摘要:2026年,"数字中国"战略落地加速叠加工业物联网规模扩张,推动国产时序数据库赛道持续升温,产品分化与格局固化同步推进。本文聚焦国内主流时序数据库的技术路线与竞争态势,重点拆解金仓数据库(Kingbase)依托融合多模架构所构筑的差异化壁垒,旨在帮助企业在时序数据平台选型时厘清思路、规避风险。
一、国产时序数据库竞争版图(2026年)
经过数年的技术积淀与市场检验,国产时序数据库已形成各具特色的产品阵营。以技术路线、生态背景及主攻场景为维度,目前代表性产品可归纳如下:
| 数据库名称 | 核心厂商/社区 | 主要特点与定位 |
|---|---|---|
| TDengine | 涛思数据 | 高性能、分布式,定位为AI驱动的工业大数据平台,在写入吞吐和存储成本方面优势显著,集群开源、生态开放。 |
| KaiwuDB | 浪潮云弈 | 强调分布式多模融合架构,支持时序、关系、文档等多种数据模型的统一处理,原生集成AI算法。 |
| Apache IoTDB | 清华大学 (Apache基金会) | 专为物联网设计,采用"端-边-云"协同原生架构,数据模型常采用树形结构贴合物理设备层级。 |
| DolphinDB | 浙江智臾科技 | 将数据库与强大的编程语言、流计算引擎融合,在金融量化交易、高频数据分析领域表现突出。 |
| openGemini | 华为云 | 开源的多模态时序数据库,兼容InfluxDB生态,强调高性能与云原生特性。 |
| CnosDB | 诺司时空 | 云原生时序数据库,支持分布式与集中式部署,在监控和物联网场景有应用。 |
| GreptimeDB | 格睿科技 | 云原生分布式时序数据库,主打实时分析能力。 |
| YMatrix, RealHistorian, GoldenData等 | 四维纵横、紫金桥、庚顿数据等 | 在特定工业或监控领域拥有深厚的行业积累和定制化解决方案。 |
| 金仓时序数据库 | 中电科金仓(原人大金仓) | 基于成熟稳定的金仓数据库管理系统(KES)内核打造的时序能力增强插件,最大特点是继承了KES的融合多模架构,支持时序数据与关系型、空间(GIS)等数据的统一存储、处理与关联分析 。 |
二、核心解析:金仓时序数据库的融合多模底座优势
绝大多数时序数据库产品的演进方向是将专用引擎做深、做快。金仓则反其道而行之------它的时序能力以插件形式生长于KingbaseES(KES)关系数据库体系之上,与主库共享内核、共用运维栈。这条路线并不追求榜单上的极值,却在工程落地层面积累了难以复制的复合优势:
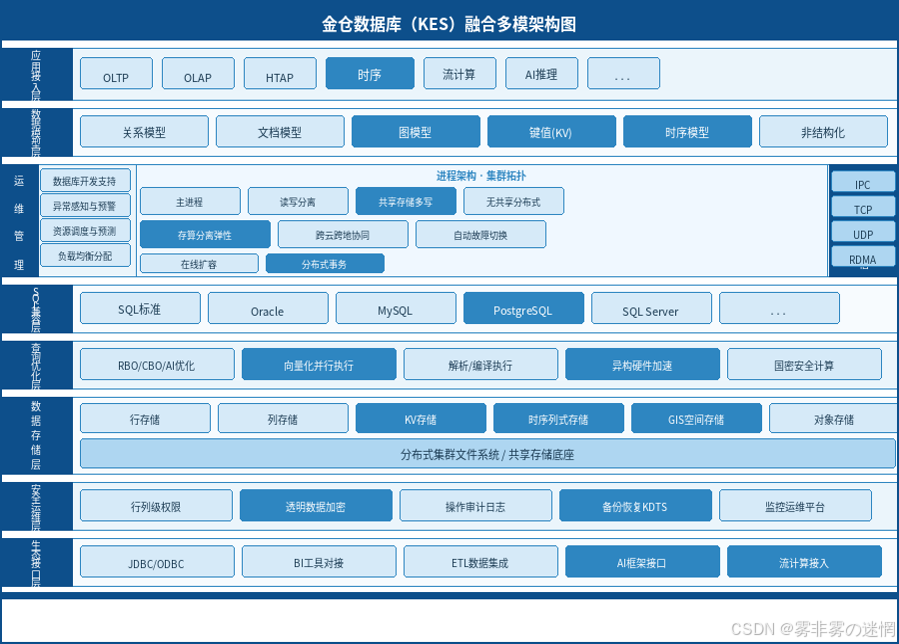
1. 同一内核承载多种数据模型,从源头消除异构孤岛
- 统一底座: 时序能力内嵌于KingbaseES主库而非独立部署,企业无需为物联网或监控数据另建一套基础设施,减少了运维节点和数据搬运成本。
- 无缝关联查询: 传感器采集量(时序)与设备档案、工单记录(关系型)天然共存于同一实例,工程师可直接用标准SQL(Oracle/PostgreSQL兼容)写跨表JOIN,不再需要先把时序数据导出再在外部做关联,分析链路大幅压缩。
- 支持丰富数据类型: KES内核原生支持JSON半结构化数据、PostGIS地理空间扩展、数组及自定义类型,时序表可与这些类型自由混用,覆盖从设备坐标轨迹到非结构化日志的广泛工业场景。
2. 直接复用关系库成熟能力,降低企业级部署门槛
- 极致的事务(ACID)保证: 时序写入与普通关系表写入共享同一套ACID事务机制,在电网调度、金融交易流水等不允许数据乱序或丢失的核心场景中,这一能力是纯时序引擎无法轻易提供的。
