文章目录
NLP技术演进主线
NLP的架构经历了规则系统->统计方法->机器学习->深度学习的发展。
在深度学习之前,NLP的核心是特征工程,即专家设计并从语料中提取特征后交给模型,后者根据特征决策。
从深度学习开始,NLP的核心成为了表示学习,不再依赖人工设计和提取特征,模型直接接收分词后的文本序列,自主从语料中理解语言结构,学习特征表示或决策。
特征工程 :人(专家)告诉模型"应该看什么"
表示学习 :模型自主学习"应该关注什么"
现代大模型都属于表示学习的范畴。
表示学习(深度学习)经历了 RNN->LSTM->GRU->Seq2Seq->Seq2Seq+Attention->Transformer的发展,Transformer正是现代大模型的基石。
1)RNN
RNN(Recurrent Neural Network,循环神经网络)的核心思想是逐个读取句子中的词语,并在每一步结合当前词和前面的上下文信息,不断更新对句子的理解,其基本结构如下。
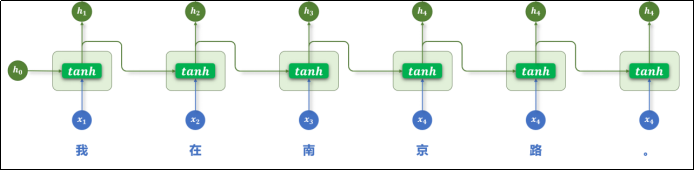
RNN的问题在于
- 长期依赖建模困难:当文本序列很长时,经过多级传递,早期输入的影响难以保留。
- 难以并行计算:每个词的处理都依赖上一个词的输出,难以并行计算。
2)LSTM
LSTM(Long Short-Term Memory,长短期记忆网络)是在RNN基础上的优化,引入了记忆单元(Ct)和门控机制(遗忘门(紫色σ)、输入门(橘黄色σ)和输出门(红色σ)),一定程度上缓解了RNN长期建模困难的问题。
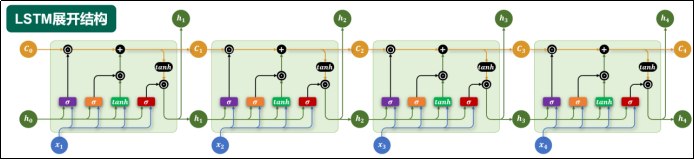
但是,LSTM引入了新的问题
- 参数量大,计算开销大:LSTM引入了新的组件,大幅增大了模型的参数量。
此外,RNN的问题并没有完美解决 - 并行计算难的问题没有解决
- 长期依赖建模依然困难:LSTM只是缓解了这个问题,当序列超长时,早期输入仍然会被遗忘。
3)GRU
Gated Recurrent Unit(GRU)在LSTM基础上做出了改进,减少了参数量:
- 去掉了记忆单元。
- 优化门控机制,将三个门改为两个:重置门(橘黄色σ)、更新门(紫色σ)。
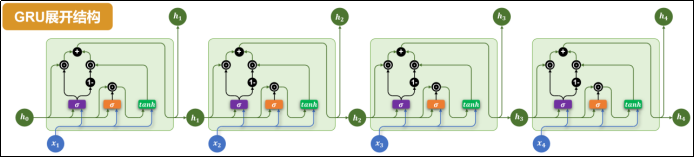
GRU改善了LSTM,但RNN固有的两个问题依然没有解决。
- 长期依赖建模困难。
- 难以并行计算。
4)Seq2Seq
Seq2Seq是专门为以动态输出为主的NLP任务设计的深度模型架构,这类任务的特征是输入输出均为序列且长度可变,如机器翻译、文本摘要等。
基本架构如下,由一个编码器和一个解码器构成。编码器和解码器的主要架构通常是(RNN / LSTM / GRU)。

Seq2Seq存在两个问题
- 信息压缩困难,语义表达受限
