我的第一个开源项目:一个桌面小窗口,帮你看清此刻的世界
❝
一个计算机专业大学生的第一个亲手做的项目,从零到 GitHub 开源,记录这一路的踩坑与收获。
故事从一个"信息焦虑"的下午开始
不知道你有没有过这种感觉:刷了一个小时的短视频,放下手机后回想一下,好像什么都看了,又好像什么都没记住。时间倒是确确实实地没了。
我和大多数人一样,每天的信息来源就是抖音、B站、小红书。吃饭的时候刷几条,课间刷几条,睡前再刷半小时。15 秒一条,手指一滑就过去了,轻松、解压、不用动脑。直到有天下午我在宿舍赶课程作业,一边开着 B 站当"背景音",一边刷朋友圈,突然看到有人在讨论一个科技圈的新闻------我当时完全不知道那是什么。去搜了一下才发现,这件事已经在热搜上挂了整整一个下午了,而我刷了两小时短视频,一条都没看到。
那一刻我忽然意识到一个问题:我以为自己一直在"看新闻",但实际上我看到的只是算法喂给我的东西。
短视频时代的"信息茧房"
这不是我一个人的问题。
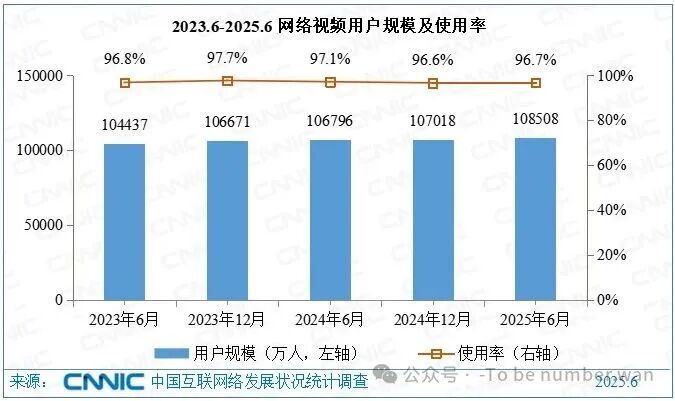
根据中国互联网络信息中心(CNNIC)的报告,截至 2025 年,中国短视频用户规模已超过 10 亿,人均单日使用时长超过 2.5 小时。大学生群体更是重度用户------课堂间隙刷、食堂排队刷、熄灯前还要再刷一会儿。短视频已经成为很多人获取信息的第一渠道。
但短视频天然有几个局限,而这些局限正在悄悄塑造我们对世界的认知:
第一,算法茧房。 你点赞了一条娱乐八卦,接下来十条推荐全是同类型的。你以为世界就是这个样子,其实你只是被困在了一个越缩越小的信息泡泡里。算法的目标是让你"多看一会儿",而不是让你"看得更全"。
第二,碎片化严重。 一条 15 秒的视频只能传递一个碎片:一句话、一个画面、一个情绪。它告诉你"某某塌房了",但不告诉你前因后果;它给你看一段掐头去尾的采访,但不给你完整的上下文。你以为自己了解了全貌,其实你只看到了一个切面。
第三,被动投喂。 刷短视频是不需要主动选择的------你不用想"今天该看什么",算法替你想好了。但这也意味着你的信息面完全被算法定义了。科技动态、政策解读、行业新闻......这些"不够刺激"的内容,天然在推荐权重中排在后面。
第四,效率极低。 看完一条 15 秒的短视频,你获得的信息量可能还不如读一行文字标题。但视频的时间成本是固定的,你没法"一目十行"地扫视频。
我不是说短视频不好------它确实有它的价值,娱乐、放松、学习技能都可以。但如果你把短视频当成"了解世界"的主要渠道,那你看到的世界一定是被严重过滤和扭曲的。
我想要的是什么?
想明白这些之后,我开始问自己:有没有一种方式,能让我用最少的时间、最低的操作成本,快速知道"此刻正在发生什么"?
