最近轻量级图像超分方向越来越卷,单纯比 PSNR 已经不够了,参数量、计算量、感受野、真实纹理恢复能力都要一起看。UCAN 是 CVPR 2026 中一篇比较值得关注的轻量超分工作,它的核心不是继续无脑堆模块,而是围绕"如何在轻量条件下扩大有效感受野"来设计网络。
论文与代码
论文题目:
UCAN: Unified Convolutional Attention Network for Expansive Receptive Fields in Lightweight Super-Resolution
论文链接:
arXiv 链接:
代码链接:
会议:
CVPR 2026
任务方向:
Lightweight Image Super-Resolution,轻量级图像超分辨率
代码框架:
BasicSR
关键词:
轻量超分、有效感受野、窗口注意力、Hedgehog Attention、大核蒸馏、跨层共享
1. 为什么轻量级超分需要更大的有效感受野?
图像超分辨率的目标,是从低分辨率图像恢复高分辨率图像。这个任务看起来像是"把图放大",但真正难的地方在于:高分辨率图像中的大量细节,在低分辨率输入中已经缺失了。
对于一些简单区域,比如天空、墙面、平滑背景,模型只需要局部信息就能恢复得不错。但对于结构复杂的区域,比如建筑窗格、漫画线条、道路边缘、重复纹理,仅靠局部小范围信息往往不够。
这就引出了 UCAN 这篇论文的核心概念:
Effective Receptive Field,有效感受野。
有效感受野可以理解为:模型在恢复某个像素或某个局部区域时,真正能够参考到的输入图像范围。
有效感受野越大,模型越容易利用远处的相似纹理、重复结构和长距离上下文。例如,恢复建筑物上的一个窗户时,如果模型能看到旁边更多相似窗户,那么它就更容易恢复出规整的线条和重复结构;如果模型只能看到很小一块局部区域,就容易出现线条断裂、纹理错乱或者结构变形。
传统 CNN 擅长局部纹理建模,但是天然偏局部。Transformer 擅长长距离依赖建模,但是 attention 计算量较大。线性注意力虽然计算便宜,但表达能力又可能不足。
所以 UCAN 想解决的不是一个单点问题,而是轻量超分中的核心矛盾:
| 需求 | 问题 |
|---|---|
| 想提升复杂纹理恢复能力 | 需要更大有效感受野 |
| 想扩大感受野 | 需要更大窗口、更大卷积核或更强全局建模 |
| 想保持轻量化 | 不能让参数量和计算量明显上升 |
UCAN 的方法就是围绕这个矛盾展开的:
在轻量计算量下,通过卷积和注意力的统一设计,扩大模型有效感受野,同时控制模型复杂度。
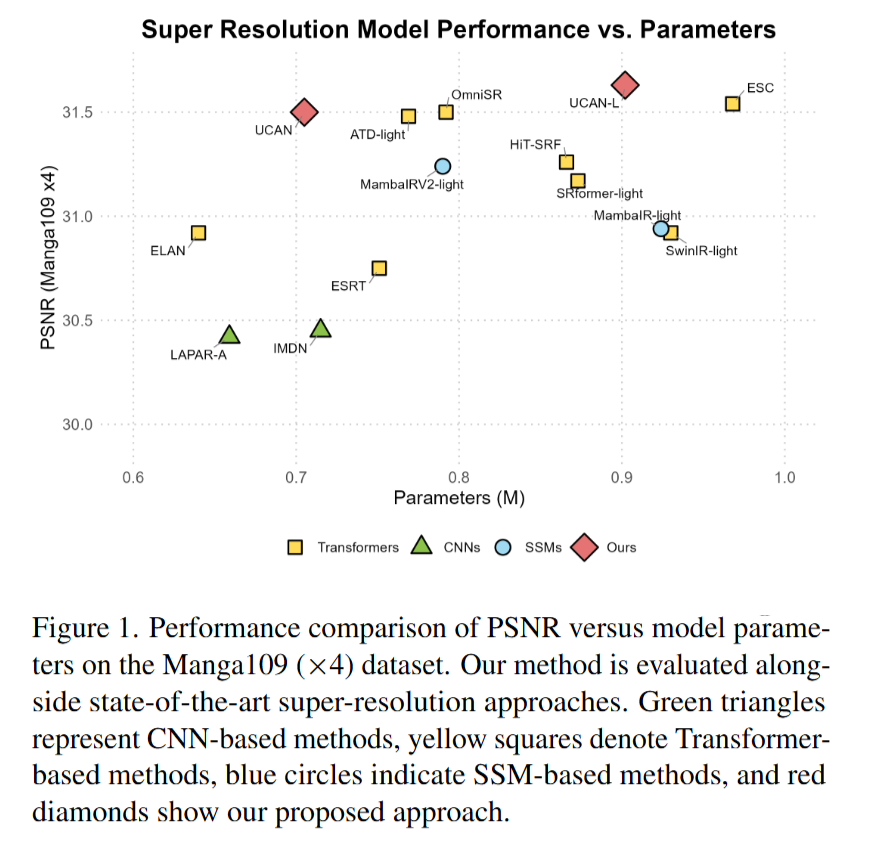
图中横轴是参数量,纵轴是 PSNR。越靠左表示模型越轻,越靠上表示性能越好。UCAN 想表达的不是"我模型最大,所以性能高",而是"我在较低复杂度下取得了更好的性能-参数量平衡"。
