最近在做一个项目,要进行手写数字识别,手写数字识别作为一个最简单的应用,但是最简单的 OCR 模型在识别时,总是差强人意。使用大模型,虽然能够识别,但是这么简单的任务使用参数上亿的模型简直是浪费,且使用大模型使用这个任务,效果也不是很明显。
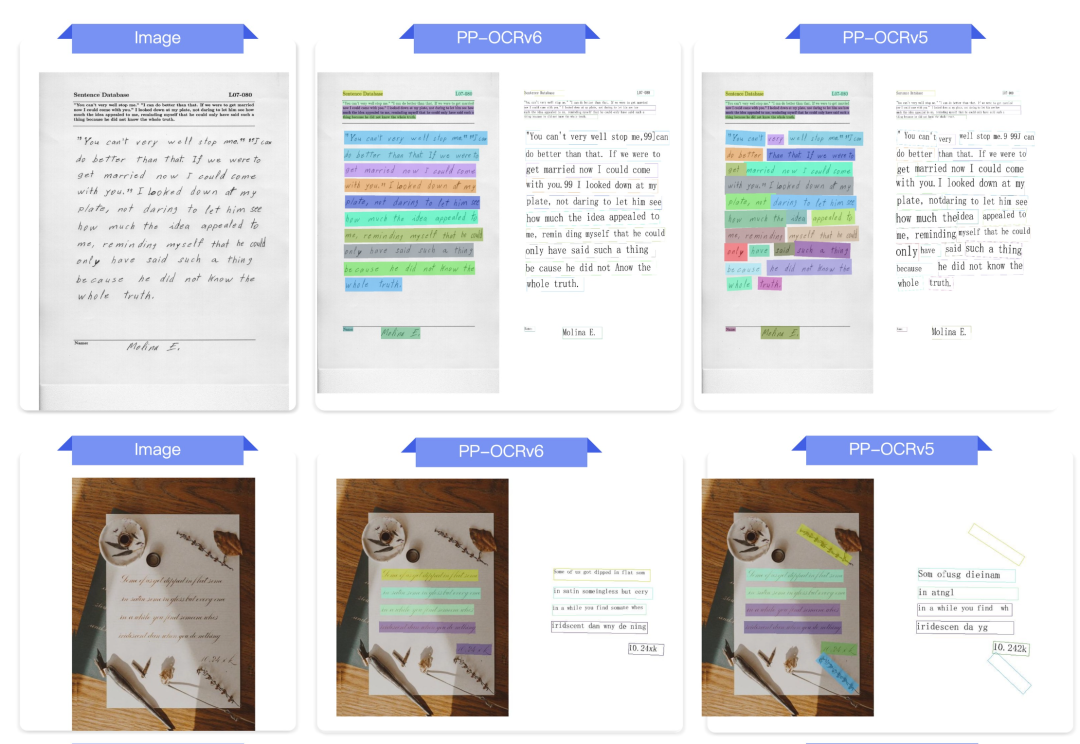
最后,使用到了PP-OCRv5 模型,但是最近 paddle OCR 更新了其模型,PP-OCRv6模型强势开源,其参数虽然较少,但是其效果精度却全面超越。今天我们就认识一下这个百度开源的PP-OCRv6模型。
先说结论:小身材,大能量
PP-OCRv6这次一口气推出三档模型:
-
Tiny版
:仅1.5M参数
-
Small版
:7.7M参数
-
Medium版
:34.5M参数
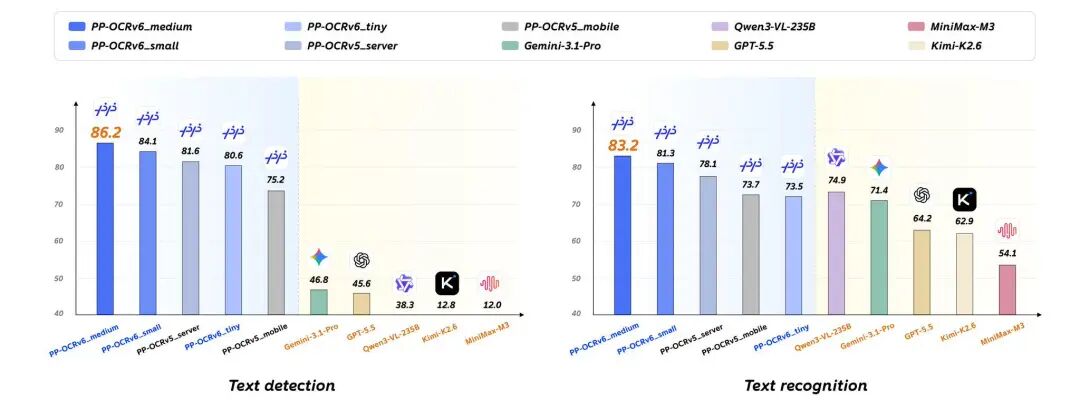
然后拿这三个"小不点"去跟Qwen3-VL-235B(2350亿参数)、GPT-5.5、Gemini-3.1-Pro这些"庞然大物"正面硬刚------结果全赢了。
Medium版识别准确率83.2%,检测Hmean达86.2%,直接超越以上所有大模型,参数量却少了几千倍。这场景,就像一个小学生在奥数比赛上把博士们按在地上摩擦。
大模型做OCR,为什么总翻车?
