大家好,我是你们的技术伙伴。👋
在机器学习的算法家族中,Logistic回归(逻辑回归)堪称"万能基石"。它不仅是金融风控、医疗诊断、点击率预估等领域的首选模型,更是理解深度学习神经网络激活函数的起点。尽管它的名字里带有"回归"二字,但它本质上是一个强大的二分类(及多分类)算法。
在2026年的今天,面试官在考察Logistic回归时,不再满足于简单的API调用,而是更关注候选人对概率建模 、损失函数凸性 以及多分类扩展的深度理解。
今天,我将为你带来一份Logistic回归面试题深度解析。我们将涵盖从基础的Sigmoid特性到复杂的Softmax多分类原理,助你在面试中脱颖而出。
1. Logistic 回归为什么叫回归?
Logistic回归之所以被称为"回归",是因为它的算法本质是基于线性回归的扩展。在构建模型时,它首先像线性回归一样,对特征进行线性加权求和,得到一个线性打分 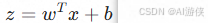 。然而,由于分类问题的目标变量是离散的(如0或1),不能直接套用线性回归。因此,它引入了一个非线性的Sigmoid函数(也称为逻辑函数),将这个连续的线性打分"映射"或"压缩"到了(0, 1)的概率区间。这种"先线性回归,再通过逻辑函数变换"的建模过程,使得它在数学推导上保留了回归的基因,故而得名。
。然而,由于分类问题的目标变量是离散的(如0或1),不能直接套用线性回归。因此,它引入了一个非线性的Sigmoid函数(也称为逻辑函数),将这个连续的线性打分"映射"或"压缩"到了(0, 1)的概率区间。这种"先线性回归,再通过逻辑函数变换"的建模过程,使得它在数学推导上保留了回归的基因,故而得名。
2. Logistic 回归的原理是什么?
Logistic回归的核心原理是不做"非黑即白"的硬分类,而是输出"某个样本属于正类的概率"。它首先构建一个线性模型 来计算特征的线性组合,然后通过Sigmoid函数 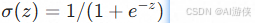 将这个任意实数范围的线性打分压缩到(0, 1)之间,使其可以被解释为概率。当预测概率 p≥0.5 时,模型判定为正类(1);当 p<0.5 时,判定为负类(0)。在统计学层面,Logistic回归假设因变量服从伯努利分布(0-1分布),并通过最大似然估计(MLE)来寻找最优的模型参数,使得观测到的这批训练数据出现的可能性最大。
将这个任意实数范围的线性打分压缩到(0, 1)之间,使其可以被解释为概率。当预测概率 p≥0.5 时,模型判定为正类(1);当 p<0.5 时,判定为负类(0)。在统计学层面,Logistic回归假设因变量服从伯努利分布(0-1分布),并通过最大似然估计(MLE)来寻找最优的模型参数,使得观测到的这批训练数据出现的可能性最大。
3. Sigmoid 函数有什么特点?
Sigmoid函数是Logistic回归的灵魂,它具有几个非常鲜明的数学与工程特点。首先,它的输出范围严格限制在(0, 1)区间内,完美适配概率预测的场景;其次,它是一个光滑且严格单调递增的函数,且在 z=0 时输出恰好为0.5,这为分类决策提供了天然的边界。在优化层面,Sigmoid函数处处可导,且其导数可以用自身表示(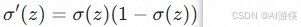 ),这极大地简化了反向传播时的梯度计算。不过,Sigmoid也存在一定的局限性,当输入值趋于正无穷或负无穷时,其梯度会趋近于零,在深层网络中容易引发梯度消失问题,且其计算涉及指数运算,相对复杂。
),这极大地简化了反向传播时的梯度计算。不过,Sigmoid也存在一定的局限性,当输入值趋于正无穷或负无穷时,其梯度会趋近于零,在深层网络中容易引发梯度消失问题,且其计算涉及指数运算,相对复杂。
4. Logistic 回归为什么使用交叉熵损失?
Logistic回归使用交叉熵损失函数,根本上是因为它与模型的统计学基石------最大似然估计(MLE)是完全等价的。当我们假设数据服从伯努利分布并推导其对数似然函数时,取负号后得到的正是交叉熵损失的形式。从优化的角度来看,交叉熵损失函数关于模型参数是一个凸函数,这意味着损失曲面只有一个唯一的全局最低点,使用梯度下降法一定能收敛到全局最优解。此外,交叉熵的梯度形式极其简洁(误差 = 预测概率 - 真实标签),这使得参数更新非常高效且直观。
