🙋
我是 Luhui Dev,一个长期拆解 Agent 工程、探索 AI 教育落地的开发者。关注 Agent Harness、LLM 应用工程、AI for Math 与教育 SaaS 产品化实践。
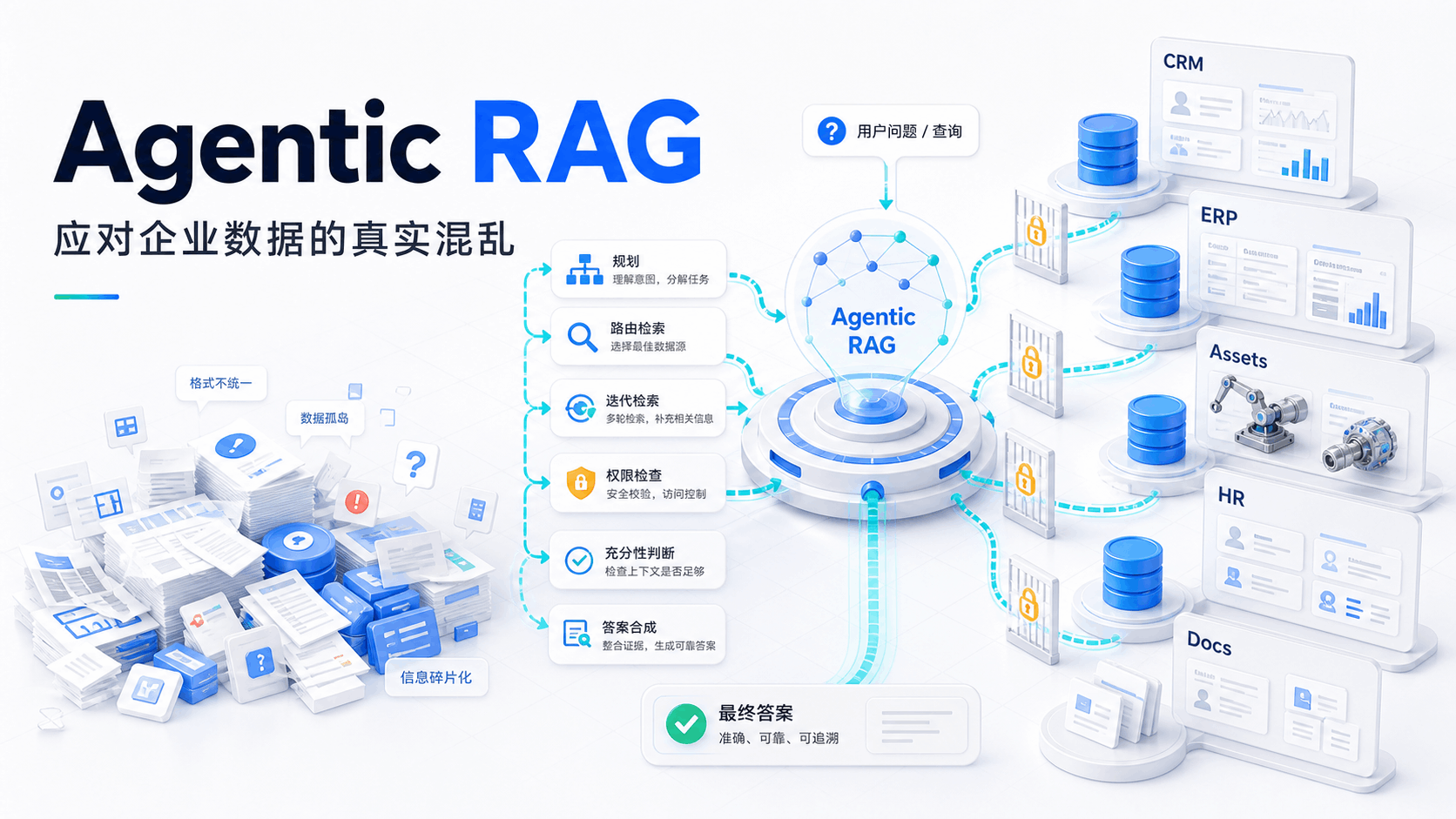
一个工单背后的数据迷宫
假设你的公司刚上线了一套 AI 客服系统。
一位大客户发来工单:"我们上个季度在项目 Alpha 采购的服务器,保修期还有多久?能否告知当时的合同条款和对应的技术支持联系人?"
