在某些复杂的实时数据处理场景中,必要时需要对事件流进行特定事件模式的检测,例如:在金融领域中的欺诈检测,需要在交易事件流中发现一系列异常交易行为;在物联网领域中需要在设备运行状态事件流中实时监测设备状态变化及设备之间协作。这些事件模式往往涉及多个事件之间的关系和顺序,这种多事件处理我们称作"复杂事件"处理,尽管可以利用Flink DataStream底层API进行这种复杂事件模式的检测,通常情况下,这会导致代码中涉及大量状态和定时器的定义,从而使代码复杂度急剧增加。
为了有效地应对这类复杂事件处理情况,Flink提供了CEP(Complex Event Processing)模块,即复杂事件处理模块。Flink CEP是一个构建在Flink之上的复杂事件处理库,它使用户能够高效且灵活地从无限的事件流中检测特定的事件模式,并对其进行相应的操作和处理。在本章中,我们将详细介绍Flink CEP的相关内容,以及它在处理复杂事件时的作用和优势。
CEP快速上手
在Apache Flink中,事件处理包括两种类型:简单事件和复杂事件。
简单事件是现实世界中的基本事件单位,具有明确的定义和单一性,可以通过简单的数据处理直接计算结果,无需考虑多个事件之间的关系。例如,交易金额、点击事件和传感器读数都是简单事件的例子。
复杂事件则涉及多个事件的组合,多个事件之间存在多种关系(时序关系、聚合关系、层次关系等),例如:在金融领域中检测欺诈交易行为时,需要考虑多笔交易之间的时序和金额关系。
Flink CEP 进行复杂事件处理时可以监测和分析事件流,在特定事件序列发生时触发操作。这些特定事件序列需要通过一定的规则进行模式匹配,在使用Flink CEP时,包含如下四个步骤:
-
创建事件流
-
定义模式匹配规则
-
模式匹配规则应用在事件流上进行检测
-
对匹配的复杂事件进行结果输出
使用Flink CEP进行复杂事件处理的代码形式如下:
#1.定义输入事件流
DataStream<Event> input = ...;
#2.定义模式匹配规则
Pattern<Event, ?> pattern = Pattern.<Event>begin("start")
.where(SimpleCondition.of(event -> event.getId() == 42))
.next("middle")
.subtype(SubEvent.class)
.where(SimpleCondition.of(subEvent -> subEvent.getVolume() >= 10.0))
.followedBy("end")
.where(SimpleCondition.of(event -> event.getName().equals("end")));
#3.模式匹配应用在事件流上检测
PatternStream<Event> patternStream = CEP.pattern(input, pattern);
#4.对匹配的复杂事件进行结果输出
DataStream<Alert> result = patternStream.process(
new PatternProcessFunction<Event, Alert>() {
@Override
public void processMatch(Map<String, List<Event>> pattern,
Context ctx,Collector<Alert> out) throws Exception {
out.collect(createAlertFrom(pattern));
}
});为了后续方便理解Flink CEP中的一些概念以及Flink CEP匹配复杂事件流使用特点,下面通过一个案例进行Flink CEP使用演示。在该案例中读取Socket中基站日志数据,当同一基站有连续3次通话失败情况就发出告警信息。
在代码中使用Flink CEP前需要在项目中导入对应的依赖,Java和Scala导入依赖不同,如下:
#Java项目中导入CEP依赖
<!--Flink CEP 所需依赖包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep</artifactId>
<version>${flink.version}</version>
</dependency>
#Scala项目中导入CEP依赖
<!--Flink CEP 所需依赖包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>编写代码如下:
- Java代码
//准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.定义事件流
SingleOutputStreamOperator<StationLog> ds = env.socketTextStream("node5", 9999)
.map(new MapFunction<String, StationLog>() {
@Override
public StationLog map(String value) throws Exception {
String[] arr = value.split(",");
return new StationLog(arr[0], arr[1], arr[2], arr[3], Long.valueOf(arr[4]), Long.valueOf(arr[5]));
}
});
//设置watermark并设置自动推进watermark
SingleOutputStreamOperator<StationLog> dsWithWatermark = ds.assignTimestampsAndWatermarks(
WatermarkStrategy.<StationLog>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<StationLog>() {
@Override
public long extractTimestamp(StationLog element, long recordTimestamp) {
return element.callTime;
}
}).withIdleness(Duration.ofSeconds(5))
);
KeyedStream<StationLog, String> keyedStream = dsWithWatermark.keyBy(new KeySelector<StationLog, String>() {
@Override
public String getKey(StationLog value) throws Exception {
return value.sid;
}
});
//2.定义模式匹配规则。 Pattern<T,F> : T:模式匹配中的事件类型,F:当前模式约束到的T的子类型
Pattern<StationLog, StationLog> pattern = Pattern.<StationLog>begin("first")
.where(new SimpleCondition<StationLog>() {
@Override
public boolean filter(StationLog value) throws Exception {
return value.callType.equals("fail");
}
})
.next("second")
.where(new SimpleCondition<StationLog>() {
@Override
public boolean filter(StationLog value) throws Exception {
return value.callType.equals("fail");
}
})
.next("third")
.where(new SimpleCondition<StationLog>() {
@Override
public boolean filter(StationLog value) throws Exception {
return value.callType.equals("fail");
}
});
//3.将模式匹配规则应用到数据流上
PatternStream<StationLog> patternStream = CEP.pattern(keyedStream, pattern);
//4.获取符合规则的数据
SingleOutputStreamOperator<String> result = patternStream.process(new PatternProcessFunction<StationLog, String>() {
/**
* Map<模式名称,当前模式下匹配的事件>:各个模式下匹配到的事件
* Context:上下文对象,可以获取时间相关的信息或者将数据输出到侧输出流