这张图其实就是整篇论文的第一层动机:轻量超分不能只看 PSNR,也要看模型是否足够轻、是否适合实际部署。
2. UCAN 整体方法:用统一卷积注意力扩大感受野
UCAN 的整体框架仍然是比较经典的图像超分结构:
text
LR Image
↓
Shallow Feature Extraction
↓
Broad Effective Receptive Field Groups
↓
Feature Fusion
↓
Reconstruction Module
↓
SR Image也就是说,低分辨率图像先经过浅层卷积提取初始特征,然后送入多个核心特征提取模块,最后通过重建模块生成高分辨率图像。
真正有创新的是中间的核心模块:
BERFG: Broad Effective Receptive Field Group
中文可以理解为:
宽有效感受野组
这个名字非常直白,说明作者的设计目标就是扩大有效感受野。
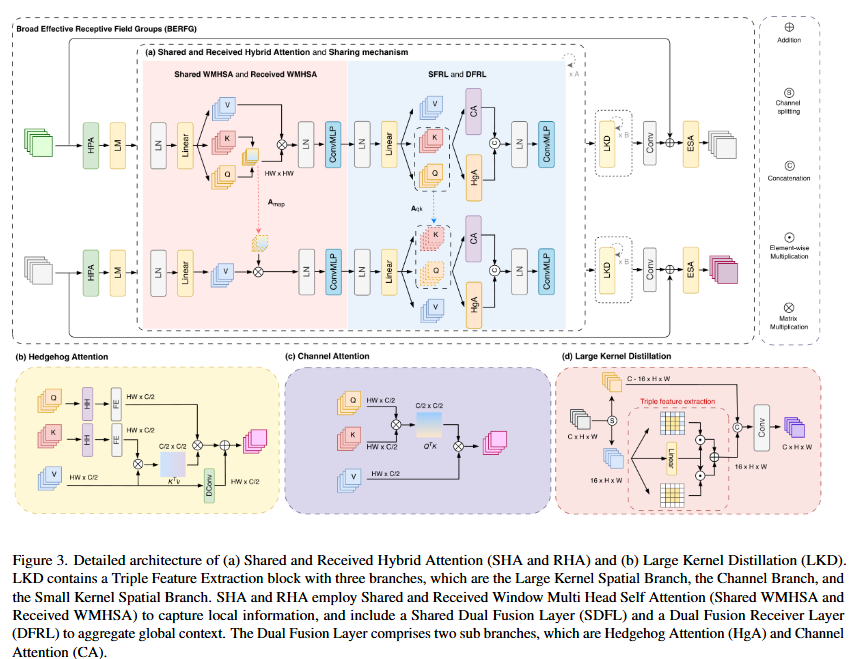
从论文结构图可以看出,UCAN 的核心主要由两类模块构成:
| 模块 | 作用 |
|---|---|
| Shared and Received Hybrid Attention | 用注意力建模局部、全局和通道关系,同时减少重复计算 |
| Large Kernel Distillation | 用低成本大核卷积增强空间结构和高频纹理恢复 |
进一步拆开,UCAN 主要有四个关键设计:
| 设计 | 解决的问题 |
|---|---|
| High Performance Attention | 大窗口注意力计算贵 |
| Hedgehog Attention | 线性注意力表达能力不足 |
| Large Kernel Distillation | 大核卷积感受野大但计算贵 |
| Semi-sharing | 多层重复计算注意力导致复杂度高 |
这几个模块不是为了堆复杂度,而是围绕同一个目标:
让轻量模型看得更远,并且不要明显增加计算量。
3. 核心模块一:High Performance Attention 与 Hedgehog Attention
UCAN 首先使用 High Performance Attention,也就是 HPA,来解决窗口注意力的问题。
普通 Window Attention 的思路是把特征划分成局部窗口,在每个窗口内部做 self-attention。这样比全局 attention 便宜,但如果窗口变大,计算量仍然会上升。
对于超分任务来说,窗口太小是不够的。因为超分不是分类任务,它要恢复像素级细节。很多纹理和结构需要参考更大范围的上下文。
比如 Urban100 中的建筑窗格,很多窗户是周期性重复的;Manga109 中的漫画线条,也经常跨越较大区域。如果模型只能看到很小窗口,就容易恢复出不连续、不规整的结构。
