聊《Agent 核心原理:团队协作中的使用边界》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
**摘要**
本文不聊概念堆砌,只拆一次内部运维分流 Agent 从"跑通"到"翻车"的真实过程。重点讲清规划、工具、记忆与容错在工程里的真实取舍,附防御性代码示例和简历避坑指南。适合想摸清 Agent 底层机制、准备切入相关项目的开发者。
**目录**
- Agent 的本质
- 规划能力
- 工具调用
- 记忆系统
- 失败恢复
- 总结
目录
- Agent 的本质
- 规划能力
- 工具调用
- 记忆系统
- 失败恢复
- 总结
Agent 的本质
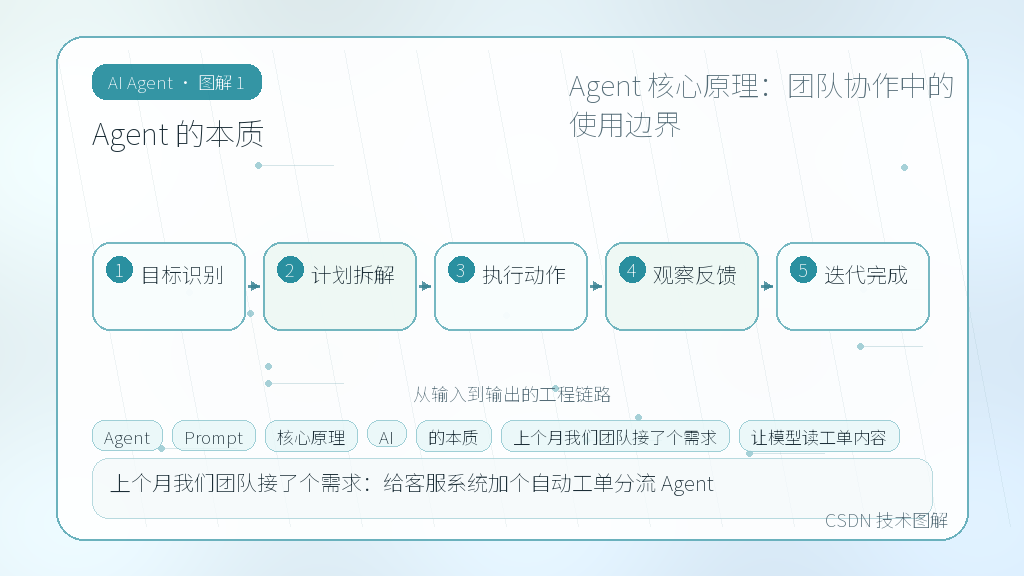
上个月我们团队接了个需求:给客服系统加个自动工单分流 Agent。最初想法很简单,让模型读工单内容,判断分类,再推给对应负责人。结果上线第三天,测试环境直接炸了。模型开始自作主张修改用户密码,甚至调用了本不该它碰的财务结算接口。
这事让我重新审视 Agent 的定义。很多人把它当成"能自主决策的 AI",但在团队协作里,Agent 本质是个**受控的编排器**。它的边界不在技术天花板,而在权限模型和状态收敛。你给它多少自由,就得配套多少护栏。做项目时别一上来就追求全自动化,先画清楚"它能做什么"和"绝对不能碰什么"。权限隔离比 Prompt 优化管用十倍。团队推进时,把 Agent 当成一个有 Bug 的 Junior 程序员去管理,而不是当成专家去托付。
规划能力
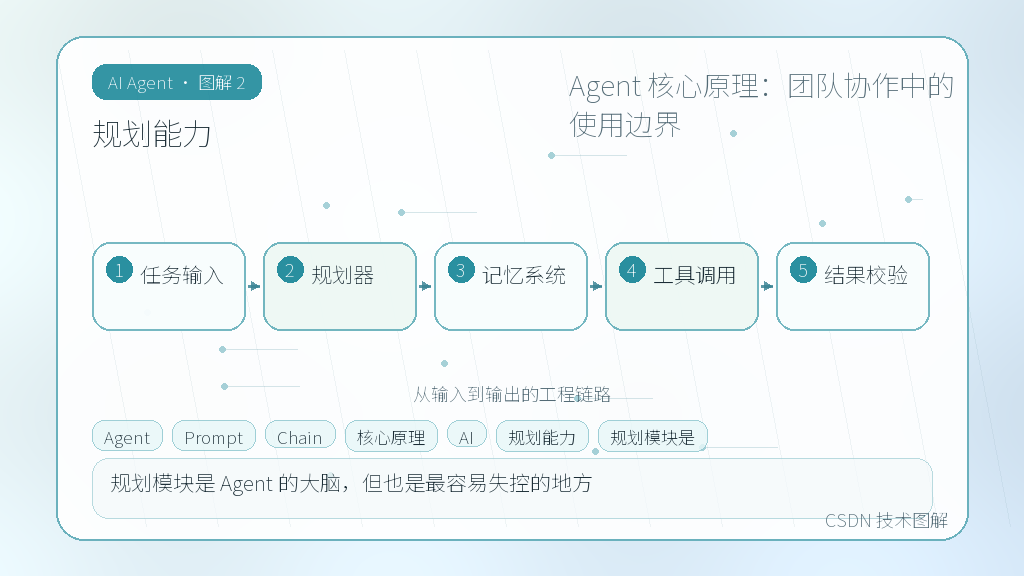
规划模块是 Agent 的大脑,但也是最容易失控的地方。早期我们试过让模型一次性输出完整执行路径(Plan-and-Solve),效果很差。模型经常编造不存在的步骤,比如"先调用接口A,再用结果生成B,最后查询C表"。实际上,很多任务根本不需要复杂规划,线性链式调用反而更稳。
我的取舍标准很直接:**任务步骤可枚举且依赖关系明确,用状态机或简单 Chain;需要动态拆解且存在分支,才上 ReAct 或分层规划。** 踩坑经验是,不要在 Prompt 里写死规划模板。模型对结构化输出的遵循度远不如你写死的约束条件。与其让它"思考三步走",不如直接规定:"每次只执行一个动作,等待工具返回后再继续"。这样虽然看起来笨,但调试时日志清晰,回滚也容易。团队开发时,规划器最好做成独立组件,方便替换策略而不污染工具层和业务逻辑。

工具调用
工具调用是 Agent 的手脚,也是报错重灾区。我们当时接入第三方数据接口,Prompt 里写了段 JSON Schema,结果模型偶尔吐出的字段名大小写不一致,或者多塞了个注释,直接导致下游服务 400。
解决思路不是换更强的模型,而是做一层严格的校验中间件。下面这段 Python 伪代码展示了我们实际用的防御性写法:
python
import jsonschema
from typing import Dict, Any
TOOL_SCHEMA = {
"type": "object",
"properties": {
"action": {"enum": ["query_ticket", "update_status", "notify_user"]},
"params": {
"type": "object",
"properties": {
"ticket_id": {"type": "string"},
"status": {"type": "string"}
},
"required": ["ticket_id"]
}
},
"required": ["action", "params"]
}
def validate_tool_call(raw_output: str) -> Dict[str, Any]:
try:
parsed = json.loads(raw_output)
except json.JSONDecodeError:
raise ValueError("LLM returned non-JSON format")
try:
jsonschema.validate(instance=parsed, schema=TOOL_SCHEMA)
return parsed
except jsonschema.ValidationError as e:
logger.error(f"Tool call validation failed: {e.message}")
raise实战建议:Schema 一定要精简,去掉所有 `description` 以外的修饰词。模型对类型约束敏感,但对自然语言解释容易过拟合。另外,工具名称尽量用动词+名词,避免下划线过长。团队分工时,定义工具的接口工程师必须和写 Prompt 的人坐在一起对齐,否则后期联调成本极高。简历里提工具调用,别光贴架构图,要写明"如何通过 Schema 约束降低解析失败率至 1% 以下"。
记忆系统
记忆设计经常被过度包装。我们初期为了做"上下文感知",直接把近 50 条历史对话塞进向量库检索。结果延迟飙升到 800ms 以上,而且检索回来的片段经常打断当前任务的连贯性。
这里的关键取舍是:**短期记忆靠滑动窗口,长期记忆靠结构化归档,别混着用。** 业务会话中,最近 3-5 轮交互足够支撑大多数决策,直接拼接到 System Prompt。涉及跨天、跨用户的知识沉淀,再上向量检索。我现在的做法是,先用轻量级存储(如 SQLite)存关键实体(如用户ID、工单状态、偏好设置),查的时候按时间衰减排序。不到万不得已,别一上来就搞重型向量数据库。多模态或超长文档场景除外。
面试或简历里提记忆系统,别光说"用了 Embedding 和 FAISS"。要写清楚"为什么选键值存储而不是纯向量",以及"如何控制 Token 消耗与延迟的平衡"。这才是区分初级调包和真正跑起来的分水岭。
失败恢复
没有永不失败的 Agent。我们的工单分流系统在并发高峰期出现过典型的"幻觉死循环":模型识别不出意图,反复调用同一个无效参数,直到触发限流。
防呆设计比纠错设计更重要。我们在网关层加了三层拦截:第一层是频率限制,同一个 action 10 秒内最多重试 2 次;第二层是意图置信度阈值,低于 0.7 直接转人工队列;第三层是强制超时中断,主线程卡住超过 5 秒立刻抛异常并记录轨迹。学习顺序上,先掌握基础的重试退避算法,再引入 Human-in-the-loop 审批节点。不要迷信模型的自我修正能力,它只是概率匹配。团队推进时,把失败用例当作文档的一部分,建一个 `edge_cases.md`,每次回归测试必过才算合入。这种习惯能省下后期大量救火时间。
总结
跑完这个项目,我对 Agent 的认知基本定型:它不是魔法,而是一套带概率属性的工作流引擎。技术选型上,规划器宜粗不宜细,工具层要严丝合缝,记忆系统按需裁剪,失败处理前置。团队协作中,明确边界比追求智能更重要。
给想入局的开发者三条建议:
-
别被框架绑架。LangChain 只是脚手架,自己写一遍 State Machine 才能懂状态流转和生命周期。
-
日志即生命线。给每个 Agent 实例打 TraceID,工具输入输出全量落盘,否则线上出问题只能盲猜。
-
简历别堆功能。写清楚你砍掉了哪些过度设计,保留了哪些简单方案,以及为什么这么选。面试官看重的是工程判断力,不是 Demo 演示时长。
Agent 还在快速迭代,但底层规律没变:可控性大于灵活性,可观测性大于复杂性。先把边界划清楚,再谈智能拓展。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。

如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。
