大家好,我是贺老师,嵌入式 AI工程师,《嵌入式AI:让单片机学会思考》课程主理人,专注AI在MCU上的落地实践。
前几天有个学员来问我,说自己想系统学一下嵌入式 AI,准备回公司问问老板能不能报销。结果老板回了一句:"嵌入式AI就是在单片机上运行神经网络算法,没啥难度。"
出于PUA员工的目的,这种"把事情想的很简单"的话,一般会出自老板的口中。
不过,【嵌入式AI就是在单片机上运行神经网络算法】这句话很适合拿出来聊一聊。
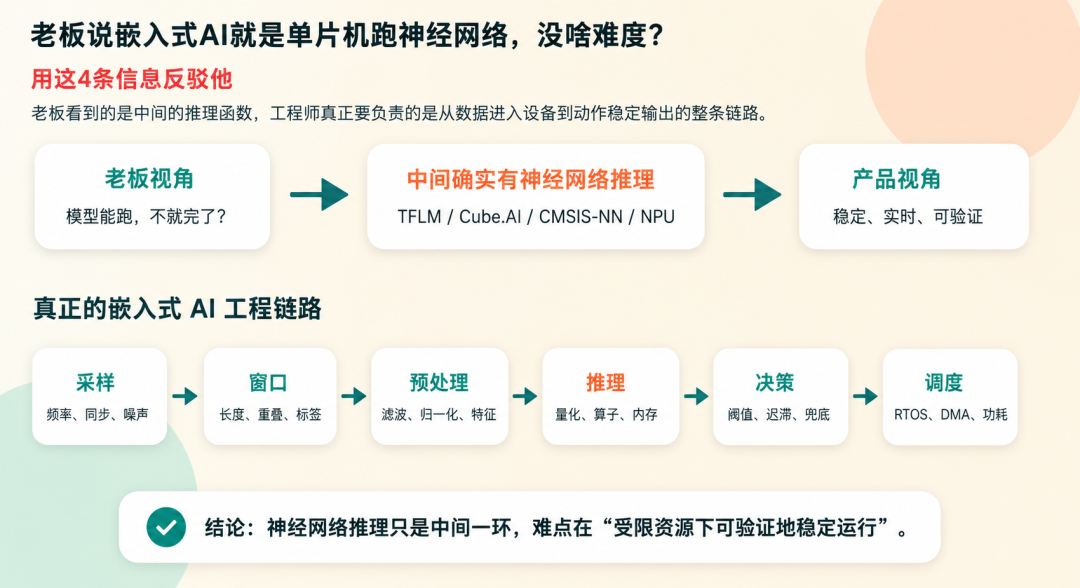
暂不评论对错,平心来论的话:老板看到的是"模型在单片机上跑起来",工程上真正麻烦的是:输入到模型的现场数据是否可靠,推理会不会影响实时任务,输出结果能不能变成安全动作,上线以后能不能长期稳定。
一、这句话哪里对:模型推理这件事确实没以前那么难
先公平一点讲,老板这句话不是完全错误。今天在 MCU 上跑一个小模型,确实比几年前容易很多。
模型可以从 TensorFlow、Keras、ONNX 等格式转换,量化成 INT8,生成 C 数组或专用格式,再通过推理框架放进固件。很多工具还能直接给出 RAM、Flash、MACC、推理时间和算子支持情况。
如果项目目标是验证可行性,比如用开发板识别几个手势、做一个简单的振动分类、判断一段音频里有没有关键词,那么"把神经网络放到 MCU 上跑起来"并不是最难的部分。真正熟悉工具链的人,甚至可以在很短时间内跑通第一版。
问题在于,能跑起来只是起点。真正让推理模型稳定的解决工程中的实际问题就没有那么简单了。
把嵌入式 AI 理解成"MCU 跑神经网络",就像把电机控制理解成"让电机转起来"。第一句话不能说错,但真正的工程问题还包括启动、负载、保护、噪声、温升、寿命、异常工况和安全边界。
二、第1条信息:模型前面的数据链路,往往比模型更难
嵌入式 AI 项目里,最容易被低估的是数据链路。很多人讨论模型时喜欢从网络结构开始
他的老板听到他学习我的课程之后,第一反应也是问了:设计了几层的网络,用了多少神经元。
但在设备端,模型看到的不是"抽象数据",而是 ADC 采样值、I2S 音频流、IMU 三轴数据、摄像头帧、温湿度曲线、电流波形或多传感器同步结果。
这些数据只要前端稍微变化,模型输出就可能变得不可靠。这就是为什么嵌入式 AI 很少只是"算法移植"。
它首先是一个数据工程问题:采样频率是否稳定,窗口长度是否合理,滤波顺序是否和训练一致,归一化参数是否一致,异常样本是否覆盖真实工况,标签是不是来自可靠规则或人工确认。
任何一个环节处理不好,后面的神经网络再漂亮,也只是建立在不可靠输入上。
所以一个成熟的嵌入式 AI 项目,通常会非常重视数据采集器、数据版本、预处理脚本、板端预处理代码和验证数据集。真正难的不是让模型"会算",而是保证模型每次拿到的输入都符合它训练时理解的世界。
三、第2条信息:单片机不是小电脑,资源约束会改变方案