所以 HPA 的作用可以理解为:
让模型能够使用较大的窗口进行局部上下文建模,同时通过高效 attention 计算控制复杂度。
不过,仅有窗口注意力还不够。UCAN 还引入了 Hedgehog Attention,用于增强线性注意力的表达能力。
普通 softmax attention 可以写成:
text
Attention(Q, K, V) = softmax(QK^T)V它表达能力强,但在高分辨率图像中计算完整 attention matrix 比较贵。线性注意力的思路是用 feature map 把注意力改写成更低复杂度形式:
text
softmax(QK^T)V → φ(Q)(φ(K)^T V)这样计算更省,但问题是特征表达能力可能下降,容易出现论文中提到的 rank collapse,也就是特征秩不足、特征多样性不够。

这张图对比了不同 feature map 的表达能力。ReLU、ELU 这类映射虽然简单,但可能丢失一部分特征方向。Hedgehog feature map 通过正负方向拼接,保留更多特征信息,从而提升线性注意力的表达能力。
它的核心思想可以非常简单地理解成:
text
普通 feature map:只保留一部分方向的信息
Hedgehog feature map:同时保留正方向和负方向的信息代码层面可以概括成一句:
python
hedgehog_feature = softmax(concat([2 * x, -2 * x]))这不是为了写花哨,而是为了让线性注意力在保持低计算量的同时,尽量保留更多有效特征方向。
所以 UCAN 中 Hedgehog Attention 的意义是:
用接近线性注意力的复杂度,获得比普通线性 feature map 更强的表达能力。
4. 核心模块二:Semi-sharing,减少重复计算但不完全共享
UCAN 另一个比较重要的设计是 semi-sharing,也就是半共享机制。
普通网络中,每一层 attention 通常都要重新计算 q、k、v 和 attention map。这样当然灵活,但问题是:不同层之间可能存在大量重复计算。
UCAN 的想法是:前面的 Sharing Block 先计算一部分注意力信息,后面的 Receiving Block 复用其中一部分,而不是每一层都完全重新计算。
论文中对应两个模块:
| 模块 | 含义 | 作用 |
|---|---|---|
| SDFL | Shared Dual Fusion Layer | 完整计算 q、k、v,并共享部分信息 |
| DFRL | Dual Fusion Receiver Layer | 接收共享信息,只更新当前层需要的内容 |
可以这样理解:
text
SDFL:我先完整算一遍注意力关系,并把 q、k 共享出去
DFRL:我不重复算 q、k,只更新自己的 v为什么共享 q、k,而不是全部共享?
