就有价值 ------ 它让模糊的实践变成了可讨论、可优化、可传播的术语
-
Prompt 不会被取代,但会被升维。 Loop 不是不写 Prompt 了,而是把 Prompt 拆成了「任务描述 + 验收标准 + 纠偏策略」三个部分。Prompt 工程从「一段话」变成了「一套流程」
-
未来一年,会出现「Loop 模板市场」。 就像现在有 Prompt 模板,未来一定会有针对不同场景的 Loop 模板 ------「代码审查 Loop」「日报生成 Loop」「数据分析 Loop」。好的 Loop 写起来比好 Prompt 难得多,复用价值也高得多
-
Loop Engineering 的终局不是「人完全不用管」,而是「人只在最有价值的时候介入」。 人不再当监工,而是当架构师 ------ 设计流程、定义标准、处理 Agent 搞不定的边缘情况。人的精力从「催进度」和「改 bug」里解放出来,去干更需要创造力的事
最后
Loop Engineering 这个概念让我想起一个老笑话:
一个程序员花 5 天写了一个脚本,自动完成一件每天需要 5 分钟的事情。他一共需要连续运行这个脚本 300 年才能收回时间成本
但笑完想想,AI 时代可能正好相反:
你花 1 小时写了一个 Loop,让 Agent 自动完成一件本来每次需要 5 小时的事情。你跑第一次就赚回来了
工具的价值不在于「做了以前做不了的事」,而在于「让以前能做但太贵的事,变成顺手的事」
Loop Engineering,就是在做这件事