前言
Spring AI Framework(四:RAG ETL Pipeline 和 RAG混合检索(向量+关键词)),包括:
1)RAG ETL流水线的三个阶段(文档读取、转换处理、向量存储)及代码示例;
2)混合检索方案,结合向量相似度搜索和关键词过滤),详细展示PostgreSQL的向量+全文检索+RRF融合排序实现。
码演示了从文档处理到智能问答的完整流程,为构建高效RAG系统提供了实用解决方案。
一、RAG ETL Pipeline
Extract, Transform, and Load 流水线
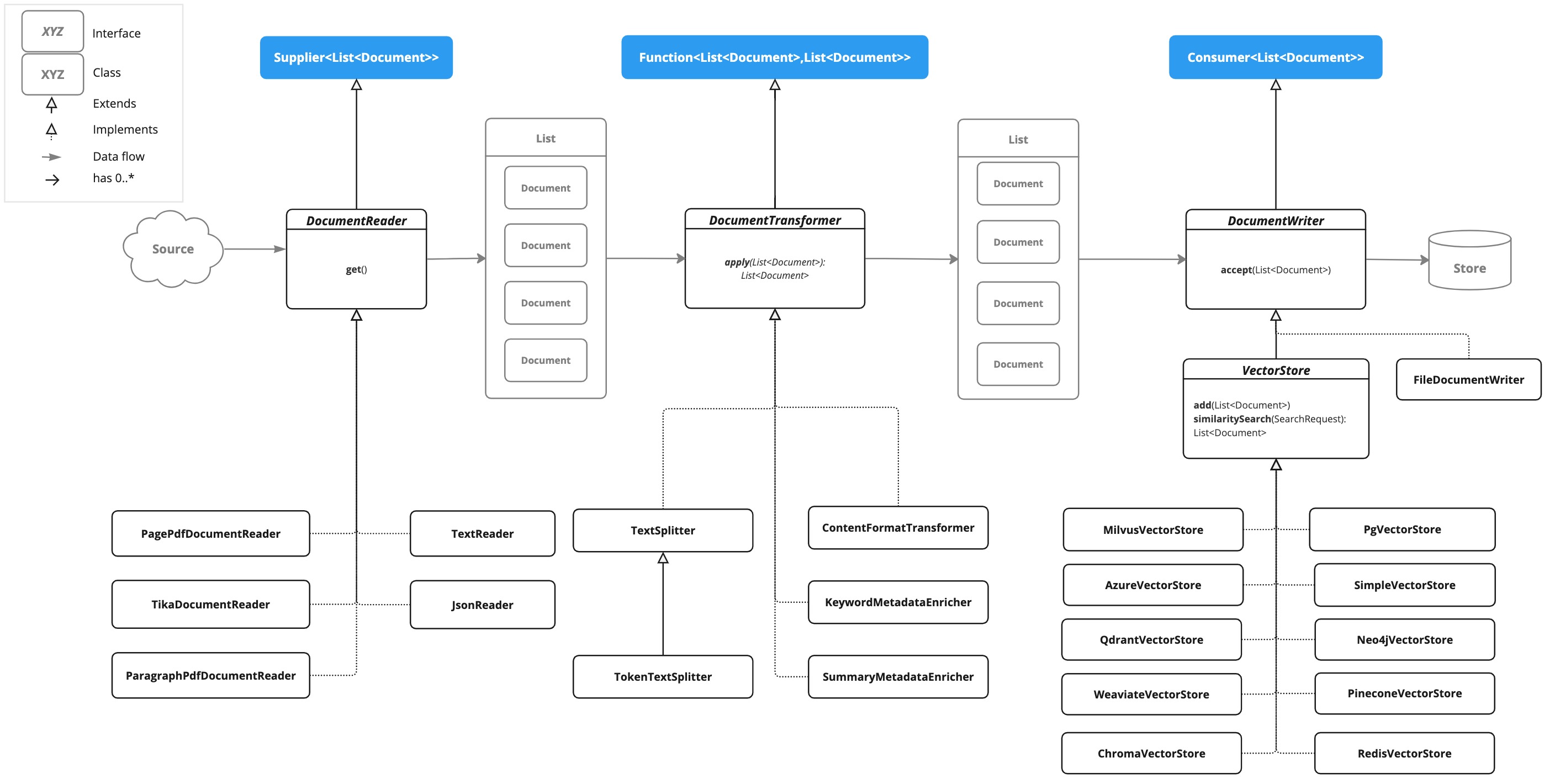
提取、转换和加载(ETL)框架是检索增强生成(RAG)应用场景中数据处理核心,负责创建、转换和存储文档(包含文本、元数据以及可选的额外媒体类型,如图片、音频和视频)实例。从原始数据源到结构化向量存储的流程,确保数据格式为 AI 模型检索的最佳格式。
ETL 流水线类图
ETL 流程图
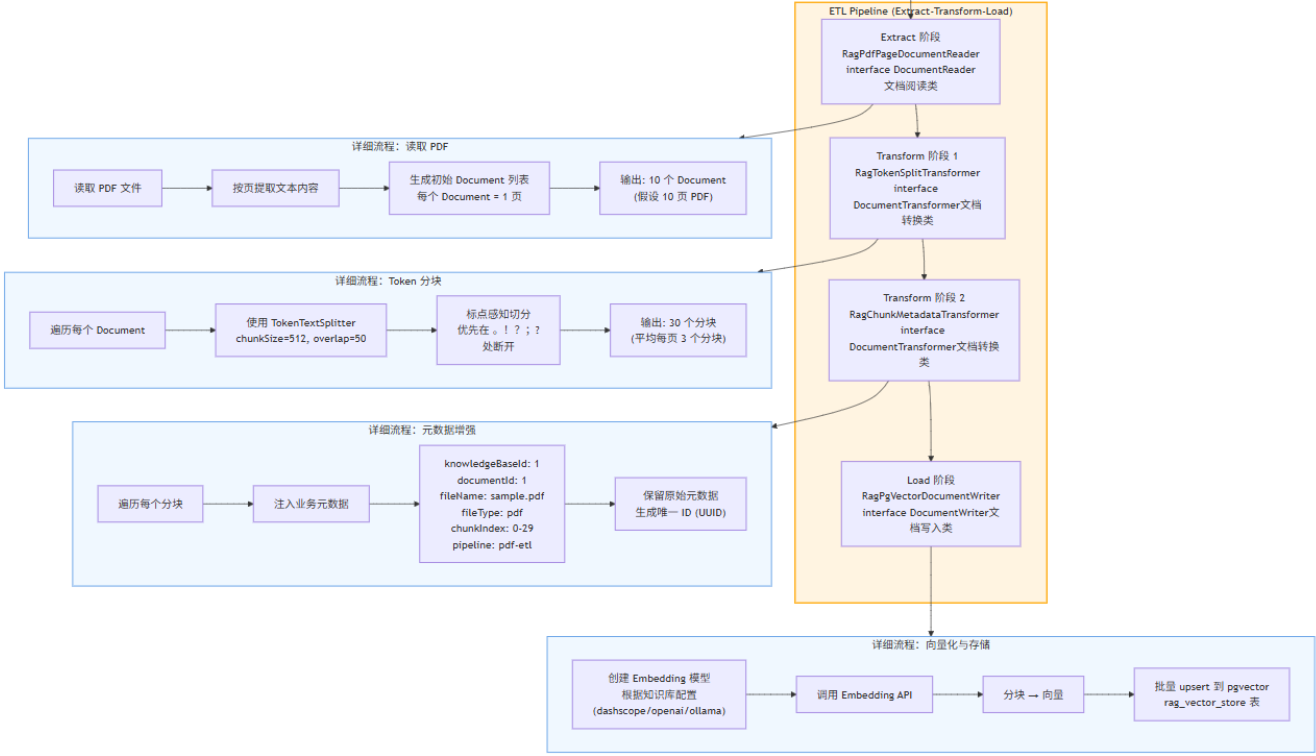
RAG ETL三阶段 + LLM生成流程
ETL阶段:DocumentReader → DocumentTransformer → DocumentWriter
[读取] [转换] [向量增强、存储:写入向量数据库(Vector Store)]
用户提问(userQuestion) → [ETL阶段] → 检索阶段 → Prompt填充 → LLM生成示例用法
RAG ETL三阶段 + LLM生成流程Code
java
@Autowired
private PgVectorStore pgVectorStore;
log.info("step1.读取文档: {}", filePath);
DocumentReader reader = new PagePdfDocumentReader(filePath);
List<Document> rawDocs = reader.get();
log.info("Step2: 转换管道:文档转换、分块");
List<Document> processedDocs = transformDocuments(rawDocs);
/* 2.1 文档转换管道 */
private List<Document> transformDocuments(List<Document> rawDocs) {
List<Function<List<Document>, List<Document>>> transformers =
Arrays.asList(
// 1. 文本分块(Token级别)
docs -> {
TokenTextSplitter splitter = new TokenTextSplitter(500, 50);
return splitter.apply(docs);
},
// 2. 内容格式化
docs -> {
ContentFormatTransformer formatter = new ContentFormatTransformer();
return formatter.apply(docs);
},
// 3. 元数据增强
docs -> {
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher();
