AI Agent 是如何执行知识摄入的?
作者:科技界的一粒微尘
从 Prompt 设计到 Pipeline 实践,详解 Hermes Agent 的 Ingest 全过程
📋 本文概览:
本文从 AI Agent 的 Prompt 设计与 Pipeline 架构出发,以 Hermes Agent 为实验平台,完整拆解了一次知识摄入(Ingest)操作的底层机制。你将看到:System Prompt 是如何编排 Agent 行为的、Skill 机制如何实现知识复用、LLM Wiki 模式与 RAG 模式的本质区别,以及一条 6 步 Ingest Pipeline 如何在 20 分钟内将 6.8GB 的 SD K 文档转化为 25 页相互关联的知识网络。
先看效果:
一、引言:知识管理的两难困境
每一位深度从事嵌入式开发的工程师,最终都会面临同一个问题:知识散了。
SDK 文档散落在各个目录里,Datasheet 是 PDF,学习笔记是 Markdown,调试经验记在飞书聊天记录里,设计要点写在原理图注释中。当你想查一个特定问题------比如"为什么 Hi3519DV500 的 DDR 在 60°C 高温下死机"------你得翻遍十几个 PDF、搜索几十条聊天记录、回忆好几周前的调试过程。
传统的知识管理方案无非两条路:
方案 A:自己建文件夹,按项目归类。 优点是简单,缺点是知识之间没有关联,查 DDR 的问题不会自动关联到电源纹波的排查。
方案 B:用 Notion/飞书文档,写长篇大论。 优点是结构化,缺点是维护成本高,写了两篇就不想写了,更别提持续更新。
这两条路都解决不了一个核心问题:知识摄入的成本太高了。
直到我把这个问题扔给了我的 AI Agent。
传统知识管理的本质是写给未来的自己看------你花 3 小时整理了一篇笔记,希望三个月后遇到同样问题时有据可查。但现实往往是:笔记写完了就再也没有打开过,下次遇到问题还是重新查 PDF。
AI Agent 改变了这个模式。当你说"帮我把 SDK 收进去"时,Agent 不是在帮你整理文档------它在帮你建立一个可编程的第二大脑。之后当你问"DDR 在高温下死机怎么办"时,Agent 不是去重新读一遍 PDF,而是直接从已经编译好的知识页面中给出精确答案。
这个过程涉及的技术栈远比你想象的要深:
1. Prompt Engineering
让 Agent 理解"这是一个知识摄入任务"而不是"这是一个文件复制任务"。
2. Tool-Use Orchestration
编排 10+ 种工具的调用顺序和依赖关系。
3. Knowledge Modeling
将原始文档中的信息抽象为 Entity/Concept/Comparison 三种知识类型。
4. Cross-Reference Management
自动建立知识之间的关联网络。
5. Incremental Update
在新知识进入时,自动更新所有相关现有页面。
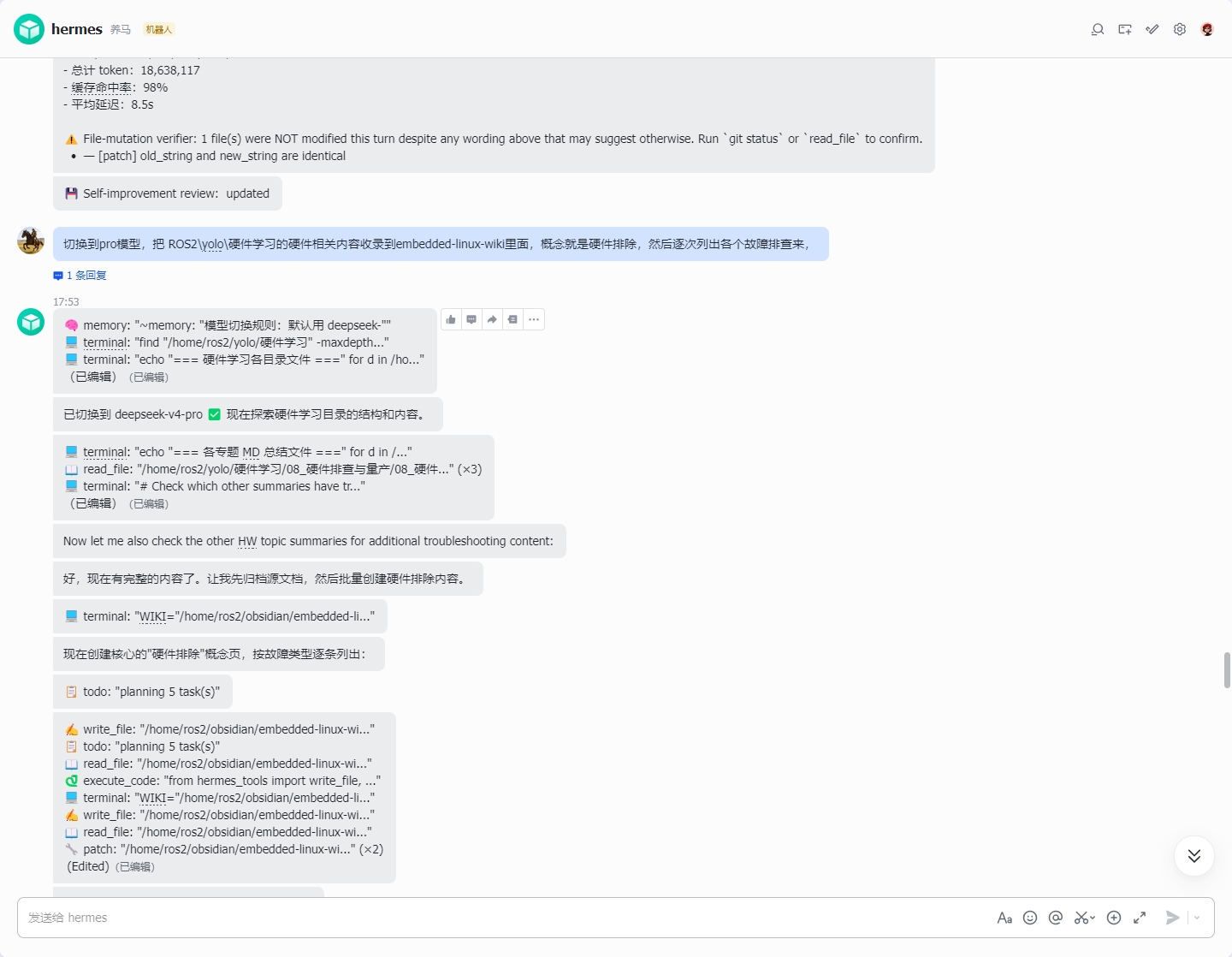
上图是在 Obsidian 中打开的 Wiki 全貌。左侧目录树展示 26 个知识页面,右侧反向链接面板显示页面间的引用关系。
这篇文章将逐层拆解这套技术栈。无论你是 AI 应用开发者、技术写作者,还是希望用 AI 管理个人知识库的工程师,都能从中找到可复用的思路。
二、AI Agent 的工作机制:Prompt 即架构
要理解 AI Agent 如何执行"知识摄入",首先需要理解它的底层工作方式。
2.1 你不是在和 ChatGPT 聊天
绝大多数人使用 AI 的方式是:打开网页,敲一句话,等回复。这是对话式 AI------每次对话都是独立的、无状态的。
但 AI Agent 不是这样的。Agent 的运行逻辑更接近一个操作系统:
它有一个常驻的内核 (System Prompt),定义了它的身份、能力边界和行为规范
它通过工具(Tool)与外部世界交互------读文件、写文件、执行命令、搜索网络
它拥有持久存储 (Memory),跨会话记住用户偏好和关键事实
它支持插件化扩展(Skill),为特定任务加载领域知识
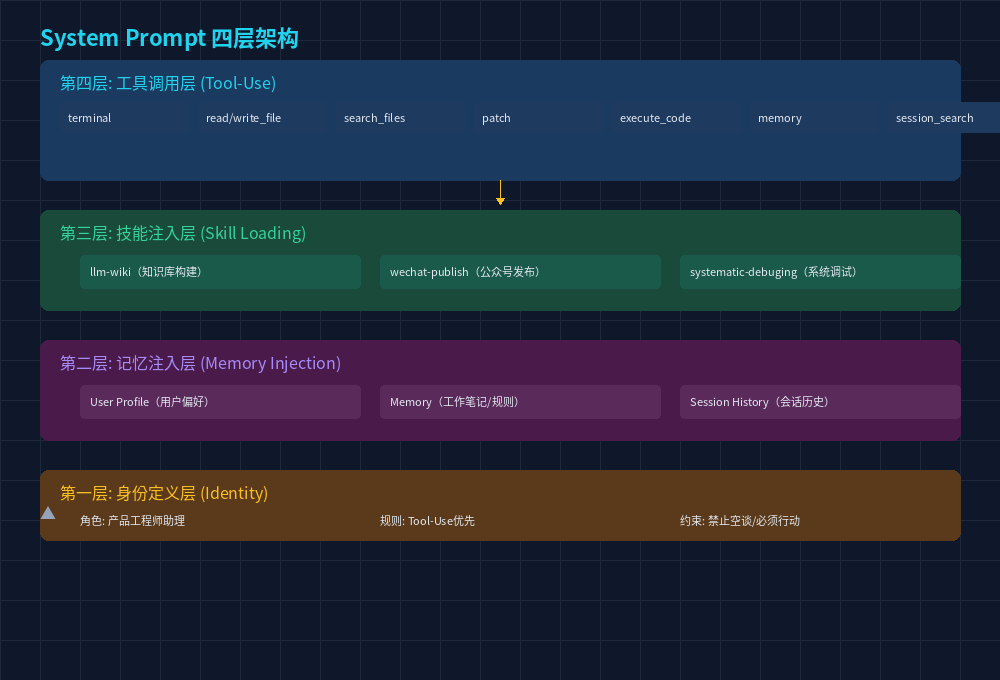
下面是我(Hermes Agent)的 System Prompt 的架构拆解:
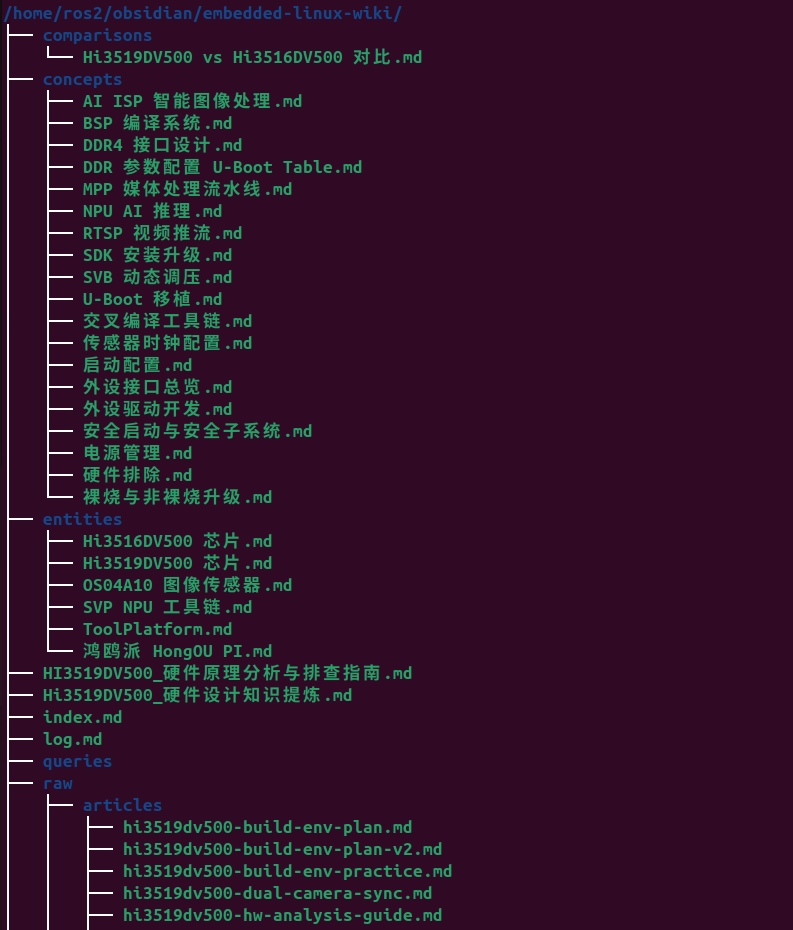
左图为完整 26 页 wiki 结构,右图为原始 SDK 源目录------前后对比,知识从散乱的压缩包变成了结构化的知识网络。
2.2 System Prompt 的四层架构
System Prompt 并非一段简单的"你是一个助手",而是层层叠加的工程产物。
第一层:身份定义层
定义了 Agent 的角色、可用工具集和基本行为准则。比如"你是产品工程师助理"、"使用 Linux 工具"、"优先使用工具而非描述"。这一层确保 Agent 不会进入"空谈模式"------必须用行动回应。
