一、故障背景
某大型云数据中心部署了一批DPDK软件交换机。
主要承担:
- EVPN VXLAN Leaf
- L2/L3 Gateway
- Overlay Routing
- ACL Filtering
- Telemetry
硬件平台:
| 项目 | 配置 |
|---|---|
| CPU | Intel Xeon Gold 6430 |
| 网卡 | Intel E810 |
| DPDK | 23.11 |
| PMD Core | 32 |
| Route Scale | 600万 Prefix |
正常运行时:
92Mpps长期稳定。
某次业务迁移期间:
大量租户迁移。
BGP EVPN发生:
路由撤销
路由学习
MAC迁移
ARP迁移此后开始出现:
P99 RTT升高
TCP重传增加
PPS下降但监控显示:
PMD线程 100%始终如此。
二、第一轮排查
查看网卡统计:
rte_eth_stats_get()结果:
imissed = 0
ierrors = 0
rx_nombuf = 0完全正常。
RSS统计:
32 Queue
均衡正常。
ACL统计:
Lookup Cycles
无明显变化正常。
LPM查找:
DIR24_8
稳定正常。
问题陷入僵局。
三、发现关键线索
运维团队发现:
问题只出现在:
EVPN收敛期间而:
静态路由环境完全正常。
这意味着:
问题可能不在:
查表而在:
更新表四、交换机中的控制面与数据面
现代交换机:
控制面:
BGP
EVPN
OSPF负责:
增删路由数据面:
PMD负责:
查找路由问题来了:
当控制面删除一条路由时:
fib_delete(prefix);如果立即释放:
free(route);危险。
因为:
PMD线程可能正在访问。
五、为什么不能立即释放
假设:
Core7:
route = fib_lookup(ip);刚拿到指针。
此时:
控制面:
free(route);那么:
Core7:
route->nh立刻变成:
野指针因此:
现代交换机大量使用:
RCU(Read Copy Update)
机制。
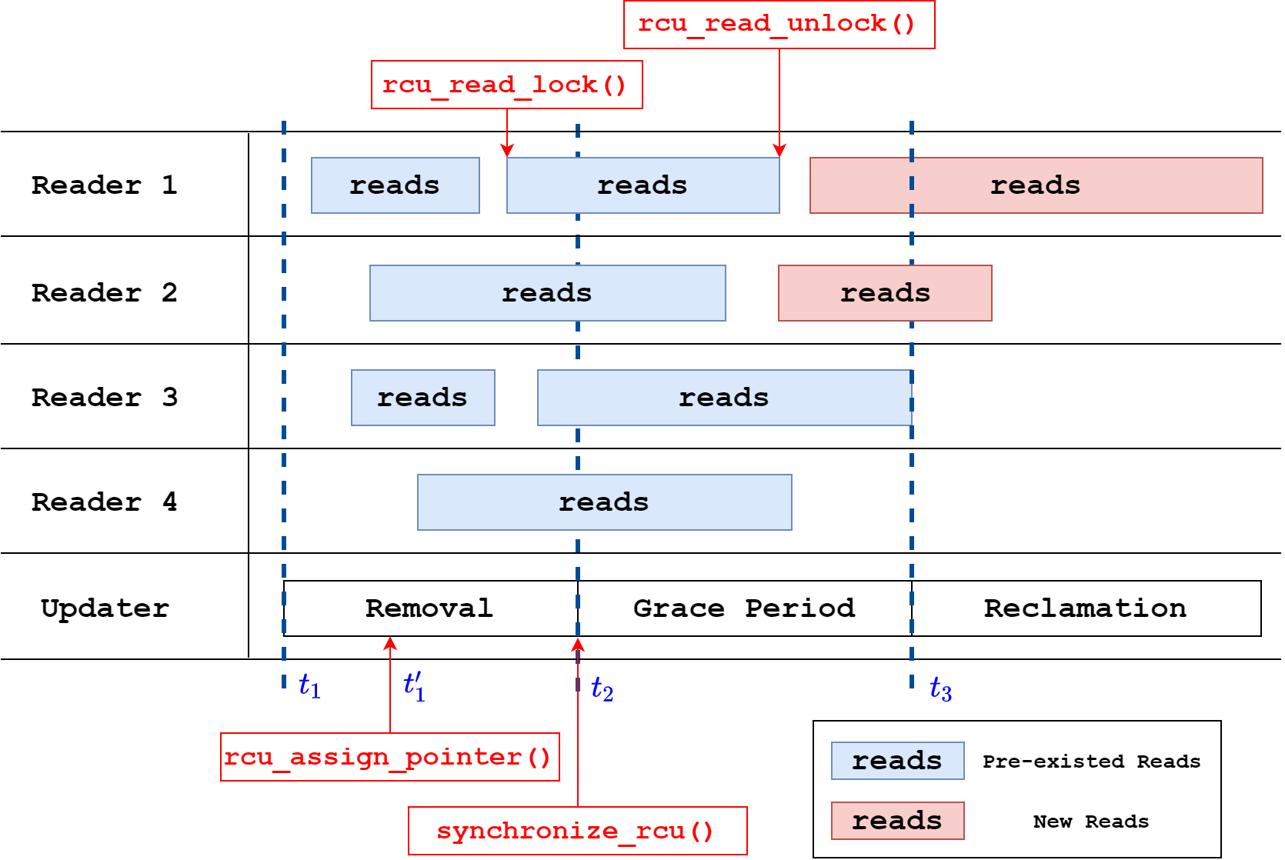