我列了几个需求:
-
不能打断我手头的事------写代码、写论文、做项目的时候,不想切换到别的 App
-
信息密度要高------一眼就能看到十几条热点,而不是一条一条地刷
-
覆盖面要广------不能只看某一类信息,社会、娱乐、科技都要有
-
不用我主动去刷------最好它就在那里,我想看就看一眼,不想看也不碍事
-
点击就能深入了解------看到感兴趣的标题,一步跳转详情
想了一圈,发现市面上的资讯类 App 都不太满足:要么太重(打开一个新闻 App 要花好几秒),要么太吵(推送通知一个接一个),要么信息面太窄(只看某一类)。
那为什么不自己做一个呢?刚好我是计算机专业的,刚好我在学 Python,刚好我一直想做点"真正能用"的东西而不只是课程作业。
于是,HotSearch 诞生了。
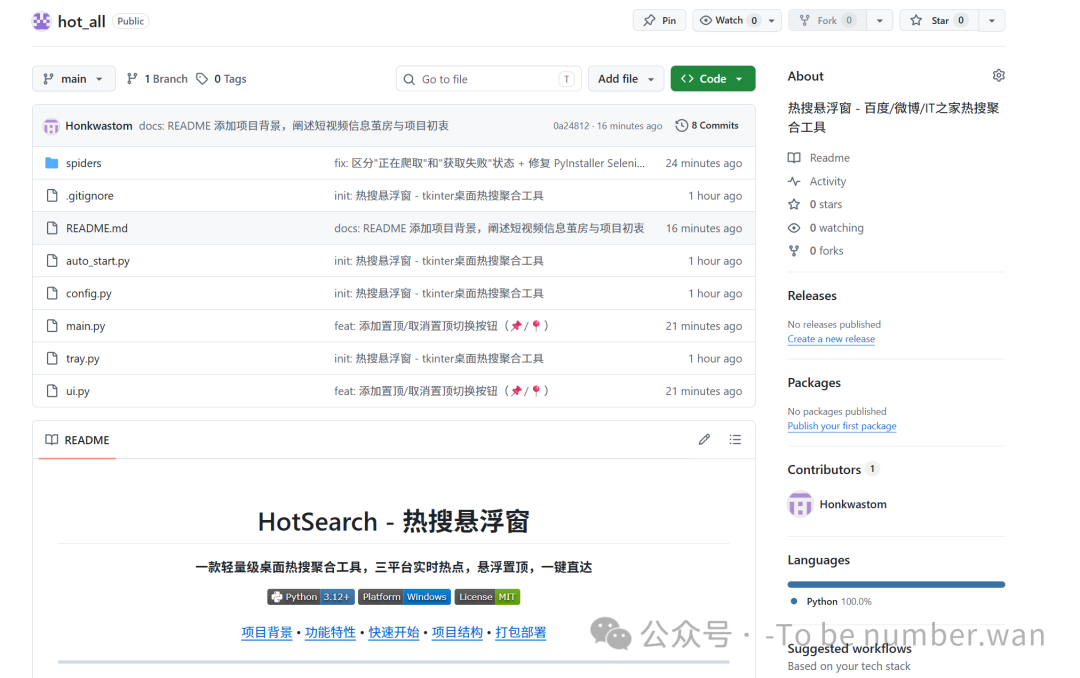
它是什么?