* Collector:用于输出结果
*/
@Override
public void processMatch(Map<String, List<StationLog>> match, Context ctx, Collector<String> out) throws Exception {
StationLog start = match.get("first").iterator().next();
StationLog second = match.get("second").iterator().next();
StationLog third = match.get("third").iterator().next();
out.collect("预警信息:\n" + start + "\n" + second + "\n" + third);
}
});
result.print();
env.execute();- Scala代码
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//1.定义事件流
val ds: DataStream[StationLog] = env.socketTextStream("node5", 9999)
.map(line => {
val arr: Array[String] = line.split(",")
StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
}).assignTimestampsAndWatermarks(
WatermarkStrategy.forBoundedOutOfOrderness[StationLog](Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner[StationLog] {
override def extractTimestamp(element: StationLog, recordTimestamp: Long): Long = element.callTime
})
.withIdleness(Duration.ofSeconds(5))
)
val keyedStream: KeyedStream[StationLog, String] = ds.keyBy(_.sid)
//2.定义模式匹配
val pattern: Pattern[StationLog, StationLog] = Pattern.begin[StationLog]("first")
.where(_.callType.equals("fail"))
.next("second")
.where(_.callType.equals("fail"))
.next("third")
.where(_.callType.equals("fail"))
//3.模式匹配
val patternStream: PatternStream[StationLog] = CEP.pattern[StationLog](keyedStream, pattern)
//4.获取符合规则的数据
val result: DataStream[String] = patternStream.process(new PatternProcessFunction[StationLog, String] {
override def processMatch(`match`: util.Map[String, util.List[StationLog]],
ctx: PatternProcessFunction.Context,
out: Collector[String]): Unit = {
val first: StationLog = `match`.get("first").iterator().next()
val second: StationLog = `match`.get("second").iterator().next()
val third: StationLog = `match`.get("third").iterator().next()
out.collect(s"预警信息:\n$first\n$second\n$third")
}
})
result.print()
env.execute()在以上代码中首先针对Socket读取的数据流进行了转换并设置了Watermark,然后通过Flink Pattern API设置了匹配规则,"Pattern.begin("first").where(...)"中"Pattern.begin"表示开始一个模式规则匹配,并指定一个简单事件名称为first,where指定了匹配该简单事件的约束条件;又通过"next(...)"连接了其他简单事件并通过"where(...)"指定了简单事件的约束条件,最终将名称为"first"、"second"、"third"的简单事件组合成了一个复杂事件,返回的Pattern对象就是复杂事件的模式匹配规则,即:当同一个基站连续有三次通话状态为"fail"时就会匹配上该规则。然后又通过"CEP.pattern(DataStream,Pattern)"方法将复杂事件的匹配规则应用到事件流上,针对返回的PatternStream调用process方法获取到匹配的事件并发出告警信息。
在编写Flink CEP代码时需要注意如下几点:
-
使用Flink CEP时,处理数据时的时间语义默认为事件时间,一个事件到来后先被放到一个缓冲区,在缓冲区里事件都是按照时间戳从小到大排序,当watermark到达某个时刻后,该时刻前的事件如果有匹配上规则的事件才会输出。
-
使用Flink CEP也可以基于处理时间不必指定watermark,但需要在将匹配规则应用到数据流上时调用"inProcessTime"方法(CEP.pattern(...).inProcessTime()),否则匹配规则的事件不会被输出。
-
基于事件时间处理数据流时,需要设置watermark自动推进机制。
以上代码启动后,向socket中输入如下数据:
#socket-9999 中输入数据
001,181,182,busy,1000,10
001,183,184,fail,2000,30
002,182,183,fail,3000,20
001,184,185,fail,6000,40
001,181,183,fail,5000,50
#001基站输出匹配事件
003,182,183,success,8001,20当"003,182,183,success,8001,20"数据输入后,此刻watermark为6000,基站"001"连续三条数据通话状态为"fail"状态,会匹配上复杂事件规则触发告警输出,最终输出结果如下:
预警信息:
StationLog{sid='001', callOut='183', callIn='184', callType='fail', callTime=2000, duration=30}
StationLog{sid='001', callOut='181', callIn='183', callType='fail', callTime=5000, duration=50}
StationLog{sid='001', callOut='184', callIn='185', callType='fail', callTime=6000, duration=40}Pattern API
Flink CEP复杂事件处理中最终要的就是匹配复杂事件的模式,通过上一小节案例的学习我们了解到可以通过Pattern API 来设置匹配复杂事件的模式,这一小节我们将对Pattern API使用进行详细介绍。
Pattern API使用形式
通过Pattern API 我们可以定义从输入流中抽取复杂事件的模式,每个复杂事件的模式一般都是由多个简单事件模式组合而成,这些简单的事件模式匹配我们叫做"单独模式(Individual Patterns)",多个"单独模式"组合成的复杂事件的匹配我们叫做"组合模式(Combining Patterns)",无论是"单独模式"还是"组合模式"都是通过Pattern API来定义的,每个Pattern都是以begin方法开始定义,下面是"单独模式"和"组合模式"使用的一般形式:
#定义简单事件的匹配模式,简单事件模式匹配名称为start
Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(...)
#定义多个简单事件匹配组成的复杂事件匹配模式,多个简单事件匹配名称为 first 、second、third
Pattern<Event, ?> pattern = Pattern.<Event>begin("first").where(...)
.next("second").where(...)
