文章目录
- 位图是什么
- 位图的应用
-
- [引用:P1059 NOIP 2006 普及组 明明的随机数](#引用:P1059 [NOIP 2006 普及组] 明明的随机数)
- 位图在特定场景中的优化
- 总结一下
位图是什么
通俗一点来讲,位图就是利用二进制0和1进行标记的一个集合结构,0代表不存在,1代表存在,那它有啥好处呢,就是能够极致压缩空间,试想一下,我如果能用一个比特位就能存入一个数(一般的,数字需要8个比特位),那么空间是不是就小很多,而位图就是以此为原理来压缩空间的,在此手写一个位图如下:
java
class Bitset{
static int []bits;
public Bitset(int n){
bits=new int[(n+31)/32]; //这里用了向上取整即(a+b-1)/b,因为我们要存入33个数字那就要开两个比特位了。
}
public void add(int x){
int index=x/32;
int bit=x%32;
bits[index]|=(1<<bit);
}
public void remove(int x){
int index=x/32;
int bit=x%32;
bits[index]&=~(1<<bit);
}
public boolean contains(int x){
int index=x/32;
int bit=x%32;
return (bits[index]&(1<<bit))!=0;
}
public void reverse(int x){
int index=x/32;
int bit=x%32;
bits[index]^=(1<<bit);
}
public int size(){
int count=0;
for(int i=0;i<bits.length;i++){
count+=Integer.bitCount(bits[i]);
}
return count;
}
}对于以上代码,可以一个一个来分析它们的方法:
插入数字:
java
//其实要加入一个数字就是要把这个数字所对应的空间标记为1,即存在就可以了
public void add(int x){
int index=x/32; //找到这个数字属于哪个int里
int bit=x%32; //找到他在该范围的位置
bits[index]|=(1<<bit); //利用位运算将该位置标记为1
}
//在这里特别分析一下bits[index]|=(1<<bit):
//首先(1<<bit)是将1向左移动bit位其实就是将第bit位变为1,其他位全为0
//bits[index]|=(1<<bit)其实就是bits[index]=bits[index]|(1<<bit)的简写
//然后和原二进制数进行一个或运算,利用
// 0 | 0 = 0
// 0 | 1 = 1
// 1 | 0 = 1
// 1 | 1 = 1
//那么这一位就被我们标记为1(即存在)了
//再举个例子:
//1 0 1 0 0 1 0 1 (set[idx] 原本的值)
//0 0 0 0 1 0 0 0 (1 << 3 产生的掩码,再进行或运算)
//↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ (有1则1,全0才0)
//1 0 1 0 1 1 0 1 (结果:只有第3位变成了1,其他位都没有变)删除数字:
java
public void remove(int x){
//这里和插入相同,也要先找到这个数字对应的空间
//而要删除就只要把它的状态变为0就行了
int index=x/32;
int bit=x%32;
bits[index]&=~(1<<bit);
}
//在这里,也特别分析一下bits[index]&=~(1<<bit):
//这一行代码其实是bits[index]=bits[index]&~(1<<bit)
//(1<<bit)其实还是一样,把第bit位变为1,而~则是按位取反
//就是比如我移位后是0000 1000,那么取反后就是1111 0111
//然后进行与运算,举个例子:
// 1 0 1 0 1 1 0 1 (bits[index] 原本的值)
// 1 1 1 1 0 1 1 1 (~(1 << 3) 产生的反向掩码,再进行与运算)
// ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ (同1才1,有0则0)
// 1 0 1 0 0 1 0 1 (结果:只有第3位变成了0,其他位都没变)查询数字是否存在:
java
//要查询是否存在这个位是否有值
public boolean contains(int x){
//也这里和插入相同,也要先找到这个数字对应的空间
int index=x/32;
int bit=x%32;
return (bits[index]&(1<<bit))!=0;
}
//在这里,也仔细分析一下return (bits[index]&(1<<bit))!=0;
//同样的举个例子:
// 1 0 1 0 0 1 0 1 (bits[index] 原本的值)
// 0 0 0 0 1 0 0 0 (1 << 3 产生的探针,再进行与运算&)
// ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ (同1才1,有0则0)
// 0 0 0 0 0 0 0 0 (按位与结果:0,就说明该数不存在)反转此位的状态即0变1,1变0:
java
public void reverse(int x){
//也这里和插入相同,也要先找到这个数字对应的空间
int index=x/32;
int bit=x%32;
bits[index]^=(1<<bit);
}
//也仔细分析一下bits[index]^=(1<<bit);
//(1<<bit)其实还是一样,把第bit位变为1
//进行异或运算就是反转的神器,举个例子:
// 1 0 1 0 0 1 0 1 (bits[index] 原本的值)