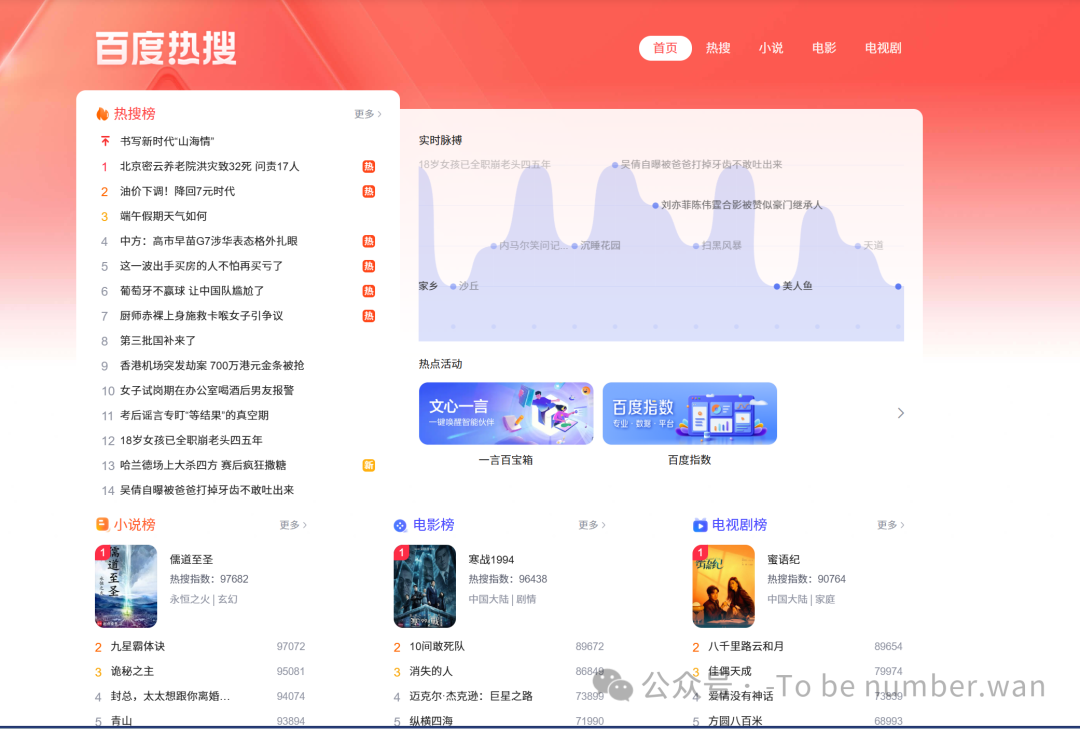
简单来说,HotSearch 是一个桌面悬浮窗小工具。它实时聚合了百度热搜、微博热搜、IT之家热门资讯三个平台的数据,以一个半透明的小窗口"钉"在你的桌面角落。
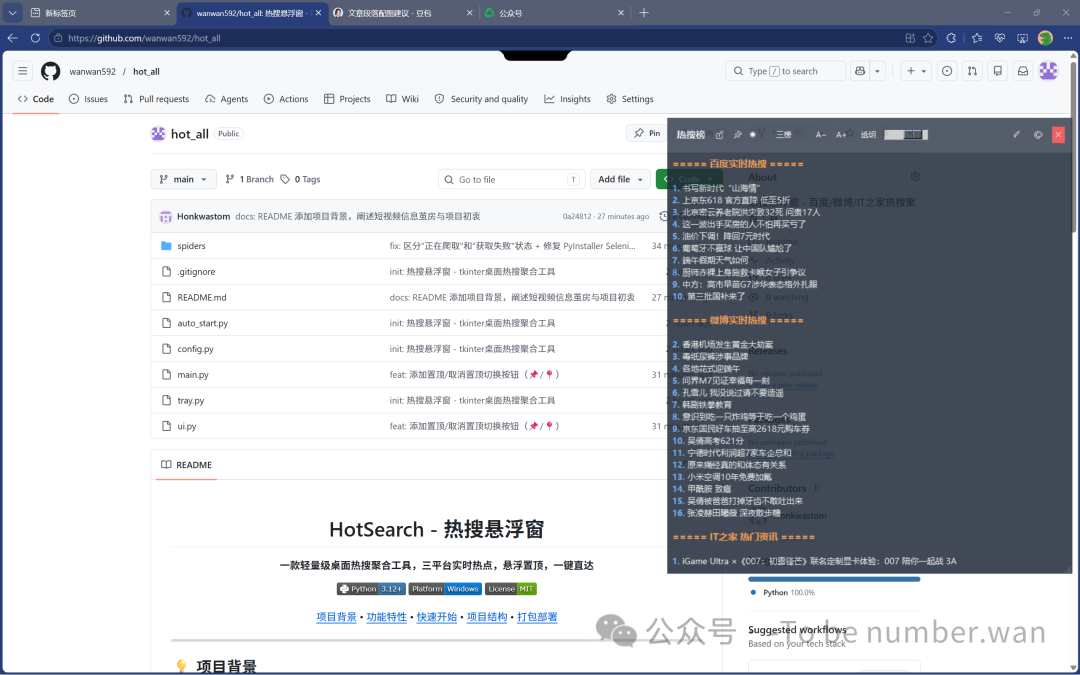
你可以一边写代码、一边写文档、一边打游戏,眼角余光就能看到最新的热点。想了解哪条?点一下标题,自动跳转浏览器详情页。
不干扰你,但你需要的时候,它一直在。
打个比方:传统的新闻 App 像是你主动走到报亭去买报纸,而 HotSearch 更像是把报亭的头条滚动屏搬到了你的桌角------你不用做任何操作,信息自己来到你面前。
为什么是这三个平台?
