发布日期: 2026年6月17日
阅读时间: 约 10-12 分钟
分类:技术杂谈
专栏:数据工程实战录
关键词:
AB测试数据驱动产品增长转化率优化用户体验统计学A/B测试数据科学
导读:用户划走一个视频只需 0.5 秒,关闭一个网页不到 3 秒。在这个注意力稀缺的时代,如何用数据留住用户?又如何用科学实验验证你的每一个产品决策?本文从感知到验证,拆解数据驱动增长的完整闭环。
一、3 秒定生死:用户不会给你第二次机会
1.1 残酷的数据
| 场景 | 时间阈值 | 后果 |
|---|---|---|
| 网页加载 | > 3 秒 | 跳出率增加 32%(Google 研究) |
| 短视频开头 | > 3 秒 | 划走率超过 50% |
| APP 启动 | > 3 秒 | 次日留存下降 15% |
| 客服响应 | > 3 秒 | 用户满意度断崖式下跌 |
前 3 秒定律:用户在接触产品的最初 3 秒内,已经完成了"是否继续"的潜意识决策。这不是理性判断,而是本能反应。
1.2 3 秒内的信息架构
用户打开页面的前 3 秒,眼睛在看哪里?
┌─────────────────────────────────────┐
│ [Logo] 核心价值主张(1秒) │ ← F型阅读热区
│ "全网最低价,正品保障" │
├─────────────────────────────────────┤
│ [搜索框] [分类导航] │ ← 操作入口(2秒)
│ 让用户知道"我能做什么" │
├─────────────────────────────────────┤
│ [Banner] [商品卡片] [商品卡片] │ ← 内容吸引(3秒)
│ 视觉锤:图片 > 文字 │
└─────────────────────────────────────┘1.3 实战:3 秒优化清单
html
<!-- 反面教材:3 秒内用户看到了什么? -->
<html>
<head>
<script src="https://heavy-analytics.js"></script> <!-- 阻塞加载 1.5s -->
<script src="https://ad-network.js"></script> <!-- 阻塞加载 1s -->
<link rel="stylesheet" href="https://cdn.bigcss.com"> <!-- 阻塞加载 0.8s -->
</head>
<body>
<div id="app"></div> <!-- 空白 3 秒,用户已关闭标签页 -->
<script>renderApp();</script>
</body>
</html>
html
<!-- 正面案例:3 秒内呈现核心价值 -->
<html>
<head>
<!-- 关键 CSS 内联,首屏直出 -->
<style>
.hero { background: #ff6b6b; color: white; padding: 40px; }
.skeleton { animation: pulse 1.5s infinite; }
</style>
<!-- 非关键资源异步加载 -->
<link rel="preload" href="critical.css" as="style">
<script src="analytics.js" async></script>
</head>
<body>
<!-- 服务端渲染(SSR),首屏直出 -->
<div class="hero">
<h1>双11 全场 5 折起</h1>
<button>立即抢购</button>
</div>
<!-- 骨架屏,缓解等待焦虑 -->
<div class="skeleton-product-list">
<div class="skeleton-card"></div>
<div class="skeleton-card"></div>
</div>
</body>
</html>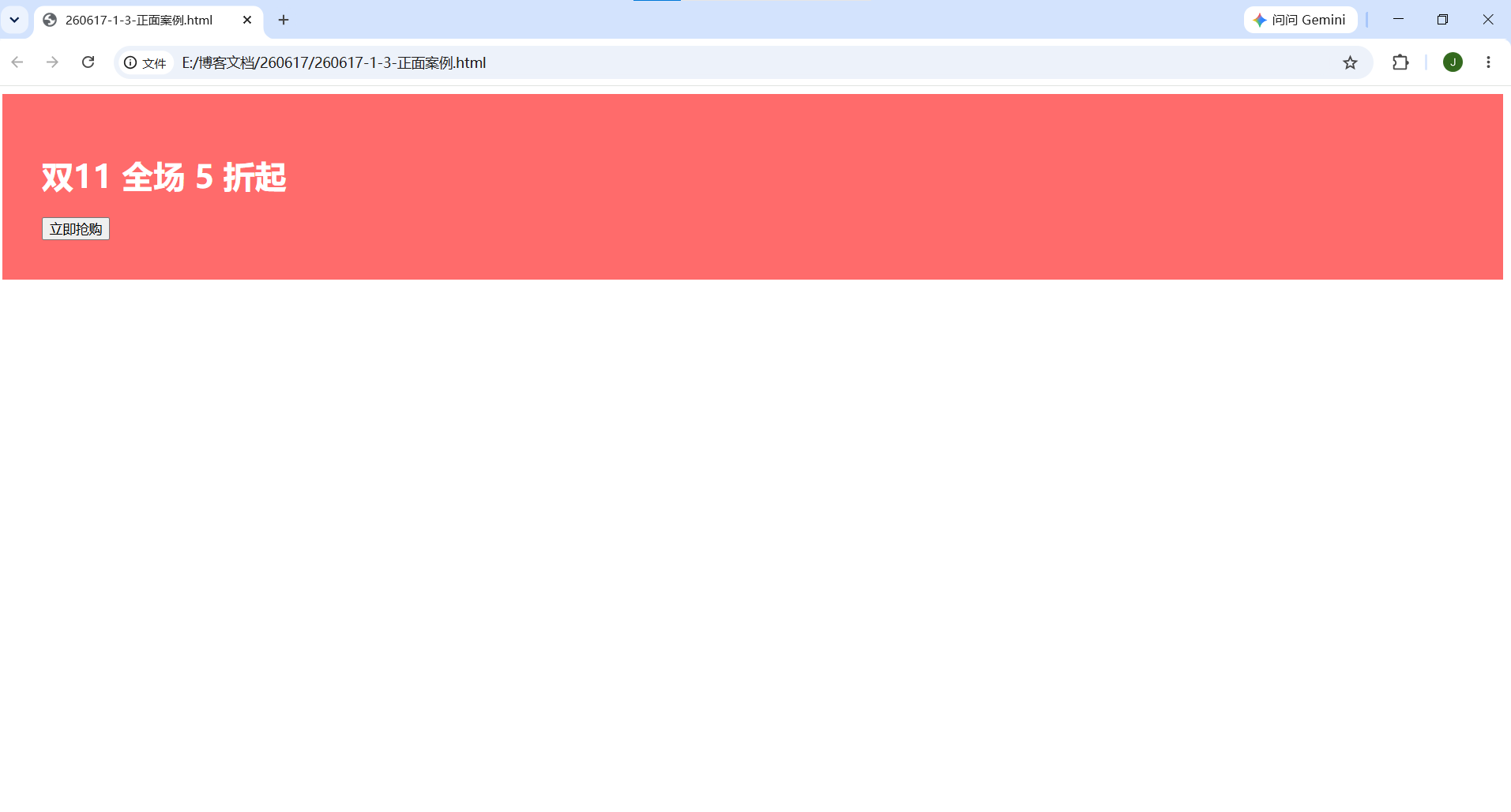
关键指标 :FCP(First Contentful Paint)< 1.8s,LCP(Largest Contentful Paint)< 2.5s
二、Range 值:定义"好"与"坏"的标尺
2.1 为什么需要 Range 值?
没有 Range 的指标,就像没有刻度的温度计------你知道热了,但不知道多热。
| 指标 | 数值 | 好还是坏? |
|---|---|---|
| 日活用户(DAU) | 100 万 | ?(看环比) |
| 订单转化率 | 3.5% | ?(看行业基准) |
| 接口 P99 延迟 | 200ms | ?(看 SLA) |
| 服务器 CPU | 75% | ?(看是否持续) |
2.2 Range 值的三种类型
┌─────────────────────────────────────────┐
│ Range 值分类体系 │
├─────────────────────────────────────────┤
│ 1. 健康区间(Healthy) │
│ 正常波动范围,无需关注 │
│ 例:转化率 2.5% ~ 4.0% │
├─────────────────────────────────────────┤
│ 2. 预警区间(Warning) │
│ 需要关注,可能存在问题 │
│ 例:转化率 1.5% ~ 2.5% │
├─────────────────────────────────────────┤
│ 3. 危险区间(Critical) │
│ 必须立即干预,触发告警 │
│ 例:转化率 < 1.5% │
└─────────────────────────────────────────┘2.3 实战:如何科学设定 Range 值?
方法一:统计法(基于历史数据)
python
import numpy as np
import pandas as pd
# 过去 30 天的转化率数据
conversion_rates = pd.Series([3.2, 3.5, 2.8, 3.1, 3.6, 3.0, 2.9, ...])
# 计算均值和标准差
mean = conversion_rates.mean() # 3.15%
std = conversion_rates.std() # 0.25%
# 正态分布假设下:
# 68% 的数据落在 mean ± 1std → 健康区间
# 95% 的数据落在 mean ± 2std → 预警区间
# 99.7% 的数据落在 mean ± 3std → 危险区间
healthy_range = (mean - std, mean + std) # (2.90%, 3.40%)
warning_range_low = (mean - 2*std, mean - std) # (2.65%, 2.90%)
critical_threshold = mean - 3*std # 2.40%方法二:分位数法(更鲁棒,不受异常值影响)
python
# 使用分位数,不假设正态分布
q25 = conversion_rates.quantile(0.25) # 2.95%
q75 = conversion_rates.quantile(0.75) # 3.35%
iqr = q75 - q25 # 0.40%
# 健康区间:[Q25, Q75]
# 预警区间:[Q25 - 1.5*IQR, Q25] 和 [Q75, Q75 + 1.5*IQR]
# 危险区间:超出上述范围方法三:业务法(基于目标)
python
# 直接根据业务目标设定
kpi_target = 4.0 # 业务目标转化率
tolerance = 0.5 # 允许波动
healthy_range = (kpi_target - tolerance, kpi_target + tolerance) # (3.5%, 4.5%)
warning_range = (kpi_target - 2*tolerance, kpi_target - tolerance) # (3.0%, 3.5%)
critical_threshold = kpi_target - 3*tolerance # 2.5%2.4 Range 值在监控中的应用
yaml
# Prometheus 告警规则
groups:
- name: conversion_rate_alerts
rules:
- alert: ConversionRateWarning
expr: |
(
rate(orders_total[1h])
/ rate(visits_total[1h])
) < 0.025
for: 5m
labels:
severity: warning
annotations:
summary: "转化率低于预警阈值"
- alert: ConversionRateCritical
expr: |
(
rate(orders_total[1h])
/ rate(visits_total[1h])
) < 0.015
for: 2m
labels:
severity: critical
annotations:
summary: "转化率进入危险区间,立即排查!"三、AB 实验:用数据验证直觉
3.1 为什么需要 AB 实验?
人类的直觉,在复杂系统中往往是错的。
经典案例:Google 测试了 41 种蓝色阴影,发现某种蓝色让年收入增加了 2 亿美元。
| 决策方式 | 问题 |
|---|---|
| 老板拍脑袋 | "我觉得红色按钮更好" → 无依据 |
| 看竞品 | "淘宝这么做,我们也做" → 场景不同 |
| 用户调研 | "用户说想要" → 言行不一 |
| AB 实验 | "数据证明哪个更好" → 唯一可信 |
3.2 AB 实验的完整流程
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 1. 假设 │ → │ 2. 设计 │ → │ 3. 分流 │
│ "新UI能 │ │ 确定指标 │ │ 随机分组 │
│ 提升转化" │ │ 计算样本量 │ │ A组 vs B组 │
└─────────────┘ └─────────────┘ └─────────────┘
↓
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 6. 上线 │ ← │ 5. 分析 │ ← │ 4. 运行 │
│ 全量发布 │ │ 统计显著性 │ │ 收集数据 │
│ 或继续迭代 │ │ p-value │ │ 观察周期 │
└─────────────┘ └─────────────┘ └─────────────┘3.3 实战:样本量计算
核心问题:实验需要跑多久?多少用户?
python
from scipy import stats
import math
def sample_size_per_group(
baseline_rate, # 基准转化率,如 3%
mde, # 最小可检测效应(Minimum Detectable Effect),如 10% 相对提升 → 3.3%
alpha=0.05, # 显著性水平(第一类错误)
power=0.8, # 统计功效(1 - 第二类错误)
ratio=1 # 实验组:对照组 = 1:1
):
"""
计算每组所需样本量
"""
p1 = baseline_rate
p2 = baseline_rate * (1 + mde)
# 合并比例
p_pooled = (p1 + p2) / 2
# Z 分数
z_alpha = stats.norm.ppf(1 - alpha / 2) # 双侧检验
z_beta = stats.norm.ppf(power)
# 样本量公式
n = (
(z_alpha * math.sqrt(2 * p_pooled * (1 - p_pooled)) +
z_beta * math.sqrt(p1 * (1 - p1) + p2 * (1 - p2)))
/ (p2 - p1)
) ** 2
return math.ceil(n)
# 例子:基准转化率 3%,期望检测到 10% 相对提升(即 3.3%)
n = sample_size_per_group(
baseline_rate=0.03,
mde=0.10, # 10% 相对提升
alpha=0.05,
power=0.8
)
print(f"每组需要 {n} 个用户") # 输出:每组需要约 29,000 个用户
print(f"总流量需要 {n * 2} 个用户")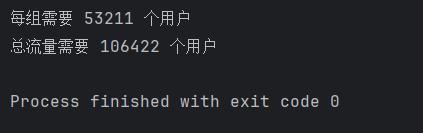
关键洞察:
- 转化率越低,需要的样本量越大(检测微小差异更难)
- MDE 越小,需要的样本量越大(想检测 1% 提升 vs 10% 提升,后者更容易)
- 通常实验周期至少覆盖 1-2 个完整业务周期(如一周),避免周末效应
3.4 实战:实验结果分析
python
import pandas as pd
from scipy.stats import chi2_contingency, ttest_ind
# 模拟实验数据
data = {
'group': ['A'] * 10000 + ['B'] * 10000,
'converted': [0] * 9700 + [1] * 300 + [0] * 9600 + [1] * 400
}
df = pd.DataFrame(data)
# 转化率
conv_a = df[df.group == 'A'].converted.mean() # 3.0%
conv_b = df[df.group == 'B'].converted.mean() # 4.0%
# 卡方检验(分类变量)
contingency = pd.crosstab(df.group, df.converted)
chi2, p_value, dof, expected = chi2_contingency(contingency)
print(f"A组转化率: {conv_a:.2%}")
print(f"B组转化率: {conv_b:.2%}")
print(f"相对提升: {(conv_b - conv_a) / conv_a:.1%}")
print(f"P-value: {p_value:.4f}")
if p_value < 0.05:
print("✅ 统计显著,B组显著优于A组")
else:
print("❌ 统计不显著,无法得出结论")
3.5 AB 实验的五大陷阱
| 陷阱 | 表现 | 解决方案 |
|---|---|---|
| 样本不足 | 实验跑 1 天,流量只有几百 | 提前计算样本量,不偷看数据 |
| 多重检验 | 同时测 20 个指标,必有一个"显著" | Bonferroni 校正,或选定唯一核心指标 |
| 辛普森悖论 | 整体数据 B 好,但每个细分群体 A 好 | 分层分析,检查混淆变量 |
| 新奇效应 | 新功能短期数据好,长期回落 | 延长观察期,关注长期指标 |
| 选择偏差 | 实验组和对照组用户特征不同 | 严格随机分流,AA 测试验证 |
四、闭环:从感知到验证的完整链路
┌─────────────────────────────────────────────────────────┐
│ 数据驱动增长闭环 │
├─────────────────────────────────────────────────────────┤
│ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 前 3 秒 │ → │ Range │ → │ AB 实验 │ │
│ │ 发现问题 │ │ 定义标准 │ │ 验证方案 │ │
│ │ │ │ │ │ │ │
│ │"用户流失 │ │"流失率 │ │"新设计 │ │
│ │ 率高" │ │ > 5% │ │ 能否降低│ │
│ │ │ │ 需干预" │ │ 流失率" │ │
│ └─────────┘ └─────────┘ └─────────┘ │
│ ↑ │ │
│ └──────────────────────────────┘ │
│ 实验结果反馈,持续优化 │
│ │
└─────────────────────────────────────────────────────────┘真实案例:某电商首页改版
| 阶段 | 动作 | 结果 |
|---|---|---|
| 感知 | 热力图发现用户在前 3 秒只看了首屏 40% | 发现问题 |
| 定义 | 设定 Range:首屏点击率 < 15% 为危险 | 量化标准 |
| 假设 | "将推荐算法从协同过滤改为深度学习,能提升点击率" | 形成假设 |
| 实验 | AB 实验,50% 流量,跑 2 周 | 科学验证 |
| 结果 | 点击率从 12% → 18%,p < 0.01 | 显著有效 |
| 上线 | 全量发布,监控长期指标 | 持续观察 |
五、总结
| 概念 | 核心作用 | 关键动作 |
|---|---|---|
| 前 3 秒定律 | 发现问题 | 优化首屏体验,降低跳出率 |
| Range 值 | 定义标准 | 建立指标的健康/预警/危险区间 |
| AB 实验 | 验证方案 | 用统计方法科学决策,避免拍脑袋 |
最后的话:数据驱动不是万能的,但没有数据驱动是万万不能的。前 3 秒让你感知用户,Range 值让你量化问题,AB 实验让你验证答案------三者结合,才是产品增长的科学方法论。
六、工具箱
| 类型 | 工具推荐 |
|---|---|
| 性能监控 | Lighthouse、WebPageTest、Chrome DevTools |
| 热力图/行为分析 | Hotjar、Clarity、神策数据 |
| AB 实验平台 | Google Optimize(已停止)、Optimizely、自研实验平台 |
| 统计分析 | R、Python (scipy、statsmodels)、Evan Miller 样本量计算器 |
| 指标看板 | Grafana、Tableau、Superset |
参考文献
1 Google. Find out how you stack up to new industry benchmarks for mobile page speed.
2 Philip Walton, Barry Pollard. Largest Contentful Paint (LCP).
3 Evan Miller. Sample Size Calculator for A/B Testing.
https://www.evanmiller.org/ab-testing/sample-size.html
4 Twitter Snowflake.
https://github.com/twitter-archive/snowflake
5 Wikipedia. Chi-squared test.
https://en.wikipedia.org/wiki/Chi-squared_test
本专栏将数据存储到系统架构,再到产品增长,覆盖数据工程师和产品经理的核心知识体系。如果对你有帮助,欢迎关注专栏,持续获取更多数据工程实战内容。
🗓️ 文章信息
更新日期:2026年06月17日
当前版本:v1.0
分类:技术杂谈
专栏:数据工程实战录
关键词:AB测试 数据驱动 产品增长 转化率优化 用户体验 统计学 A/B测试 数据科学
原创声明
本文为作者原创,版权归作者所有。原文于 2026年06月17日 同步发布于 CSDN、博客园、稀土掘金、51CTO、知乎。
欢迎学习与分享,但请尊重原创,转载请保留署名与出处。
未经许可,禁止用于商业用途或二次发布。