// 0 0 0 0 1 0 0 0 (1 << 3 产生的掩码)
// ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ (进行异或运算,相同为0,不同为1)
// 1 0 1 0 1 1 0 1 (结果:只有第3位从0变成了1,其他位都没变)查询该容器的有效长度,就是状态1的个数
java
public int size(){
int count=0;
for(int i=0;i<bits.length;i++){//循环中的bits.length是指在位图中有多少个int空间
count+=Integer.bitCount(bits[i]);
}
return count;
}
//而Integer.bitCount(x)则是查询 32 位整数中 1 的个数相加就是所求的值了
//这个方法对应C++的std::popcount(static_cast<unsigned int>(x))
//对应Python的bin(x).count('1')但是其实在写题中各语言都提供了各自的库和API方法,但是上面的基本底层代码还是要懂得并理解为好:
| 语言 | 原生位图工具 | 底层存储 | 增删查对应方法 | 核心特点 |
|---|---|---|---|---|
| Java | BitSet | long数组,64位分桶,自动扩容 | set、clear、get | 内置成熟工具,自动扩容,仅支持非负整数 |
| C++ | bitset | 固定长度位存储 / 动态比特容器 | set、reset、test | bitset编译定长速度快,vector支持动态长度 |
| Python | 无原生位图,可借助整数或第三方库(建议第三方库,运行更快) | 无限长整型 / 第三方比特数组 | 位运算手动实现标记、清除、判断 | 原生无封装,小数据简单,超大数值性能一般 |
位图的应用
根据位图的特性,它在写题可以应用于去重 和快速查找 以及可以减小质数筛的空间复杂度,以下以去重为例:
引用:P1059 NOIP 2006 普及组 明明的随机数

题目链接如下:
这个题目细看其实是个排序加去重问题,那么脑海中就一定会有思路了:双指针原地去重,哈希表等等,那么它们的代码如下:
解法①:原地双指针解法
java
import java.io.*;
import java.util.*;
public class Main{
static BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
static PrintWriter out=new PrintWriter(System.out);
static StringTokenizer st;
static int n;
static int[]ans;
public static void main(String[] args)throws IOException{
n=Integer.parseInt(br.readLine());
ans=new int[n];
st=new StringTokenizer(br.readLine());
for(int i=0;i<n;i++){
ans[i]=Integer.parseInt(st.nextToken());
}
Arrays.sort(ans); //使用双指针的前提是要有序
int left=0;
for(int right=0;right<n;right++){
if(ans[right]==ans[left]){ //如果判断的数字和前面的数字相同,那就跳过
continue;
}
//如果不同就让左指针追上右指针
left++;
ans[left]=ans[right];// 将左指针的值赋值为右指针的值
}
out.println(left+1);//此时去重后的长度为left+1
for(int i=0;i<=left;i++){
out.print(ans[i]);
if(i!=left) out.print(" ");
}
out.flush();
out.close();
br.close();
}
}很显然,这种解法的时间复杂度 式O(nlogn) (排序是要O(nlogn) ,遍历数组要O(n) ,综合起来就是O(nlogn) ),空间复杂度 为O(n),而这种解法有一个最大的弊端,就是对于不能改变顺序的去重,那直接无效了。
解法②:HashSet+排序或者TreeSet
TreeSet解法:
java
import java.io.*;
import java.util.*;
public class Main{
static BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
static PrintWriter out=new PrintWriter(System.out);
static StringTokenizer st;
public static void main(String[] args)throws IOException{
int n=Integer.parseInt(br.readLine());
st=new StringTokenizer(br.readLine());
TreeSet<Integer> ts=new TreeSet<>(); //TreeSet会自动排序去重
for(int i=0;i<n;i++){
int num=Integer.parseInt(st.nextToken());
ts.add(num);
}
out.println(ts.size());
ts.stream().forEach(num->{
out.print(num + " ");
});
out.flush();
out.close();
br.close();
}
}它的时间复杂度 为插入的插入 O (n logts.size()) ,因为他的底层式红黑树,天然就是有序的,而空间复杂度 为O(ts.size()),因为红黑树不会保存重复元素的.
