前言
做后端联调、前端开发、线上问题排查的时候,你一定遇到过这类高频痛点:调用接口返回一串 \u4f60\u597d 格式的Unicode转义字符,肉眼无法直接读取内容;排查服务器日志,中文信息全被编码成 \uXXXX 形式,定位问题还要额外写脚本解码;编写JavaScript、Java代码时,为了规避字符集乱码,需要手动将中文转义成Unicode格式;做HTML页面开发时,特殊字符、生僻字需要转成HTML实体才能正常显示。
传统的解决方案要么需要编写代码脚本,调试成本高;要么本地安装的编码工具功能单一,不支持多种格式互转;更有不少在线工具需要上传数据,存在敏感内容泄露的风险。今天给大家推荐一款开箱即用的在线Unicode中文互转工具,支持双向转换、多格式输出、批量文本处理,所有转换全程在浏览器本地完成,数据不上传服务器,开发人员可以放心使用。
工具直达地址:https://www.itptg.com/tools/unicode-chinese-converter.html
一、核心功能全解析:覆盖全场景编码转换需求
这款工具聚焦Unicode编码转换场景,没有冗余功能,所有能力都精准匹配开发、运维、测试人员的日常需求,上手零门槛。
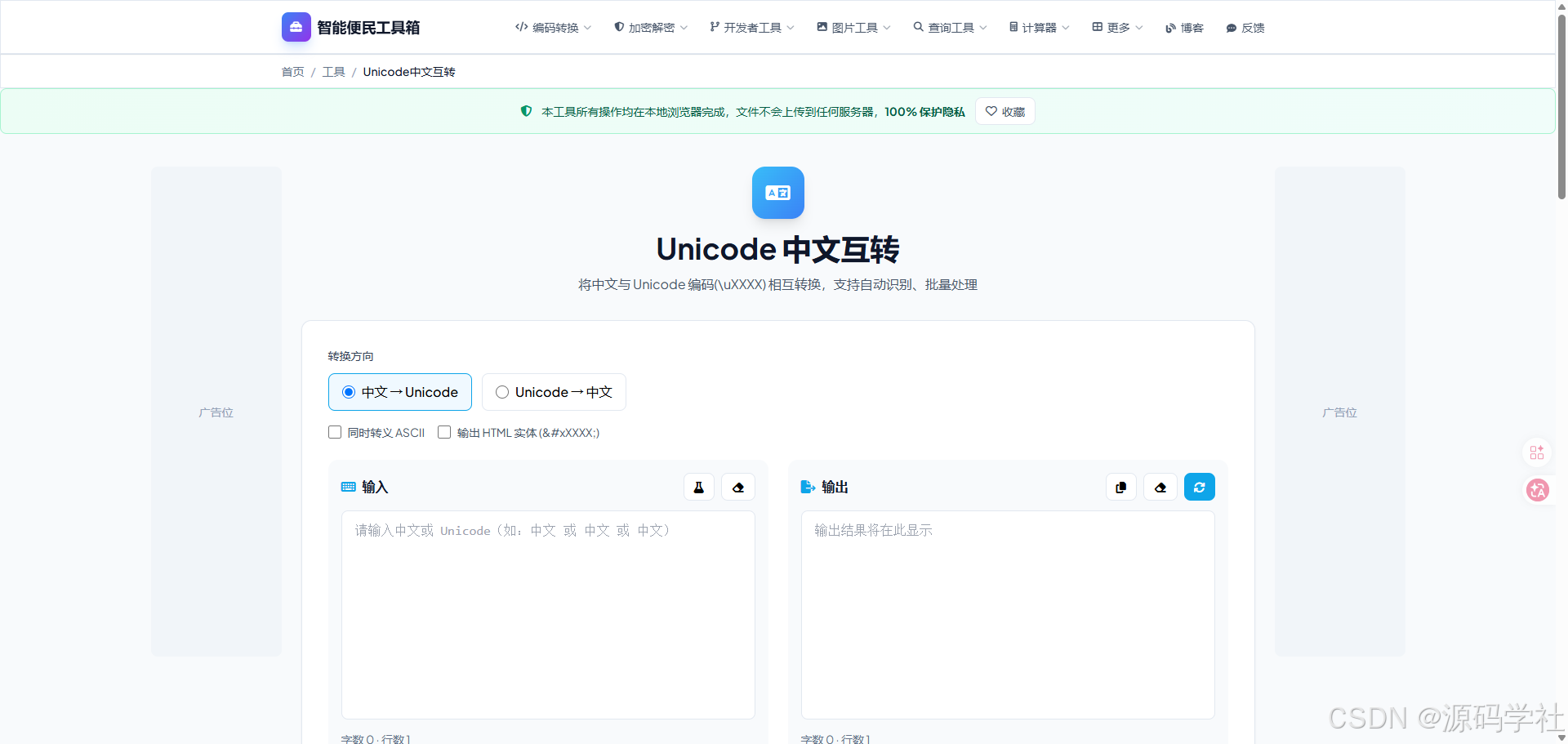
1. 双向智能转换,中文↔Unicode无缝切换
工具支持两种核心转换方向,同时自带自动识别能力:
- 中文 → Unicode :输入中文文本,一键转换为
\uXXXX格式的转义编码,适用于代码字符串转义、特殊字符处理等场景; - Unicode → 中文 :粘贴
\uXXXX格式的编码内容,一键还原为可读中文,是接口调试、日志排查的高频需求; - 自动识别转换:无需手动选择方向,粘贴混合内容后自动识别并完成转换,大幅提升操作效率。
2. 多格式兼容,不止是\uXXXX转义
除了最常用的反斜杠Unicode格式,工具还支持多种开发场景下的编码格式,无需切换多个工具:
- 反斜杠形式(\uXXXX):JavaScript、Java、Python等编程语言中最常用的Unicode转义格式,适配绝大多数代码场景;
- HTML十六进制实体(&#xXXXX;):HTML文档专用的字符表示方式,用于页面中展示特殊字符、生僻字,规避浏览器字符兼容问题;
- HTML十进制实体(&#DDDD;):HTML数值引用格式,适配部分老旧系统、CMS平台的字符展示需求。
3. 高级选项自定义,灵活适配业务需求
针对个性化转换场景,工具提供了高级配置项,无需修改代码即可实现定制化输出:
- 同时转义ASCII:勾选后可将ASCII字符一同转义为Unicode格式,适配全量字符转义的特殊业务场景;
- 输出HTML实体:一键切换输出格式为HTML实体编码,满足前端页面开发、富文本内容处理的需求。
4. 批量文本秒处理,大内容无压力
支持大段文本、多行内容批量转换,输入框无强制字数限制,日常接口返回报文、整段日志内容都可以直接粘贴处理。页面实时显示输入输出的字数、行数,方便统计与核对内容。
5. 纯前端本地处理,数据安全零风险
对于开发人员而言,接口报文、线上日志往往包含业务敏感数据,上传到第三方服务器存在泄露风险。这款工具采用纯前端JavaScript实现,所有转换运算全部在浏览器本地完成,数据不会上传到任何服务器,无需联网也能正常使用,且不保存任何输入输出内容,全程隐私安全有保障。
二、3步零门槛上手:1分钟完成编码转换
工具操作逻辑非常简洁,即使是第一次使用,也能快速完成转换,完整流程仅需3步:
步骤1:选择转换方向
