文章目录
- 本篇摘要
- 一.基于httplib与Protobuf的轻量级通讯录HTTP服务实现
- 二.PB与Json性能简单测试与对比及总结
- 三.源码仓库
- 四.本篇小结
本篇摘要
本文介绍了基于httplib和Protobuf的轻量级通讯录HTTP服务实现,通过Protobuf序列化实现客户端与服务端的数据交互,展示了客户端和服务端的实现流程,并进行了PB与JSON的性能对比测试,结果显示Protobuf在序列化和反序列化性能上优于JSON。
一.基于httplib与Protobuf的轻量级通讯录HTTP服务实现
1·简单介绍
应用场景说明
Protobuf 除常见用途外,这里用于实现网络版本通讯录中客户端与服务端之间的协议序列化,以完成两者交互。
客户端功能需求
客户端能够对通讯录执行以下操作:
- 新增联系人:可以向通讯录中添加新的联系人信息。
- 删除联系人:能够从通讯录里移除指定的联系人。
- 查询通讯录列表:获取通讯录中所有联系人的列表信息。
- 查询单个联系人详细信息:针对特定联系人,获取其详细的联系方式等信息。
服务端功能需求
服务端需提供增、删、查的能力,并且要对通讯录数据进行持久化存储,以保证数据在服务端重启等情况下不会丢失(这里不使用数据库了简单改成文件存储)。
数据交互方式
客户端和服务端之间交互的数据采用 Protobuf 格式来完成序列化和反序列化等操作,以此实现高效、稳定的数据传输与交互。
2·基于httplib库的简单介绍及安装
库的基本信息
- 性质:它是一个开源的C++封装的HTTP库。
- 跨平台性:能够在Linux和Windows平台上使用,用于搭建HTTP客户端和HTTP服务端。
功能特点
- 简洁易用:使用起来非常方便,对于开发者来说容易上手,降低了开发HTTP相关功能的难度。
使用方法
- 包含头文件 :在C++代码中,只需要包含
httplib.h头文件即可使用该库提供的功能。如:
cpp
#include "httplib.h"- 编译选项 :在编译程序时,需要带上
-lpthread选项。假设你的源文件名为main.cpp,在Linux平台下使用g++编译器的编译命令示例如下:
bash
g++ main.cpp -lpthread这将生成一个名为a.out的可执行文件。
应用场景(简单客户端和服务端搭建)
HTTP服务端
cpp
#include "httplib.h"
int main() {
httplib::Server svr;
svr.Get("/", const httplib::Request&, httplib::Response& res {
res.set_content("Hello, World!", "text/plain");
});
svr.listen("0.0.0.0", 8080);
return 0;
}- 上述创建了一个简单的HTTP服务端,监听在本地的8080端口,当访问根路径
/时,返回"Hello, World!"(可以理解成把对应get方法对应的'/'URl处注册进对应方法;只要被客户访问就自动返回对应的内容+功能类型的http答复)。
HTTP客户端
cpp
#include "httplib.h"
#include <iostream>
int main() {
httplib::Client cli("localhost", 8080);
auto res = cli.Get("/");
if (res && res->status == 200) {
std::cout << res->body << std::endl;
}
return 0;
}- 创建了一个HTTP客户端,向本地8080端口的服务端发送GET请求,并在请求成功(状态码为200)时输出响应的内容(即访问对应的上面服务端的get处的
'/'对应的方法)。
安装教程
这里可以直接git clone即可:
https://github.com/yhirose/cpp-httplib
下载后可以看到对应里面内容:

- 这里我们只需要用到对应头文件
httplib.h就够了。
3·项目整体流程操作概览
http请求与应答双方约束:
1·规定此次通讯交互的对应类型:
Content-Type: application/protobuf
2·对应增 删 详查 全查 访问的服务端对应url:
- 增 :
/contacts/add - 删 :
/contacts/del - 详查:
/contacts/find-one - 全查:
/contacts/find-all
3.简单演示下对应的双方如何操作:
比如客户端请求对应的添加联系人:
cpp
// 发送psot请求
auto res = cli.Post("/contacts/add", req_str, "application/protobuf"); // url即服务端对应的post对应的url来接收;其次就是对应的请求头类型:Content-Type:- 此时就是post请求把对应req_str(序列化后的proto对象)发送给对应服务端注册的接收post请求url为
"/contacts/add"的位置;然后调用对应回调。
对应服务端接收到上面请求进行处理:
cpp
srv.Post("/contacts/add", [&contactsServer](const httplib::Request &req, httplib::Response &res){ //处理 });- 此时就可以理解服务端去拿着对应接收到的请求调用这个回调函数然后构建res(http库内设置的)即可(也就是回调函数里要完成任务);最后发送有http库自动完成;用户无需关心。
4.基于整个交互流程操作总结功能流程图:
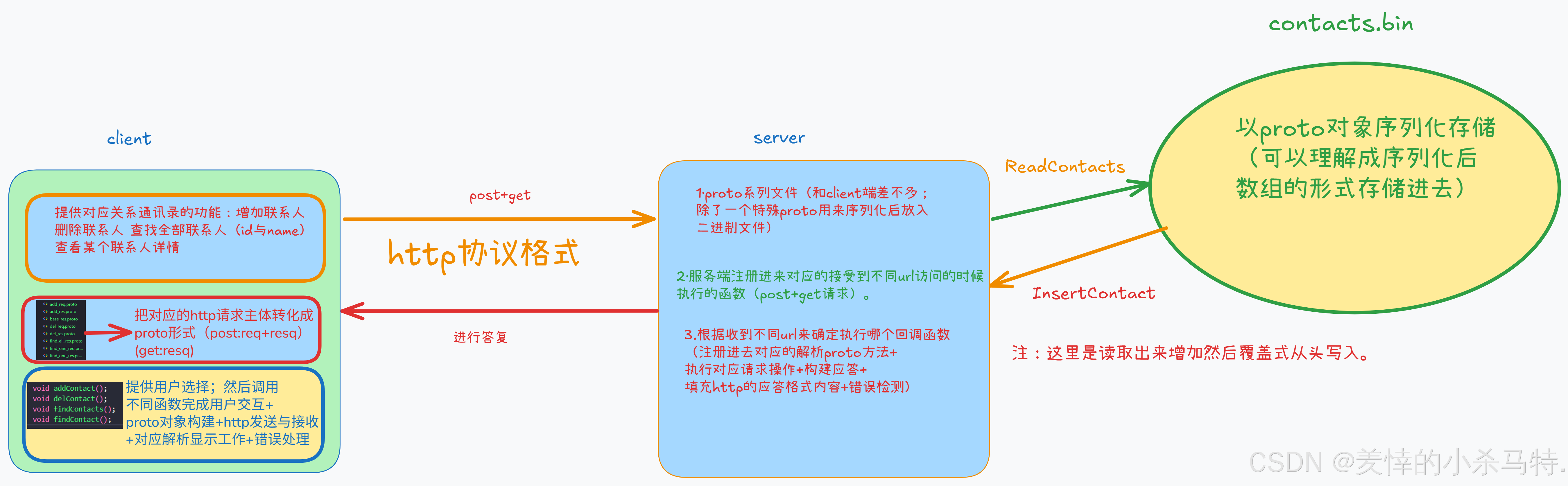
4·实现流程
client与server处对应proto文件设置
client处的发送的请求(序列化)+接收的答复(反序列化)
设计的时候为了简单;因此增加需要对应的具体内容;删除通过服务端储存的id来操作;查询也是id;全查就是通过get直接获取;而对应的应答都要包含基础应答(如是否成功;如果错误,对应错误原因);剩下就是填写对应需要内容;总体如下:
add_req.proto:
cpp
syntax = "proto3";
package add_contact_req;
// 新增联系人 req
message AddContactRequest {
string name = 1; // 姓名
int32 age = 2; // 年龄
message Phone {
string number = 1; // 电话号码
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
PhoneType type = 2; // 类型
}
repeated Phone phone = 3; // 电话
map<string, string> remark = 4; // 备注
}add_res.proto:
cpp
syntax = "proto3";
package add_contact_res;
import "base_res.proto";
//服务端管理的有个uid-contactmap;查询拿到uid来进行删除等操作:
message AddContactResponse {
base_res.BaseResponse base_resp = 1;
string uid = 2;
}base_res.proto:
cpp
syntax = "proto3";
package base_res;
message BaseResponse {
bool success = 1; // 返回结果
string error_desc = 2; // 错误描述
}del_req.proto:
cpp
syntax = "proto3";
package del_req;
//服务端管理的有个uid-contactmap;查询拿到uid来进行删除等操作:
message DelContactRequest {
string uid = 1;
}del_res.proto:
cpp
syntax = "proto3";
package del_res;
//服务端管理的有个uid-contactmap;查询拿到uid来进行删除等操作:
import "base_res.proto";
message DelContactResponse {
base_res.BaseResponse base_resp = 1;
string uid = 2;
}find_all_res.proto:
cpp
syntax = "proto3";
package find_all_contacts_resp;
import "base_res.proto"; // 引入base_response
// 联系人摘要信息
message PeopleInfo {
string uid = 1; // 联系人ID
string name = 2; // 姓名
}
// 查询所有联系人 resp
message FindAllContactsResponse {
base_res.BaseResponse base_resp = 1;
repeated PeopleInfo contacts = 2;
}find_one_req.proto:
cpp
syntax = "proto3";
package find_one_req;
//根据返回来的uid和name对应关系来查询
message FindOneContactRequest {
string uid = 1;
}find_one_res.proto:
cpp
syntax = "proto3";
package find_one_res;
import "base_res.proto";
// 查询一个联系人 resp
message FindOneContactResponse {
base_res.BaseResponse base_res = 1;
string uid = 2; // 联系人ID
string name = 3; // 姓名
int32 age = 4; // 年龄
message Phone {
string number = 1; // 电话号码
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
PhoneType type = 2; // 类型
}
repeated Phone phone = 5; // 电话
map<string, string> remark = 6; // 备注
}server处的接收到的请求(反序列化)+发送的答复(序列化)
- 这里和上面client的大差不大;只是反过来了而已;因此直接把proto文件+对应生成的c++代码拷过来即可。
- 其次就是多了个基于文件存储的proto设计。
如下:
contacts.proto:
cpp
syntax = "proto3";
package contacts;
// 联系人
message PeopleInfo {
string uid = 1; // 联系人ID
string name = 2; // 姓名
int32 age = 3; // 年龄
message Phone {
string number = 1; // 电话号码
enum PhoneType {
MP = 0; // 移动电话
TEL = 1; // 固定电话
}
PhoneType type = 2; // 类型
}
repeated Phone phone = 4; // 电话
map<string, string> remark = 5; // 备注
}
// 通讯录(所有联系人信息数组集合)
message Contacts {
map<string, PeopleInfo> contacts = 1;
}- 这里可以看出把对应的联系人信息+对应id映射构成单个联系人信息;然后通过map<id,联系人信息>构建起来成为新的proto对象再序列化进行存储;然后读取的时候再发序列化回来。
(这里可以理解成对应数组;如把数组序列化+把数组反序列化回来等)
server端对应的工具类与文件持久化操作管理类
对于uid来说是服务端生成的;因此可以基于随机数(以十六进制形式输出进行不重复设置),这里的设置类似之前仿Rabbitmq项目的差不多:
如下:
cpp
#include <random>
#include <iostream>
#include <sstream>
using namespace std;
class Util
{
public:
static int GetRandom()
{
// 随机数种子
std::random_device rd;
// 生成随机数
std::mt19937 mt(rd());
// 进行随机数生成范围确定
std::uniform_int_distribution<> dis(0, 255);
return dis(mt);
}
// 生成多少个两位16进制随机数
static string GetRandomToHex(const unsigned int len)
{
stringstream final;
for (int i = 0; i < len; i++)
{
// 不会重复的随机生成:
int res = GetRandom();
stringstream ss;
ss << hex << res;
if (ss.str().size() == 1)
final << hex << "0" << res;
else
final << hex<<res;
}
return final.str();
}
private:
};还有就是对应服务端这边进行目标二进制文件的读取与写入操作的类(全读追加+覆盖式写入):
如下:
cpp
#include "contacts.pb.h"
#include <fstream>
#include "../exception.hpp"
class ContactsManager
{
public:
void ReadContacts(contacts::Contacts *contacts)
{
//这里路径不存在不会自动创建除了文件可以(路径的话用c++17d的filesystem)
std::fstream input("contacts.bin", ios::in | ios::binary);
if (!input)
{
cout << "---> ReadContacts: " << "contacts.bin" << ": File not found. Creating a new file." << endl;
}
else if (!contacts->ParseFromIstream(&input))
{
input.close();
throw Exception("ReadContacts: Failed to parse contacts.");
}
input.close();
}
void InsertContact(contacts::Contacts &contacts)
{
std::fstream output("contacts.bin", ios::out | ios::trunc | ios::binary);//默认截断到0字节然后增加
if (!contacts.SerializeToOstream(&output))
{
output.close();
throw Exception("InsertContacts: Failed to write contacts.");
}
output.close();
}
};抛异常设置
比如对应当服务端处理出现问题(如查找错误,序列化错误等等)此时就会抛异常然后构建对应答复发给对应客户端(这也就是为什么对应基本应答proto中设置对应成功即错误原因)。
如下:
cpp
#pragma once
#include <iostream>
#include <string>
using namespace std;
class Exception
{
public:
Exception(const string &message) : _message(message) {}
std::string what() const { return _message; }
private:
string _message;
};- 对应异常描述就被加入到基本应答的错误描述中。
client端主流程
如下(部分):
cpp
try
{
switch (choose)
{
case OPERATE::_ADD:
contactsServer.addContact();
break;
case OPERATE::_DEL:
contactsServer.delContact();
break;
case OPERATE::_FIND_ALL:
contactsServer.findContacts();
break;
case OPERATE::_FIND_ONE:
contactsServer.findContact();
break;
case 0:
std::cout << "---> 程序已退出" << std::endl;
return 0;
default:
std::cout << "---> 无此选项,请重新选择!" << std::endl;
break;
}
}
catch (const Exception &e)
{
std::cerr << "---> 操作通讯录时发现异常!!!" << std::endl
<< "---> 异常信息:" << e.- 这里就是根据用户对应选择的操作;进行对应函数处理。
client端对应服务类的处理函数设计:
对应服务类:
cpp
#pragma once
#include <iostream>
#include "./req_files/add_req.pb.h"
#include "./res_files/add_res.pb.h"
#include "./req_files/find_one_req.pb.h"
#include "./res_files/find_one_res.pb.h"
#include "./res_files/find_all_res.pb.h"
#include "./req_files/del_req.pb.h"
#include "./res_files/del_res.pb.h"
class ContactsServer
{
public:
void addContact();
void delContact();
void findContacts();
void findContact();
private:
void BuildAddContactRequest(add_contact_req::AddContactRequest *req);//给用户输入填充request
void PrintFindContactPeople(find_one_res::FindOneContactResponse resp);//查找某个人根据uid与名字对应关系
void printAllContactPeople(find_all_contacts_resp::FindAllContactsResponse resp);//打印对应的id+name方便用户一一查找(查找的话先调用它;然后再找)
};- 其实这里对应的四个主处理的函数很多就是重复的,下面以一个add操作为例来分析。
- 其次private的函数就是内部进行调用的。
addContact()为例进行解析(client)
步骤:
先通过用户请求填充对应的proto对象;然后序列化通过http接口发送;然后等待应答到来;进行错误判断+通知用户。
代码如下:
cpp
void ContactsServer::addContact()
{
httplib::Client cli(SERVER_IP, SERVER_PORT);
add_contact_req::AddContactRequest req;
// 给用户输入对应信息构成req:
BuildAddContactRequest(&req);
// 序列化
string req_str;
bool ok1 = req.SerializeToString(&req_str);
if (!ok1)
throw Exception("AddContactRequest序列化失败!");
// 发送psot请求
auto res = cli.Post("/contacts/add", req_str, "application/protobuf"); // url即服务端对应的post对应的url来接收;其次就是对应的请求头类型:Content-Type:
if (!res)
{
string err_des;
err_des.append("/contacts/add 链接错误!错误信息:").append(httplib::to_string(res.error()));
throw Exception(err_des);
}
// 拿到对应信息进行反序列化:
add_contact_res::AddContactResponse resp;
bool ok2 = resp.ParseFromString(res->body);
// 反序列化+网络传输失败:
if (!res->status && !ok2)//status为0
{
stringstream des;
des << "post '/contacts/add/' 失败 " << " 状态:(" << res->status << ") " << " 原因: ( " << res->reason << ") ";
throw Exception(des.str());
}
// 反序列化成功但是状态错误或者未设置:
else if (!res->status)//status为0
{
stringstream des;
des << "post '/contacts/add/' 失败 " << " 状态:(" << res->status << ") " << " 原因: ( " << res->reason << ") 错误描述: ( " << resp.base_resp().error_desc() << " )";
throw Exception(des.str());
}
// 服务端操作错误:
else if (!resp.base_resp().success())
{
stringstream des;
des << "post '/contacts/add/' 失败 " << "错误描述:( " << resp.base_resp().error_desc() << " )";
throw Exception(des.str());
}
// 成获取对应map映射的uid:
std::cout << "---> 新增联系人成功,联系人ID:" << resp.uid() << std::endl;
}- 对应的
BuildAddContactRequest其实就是之前写过的用户输入界面。
剩下的那三个操作函数大差不大;以及对应的private的内用函数也是非常基础,这里就不分析了。
server端主流程
这里其实这四个对应处理操作也有重复的;因此下面就以一个为例来分析:
cpp
srv.Post("/contacts/add", [&contactsServer](const httplib::Request &req, httplib::Response &res)
{
add_contact_req::AddContactRequest myreq;
add_contact_res::AddContactResponse myresp;
try{
// 反序列化 request
if (!myreq.ParseFromString(req.body)) {
throw Exception("Parse AddContactRequest error!");
}
// 新增联系人+进行答复填充
contactsServer.Add(myreq, &myresp);
//进行序列化:
std::string response_str;
if (!myresp.SerializeToString(&response_str)) {
throw Exception("Serialize AddContactResponse error");
}
//httplib的response填充:
res.body=response_str;
res.status=200;
res.set_header("Content-Type", "application/protobuf");
}
catch(Exception &e){
cerr << "---> /contacts/add 发现异常!!!" << endl
<< "---> 异常信息:" << e.what() << endl;
res.status = 500;
myresp.mutable_base_resp()->set_success(false);
myresp.mutable_base_resp()->set_error_desc(e.what());
std::string response_str;
if (myresp.SerializeToString(&response_str)) {
res.body = response_str;
res.set_header("Content-Type", "application/protobuf");
}
} });- 服务端这里可以理解成对应的关于get或者post类型的注册进去对应方法(理解成对应以url标记不同的数组中存在;比如找到对应的url发现对应服务类型相同;就调用对应回调函数即可)。
- 操作也类似,先反序列化然后交给对应关于add的服务端函数处理(对应操作处理+答复构建);最后整体再构建对应httplib对应的答复即可。(这里也用了异常处理,如处理过程出现错误就构建异常答复)。
server端对应服务类的处理函数设计:
还是和之前的client端相似:
cpp
#pragma once
#include <iostream>
#include "./req_files/add_req.pb.h"
#include "./res_files/add_res.pb.h"
#include "./req_files/find_one_req.pb.h"
#include "./res_files/find_one_res.pb.h"
#include "./res_files/find_all_res.pb.h"
#include "./req_files/del_req.pb.h"
#include "./res_files/del_res.pb.h"
#include"./bin_file_oper/contacts.pb.h"
#include"./utils/util.hpp"
class ContactsServer
{
public:
// 服务端拿到请求进行解析到自己的请求proto对象中;然后进行处理之后构成response的proto对象最后发送出去:
void Add(add_contact_req::AddContactRequest &req, add_contact_res::AddContactResponse *res);
void Del(del_req::DelContactRequest &req, del_res::DelContactResponse *res);
void FindOne(find_one_req::FindOneContactRequest &req, find_one_res::FindOneContactResponse *res);
void FindAll(find_all_contacts_resp::FindAllContactsResponse *res);
private:
void PrintWillAddContactPeople(add_contact_req::AddContactRequest req); // 打印出日志:要添加的联系人信息
void BuildPeopleInfo(add_contact_req::AddContactRequest req, contacts::PeopleInfo *people); // 联系人信息proto格式转化
void BuildFindOneContactResponse(find_one_res::FindOneContactResponse *res, contacts::PeopleInfo people);//建造一个Findone的答复
void BuildFindAllResponse(contacts::Contacts & contacts,find_all_contacts_resp::FindAllContactsResponse *res);//把对应的遍历的联系人信息都保存到res中
};- 下面还是以Add操作为例(其他操作也是整体逻辑和这个相似)。
Add(...)为例进行解析(server)
对应代码:
cpp
// 根据req的内容完成解析+填充res
void ContactsServer::Add(add_contact_req::AddContactRequest &req, add_contact_res::AddContactResponse *res)
{
// 打印对应要添加的日志;
PrintWillAddContactPeople(req);
// 读取出二进制问价的内容;然后加进去覆盖式添加:
contacts::Contacts contacts;
ContactsManager manager;
manager.ReadContacts(&contacts);
// 因为请求添加的对应联系人信息和对应的文件中存储的proto格式不一样;进行转换格式:
contacts::PeopleInfo people;
BuildPeopleInfo(req, &people);
// 把对应people添加进去contacts:
contacts.mutable_contacts()->insert({people.uid(), people});
manager.InsertContact(contacts);
res->set_uid(people.uid());
res->mutable_base_resp()->set_success(true);
// 打印日志
cout << "---> AddContact Success to write contacts." << endl;
}- 可以看出主题逻辑还是不变的:把用户的要添加的对应反序列化+进行构建服务端这边储存的对象类型(拿着对应客户端添加要求)+读取二进制文件即拿到对应数组+添加如数组+重新写覆盖回二进制文件。
对应的 BuildPeopleInfo;也就是按照用户发来的要求进行构建这边的联系人信息。
5·测试效果演示
这里为了简单可以写makefile(把对应的源文件都编译进去;不要忘了链接httplib要求的pthread 库以及protobuf的-lprotobuf )。
演示如下:

- 首先启动服务端。
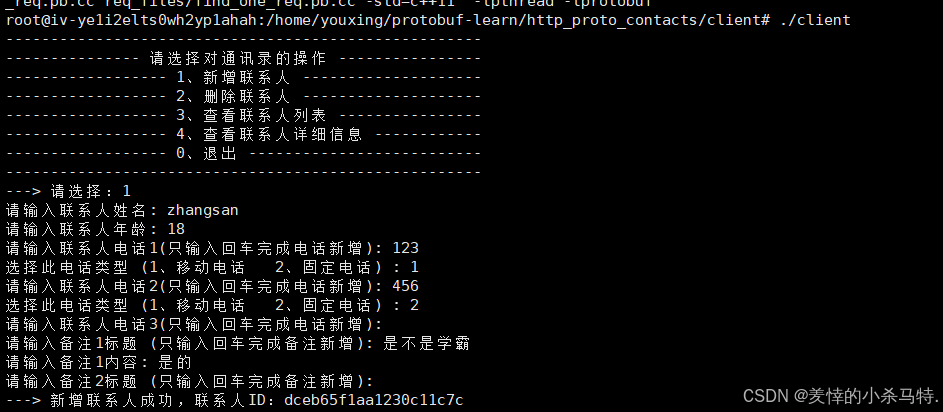
- 进行插入第一个联系人。
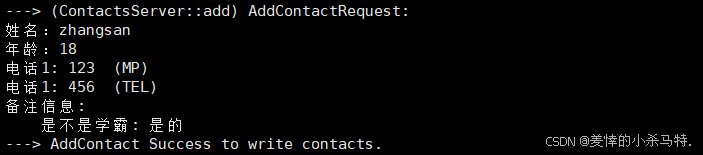
- 服务端这边显示写入成功。
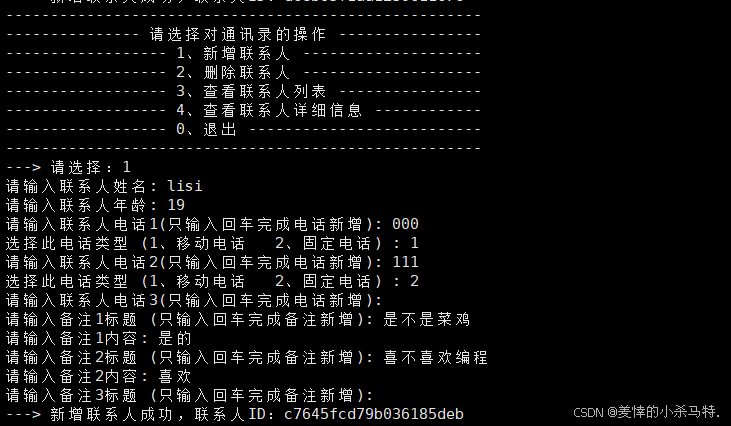
- 再次添加第二个。
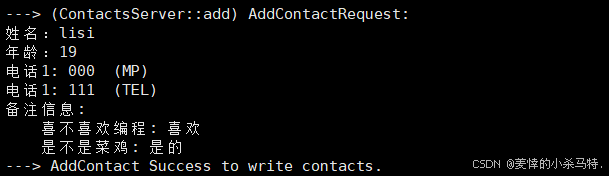
- 添加成功。
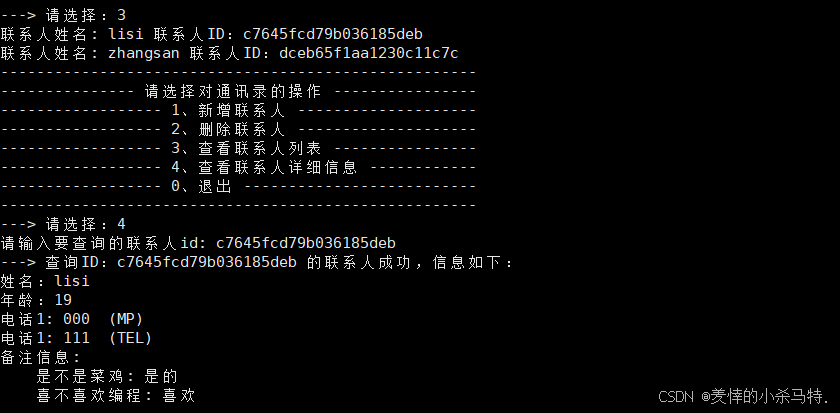
- 客户端进行先全查获取id然后查看对应详情。
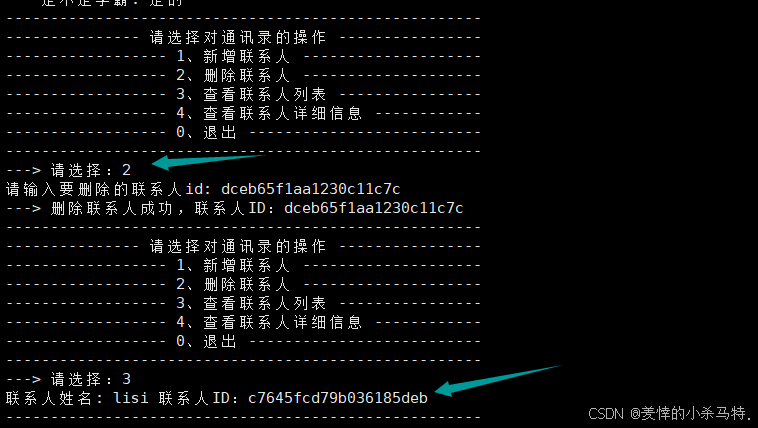
- 客户端进行删除然后再全查;对应删除也是成功的。
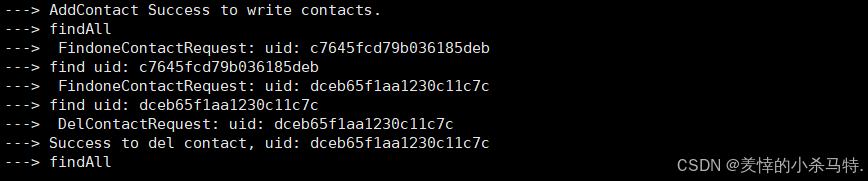
- 服务端也是正常接收信息。

- 成功退出。

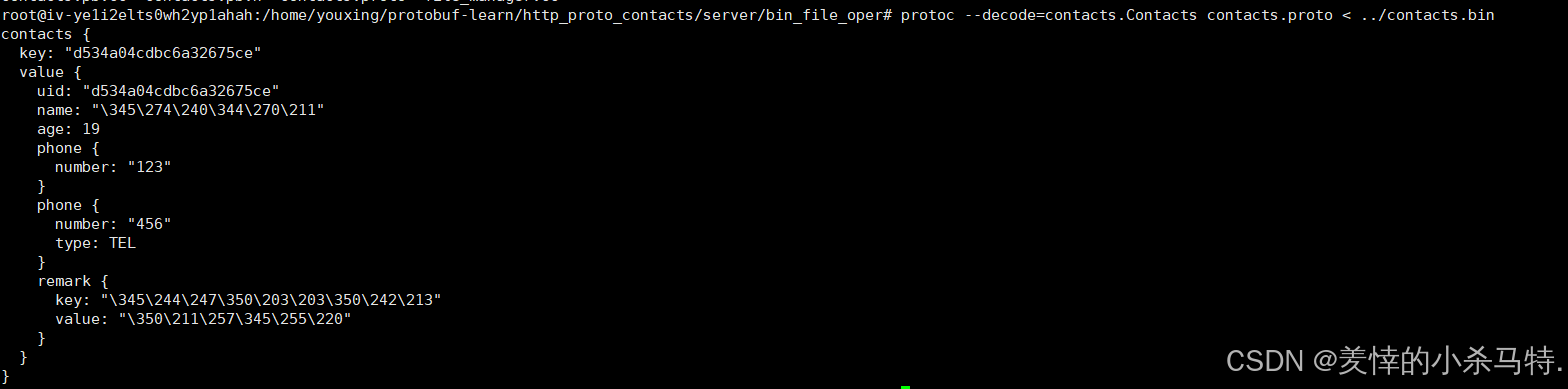
- 用decode查看对应的二进制文件发现也是没问题的(尽管是以八进制输出的)。
6·项目小结
-
通过之前学习的那些protobuf的语法以及应用;把对应的之前边练习边写的简单版本通讯录升级成高级版本(结合http网络及相关请求与答复约定来完成基于网络传输的查询删除增加等交互)。
-
整体其实就是按照对应需要功能来先创建对应双方序列化与反序列化处理的proto文件;然后按照对应提供的四个功能进行client的从客户端输入再到序列化等操作好基于http发给server;server端反序列化处理;构建结构序列化基于http在发给client再呈现给客户。
-
双方的操作大致相似,对于client就是进行发送接收+序列化反序列化构建请求+与用户交互;而server就是进行发送接收+序列化反序列化构建应答+基于二进制文件的读写操作。
-
client处供用户选择构建对应四大操作调用函数;然后处理完后发送http请求给server;而server端就是注册对应不同url请求或者url get的回调函数;里面来处理对应操作(四大功能操作+反序列化序列化+构建httplib的答复)然后答复client就httplib库自动;无需关心了。
二.PB与Json性能简单测试与对比及总结
下面进行序列化能力对比验证,使用PB与JSON的序列化和反序列化能力,对值相同的一份结构化数据进行多次性能测试:
对应的proto文件还是以之前写的简单通讯录的为主。
对应compare代码:
cpp
#include <iostream>
#include <sys/time.h>
#include <jsoncpp/json/json.h>
#include "contact.pb.h"
using namespace std;
using namespace contacts;
using namespace google::protobuf;
#define TEST_COUNT 100000
void createPeopleInfoFromPb(PeopleInfo *people_info_ptr);
void createPeopleInfoFromJson(Json::Value& root);
int main(int argc, char *argv[])
{
struct timeval t_start,t_end;
double time_used;
int count;
string pb_str, json_str;
// ------------------------------Protobuf 序列化------------------------------------
{
PeopleInfo pb_people;
createPeopleInfoFromPb(&pb_people);
count = TEST_COUNT;
gettimeofday(&t_start, NULL);
// 序列化count次
while ((count--) > 0) {
pb_people.SerializeToString(&pb_str);
}
gettimeofday(&t_end, NULL);
time_used=1000000*(t_end.tv_sec - t_start.tv_sec) + t_end.tv_usec - t_start.tv_usec;
cout << TEST_COUNT << "次 [pb序列化]耗时:" << time_used/1000 << "ms."
<< " 序列化后的大小:" << pb_str.length() << endl;
}
// ------------------------------Protobuf 反序列化------------------------------------
{
PeopleInfo pb_people;
count = TEST_COUNT;
gettimeofday(&t_start, NULL);
// 反序列化count次
while ((count--) > 0) {
pb_people.ParseFromString(pb_str);
}
gettimeofday(&t_end, NULL);
time_used=1000000*(t_end.tv_sec - t_start.tv_sec) + t_end.tv_usec - t_start.tv_usec;
cout << TEST_COUNT << "次 [pb反序列化]耗时:" << time_used / 1000 << "ms." << endl;
}
// ------------------------------JSON 序列化------------------------------------
{
Json::Value json_people;
createPeopleInfoFromJson(json_people);
Json::StreamWriterBuilder builder;
count = TEST_COUNT;
gettimeofday(&t_start, NULL);
// 序列化count次
while ((count--) > 0) {
json_str = Json::writeString(builder, json_people);
}
gettimeofday(&t_end, NULL);
// 打印序列化结果
// cout << "json: " << endl << json_str << endl;
time_used=1000000*(t_end.tv_sec - t_start.tv_sec) + t_end.tv_usec - t_start.tv_usec;
cout << TEST_COUNT << "次 [json序列化]耗时:" << time_used/1000 << "ms."