.followedBy("third").where(...)以上每个简单事件匹配规则定义都对应一个名字,定义模式名称时不能包含字符":",后续可以使用该名字表示匹配的简单事件,同时每个简单事件一般通过where方法来指定匹配该事件的条件;定义的复杂事件匹配规则是将多个简单事件的匹配规则通过next/followedBy方法进行连接,这些方法表示不同的事件的连续策略,关于连续策略后续小节会进行介绍。
单独模式
单独模式(Individual Patterns)是简单事件的匹配模式,单独模式又分为单例(singleton)模式和循环(looping)模式。例如针对基站日志通话数据流匹配通话时长大于10s的事件就是单例模式,单例模式表示的就是一个事件匹配,我们可以在单例模式后设置量词来指定匹配的循环次数,这就形成了循环模式,例如:
#匹配通话时长大于10的单例模式
Pattern<StationLog, StationLog> pattern =
Pattern.<StationLog>begin("start")
.where(SimpleCondition.of(value -> value.druation()>10))
#匹配通话时长大于10的循环模式
Pattern<StationLog, StationLog> pattern =
Pattern.<StationLog>begin("start")
.where(SimpleCondition.of(value -> value.druation()>10))
.times(4);//期望出现4次以上"where..."指定的是条件,"times"就是量词,下面分别对量词和条件进行介绍。
1. 量词(Quantifiers)
在Flink CEP中可以对定义好的一个pattern调用如下量词形成循环模式,可以匹配接收多个事件。
- oneOrMore()
指定模式期望匹配到的事件至少出现一次。假设pattern表示匹配a事件,pattern.oneOrMore()表示匹配a事件一次到多次。
- times(#ofTimes)
指定模式期望匹配到的事件正好出现的次数。假设pattern表示匹配a事件,pattern.times(2)表示匹配a事件2次。
- times(#fromTimes,$toTimes)
指定模式期望匹配到的事件出现次数在#fromTimes和#toTimes之间。假设pattern表示匹配a事件,pattern.times(2,4)表示匹配a事件2、3、4次。
- timesOrMore(#times)
指定模式期望匹配到的事件至少出现times次。假设pattern表示匹配a事件,pattern.timesOrMore(2)表示匹配a事件2次到多次。
- optional()
指定该模式是可选的,表示该模式可以出现也可以不出现,对前面这些量词都适用,在多个单独模式组合成组合模式中使用才有意义。假设pattern表示匹配a事件,pattern.times(2,4).optional()表示匹配a事件0、2、3、4次。
- greedy()
指定该模式是贪心的,会重复尽可能多的次数,只对量词适用,不支持模式组 ,在多个单独模式组合成组合模式中使用才有意义。假设pattern表示匹配a事件,pattern.times(2,4).greedy()表示尽可能多的匹配a事件,如果输入4次a,那么2次a和3次a事件都不算匹配事件。
假设现在已有定义好名称为"start"的pattern对象,以上量词使用方式如下:
// 期望出现4次
start.times(4);
// 期望出现0或者4次
start.times(4).optional();
// 期望出现2、3或者4次
start.times(2, 4);
// 期望出现2、3或者4次,并且尽可能的重复次数多
start.times(2, 4).greedy();
// 期望出现0、2、3或者4次
start.times(2, 4).optional();
// 期望出现0、2、3或者4次,并且尽可能的重复次数多
start.times(2, 4).optional().greedy();
// 期望出现1到多次
start.oneOrMore();
// 期望出现1到多次,并且尽可能的重复次数多
start.oneOrMore().greedy();
// 期望出现0到多次
start.oneOrMore().optional();
// 期望出现0到多次,并且尽可能的重复次数多
start.oneOrMore().optional().greedy();
// 期望出现2到多次
start.timesOrMore(2);
// 期望出现2到多次,并且尽可能的重复次数多
start.timesOrMore(2).greedy();
// 期望出现0、2或多次
start.timesOrMore(2).optional();
// 期望出现0、2或多次,并且尽可能的重复次数多
start.timesOrMore(2).optional().greedy();注意:循环模式中就是对单个事件进行匹配多次,假设pattern表示匹配a事件,pattern.times(2)表示匹配a事件2次,不必连续出现两次a事件,两次a事件之间可以有其他事件,只要有2个a事件出现后,就会匹配到该模式,多个a事件是"宽松近邻"关系,关于事件时间的关系后续还会介绍。
2. 条件
每个模式都需要指定触发条件,作为事件进入到该模式是否接受的判断依据,当事件满足条件时,便进行下一步操作。在Flink CEP中通过pattern.where()、pattern.or()及pattern.until()方法来为Pattern指定条件,条件又分为迭代条件、简单条件、组合条件和停止条件四种。
- 迭代条件
迭代条件需要在当前事件处理中获取到该模式先前匹配的事件进行对比或处理才能决定当前事件是否被匹配,这种需要对该模式先前匹配事件进行处理作为判断当前事件是否匹配模式的条件叫做迭代条件。如下所示:
middle.oneOrMore()
.subtype(SubEvent.class)
.where(new IterativeCondition<SubEvent>() {
@Override
public boolean filter(SubEvent value, Context<SubEvent> ctx) throws Exception {
//判断当前事件是否以foo开头
if (!value.getName().startsWith("foo")) {
return false;
}
double sum = value.getPrice();
//获取当前模式先前已经匹配的事件,计算sum总和
for (Event event : ctx.getEventsForPattern("middle")) {
sum += event.getPrice();
}
return Double.compare(sum, 5.0) < 0;
}
});以上代码中,当前模式名称为middle,每有一个事件进入后都会与该模式先前匹配的事件进行price价格累加和计算,如果总和小于5.0,该事件就会被匹配否则不能匹配该事件。迭代条件经常与循环模式结合使用,用于复杂需求数据匹配情况,例如:股票交易场景中,当某个客户最近4次交易的金额超过某个阈值时就认为该用户存在异常交易。
以上"subtype(SubEvent.class)"是限制接受的事件类型。
- 简单条件
简单条件非常简单,从事件本身中获取信息来进行判断,只需要考虑当前事件本身即可。
start.where(SimpleCondition.of(value -> value.getName().startsWith("foo")));- 组合条件
组合条件是将简单条件进行合并,通常情况下也可以使用where方法进行条件的组合,默认每个条件通过AND逻辑相连。如果需要使用OR逻辑,直接使用or方法连接条件即可。
