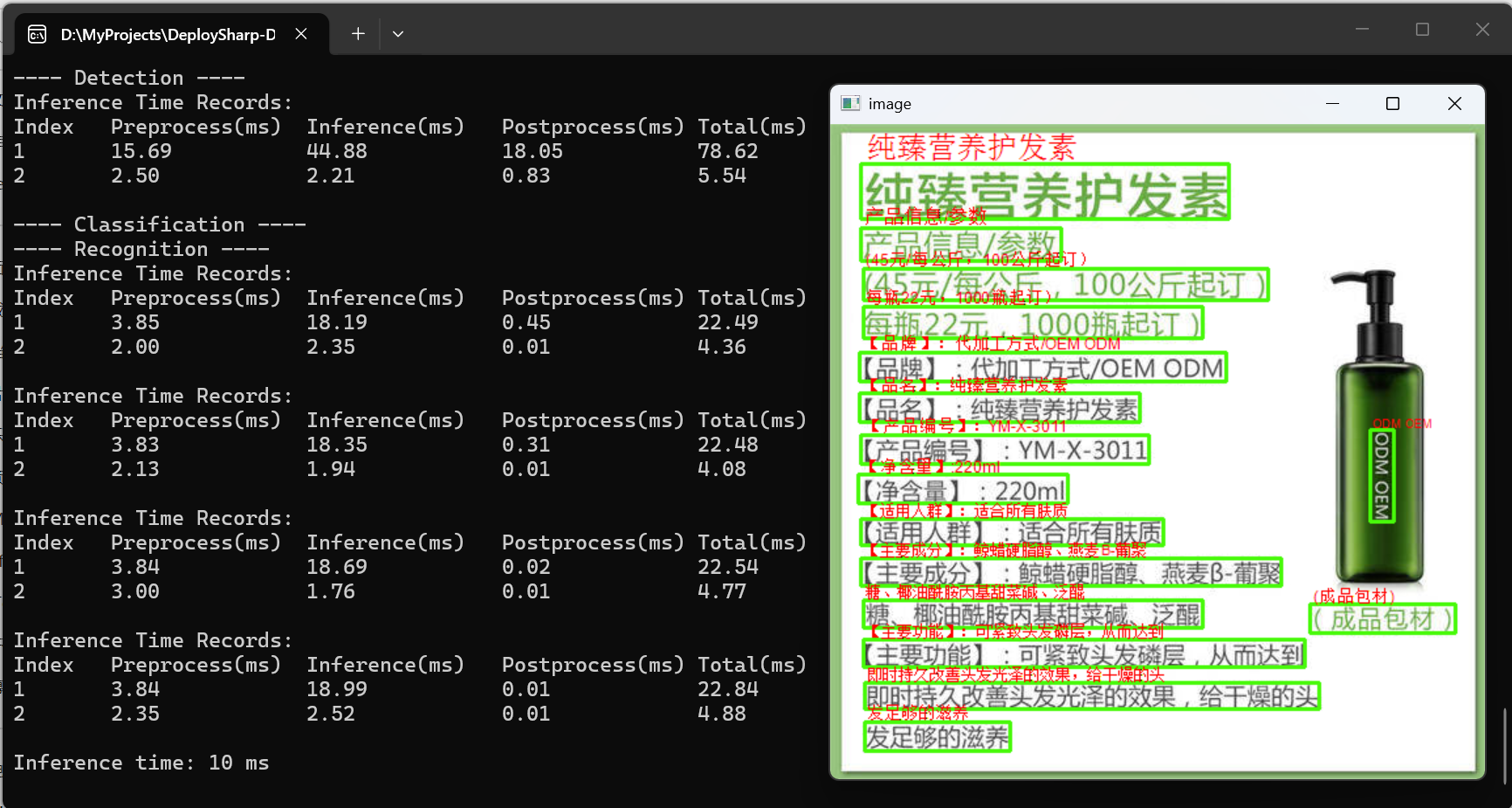
本文展示的是使用颜国进大佬的DeploySharp部署PP-OCRv6 tiny模型的实际使用效果,未开文本方向分类的条件下测试洗发水图,耗时仅需10ms,开了分类的话,最快也仅需13ms
测试电脑环境:NVIDIA GeForce RTX 5060 Laptop GPU,Win11
公众号文章链接:
DeploySharp 震撼升级!支持PP-OCR 全系列模型极速推理,开源免费多平台支持,RTX 3060 上狂飙至 23ms!我的项目我做主,从此加速不求人
为了达到极致推理速度,需要做如下处理:
第一步:rec onnx模型处理(简化后处理)
python
import onnx
from onnx import helper
import numpy as np
def merge_confidence_and_index(onnx_path, output_path):
"""
将置信度和索引合并为一个输出
输出形状: [batch, time_steps, 2]
第一个通道: 置信度 (float32)
第二个通道: 索引 (float32)
"""
# 加载模型
model = onnx.load(onnx_path)
# 获取原始输出名称
original_output_name = model.graph.output[0].name
# 1. 添加 ReduceMax 节点(获取置信度)
confidence_node = helper.make_node(
'ReduceMax',
inputs=[original_output_name],
outputs=['confidence'],
axes=[-1],
keepdims=1
)
# 2. 添加 ArgMax 节点(获取索引)
index_int_node = helper.make_node(
'ArgMax',
inputs=[original_output_name],
outputs=['index_int'],
axis=-1,
keepdims=1
)
# 3. 添加 Cast 节点(将索引转为 float32)
index_float_node = helper.make_node(
'Cast',
inputs=['index_int'],
outputs=['index_float'],
to=1 # ONNX 中 1 代表 FLOAT
)
# 4. 添加 Concat 节点(拼接置信度和索引)
combined_node = helper.make_node(
'Concat',
inputs=['confidence', 'index_float'],
outputs=['combined_output'],
axis=-1
)
# 5. 获取原始输出形状(用于构建新输出信息)
original_output = model.graph.output[0]
original_shape = original_output.type.tensor_type.shape.dim
# 提取前两维,若为动态则用 "?" 表示
dim0 = original_shape[0].dim_param if original_shape[0].HasField('dim_param') else original_shape[0].dim_value
dim1 = original_shape[1].dim_param if original_shape[1].HasField('dim_param') else original_shape[1].dim_value
# 如果 dim_value 是 0(表示动态),也转为 "?"
dim0 = dim0 if dim0 != 0 else "?"