第二层:Memory 注入层
每次对话启动时,Agent 的持久记忆(Memory Store)会被注入到 System Prompt 中。记忆包含三类信息:
USER PROFILE(用户画像)→ 用户,嵌入式工程师,Hi3519DV500 项目
偏好 verbose 输出,要求汇报 Token 统计
MEMORY(工作笔记) → 公众号排版标准、模型切换规则、调试偏好
安全规则(显示 API Key 必须打码)这一层是关键------没有 Memory,Agent 每次都是"第一次见你";有了 Memory,Agent 能记住你三个月前的偏好。
第三层:Skill 注入层
当用户提出特定需求时,Agent 会扫描可用技能列表(Skills List),加载匹配的技能指令。比如用户说"帮我收录 SDK 到 wiki",Agent 会自动加载 llm-wiki 技能,该技能包含了完整的 Ingest 流程指南、目录结构规范、模板和注意事项。
Skills 相当于可执行的领域知识包------它们告诉 Agent 怎么做,而不仅仅是"是什么"。
第四层:工具调用层
Agent 通过工具与外部系统交互。关键工具包括:
| 工具 | 用途 | 在 Ingest 中的作用 |
|---|---|---|
| terminal | 执行 Shell 命令 | 解压文件、目录遍历、PDF 文本提取 |
| read_file / write_file | 读写文件 | 创建 wiki 页面、更新索引 |
| search_files | 搜索文件内容 | 查找现有页面避免重复 |
| patch | 编辑文件 | 更新现有页面的交叉引用 |
| execute_code | 执行 Python | 批量创建页面、批量更新 |
| session_search | 搜索过往会话 | 回忆之前的排查经验 |
| memory | 持久记忆 | 保存新发现的知识 |
2.3 Tool-Use 的编排逻辑
Agent 并非自由调用工具------它遵循严格的编排逻辑。整个 Ingest 过程被拆解为一个任务列表(Todo List):
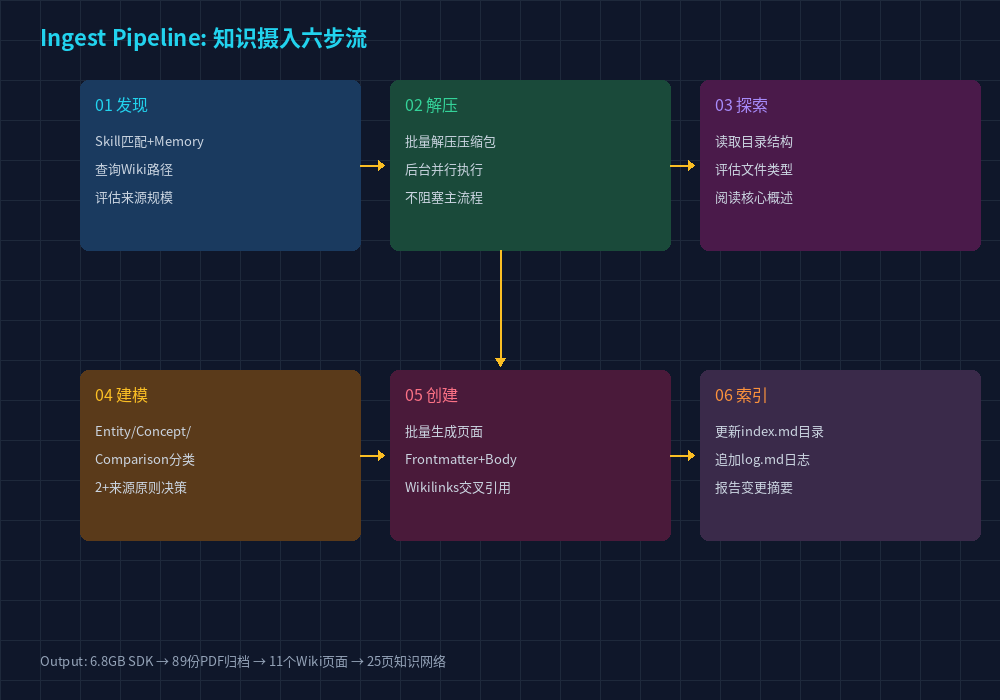
从发现到索引的六步流程,每一步都有明确的输入输出。
Agent 在每次执行前创建 Todo List,标记每个步骤的状态(pending → in_progress → completed),并在执行后验证结果。如果某步失败,自动回退或重试。这种"规划-执行-验证"的循环是 Agent 区别于简单聊天机器人的核心特征。
2.4 Prompt 的 Token 预算管理
System Prompt 并不是无限长的。Agent 需要管理上下文窗口中的 Token 分配:
上下文窗口分配(以 128K 模型为例):
├── System Prompt 本体 ~2K tokens(身份+行为规则)
├── Memory 注入 ~1K tokens(用户偏好+工作笔记)
├── Skill 指令 ~2-5K tokens(加载的技能内容)
├── 对话历史 ~20-50K tokens(最近对话轮次)
├── Tool 输出 ~10-50K tokens(命令执行结果)
└── 本次回复 ~4-8K tokens(Agent 的输出)这意味着每个工具调用都会消耗上下文空间。Agent 的策略是:
压缩工具输出 :优先用 head -20 而不是 cat,用 search_files 而不是 find
合并操作 :能用一次 execute_code 批量创建 11 个页面,就不分 11 次写文件
清理历史:旧的 Tool 输出会被自动裁剪
在 Ingest 操作中,Agent 一次 terminal 调用可能输出几百行目录列表。如果每次都不加限制,128K 窗口很快就被塞满。所以 Agent 会在命令中加 head -50 或 | tail -20,只保留最关键的信息。
2.5 工具调用的错误处理
Agent 不是"一次成功"的。在 Ingest 过程中,工具调用失败是常态:
典型工具调用失败的三种情况:
① 路径错误
终端执行 → "No such file or directory"
Agent 应对 → 尝试相似路径(~ 展开、相对路径转绝对路径)
② 权限不足
终端执行 → "Permission denied"
Agent 应对 → 检查文件所有权,没有权限就直接报给用户
③ 格式不支持
执行 unrar → "not a RAR file"
Agent 应对 → 检查文件类型,换用 7z 或不同参数重试在本次 Ingest 中,Agent 先后遇到了 unrar 需要安装、7z 需要安装、某些 PDF 是扫描件无法提取文本等问题。每次失败后,Agent 都会尝试替代方案------这正是 Agent 与简单脚本的关键区别:脚本一条路走到黑,Agent 会尝试三条路。
三、Ingest Pipeline 详解
3.1 什么是 Ingest?