HashMap+排序解法:
java
import java.io.*;
import java.util.*;
import java.util.stream.Collectors;
public class Main{
static BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
static PrintWriter out=new PrintWriter(System.out);
static StringTokenizer st;
static int n;
static int[]ans;
public static void main(String[] args)throws IOException{
n=Integer.parseInt(br.readLine());
ans=new int[n];
st=new StringTokenizer(br.readLine());
for(int i=0;i<n;i++){
ans[i]=Integer.parseInt(st.nextToken());
}
HashSet<Integer> hs=new HashSet<>();
for(int i=0;i<n;i++) hs.add(ans[i]);
out.println(hs.size());
String result = hs.stream()
.sorted()
.map(String::valueOf)
.collect(Collectors.joining(" "));
out.println(result);
out.flush();
out.close();
br.close();
}
}设去重后的数组长度为m
那么它的时间复杂度 为O(n+mlogm) ,即为:
1.读取数组:O(n)
2.HashSet 插入全部元素:每个元素哈希插入平均 O(1) ,总 O(n)
3.流式排序 .sorted():底层归并排序,对 m 个元素排序 O(mlogm)
4.字符串拼接、输出:O(m)
空间复杂度
输入数组 ans:O(n)
HashSet 存储不重复元素:O(m)
Stream 排序临时存储、拼接字符串:O(m)
总空间复杂度:O(n+m) ,可以去掉ArrayList,空间复杂度降低为O(m)
解法③Bitset+标记:
java
import java.io.*;
import java.util.*;
import java.util.BitSet;
public class Main{
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static PrintWriter pw = new PrintWriter(System.out);
static StringTokenizer st;
static int n;
public static void main(String[] args)throws IOException{
BitSet bs=new BitSet();
n=Integer.parseInt(br.readLine());
st=new StringTokenizer(br.readLine());
for (int i = 0; i < n; i++) {
int x = Integer.parseInt(st.nextToken());
bs.set(x); //位图在底层是按数字升序去位运算判断的,相当于排了序
}
int count = bs.cardinality();
pw.println(count);
boolean first = true;
for(int i = 0; i <= 2000; i++){
if(bs.get(i)){
if(!first) pw.print(" ");
pw.print(i);
first = false;//已经加入了就标记
}
}
pw.println();
pw.flush();
pw.close();
br.close();
}
}BitSet在底层为位图,他对每个数字进行位运算,那么时间复杂度即 为O(n) ,该算法最后存入的数字为count个(count<=n),那么空间复杂度 为O(count) ,总体上时间复杂度和空间复杂度上占优的,但其实他也是有弊端的:
1.位图无法支持负数的去重,底层上不可行
