文章目录
- 前言
- 一、状态概述
- 二、检查点(Checkpoint)
-
- (一)概念
- (二)设置CheckPoint
-
- [1. 开启快照,每隔1s保存一次快照:](#1. 开启快照,每隔1s保存一次快照:)
- [2. 设置快照保存的位置](#2. 设置快照保存的位置)
- [3. 取消flink的job时,不删除HDFS的checkpoint目录](#3. 取消flink的job时,不删除HDFS的checkpoint目录)
- 4.具体示例完整代码
- (三)从CheckPoint重启应用
- 三、保存点(Savepoint)
- 总结
前言
在实时流处理领域,Apache Flink 凭借其卓越的容错机制和精确的状态管理能力,成为业界公认的标准。状态(State)是流处理中承载计算逻辑与历史信息的核心载体,它决定了算子能否在事件驱动的场景下实现聚合、窗口、去重等复杂功能。本文围绕 Flink 的状态管理展开系统梳理:首先厘清无状态与有状态算子的区别,继而深入剖析托管状态(Managed State)的两大分支------算子状态(Operator State)与按键分区状态(Keyed State),并重点演示 ValueState 的代码实战;随后,文章详细介绍了保障故障恢复的两大机制:自动触发的检查点(Checkpoint)与手动管理的保存点(Savepoint),包括配置方式、重启流程及实际命令行操作。通过本文,读者将建立起对 Flink 状态体系的全方位认知,为编写健壮的流式应用打下坚实基础。
一、状态概述
在Flink中,算子任务可以分为无状态和有状态两种情况。
(一)无状态
- 无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果 。我们之前讲到的基本转换算子,如
map、filter、flatMap,计算时不依赖其他数据,就都属于无状态的算子。

(二)有状态
1.概念
- 而有状态的算子任务 ,则除当前数据之外,还需要一些其他数据来 得到计算结果。这里的**"其他数据",就是所谓的状态(state)**。我们之前讲到的算子中,聚合算子、窗口算子都属于有状态的算子。
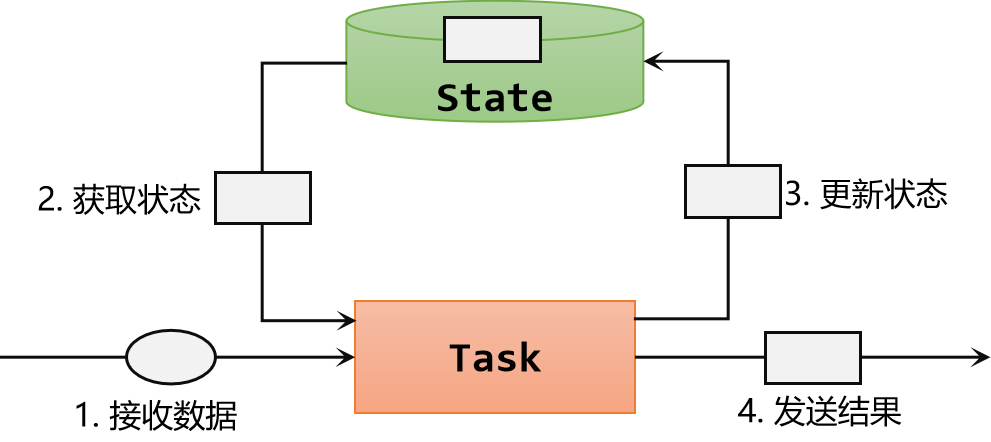
2.步骤
有状态算子的一般处理流程,具体步骤如下:
- 1.算子任务接收到上游发来的数据;
- 2.获取当前状态;
- 3.根据业务逻辑进行计算,更新状态;
- 4.得到计算结果,输出发送到下游任务
(三)状态分类
1.托管状态(Managed State)
托管状态就是由Flink统一管理 的,状态的存储访问、故障恢复和重组等一系列问题都由Flink实现,我们只要调接口 就可以;
通常我们采用Flink托管状态来实现需求。
2.原始状态(Raw State)
原始状态则是自定义 的,相当于就是开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复。
- 在Flink中,一个算子任务会按照并行度分为多个并行子任务执行 ,而不同的子任务会占据不同的任务槽(task slot)。
- 由于不同的slot在计算资源上是物理隔离的,所以Flink能管理的状态在并行任务间是无法共享的,每个状态只能针对当前子任务的实例有效。
- 很多有状态的操作(比如聚合、窗口)都是要先做keyBy进行按键分区的。按键分区之后,任务所进行的所有计算都应该只针对当前key有效,所以状态也应该按照key彼此隔离。
- 基于这样的想法,我们又可以将托管状态分为两类:算子状态和按键分区状态。
3.算子状态(Operator State)
- 状态作用范围限定为当前的算子任务实例,也就是只对当前并行子任务实例有效 。这就意味着对于一个并行子任务,占据了一个"分区",它所处理的所有数据都会访问到相同的状态,状态对于同一任务而言是共享的。
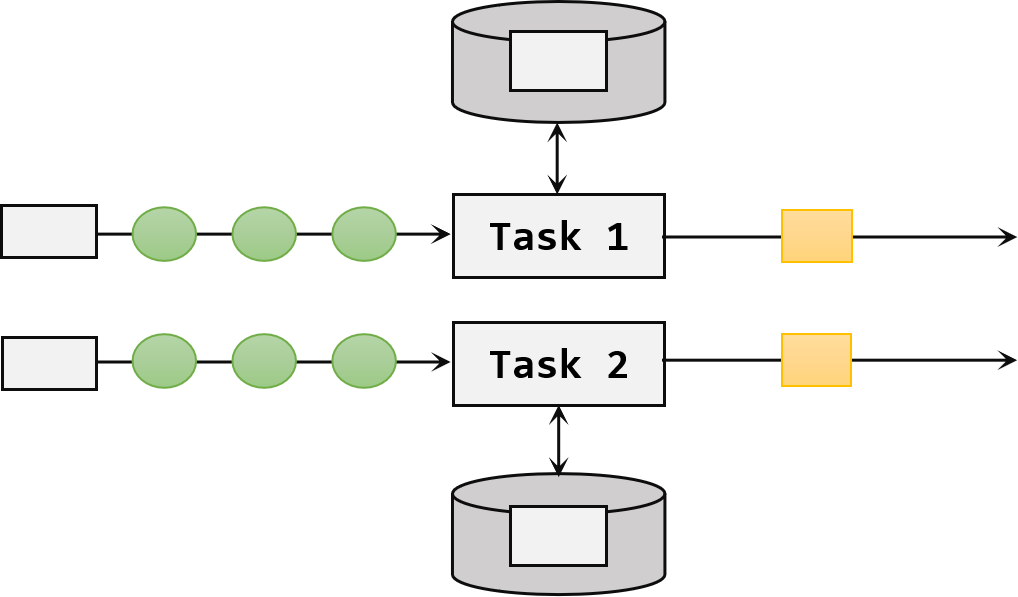