pattern
.where(SimpleCondition.of(value -> ... /*一些判断条件*/))
.or(SimpleCondition.of(value -> ... /*一些判断条件*/));- 停止条件
如果定义模式时使用了oneOrMore或者oneOrMore().optional()方法,则必须指定停止条件,否则模式中的规则会一直循环下去。可以通过until()方法指定停止条件。
pattern.oneOrMore().until(new IterativeCondition<Event>() {
@Override
public boolean filter(Event value, Context ctx) throws Exception {
return ...; // 替代条件
}
});假设pattern表示匹配a事件,pattern.oneOrMore(1).until(b)表示匹配a事件1次到多次直到匹配到b事件,那么当数据流为"a1 c a2 b a3"时,该模式匹配到的结果如下:{a1、a1,a2、a2、a3}。
下面我们通过一个案例在单独模式中综合使用量词和条件来加深模式匹配中量词和条件的理解。该案例中读取socket中数据进行符合条件事件的匹配,设置的模式匹配为:只要输入的数据是以a开头的数据就会进行匹配并输出结果,直到end字符串输入后不再输出匹配结果。
- Java代码
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.定义事件流
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//2.定义匹配规则
Pattern<String, String> pattern = Pattern.<String>begin("first")
.where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("a");
}
}))
.oneOrMore()
.until(new IterativeCondition<String>() {
@Override
public boolean filter(String value, Context<String> ctx) throws Exception {
return value.equals("end");
}
});
//3.应用规则
PatternStream<String> patternStream = CEP.pattern(ds, pattern).inProcessingTime();
//4.获取匹配到的数据
patternStream.select(new PatternSelectFunction<String, String>() {
@Override
public String select(Map<String, List<String>> pattern) throws Exception {
List<String> first = pattern.get("first");
StringBuilder sb = new StringBuilder();
for (String s : first) {
sb.append(s+"-");
}
return sb.substring(0,sb.length()-1);
}
}).print();
env.execute();- Scala代码
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//导入隐式转换
import org.apache.flink.streaming.api.scala._
//1.定义事件流
val ds: DataStream[String] = env.socketTextStream("node5", 9999)
//2.定义匹配规则
val pattern: Pattern[String, String] = Pattern.begin[String]("first").where(_.startsWith("a"))
.oneOrMore
.until(_.equals("end"))
//3.将规则应用到事件流上
val patternStream: PatternStream[String] = CEP.pattern(ds, pattern).inProcessingTime()
//4.获取匹配到的数据
patternStream.select(new PatternSelectFunction[String,String] {
override def select(pattern: util.Map[String, util.List[String]]): String = {
val list: util.List[String] = pattern.get("first")
import scala.collection.JavaConverters._
list.asScala.mkString("-")
}
}).print()
env.execute()以上代码中没有设置事件时间及watermark,所以在使用CEP.pattern时需要调用inProcessingTime()方法,代码执行后向socket-9999中输入如下数据:
#向socket-9999中输入如下数据
a1
b1
a2
b2
a3
#此条数据输入后,不再匹配前面a开头的数据
end
a4可以看到最终结果输出如下:
6> a1
8> a2
7> a1-a2
2> a2-a3
1> a1-a2-a3
3> a3
4> a4组合模式
将定义的多个单独模式组合在一起就形成了模式序列,即:组合模式。组合模式也叫模式序列。可以对单独模式通过调用next、followedBy、followedByAny方法进行连接,不同方法表示了事件之间不同的连续策略,分别对应严格邻近(Strict Contiguity)、宽松邻近(Relaxed Contiguity)、非确定宽松邻近(Non-Deterministic Relaxed Contiguity)三种事件连续策略。
- 严格邻近
严格邻近中期望所有匹配的事件严格一个接一个出现,中间没有任何不匹配的事件。事件之间严格邻近策略示意图如下:
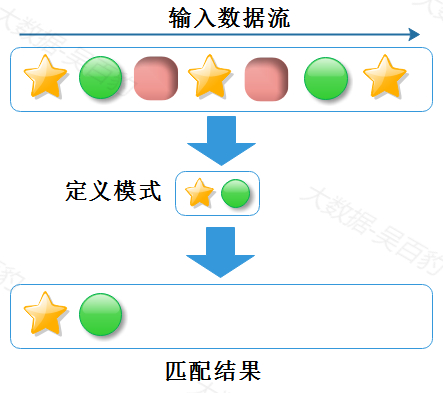
代码中严格邻近对应next方法,使用形式如下:
// 严格邻近
Pattern<Event, ?> strict = start.next("middle").where(...);- 宽松邻近
宽松邻近并不会像严格邻近这么严格,两个匹配的事件之间可以有其他不匹配的事件出现,也就是说宽松邻近会忽略没有成功匹配的事件直到下一个匹配事件出现为止。事件之间宽松邻近策略示意图如下:
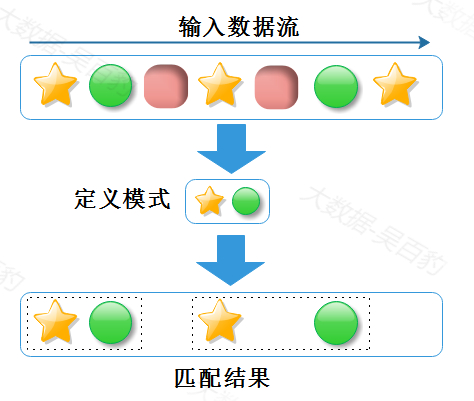
代码中严格邻近对应followedBy方法,使用形式如下:
//宽松邻近
Pattern<Event, ?> relaxed = start.followedBy("middle").where(...);- 非确定宽松邻近
非确定宽松邻近策略相比于宽松邻近策略更加宽松,可以忽略已经匹配的事件,也就是说可以重复使用匹配过的事件,非确定宽松邻近比宽松邻近匹配的结果往往更多。事件之间非确定宽松邻近策略示意图如下:
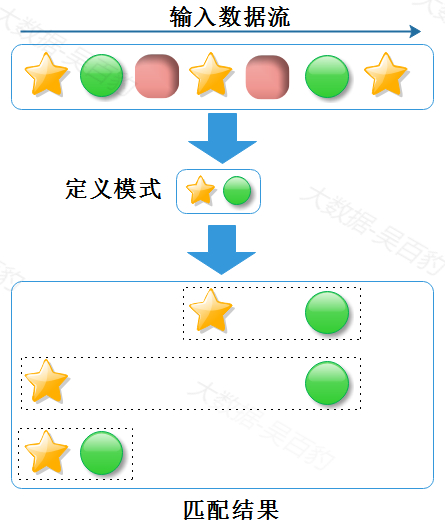
代码中非确定宽松邻近对应followedByAny方法,使用形式如下:
//非确定宽松邻近