不是随便选的。每个平台都有自己的"信息人格":
| 平台 | 定位 | 你能看到什么 | 看不到什么 |
|---|---|---|---|
| 百度热搜 | 全民搜索引擎 | 大众最关心的社会热点、民生话题、政策解读 | 小圈子的亚文化话题 |
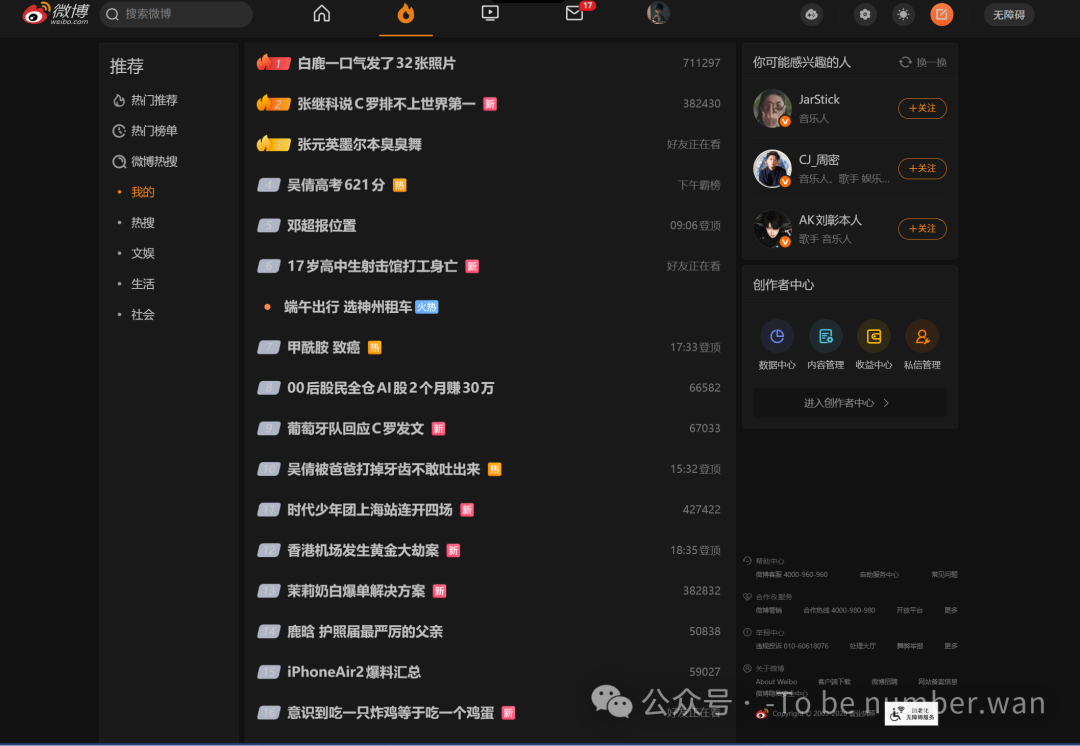
| 微博热搜 | 社交媒体舆论场 | 娱乐八卦、突发事件、网络热议、明星动态 | 严肃的深度报道 |
| IT之家 | 科技数码资讯 | 手机发布、系统更新、AI 动态、行业趋势 | 娱乐和社会新闻 |
三个平台覆盖了社会面、舆论面、科技面三个维度。百度告诉你"大家在关心什么",微博告诉你"大家在讨论什么",IT之家告诉你"科技圈在发生什么"。三个视角交叉在一起,基本就是当下中文互联网的全景图。
而且这三个平台都有一个共同点:它们的热搜/热榜都是实时更新的,反映的是"此刻"而不是"昨天"。这对于一个追求信息时效性的工具来说至关重要。
都有哪些功能?
功能不算复杂,但每一个都是从实际使用中打磨出来的:
📌 置顶随心控点击 📌 按钮,悬浮窗可以在"始终置顶"和"普通窗口"之间切换。写代码的时候让它置顶,随时瞟一眼;全屏打游戏的时候取消置顶,它就不会挡住你的准星了。
🎨 主题与配色内置深色和浅色两套主题,一键切换,熬夜党的眼睛会感谢你的。觉得默认配色不够个性?还有拾色器,标题栏、文字颜色、序号高亮色......全部可以自定义。我把它调成了和 IDE 一样的暗色主题,看起来浑然一体。
📊 三榜灵活切换默认三榜合并展示,一个窗口看完所有热点。如果你只关心某个平台,点击切换按钮可以只看百度、只看微博、或只看 IT之家。
🔍 点击即跳转点任何一条热搜标题,自动打开浏览器跳转到对应的详情页或搜索结果页。百度热搜跳到百度搜索,微博热搜跳到微博搜索页,IT之家直接跳到文章原文。零操作步骤,从"看到"到"了解"只需要一次点击。
💤 静默开机自启开机后自动启动,缩到系统托盘里,不占任务栏空间。你甚至感觉不到它的存在------但双击托盘图标,它就立刻弹出来。右键托盘菜单可以随时开关自启、显示/隐藏窗口、或完全退出。
🔄 智能并行刷新每 5 分钟自动抓取最新数据。三个爬虫在不同线程并行执行,哪个先回来就先显示哪个的数据------不会出现"因为微博爬得慢,所以百度和 IT之家也跟着一起等"的情况。加载中的榜单会显示"⏳ 正在爬取..."而不是"获取失败",直到数据真正到达才切换显示。
🔒 窗口锁定拖动时手抖容易把窗口位置弄乱?点击锁定按钮,窗口位置就固定了,不再响应拖拽。解锁后才能重新调整位置。
📐 自由缩放右下角有一个缩放手柄,拖动可以调整窗口大小。配合字体 A+/A- 按钮和透明度滑杆,可以调出最适合自己屏幕的尺寸和视觉效果。
谁适合用?
说实话,这个工具不是给所有人设计的。它最适合这几类人:
长期面对电脑工作的人。 程序员、设计师、写论文的学生......你的视线大部分时间都在屏幕上,一个角落里的信息窗口几乎零成本。
对信息广度有要求的人。 不满足于只看某一类信息,想知道社会热点、娱乐动态、科技趋势的交叉全貌。
想减少短视频时间的人。 如果你也意识到自己刷了太多短视频,但又需要一个"了解世界"的替代品,热搜聚合窗口是一个轻量级的选择。
不想被算法定义信息面的人。 热搜榜单是"大家在搜什么",不是"算法觉得你想看什么"。这是一种更客观的信息获取方式。
技术实现:踩了哪些坑?