2.位图位图占用空间由数字最大值决定,和输入数字个数无关,在做题的时候未知最大值,取空间的时候就有不确定性
3.位图只能标记是否存在,对于有附加问题比如统计每个数字出现的次数就无能为力了
在实际生活中也有它的广泛应用:
| 应用场景 | 具体业务说明 | 位图核心作用 | 核心优势 |
|---|---|---|---|
| 社交软件好友状态管理 | 微信、QQ等平台,实时展示好友在线/离线/忙碌/隐身等状态 | 1个比特位标记1个好友的核心状态,额外比特位标记细分状态,1个好友仅占几比特内存 | 百万级好友列表仅需几十KB内存,状态更新和查询速度极快,大幅降低服务器带宽压力 |
| 电商平台商品状态标记 | 淘宝、京东等平台,标记商品是否上架、是否有货、是否参与促销、是否合规等状态 | 不同比特位分别对应商品的1项状态,1个商品的所有状态仅需1组比特位存储 | 千万级商品库的状态筛选仅需毫秒级,无需重复查询数据库,大幅降低服务器负载 |
| 音视频平台会员权益管理 | 爱奇艺、网易云音乐等平台,标记用户是否开通会员、是否可看付费内容、是否可跳过广告等权益 | 1个比特位对应1项会员权益,1个用户的所有权益状态仅需1个或几个整数即可完整存储 | 用户登录时一次性加载所有权益,页面权限判断无需重复请求接口,内容加载速度大幅提升 |
| 办公软件人员权限管控 | 飞书、企业微信等平台,标记员工是否可查看文档、编辑表格、发起审批、管理部门等权限 | 用比特位矩阵标记员工-权限的对应关系,1个比特位代表1项权限是否开启 | 企业级万人组织的权限校验仅需内存位运算,无需查询数据库,权限变更可实时生效 |
| 游戏内成就/道具解锁管理 | 王者荣耀、原神等游戏,标记玩家是否解锁成就、拥有皮肤/道具、通关关卡等状态 | 1个比特位对应1个成就/道具,玩家的所有解锁状态仅需少量内存即可完整存储 | 玩家登录时快速加载所有解锁状态,游戏内成就触发和道具检查无卡顿,不影响游戏运行帧率 |
| 内容平台内容审核状态管理 | 抖音、小红书等平台,标记内容是否通过审核、是否违规、是否可推荐、是否可评论等状态 | 不同比特位标记内容的审核结果、违规类型、推荐权限,1条内容对应1组比特位 | 亿级内容库的合规筛选和推荐排序仅需内存运算,无需全表扫描数据库,大幅提升内容分发效率 |
| 门禁/考勤系统人员权限管控 | 公司、小区的门禁系统,标记人员是否可进入对应区域、是否在权限有效期内、是否有考勤记录 | 1个比特位对应1个门禁区域的权限,1个人员的所有权限仅需1个整数即可存储 | 门禁刷卡时权限校验仅需微秒级,无需联网查询数据库,断网也可正常使用,响应速度极快 |
位图在特定场景中的优化
在听了左神的课后,意识到有些位图题中需要懒标记 的应用,就让我意识到它不是只用于线段树 :
1.那么懒标记是啥,字面上看就是能拖就拖,直到要用了,才干活。
2.它的好处就是不用遍历大数次,在特定的时候再用通过标记来搞就能极大地提高时间复杂度
在位图中以力扣2166题设计位集为例:
引用力扣2166题:

题目链接如下:
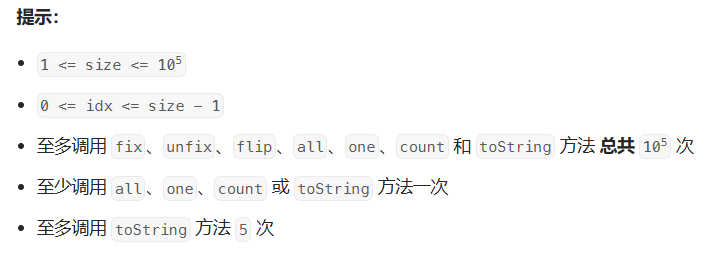
这里还是要特别关注一下它的提示内容,它其实就是位图的改版,就是要把每一位的状态值都反转过来,看到提示,会不会想我直接遍历会不会超时?会不会过不了所有样例?(我就是这样错了几次提交),那这样我们直接遍历时间复杂度那就会O(count)啦,那我能不能用懒标记的思想呢?就是我不去遍历,就用一个标记比如叫reverse,我在要翻转的时候把规则一改存,就是要调用这个flip函数的时候就改一次规则,比如上一次是1代表存在,0代表不存在,那我调用的时候就改为0代表存在,一代表不存在,然后在添加数字和删除数字的时候分别在判断是什么样的规则在看就行了,这样翻转的时间复杂度一下子就成**O(1)**了,所以代码如下:
java
//听了左神的课写的,理解最重要
class Bitset {
private int[] bits;
private final int size;
private int zeros; // 记录当前逻辑上 0 状态的个数
private int ones; // 记录当前逻辑上 1 状态的个数
private boolean reverse; // 记录现在的规则有没有被翻转
public Bitset(int n) {
bits = new int[(n + 31) / 32]; // 向上取整,算出需要几个 int 来存
