本地缓存把数据缓存在服务进程的内存中.不需要网络开销.故而性能非常高.但是把数据缓存到内存中也有较多限制.
1.无法共享:
多个服务进程之间无法共享本地缓存.
2.编程语言限制:
本地缓存与程序绑定.用Golang开发的本地缓存组件不可以直接用Java语言开发的服务所使用.
3.可扩展性差:
由于服务进程携带了数据.因此服务是有状态的.有状态的服务不具备较好的可扩展性.
4.内存易失性:
服务进程重启.缓存数据全部丢失.
分布式缓存选型:
主流的分布式缓存开源项目有Memcached和Redis.两者都是优秀的缓存产品.并且都具有缓存数据共享 与编程语言无关的能力.不过相对于Memcached而言.Redis更为流行.主要体现如下.
1.数据类型丰富:
Memcached仅支持字符串数据类型缓存.而Redis支持字符串 列表 集合 哈希 有序集合等数据类型缓存.
2.数据可持久:
Redis通过RDB机制和AOF机制支持数据持久化.而Memcached没有数据持久化能力.
3.高可用性:
Redis支持主从复制模式.在服务器遇到故障后.它可以通过主从切换操作保证缓存服务不间断.Redis具有较高的可用性.
4.分布式能力:
Memcached本身并不支持分布式.因此只能通过客户端.以一致性哈希这样的负载均衡算法实现基于Memcached分布式缓存系统.而Redis有官方出品的无中心分布式方案Redis Cluster.业界也有豆瓣Codis和推特的Twemproxy的中心化分布式方案.
Redis缓存使用:
1.尝试在Redis缓存中查找数据.如果命中缓存.则返回数据.
2.如果在Redis缓存中找不到数据.则从数据库读取数据.
3.将从数据库中读取的数据保存到Redis缓存中.并为此数据设置一个过期时间.
4.下次在Redis缓存中查找同样的数据.就会命中缓存.
将数据保存到Redis缓存时.需要为数据设置一个合适的过期时间.这样有如下好处.
1.如果没有为缓存数据设置过期时间.那么数据会一直堆积在Redis内存中.尤其是那些不在被访问或者命中率极低的缓存数据.它们一直占用Redis内存会造成大量资源的浪费.设置过期时间可以使Redis自动删除那些不被访问的缓存数据.而对于经常被访问的缓存数据.每次被访问时都会重置过期时间.可以保证缓存命中率高.
2.当数据库与Redis缓存由于各种故障出现了数据不一致的情况时.过期时间是一个很好的兜底手段.例如.设置缓存数据的过期时间为10s.那么数据库和Redis即使出现数据不一致的情况.最多也就持续10s.过期时间可以保证数据库和Redis缓存仅在此时间内有数据不一致的情况.因此可以保证数据的最终一致性.
在上述逻辑中.有一个极有可能带来风险的操作.某请求访问的数据在Redis缓存中不存在.此请求会访问数据库读取数据.而如果有大量请求访问数据库.则可能导致数据库崩溃.Redis缓存中不存在某数据.只可能有两种原因.一是在Redis缓存中从未存储过此数据.二是此数据已经过期.
缓存穿透:
当用户试图请求一条连数据库中都不存在的非法数据时.Redis缓存会显得形同虚设.
1.尝试在Redis缓存中查找此数据.如果命中.则返回数据.
2.如果在Redis缓存中找不到此数据.则从数据库中读取数据.
3.如果在数据库中也找不到此数据.则最终向用户返回空数据.
可以看到.Redis缓存完全无法阻挡此类请求直接访问数据库.如果黑客恶意持续发起请求来访问某条不存在的非法数据.那么这些非法请求会全部穿透Redis缓存而直接访问数据库.最终导致数据库崩溃.这种情况被称为"缓存穿透".
为了防止出现缓存穿透的情况.当在数据库中也找不到某数据时.可以在Redis缓存中为此数据保存一个空值.用于表示此数据为空.这样一来.之后对此数据的请求均会被Redis缓存拦截.从而阻断非法请求对数据库的骚扰.
如果黑客访问的不是一条非法数据.而是大量不同的非法数据.那么此方案会使得Redis缓存中存储大量无用的空数据.甚至会逐出较多的合法数据.大大降低了Redis缓存命中率.数据再次面临风险.可以使用布隆过滤器来解决缓存穿透问题.
布隆过滤器由一个固定长度为m的二进制向量和k个哈希函数组成.当某数据被加入布隆过滤器后.k个哈希函数为此数据计算出k个哈希值与m取模.并且在二进制向量对应的N个位置上设置值为1.如果想要查询某数据是否在布隆过滤器中.则可以通过相同的哈希计算后在二进制向量中查看这个k个位置值.
如果有任意一个位置值为0.则说明被查询的数据一定不存在.
如果所有的位置都为1.则说明被查询的数据可能存在.之所以说可能存在.是因为哈希函数免不了会有数据碰撞的可能性.在这种情况下会造成对数据的误判.不过可以通过调整m和k的值来降低误判率.
虽然布隆过滤器对于"数据存在"有一定的误判.但是对于"数据不存在"的判定是准确的.布隆过滤器很适合用来防止缓存穿透.将数据库中的全部数据加入布隆过滤器中.当用户请求访问某数据但是在Redis缓存找不到时.检查布隆过滤器中是否记录了此数据.如果布隆过滤器认为数据不存在.则用户请求不在访问数据库.如果布隆过滤器认为数据可能存在.则用户请求继续访问数据库.如果在数据库中找不到此数据,则在Redis缓存中设置空值.虽然布隆过滤器对"数据存在"有一定的误判.但是误判率较低.最后.在Redis缓存中设置的空值也很少.不会影响Redis缓存命中率.
缓存雪崩:
如果在同一时间Redis缓存中的数据大面积过期.则会导致请求全部涌向数据库.这种情况称为"缓存雪崩".缓存雪崩和缓存穿透的区别是.前者是很多缓存数据不存在造成的.后者是一条数据不存在导致的.
缓存雪崩一般有两种诱因.大量数据有相同的过期时间.或者Redis服务宕机.第一种诱因的解决方案比较简单.可以在为缓存设置过期时间时.让过期时间的值在预设的小范围内随机分布.避免大部分缓存数据有相同的过期时间.第二中诱因取决于Redis的可用性.选取高可用的Redis集群架构可以极大的降低Redis服务宕机的概率.
缓存更新:
1.先修改缓存.在更新数据库:
在更新某数据时.先把缓存数据修改为最新值.在更新数据库.在并发写请求的场景下.这种方案存在数据不一致的问题.假设此时对数据X=a有两个并发请求:请求A修改数据X=b.请求B修改数据为X=c.一种可能的执行序列如下.
1.请求A修改缓存.缓存数据被更新为b.
2.请求B修改缓存.缓存数据被更新为c.
3.请求B更新数据库.数据库中的数据被更新为c.
4.请求A更新数据库.数据库中的数据更新为b.
数据X在数据库中的最新值为c.而在缓存中的最新值为b.此时就会出现缓存与数据库的数据不一致的情况.此外.如果修改缓存后更新数据库失败.数据的此修改不应该生效.需要将缓存数据重置为原值.这就要求请求每次在修改缓存前都要先暂存缓存数据的原值.只要更新数据库失败.就将缓存数据重新修改回原值.这是一种典型的事务回滚场景.而Redis并发并不支持回滚.因此该方案不可取.
2.先更新数据库.在修改缓存:
与方案1类似.在并发写请求的场景下.此方案存在数据不一致的问题.假设此时对数据X=a有两个并发请求.请求A修改数据为X=b.请求B修改数据为X=c.一种可能的执行序列如下.
1.请求A更新数据库.数据库中的数据更新为b.
2.请求B更新数据库.数据库中的数据更新为c.
3.请求B修改缓存.缓存数据被更新为c.
4.请求A修改缓存.缓存数据被更新为b.
数据X在数据库中的最新值为c.而在缓存中的最新值为b.此时会出现缓存与数据库的数据不一致的情况.因此.也不建议采用这种方案.