Pattern<Event, ?> nonDetermin = start.followedByAny("middle").where(...);除了以上三种事件连续策略之外,还可以调用notNext()、notFollowedBy()方法来定义"不希望出现某种邻近连续"。
- notNext()
notNext()方法就是next方法的Not模式,即:notNext()就是严格邻近策略的Not模式,表示不想让某个事件后面直接连接某个特定事件。使用形式如下:
// 严格邻近的NOT模式
Pattern<Event, ?> strictNot = start.notNext("not").where(...);- notFollowedBy()
notFollowedBy()方法就是followedBy()方法的Not模式,即:notFollowedBy()就是宽松邻近策略的Not模式,表示不想一个特定的事件发生在两个事件之间的任何地方。使用形式如下:
// 宽松邻近NOT模式
Pattern<Event, ?> relaxedNot = start.notFollowedBy("not").where(...);此外,FlinkCEP中我们还可以对模式指定一个有效时间约束,例如,可以通过pattern.within()方法指定一个模式应该在10秒内发生,表示只有在这期间内匹配的复杂事件才有效,within指定的时间支持ProcessTime和EventTime。within()使用形式如下:
next.within(Time.seconds(10));使用Not策略及with时需要注意以下几点:
-
使用notNext()/notFollowedBy()时,肯定会有前面的事件匹配模式,所以Not策略前面不能是可选的模式。
-
notFollowedBy()表示的是不希望特定事件在两个事件之间出现,也就是说notFollowedBy()后会有某个事件,如果没有指定后面的事件也可以在notFollowedBy()后跟上within指定一个时间,那么该模式序列表示一定时间内某事件后没有出现特定事件。
-
如果模式序列(组合模式)没有定义时间约束,不能以notFollowedBy()结尾。
-
一个模式序列中只能有一个时间限制,如果在多个单独模式中限制了时间,会使用最小的时间限制。
下面通过案例演示以上组合模式中的事件连续策略。案例通过读取Socket基站日志数据,基于ProcessTime进行事件处理并设置匹配模式进行符合条件事件的输出。由于Java代码和Scala代码非常类似,这里只给出Java代码实现。
1. 严格邻近(next)案例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.定义事件流
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//2.定义匹配规则
Pattern<String, String> pattern = Pattern.<String>begin("start")
.where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("a");
}
}))
.next("middle").where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("c");
}
}));
//3.应用规则
PatternStream<String> patternStream = CEP.pattern(ds, pattern).inProcessingTime();
//4.获取匹配到的数据
patternStream.select(new PatternSelectFunction<String, String>() {
@Override
public String select(Map<String, List<String>> pattern) throws Exception {
String start = pattern.get("start").get(0);
String middle = pattern.get("middle").get(0);
return start+"-"+middle;
}
}).print();
env.execute();以上代码设置了名称为start和middle的严格邻近组合模式,匹配数据流中a事件后紧跟c事件的事件序列。代码执行后向socket中输入如下数据:
#socket-9999中输入事件流
a1
b1
a2
b2
c1
a3
c2输出结果中只有a事件后紧跟c事件的事件组才会被匹配,输出结果如下:
3> a3-c22. 宽松邻近(followedBy)案例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.定义事件流
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//2.定义匹配规则
Pattern<String, String> pattern = Pattern.<String>begin("start")
.where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("a");
}
}))
.followedBy("middle").where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("c");
}
}));
//3.应用规则
PatternStream<String> patternStream = CEP.pattern(ds, pattern).inProcessingTime();
//4.获取匹配到的数据
patternStream.select(new PatternSelectFunction<String, String>() {
@Override
public String select(Map<String, List<String>> pattern) throws Exception {
String start = pattern.get("start").get(0);
String middle = pattern.get("middle").get(0);
return start+"-"+middle;
}
}).print();
env.execute();以上代码设置了名称为start和middle的宽松邻近组合模式,匹配数据流中a事件与c事件符合宽松邻近关系的事件序列。代码执行后向socket中输入如下数据:
#socket-9999中输入事件流
a1
b1
a2
b2
c1
a3
c2由于a事件和c事件之间是宽松邻近关系,所以a事件和c事件之间可以存在其他事件,最终输出结果如下:
4> a2-c1
3> a1-c1
5> a3-c23. 非确定宽松邻近(followedByAny)案例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.定义事件流
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//2.定义匹配规则
Pattern<String, String> pattern = Pattern.<String>begin("start")
.where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("a");
}
}))
.followedByAny("middle").where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("c");
}
}));
//3.应用规则