编解码器中间的特征表示长度固定,面对长句时,大量信息丢失,成为了"信息瓶颈"。 - 缺乏动态感知,解码难以精准生成
生成过程中,不同位置的目标词,往往依赖源句中的不同关键信息,如生成主语时可能更依赖开头,生成谓语或宾语时,可能需要参考句中或句末内容。
在固定表示下,解码器无法有选择地关注源句中的不同部分。
5)Seq2Seq+Attention
为了解决Seq2Seq的不足,引入了Attention(注意力)机制。核心思想是在解码时动态从编码器的隐藏状态(隐藏状态和源句中的词一一对应)中提取信息,不再仅仅依赖一个固定的上下文向量。
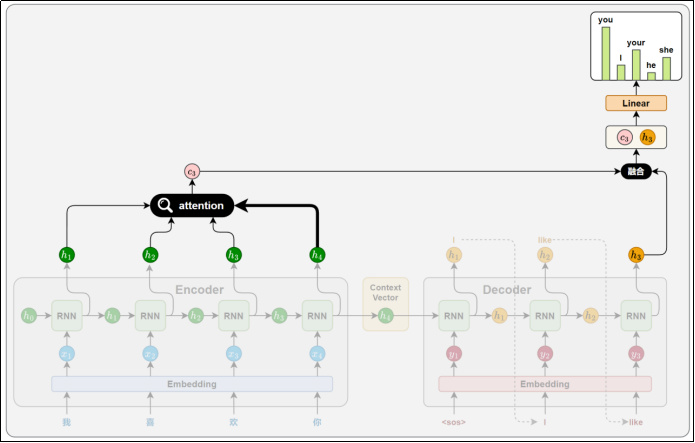
然而,模型架构依然是以RNN为基础,仍然存在固有缺陷
- 长期依赖建模困难
- 难以并行计算
6)Transformer
Attention机制也具备建模词语间依赖的关系,理论上,可以彻底摒弃RNN,直接作为神经网络的核心。
2017年,谷歌发表了《Attention Is All You Need》,提出了Transformer。该模型彻底摒弃了RNN结构,转而使用注意力机制直接建模序列中各位置之间的关系。通过这种方式,Transformer不仅显著提升了训练效率(支持并行计算),也增强了模型对长距离依赖的建模能力(任意两个都可以直接计算注意力,不存在长程间接依赖)。
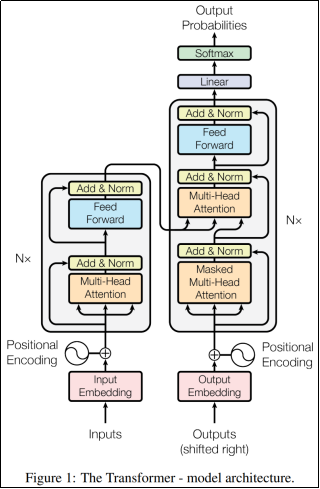
Transformer沿用了Seq2Seq的编解码器架构,左侧为编码器,右侧为解码器。编码器内部包括自注意力层和前馈层(多个线性层的组合),解码器包含自注意力层、交叉注意力层和前馈层。
为什么大语言模型都采用Transformer架构?
Transformer 胜出的原因可以用三点概括:并行计算、全局依赖、可扩展性。
1)支持并行计算,训练效率高
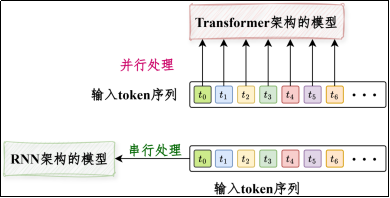
基于RNN的模型在时间步上天然串行。基于Transformer的模型可在序列维度上并行计算,使得大规模训练成为现实。
2)全局依赖建模更直接
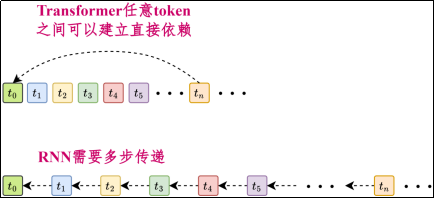
注意力机制允许任意两个位置直接建立信息通路,不需要像RNN那样通过多步传递才能"间接关联",因此更擅长长程依赖与复杂结构关系建模。
3)工程可扩展性好:规模变大仍能持续受益
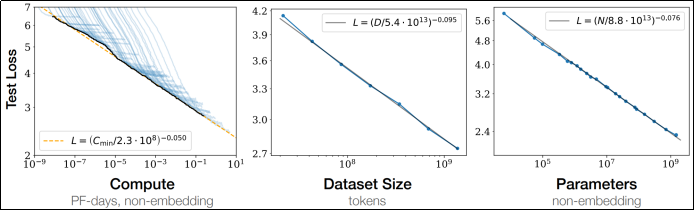
在实践中,Transformer在参数规模、训练数据、训练步数提升时通常能持续提升效果,形成稳定的"规模化收益",这使其成为大模型时代的默认架构选择。
为什么现代大语言模型是Decoder-Only(仅解码器架构)?