size = n; // 初始总长度就是 n
// 一开始按正常规则来,啥都没加,所以全是 0
zeros = n;
ones = 0;
reverse = false; // 初始规则:1 代表存在,0 代表不存在
}
public void fix(int idx) {
int index = idx / 32; // 算出在数组的哪个位置
int bit = idx % 32; // 算出在那个 int 里的第几位
if (!reverse) { // 如果是正常规则(1=存在,0=不存在)
// 题目要求:只有当该位不是 1 的时候,才去改它
if ((bits[index] & (1 << bit)) == 0) {
// 既然要把它变成 1,那 0 的个数就少一个,1 的个数多一个
zeros--;
ones++;
bits[index] |= (1 << bit); // 用或运算把它强行变成 1
}
//翻转的模式下,逻辑 1 等价物理 0;若当前物理位为 1,代表逻辑是 0,需要翻转成物理 0,才能达到逻辑 1
} else { // 如果规则反了(0=存在,1=不存在)
// 所以我们要检查物理上是不是 1,如果是 1 就得把它变为0
if ((bits[index] & (1 << bit)) != 0) {
zeros--;
ones++;
bits[index] ^= (1 << bit); // 和上面的一样用异或把 1 变成 0
}
}
}
public void unfix(int idx) {
int index = idx / 32;
int bit = idx % 32;
if (!reverse) { // 正常规则下,想让某位变成 0
// 只有当它现在是 1 的时候,才去改
if ((bits[index] & (1 << bit)) != 0) {
ones--;
zeros++;
bits[index] ^= (1 << bit); // 用异或把 1 变成 0
}
//翻转模式下,逻辑 0 等价物理 1;当前物理位为 0 代表逻辑 1,需要改成物理 1,才能达到逻辑 0。
} else { // 规则反了,如果要让逻辑上是 0(也就是物理上得是 1)
// 检查物理上是不是 0,如果是 0 就得把它变成 1
if ((bits[index] & (1 << bit)) == 0) {
ones--;
zeros++;
bits[index] |= (1 << bit); // 用或运算把它强行变成 1
}
}
}
public void flip() {
// 懒标记:我不去遍历数组,我只要把规则反过来就nice了
reverse = !reverse;
// 也要把 0 和 1 的个数也互换一下,保证计数器是对的
int temp = zeros;
zeros = ones;
ones = temp;
}
public boolean all() {
// 只要 1 的个数等于总长度,说明全都是 1
return ones == size;
}
public boolean one() {
// 只要有至少一个 1,就返回 true
return ones > 0;
}
public int count() {
// 直接返回我们维护好的计数器,O(1) 搞定
return ones;
}
public String toString() {
StringBuilder sb = new StringBuilder();
// 外层循环遍历数组,内层循环遍历每个 int 的 32 个位
for (int i = 0, k = 0, number, status; i < size; k++) {
number = bits[k];
for (int j = 0; j < 32 && i < size; j++, i++) {
// 把每一位抠出来
status = (number >> j) & 1;
// 如果规则反了,就异或 1 把它翻过来;没反就保持原样
status ^= reverse ? 1 : 0;
sb.append(status);
}
}
return sb.toString();
}
}总结一下
其实我刚在学习位图的时候,就发现它比哈希表要神奇,但细细学来,其实它也有许多哈希表能做他却做不到的,数据结构里没有哪一个容器是完美适用所有场景的,每个容器也不是一成不变的,所以其实还要多学习,多思考,加油!