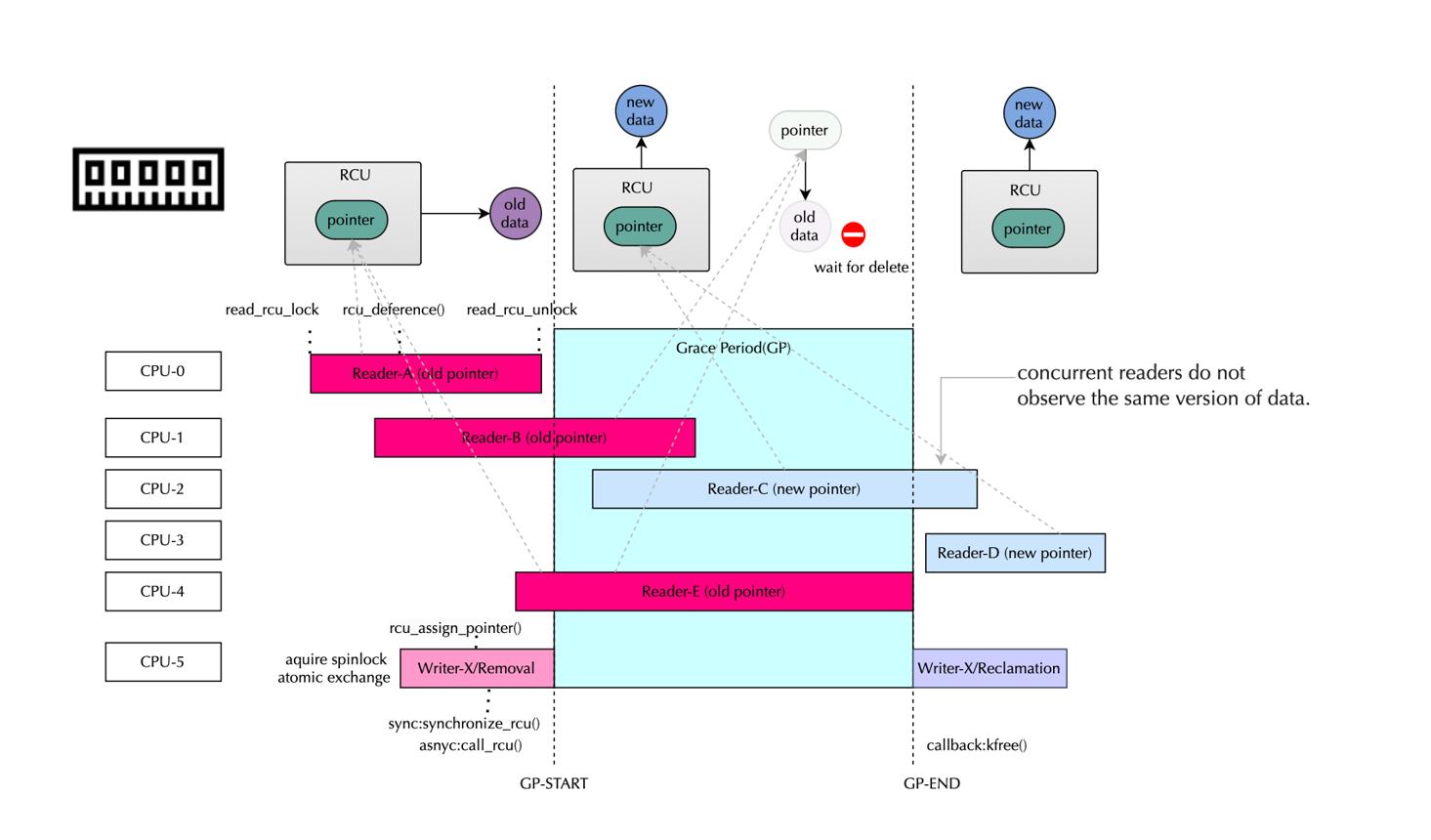
六、RCU工作原理
控制面:
创建新版本
↓
替换指针
↓
旧对象进入回收队列数据面:
继续访问旧对象。
等待:
Grace Period结束。
再释放。
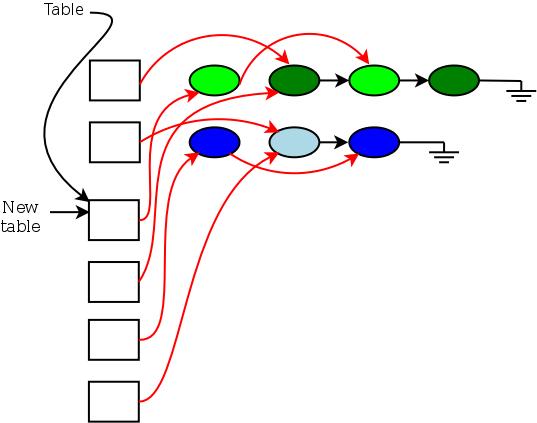
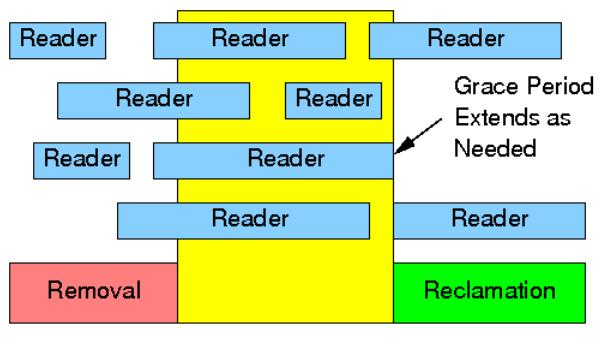
下面是典型的RCU结构示意:
七、问题开始浮现
EVPN收敛期间:
每秒:
120万次
Route Update意味着:
旧路由对象
旧邻接对象
旧MAC对象持续进入:
RCU回收链表理论上:
没问题。
但:
现场统计发现:
RCU Pending Objects不断增长。
八、为什么会增长
继续分析。
发现:
PMD线程:
while(1)
{
rte_eth_rx_burst();
process();
rte_eth_tx_burst();
}永远不睡眠。
对于RCU来说:
需要:
Reader离开临界区才能完成Grace Period。
而某些代码:
rcu_read_lock();
process_packet();
rcu_read_unlock();包围了整个Burst处理。
结果:
Grace Period
极长九、RCU对象开始堆积
系统运行数分钟后:
Pending Route
280万继续增长:
Pending Route
430万最终:
700万+十、第二个隐患
这些对象虽然:
逻辑删除但:
物理未释放于是:
内存占用:
16GB
↓
44GB
↓
78GB持续增长。
十一、缓存开始失效
原来:
活跃FIB:
8GB后来:
8GB
+
70GB Pending导致:
CPU缓存命中率下降。
Perf统计:
LLC Miss从:
4%增长到:
18%十二、为什么查找时间没变
这是最迷惑人的地方。
单次:
fib_lookup()耗时仍然正常。
但:
缓存污染导致:
Route Metadata
Neighbor Metadata访问成本上升。
于是:
Cycles/Packet持续增加。