打开工具页面后,根据需求选择「中文 → Unicode」或「Unicode → 中文」;如果不确定内容格式,也可以直接使用自动识别功能,无需手动切换。
步骤2:输入待转换内容
在左侧输入框中粘贴需要处理的文本,可以是中文内容,也可以是 \uXXXX 格式的Unicode编码、混合文本,支持多行、大段内容批量粘贴。
步骤3:转换并复制结果
点击「开始转换」按钮,右侧输出框会瞬间生成转换后的结果,点击「复制」按钮即可一键将内容复制到剪贴板,直接粘贴到代码、日志、文档中使用。
如果有特殊格式需求,可以提前勾选高级选项中的配置,转换时会自动生效。
三、高频适用场景:开发/运维/测试全员通用
这款工具虽然轻量,但精准命中了技术人员的多个日常工作场景,堪称职场效率神器:
- 接口联调调试:后端接口返回Unicode转义的中文报文,直接粘贴即可解码查看,不用写临时脚本、不用借助Postman额外配置,联调效率直接翻倍。
- 线上日志排查 :服务器日志、错误堆栈中的中文被转义为
\uXXXX格式,粘贴工具中快速还原原文,精准定位问题原因,缩短故障排查时间。 - 前端开发编码:处理JavaScript字符串转义、国际化资源文件,快速将中文转为Unicode格式,规避不同环境下的字符集乱码问题。
- 数据库乱码排查:排查数据库字符集不兼容导致的中文乱码问题,通过编码转换验证字符正确性,定位乱码根源。
- HTML页面开发:将特殊符号、生僻字、保留字符转换为HTML实体,确保在不同浏览器、不同字符集环境下都能正常显示。
- 爬虫与数据处理:处理爬取到的Unicode编码内容,快速批量还原为可读中文,无需额外编写解码逻辑。
四、技术科普:Unicode编码的核心知识点
很多开发者天天和Unicode打交道,但对其底层概念并不完全清晰,这里补充几个核心知识点,帮助大家更好地理解编码转换逻辑。
1. 什么是Unicode?
Unicode又称统一码、万国码,是计算机科学领域的业界字符编码标准。它为全球每种语言的每个字符都设定了统一且唯一的二进制编码,从根本上解决了跨语言、跨平台场景下的字符乱码问题,目前可以表示超过100万个字符,覆盖了世界上几乎所有的文字系统。
2. 常见的Unicode表示格式
- \uXXXX 转义格式:开发中最常用的Unicode表示法,用反斜杠+u加4位十六进制数表示一个字符,广泛应用在JavaScript、Java、C#等编程语言的字符串转义中。
- HTML实体格式 :分为十六进制(
&#xXXXX;)和十进制(&#DDDD;)两种,用于HTML文档中表示无法直接输入的特殊字符、保留字符与生僻字,避免页面显示异常。
3. 中文的Unicode编码范围
常用中文的核心编码范围为 U+4E00 - U+9FFF(基本汉字区),包含了2万多个常用简体、繁体汉字;除此之外还有扩展A-G区,覆盖了生僻字、古籍用字、少数民族文字等,满足各类特殊文本处理需求。
五、总结
总的来说,这是一款专为技术人员打造的轻量Unicode编码转换工具。它没有复杂的配置与冗余的功能,把中文与Unicode互转这件事做到了精准、高效、安全:双向转换+自动识别覆盖绝大多数使用场景,多格式输出适配前后端不同开发需求,纯前端本地运行的特性彻底解决了敏感数据的安全顾虑,再加上浏览器即用即走、无需安装的优势,完全可以替代本地的各类编码小工具。
如果你经常需要处理Unicode编码、排查乱码问题,不妨收藏这个工具,下次遇到 \uXXXX 转义内容时,打开网页就能一键解决。
工具直达地址:https://www.itptg.com/tools/unicode-chinese-converter.html