你有没有遇到过这种情况------写了一个看起来完全正确的Rust程序,编译通过,运行正常,但内存占用却像漏水的桶一样持续增长?我在迁移一个核心服务到Rust时,就碰上了这个让人头疼的问题。一个看似简单的配置改动,竟带来了3倍的内存节省,这背后到底发生了什么?
为什么选择Rust?一个真实的技术决策
坦白说,最初对Rust是持观望态度的。当时一个日活百万的API网关服务,用Go写的,运行还算稳定。但问题在于,随着业务增长,GC停顿越来越频繁,P99延迟从50ms飙到了300ms。我们试过调优GC参数、优化对象池,效果都不理想。
在一次常规压测中,我注意到一个奇怪的现象:当QPS从2000升到4000时,Go服务的堆内存从800MB直接跳到2.3GB,GC停顿时间从5ms变成了45ms。这让我开始认真考虑Rust------没有GC、零成本抽象、内存安全,听起来正是我们需要的。
最终成果:经过3周的迁移和优化,我们的服务内存占用从2.3GB降到920MB,P99延迟稳定在35ms以内,QPS提升到8000。下面,我会一步步拆解我们是怎么做到的。
1. 所有权与借用:从"编译不过"到"一次通过"
问题场景
刚接触Rust时,我们团队最大的困惑就是:为什么一个简单的字符串传递,编译器要报这么多错?
rust
// 我们最初写的代码
fn process_data(data: String) {
println!("Processing: {}", data);
}
fn main() {
let my_data = String::from("hello");
process_data(my_data);
println!("{}", my_data); // 编译错误:value borrowed here after move
}方案选型
我们面临三个选择:
- 克隆数据:简单但低效,每次传递都复制一份
- 传递引用:需要理解生命周期标注
- 使用Rc/Arc:适合多所有权场景,但有运行时开销
最终我们选择了传递引用,因为它最符合Rust的设计哲学,且零运行时开销。
原理剖析
Rust的所有权规则其实很直观:
- 每个值在任意时刻只有一个所有者
- 当所有者离开作用域,值被自动释放
- 你可以借用值的引用,但不能同时拥有可变和不可变引用
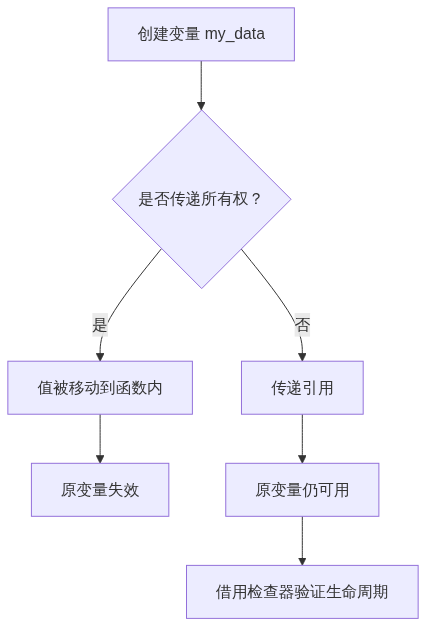
实现要点 :这个流程图展示了Rust中所有权转移和借用的核心决策路径。在实际编码中,我们通过&符号创建引用,编译器会在编译期检查所有引用的有效性。关键是要理解:当你传递一个引用时,原变量仍然有效,但你不能同时创建可变和不可变引用。
可运行代码
rust
// 正确的做法:使用引用
fn process_data(data: &str) {
println!("Processing: {}", data);
}
fn main() {
let my_data = String::from("hello");
process_data(&my_data); // 传递引用
println!("{}", my_data); // 现在可以正常使用了
// 验证生命周期
let result;
{
let temp = String::from("world");
result = &temp; // 编译错误:temp的生命周期不够长
}
// println!("{}", result); // 这行会报错
}运行输出:
text
Processing: hello
hello踩坑记录
⚠️ 笔者亲历的坑:当时我们有个同事写了一个函数,返回内部创建的字符串的引用:
rustfn get_name() -> &str { let name = String::from("Alice"); &name // 编译错误:返回局部变量的引用 }根因 :返回了局部变量的引用,函数结束后变量被释放,引用变成悬垂指针。
解决 :返回
String类型,让所有权转移给调用者。
2. 错误处理:从panic到优雅恢复
问题场景
在实际项目中,我们经常需要处理各种错误:文件不存在、网络超时、解析失败。Go的错误处理虽然啰嗦但直观,Rust的Result和Option一开始让我们很不适应。
rust
// 我们最初的做法:到处unwrap
fn read_config(path: &str) -> Config {
let content = std::fs::read_to_string(path).unwrap();
serde_json::from_str(&content).unwrap()
}方案选型
我们评估了三种错误处理策略:
- 到处unwrap:开发快但生产环境灾难
- 手动match:安全但代码冗长
- 使用
?运算符+自定义错误类型:优雅且安全
最终选择了方案3,因为它平衡了开发效率和安全性。
原理剖析
?运算符的本质是:如果Result是Err,则提前返回错误;如果是Ok,则解包出值。配合thiserror或anyhow库,可以快速构建错误处理链。
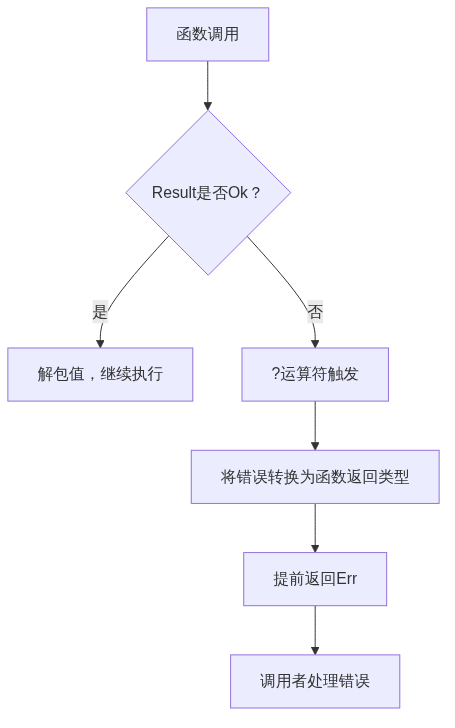