作为我的第一个完整项目,这一路踩的坑比写的代码还多。简单聊聊技术选型和踩坑经历,也算给同样在学 Python 的同学一些参考。
技术栈一览
| 模块 | 方案 | 一句话说明 |
|---|---|---|
| GUI | tkinter |
Python 自带,不用装额外库,轻量够用 |
| 百度爬虫 | requests + lxml |
最经典的 HTTP + XPath 组合 |
| 微博爬虫 | Selenium + Edge |
微博页面是动态渲染的,得上浏览器 |
| IT之家爬虫 | requests + parsel |
CSS 选择器比 XPath 写起来更直观 |
| 系统托盘 | pystray + Pillow |
跨平台的托盘图标方案 |
| 开机自启 | winreg |
读写 Windows 注册表,几行代码搞定 |
| 打包发布 | PyInstaller |
打成单个 exe,双击就能用 |
三种爬虫:思路与实现
三个平台的数据获取方式完全不同,这也是我觉得这个项目最有学习价值的地方------同一个目标(拿到热搜数据),根据目标网站的特性选择不同的技术路线。
🔵 百度热搜:requests + lxml(XPath 解析)
百度热搜的思路最简单。百度首页本身就内嵌了热搜模块,而且这个数据是服务端直出的,不需要 JavaScript 渲染。
所以最轻量的方案就够了:用 requests 发一个 HTTP GET 请求拿到 HTML,再用 lxml 库通过 XPath 表达式提取标题文本。
python
res = requests.get("https://www.baidu.com/", headers=headers, timeout=10)
html = etree.HTML(res.text)
titles = html.xpath('//*[@id="hotsearch-content-wrapper"]/li/a/span[@class="title-content-title"]/text()')核心就是一个 XPath 表达式://span[@class="title-content-title"]/text(),定位到每个热搜标题的 <span> 标签,取它的文本内容。整个过程不到 1 秒就能完成,非常轻量。
但百度首页的 DOM 结构偶尔会改,所以我准备了四条不同的 XPath 作为备选,按优先级依次尝试,哪条能取到数据就用哪条。
这种"多路降级"的思路在实际爬虫项目中非常常见------你永远不能假设网页结构一成不变。
🟡 微博热搜:Selenium + Edge(无头浏览器)
微博就没那么友好了。
微博热搜页面(s.weibo.com/top/summary)是通过 JavaScript 动态渲染的。
如果你直接用 requests 去请求,拿到的只是一个空壳 HTML,真正的热搜数据藏在 JS 执行后才生成的 DOM 里。
这种情况就得搬出"重型武器"------Selenium。
它本质上是在后台启动一个真实的浏览器,让浏览器去加载页面、执行 JavaScript,等页面渲染完毕后再从 DOM 中提取数据。我用的是 Edge 浏览器(反正 Windows 自带,不用额外安装 Chrome),通过设置 --headless=new 参数让它在后台运行,用户完全看不到浏览器窗口。
python
options = EdgeOptions()
options.add_argument('--headless=new') # 后台运行,不弹窗口
options.add_argument('--disable-blink-features=AutomationControlled') # 隐藏自动化特征
options.add_experimental_option("excludeSwitches", ["enable-automation"])
driver = EdgeWebDriver(options=options)
driver.get('https://s.weibo.com/top/summary?cate=realtimehot')微博对爬虫有检测机制,所以我还加了一些反自动化检测的配置,比如禁用 enable-automation 开关、隐藏 WebDriver 标志等,让浏览器看起来更像是一个正常用户在操作。
等页面加载完后,用 WebDriverWait 显式等待热搜表格出现(最多等 15 秒),然后用 CSS 选择器 #pl_top_realtimehot tbody tr 逐行提取标题和热度值。每条热搜还会同时记录排名和热度数值。
这个方案虽然重(每次启动浏览器大概要 10 秒),但是最稳妥。对于动态渲染的页面,Selenium 基本是"终极方案"。
🟢 IT之家:requests + parsel(CSS 选择器)
IT之家的热门文章列表也是服务端直出的。
所以可以像百度一样用 requests 直接请求。但解析工具我换成了 parsel------这是 Scrapy 框架中提取数据的库,单独拿出来用也非常好用,它的 CSS 选择器语法比 XPath 更简洁直观。