因为 q 和 k 更像是在决定"关注哪里",而 v 更像是在决定"取什么内容"。如果 q、k 里已经包含了比较稳定的注意力关系,后续层可以复用它们;但每一层的特征内容仍然需要更新,所以 v 不能完全照搬。
这就是 semi-sharing 的核心:
text
完全独立:表达能力强,但重复计算多
完全共享:计算量低,但表达能力弱
半共享:共享注意力关系,保留内容更新这个设计非常适合轻量模型。轻量化不是简单减少参数,而是要减少无效重复计算,同时避免特征表达能力明显下降。
UCAN 在窗口注意力中也有类似做法。普通窗口注意力需要自己计算 attention map,而共享窗口注意力可以复用前面已经算好的 attention map,只重新计算当前层 value。
这样一来,UCAN 既保留了 attention 的上下文建模能力,又避免了每一层都从零计算 attention 带来的额外开销。
5. 核心模块三:Large Kernel Distillation,用低成本大核增强空间结构
UCAN 的第三个关键模块是 Large Kernel Distillation,简称 LKD。
大核卷积的好处很明显:卷积核越大,模型能看到的空间范围越大,也就更容易捕获长距离结构和大范围纹理。
但问题同样明显:直接使用大核卷积会增加参数量和计算量,尤其是在轻量超分模型中,很难无脑堆大核。
UCAN 的 LKD 没有直接把所有特征都送入大核卷积,而是采用了特征拆分和多分支处理的方式。
| 分支 | 作用 |
|---|---|
| Large Kernel Spatial Branch | 捕获大范围空间结构 |
| Small Kernel Spatial Branch | 保留局部纹理细节 |
| Channel Branch | 做通道选择和特征增强 |
可以把它理解成:
text
一部分特征看远处结构
一部分特征看局部细节
一部分特征负责通道选择
最后再融合这其实就是"蒸馏"的含义:不是所有特征都走复杂路径,而是把不同类型的信息分流处理,尽量把计算用在关键地方。
大核空间分支中,UCAN 还使用了几个轻量化技巧:
| 技巧 | 作用 |
|---|---|
| Depth-wise convolution | 降低卷积计算量 |
| 水平/垂直方向分解 | 用一维方向卷积近似二维大核 |
| Dilation | 在不显著增加参数的情况下扩大感受野 |
| 小核旁路 | 保留局部细节,不让模型只关注大范围结构 |
所以 LKD 的核心不是简单一句"大核卷积有效",而是:
用 depth-wise、方向分解、dilation 和特征蒸馏,在较低成本下获得更大空间建模范围。
这个模块很适合后续做二次改进,因为它本身就是一个结构化模块,容易替换、增强或者动态化。
6. 实验结果:UCAN 到底强在哪里?
UCAN 在 Set5、Set14、BSD100、Urban100 和 Manga109 五个经典超分数据集上进行实验,指标是 PSNR 和 SSIM。
下面是论文中 ×4 设置下部分结果整理:
| Method | Params | MACs | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|---|
| OmniSR | 792K | 50.9G | 32.49 | 28.78 | 27.71 | 26.64 | 31.02 |
| SRFormer-light | 873K | 62.8G | 32.51 | 28.82 | 27.73 | 26.67 | 31.17 |
| ATD-light | 769K | 100.1G | 32.63 | 28.89 | 27.79 | 26.97 | 31.48 |
| MambaIRV2-light | 790K | 75.6G | 32.51 | 28.84 | 27.75 | 26.82 | 31.24 |
| ESC | 968K | 149.2G | 32.68 | 28.93 | 27.80 | 27.07 | 31.54 |
| UCAN | 705K | 38.1G | 32.65 | 28.95 | 27.79 | 26.89 | 31.50 |
| UCAN-L | 902K | 48.4G | 32.68 | 28.99 | 27.80 | 27.06 | 31.63 |
从表中可以看到,UCAN 的重点不是用最大参数量去刷最高指标,而是在较低 MACs 下获得比较强的性能。
特别是 UCAN-L,在 Manga109 ×4 上达到 31.63 dB,同时 MACs 只有 48.4G。对于轻量级超分来说,这种性能-复杂度平衡比单纯 PSNR 更重要。
为什么 Manga109 和 Urban100 更能体现 UCAN 的优势?
因为这两个数据集包含大量复杂结构:
| 数据集 | 结构特点 |
|---|---|
| Urban100 | 建筑、窗户、栅格、重复线条 |
| Manga109 | 漫画线条、网点纹理、强边缘结构 |
这些内容非常依赖长程上下文。如果模型感受野不足,就容易出现纹理错乱、线条断裂、重复结构不规整等问题。

视觉对比中,重点不是看图像是否简单变锐,而是看结构是否恢复正确。例如建筑窗户是否规整、线条是否连续、重复纹理是否一致。UCAN 的优势主要体现在复杂重复结构的恢复上,这和它扩大有效感受野的设计目标是一致的。
论文还给出了 ERF 和 LAM 分析,用来证明 UCAN 不是只在指标上变好,而是真的利用了更大范围的信息。
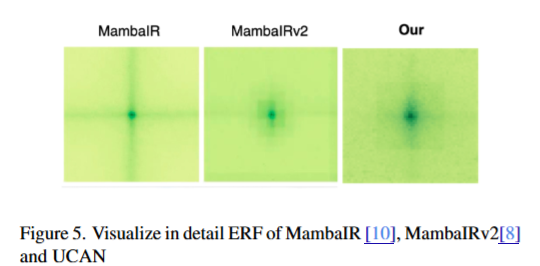
ERF 是 Effective Receptive Field,也就是有效感受野。响应区域越大,说明模型在恢复局部区域时能利用更广范围的信息。

LAM 是 Local Attribution Maps,用来分析模型在恢复某个目标区域时主要参考了输入图像中的哪些位置。LAM 区域越大,说明模型利用的上下文越广。
UCAN 的论文证据链比较完整:
text
结构设计:HPA + Hedgehog Attention + LKD + semi-sharing
↓
可视化分析:ERF / LAM 证明感受野更大
↓
定量结果:Urban100 / Manga109 等复杂纹理数据集表现更好这也是这篇论文值得学习的地方。它不是只说"我提出一个模块",而是围绕一个问题提供了结构、可视化和实验三方面证据。
7. 消融实验:哪些设计真正有效?
消融实验是理解 UCAN 的关键。论文主要验证了 HPA、窗口大小、Hedgehog feature map、LKD kernel size 和 sharing strategy 的作用。
| Block | Case | Set5 PSNR | Set5 SSIM | Urban100 PSNR | Urban100 SSIM |
|---|---|---|---|---|---|
| HPA | w/o HPA | 38.27 | 0.9616 | 32.90 | 0.9346 |
| HPA | regular window | 38.32 | 0.9617 | 33.04 | 0.9364 |
| WMHA | smaller WS | 38.32 | 0.9617 | 33.02 | 0.9361 |
| DFL | ReLU | 38.33 | 0.9618 | 33.16 | 0.9374 |
| DFL | ELU+1 | 38.33 | 0.9618 | 33.16 | 0.9373 |
| LKD | smaller/larger KS | 38.33/38.34 | 0.9618 | 33.12/33.15 | 0.9369/0.9372 |
| Sharing | Full sharing | 38.29 | 0.9617 | 32.89 | 0.9350 |
| UCAN | Full model | 38.34 | 0.9618 | 33.22 | 0.9379 |
这组结果可以得到几个结论。
第一,去掉 HPA 后性能下降,说明高效窗口注意力确实有作用。尤其是在 Urban100 上,下降更明显,因为 Urban100 对复杂结构和上下文信息更加敏感。
第二,窗口大小不能太小。窗口变小后,模型能利用的上下文范围变小,复杂纹理恢复能力会受到影响。
第三,ReLU 和 ELU feature map 不如 Hedgehog feature map。这说明 Hedgehog Attention 不是一个随便换名字的设计,而是确实缓解了线性注意力表达能力不足的问题。
第四,LKD 的 kernel size 需要平衡。大核不是越大越好,过小感受野不足,过大又可能带来冗余和不稳定。
第五,Full sharing 不如 semi-sharing。完全共享虽然更省计算,但会损害特征表达能力。UCAN 的半共享机制更加合理,因为它共享注意力中的重复部分,同时保留每层自己的内容表征。
这组消融实验和论文主线是统一的:
UCAN 的每个模块都在围绕"扩大有效感受野"和"控制复杂度"服务。
8. 代码复现:只看最关键的入口
UCAN 代码基于 BasicSR,所以复现流程和 SwinIR、HAT、MambaIR 等项目比较类似。
安装环境:
bash
git clone https://github.com/hokiyoshi/UCAN.git
cd UCAN
conda create -n UCAN python=3.10
conda activate UCAN
pip install -r requirements.txt
python setup.py develop这里 python setup.py develop 很重要。BasicSR 项目如果不执行这一步,容易出现自定义网络注册失败、模块找不到等问题。
测试命令:
bash
python basicsr/test.py -opt options/Test/test_UCAN_x2.yml
python basicsr/test.py -opt options/Test/test_UCAN_x3.yml
python basicsr/test.py -opt options/Test/test_UCAN_x4.yml训练命令:
bash
python basicsr/train.py -opt options/Train/train_UCAN_x2.yml第一次复现不建议直接完整训练。更稳的路线是:
text
先跑官方预训练模型测试
↓
确认数据路径和权重路径没问题
↓
再把 total_iter 改小跑一个小训练
↓
最后再考虑完整训练源码阅读也不要一上来钻进所有模块。建议先看主干文件:
text
basicsr/archs/ucan_arch.py阅读顺序可以是:
text
UCAN 主类
↓
ResidualGroup / BasicLayer
↓
HybridBlock
↓
SDFL / DFRL
↓
Window Attention / Hedgehog Attention
↓
Large Kernel Distillation如果只是想使用 UCAN 作为 baseline,重点改配置文件和数据路径即可。如果想基于 UCAN 写新论文,真正值得改的地方主要是 Hybrid Attention、Large Kernel Distillation 和 Sharing Strategy。
9. UCAN 的优点、不足与改进方向
UCAN 的优点主要有三个。
第一,动机清楚。它抓住了轻量 SR 中"有效感受野不足"和"计算量受限"的矛盾,这个问题本身就很自然。
第二,模块目标统一。HPA、Hedgehog Attention、LKD 和 semi-sharing 虽然是不同模块,但都服务于扩大有效感受野和降低复杂度。
第三,实验支撑比较完整。论文不仅给出 PSNR/SSIM,还给出了视觉对比、ERF、LAM 和消融实验,说明作者不是只堆了一个模块,而是把问题、方法和证据串了起来。
不过 UCAN 也有不足。
首先,它的创新有一定组合式创新的味道。Flash Attention、大核卷积、窗口注意力、参数共享等概念都不是完全新的,UCAN 的价值更多在于组合和适配。
其次,模块数量比较多。HPA、SHA、RHA、SDFL、DFRL、LKD、SGFN、ESA 等结构叠在一起,对初学者读代码不算特别友好。
最后,它主要还是经典 bicubic SR。如果后续继续只在 Set5、Set14、Urban100、Manga109 上卷,应用价值可能不够强。更适合的路线是把 UCAN 迁移到更具体的场景。
9.1 Geo-UCAN:遥感图像超分
这是比较推荐的方向。