十三、真正根因
完整链路:
EVPN收敛
↓
大量Route Delete
↓
RCU Pending增长
↓
Grace Period过长
↓
对象无法释放
↓
内存膨胀
↓
Cache污染
↓
Cycles/Packet增加
↓
PPS下降十四、定位证据
统计:
rcu_pending_count();结果:
| 时间 | Pending |
|---|---|
| 初始 | 2万 |
| 5分钟 | 180万 |
| 10分钟 | 420万 |
| 20分钟 | 730万 |
与PPS下降趋势完全一致。
十五、解决方案
方案一
缩小RCU读侧范围:
原来:
rcu_read_lock();
process_burst();
rcu_read_unlock();改为:
for(each packet)
{
rcu_read_lock();
fib_lookup();
rcu_read_unlock();
}Grace Period显著缩短。
方案二
分层路由对象
把:
Route
Neighbor
Statistics拆分。
减少回收对象大小。
方案三
异步批量释放
引入:
RCU Reclaimer Thread集中回收。
方案四
控制面限速
避免:
百万级更新风暴瞬时冲击。
优化结果
| 指标 | 优化前 | 优化后 |
|---|---|---|
| PPS | 61M | 91M |
| Pending Route | 730万 | 8万 |
| LLC Miss | 18% | 4% |
| RTT P99 | 5.3ms | 0.7ms |
核心知识点总结
知识点1
高性能交换机中的性能问题不一定发生在:
查表也可能发生在:
删表知识点2
RCU解决的是:
读写并发问题。
知识点3
RCU的成本不是查找。
而是:
延迟释放知识点4
PMD线程100%运行时。
Grace Period设计尤为关键。
知识点5
大量Pending对象会污染缓存。
知识点6
缓存污染不一定体现在Lookup时间上。
却会体现在:
Cycles Per Packet上。
知识点7
大型EVPN交换机设计中:
FIB更新架构和:
FIB查找架构同样重要。