1)Transformer架构的三种技术路线
Transformer架构的模型主要有三条技术路线:
- Encoder-Only(仅编码器架构)
- Encoder-Decoder(编码器-解码器架构,原版Transformer的架构)
- Decoder-Only(仅解码器架构)
Encoder-Only架构
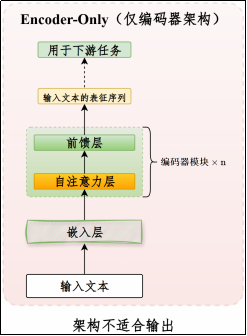
该架构以"编码输入 "为核心,输出的是固定维度的向量表示 (特征),擅长表征学习与判别式任务。
Decoder-Only架构
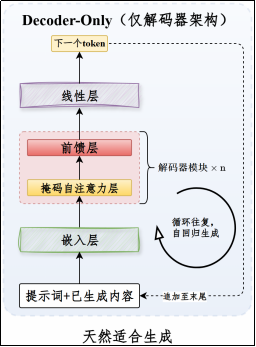
核心机制是自回归语言建模,天然契合自回归生成任务。
Encoder-Decoder架构
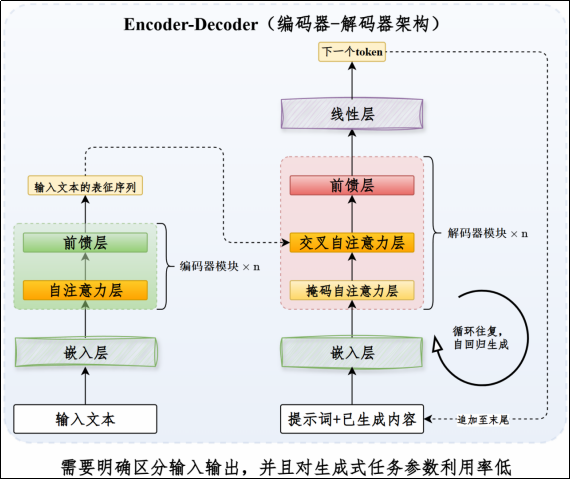
该架构需要明确区分输入和输出,对于翻译这样输入输出区分明确的任务非常友好。
为什么采用Decoder-Only?
- 更适合自由对话/连续生成:不需要人为把"输入/输出"硬切分;Encoder-Only不适合用于生成任务,而Encoder-Decoder在这类场景里切分不自然,训练与使用范式更繁琐。
- 参数利用率更高、性价比更高:同样总参数和训练预算下,Encoder-Decoder的参数分散在Encoder和Decoder;Decoder-Only参数更集中用于生成建模,效率更高。
- 普适性好 :大多数NLP任务都可转化为"给定上下文预测下一个token"的自回归生成任务;通用LLM想要获得跨任务泛化能力,就需要自回归机制。
因此Decoder-Only架构成为主流选择,现代LLM基本都是(Decoder-Only)模型。
Decoder-Only的流程
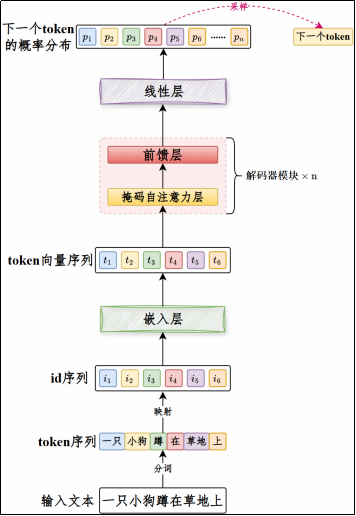
工作流程大致如下
- 输入文本通过分词器切分为token(词元),然后根据词表(id和token的映射)转换为id序列,再通过嵌入矩阵(Embedding)映射为token向量序列,再输入大模型。
- 在模型内部经过自注意力层、前馈层的处理(重复若干次)输出下一个token的概率分布。
- 根据上一步的概率分布采样,确定下一个token的id,然后通过词表映射为token。
将新生成的token追加到输入文本末尾,重复(2)和(3)。
相关文章: