上季度团队在做一个大模型垂直领域的微调项目,目标是让模型能准确理解医疗领域的专业术语、诊断逻辑和文献表述。底层模型选好了,LoRA 配置也调通了,结果卡在基础的地方,这个也比较容易被低估的环节------数据。一开始我们信心满满,觉得自己整理了一批公开论文摘要就够了。真正跑起来才发现,医疗数据的复杂程度远超预期。
同一个症状在不同科室的描述方式基本不同,"胸痛"在心内科和呼吸科的语境差异很大,模型根本学不会这种细粒度的语义边界。我们自己手动标注了两周语料,质量参差不齐,有的样本前后标签自相矛盾------同一个术语在不同位置被标注成了不同的实体类别。模型一次微调跑完,测试集上的准确率反而比基座模型还低,说明数据噪声已经严重干扰了参数更新方向。那段时间整个团队也很沮丧,算力烧了不少,效果却在原地踏步。
从零散收集到直接用成品数据集
后来调研了一圈数据供给方案,发现 Dataify 那边有现成的行业专业数据集和文本类数据集,覆盖了包括医疗、法律、金融在内的多个垂直领域。
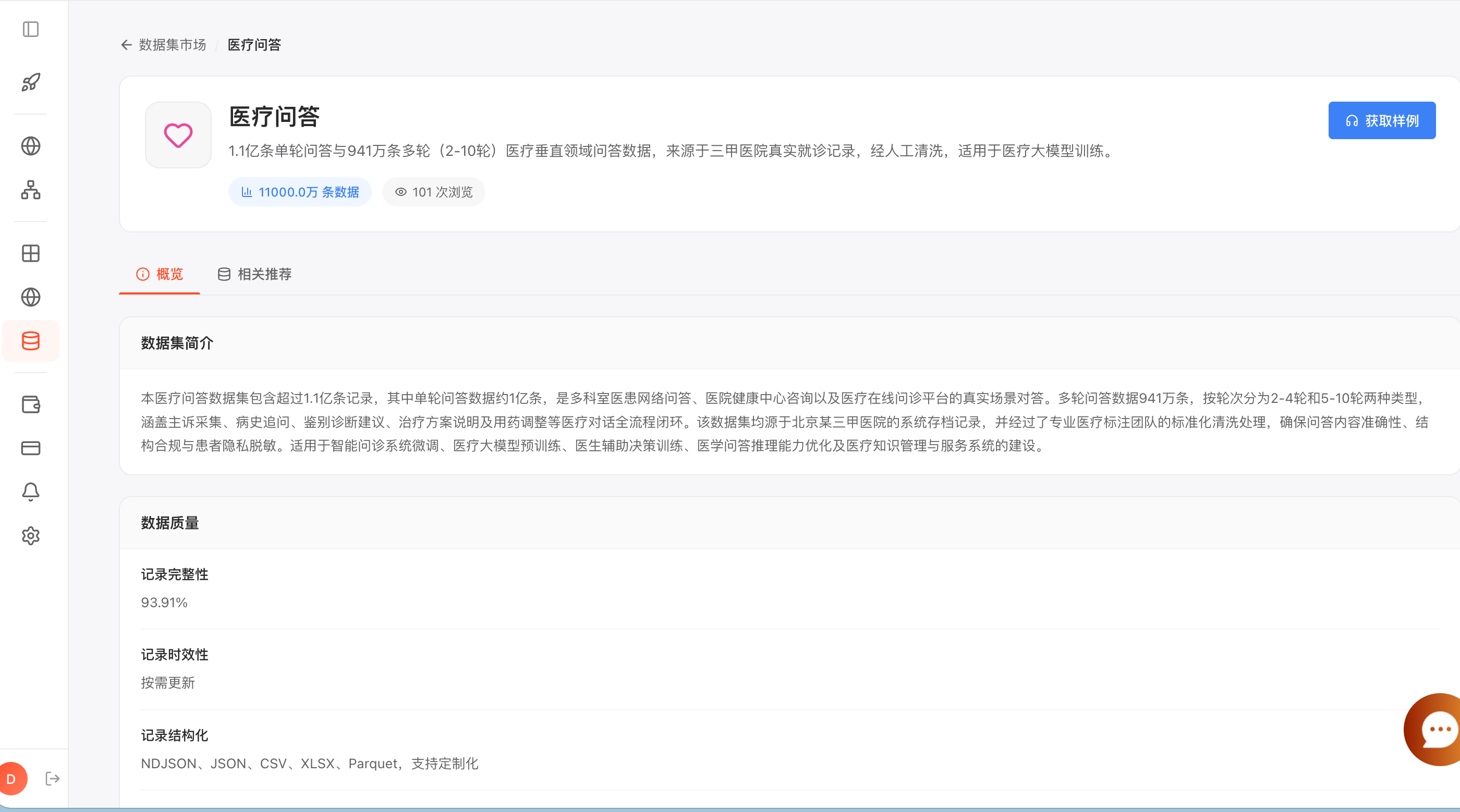
他们的数据集页面把各类数据按场景做了清晰分类------文本类、图像类、视频类和多模态,每个地方也标注了数据规模和适用方向。我们直接申请了医疗方向的 SFT 数据集样本,拿到数据后,我们感觉是字段结构真的干净:每条数据包含完整的用户问法和标准回答,标签体系统一,格式直接是 JSON Lines,读取和处理也非常方便。
plain
import json
# 加载 Dataify 提供的 SFT 数据集样本
with open("dataify_medical_sft_sample.json", "r", encoding="utf-8") as f:
samples = [json.loads(line) for line in f]
print(f"数据集总量: {len(samples)} 条")
# 查看科室分布
from collections import Counter
dept_counter = Counter(item["department"] for item in samples)
print("科室覆盖:", dict(dept_counter.most_common(10)))
# 随机查看一条样本
sample = samples[0]
print("\n=== 样本示例 ===")
print(f"科室: {sample['department']}")
print(f"指令: {sample['instruction']}")
print(f"回答长度: {len(sample['response'])} 字")
print(f"难度等级: {sample.get('difficulty', 'N/A')}")用这个方式做数据初始化,效率比我们自己标注高出太多了。而且数据集本身经过了多轮质量审核和一致性校验,不需要再花时间做清洗和格式转换。我们把 Dataify 数据和少量内部自有数据按 3:1 混合后重新训练,模型在医疗问答任务上的准确率直接提升了十几个百分点,BLEU 和 ROUGE 指标也有了明显改善。
不同类型数据集的应用场景
在这个过程中,我也比较完整地了解了 Dataify 的整体数据集体系。除了我们用的文本类 SFT 数据,他们还有五种主要类型。音视频数据集覆盖了多语种语音、视频字幕和画面描述,适合做语音识别或视频理解模型的训练数据。电子商务数据集包含商品标题、价格区间、评论内容和卖家信息,字段维度很丰富,可以用来训练推荐系统或价格预测模型。社交媒体数据集以平台公开内容为基础,包含帖子文本、互动数据和用户画像聚合信息,适合做舆情分析和用户意图识别。
行业专业数据集则针对法律、金融、教育等垂直领域做了专门优化。每种数据集的标注规范和字段结构很清楚写在产品页面上,选型的时候不需要来回沟通确认,这一点对于技术评估阶段来说省了很多时间。对于我们这种 AI 团队来说,数据准备阶段从原来预计的六周压缩到一周以内,意味着可以更早进入模型迭代的正循环,而不是反复在数据清洗里打转。