很多人可能会想:GPT-5.5这么强,做个文字识别不是小菜一碟?
现实是:根本不行。
论文里总结了VLM做OCR的三大死穴:
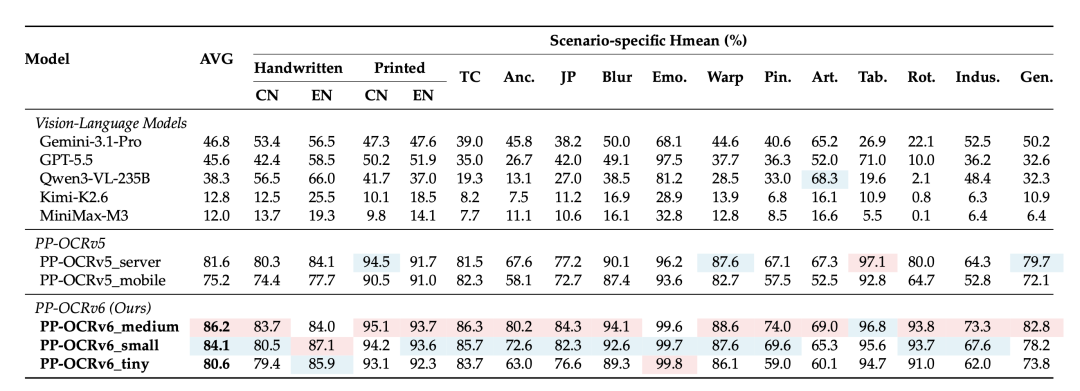
① 定位稀烂 大模型框出来的文字框,经常歪歪扭扭,压根贴不紧文字边界。PP-OCRv6 Medium的检测Hmean是86.2%,而Gemini-3.1-Pro只有46.8%,GPT-5.5只有45.6%。差距将近40个百分点,这不是输,这是降维打击。
② 幻觉问题很致命 这是VLM最要命的毛病。大模型看到一张写着故意错别字的图,它会"好心"帮你改掉------识别出来的字根本不是图上写的!
PP-OCRv6在幻觉测试中准确率高达93.2%,而Qwen3-VL-235B只有80.56%,MiniMax-M3更是只有72.6%。对于金融票据、医疗档案这类场景,幻觉就是事故。

③ 算力成本完全不现实 几百亿参数的大模型跑一张图要多少资源?部署成本、延迟统统是噩梦。PP-OCRv6 Tiny在Intel Xeon CPU上的推理速度比上一代移动端模型快3.9倍,这才是工业落地该有的样子。
PP-OCRv6到底改了什么?