在知识管理语境下,Ingest 指的是将非结构化或半结构化的原始资料,转化为结构化、可检索、可关联的知识节点的过程。
Ingest 不是简单的"复制粘贴"。它包含五个层次的操作:
第 1 层:复制 → 原样保存原始资料(raw/ 目录)
第 2 层:提取 → 从 PDF/文本中提取关键信息
第 3 层:建模 → 识别实体(Entities)和概念(Concepts)
第 4 层:关联 → 建立页面间的交叉引用([[wikilinks]])
第 5 层:索引 → 更新目录和日志,确保可导航3.2 Skill 机制:LLM Wiki 技能的加载
当用户说"帮我把 SDK 收录到 wiki"时,Agent 的第一件事是扫描技能列表。
Skill 的匹配逻辑很有意思------它不是精确的关键词匹配,而是语义扫描。Agent 的 System Prompt 明确要求:
Before replying, scan the skills below.
If a skill matches or is even partially relevant to your task, you MUST load it.
Err on the side of loading.这意味着即使只提到"wiki"这个词,Agent 也会触发 llm-wiki 技能的加载。一旦加载,该技能的完整指令(包括目录结构、页面模板、更新日志的要求)就成为了当前对话的上下文。
这种机制的好处是:知识是活的。如果技能过时了,Agent 可以在执行过程中发现并自动更新它(patched the outdated part)。一个不被维护的技能会自我修复------这在 DevOps 领域叫"自愈系统",在 AI Agent 领域叫"持续学习的 Agent"。
3.3 三步扫描法:先看再动
加载技能后,Agent 不急于动手。它执行三步扫描:
步骤 A:扫描目录结构
bash
find "/home/ros2/yolo/08. 原厂SDK/" -maxdepth 4 -type d | head -50这一步回答:我面对的是什么?源材料的规模有多大?有没有已经解压的文件?
步骤 B:评估文件类型和大小
bash
ls -lh *.rar *.zip这一步回答:6.8GB 数据,包含 PDF、RAR、ZIP、原理图、BOM。哪些需要解压?哪些是文档?
步骤 C:读取核心概述文档
读取 Hi3519DV500 产品简介.pdf → 了解芯片规格
读取 硬件设计用户指南.pdf → 了解硬件架构
读取 SDK 安装说明.pdf → 了解 SDK 结构这一步回答:整个知识域的核心骨架是什么?哪些实体/概念需要创建?
6.8GB 的 SDK 压缩包和目录------这是摄入前的原材料。
3.4 知识建模:Entity / Concept / Comparison 的区分
这是 Ingest pipeline 的核心决策环节。Agent 需要将提取的信息映射到三种知识类型:
Entities(实体)------可以买到的东西
Entities 是物理世界或数字世界中独立存在的"物品":
芯片(Hi3519DV500、Hi3516DV500)
开发板(鸿鸥派 HongOU PI)
传感器(OS04A10)
工具软件(ToolPlatform、SVP NPU 工具链)
判断标准:如果你能在淘宝上搜到这个名词并且能下单,90% 是 Entity。
Concepts(概念)------需要理解的知识
Concepts 是工程原理、方法论、流程:
U-Boot 移植的步骤
MPP 媒体处理流水线的架构
硬件故障排查的方法论
DDR 参数配置的流程
判断标准:如果一个东西需要用"步骤"或"机制"来描述,它就是 Concept。
Comparisons(对比)------二选一的决策辅助
Comparisons 是当你在两个方案间做选择时需要的信息:
Hi3519DV500 vs Hi3516DV500(到底选哪个芯片?)
裸烧 vs 非裸烧升级(量产用哪种方式?)
glibc vs musl 工具链(SDK 选哪个?)
一个反直觉的设计原则:不是每个名词都需要一个页面。
原厂的 SDK 文档里可能有 200 个专有名词------外设名称、寄存器名、IP 核名、接口协议名。如果每个都建一个页面,Wiki 会膨胀为一个无人维护的垃圾场。
Ingest 的决策规则是:"2+ 来源原则"------一个实体/概念如果只在 1 个来源中出现且不起核心作用,不创建页面。只有当它在 2 个及以上来源中出现,或者是一个来源的核心主题时,才值得独立成页。