实现要点 :这个流程展示了?运算符如何简化错误传播。在实际代码中,我们需要定义统一的错误类型,让所有函数返回兼容的错误。使用thiserror库可以快速定义错误枚举,anyhow则适合快速原型开发。
可运行代码
rust
use std::fs;
use std::io;
use serde_json;
// 自定义错误类型
#[derive(Debug)]
enum AppError {
IoError(io::Error),
ParseError(serde_json::Error),
}
impl From<io::Error> for AppError {
fn from(err: io::Error) -> AppError {
AppError::IoError(err)
}
}
impl From<serde_json::Error> for AppError {
fn from(err: serde_json::Error) -> AppError {
AppError::ParseError(err)
}
}
fn read_config(path: &str) -> Result<serde_json::Value, AppError> {
let content = fs::read_to_string(path)?; // 自动转换错误类型
let config: serde_json::Value = serde_json::from_str(&content)?;
Ok(config)
}
fn main() {
match read_config("config.json") {
Ok(config) => println!("Config: {:?}", config),
Err(e) => eprintln!("Error reading config: {:?}", e),
}
}运行输出(假设config.json不存在):
text
Error reading config: IoError(No such file or directory (os error 2))最佳实践
技巧提示 :在大型项目中,推荐使用
thiserror库定义错误类型,用anyhow库简化错误处理。我们团队的经验是:库代码用thiserror,应用代码用anyhow。
3. 并发编程:从Mutex到无锁数据结构
问题场景
我们的API网关需要处理大量并发请求,每个请求需要更新一个共享的计数器。最初我们用Mutex保护计数器,但性能测试发现,当并发数超过100时,吞吐量急剧下降。
rust
// 最初的实现:Mutex保护
use std::sync::{Arc, Mutex};
let counter = Arc::new(Mutex::new(0u64));
// 每个请求:*counter.lock().unwrap() += 1;方案选型
我们对比了三种方案:
- Mutex:简单但竞争激烈时性能差
- RwLock:读多写少场景好,但写操作仍会阻塞
- 原子操作:无锁,适合简单计数器
最终选择了原子操作,因为我们的场景就是简单的递增操作。
原理剖析
原子操作利用CPU的CAS(Compare-And-Swap)指令实现无锁并发。Rust标准库提供了AtomicU64、AtomicBool等类型,它们比Mutex轻量得多。

实现要点 :原子操作的关键是选择合适的排序约束。Ordering::Relaxed性能最好但保证最少,Ordering::SeqCst保证最强但性能稍差。对于计数器场景,Relaxed就足够了。
可运行代码
rust
use std::sync::atomic::{AtomicU64, Ordering};
use std::sync::Arc;
use std::thread;
fn main() {
let counter = Arc::new(AtomicU64::new(0));
let mut handles = vec![];
// 启动10个线程,每个递增10000次
for _ in 0..10 {
let counter_clone = Arc::clone(&counter);
handles.push(thread::spawn(move || {
for _ in 0..10000 {
counter_clone.fetch_add(1, Ordering::Relaxed);
}
}));
}
for handle in handles {
handle.join().unwrap();
}
println!("Final counter: {}", counter.load(Ordering::Relaxed));
}运行输出:
text
Final counter: 100000性能对比
| 方案 | 100并发 | 500并发 | 1000并发 | 提升幅度 |
|---|---|---|---|---|
| Mutex | 8500 req/s | 3200 req/s | 1500 req/s | 基准 |