PatternStream<String> patternStream = CEP.pattern(ds, pattern).inProcessingTime();
//4.获取匹配到的数据
patternStream.select(new PatternSelectFunction<String, String>() {
@Override
public String select(Map<String, List<String>> pattern) throws Exception {
String start = pattern.get("start").get(0);
String middle = pattern.get("middle").get(0);
return start+"-"+middle;
}
}).print();
env.execute();以上代码设置了名称为start和middle的非确定宽松邻近组合模式,匹配数据流中a事件与c事件符合非确定宽松邻近关系的事件序列。代码执行后向socket中输入如下数据:
#socket-9999中输入事件流
a1
b1
a2
b2
c1
a3
c2由于a事件和c事件之间是非确定宽松邻近关系,所以a事件和c事件之间可以存在其他事件并且会忽略匹配过的事件,最终输出结果如下:
8> a2-c1
7> a1-c1
2> a2-c2
3> a3-c2
1> a1-c24. notNext案例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.定义事件流
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//2.定义匹配规则
Pattern<String, String> pattern = Pattern.<String>begin("start")
.where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("a");
}
}))
.notNext("middle").where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("c");
}
}));
//3.应用规则
PatternStream<String> patternStream = CEP.pattern(ds, pattern).inProcessingTime();
//4.获取匹配到的数据
patternStream.select(new PatternSelectFunction<String, String>() {
@Override
public String select(Map<String, List<String>> pattern) throws Exception {
String start = pattern.get("start").get(0);
return start;
}
}).print();
env.execute();以上代码设置了名称为start和middle的事件组合模式,该组合模式会匹配数据流中a事件后没有紧跟c事件的a事件,特别值得注意的是middle事件模式不能单独在select中获取,否则会得到空指针错误。代码执行后向socket中输入如下数据:
#socket-9999中输入事件流
a1
b1
c1
a2
c2由于a事件后没有c事件的a事件才会被输出,最终输出结果如下:
2> a15. notfollowedBy+within 案例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.定义事件流
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//2.定义匹配规则
Pattern<String, String> pattern = Pattern.<String>begin("start")
.where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("a");
}
}))
.notFollowedBy("middle").where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("c");
}
}))
.within(Time.seconds(10));
//3.应用规则
PatternStream<String> patternStream = CEP.pattern(ds, pattern).inProcessingTime();
//4.获取匹配到的数据
patternStream.select(new PatternSelectFunction<String, String>() {
@Override
public String select(Map<String, List<String>> pattern) throws Exception {
String start = pattern.get("start").get(0);
return start;
}
}).print();
env.execute();以上代码设置了名称为start和middle的事件组合模式,该组合模式会匹配数据流中a事件后10s内没有出现c事件的a事件,只要在10s内a事件后出现了c时间,那么该a事件就不会匹配,在该段时间内c事件不必紧跟在a事件后。代码执行后向socket中输入如下数据:
#socket-9999中输入事件流
a1
b1
#在a1输入后的10内输入c1,则a1不会匹配,否则匹配
c1
a2
#在a1输入后的10内输入c1,则a1不会匹配,否则匹配
c2由于a事件后没有c事件的a事件才会被输出,最终输出结果如下:
2> a1循环模式中的连续性
在Flink CEP模式匹配中,某个单独模式使用了oneOrMore()/times这些量词形成循环模式,默认循环中匹配各个事件之间连续策略为宽松邻近策略,即循环匹配多个事件时,这些事件之间可以有其他不匹配的事件,这种情况下循环模式等价于定义一个单独模式后再通过followedBy连接另外相同一个单独模式。举例如下:
#定义简单事件的匹配模式
Pattern<Event, ?> pattern =
Pattern.<Event>begin("start").where(“匹配a事件”).times(2)
#以上单独模式等价于如下组合模式
Pattern<Event, ?> pattern =
Pattern.<Event>begin("first").where(“匹配a事件”)
.followedBy("second").where(“匹配a事件”)这种循环事件中,事件连续策略也可不使用默认的宽松邻近策略,可以通过设置使用严格邻近策略或者非确定宽松邻近策略,如果想要使用严格邻近策略,可以通过调用consecutive()方法明确指定;如果想要使用非确定宽松邻近策略,可以通过调用allowCombinations()方法明确指定。
下面通过案例来演示consecutive()方法和allowCombinations()方法的使用。案例还是通过读取Socket基站日志数据,基于ProcessTime进行事件处理并设置匹配模式进行符合条件事件的输出。由于Java代码和Scala代码非常类似,这里只给出Java代码实现。
- 通过调用consecutive()方法使用严格邻近策略
对某个单独模式调用consecutive()方法时,需要设置times()/oneOrMore()量词形成循环模式,并且当前循环模式中所有事件都是严格连续的,当有不匹配的事件出现时,当前循环检测就会终止。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.定义事件流
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//2.定义匹配规则
Pattern<String, String> pattern = Pattern.<String>begin("start")
.where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("a");
}
})).followedBy("middle").where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("c");
}
})).oneOrMore().consecutive();
//3.应用规则
PatternStream<String> patternStream = CEP.pattern(ds, pattern).inProcessingTime();
//4.获取匹配到的数据
patternStream.select(new PatternSelectFunction<String, String>() {
@Override
public String select(Map<String, List<String>> pattern) throws Exception {
String start = pattern.get("start").toString();
String middle = pattern.get("middle").toString();
return start+"-"+middle;
}
}).print();
env.execute();以上代码设置了名称为start和middle的宽松邻近组合模式,匹配数据流中a事件与c事件符合宽松邻近关系的事件序列,c事件可以出现一到多次,默认多个c事件之间为宽松邻近策略,由于代码中调用了consecutive()方法,所以多个c事件之间为严格邻近策略。代码执行后向socket中输入如下数据:
#socket-9999中输入事件流
a1
b1
c1
b2
#c2没有紧跟c1,所有不会输出匹配结果
c2
a2
c3
#c4紧跟c3,所有会输出匹配结果
c4最终输出结果如下:
2> [a1]-[c1]
3> [a2]-[c3]
4> [a2]-[c3, c4]如果不调用consecutive()方法,多个c事件之间为宽松邻近策略,输出结果如下:
4> [a1]-[c1]
5> [a1]-[c1, c2]
7> [a2]-[c3]
6> [a1]-[c1, c2, c3]
1> [a2]-[c3, c4]
8> [a1]-[c1, c2, c3, c4]- 通过调用allowCombinations()方法使用非确定宽松邻近策略
对某个单独模式调用allowCombinations()方法时,需要设置times()/oneOrMore()量词形成循环模式,当前循环模式中所有事件顺序是非确定宽松邻近策略,可以忽略已经匹配的事件。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.定义事件流
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//2.定义匹配规则
Pattern<String, String> pattern = Pattern.<String>begin("start")
.where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("a");
}
})).followedBy("middle").where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("c");
}
})).times(2).allowCombinations();
//3.应用规则
PatternStream<String> patternStream = CEP.pattern(ds, pattern).inProcessingTime();
//4.获取匹配到的数据
patternStream.select(new PatternSelectFunction<String, String>() {
@Override
public String select(Map<String, List<String>> pattern) throws Exception {
String start = pattern.get("start").toString();
String middle = pattern.get("middle").toString();
return start+"-"+middle;
}
}).print();
env.execute();以上代码设置了名称为start和middle的宽松邻近组合模式,匹配数据流中a事件与c事件符合宽松邻近关系的事件序列,c事件出现2次就会匹配,默认2个c事件之间为宽松邻近策略,由于代码中调用了allowCombinations()方法,所以2个c事件之间为非确定宽松邻近策略,会忽略匹配过的事件。代码执行后向socket中输入如下数据:
#socket-9999中输入事件流
a1
b1
c1
b2
#输出[a1]-[c1,c2]匹配结果
c2
a2
#会忽略匹配的c2,继续输出[a1]-[c1,c3]匹配结果
c3
#会忽略匹配的c2,c3,输出[a1]-[c1,c4],[a2]-[c3,c4]匹配结果
c4最终输出结果如下:
8> [a1]-[c1, c2]
1> [a1]-[c1, c3]
3> [a2]-[c3, c4]
2> [a1]-[c1, c4]如果不调用allowCombinations()方法,2个c事件之间为宽松邻近策略,输出结果如下:
2> [a1]-[c1, c2]
3> [a2]-[c3, c4]模式组
在Flink CEP中对于一些事件匹配非常复杂的业务,我们还可以定义模式组(Gruops of Patterns)。在模式组中,我们可以将多个模式序列以一种嵌套的方式连接起来,通过一系列的连接词,如begin()、next()、followedBy()、followedByAny()等,将这些模式序列组合成一个有机的整体。在模式组中也可以使用量词(如:times()、oneOrMore()、optional())指定某个模式组不出现或出现一次到多次。
以下给出模式组的使用示例,这里不再进行案例演示。
Pattern<Event, ?> start = Pattern.begin(
Pattern.<Event>begin("start").where(...).followedBy("start_middle").where(...)
);
// 严格邻近连续
Pattern<Event, ?> strict = start.next(
Pattern.<Event>begin("next_start").where(...).followedBy("next_middle").where(...)
).times(3);
// 宽松邻近连续
Pattern<Event, ?> relaxed = start.followedBy(
Pattern.<Event>begin("followedby_start").where(...).followedBy("followedby_middle").where(...)
).oneOrMore();
// 非确定宽松邻近连续
Pattern<Event, ?> nonDetermin = start.followedByAny(
Pattern.<Event>begin("followedbyany_start").where(...).followedBy("followedbyany_middle").where(...)