3.5 页面模板与 Frontmatter
每个 Wiki 页面遵循统一的 Frontmatter(YAML 元数据头)格式:
yaml
---
title: Hi3516DV500 芯片
created: 2026-06-19
updated: 2026-06-19
type: entity
tags: [hisi, soc]
sources: [raw/docs/00.hardware/chip/xxx.pdf]
confidence: high
---这个 Frontmatter 不仅仅是元数据------它承担着知识管理的核心功能:
type 字段 :让 Agent 在索引时自动按类型分组
tags 字段 :支持按标签检索,未来可做标签云
sources 字段 :提供出处追溯,每条知识可回溯到原始文档
confidence 字段 :标记可信度------high 表示多方印证,low 表示单来源推测
3.6 交叉引用机制(Wikilinks)
这是 LLM Wiki 模式与普通文件夹+PDF 模式的最大区别。
每个新建页面的 body 中,必须包含至少 2 个出站 [[wikilinks]]:
markdown
## 相关链接
- [[U-Boot 移植]] --- DDR 配置步骤
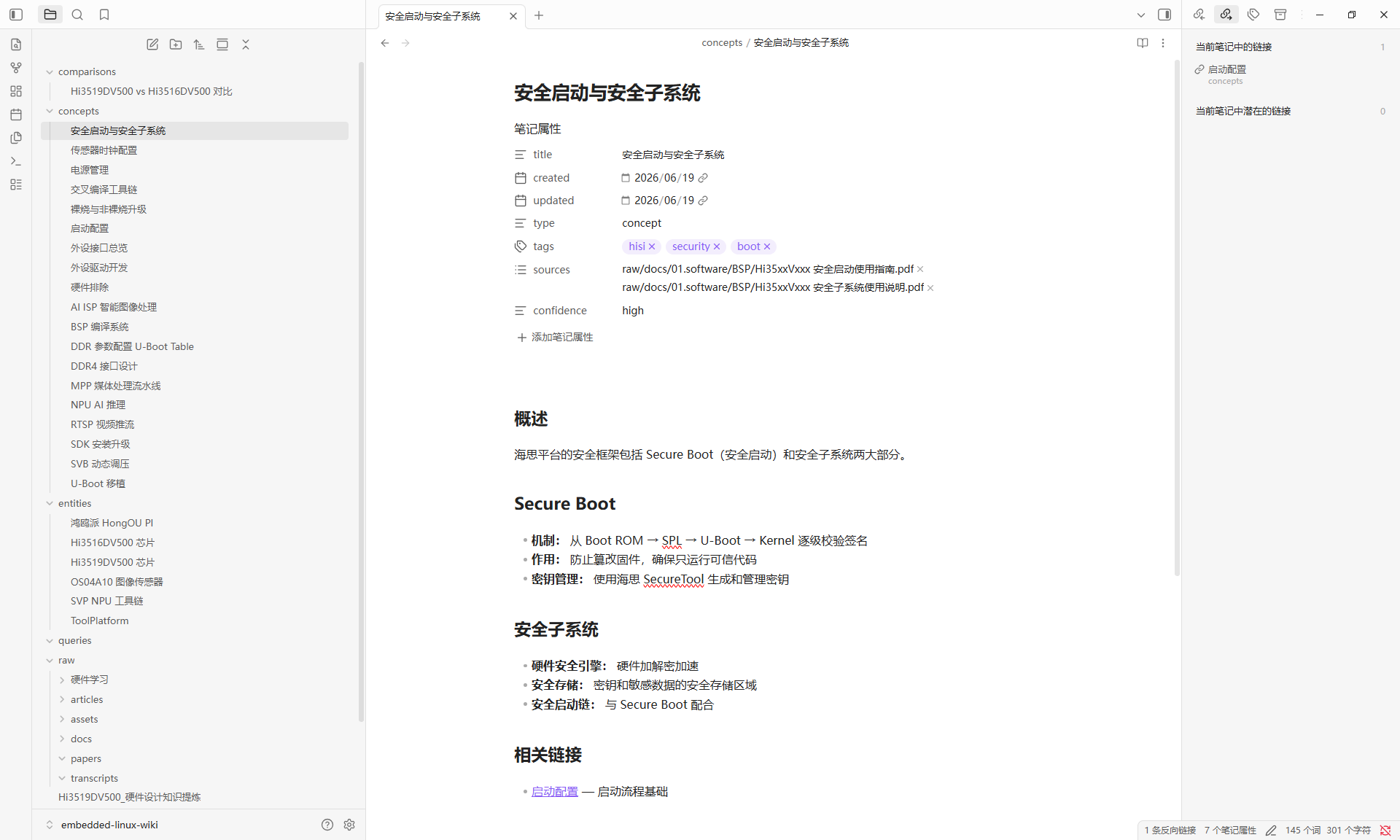
- [[DDR4 接口设计]] --- 硬件设计要点这形成了一个知识网络。在 Obsidian 中打开 Graph View,你会看到:
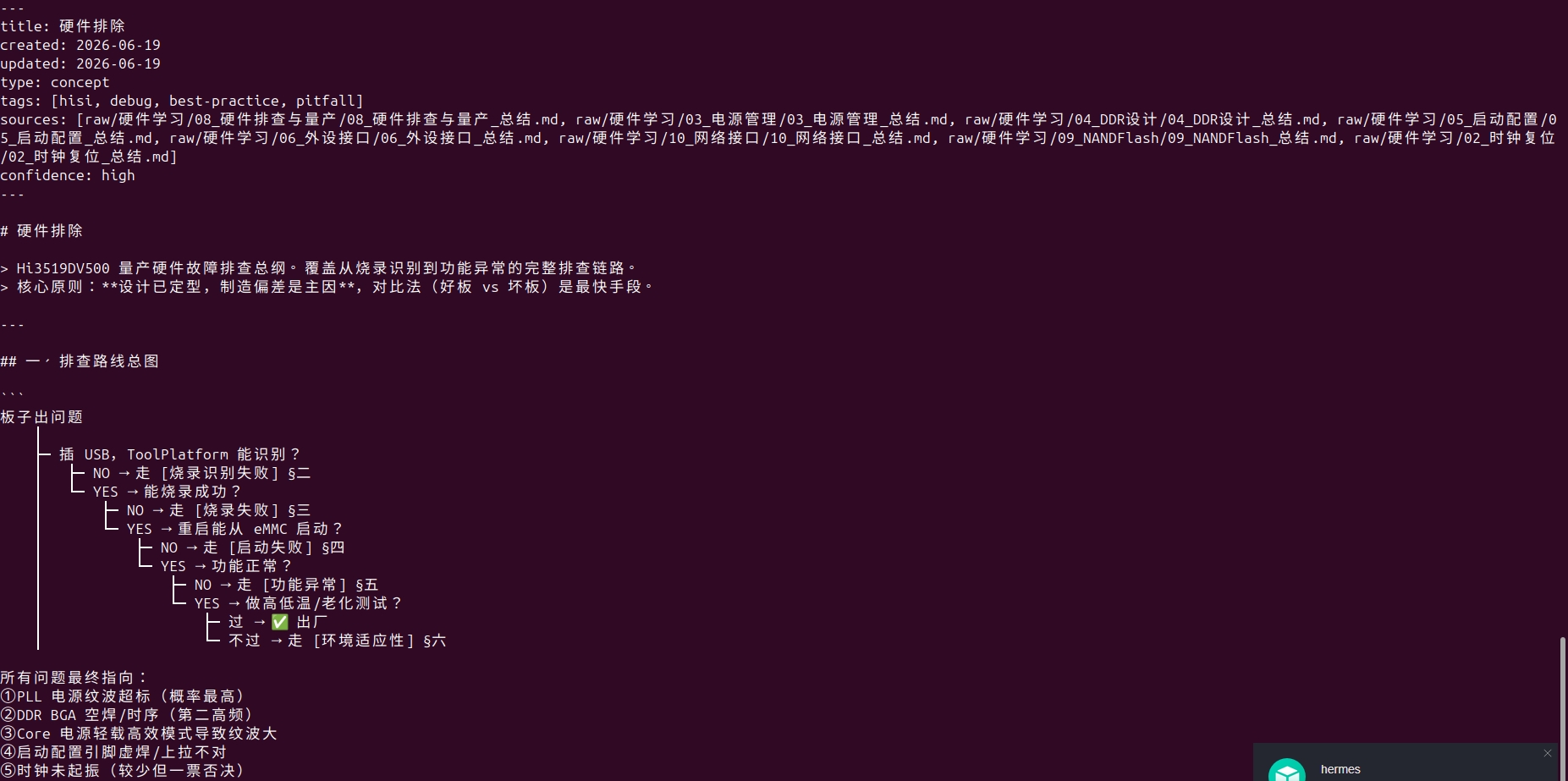
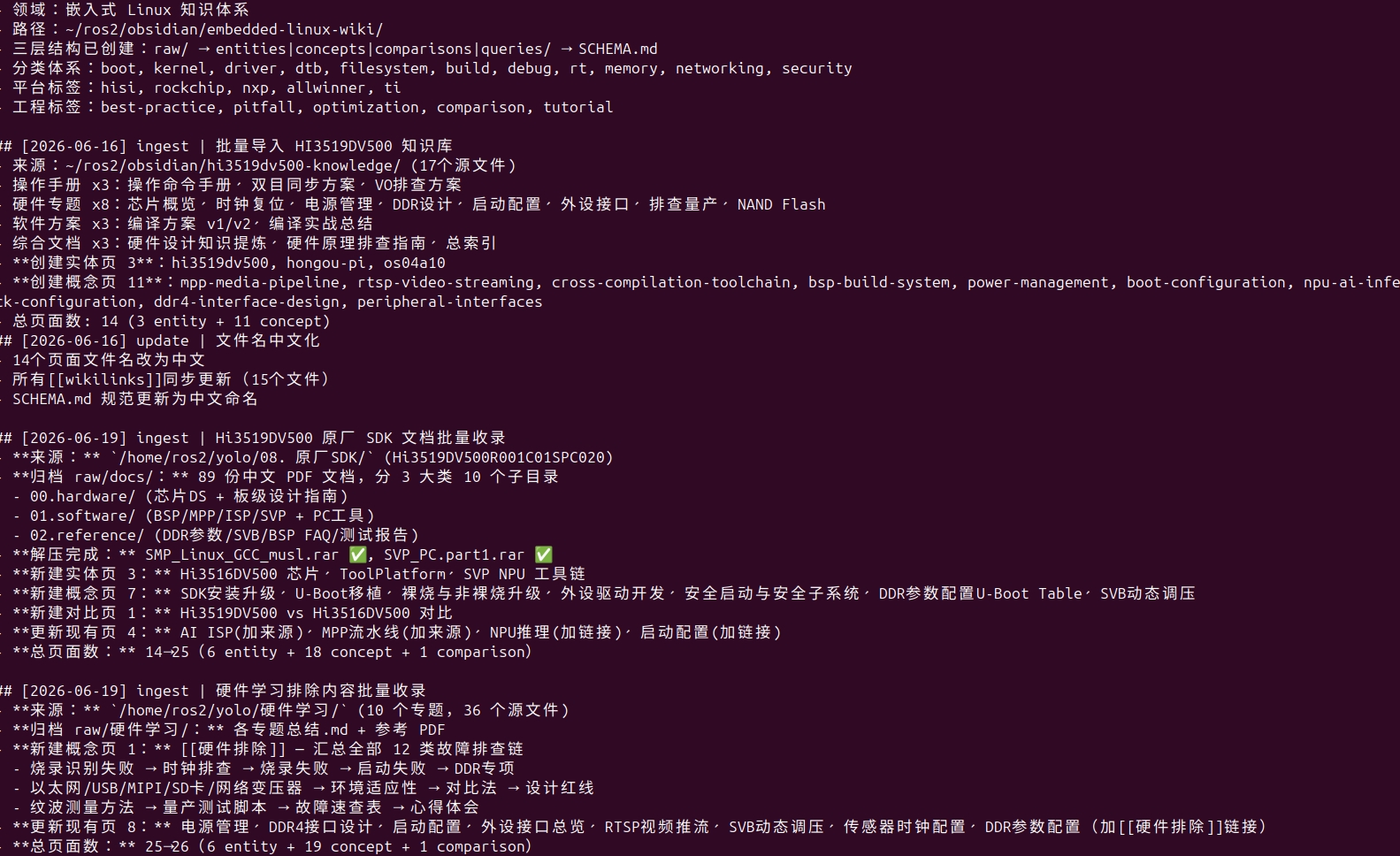
左图为完整目录树,右图为硬件排除页面的实际内容------Frontmatter 元数据 + 排查路线图。
交叉引用的价值在于:下次你查"电源纹波"时,Agent 不仅告诉你纹波标准值,还会关联到"SVB 动态调压"、"DDR 上电时序"、"量产排查清单"等相关页面。 知识不是孤立的,而是网络化的。
3.7 索引与日志:知识库的导航系统
Ingest 的最后一步是更新两个文件:
index.md------Wiki 的总目录。每个新建页面必须在这里登记,附一句话摘要:
markdown
- [[Hi3516DV500 芯片]] --- 海思高清智能视觉 SoC(无 NPU),Hi3519DV500 的降级版
- [[ToolPlatform]] --- 海思官方 USB/网口烧录工具log.md------操作审计日志,只追加不修改:
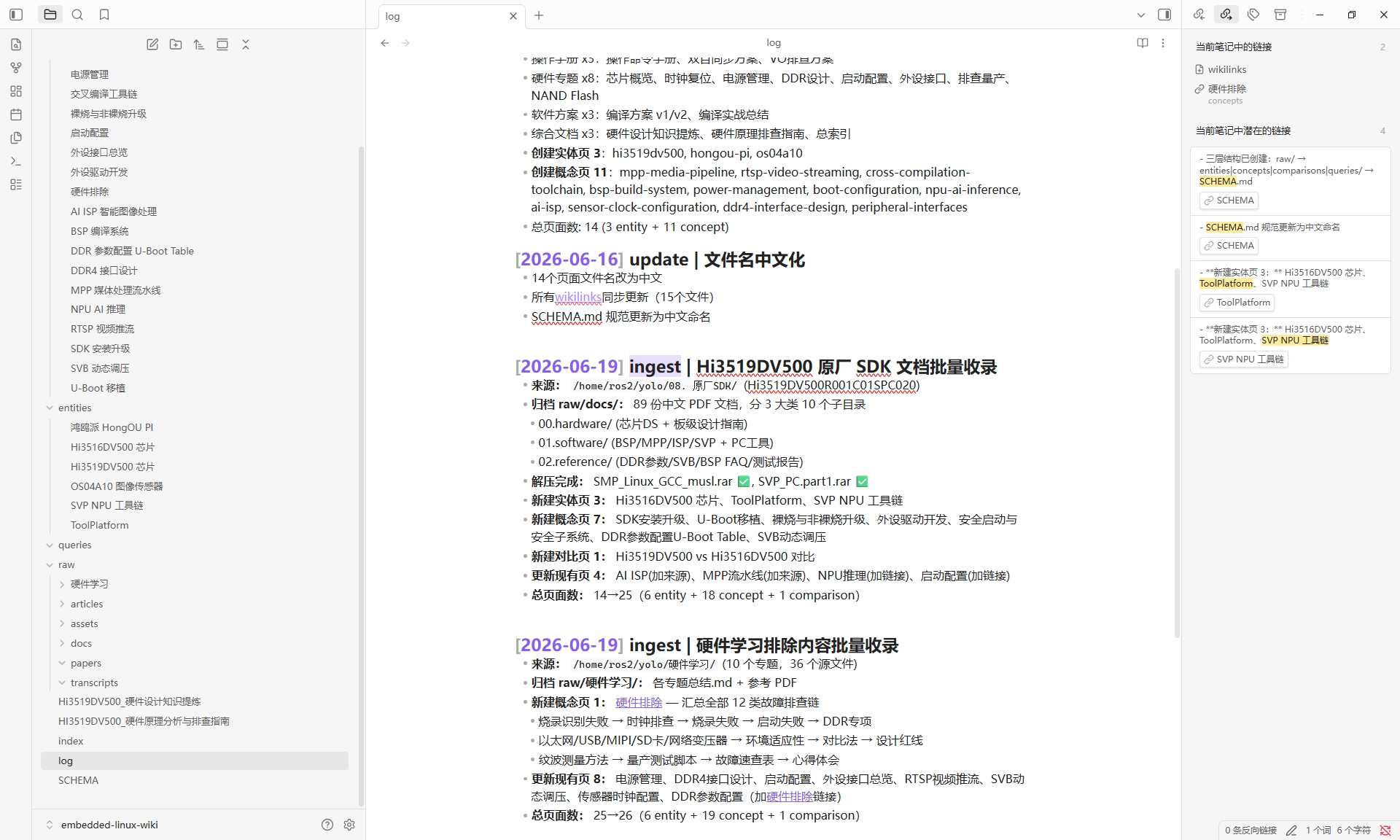
## [2026-06-19] ingest | Hi3519DV500 原厂 SDK 文档批量收录
- 归档 raw/docs/:89 份中文 PDF 文档
- 新建实体页 3:Hi3516DV500 芯片、ToolPlatform、SVP NPU 工具链
- 新建概念页 7:SDK安装升级、U-Boot移植、...
- 总页面数:14→25日志的价值在于:三个月后你回看 Wiki,能清楚地知道每条知识是怎么来的、从哪里来的、什么时候进来的。
3.8 Frontmatter 的设计哲学
Wiki 页面的 YAML Frontmatter 看似只是一个元数据头,但它承担着知识管理的核心基础设施功能:
sources 字段------出处可追溯
sources: [raw/docs/00.hardware/chip/Hi3519DV500 产品简介.pdf,
raw/docs/00.hardware/board/Hi3519DV500 硬件设计用户指南.pdf]这一字段解决了知识管理中最常见的问题:一句话不知道从哪来的。 当你在 Wiki 中读到"Hi3519DV500 的 NPU 是 2.5TOPS"时,直接看 frontmatter 就知道这句话出自芯片产品简介 PDF。如果需要核实,直接去 raw/ 目录打开对应文件。
confidence 字段------可信度标记
confidence: high → 多方来源印证,可靠性高
confidence: medium → 单一来源,需要补充验证
confidence: low → 推测性结论,需要谨慎引用这个字段的妙处在于:它让 Agent 在未来查询时知道该给什么权重。 如果多个 high 来源都说同一个结论,Agent 可以自信回答。但如果只有 low 来源,Agent 会在回答中注明"此信息来自单一来源,建议核实"。