这次升级不是简单堆数据,而是架构和数据双管齐下,核心创新有三个:
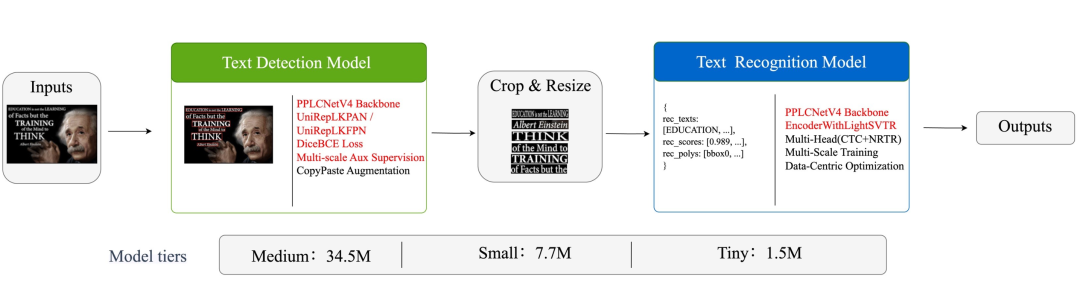
LCNetV4:一套骨架打天下
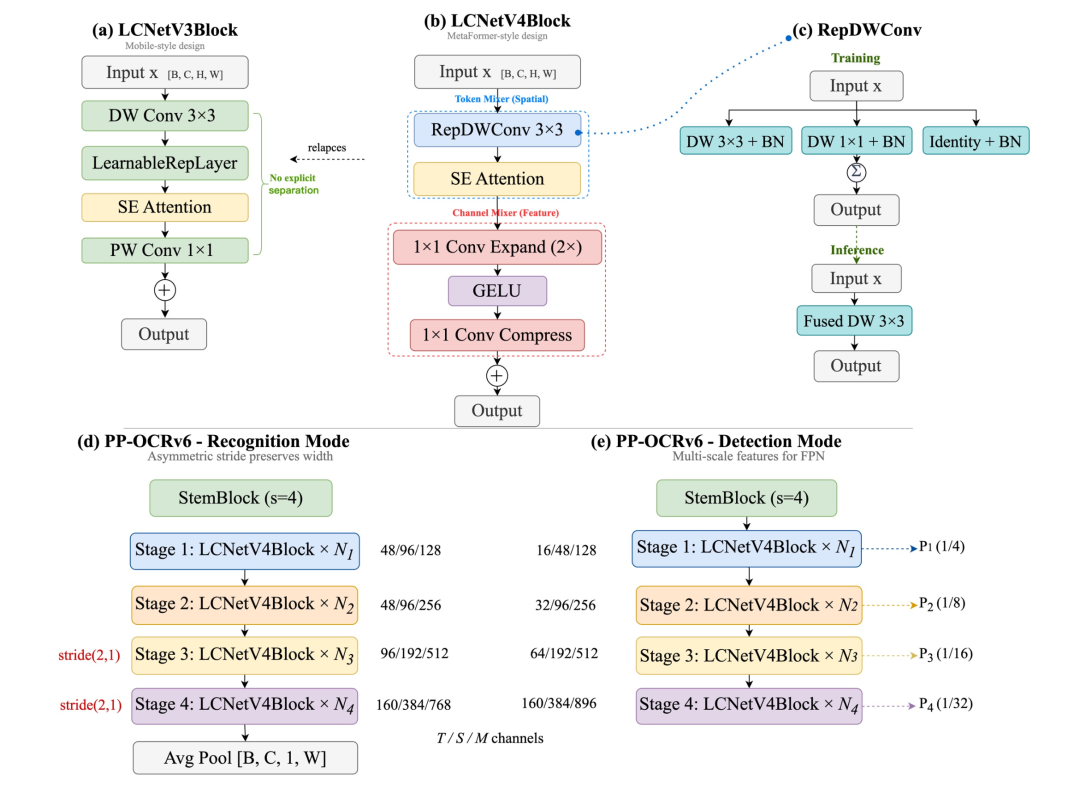
以前PP-OCR的检测和识别用的是两套不同的backbone,工程维护极其麻烦。这次PP-OCRv6设计了全新的LCNetV4,一套骨架同时支持检测和识别两个任务,只通过不同的stride配置来区分。
LCNetV4的核心思路借鉴了MetaFormer范式,把每个block拆成两部分:
-
Token Mixer
:负责空间特征聚合(用的是3×3深度卷积)
-
Channel Mixer
:负责通道特征变换(1×1卷积)
两者解耦之后,各自优化,互不干扰。实验证明,光是这一个改动,识别准确率就提升了+2.23%,是单项改进里贡献最大的。
另外Token Mixer还引入了结构重参数化 (RepDWConv)------训练时用三路并行分支(3×3、1×1、Identity)获得更丰富的梯度信息,推理时自动合并成一个3×3卷积,推理成本零增加,纯赚。
RepLKFPN:检测脖子升级