听起来是个再普通不过的问题。但你的技术负责人看到这条工单,沉默了三秒。
因为他知道,要回答这个问题,系统需要:
- 去 CRM 系统里查这家客户的客户档案和项目记录
- 去 ERP/合同管理系统里查项目 Alpha 的采购合同和保修条款
- 去 资产管理系统里查那批服务器的入库日期和设备序列号
- 去 HR 系统里查客户成功团队的当前负责人
这四个系统,分属不同的技术团队维护,使用不同的数据库,有不同的访问权限控制。
普通的 RAG 系统对这种情况束手无策。它只能回答:"抱歉,我找不到相关信息。"
这就是 Agentic RAG 要解决的问题。
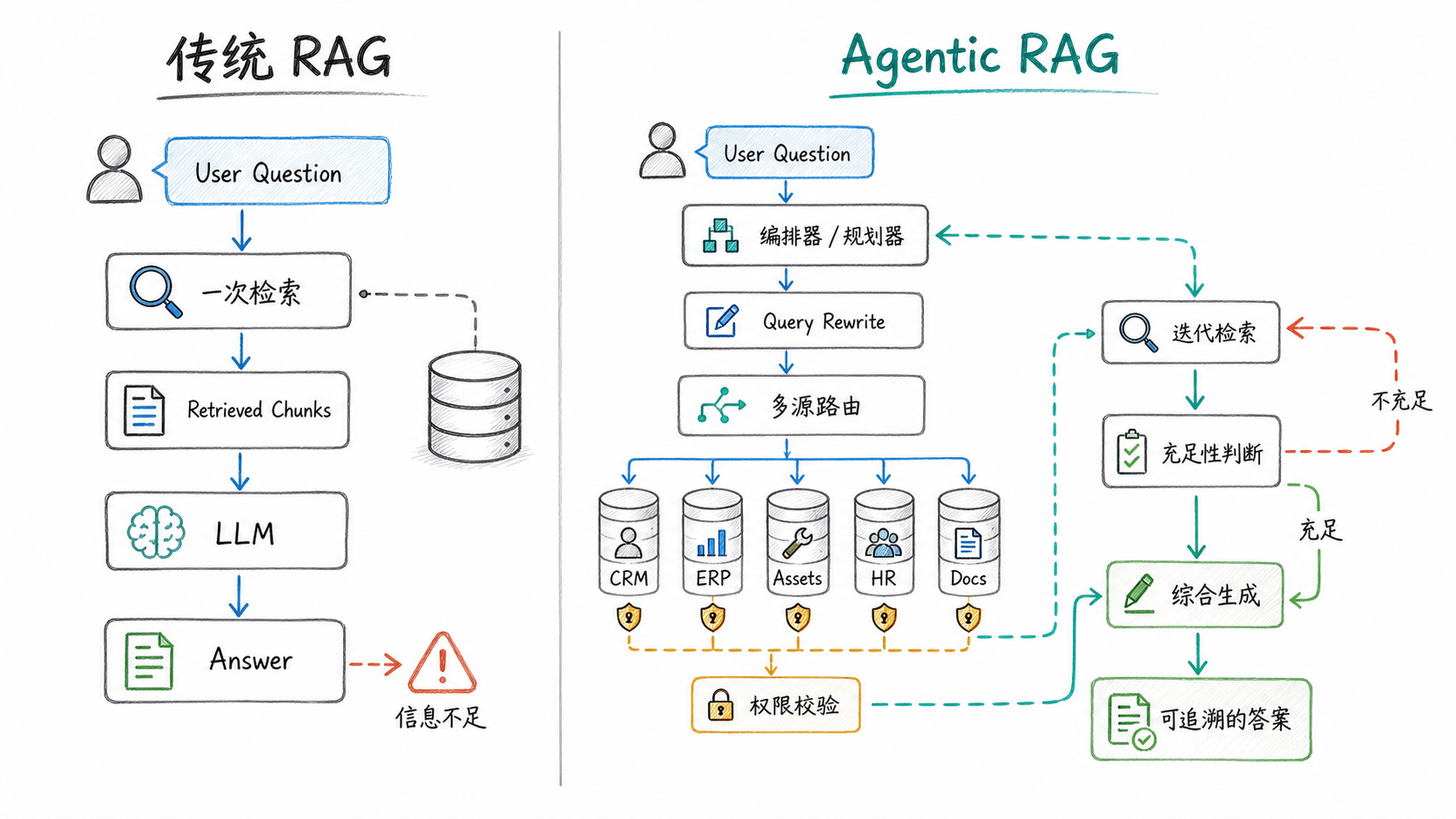
传统 RAG:一次性的检索员
先快速回顾一下 RAG 的工作原理。
RAG(检索增强生成) 的核心思路很简单:LLM 的训练知识是静态的,而企业数据是动态私有的。解决办法是在生成答案之前,先去数据库里检索相关文档片段,把它们塞进上下文,让 LLM 基于这些材料来回答。
用户问题 → [向量检索] → 召回相关文档片段 → [LLM] → 生成回答这个流程在单一知识库、问题明确的场景下效果不错。但它有两个根本性的限制:
限制一:单次检索,不迭代。 检索一次,给 LLM 一次,完成。如果第一次检索没找到关键信息,整个链路就断了,LLM 只能靠猜或者说"我不知道"。
限制二:单一语料库,不路由。 传统 RAG 预设知识存在一个统一的向量数据库里。现实企业里,数据分布在 CRM、ERP、Confluence、数据仓库、私有文档库......每个系统有自己的访问入口和权限边界。
用一个比喻来说:传统 RAG 是一个只能在图书馆一楼找书的图书管理员,而你需要的书可能分布在四层楼,每层楼还有不同的入馆许可。
Agentic RAG:会思考的检索部门
Agentic RAG 的核心转变是:把一次检索变成一个有规划、能迭代的检索过程。
它不再是一个被动的查询-返回流程,而是一个由多个专职 Agent 协作的工作流,每个 Agent 负责不同的职责。
让我们用前面那个客服工单的例子,拆解整个工作流是如何运转的。
第一步:编排器拆解任务
用户的问题被送到编排器(Orchestrator)。
编排器不直接去检索。它先理解问题的结构:这个问题涉及几个独立的信息需求?它们之间有没有依赖关系?需要访问哪些数据源?
对于我们的工单,编排器会拆解出:
- 子任务 A:从 CRM 查客户"项目 Alpha"的基本信息(客户 ID、项目编号)
- 子任务 B:用项目编号,从合同系统查保修条款
- 子任务 C:用项目编号,从资产管理系统查设备序列号和入库日期
- 子任务 D:从 HR 系统查当前技术支持负责人
注意:子任务 B 和 C 依赖于子任务 A 的结果(需要先拿到项目编号)。子任务 D 可以并行执行。
这个依赖关系图,就是规划器(Planner Agent) 输出的执行计划。
第二步:查询改写,适配不同数据源
每个数据源的查询方式不同。CRM 可能需要关键词检索,合同系统可能需要结构化 SQL 查询,向量数据库需要语义检索。
查询改写器(Query Rewriter) 负责把自然语言的子任务,翻译成每个目标数据源能理解的查询形式:
- 对 CRM 向量库:
"Alpha 项目 采购记录 {客户名}" - 对合同系统:
SELECT warranty_terms FROM contracts WHERE project_id = 'Alpha-XXX' - 对资产管理:
"Alpha项目 服务器 入库日期 序列号"
第三步:并行检索,跨越权限边界
检索扩散器(Search Fanout Agent) 同时向多个数据源发起查询。
这里有个关键的工程问题:权限。
不同数据源的访问权限不同。CRM 数据可能是销售团队开放的,但 HR 数据只有管理员能访问,合同数据需要法务审批。Agentic RAG 框架需要在这一层维护"凭证池"------不同数据源对应不同的访问令牌,且检索时的权限不会超出当前用户的授权范围。
这不只是技术问题,也是合规问题:AI 不应该因为你用自然语言问了一个问题,就绕过了你本来不应该有的数据访问权限。
第四步:充足性判断------这是最关键的创新
所有检索结果汇聚后,进入充足上下文检验器(Sufficient Context Agent)。
这个环节是 Agentic RAG 区别于传统 RAG 最核心的设计:系统会主动判断当前收集到的信息是否足以回答原始问题,如果不够,明确指出缺什么,然后继续检索。
对我们的工单案例,检验器可能发现:
✅ 已找到:客户档案、项目编号、设备序列号
✅ 已找到:技术支持负责人
❌ 缺失:合同系统返回了文件,但保修条款在附件 PDF 里,向量检索没有命中
检验器输出的不是"信息不足",而是精确的缺口描述:
"已获取项目编号 Alpha-2024-087,设备序列号 SN-XXX-YYY-ZZZ,入库日期 2024 年 3 月。合同主文件已检索,但保修条款位于合同附件 B,需要针对'附件 B 保修期限'重新检索合同附件库。"
这条反馈驱动第二轮检索:改写器生成更精准的查询,专门针对合同附件进行检索。
这个"检索 → 评估 → 再检索"的迭代循环,会一直持续,直到充足性检验器判断信息已经完备,或者达到最大迭代次数限制。
第五步:综合生成最终回答
所有信息齐备后,综合 Agent(Synthesis Agent) 把来自四个不同系统的碎片信息,整合成一个连贯、准确、可引用来源的回答:
"项目 Alpha(编号 Alpha-2024-087)采购的 3 台服务器(序列号 SN-XXX-001 至 003),根据合同附件 B 第 4.2 条,保修期为自入库日期(2024 年 3 月 15 日)起 36 个月,即至 2027 年 3 月 14 日到期。当前技术支持负责人为李明(分机 4521,liming@company.com)。"
每一句话都有数据来源,都可追溯。
跨权限边界:比技术更难的问题
值得单独拿出来说的是权限边界的处理。
真实企业里,数据权限是一个多维度的问题:
| 维度 | 说明 | 示例 |
|---|---|---|
| 角色权限 | 不同角色能看到不同数据 | 销售能查合同摘要,但不能查原文 |
| 数据分级 | 同一数据库内有不同密级 | 员工薪资 vs 员工花名册 |
| 时间权限 | 部分数据有时效性访问限制 | 审计期间的财务数据只读 |
| 跨系统权限 | A 系统的数据不能出现在 B 系统的上下文里 | GDPR 要求数据不跨境流转 |
Agentic RAG 框架需要在每次检索调用时,都严格遵守这些权限规则,而不是在索引时统一授权。
这意味着架构上要实现**查询时权限校验,而不是把所有数据统一向量化放进一个大库这种简单粗暴的做法。
用数据库的比喻来说:传统 RAG 像是把所有表 JOIN 成一张大表再给 LLM 用;Agentic RAG 像是为每次查询动态生成带权限过滤的 SQL。