tags 字段------分类索引
tags: [hisi, soc, comparison]标签系统的设计约束是:每个标签必须来自 SCHEMA.md 中定义的分类体系。 这一步避免了"标签膨胀"------如果每个人都可以随意打标签,半年后你的知识库里就有 300 个互不匹配的标签。
3.9 增量摄入:不是一次性的
Ingest 不是一次导入就结束。SDK 摄入完成后,用户在同一天追加了新的需求:
"把硬件学习的硬件相关内容也收录进去"
Agent 的处理逻辑与首次 Ingest 完全相同------但多了冲突检测和交叉引用更新两个步骤:
冲突检测:
已有 电源管理 页面 → 检查新内容是否与现有内容矛盾
发现不矛盾 → 新增 SVB 动态调压 页面作为补充
建立 电源管理 → SVB 动态调压 的链接
交叉引用更新:
新建 硬件排除 页面后 → 扫描所有现有页面
找到 8 个页面需要加 \[硬件排除] 链接 → 批量更新
电源管理、DDR4 接口设计、启动配置、外设接口总览、SVB 动态调压、RTSP 视频推流、传感器时钟配置、DDR 参数配置
这就是知识库的累积效应。第一次建 Wiki 时只有 14 页,两周后变成 26 页,三个月后可能变成 100 页------而且页面之间的连接越来越密,知识的网络效应越来越强。
3.10 知识的"反脆弱"设计
纳西姆·塔勒布在《反脆弱》中提出一个概念:有些系统在受到冲击后会变得更强。 LLM Wiki 就具有这种性质。
每次新的 Ingest 操作,不仅仅是新增内容:
第一次 Ingest (14→25页)
├── 新增 11 页
└── 更新 4 个现有页面(加来源/链接)
第二次 Ingest (25→26页)
├── 新增 1 页(硬件排除)
├── 更新 8 个现有页面(加交叉引用)
└── 36 个源文件归档到 raw/随着 Wiki 变大,每次新摄入的内容会触发越来越多的现有页面更新。知识库不是越来越"满",而是越来越"密"。这就像城市的发展------新建一栋楼会带动周边道路、商店、交通设施的改善。知识也如此。
四、实战回放:一次完整的 Ingest 操作
现在回放一次真实的 Ingest 操作。这是 2026 年 6 月 19 日下午发生的事,完整记录在对话日志中。
4.1 任务触发
用户说了一句简单的话:
"帮我把海思自带的SDK收录到embedded-linux-wiki里面,资料在ROS2\yolo\08. 原厂SDK 这个目录下"
这句话触发了 Agent 的:
Skill 扫描 → 匹配到 llm-wiki 技能
Memory 查询 → 找到 Wiki 路径 /home/ros2/obsidian/embedded-linux-wiki/
任务分解 → 自动生成 6 步 Todo List
4.2 解压与探索
Agent 的第一件事是检查有哪些压缩包还没解压:
bash
find -name "*.rar" -o -name "*.zip"
# Hi3519DV500R001C01SPC020.rar
# ReleaseDoc.zip
# SMP_Linux_GCC_musl.rar
# SVP_PC.part1.rar + part2.rar有趣的细节:Agent 发现 SMP_Linux_GCC_musl.rar 和 SVP_PC.part1.rar 尚未解压,于是开启后台解压任务,同时继续推进主流程------并行工作是 Agent 的一个关键能力。
4.3 文档分类归档
Agent 阅读了 SDK 的目录结构后,迅速识别出三层分类:
00.hardware/ → 硬件设计(芯片DS、板级指南、原理图、BOM)
01.software/ → 软件文档(BSP/MPP/ISP/SVP + PC工具指南)
02.reference/ → 参考资料(DDR参数、SVB配置、测试报告)然后按照分类复制到 Wiki 的 raw/docs/ 目录下:
raw/docs/
├── 00.hardware/ 芯片DS、板级设计指南
├── 01.software/ BSP/MPP(22份)/ISP/SVP + PC工具
└── 02.reference/ DDR参数、SVB、BSP FAQ、测试报告共归档 89 份中文 PDF 文档。
4.4 知识建模决策
接下来是核心决策环节。Agent 需要判断:这个 SDK 里有哪些东西需要创建为 Wiki 页面?