return enricher.apply(docs);
}
);
//遍历Transformer,执行apply进行转换/增强
List<Document> processedDocs = rawDocs;
for (Function<List<Document>, List<Document>> transformer : transformers) {
processedDocs = transformer.apply(processedDocs);
}
return processedDocs;
}
/*step3.向量增强、写入、存储
pgVectorStore implements VectorStore
extends DocumentWriter[写入类], VectorStoreRetriever[检索器]
*/
// 方式一:使用 Spring AI 自动向量化(推荐)
pgVectorStore.add(processedDocs);
// 方式二:手动控制向量化(自定义)
List<Document> embeddedDocs = embedDocuments(processedDocs);
pgVectorStore.add(embeddedDocs);
/* 自定义:手动向量化(如需要精细控制) */
private List<Document> embedDocuments(List<Document> docs) {
// 批量提取文本
List<String> contents = docs.stream()
.map(Document::getContent)
.collect(Collectors.toList());
// 批量生成向量(节省API调用)
List<List<Double>> embeddings = embeddingModel.embed(contents);
// 将embed加强向量写入Document
for (int i = 0; i < docs.size(); i++) {
Document doc = docs.get(i);
doc.getMetadata().put("embedding", embeddings.get(i));
}
return docs;
}
//step4.检索阶段:执行相似性检索
//构建检索请求(支持过滤器)
//过滤器:按knowledgeBaseId=1条件过滤知识库空间
Filter.Expression knowledgeBaseFilter = new Filter.Expression(
Filter.ExpressionType.EQ,
new Filter.Key("knowledgeBaseId"),
new Filter.Value("1"));
SearchRequest request = SearchRequest.builder()
.query(userQuestion) //用户问题
.topK(4) //相似度召回:返回匹配的结果数量,默认值4
.similarityThreshold(0.6).
.filterExpression(knowledgeBaseFilter)//可选的过滤条件表达式
.build();//相似度过滤阈值
List<Document> relevantDocs = pgVectorStore.similaritySearch(request);
log.info("检索到{}个相关文档", relevantDocs.size());
//step5.Prompt填充
String prompt = buildRagPrompt(userQuestion, relevantDocs);
private String buildRagPrompt(String question, List<Document> docs) {
// 构建上下文
String context = docs.stream().map(doc -> {
Map<String, Object> metadata = doc.getMetadata();
String source = (String) metadata.getOrDefault("source", "未知来源");
String page = String.valueOf(metadata.getOrDefault("pageNum", "N/A"));
String keywords = String.valueOf(metadata.getOrDefault("keywords", ""));
return String.format(
"【来源:%s | 页码:%s | 关键词:%s】\n%s",
source, page, keywords, doc.getContent());
})
.collect(Collectors.joining("\n\n---\n\n"));
return String.format("""
你是一个知识助手,请基于以下文档上下文回答问题。
## 文档上下文
%s
## 用户问题
%s
## 要求
1. 只基于上述上下文回答
2. 如果上下文信息不足,请明确说明
3. 回答要准确、结构化
4. 可以引用文档来源
""", context, question);
}
//step6.LLM生成
String response = DefaultChatClientRequestSpec
.user(userPrompt).call().content();二、RAG混合检索(向量+关键词)
混合检索(向量 +关键词 (内存)排序
java
/**
* 混合检索(向量+关键词)
*/
public String hybridSearchChat(String userQuestion, String keyword) {
// 1. 向量检索
List<Document> vectorResults = pgVectorStore.similaritySearch(
SearchRequest.query(userQuestion).withTopK(10)
);
// 2. 关键词过滤(内存中过滤)
List<Document> keywordResults = vectorResults.stream()
.filter(doc -> doc.getContent().toLowerCase()
.contains(keyword.toLowerCase()))
.limit(3)
.collect(Collectors.toList());