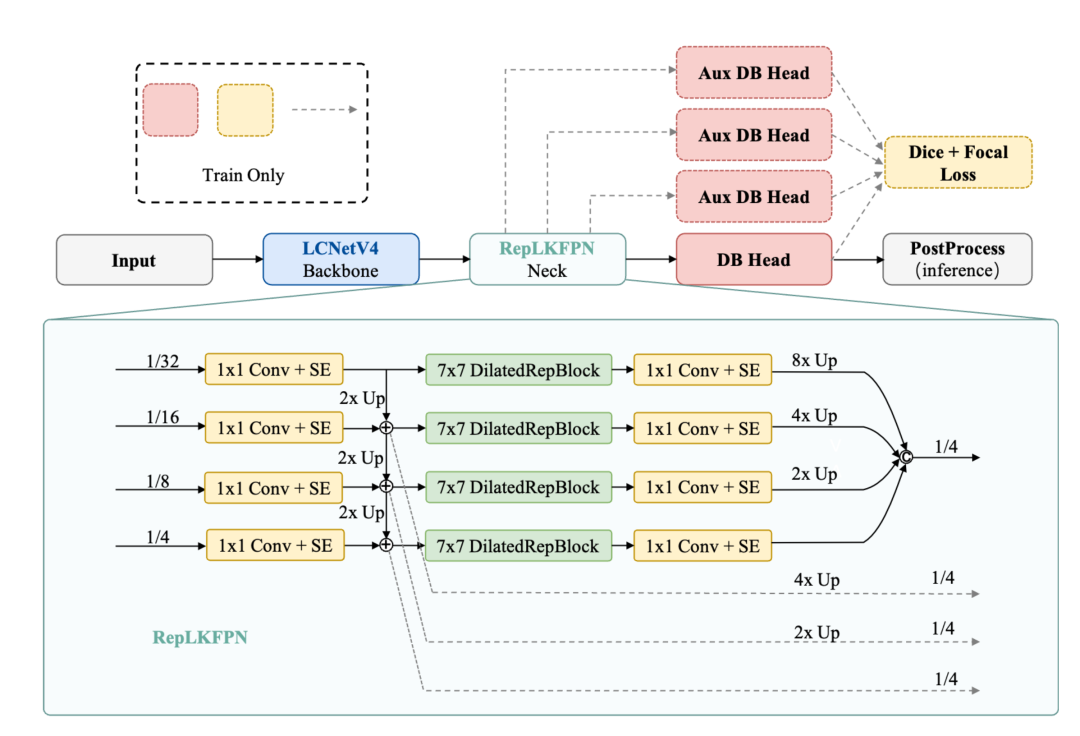
检测任务的FPN颈部也做了大手术,用RepLKFPN替换了原来的RSEFPN。
核心改进是把每个金字塔层级的局部感受野从3×3扩大到了7×7,同时参数量反而从172K降到了118K。大感受野意味着对大文字和密集排列文字的理解能力更强,这也解释了为什么在工业字符、旋转文字等场景上提升特别明显。
LightSVTR:识别脖子减负
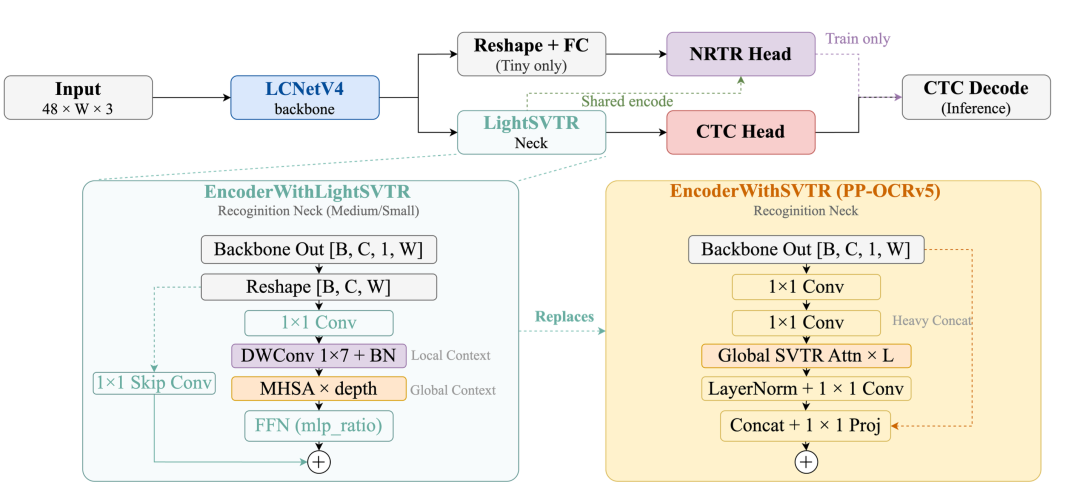
识别模块的颈部也做了重新设计,提出EncoderWithLightSVTR。
原来的方案把全局注意力结果和输入特征在通道维度上拼接,参数量很重。新方案改成加法跳跃连接,同时在全局注意力之前先做一个1×7的局部卷积,先感知相邻字符的局部上下文,再做全局交互。这种"局部→全局"的顺序更符合文字的序列本质,效果也更好。

50种语言,一个模型搞定
之前PP-OCR做多语言需要针对每种语言单独训练模型,这次Medium和Small版本直接用一个统一模型支持50种语言,包括中文(简繁)、英文、日文,以及法语、德语、西班牙语等46种拉丁字母语系语言。