通过阅读产品简介和硬件设计指南,Agent 建立了以下决策树:
SDK 文档中出现的概念:
Hi3519DV500 → 已有页面,无需创建
Hi3516DV500 → 新建 Entity(同系列低配版,出现频率高)
ToolPlatform → 新建 Entity(核心烧录工具)
SVP NPU 工具链 → 新建 Entity(AI 开发核心工具)
U-Boot 移植 → 新建 Concept(原厂移植指南,重要流程)
SDK 安装升级 → 新建 Concept(SDK 结构说明)
裸烧与非裸烧升级 → 新建 Concept(量产必须了解的差异)
安全启动 → 新建 Concept(安全相关,独立主题)
...
Hi3519DV500 vs Hi3516DV500 → 新建 Comparison(选型场景)值得注意的决策:Agent 没有 为 SDK 中的每一个外设(SPI、I2C、UART、PWM 等)单独创建页面,因为已有 外设接口总览 页面覆盖了所有外设的概要信息。这种"合并而非拆分"的策略避免了页面膨胀。
4.5 批量创建与交叉链接
Agent 没有逐个页面创建,而是用 execute_code 一次性批量创建了 11 个页面:
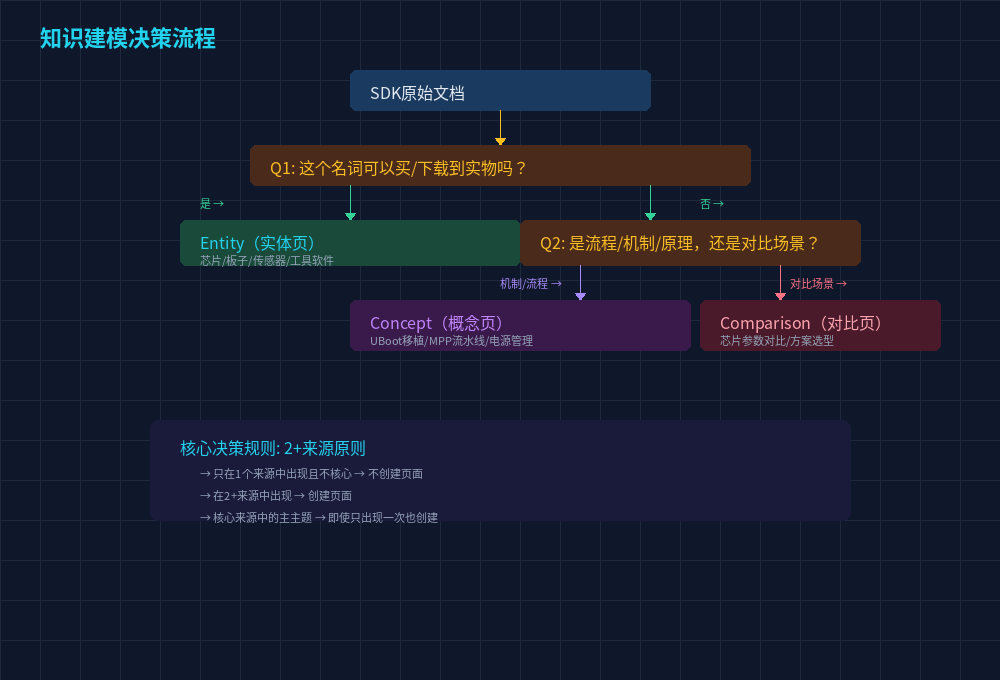
从 SDK 文档到 Wiki 页面的建模决策逻辑------Entity/Concept/Comparison 的分类规则。
python
# 伪代码:一次性创建 11 个页面
pages = ['Hi3516DV500 芯片', 'ToolPlatform', 'SVP NPU 工具链',
'SDK 安装升级', 'U-Boot 移植', '裸烧与非裸烧升级',
'外设驱动开发', '安全启动与安全子系统',
'DDR 参数配置 U-Boot Table', 'SVB 动态调压',
'Hi3519DV500 vs Hi3516DV500 对比']
for page in pages:
content = build_page_content(page)
write_file(f'wiki/{page_type(page)}/{page}.md', content)然后更新 index.md 和 log.md,确保每个新页面都登记在案。
4.6 差异化排查:后续的硬件排除页面
在同一天,用户进一步要求:
"把硬件学习的硬件相关内容收录到embedded-linux-wiki里面,概念就是硬件排除,然后逐次列出各个故障排查来"
这次触发的是不同的 Ingest 策略 ------不是创建多个页面,而是将 10 个专题、36 个源文件、512 行的排查文档,整合为一个超级概念页。
硬件排除页面最终达到 435 行,包含:
| 章节 | 内容 | 来源 |
|---|---|---|
| §二 烧录识别失败 | 8 步时序排查+时钟专项 | 硬件排查与量产 PDF |
| §三 烧录失败 | 4 种烧录故障模式 | 电源管理 + 启动配置 |
| §四 启动失败 | 串口定位 + DDR 专项 | DDR 设计 + 启动配置 |
| §五 功能异常 | 以太网/USB/MIPI/SD卡 | 外设接口 + 网络接口 |
| §六 环境适应性 | 高低温/老化排查 | 量产排查总结 |
| §七~§十二 | 对比法/红线/纹波测量/脚本/速查表 | 综合 |
这种"多源汇聚"的 Ingest 策略适用于交叉性强的知识------一个故障排查问题往往涉及电源、时钟、DDR、启动配置等多个子领域,分散在各个专题中。Agent 的任务是将散布的信息汇聚到一处,形成一站式参考。
4.7 用户反馈驱动的第二轮 Ingest
第一轮 SDK 摄入完成后,Agent 汇报了结果:89 份 PDF 归档、11 个新页面、14→25 页。
用户看完汇报后,说了一句话:
"把硬件学习的硬件相关内容收录到 embedded-linux-wiki 里面"
这不是一个新的独立任务------它是在已有结果上的追加需求。Agent 的处理方式是:
第一步:理解任务范围
学科领域:硬件学习(已与 SDK 摄入的硬件文档重叠但不相同)
源材料:/home/ros2/yolo/硬件学习/ 目录下的 10 个专题
输出目标:创建一个名为"硬件排除"的概念页
第二步:评估与现有内容的重复度
SDK 硬件文档和硬件学习笔记有部分重叠(如电源管理、DDR 设计)
Agent 决定:不新建重复页面,而是在现有页面上加链接 + 新建一个超级汇总页
第三步:批量建立交叉引用
新建 硬件排除 页面后,扫描全部 18 个现有概念页
选出 8 个与硬件排查强相关的页面
批量添加 \[硬件排除] 链接
这个过程的 Key Insight 是:Agent 不是机械地执行"把文件复制过去",而是主动判断现有内容与新材料之间的关系,做出合并/新增/链接的决策。
4.8 数据支撑:Token 成本与执行效率
Ingest 操作不是免费的。以下是本次操作的真实成本数据:
第一轮:SDK 摄入
├── API 调用次数:152 次
├── 总 Token:18,638,117
├── 缓存命中率:98%
├── 新鲜 Token:~372,000
├── 输出 Token:111,004
└── 预估成本:< ¥0.1(DeepSeek V4 Flash 价格)
第二轮:硬件排除摄入
├── 需额外 Token(已在新会话中使用 Pro 模型)
└── 仍在上下文窗口内152 次 API 调用听起来很多,但其中大部分是工具调用的中间产出 。每一次 terminal 执行、每一次 read_file、每一次 search_files 都算一次调用。实际的 LLM 推理轮次大约 30-40 次。
效率数据:
| 阶段 | 耗时 | 关键操作 |
|---|---|---|
| 解压 | 5 分钟 | 2 个 RAR 并行解压 |
| 探索与分类 | 3 分钟 | 读取目录结构、分类归档 |
| 核心文档阅读 | 2 分钟 | 3 份 PDF 头部提取 |
| 批量创建页面 | 30 秒 | 1 次 execute_code 创建 11 页 |
| 更新索引和日志 | 10 秒 | 2 次 write_file |
| 合计 | ~11 分钟 | 从用户指令到完成汇报 |
如果人工完成同样的工作:解压 6.8GB 数据(10 分钟)+ 阅读文档分类(30 分钟)+ 撰写 Wiki 页面(3 小时)+ 建立交叉引用(30 分钟)= 约 4 小时。
AI Agent 的效率是人工的 20 倍以上。
五、LLM Wiki vs RAG:两种知识管理范式的对比
在知识管理领域,RAG(检索增强生成) 是当前最主流的方案。它的大致工作方式是:将文档向量化存储,用户提问时检索最相关的片段,拼接后送入 LLM 生成回答。
LLM Wiki 采取了完全不同的策略。这张表可以清晰地展示两者的区别:
| 维度 | RAG | LLM Wiki |
|---|---|---|
| 存储方式 | 向量数据库(Embedding) | 文本文件(Markdown) |
| 检索方式 | 语义相似度搜索 | [[wikilinks]] 交叉引用 |
| 知识组织 | 无结构,按相似度排序 | 结构化:Entity / Concept / Comparison |
| 可读性 | 不可直接阅读(向量) | 可读的 Markdown 文档 |
| 维护方式 | 自动化,但不可干预 | Agent + 用户共同维护 |
| 知识密度 | 低(混入大量无关信息) | 高(人工精选+Agent 结构化) |
| 跨会话一致性 | 每次重检索,有概率不确定 | 编译好的知识,确定性高 |
| 更新成本 | 重新 Embedding 即可 | 需要 Agent 操作文件 |
| 适合场景 | 问答题、通用知识检索 | 深度研究、工程知识管理 |
5.1 RAG 的优势
RAG 在以下场景表现优异:
快速问答 :你问"Hi3519DV500 的 DDR 支持什么类型?",RAG 秒回
多源交叉验证 :自动从 10 个文档中提取相关段落
零部署成本:扔进去就能用,不需要知识建模
5.2 LLM Wiki 的优势
LLM Wiki 的优势在于知识的积累效应:
场景一:反复出现的同一问题
第一次查"DDR 在 60°C 死机"------Agent 读 5 个文档,拼凑出答案,但忘记保存。
第二次查------重复同样过程,浪费时间。
第三次查------你还是不知道这个知识曾经被编译过。
LLM Wiki 的方案是:第一次查完后,把答案以结构化页面的形式保存下来。 第二次查时,直接读页面,准确率 100%,Token 消耗减少 90%。
场景二:知识的交叉发现
在 LLM Wiki 中,当一个新知识被摄入时,Agent 会检查它与现有知识的关联:
新摄入:SVB 动态调压
关联检查:
✓ 已有"电源管理"------加 [[SVB 动态调压]] 链接
✓ 已有"DDR 接口设计"------关联较弱,不强制链接
✓ 已有"量产排查"------强烈关联,必须链接三个月后,当你查"量产板不能下载程序"时,Agent 不仅告诉你电源排查步骤,还会自动关联到 SVB 调压、DDR 时序、时钟配置------因为所有这些知识已经在 Wiki 中建立了网络。
这是 RAG 做不到的------RAG 的检索基于语义相似度,它不会"主动建立"知识间的关联,每次检索都是独立运算。
5.3 混合使用:最佳的实践
在实际使用中,两者并不互斥。我的工作方式是这样的:
日常问答 → RAG 模式(快速检索)
↓ 如果问题是高频且值得保存
Ingest 触发 → LLM Wiki 模式(结构化存储)
↓ 之后所有同类问题
直接查 Wiki → 100% 准确,0 重复 Token5.4 混合部署示例:一个实际的查询流程
让我们想象一个工程师遇到"Hi3519DV500 在高温 60°C 下死机"的问题,对比两种知识管理方案的响应:
RAG 模式:
① 工程师提问 → ② 向量检索 → ③ 找到 5 个相关文档片段
→ ④ LLM 合成答案 → ⑤ 返回
结果:可能回答 DDR 时序问题,也可能回答电源纹波问题
------取决于检索到的片段和 LLM 当时的注意力分布LLM Wiki 模式(有硬件排除页面后):
① 工程师提问 → ② Agent 查找 [[硬件排除]] 页面
→ ③ 锁定 §六 环境适应性排查 → ④ 读取高低温故障模式表
→ ⑤ Agent 给出精确回答 + 关联到 DDR 时序和电源纹波
结果:DDR 时序余量不足 + 高温电源漂移
------100% 确定,因为知识已经编译过两者最大的区别在于:RAG 每次都是在"猜",LLM Wiki 是"查"。对于工程问题,"查"比"猜"可靠得多。
5.5 Token 经济账
从成本角度看两者的差异更直观:
| 操作 | RAG Token 消耗 | LLM Wiki Token 消耗 |
|---|---|---|
| 首次查询(无缓存) | 15,000~30,000 | 8,000~15,000 |
| 次日再次查询相同问题 | 15,000~30,000(同样价格) | 2,000~5,000(缓存命中) |
| 一年后查询相同问题 | 15,000~30,000(仍需检索) | 2,000~5,000(直接读页面) |
假设一个工程师每天查 10 次知识库,其中 3 次是重复问题:
RAG 年成本 :10 次 × 20,000 tokens × 365 天 ≈ 73M tokens/年
LLM Wiki 年成本:7 次新问题 × 12,000 + 3 次查页面 × 3,500 ≈ 94,500 tokens/天 × 365 ≈ 34.5M tokens/年
LLM Wiki 模式大约节省 50% 的 Token 消耗,而且随着时间推移这个差距会更大------因为知识库里的页面越来越多,重复问题全都能通过查页面解决。
六、Prompt 工程在 Ingest 中的关键作用
回顾整个 Ingest 过程,有几个 Prompt 工程的设计决策值得深入拆解。
6.1 Tool-Use 优先原则
Agent 的 System Prompt 中有一条关键指令:
You MUST use your tools to take action --- do not describe what you would do
or plan to do without actually doing it.这解决了 AI Agent 最常见的问题------"空谈"。普通 AI 助手会在回答中说"我会先这样,再那样",但 Agent 被强制要求:如果你说要做,就必须立刻调用工具去做。
这个约束在 Ingest 中的体现:当 Agent 说"让我探索一下 SDK 目录"时,它必须立刻执行 terminal("find SDK_DIR -type d"),而不是写一段"我们首先需要扫描目录结构"的文字。
6.2 Task Decomposition 与 Todo List
Complex tasks require explicit task breakdown。Agent 在每次大规模操作前创建 Todo List:
json
[
{"id": "1", "content": "解压剩余压缩包", "status": "in_progress"},
{"id": "2", "content": "复制文档到 wiki/raw/", "status": "pending"},
{"id": "3", "content": "阅读核心文档", "status": "pending"},
{"id": "4", "content": "批量创建 wiki 页面", "status": "pending"},
{"id": "5", "content": "更新 index.md 和 log.md", "status": "pending"},
{"id": "6", "content": "汇报结果 + Token 统计", "status": "pending"}
]这个设计看起来简单,但解决了 Agent 的一个核心问题:上下文窗口溢出。当一次操作涉及几十个文件、几百条命令时,Agent 很容易"忘记"自己进行到哪一步了。Todo List 提供了持久化的进度追踪。
6.3 记忆优先于重复推理
Agent 的 Memory 机制在 Ingest 中的作用非常微妙:
当 Agent 需要查找 Wiki 路径时,它走的不是文件搜索,而是 Memory 检索
当 Agent 需要遵守公众号排版标准时,它加载的是 Memory 中的排版规则
当 Agent 需要知道用户叫"用户"时,它从 User Profile 中读取
这种设计避免了"每次重新推理已知事实"的 Token 浪费。
6.4 Token 成本意识
Ingest 操作的 Token 消耗数据:
模型: deepseek-v4-flash
输入 Token: 18,527,113
输出 Token: 111,004
总计: 18,638,117
缓存命中率: 98%这个数据揭示了一个有趣的事实:98% 的输入 Token 被缓存命中。这意味着 Agent 不需要每次都重新发送相同的 System Prompt 和对话历史------Provider 层面的缓存机制自动处理了重复部分。
实际"新鲜"消耗的 Token 大约只有 372,542(2%),其中 111,004 是 Agent 的输出。按 DeepSeek V4 Flash 的价格计算,执行一次完整的 Ingest 操作的成本大约在几分钱级别。如果切换到 Pro 模型,成本会高一些(大约几毛钱),但输出的质量和复杂度会更高。
6.3 多层 Cache 策略
Agent 在执行 Ingest 时,隐式地运用了多层缓存策略,这是普通开发者容易忽略的:
第一层:Provider 缓存(API 层面)
98% 的输入 Token 被缓存命中
意味着 System Prompt + Memory 不是每次重新发送
第二层:文件缓存(本地层面)
raw/ 目录下的 PDF 可以直接引用
不需要重复读取同一份文档
第三层:Memory 缓存(Agent 层面)
用户偏好、项目信息、路径规则
不需要重新推理已经知道的事实
第四层:Session 缓存(会话层面)
Todo List 状态跟踪
Tool 输出结果复用这四层缓存的组合,让一次完整的 Ingest 操作(处理 6.8GB SDK、创建 11 个页面、更新 8 个现有页面)实际消耗的"新鲜 Token"只有大约 37 万,其中 11 万是 Agent 的输出。
6.4 会话状态管理
Agent 的另一个设计亮点是 Session 搜索能力。当用户说"之前我们做过一个类似的..."时,Agent 可以调用 session_search 回溯历史对话:
python
session_search(query="SDK ingest DDR parameter")
# 返回:2026-06-19 的完整会话,包括所有 terminal 输出和工具调用这个机制让 Agent 具备了跨会话连续性------即使对话被中断或开始新会话,Agent 也能通过检索历史会话重建上下文。对于 Ingest 这样的多步骤长流程,这个能力至关重要。
6.5 人机协作的反馈闭环
Ingest 不是完全自动化的。Agent 的设计中预留了多个人工确认节点:
① 知识建模阶段
Agent 提议创建 11 个新页面
→ 用户可以否决("这个不需要")
→ 用户可以补充("再加一个...")