// 3. 构建Prompt并生成回答
String prompt = buildRagPrompt(userQuestion, keywordResults);
return response = DefaultChatClientRequestSpec
.user(prompt).call().content();
}混合检索:向量相似度 + 全文检索 + RRF 融合
java
//1.PostgreSQL Repository 自带全文检索能力(tsvector / ts_rank)
@Repository
public interface DocumentRepository extends JpaRepository<DocumentEntity, Long> {
/**
* 混合检索:向量相似度 + 全文检索 + RRF 融合
* PostgreSQL函数:
* to_tsvector 全文检索中最核心的函数,将文本转换为文本搜索向量
* ts_rank-计算文本相关性分数
* setweight-设置词条权重(A最重)
* websearch_to_tsquery-解析 Web 风格查询
* @param queryText 用户查询文本,如:⽤「⼤⽩话+极简步骤」讲明⽩...
* @param queryVector 加强向量浮点数组向量,如[-0.09364914,....共1024个值......]。
和存储嵌入模型embeddingModel维度有关,如V3是1024,故数组长度为1024]
* @param topK 返回结果数量,相似度召回:返回匹配的结果数量,默认值4
* @param vectorLimit 向量检索取更多候选,topK * 2,提高召回率
* @return 按混合相关性排序的文档列表
*/
@Query(value = """
SELECT * from (
SELECT
id,
content,
metadata,
vector_score,
keyword_score,
-- RRF 融合公式: 1/(60 + rank) 求和
(COALESCE(1.0 / (60 + vector_rank), 0) + COALESCE(1.0 / (60 + keyword_rank), 0)) as rrf_score
FROM (
-- 向量相似度
SELECT
COALESCE(v.id, k.id) as id,
COALESCE(v.content, k.content) as content,
COALESCE(v.metadata, k.metadata) as metadata,
v.vector_score,
v.vector_rank,
k.keyword_score,
k.keyword_rank
FROM (
SELECT
id,
content,
metadata,
embedding,
1 - (embedding <=> :queryVector::vector) AS vector_score,
ROW_NUMBER() OVER (ORDER BY embedding <=> :queryVector::vector) as vector_rank
FROM rag_vector_store
LIMIT :vectorLimit
