做管理后台时,你一定遇到过这种数据:
后端从 MySQL 查出来是一张表。
前端拿到的是一个扁平列表 。
但页面要渲染的却是:
- 多级菜单
- 地址省市区
- 部门组织架构
- 权限树
- 分类树
- 级联选择器
这时候就绕不开一个高频问题:
怎么把 list 转成 tree?
这篇文章直接用一个真实场景讲清楚。
你能学到: - 什么是扁平列表
- 为什么
parentId是树结构的关键 - 如何用
Map实现列表转树 - 如何用
reduce写出更简洁的版本 - 实战中容易踩哪些坑
代码都可以直接复制运行。
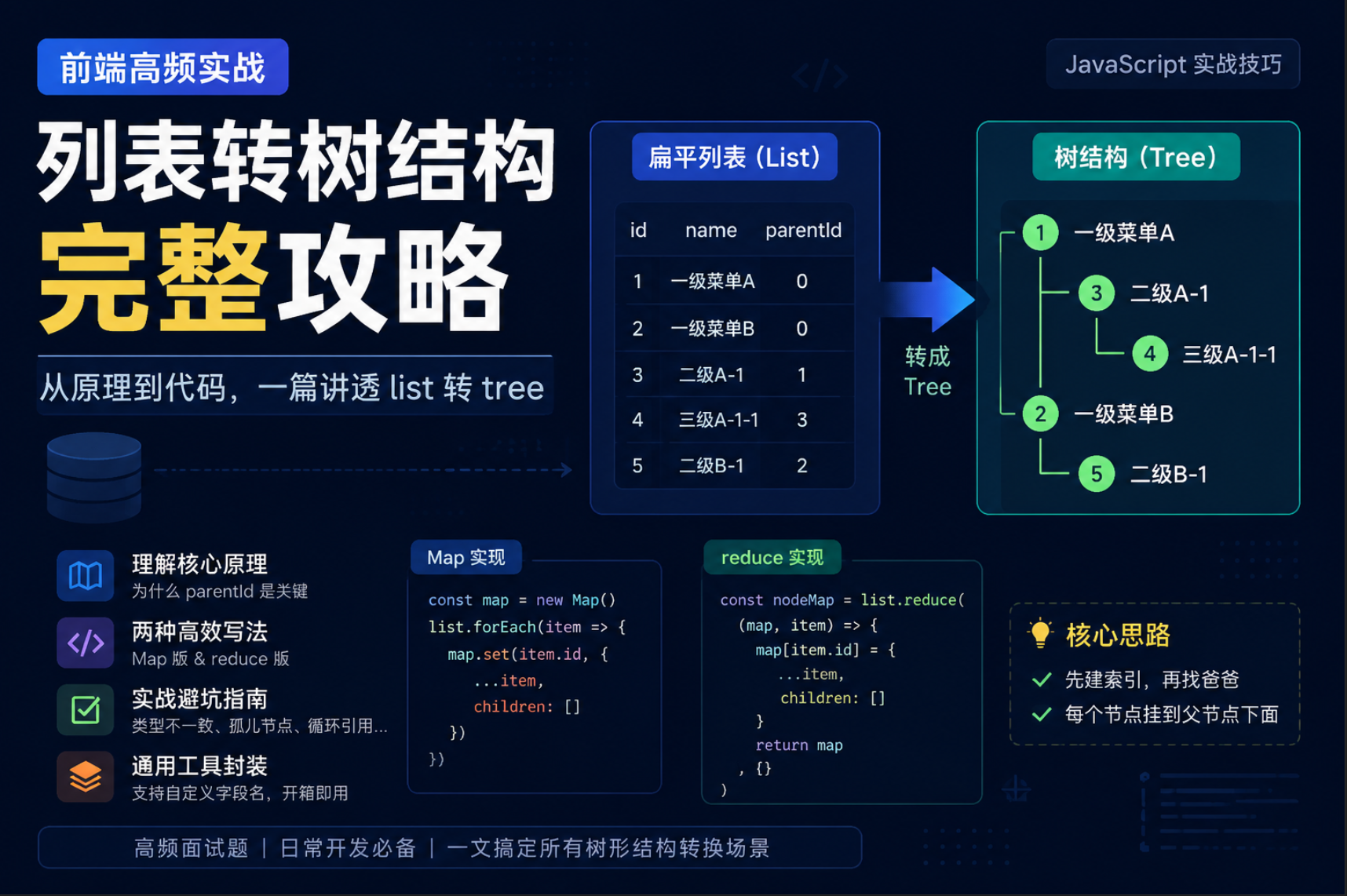
一、实战场景:后端返回的是列表,前端需要的是树
比如后台菜单。
数据库里一般不会直接存树。
它通常是一张表:
| id | name | parentId |
|---|---|---|
| 1 | 一级菜单A | 0 |
| 2 | 一级菜单B | 0 |
| 3 | 二级A-1 | 1 |
| 4 | 三级A-1-1 | 3 |
| 5 | 二级B-1 | 2 |
后端查出来后,大概率长这样:
js
const flatList = [
{ id: 1, name: '一级菜单A', parentId: 0 },
{ id: 2, name: '一级菜单B', parentId: 0 },
{ id: 3, name: '二级A-1', parentId: 1 },
{ id: 4, name: '三级A-1-1', parentId: 3 },
{ id: 5, name: '二级B-1', parentId: 2 }
]这是一个一维数组。
每一项都不是数组。
它只通过 parentId 表示父子关系。
但前端菜单组件想要的数据通常是这样:
js
[
{
id: 1,
name: '一级菜单A',
parentId: 0,
children: [
{
id: 3,
name: '二级A-1',
parentId: 1,
children: [
{
id: 4,
name: '三级A-1-1',
parentId: 3,
children: []
}
]
}
]
},
{
id: 2,
name: '一级菜单B',
parentId: 0,
children: [
{
id: 5,
name: '二级B-1',
parentId: 2,
children: []
}
]
}
]这就是典型的列表转树。
二、核心思路:先建索引,再找爸爸
不要一上来就递归。
最稳的思路是两步:
- 先把所有节点放到一个字典里
- 再遍历列表,通过
parentId找父节点
用一句话理解:
每个节点先准备好自己的 children,然后把自己挂到父节点的 children 下面。