dim1 = dim1 if dim1 != 0 else "?"
# 6. 创建新的输出信息 (形状 [batch, time_steps, 2])
combined_output_info = helper.make_tensor_value_info(
'combined_output',
onnx.TensorProto.FLOAT,
[dim0, dim1, 2]
)
# 7. 添加所有新节点到图中
model.graph.node.extend([
confidence_node,
index_int_node,
index_float_node,
combined_node
])
# 8. 更新模型输出(清空原输出,添加新的 combined_output)
model.graph.output.clear()
model.graph.output.append(combined_output_info)
# 9. 保存模型
onnx.save(model, output_path)
print(f"✅ 已保存合并输出模型到: {output_path}")
print(f" 输出形状: [batch, time_steps, 2]")
print(f" 通道0: 置信度 (float32)")
print(f" 通道1: 索引 (转换为 float32)")
return model
if __name__ == "__main__":
merge_confidence_and_index(
"PP-OCRv6_tiny_rec.onnx",
"PP-OCRv6_tiny_rec.onnx"
)第二步,onnx→engine转换命令(cmd里头运行):
Det文本检测模型:
trtexec --onnx=PP-OCRv6_tiny_det.onnx ^
--saveEngine=PP-OCRv6_tiny_det_fp16.engine ^
--fp16 ^
--minShapes=x:1x3x32x32 ^
--optShapes=x:1x3x960x960 ^
--maxShapes=x:1x3x960x960
Rec文本识别模型:
trtexec --onnx=PP-OCRv6_tiny_rec.onnx ^
--saveEngine=PP-OCRv6_tiny.engine ^
--minShapes=x:1x3x48x32 ^
--optShapes=x:4x3x48x320 ^
--maxShapes=x:16x3x48x1280
Cls文本分类模型(可选):
trtexec --onnx=PP-OCRv5_mobile_cls_onnx.onnx ^
--saveEngine=PP-OCRv5_mobile_cls_fp16.engine ^
--fp16 ^
--minShapes=x:1x3x80x160 ^
--optShapes=x:4x3x80x160 ^
--maxShapes=x:8x3x80x160
第三步,模型转换成功后,在颜国进大佬的DeploySharp源代码里头按如下配置就可以体验极致的推理速度了
// 配置推理引擎和设备
// 1. 设置全局推理后端为 ONNX Runtime
paddleOCRConfig.GlobalInferenceBackend = InferenceBackend.TensorRT;
// 2. 配置硬件加速设备
paddleOCRConfig.GlobalDeviceType = DeviceType.GPU0;
paddleOCRConfig.GlobalOnnxRuntimeDeviceType = OnnxRuntimeDeviceType.TensorRT;