- 算子状态可以用在所有算子上,使用的时候其实就跟一个本地变量没什么区别------因为本地变量的作用域也是当前任务实例。在使用时,我们还需进一步实现CheckpointedFunction接口。
- FLIP-27的新Source架构,则是需要继承SourceReaderBase抽象类。
4.按键分区状态(Keyed State)
- 状态是根据输入流中定义的键(key)来维护和访问的,所以只能定义在**按键分区流(KeyedStream)**中,也就keyBy之后才可以使用。
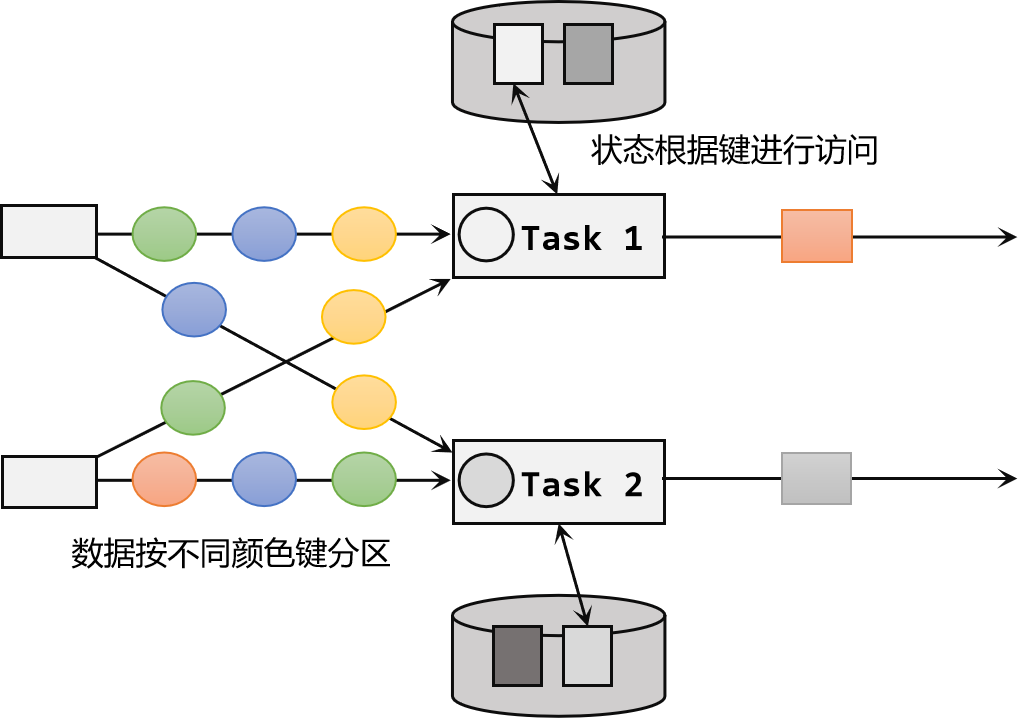
- 按键分区状态应用非常广泛。之前讲到的聚合算子必须在keyBy之后才能使用 ,就是因为聚合的结果是以
Keyed State的形式保存的。
(2)Keyed State概念
- 按键分区状态(Keyed State):是任务按照键(key)来访问和维护的状态。它的特点非常鲜明,就是以key为作用范围进行隔离。
- 需要注意,使用Keyed State必须基于KeyedStream。没有进行keyBy分区的DataStream,即使转换算子实现了对应的富函数类,也不能通过运行时上下文访问Keyed State。
- Flink 提供了以下数据格式来管理和存储键控状态 (Keyed State) :·
ValueState:存储单值类型 的状态。可以使用update(T)进行更新,并通过T value()进行检索。ListState:存储列表类型 的状态。可以使用add(T)或addAll(List)添加元素;并通过get()获得整个列表。ReducingState:用于存储经过 ReduceFunction 计算后的结果,使用 add(T) 增加元素。AggregatingState:用于存储经过 AggregatingState 计算后的结果,使用 add(IN) 添加元素。FoldingState:已被标识为废弃,会在未来版本中移除,官方推荐使 AggregatingState 代替。MapState:维护 Map 类型的状态。
(3)代码
java
package chapter07;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
// 使用KeyState中的ValueState获取数据中的最大值(获取每个key的最大值)(实际中直接使用max/maxby即可)
public class KeyedStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Tuple2<String, Long>> tupleDS = env.fromElements(
Tuple2.of("北京", 1L),
Tuple2.of("上海", 2L),
Tuple2.of("北京", 6L),
Tuple2.of("上海", 8L),
Tuple2.of("北京", 3L),
Tuple2.of("上海", 4L),
Tuple2.of("北京", 7L)
);
tupleDS
.keyBy(v -> v.f0)
.map(new RichMapFunction<Tuple2<String, Long>, Tuple2<String, Long>>() {
// 状态采用ValueState用于保存最大值
ValueState<Long> maxValueState = null;
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<Long> stateDescriptor = new ValueStateDescriptor<>("valueState", Long.class);
maxValueState = getRuntimeContext().getState(stateDescriptor);