) v
FULL OUTER JOIN (
-- key全文检索
SELECT
id,
content,
metadata,
embedding,
ts_rank(setweight(to_tsvector('simple', COALESCE(content, '')), 'A'), websearch_to_tsquery('simple', :queryText)
) as keyword_score,
ROW_NUMBER() OVER (
ORDER BY ts_rank(
setweight(to_tsvector('simple', COALESCE(content, '')), 'A'),
websearch_to_tsquery('simple', :queryText)
) DESC
) as keyword_rank
FROM rag_vector_store
WHERE websearch_to_tsquery('simple', :queryText) @@ setweight(to_tsvector('simple', COALESCE(content, '')), 'A')
) k ON v.id = k.id
) combined
) u
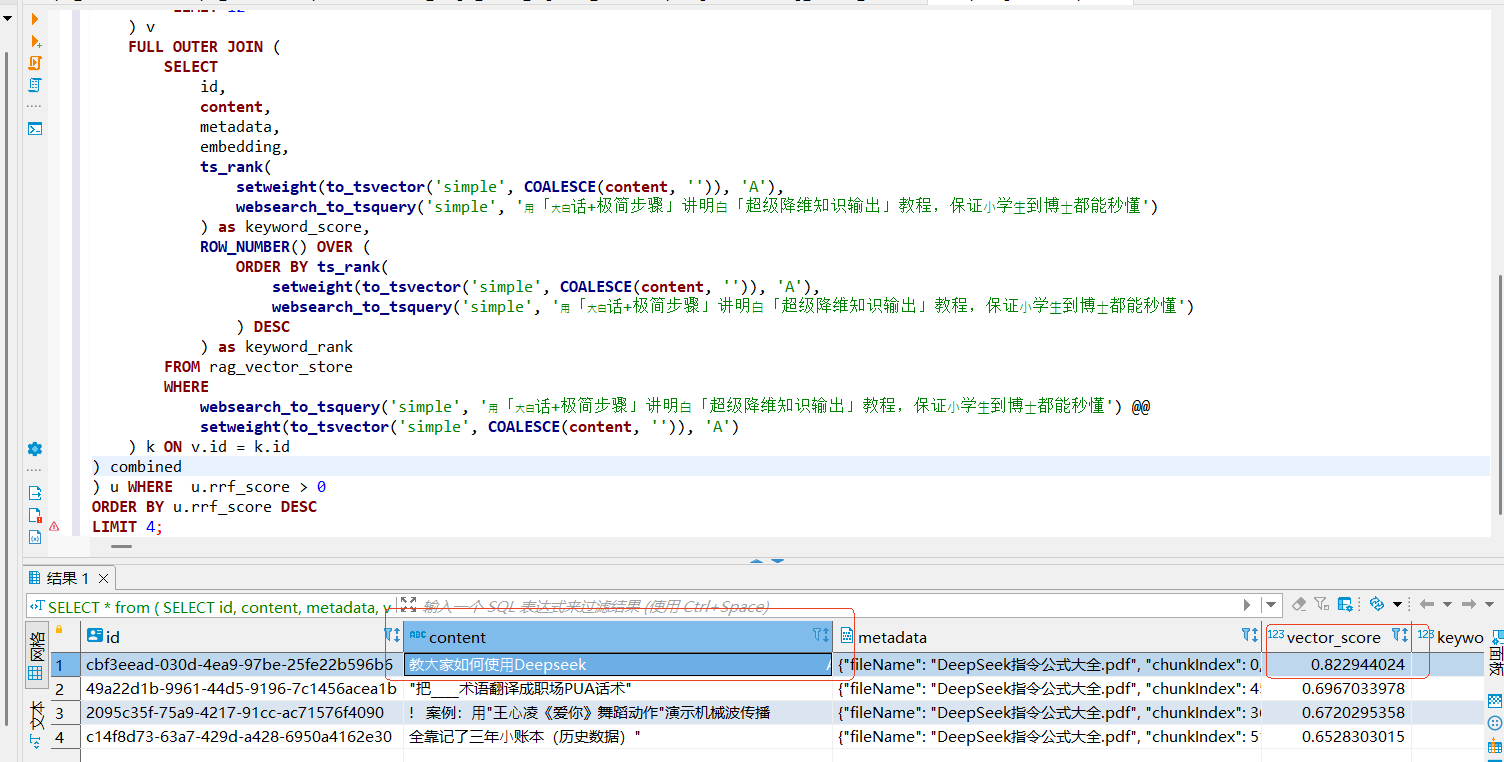
WHERE u.rrf_score > 0
ORDER BY u.rrf_score DESC
LIMIT :topK
""", nativeQuery = true)
List<Object[]> hybridSearch(
@Param("queryText") String queryText,
@Param("queryVector") String queryVector,
@Param("topK") int topK,
@Param("vectorLimit") int vectorLimit
);
}
/***************************分割线******************************/
//检索
String queryText = searchRequest.getQuery();
// 生成查询向量
float[] queryVector = embeddingModel.embed(queryText);
//转换为PGVector可接受的字符串格式
String vectorString = formatVector(queryVector);
// 转换方法体
private String formatVector(float[] vector) {
StringBuilder sb = new StringBuilder("[");
for (int i = 0; i < vector.length; i++) {
if (i > 0) sb.append(",");
sb.append(vector[i]);
}
sb.append("]");
return sb.toString();
}
List<Object[]> results = documentRepository.hybridSearch(
queryText,
vectorString,
topK,
vectorLimit
);检索后的结果