5. Logistic 回归为什么不用 MSE?
如果在Logistic回归中使用均方误差(MSE),会导致严重的优化灾难。因为MSE套上Sigmoid这个非线性函数后,整体损失函数关于参数 w 会变成一个非凸函数。非凸函数的图像上会存在许多局部的"小坑"(局部最优解),当我们使用梯度下降法寻找最低点时,很容易"掉进"一个小坑里就出不来了,无法保证找到全局最优解,导致模型训练结果极不稳定。此外,当模型预测错得很离谱时,MSE产生的梯度反而很小(因为Sigmoid进入了饱和区),导致模型修正速度极慢;而交叉熵在预测错误时会产生巨大的梯度惩罚,迫使模型快速学习。
6. Logistic 回归如何处理多分类问题?
当类别数 K>2 时,标准的二分类Logistic回归可以通过策略扩展或模型升级来处理多分类问题。主要有三种主流方法:第一种是 One-vs-Rest (OvR) ,即为每个类别训练一个独立的二分类器,区分"该类别"与"所有其他类别",预测时选择概率最高的类别;第二种是 One-vs-One (OvO) ,为每对类别训练一个二分类器,通过投票机制决定最终类别;第三种是直接升级为 Softmax回归(Multinomial Logistic Regression),这是最正统的多分类扩展,它直接为每个类别计算线性得分,并通过Softmax函数将其转化为一个总和为1的概率分布,同时优化所有类别的参数。
7. One-vs-Rest 和 One-vs-One 的区别是什么?
One-vs-Rest (OvR) 和 One-vs-One (OvO) 的核心区别在于分类器的数量和训练策略。OvR需要训练 K 个分类器,实现简单且可重用二分类代码,但在类别数量很大时,每个二分类器面对的正负样本会极度不平衡。OvO则需要训练 K(K−1)/2 个分类器,随着类别增加,分类器数量呈平方级增长,训练成本较高;但它的优势在于每个分类器只在两个类别间进行区分,完美避免了类别不平衡问题,且通常能提供更精细的决策边界。在实际工程中,OvR因其计算效率高而更为常用,而OvO则常用于对分类精度要求极高且类别数适中的场景。
8. Softmax 函数是什么?
Softmax函数是Sigmoid函数在多分类场景下的自然推广。它的核心作用是将一个包含 K 个任意实数(线性得分 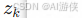 )的向量,压缩并转化为一个 K 维的概率分布向量。其计算公式为
)的向量,压缩并转化为一个 K 维的概率分布向量。其计算公式为 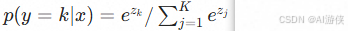 。Softmax函数确保了所有类别的预测概率都是正数,且所有类别的概率之和严格等于1。这使得模型输出的结果可以直接被解释为样本属于各个类别的置信度,配合多类交叉熵损失函数,能够非常优雅地解决多分类任务中的概率建模与参数优化问题。
。Softmax函数确保了所有类别的预测概率都是正数,且所有类别的概率之和严格等于1。这使得模型输出的结果可以直接被解释为样本属于各个类别的置信度,配合多类交叉熵损失函数,能够非常优雅地解决多分类任务中的概率建模与参数优化问题。
9. Softmax 和 Sigmoid 的区别是什么?
Sigmoid和Softmax虽然都是将实数映射到概率空间的激活函数,但适用场景和数学性质截然不同。Sigmoid主要用于二分类 问题,它将单个线性得分独立地映射到(0, 1)之间,各个类别的概率之间没有强制的归一化约束(即 P(y=1) 和 P(y=0) 是互补的)。而Softmax主要用于多分类问题,它同时处理多个类别的线性得分,通过分母上的求和项引入了类别间的"竞争机制",确保所有类别的概率总和为1。可以说,当类别数 K=2 时,Softmax函数在数学上就等价于Sigmoid函数,Sigmoid是Softmax在二分类下的特例。
📌 结语
Logistic回归看似简单,实则蕴含了丰富的统计学思想与优化智慧。从Sigmoid的概率映射到交叉熵的凸优化保障,再到Softmax的多分类扩展,每一个设计都体现了机器学习"大道至简"的美学。
希望这篇深度解析能帮你彻底打通Logistic回归的底层逻辑。如果你在面试或工作中遇到了相关难题,欢迎在评论区留言讨论。如果觉得文章对你有帮助,可以点赞、收藏、关注.