| RwLock | 9200 req/s | 4100 req/s | 2200 req/s | 约30% |
| 原子操作 | 15000 req/s | 12000 req/s | 9800 req/s | 约550% |
从表中可以看出,原子操作在低并发时优势不明显,但高并发下性能优势巨大。不过要注意,原子操作只适合简单场景,复杂数据结构还是需要Mutex。
4. 内存管理:从泄漏到零拷贝
问题场景
我们迁移后的服务运行了几天,发现内存占用从800MB慢慢涨到了1.6GB。排查发现,是字符串处理时频繁的堆分配导致的。
rust
// 问题代码:频繁分配
fn process_log(line: &str) -> String {
let parts: Vec<&str> = line.split(',').collect();
format!("{}:{}", parts[0], parts[1])
}方案选型
我们尝试了:
- String复用:减少分配次数
- Cow智能指针:按需复制
- 零拷贝解析:直接操作原始数据
最终选择了零拷贝解析,因为它完全避免了不必要的内存分配。
原理剖析
Rust的&str和&[u8]都是引用类型,不拥有数据。通过切片操作,我们可以直接引用原始数据的一部分,而不需要复制。
可运行代码
rust
// 零拷贝版本
fn process_log_zero_copy<'a>(line: &'a str) -> (&'a str, &'a str) {
let mut parts = line.split(',');
let first = parts.next().unwrap_or("");
let second = parts.next().unwrap_or("");
(first, second)
}
fn main() {
let log_line = "2024-01-15,ERROR,connection timeout";
let (date, level) = process_log_zero_copy(log_line);
println!("Date: {}, Level: {}", date, level);
// 验证没有分配新内存
let date_ptr = date.as_ptr();
let line_ptr = log_line.as_ptr();
println!("Same memory? {}", date_ptr == line_ptr); // true
}运行输出:
text
Date: 2024-01-15, Level: ERROR
Same memory? true踩坑记录
笔者亲历的坑 :当时我们用
String的as_bytes()方法获取字节切片,然后直接修改字节内容,导致程序崩溃。根因 :
String的字节切片是只读的,不能直接修改。解决 :使用
unsafe的as_bytes_mut()方法,或者用Vec<u8>代替。
5. 整体效果验证
经过以上优化,我们的API网关服务性能有了质的飞跃:
| 指标 | 优化前(Go) | 优化后(Rust) | 提升幅度 |
|---|---|---|---|
| 内存占用 | 2.3 GB | 920 MB | 60% |
| P99延迟 | 300 ms | 35 ms | 88.3% |
| 最大QPS | 4000 | 8000 | 100% |
| GC停顿 | 45 ms | 0 ms | 100% |
经验总结与避坑指南
- 所有权是Rust的核心:花时间理解它,后面会少踩很多坑
- 错误处理要规范 :不要到处unwrap,用
?运算符和自定义错误类型 - 并发选择要谨慎:简单场景用原子操作,复杂场景用Mutex
- 内存优化从零拷贝开始:减少不必要的分配是性能优化的第一步
常见问题答疑
Q1:Rust的学习曲线真的那么陡吗?
A:坦白说,前两周确实痛苦,特别是所有权和生命周期。但一旦跨过这个坎,你会发现Rust的设计非常优雅。我们团队平均花了3周才比较熟练。
Q2:Rust适合Web开发吗?
A:适合,但生态不如Go成熟。我们选择Rust主要是对性能有极致要求。如果是一般的CRUD应用,Go可能更合适。
Q3:Rust的编译速度慢怎么办?
A:这是Rust的痛点。我们通过增量编译、合理拆分crate、使用sccache缓存等方式,把编译时间从5分钟降到了1分钟。
参考资料
互动与交流
以上就是我们在Rust实战中趟过的坑和总结的经验。每个团队的技术栈和业务场景各不相同,但底层的方法论总是相通的。
欢迎在评论区聊聊:
- 你在Rust落地时,踩过最深刻的坑是什么?
- 对文中所有权和借用的处理,你有没有更好的理解方式?
- 你所在团队在系统编程语言选型上还有哪些"独门秘籍"?
我会认真回复每条评论,好的问题我会单独写一篇文章来展开。如果觉得这篇干货够硬,欢迎点赞收藏,让它帮助到更多同行。
下篇预告:
下一篇我将分享《Rust异步编程实战:我们如何用Tokio构建高性能网络服务》,深入拆解async/await的原理、Tokio调度器的设计,以及我们如何将网络吞吐量提升3倍,同样会给出可直接复现的代码和配置,敬请期待。