在英文独立测试集上,PP-OCRv6 Medium达到88.4%,比PP-OCRv5的英文专用模型还高了2.4个百分点------用一个通用模型打赢了专用模型,这才叫效率。
真实速度测试:CPU上也能飞
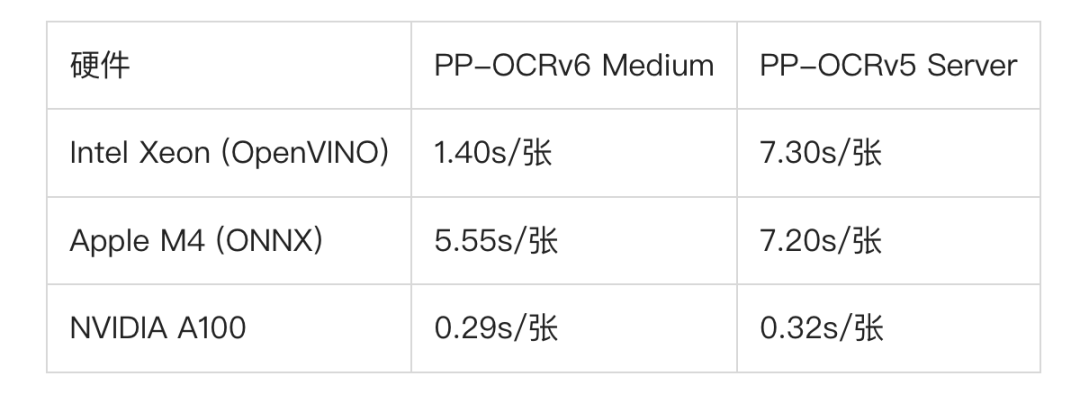
Medium版在Intel Xeon CPU上比上代Server版快了整整5.2倍,而且精度还更高。Tiny版在苹果M4上只要0.35秒一张,端侧部署完全没压力。
总结一下
PP-OCRv6这次发布,我认为有几个值得关注的意义:
第一,重新定义了"够用"的边界。1.5M的模型能打过2350亿参数的大模型,说明专用轻量模型在垂直任务上的天花板远比想象中高。
第二,幻觉问题在专用模型这里根本不存在。CTC解码架构天然不会"脑补",这对严肃业务场景是刚需。
第三,工程友好性拉满。一套LCNetV4骨架覆盖从边缘设备到服务器的全部场景,运维成本大幅下降。
代码和模型全部开源,地址在 GitHub PaddlePaddle/PaddleOCR,模型权重也上传到了HuggingFace。API 也全面开放,代入自己的 API key 即可。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程