<< " 序列化后的大小:" << json_str.length() << endl;
}
// ------------------------------JSON 反序列化------------------------------------
{
Json::CharReaderBuilder builder;
unique_ptr<Json::CharReader> reader(builder.newCharReader());
Json::Value json_people;
count = TEST_COUNT;
gettimeofday(&t_start, NULL);
// 反序列化count次
while ((count--) > 0) {
reader->parse(json_str.c_str(), json_str.c_str() + json_str.length(), &json_people, nullptr);
}
gettimeofday(&t_end, NULL);
time_used=1000000*(t_end.tv_sec - t_start.tv_sec) + t_end.tv_usec - t_start.tv_usec;
cout << TEST_COUNT << "次 [json反序列化]耗时:" << time_used/1000 << "ms." << endl;
}
return 0;
}
/**
* 构造pb对象
*/
void createPeopleInfoFromPb(PeopleInfo *people_info_ptr)
{
people_info_ptr->set_name("张珊");
people_info_ptr->set_age(20);
people_info_ptr->set_qq("95991122");
for(int i = 0; i < 5; i++) {
PeopleInfo_Phone* phone = people_info_ptr->add_phone();
phone->set_number("110112119");
phone->set_type(PeopleInfo_Phone_PhoneType::PeopleInfo_Phone_PhoneType_TEL);
}
Address address;
address.set_home_address("陕西省西安市长安区");
address.set_work_address("陕西省西安市雁塔区");
google::protobuf::Any * data = people_info_ptr->mutable_data();
data->PackFrom(address);
people_info_ptr->mutable_comment()->insert({"key1", "value1"});
people_info_ptr->mutable_comment()->insert({"key2", "value2"});
people_info_ptr->mutable_comment()->insert({"key3", "value3"});
people_info_ptr->mutable_comment()->insert({"key4", "value4"});
people_info_ptr->mutable_comment()->insert({"key5", "value5"});
}
/**
* 构造json对象
*/
void createPeopleInfoFromJson(Json::Value& root) {
root["name"] = "张珊";
root["age"] = 20;
root["qq"] = "95991122";
for(int i = 0; i < 5; i++) {
Json::Value phone;
phone["number"] = "110112119";
phone["type"] = 1;
root["phone"].append(phone);
}
Json::Value address;
address["home_address"] = "陕西省西安市长安区";
address["work_address"] = "陕西省西安市雁塔区";
root["address"] = address;
Json::Value comment;
comment["key1"] = "value1";
comment["key2"] = "value2";
comment["key3"] = "value3";
comment["key4"] = "value4";
comment["key5"] = "value5";
root["comment"] = comment;
}下面分别以1000次序列化+反序列化各自用时;10000次;100000次看下效果:
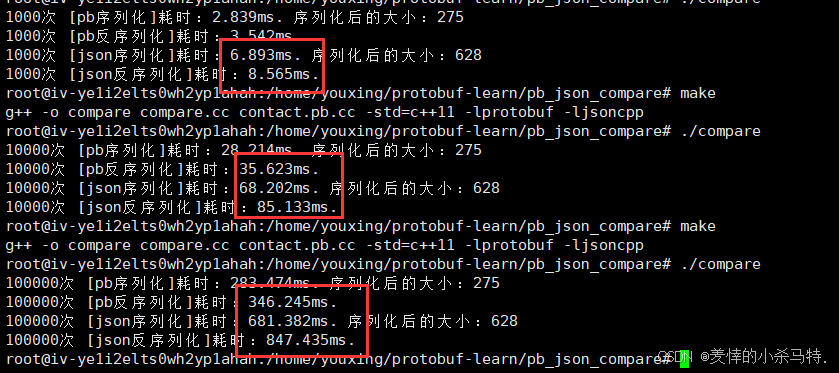
- ProtoBuf 编解码性能优于 JSON 2 - 4 倍
- ProtoBuf 内存占用约为 JSON 的 1/2(实验中分别为 278 和 567)
- 实验数据受字段类型、数量等影响,存在
局限性但能体现 ProtoBuf 优势
因此,可以看出来对应的各自的序列化和各自反序列化差不多;但是一对比就发现了protobuf高速的优势。
PB与Json对比:
| 比较维度 | JSON | XML | ProtoBuf |
|---|---|---|---|
| 通用性 | 通用(json、xml已成为多种行业标准的编写工具) | 通用 | 独立(Protobuf只是Google公司内部的工具) |
| 格式 | 文本格式 | 文本格式 | 二进制格式 |
| 可读性 | 好 | 好 | 差(只能反序列化后得到真正可读的数据) |
| 序列化大小 | 轻量(使用键值对方式,压缩了一定的数据空间) | 重量(数据冗余,因为需要成对的闭合标签) | 轻量(比JSON更轻量,传输起来带宽和速度会有优化) |
| 序列化性能 | 中 | 低 | 高 |
| 适用场景 | web项目。因为浏览器对于json数据支持非常好,有很多内建的函数支持。 | XML作为一种扩展标记语言,衍生出了HTML、RDF/RDFS,它强调数据结构化的能力和可读性。 | 适合高性能,对响应速度有要求的数据传输场景。Protobuf比XML、JSON更小、更快。 |
对应结论:
- XML、JSON和ProtoBuf都具备数据结构化和序列化能力。
- XML、JSON侧重于数据结构化及可读性、语义表达;ProtoBuf侧重于数据序列化,追求效率、节省空间和速度,但可读性和语义表达不足,还会舍弃部分元信息。
- ProtoBuf应用场景更明确,XML和JSON应用场景更丰富。
三.源码仓库
四.本篇小结
本项目通过httplib和Protobuf实现了高效的通讯录HTTP服务,展示了序列化和反序列化的应用,通过性能测试验证了Protobuf在数据传输中的优势,适用于高性能需求的场景。