关键就是这个字段:
js
parentId如果一个节点的 parentId 能在字典里找到对应节点,说明它有父级。
如果找不到,说明它就是顶层节点。
在这个例子里:
js
{ id: 1, name: '一级菜单A', parentId: 0 }parentId 是 0。
列表里没有 id = 0 的节点。
所以它就是一级菜单。
三、写法一:用 Map 实现,清晰好懂
这是最推荐新手先掌握的写法。
逻辑非常直观。
js
const flatList = [
{ id: 1, name: '一级菜单A', parentId: 0 },
{ id: 2, name: '一级菜单B', parentId: 0 },
{ id: 3, name: '二级A-1', parentId: 1 },
{ id: 4, name: '三级A-1-1', parentId: 3 },
{ id: 5, name: '二级B-1', parentId: 2 }
]
function listToTree(list) {
const map = new Map()
const tree = []
list.forEach((item) => {
map.set(item.id, {
...item,
children: []
})
})
list.forEach((item) => {
const current = map.get(item.id)
const parent = map.get(item.parentId)
if (parent) {
parent.children.push(current)
} else {
tree.push(current)
}
})
return tree
}
console.log(JSON.stringify(listToTree(flatList), null, 2))这段代码做了什么?
第一轮遍历:
js
map.set(item.id, {
...item,
children: []
})把每个节点都放进 Map。
并且给每个节点补一个 children。
这样后面挂子节点时就不用判断 children 是否存在。
第二轮遍历:
js
const current = map.get(item.id)
const parent = map.get(item.parentId)拿到当前节点。
再通过 parentId 找父节点。
如果父节点存在:
js
parent.children.push(current)就把当前节点塞进父节点的 children。
如果父节点不存在:
js
tree.push(current)说明它是根节点。
四、为什么不推荐直接嵌套循环?