遥感图像天然需要大感受野。建筑群、道路、农田、河流、机场跑道等结构具有明显几何形态和大范围重复纹理。UCAN 的大感受野设计和遥感超分很契合。
可以设计:
text
Geo-UCAN: Geometry-Aware Unified Convolutional Attention Network for Remote Sensing Image Super-Resolution核心思路是在 UCAN backbone 后加入几何结构引导分支,让模型更加关注建筑边缘、道路结构和重复纹理。
论文动机可以写成:
现有轻量 SR 方法主要面向自然图像,对遥感图像中的几何边缘、重复纹理和大范围结构建模不足。基于 UCAN 的大感受野能力,引入几何结构引导模块,可以提升建筑边缘、道路纹理和遥感重复结构恢复质量。
可以考虑的实验设置:
| 内容 | 选择 |
|---|---|
| 数据集 | AID、UCMerced、NWPU-RESISC45、DOTA 裁剪 |
| 对比方法 | EDSR、RCAN、SwinIR、HAT、OmniSR、MambaIR、UCAN |
| 指标 | PSNR、SSIM、Params、FLOPs、Runtime |
| 可视化 | 建筑边缘、道路纹理、机场跑道、重复屋顶 |
这个方向优点是论文故事比较完整,可视化也容易做。
9.2 Real-UCAN:真实退化图像超分
UCAN 主要针对 bicubic 退化,而真实图像退化往往包含模糊、噪声、压缩伪影和未知退化核。
可以在 UCAN 中加入 degradation-aware modulation,让网络根据输入退化情况动态调整特征。
这个方向的核心故事是:
UCAN 能在理想退化下扩大感受野,但真实退化场景中,不同图像的退化类型差异较大。通过退化感知调制,可以让网络根据模糊、噪声和压缩特征动态调整恢复过程。
可以考虑:
| 内容 | 选择 |
|---|---|
| 数据集 | RealSR、DRealSR、DPED、Real-ESRGAN 合成退化数据 |
| 指标 | PSNR、SSIM、LPIPS、NIQE、MUSIQ、MANIQA |
| 重点 | 真实退化泛化能力、视觉质量、感知指标 |
这个方向应用价值更强,但训练和评估复杂度也更高。
9.3 Dynamic-LKD:动态大核蒸馏
UCAN 的 LKD 使用固定大核设计,但不同图像区域需要的感受野并不一样。
平坦区域不需要很大核,边缘区域需要中等范围,重复纹理区域可能需要更大范围。因此可以把 LKD 改成动态选择不同尺度卷积核。
论文动机可以写成:
固定大核难以适应不同区域的结构差异,因此设计动态大核蒸馏,根据图像内容自适应选择不同尺度感受野。
这个方向改动集中,适合做模块级创新,也比较容易做消融实验。
10. 总结
UCAN 这篇论文的核心可以概括为:
通过高效窗口注意力、Hedgehog 线性注意力、大核蒸馏和半共享机制,在轻量级超分网络中扩大有效感受野,并控制参数量和计算量。
它最值得学习的不是某一个单独模块,而是整篇论文的组织逻辑:
text
问题:轻量 SR 模型有效感受野不足
矛盾:扩大感受野会增加计算量
方法:高效注意力 + 大核蒸馏 + 半共享
证据:PSNR/SSIM + ERF + LAM + 消融实验对于想做超分论文的人来说,UCAN 有两个价值。
第一,它可以作为 CVPR 2026 轻量 SR 的新 baseline。
第二,它提供了多个可继续改进的入口,比如遥感图像超分、真实退化超分、动态大核蒸馏等。
如果后续想基于 UCAN 写新论文,我个人更看好 Geo-UCAN 这条路线。遥感图像本身就需要长程结构建模,与 UCAN 的大感受野设计高度匹配,而且边缘、道路、建筑等结构也方便做可视化和消融实验。
总的来说,UCAN 不是那种完全颠覆式工作,但它把轻量化、大感受野和高效注意力结合得比较完整,是一篇很适合复现、分析和二次改进的 CVPR 2026 超分论文。