- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、基础准备
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"当前使用的计算设备: {device}")二、数据预处理与加载
python
# 规定 ResNeXt 标准输入尺寸为 224x224
data_dir = './data'
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
try:
full_ds = datasets.ImageFolder(root=data_dir, transform=transform)
train_size = int(0.8 * len(full_ds))
test_size = len(full_ds) - train_size
train_ds, test_ds = random_split(full_ds, [train_size, test_size])
train_dl = DataLoader(train_ds, batch_size=16, shuffle=True)
test_dl = DataLoader(test_ds, batch_size=16, shuffle=False)
num_classes = len(full_ds.classes)
print(f"数据加载成功。共 {num_classes} 个类别: {full_ds.classes}")
except Exception as e:
print(f"数据目录加载失败,请检查 '{data_dir}' 路径。错误详情: {e}")
exit()三、模型构建 (迁移学习)
python
# 调用预训练的 ResNeXt-50 模型
model = models.resnext50_32x4d(pretrained=True)
# 修改最后的分类层以适配猴痘类别数
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, num_classes)
model = model.to(device)四、损失函数与优化器
python
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)五、训练与测试函数定义
python
def train_model(dataloader, model, loss_fn, optimizer):
model.train()
for x, y in dataloader:
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
def test_model(dataloader, model, loss_fn):
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
pred = model(x)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
return test_loss / len(dataloader), correct / len(dataloader.dataset)六、执行训练循环
python
print("开始执行模型训练...")
epochs = 15
train_acc_hist, test_acc_hist = [], []
for epoch in range(epochs):
train_model(train_dl, model, loss_fn, optimizer)
_, train_acc = test_model(train_dl, model, loss_fn)
_, test_acc = test_model(test_dl, model, loss_fn)
train_acc_hist.append(train_acc)
test_acc_hist.append(test_acc)
print(f"Epoch {epoch+1:02d}/{epochs} | Train Acc: {train_acc:.1%} | Test Acc: {test_acc:.1%}")
print("模型训练结束。")七、结果可视化
python
plt.figure(figsize=(8, 5))
plt.plot(train_acc_hist, label='Train Accuracy', color='#1f77b4', marker='o')
plt.plot(test_acc_hist, label='Test Accuracy', color='#ff7f0e', marker='x')
plt.title('ResNeXt-50 Classification Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.6)
plt.show()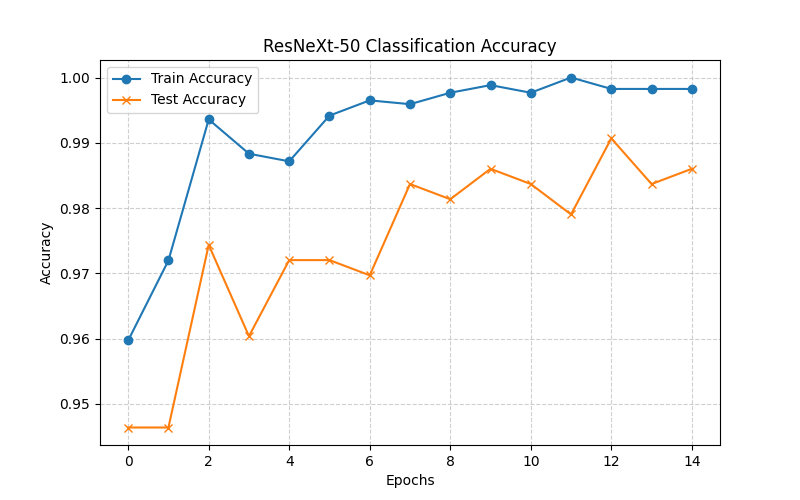
八、总结
ResNeXt-50 是在 ResNet 和 Inception 基础上发展而来的网络架构。它的主要贡献在于提出了一种在不增加参数复杂度的前提下,提升模型准确率的标准方法。
1. 架构基础:ResNet 与 Inception 的结合
继承 ResNet: 保留了残差连接(Shortcut Connection)。这一结构解决了深层网络中的梯度消失问题,使得特征可以在不同层级间无损传递。
借鉴 Inception: 采用了"分割-变换-聚合(Split-Transform-Merge)"的策略,将原本单一的卷积操作转换为多个并行的分支操作。
2. 核心创新点:引入"基数 (Cardinality)"
基数的定义: 传统网络通常通过增加深度(层数)或宽度(通道数)来提升性能。ResNeXt 提出了第三个维度------基数(Cardinality),即并行分支的数量(或分组的数量)。
高度标准化: 与 Inception 模块中每个分支需要人工设计不同尺寸的卷积核不同,ResNeXt 强制要求所有并行分支的拓扑结构(网络层级与参数配置)完全一致。
3. 工程实现:分组卷积 (Grouped Convolution)
在代码层面,ResNeXt 的并行分支通过分组卷积来实现。
运行机制: 将输入特征图的通道等分为 C 个组(C 即为基数),每个组独立进行常规卷积操作,最后将所有组的输出在通道维度上进行拼接(Concatenate)。
优势: 分组卷积极大减少了模型的参数量和计算开销(FLOPs)。利用节省下来的算力资源,模型可以进一步增加通道宽度,从而在同等计算资源下获得比常规 ResNet 更强的特征提取能力。