).optional();匹配后跳过策略
Flink CEP中对于给定的一个模式匹配,同一个事件可能会分配到多个匹配结果中。例如,复杂事件模式为a+ b (表示a事件可以有1到多个,再往后可以跟上1个b事件),输入数据流:a1,a2,b 输出结果会有{a1,a2,b、a1,b、a2,b} ,a1事件就会输出到多个匹配结果中,一些情况下我们希望对这些匹配的结果进行精简,可以使用Flink CEP中提供的"匹配后跳过策略"(After Match Skip Strategy)。
"匹配后跳过策略"可以控制一个事件分配到多少个匹配上,我们只需要在Pattern的begin方法中指定跳过策略AfterMatchSkipStrategy即可,使用方式如下:
AfterMatchSkipStrategy skipStrategy = ...;
Pattern.begin("patternName", skipStrategy);AfterMatchSkipStrategy一共有五种跳过策略,定义方式分别如下:
AfterMatchSkipStrategy.noSkip()
AfterMatchSkipStrategy.skipToNext()
AfterMatchSkipStrategy.skipPastLastEvent()
AfterMatchSkipStrategy.skipToFirst(patternName)
AfterMatchSkipStrategy.skipToLast(patternName)下面结合一个场景分别介绍五种跳过策略。场景:假设给定一个复杂事件模式:a+ b (表示a事件可以有1到多个,再往后可以跟上1个b事件),如果输入流为a1,a2,a3,b,那么匹配结果共有六种:{a1,a2,a3,b、a1,a2,b、a1,b、a2,a3,b、a2,b、a3,b}
- NO_SKIP-不跳过策略
NO_SKIP不跳过策略是默认策略,即所有匹配的结果都会输出。以上场景对应输出{a1,a2,a3,b、a1,a2,b、a1,b、a2,a3,b、a2,b、a3,b}结果。
- SKIP_TO_NEXT - 跳至下一个策略
SKIP_TO_NEXT策略针对相同开头事件只会输出第一个。以上场景中,a1开头的匹配事件有{a1,a2,a3,b、a1,a2,b、a1,b},那么只会输出{a1,a2,a3,b};a2开头的匹配事件有{a2,a3,b、a2,b},那么只会输出{a2,a3,b};a3开头的匹配事件只有{a3,b},所以使用这种跳过策略输出最终结果为:{a1,a2,a3,b、a2,a3,b、a3,b}。
- SKIP_PAST_LAST_EVENT - 跳过所有子匹配策略
SKIP_PAST_LAST_EVENT 策略会跳过开始匹配事件到结束匹配事件之间所有子匹配,只输出匹配的开始事件到结束事件一个匹配。以上场景中使用这种跳过策略只会输出{a1,a2,a3,b}匹配结果。
- SKIP_TO_FIRST(patternName) - 跳至第一个策略
SKIP_TO_FIRST策略需要传入一个模式名称,指定跳至哪个模式(Pattern),首先会找到整个CEP Pattern的开始事件到结束事件匹配,然后找到跳至模式的开始事件(E),会将所有不以E事件为开始的匹配都丢弃。以上场景中如果指定SKIP_TO_FIRST("a事件pattern名称")策略,首先会找到该模式匹配的开始事件到结束事件匹配------{a1,a2,a3,b},然后找到该模式的开始事件(a1),所有不以a1开始的匹配都会被丢弃,最终输出{a1,a2,a3,b、a1,a2,b、a1,b}。
- SKIP_TO_LAST(patternName) - 跳至最后一个策略
SKIP_TO_LAST策略也需要传入一个模式名称,指定跳至哪个模式(Pattern),首先会找到整个CEP Pattern 的开始事件到结束事件匹配,然后找到跳至模式的最后事件(E),会将所有不以E事件为开始的匹配都丢弃。以上场景中如果指定SKIP_TO_LAST("a事件pattern名称")策略,首先会找到该模式匹配的开始事件到结束事件匹配------{a1,a2,a3,b},然后找到该模式的最后事件(a3),所有不以a3开始的匹配都会被丢弃,最终输出{a1,a2,a3,b、a3,b}。
以上场景的代码实现如下,由于Java代码和Scala代码非常类似,这里只给出Java代码实现。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.定义事件流
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//2.定义匹配规则
//Pattern<String, String> pattern = Pattern.<String>begin("start")
//Pattern<String, String> pattern = Pattern.<String>begin("start", AfterMatchSkipStrategy.noSkip())
//Pattern<String, String> pattern = Pattern.<String>begin("start", AfterMatchSkipStrategy.skipToNext())
//Pattern<String, String> pattern = Pattern.<String>begin("start", AfterMatchSkipStrategy.skipPastLastEvent())
//Pattern<String, String> pattern = Pattern.<String>begin("start", AfterMatchSkipStrategy.skipToFirst("start"))
Pattern<String, String> pattern = Pattern.<String>begin("start", AfterMatchSkipStrategy.skipToLast("start"))
.where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("a");
}
}))
.oneOrMore()
.followedBy("middle").where(SimpleCondition.of(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("b");
}
}));
//3.应用规则
PatternStream<String> patternStream = CEP.pattern(ds, pattern).inProcessingTime();
//4.获取匹配到的数据
patternStream.select(new PatternSelectFunction<String, String>() {
@Override
public String select(Map<String, List<String>> pattern) throws Exception {
String start = pattern.get("start").toString();
String middle = pattern.get("middle").toString();
return start+"-"+middle;
}
}).print();
env.execute();以上代码中分别指定了5种匹配后跳过策略,代码执行后,向socket-9999中输入如下数据:
#socket-9999
a1
a2
a3
b可以看到对应的5种匹配后跳过策略输出结果如下:
#AfterMatchSkipStrategy.noSkip()输出结果如下
[a1, a2, a3]-[b]
[a1, a2]-[b]
[a1]-[b]
[a2, a3]-[b]
[a2]-[b]
[a3]-[b]
#AfterMatchSkipStrategy.skipToNext()输出结果如下
[a1, a2, a3]-[b]
[a2, a3]-[b]
[a3]-[b]
#AfterMatchSkipStrategy.skipPastLastEvent()输出结果如下
[a1, a2, a3]-[b]
#AfterMatchSkipStrategy.skipToFirst("start")输出结果如下
[a1, a2, a3]-[b]
[a1, a2]-[b]
[a1]-[b]
#AfterMatchSkipStrategy.skipToLast("start")输出结果如下
[a1, a2, a3]-[b]
[a3]-[b]