在 PC 或服务器上,一个模型多几十 KB、推理多几毫秒,很多时候不算大事。在 MCU 上,这些都是硬约束。Flash 放不下,固件就无法发布;RAM 不够,推理还没开始就失败;推理时间太长,采样任务、控制任务、通信任务都可能被拖住;功耗超出预算,电池设备的生命周期会直接缩水。
很多人只看模型文件大小,这是不够的。MCU 上真正紧张的往往不是权重,而是中间激活值和临时缓冲区。一个模型看起来只有几十 KB,但推理时可能需要更大的工作区。TFLite Micro 里常见的 Tensor Arena,STM32Cube.AI 生成报告里的 activation buffer,本质上都在提醒同一个问题:模型运行时需要一张"工作台",这张工作台必须在 RAM 里。
算子支持也是实际难点。模型里一个桌面端很普通的层,到了 MCU 工具链里可能不支持,或者支持但没有优化实现。没有命中 CMSIS-NN、厂商 NN 库或 NPU 加速路径,推理时间可能和预期差很多。模型结构不是越新越好,而是要和目标芯片的算子库、内存布局和加速单元匹配。
演示项目关心什么
模型能不能输出结果,串口能不能打印分类,准确率看起来是否不错。
产品项目关心什么
最坏情况下推理多久,RAM 峰值多少,是否影响实时任务,是否能升级,异常输入是否有兜底。
四、第3条信息:模型输出不是产品决策,分数不能直接变动作
神经网络通常输出一个分数、概率或类别,但产品需要的是动作。异常分数超过多少才报警?连续几次异常才停机?环境噪声变大时是否降低敏感度?模型置信度很低时怎么办?传感器断线时是否禁止模型输出?这些都不是神经网络自动解决的问题。
成熟的设计通常不会把规则系统完全删掉,而是让规则和模型分工。规则负责硬边界、保护条件和可解释兜底;模型负责复杂模式、趋势识别和早期预警。比如电流超过绝对安全阈值时,不需要模型同意,系统必须保护;但在电流尚未越界、振动模式已经异常时,模型可以提前给出维护提示。
这也是"没啥难度"这句话最容易误导的地方。它把推理函数当成最终答案,却没有看到后处理、迟滞、去抖、置信度门限、异常兜底、人工复核、日志记录和策略升级。产品不是模型竞赛,产品要对每一次动作负责。
五、第4条信息:上线以后,现场会重新考一遍模型
嵌入式 AI 最大的压力来自现场。训练集永远不可能覆盖所有工况,设备老化、传感器漂移、安装差异、温度变化、电磁干扰、用户使用方式改变,都会让输入分布慢慢偏离训练时的样子。模型不是烧进去就万事大吉,它需要验证、监控和版本管理。
这就带来一批纯工程问题:
-
如何记录模型版本和数据版本?
-
如何复现某一次误报?
-
如何判断是模型问题、传感器问题还是预处理问题?
-
固件升级时模型和阈值是否一起更新?
-
新模型上线后能否回滚?
-
设备离线运行时如何保留关键日志?
上面这些问题,不知道那些无能的老板能不能想到。
所以嵌入式 AI 项目的交付物,不应该只有模型文件,还应该包括数据采集规范、预处理定义、资源报告、推理时序、决策策略、异常兜底、验证集、现场日志和升级方案。这些东西加在一起,才叫嵌入式 AI 工程。
欢迎有不同意见的"老板们"和同学们,在评论区讨论、交流!