}
@Override
public Tuple2<String, Long> map(Tuple2<String, Long> tuple2) throws Exception {
Long maxValue = maxValueState.value();
Long currentValue = tuple2.f1;
if(maxValue == null || currentValue > maxValue){
maxValueState.update(currentValue);
maxValue = currentValue;
}
return Tuple2.of(tuple2.f0, maxValue);
}
}).print();
env.execute();
}
}无论是Keyed State还是Operator State,它们都是在本地实例上维护的,也就是说每个并行子任务维护着对应的状态,算子的子任务之间状态不共享。
二、检查点(Checkpoint)
(一)概念
- 在流处理中,我们可以用存档读档 的思路,就是将之前某个时间点所有的状态保存下来 ,这份"存档"就是所谓的"检查点"(checkpoint)。
- 遇到故障重启 的时候,我们可以从检查点中"读档",恢复出之前的状态,这样就可以回到当时保存的一刻接着处理数据了。
- 这里所谓的 "检查",其实是针对故障恢复的结果而言的 :故障恢复之后继续处理的结果,应该与发生故障前完全一致,我们需要"检查"结果的正确性。所以,有时又会把checkpoint叫做"一致性检查点"。
(二)设置CheckPoint
1. 开启快照,每隔1s保存一次快照:
java
env.enableCheckpointing(1000); 2. 设置快照保存的位置
java
env.setStateBackend(new FsStateBackend("hdfs://bigdata01:9820/flink/checkpoint")); 3. 取消flink的job时,不删除HDFS的checkpoint目录
java
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);4.具体示例完整代码
java
package chapter07;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class CheckPointDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//在windows下运行,将数据提交到hdfs,会出现权限问题
System.setProperty("HADOOP_USER_NAME", "atguigu");
// 1. 开启快照,每隔1s保存一次快照
env.enableCheckpointing(1000);
// 2. 设置快照保存的位置
env.setStateBackend(new FsStateBackend("file:///D:/flink/chk"));
// 3. 取消flink的job时,不删除hdfs的checkpoint目录
env.getCheckpointConfig()
.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
DataStreamSource<String> dataStreamSource = env.socketTextStream("hadoop102", 7777);
SingleOutputStreamOperator<Tuple2<String, Integer>> datastream = dataStreamSource
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
String[] words = s.split(",");