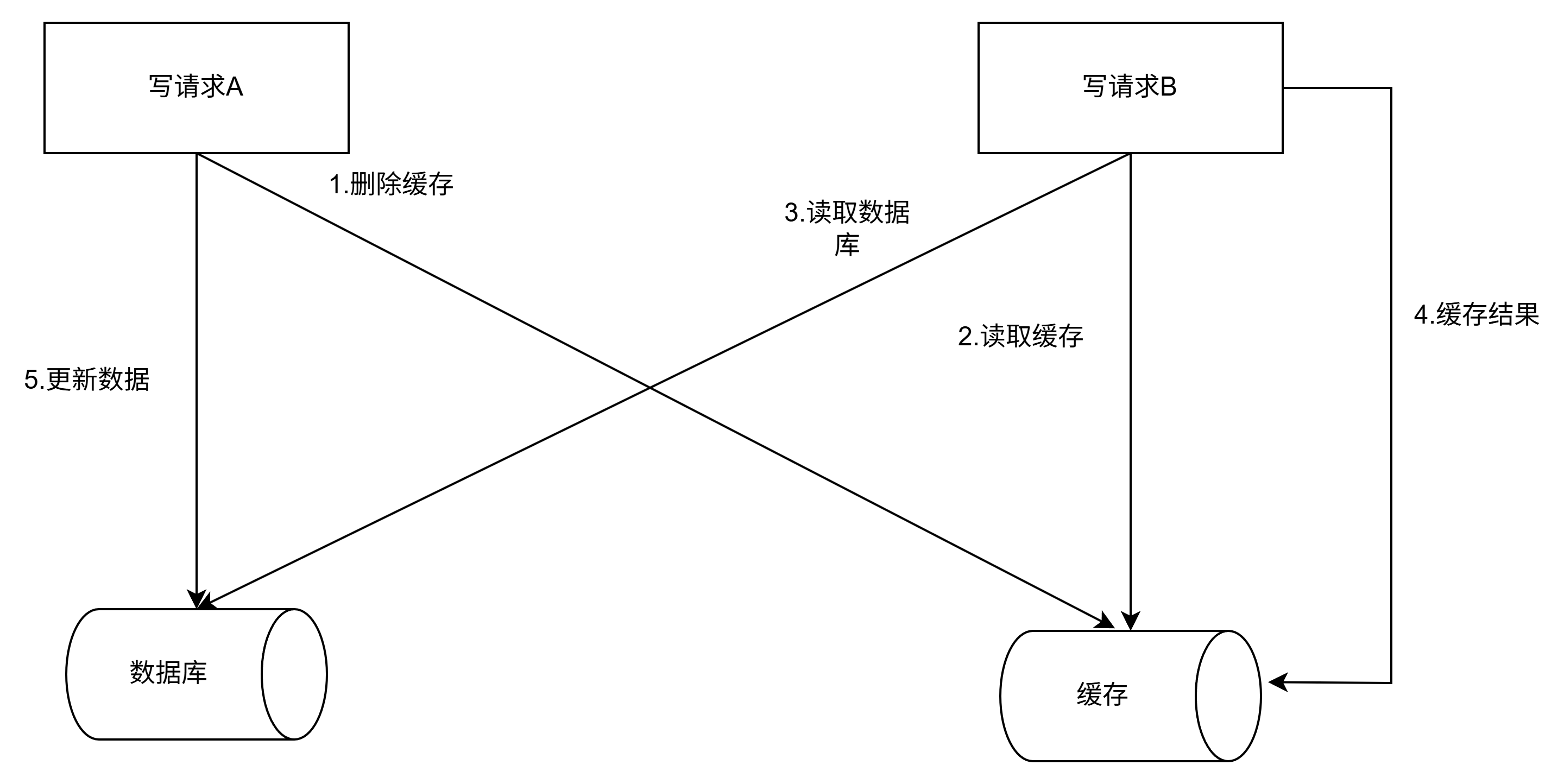
3.先删除缓存.在更新数据库:
此方案不在修改缓存.而是将缓存直接删除.在并发读写请求的场景下.此方案存在数据不一致的风险.假设此时对数据X=a有两个并发读写请求.请求A修改数据为X=b.请求B读取数据X.一种可能的执行序列如图.
1.请求A删除缓存.
2.请求B读取缓存.缓存未命中.
3.请求B进一步读取数据库.
4.请求B将读出的结果a保存到缓存中.
5.请求A更新数据库.数据库中的数据被更新为b.
数据X在数据中的最新值为b.而在缓存中的值为a.此时还是会出现缓存与数据库不一致的情况.
4.先更新数据库.再删除缓存:
在更新某数据时.先更新数据库.在更新数据成功后再将对应的缓存删除.此方案可以很好的解决上述三种方案在并发场景下数据不一致的问题.对于方案1和方案2中提到的并发写请求的场景.无论并发执行序列如何.最后一个操作一定是删除缓存.这就保证了接下来的读请求一定会从数据库中读取到最新值.而对于方案3中提到的并发读写请求场景.由于写操作在更新完数据库后删除缓存.所以无论并发执行序列如何.缓存的状态要嘛是被写请求删除.要嘛是读请求通过读数据库获取最新值.均可以保证缓存和数据库一致性.
如果更新数据库成功.删除缓存失败.最简单的方式是重试删除缓存.可以在请求删除缓存失败时.启动一个专门的线程负责不断的删除缓存.知道删除成功.
语雀地址https://www.yuque.com/itbosunmianyi/xg8vfe?
《Go.》 密码:xbkk 欢迎大家访问.提意见.