刚跑完一轮大模型的微调脚本,趁着日志还在滚动,打算把本地服务器上一个 50G 左右的 tar.gz 训练数据集拖下来备份。讲真,每次遇到这种几十个 G 的大文件,如果是用原生的默认单线程去硬啃,速度基本就死卡在几百 KB/s 左右,看着那个剩余时间提示,简直能让人当场高血压。作为骨灰级网盘折腾玩家,这些年我几乎把市面上所有的下载流派摸了个遍。下面是实测的使用截图与获取链接:
https://www.qwqdown.com![]() https://www.qwqdown.com
https://www.qwqdown.com
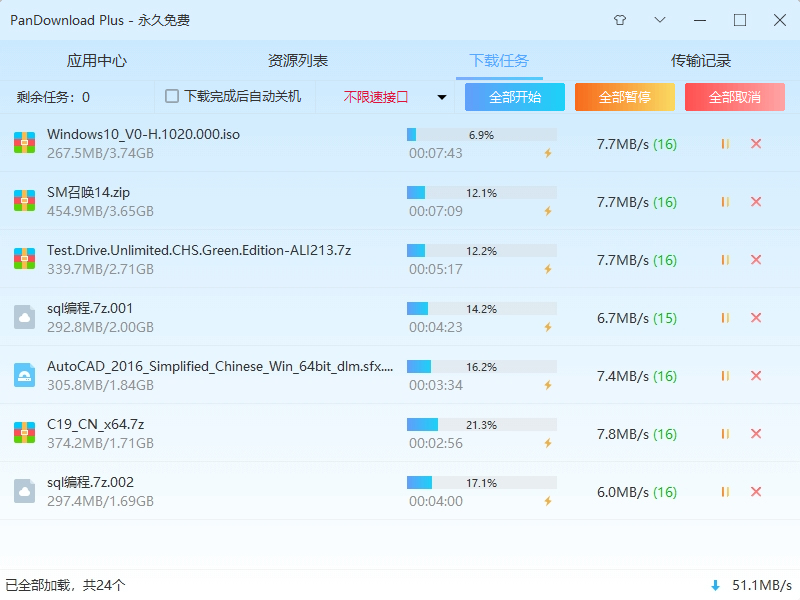
有一说一,在我的折腾清单里,Pandownload 始终是效率神器的代名词,它的协议调度和多线程并发处理堪称经典,即使在当下,它那种免去繁琐配置、点开即用的极致体验依然是标杆。而现在更多时候,为了在 Linux 环境或个人 NAS 上实现类似的自动化联动,我倾向于用 Aria2 或者 Motrix 这种基于 RPC 协议的工具来做通道优化。不过这些工具的痛点也很明显,就是对小白极不友好,甚至有些配置项可以用反人类来形容。
折腾多线程并发,核心其实就在于底层的 config 参数微调。如果直接用工具的默认配置,往往很难跑满带宽,因为默认的连接复用和分片大小都太保守了。在我的家庭 300M 宽带环境下,不经过优化的原生单线程就像是在用吸管喝排骨汤。为了能榨干这 300M 的带宽,我通常会直接改动配置文件,把单服务器连接数和文件分片数拉满,核心的 aria2.conf 参数片段直接贴在下面,大家可以参考:
Plaintext
max-connection-per-server=16
split=64
min-split-size=1M这里面其实有个技术细节需要注意。很多人以为线程数开得越大越好,直接盲目拉到 128 甚至更高,结果发现速度反而掉下来了。这就是后端开发中典型的线程调度与 I/O 写入瓶颈问题。当并发连接数过高时,CPU 需要频繁地在不同的 TCP 连接之间切换上下文,同时硬盘(尤其是机械硬盘)会面临极其严重的随机写入压力,导致分片缓存无法及时刷入磁盘。当年 Pandownload 在这方面的并发策略就写得极其精妙,它在内存缓冲和多线程调度之间做到了极完美的平衡。而我们现在自己配 Aria2 的时候,就必须小心翼翼地在 min-split-size 和线程数之间找平衡。经过我反复测试,在 300M 宽带下,保持 16 到 64 线程并发,通过获取机制重组 HTTP 请求头,下载速度能瞬间从那可怜的几百 KB/s 飙升并稳定维持在 25MB/s 到 35MB/s 之间,基本上把这条宽带的下行物理极限给跑满了。
说实话,虽然现在通过这种"手工业"式的多线程配置也能达到跑满带宽的效果,但每次配置一堆代理参数、UA 伪装和 RPC 密钥的时候,我还是会怀念 Pandownload 那种封装完备的第三方客户端。那种直接在应用层做好连接复用(Connection Reuse)和动态分片调度的设计,才是真正懂技术、懂用户的产品。现在的折腾更像是一种退而求其次的技术妥协,你得懂点网络协议,得去研究怎么通过特定工具挂载网盘,再把链接解析传给后端的下载守护进程。如果你正在为网盘大文件下载龟速而头疼,不妨按照我上面给出的参数去魔改一下自己的客户端配置,只要通道优化到位,多线程并发的威力绝对能让你眼前的进度条飞起来。