- 企业级高可用与安全: 时序数据天然纳入KES现有的高可用体系(读写分离、共享存储多写、分布式集群等),无需为其单独设计容灾方案;行列级访问控制与透明加密同样适用于时序表,满足等保合规要求。
- 成熟的生态与工具链: KDTS数据迁移工具、KES监控运维平台、主流BI和ETL工具的驱动适配,对时序数据同样适用。熟悉关系库运维的团队几乎不需要额外培训就能接管时序数据的日常维护。
3. 混合负载场景下的实测性能表现
据金仓官方发布的基准测试数据(含使用TSBS工具与InfluxDB的对照实验),时序组件在以下两类负载上具备实用竞争力:
- 写入性能: 结合时序分区裁剪与并行批量写入策略,单节点实测可稳定突破百万数据点/秒,水平扩展至集群后吞吐量可达千万级,能够满足中大规模工业采集场景的写入需求。
- 查询性能: 在需要跨时序表与业务表做多维聚合的混合查询中,KES的SQL优化器与向量化执行引擎发挥出明显优势,查询延迟普遍低于仅具备有限SQL支持的原生时序库,特别适合分析类业务与实时监控并存的场景。
三、已落地的典型应用场景
融合多模特性决定了金仓时序组件天然适合"时序数据量大 + 业务关联复杂"的双重约束场景。以下几个公开项目可印证其工程落地能力:
- 福建省船舶安全综合管理平台: 全省沿海数十万艘船舶的AIS/GPS轨迹持续写入,单日峰值超亿条记录;依托KES分片集群实现历史数据百亿级存量下的毫秒级地理围栏与航迹回溯查询,时序数据与船舶档案信息在同库内实时关联。
- 国家电网智能电网调度系统: 信创替代背景下,将原有商业数据库上的高频电力采集数据迁移至KES时序表,同步保留与既有调度业务系统的关系型数据联查能力,完成全流程国产化替换而不改变上层应用逻辑。
- 智慧港口(如厦门港)、智能制造厂区: 龙门吊、AGV及产线设备的运行时序数据与生产调度系统、设备台账在同一数据库内实时互联,支撑港口物流效率分析和厂区预测性维护两类业务并发查询,无需额外搭建数据中台。
四、选型决策框架:2026年企业如何理性选择时序数据库
时序数据库选型不是一道纯粹的性能题,更是一道架构题和组织题。2026年的企业决策者需要在以下两个维度上做出清醒判断:
- 数据架构复杂性: 如果时序数据与关系型、空间型数据高度耦合、需要频繁联查,引入一个孤立的专用时序库反而会制造新的数据孤岛。金仓的内嵌式融合架构在这类场景下能显著降低整体系统复杂度与集成成本。
- 长期运维与总拥有成本(TCO): 一套新数据库意味着新的学习曲线、独立的运维流程以及与现有系统的对接工程量。若团队已积累关系型数据库运维经验,采用金仓方案可将这些积累直接平移,实质性降低总拥有成本(TCO)。
结论
国产时序数据库市场在2026年进入成熟分化期:TDengine在工业写入吞吐方面继续领跑,IoTDB深耕物联网端边云协同,DolphinDB巩固金融量化领域壁垒,各方均在既定赛道上持续拉高技术护城河。
金仓时序数据库没有在这场速度竞赛里硬拼,而是选择了一条更具工程实用主义色彩的路径:将时序能力无缝嵌入成熟的关系型底座,用已经过大量生产验证的内核换取更低的落地风险。对于数据形态复杂、业务系统高度耦合、且有信创合规压力的组织而言,这种思路往往比追求极值更具实际价值,也体现了国产基础软件从"能用"走向"好用"的演进路径。
下一阶段,随着AI原生分析与流批一体计算加速渗透,时序数据库将不再只是一个"存数据"的组件,而是需要成为实时决策链路上的关键节点。如何在时序存储、多模融合、AI推理三条线上同步推进而不牺牲系统稳定性,将是所有参与者必须回答的核心命题。