实际场景中的三个关键决策点
当你在真实工程里实现 Agentic RAG 时,有三个决策是绕不开的。
决策一:路由策略------静态配置还是 LLM 路由?
静态路由:根据查询中的关键词或元数据,提前定义规则决定去哪个数据源。速度快,可控,但应对开放式查询能力弱。
LLM 路由:让 LLM 理解查询意图后,动态决定路由到哪个数据源。灵活,但每次路由都消耗 LLM 调用,增加延迟和成本。
决策二:迭代深度------什么时候停下来?
系统可能陷入无限迭代------每轮检索都觉得还缺点什么,一直找下去。
工程上需要设置:
- 最大迭代轮数(通常 2-4 轮)
- 时间预算(超时直接用已有信息回答)
- 降级策略(超出迭代限制时,用已有信息回答并标注信息可能不完整)
决策三:延迟 vs 准确率的权衡
Agentic RAG 比传统 RAG 慢,这是无法回避的事实。多轮 LLM 调用、并行检索、充足性评估,每一步都有延迟成本。
| 方案 | 成本倍数 | 延迟倍数 | 适用场景 |
|---|---|---|---|
| 传统 RAG | 1x | 1x | 简单问答,单一知识库 |
| Adaptive RAG | 1.5-2x | 1.2-2x | 查询复杂度差异大的混合场景 |
| CRAG(纠错 RAG) | 3-5x | 2-3x | 准确率要求高、可接受秒级延迟 |
| 完整 Agentic RAG | 5-10x | 3-6x | 复杂多跳、跨库关联、异步场景 |
不是所有场景都需要完整的 Agentic RAG。
为查询进行意图分类,复杂查询走 Agentic 流程,简单查询走传统 RAG,可以把平均成本和延迟控制在合理范围内。
写在最后
我认为 Agentic RAG 的本质,就是把 RAG 中的检索变成了可执行的策略:如果一次不够,就继续找,直到够了为止。"够了"这件事本身,也是系统来判断的。
这个改变听起来简单,但它要求系统从"查询-响应"的无状态模式,转变为"目标-规划-执行-评估-迭代"的有状态工作流。
这和 Agent 系统的通用挑战是一样的:状态管理是核心难题。
如果你正在构建一个涉及多数据源的企业 AI 系统,Agentic RAG 不只是一个检索技术的升级,它要求你重新思考数据架构、权限设计和工作流编排。把这三件事想清楚了,比选择哪个框架或哪家云厂商更重要。
参考资料
-
Google Research, Unlocking dependable responses with Gemini Enterprise Agent Platform's Agentic RAG, June 2026
-
Microsoft, Agentic Retrieval Overview -- Azure AI Search, 2026-04-01 GA
-
Amazon Web Services, Knowledge Bases for Amazon Bedrock -- Multiple Data Sources, April 2024
-
MarsDevs, Agentic RAG: The 2026 Production Guide(含各方案成本/延迟对比数据)
-
Google Research, Deeper Insights into Retrieval-Augmented Generation: The Role of Sufficient Context