return Tuple2.of(words[0], Integer.valueOf(words[1]));
}
})
.setParallelism(2)
.keyBy(0)
.sum(1);
datastream.print();
env.execute("Socket Word Count");
}
}(三)从CheckPoint重启应用
powershell
flink run -c 全类名 -s CheckPoint位置 jar包
powershell
如:flink run -c com.bigdata.day06._01CheckPointDemo -s hdfs://bigdata01:9820/flink/checkpoint/bf416df7225b264fc34f8ff7e3746efe/chk-603 /opt/app/FlinkDemo-1.0-SNAPSHOT.jar三、保存点(Savepoint)
(一)概念
- 除了检查点外,Flink还提供了另一个非常独特的镜像保存功能------保存点(savepoint)。
- 从名称就可以看出,这也是一个存盘的备份,它的原理和算法与检查点完全相同,只是多了一些额外的元数据。
(二)与检查点的区别------触发时机
- 检查点 是由Flink自动管理的,定期创建,发生故障之后自动读取进行恢复,这是一个**"自动存盘"**的功能;
- 而保存点不会自动创建 ,必须由用户明确地手动触发 保存操作,所以就是 "手动存盘" 。
(三)使用保存点
保存点的使用非常简单,我们可以使用命令行工具来创建保存点,也可以从保存点恢复作业。
1.创建保存点
要在命令行中为运行的作业创建一个保存点镜像,只需要执行:
powershell
bin/flink savepoint :jobId [:targetDirectory]- 这里jobId需要填充要做镜像保存的作业ID,目标路径targetDirectory可选,表示保存点存储的路径。
- 例如:flink savepoint 79f53c5c0bb3563b6b6ed3011176c411 hdfs://hadoop102:8020/flink/savepoint
2.从保存点重启应用
要从保存点重启一个应用只需要执行
powershell
bin/flink run -s :savepointPath [:runArgs]
##如:
bin/flink run -c chapter07.CheckPointDemo -s hdfs://hadoop102:8020/flink/savepoint/savepoint-254aa4-c601bc38410d FlinkDemos_BD1-1.0-SNAPSHOT.jar- 这里只要增加一个
-s参数,指定保存点的路径就可以了,其它启动时的参数还是完全一样的。 - 如果使用web UI 进行作业提交时,可以填入的参数除了入口类、并行度和运行参数,还有一个 "Savepoint Path",这就是从保存点启动应用的配置。
总结
本文全面梳理了 Flink 中状态管理的核心知识体系。我们首先明确了有状态与无状态算子的区分,指出聚合、窗口等操作依赖于按键分区状态(Keyed State)来实现按 key 隔离的数据存储;而算子状态(Operator State)则作用于并行子任务实例,适用于更通用的场景。在托管状态的基础上,文章重点介绍了检查点(Checkpoint)这一自动容错机制,通过周期性保存状态快照,确保故障后能够精确恢复;同时,保存点(Savepoint)作为手动触发的镜像备份,为版本升级、作业迁移提供了极大的灵活性。通过配置 enableCheckpointing、FsStateBackend 以及从检查点/保存点重启应用的具体命令,读者可以轻松将理论付诸实践。状态管理是 Flink 流处理的基石,深入理解这些概念,将有助于您设计出高可靠、易维护的实时数据管道。