python
resp = requests.get("https://www.ithome.com/", headers=headers, timeout=30)
sel = parsel.Selector(resp.text)
items = sel.css('#news_list .news-item a')IT之家的爬虫我花心思最多的地方是降级策略。
首先准备了五组不同的 CSS 选择器,应对页面改版。
如果这五组全部落空(说明 IT之家大改版了),还会启用一套"通用过滤方案":提取页面所有 <a> 标签,然后通过一系列规则过滤掉导航链接、下载链接、广告等杂质,只保留看起来像新闻标题的条目。
判断标准包括:标题长度 ≥ 5 个字、不包含"下载""RSS"等关键词、链接路径符合文章 URL 格式等。这套过滤虽然不完美,但至少保证爬虫不会因为一次改版就彻底瘫痪。
另外还加了 3 次重试机制和 2 秒间隔------网络偶尔抖动很正常,不能因为一次超时就放弃。最后还会对结果做去重,确保同一条新闻不会出现两次。
三种方案的对比总结:
| 百度 | 微博 | IT之家 | |
|---|---|---|---|
| 页面类型 | 静态直出 | JS 动态渲染 | 静态直出 |
| 请求方式 | requests HTTP GET |
Selenium 驱动真实浏览器 | requests HTTP GET |
| 解析工具 | lxml XPath |
Selenium CSS 选择器 | parsel CSS 选择器 |
| 速度 | 最快(~1s) | 最慢(~10s) | 快(~2s) |
| 反爬措施 | User-Agent | 隐藏自动化特征 | User-Agent + Referer |
| 容错策略 | 4 条 XPath 备选 | Selenium Manager + 手动驱动回退 | 5 组选择器 + 通用过滤 + 3 次重试 |
这三个爬虫基本覆盖了新手能遇到的三大类场景:简单静态页面 、JavaScript 动态渲染 、需要鲁棒降级策略的复杂页面。如果你也在学爬虫,这三个刚好是一条递进的学习路径。
踩坑记录
坑一:主题切换失效 最初切换主题后界面完全没变化。后来发现是 current_color 字典被重新赋值了一个新对象,导致其他模块引用的还是旧的。解决方案是用 clear() + update() 原地修改,保持所有模块共享同一个引用。这个 Python 可变对象的"坑",课本上真不会讲。
坑二:微博爬虫一直失败 Selenium 4 把 WebDriver 改成了懒加载(__getattr__ 动态导入),PyInstaller 做静态分析的时候根本发现不了这些隐藏依赖。打包后的 exe 一跑就报 ModuleNotFoundError。最后只能显式 from selenium.webdriver.edge.webdriver import WebDriver,再配合 --hidden-import 参数双重保险。这个问题我排查了整整一天,翻遍了 StackOverflow 才定位到原因。
坑三:三个爬虫串行执行导致加载五分钟 最初百度、微博、IT之家三个爬虫是一个接一个跑的,微博用 Selenium 特别慢,导致整个界面卡在那里等半天。改成多线程并行执行后,配合 threading.Lock 保证缓存写入的线程安全,哪个先回来就先渲染哪个,体验好了非常多。这也是我第一次真正理解"并发"在实际项目中的意义------课本上学的多线程,终于用上了。
坑四:打包成 exe 后 tkinter 找不到 DLL 我用的 Anaconda 环境,PyInstaller 没法自动发现 conda 的 DLL 路径。tcl86t.dll、tk86t.dll 等 6 个 DLL 都需要用 --add-binary 手动指定路径。这个排查花了整整一个下午,最后是在 PyInstaller 的 warning 日志里发现的线索。
写在最后
这是我的第一个完整项目。从爬虫到 GUI 到打包到开源,每一步都是自己摸索着走过来的。
说实话,做这个项目的过程中我才真正理解了很多课本上的概念:什么是线程安全、什么是懒加载、为什么共享引用要注意可变性、为什么打包工具需要做静态分析......这些东西,看十遍教材不如踩一次坑来得深刻。
项目本身很简单,代码肯定不够优雅,架构也算不上精巧。但它确确实实解决了我自己的一个痛点------不再被短视频的算法牵着鼻子走,用一个最小成本的方式,保持对世界的感知。 而且它每天都在被我自己使用,这大概就是一个开发者最大的成就感。
如果你是和我一样的计算机专业学生,正在犹豫要不要做自己的第一个项目,我的建议是:做。 不要等到"准备好了"再开始,因为你永远不会觉得自己准备好了。找一个你自己生活中的小痛点,用代码去解决它,做的过程中踩的每一个坑,都比刷十遍教程管用。
项目已经完全开源,欢迎 Star、Fork、提 Issue,也欢迎在评论区交流你的第一个项目是什么。
GitHub 仓库:github.com/wanwan592/hot_all
如果这个项目对你有帮助,请给我一个 ⭐ Star,这是对我最大的鼓励。