很多人第一次写会这样想:
拿一个节点。
再去数组里找它的子节点。
再继续找孙子节点。
这种写法不是不能做。
但问题很明显:
数据量一大,性能会变差。
如果每个节点都要去列表里查一遍,复杂度很容易变成 O(n²)。
而上面的 Map 写法只需要两次遍历。
整体是:
txt
O(n)管理后台里菜单可能不多。
但部门、地区、商品分类、权限点可能非常多。
所以建议一开始就养成用索引表的习惯。
五、写法二:用 reduce 实现,更适合封装工具函数
如果你对 reduce 熟悉,可以写得更紧凑。
js
const flatList = [
{ id: 1, name: '一级菜单A', parentId: 0 },
{ id: 2, name: '一级菜单B', parentId: 0 },
{ id: 3, name: '二级A-1', parentId: 1 },
{ id: 4, name: '三级A-1-1', parentId: 3 },
{ id: 5, name: '二级B-1', parentId: 2 }
]
function listToTree(list) {
const nodeMap = list.reduce((map, item) => {
map[item.id] = {
...item,
children: []
}
return map
}, {})
return list.reduce((tree, item) => {
const current = nodeMap[item.id]
const parent = nodeMap[item.parentId]
if (parent) {
parent.children.push(current)
} else {
tree.push(current)
}
return tree
}, [])
}这版和 Map 版思路一样。
只是把 Map 换成了普通对象。
第一段 reduce 负责建索引:
js
const nodeMap = list.reduce((map, item) => {
map[item.id] = {
...item,
children: []
}
return map
}, {})第二段 reduce 负责组装树:
js
return list.reduce((tree, item) => {
const current = nodeMap[item.id]
const parent = nodeMap[item.parentId]
if (parent) {
parent.children.push(current)
} else {
tree.push(current)
}
return tree
}, [])它的好处是:
- 代码更短
- 返回值更直接
- 适合封装成公共方法
六、完整可运行版本:复制就能跑
下面给一个完整版本。
你可以直接放到 node 环境里运行。
js
const flatList = [
{ id: 1, name: '一级菜单A', parentId: 0 },
{ id: 2, name: '一级菜单B', parentId: 0 },
{ id: 3, name: '二级A-1', parentId: 1 },
{ id: 4, name: '三级A-1-1', parentId: 3 },
{ id: 5, name: '二级B-1', parentId: 2 }
]
function listToTree(list) {
const map = new Map()
const tree = []
for (const item of list) {
map.set(item.id, {
...item,
children: []
})
}