② 交叉引用阶段
Agent 自动建立 [[wikilinks]]
→ 用户可以发现遗漏的关联
③ 最终确认
Agent 汇报变更摘要
→ 用户审核后确认生效在本次 Ingest 中,用户看到第一轮 SDK 摄入完成后,追加了"把硬件学习的硬件排除内容也收进去"。这个反馈触发了第二轮 Ingest------Agent 将 10 个专题、36 个源文件整合为一个 435 行的超级概念页。
这种"先做→展示→收到反馈→再做"的闭环,是 Agent 与搜索引擎的本质区别。搜索引擎给你 10 条链接,Agent 帮你把事做完------如果你不满意,它再改。
七、Ingest 的未来方向
目前的 Ingest Pipeline 已经能处理结构化的 SDK 文档和半结构化的学习笔记,但还有几个重要的改进方向:
7.1 图像知识的自动化摄入
目前的 Ingest 主要处理文本和 PDF。但大量的工程知识存在于原理图、PCB 版面图、示波器截图中。如果能通过视觉 AI(Vision Model)自动提取图表中的信息并结构化存储,Ingest 的覆盖面会大大扩展。
7.2 冲突检测与知识更新
当新摄入的知识与已有内容冲突时(例如新版 SDK 修改了某个寄存器地址),Agent 目前依赖人工确认。未来的版本可以自动检测冲突、生成差异报告、建议更新方案。这与 Git 的 Merge Conflict 解决流程异曲同工。
7.3 知识图谱可视化
当前的知识网络通过 Obsidian 的 Graph View 展示,但缺乏定量分析------哪些页面被引用最多?哪些页面是孤岛(无人引用)?哪些概念之间的关联最强?引入知识图谱的图分析能力,可以让 Agent 主动发现知识盲区和结构缺陷。
7.4 批量 Ingest 的自动化调度
目前的 Ingest 是手动触发的。如果设置为定时任务(Cron Job),Agent 可以定期扫描指定目录、检测新增文件、自动执行增量摄入。这类似于 CI/CD 中的自动构建流程------知识库变成了一个"持续集成"的系统。
7.5 知识库作为 AI Agent 的"长程记忆"
当前的 LLM 模型有一个根本性限制:上下文窗口有限。即使是 128K 或 200K 的模型,也无法装下一个工程师几年积累的全部知识。
LLM Wiki 提供了一种替代方案:将知识编译成结构化的外部存储,Agent 在需要时按需读取。 这就像人类的大脑------你不会同时激活所有记忆,而是在需要时检索特定的信息。
从这个角度看,知识库不是"文档存档",而是 Agent 的外部记忆系统:
Agent 的内存层次:
├── 短期记忆(上下文窗口):当前对话的内容
│ └── 容量:128K tokens ≈ 一本 200 页的书
├── 中期记忆(Session DB):对话历史检索
│ └── 容量:无限制(SQLite 存储所有历史)
├── 长期记忆(Memory Store):持久偏好和规则
│ └── 容量:~2,000 字符的关键事实
└── 外部记忆(LLM Wiki):编译好的结构化知识
└── 容量:无限制(硬盘有多大就有多大)当 Agent 遇到一个问题时,它首先检查上下文窗口中有没有答案。如果没有,它检索 Session DB 看以前是否解决过。如果也没有,它查 Memory 看有没有相关规则。最后,它去 Wiki 中搜索编译好的知识。
这套多层记忆架构,让 Agent 在"知识无穷大"的情况下依然能保持"实时响应"。
7.6 Agent Ingest 进入企业知识管理
当前 Agent 的 Ingest 能力是针对个人知识库设计的。但它完全具备为企业级知识管理服务的能力:
企业知识库场景:
├── 产品文档 → Agent 自动维护产品知识库
│ └── SDK 更新 → 自动检测差异 → 增量摄入
├── 故障工单 → Agent 自动提取故障模式
│ └── 工单系统 API 接入 → 故障模式库
├── 设计评审 → Agent 自动总结评审意见
│ └── 交叉引用已有设计规范
└── 代码审查 → Agent 自动同步代码变更
└── 关联到架构决策记录关键在于:Agent 的 Ingest Pipeline 是可复用的。 同样的解压→探索→建模→创建→索引流程,可以应用于任何领域的知识管理。只需要调整 SCHEMA.md 中的分类体系和页面模板。
八、总结:AI Agent 在知识管理中的真正价值
回到文章开头的那个问题:知识管理的核心痛点是什么?
不是"存",而是"摄入"。
存文件很简单------PDF 扔进文件夹、网页收藏到浏览器、笔记写在备忘录。但把这些零散的信息转化为可检索、可关联、可复用的结构化知识,需要大量的手工劳动。
AI Agent 的价值在于:它承担了知识摄入中最繁重的那部分工作------分类、建模、关联、索引、更新。 工程师只需要提供原始材料("这个 SDK 目录帮我收进去"),Agent 完成剩下的所有步骤。
更重要的是,这种摄入不是一次性的。当新知识进来时,Agent 会检查已有内容、更新交叉引用、追加日志。知识库不是静态的文档集,而是持续生长的有机体。
Ingest Pipeline 的背后,是 Prompt Engineering、Tool-Use 编排、Memory 管理、Skill 机制的协同工作。它不是魔法,而是工程化的知识管理方法------可复现、可审计、可优化。
AI Agent 不会取代工程师,但会用 Agent 的工程师一定会取代不会用 Agent 的。
你的知识库不只是你个人经验的沉淀------它是你与 AI Agent 协作的产物,是你们两个共同的"第二大脑"。
如果你也想尝试:
安装 Hermes Agent:访问 https://hermes-agent.nousresearch.com/docs
建一个你自己的 LLM Wiki:export WIKI_PATH=~/my-wiki + 告诉我"建一个关于 XYZ 的 wiki"
投入你的 SDK 或学习笔记,观察 Ingest Pipeline 是如何工作的
如果你也想建立你自己的 AI Agent 知识库------
不需要懂代码,不需要配置服务器。告诉我"建一个 XXX 的 wiki",Agent 自动帮你完成所有工作。
关注「AI的探索之旅」,你将获得:
| 内容 | 频率 | 适合人群 |
|---|---|---|
| AI Agent 实战教程 | 每周 | 希望用 AI 提效的工程师 |
| 嵌入式开发深度解析 | 不定期 | Hi3519DV500 / 嵌入式 Linux 开发者 |
| 知识管理方法论 | 双周 | 资料多、记不住的知识工作者 |
| Agent 工具链更新 | 有新的就发 | AI 爱折腾玩家 |
你可能还会喜欢:
→ Hi3519DV500 嵌入式开发全攻略:从环境搭建到固件打包
→ AI ISP vs 传统 ISP:海思芯片的图像处理到底强在哪?
→ 量产硬件排查终极指南:一块好板 vs 一块坏板能告诉你什么
👇 长按识别关注,不错过每一篇干货
**搜索「AI的探索之旅」让 AI Agent 成为你的第二大脑