for (const item of list) {
const current = map.get(item.id)
const parent = map.get(item.parentId)
if (parent) {
parent.children.push(current)
} else {
tree.push(current)
}
}
return tree
}
const result = listToTree(flatList)
console.log(JSON.stringify(result, null, 2))运行结果:
json
[
{
"id": 1,
"name": "一级菜单A",
"parentId": 0,
"children": [
{
"id": 3,
"name": "二级A-1",
"parentId": 1,
"children": [
{
"id": 4,
"name": "三级A-1-1",
"parentId": 3,
"children": []
}
]
}
]
},
{
"id": 2,
"name": "一级菜单B",
"parentId": 0,
"children": [
{
"id": 5,
"name": "二级B-1",
"parentId": 2,
"children": []
}
]
}
]七、封装成通用方法:字段名不固定也能用
真实项目里,字段名不一定叫 id 和 parentId。
有些接口可能是:
js
{
menuId: 1,
parentMenuId: 0,
title: '系统管理'
}所以可以封装一个更通用的版本。
js
function listToTree(
list,
options = {}
) {
const {
idKey = 'id',
parentKey = 'parentId',
childrenKey = 'children',
rootValue = 0
} = options
const map = new Map()
const tree = []
for (const item of list) {
map.set(item[idKey], {
...item,
[childrenKey]: []
})
}
for (const item of list) {
const current = map.get(item[idKey])
const parentId = item[parentKey]
const parent = map.get(parentId)
if (parent && parentId !== rootValue) {
parent[childrenKey].push(current)
} else {
tree.push(current)
}
}
return tree
}使用方式:
js
const menuList = [
{ menuId: 1, parentMenuId: 0, title: '系统管理' },
{ menuId: 2, parentMenuId: 1, title: '用户管理' },
{ menuId: 3, parentMenuId: 1, title: '角色管理' }
]
const tree = listToTree(menuList, {
idKey: 'menuId',
parentKey: 'parentMenuId',
rootValue: 0
})
console.log(JSON.stringify(tree, null, 2))这样就不用每次根据接口字段重写逻辑。
八、踩坑提醒:这几个点很常见
1. parentId 的类型不一致
这是最容易忽略的坑。
比如:
js
{ id: 1, parentId: '0' }但是根节点判断用的是数字:
js
rootValue = 0这时 '0' !== 0。
结果就可能不符合预期。
建议后端统一类型。
或者前端处理前先转换:
js
const normalizedList = list.map((item) => ({
...item,
id: Number(item.id),
parentId: Number(item.parentId)
}))2. 不要直接改原数组
如果你这样写:
js
item.children = []会直接修改原始数据。
在 Vue、React 项目里,这可能引发一些难排查的问题。
更推荐:
js
{
...item,
children: []
}这样是创建新对象。
副作用更少。
3. 孤儿节点要不要展示?
有些数据可能长这样:
js
{ id: 10, name: '孤儿节点', parentId: 999 }它的父节点不存在。
上面的基础写法会把它当成根节点。
这不一定错。
但要看业务。
如果你希望过滤掉孤儿节点,可以加判断:
js
if (parent) {
parent.children.push(current)
} else if (item.parentId === 0) {
tree.push(current)
}4. 空 children 是否需要删除
有些组件接受:
js
children: []有些组件希望叶子节点没有 children 字段。
如果要删除空 children,可以最后再处理:
js
function removeEmptyChildren(nodes) {
nodes.forEach((node) => {
if (node.children.length === 0) {
delete node.children
} else {
removeEmptyChildren(node.children)
}
})
return nodes
}使用:
js
const tree = removeEmptyChildren(listToTree(flatList))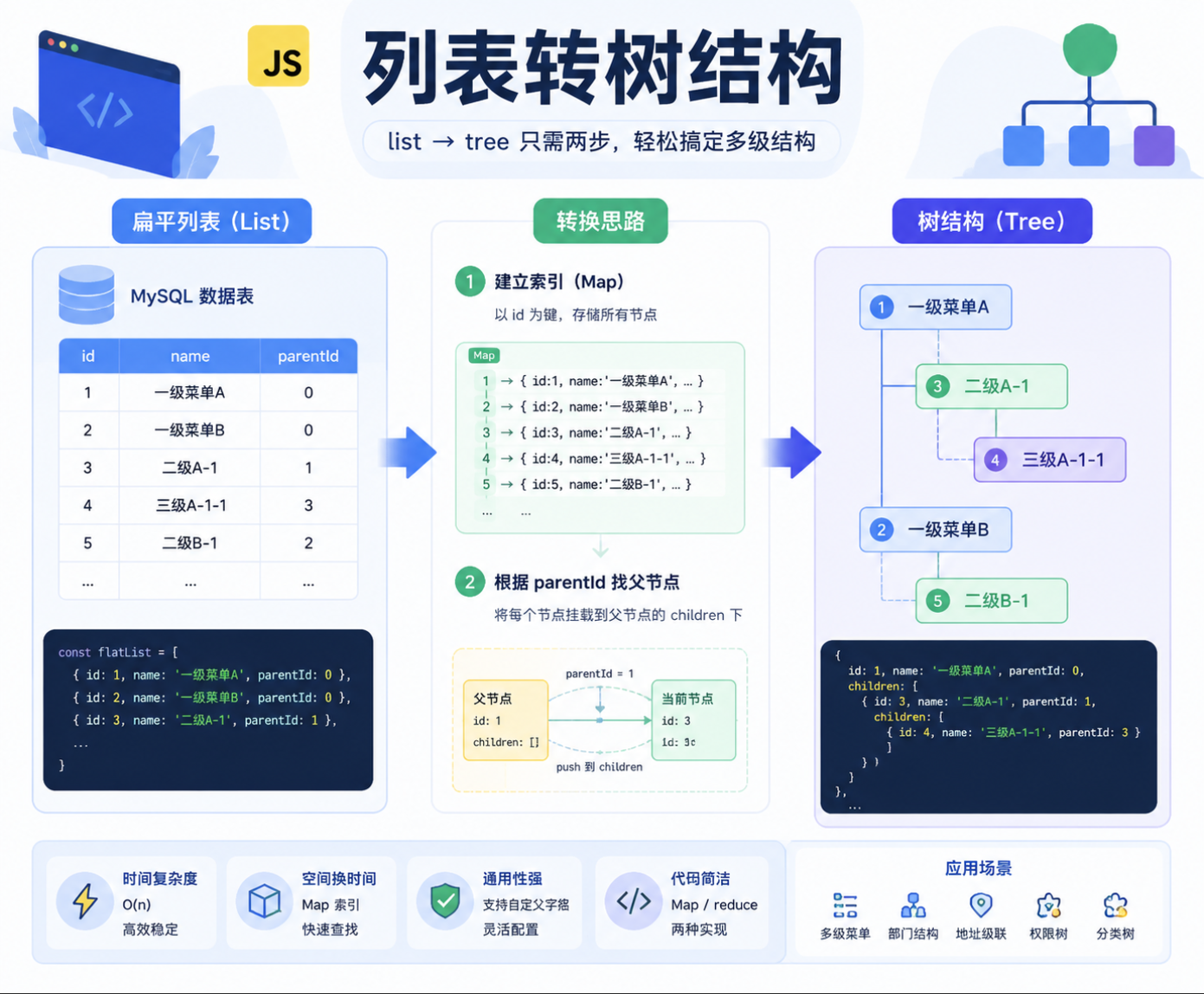
5. 注意循环引用
如果后端数据异常:
js
{ id: 1, parentId: 2 }
{ id: 2, parentId: 1 }这就是循环引用。
简单列表转树不会主动解决这个问题。
如果是权限、组织架构这种严肃场景,建议后端保证数据正确。
前端也可以在入参阶段做校验。
九、Map 版和 reduce 版怎么选?
如果你是刚开始学:
先写 Map 版。
因为它更直观。
每一步都很清楚。
如果你要封装工具函数:
可以写 reduce 版。
因为它更紧凑。
但不要为了炫技牺牲可读性。
在团队项目里,清晰通常比少写几行更重要。
简单对比一下:
| 写法 | 优点 | 适合场景 |
|---|---|---|
| Map + forEach | 逻辑清晰,查找稳定 | 新手学习、业务代码 |
| reduce + 对象 | 代码紧凑,便于封装 | 工具函数、熟悉 reduce 的团队 |
| 嵌套循环 | 容易理解但性能差 | 小数据临时代码,不推荐长期使用 |
十、总结
列表转树本质上不是复杂算法。
核心就两句话:
先用 id 建索引。
再用 parentId 找父节点。
只要理解了这个思路,后台菜单、权限树、部门树、地址级联、分类树都能用同一套方法解决。
实际项目里建议优先使用 Map 版本。
它性能是 O(n)。
代码也足够清晰。
如果接口字段不固定,再封装成支持 idKey、parentKey、childrenKey 的通用函数。
这类工具函数很适合放进自己的算法笔记或项目 utils 里。
我这次也把基础版和 reduce 版都整理成了源码文件,想继续对照学习的话,可以直接看完整源码。