文章目录
- [1. 实战概述](#1. 实战概述)
- [2. 实战步骤](#2. 实战步骤)
-
- [2.1 准备数据文件](#2.1 准备数据文件)
- [2.2 创建Maven项目](#2.2 创建Maven项目)
- [2.3 添加项目相关依赖](#2.3 添加项目相关依赖)
- [2.4 创建日志属性文件](#2.4 创建日志属性文件)
- [2.5 创建HDFS配置文件](#2.5 创建HDFS配置文件)
- [2.6 在源程序目录里创建包](#2.6 在源程序目录里创建包)
- [2.7 词频统计 - 批处理模式](#2.7 词频统计 - 批处理模式)
-
- [2.7.1 创建`BatchWordCount`类](#2.7.1 创建
BatchWordCount类) - [2.7.2 运行程序,查看结果](#2.7.2 运行程序,查看结果)
- [2.7.1 创建`BatchWordCount`类](#2.7.1 创建
- [2.8 词频统计 - 流处理模式](#2.8 词频统计 - 流处理模式)
-
- [2.8.1 创建`StreamingWordCount`类](#2.8.1 创建
StreamingWordCount类) - [2.8.2 运行程序,查看结果](#2.8.2 运行程序,查看结果)
- [2.8.1 创建`StreamingWordCount`类](#2.8.1 创建
- [2.9 词频统计 - 处理流数据](#2.9 词频统计 - 处理流数据)
-
- [2.9.1 利用`nc`产生流数据](#2.9.1 利用
nc产生流数据) - [2.9.2 启动`nc`监听端口并保持开放](#2.9.2 启动
nc监听端口并保持开放) - [2.9.3 创建`StreamingDataWordCount`类](#2.9.3 创建
StreamingDataWordCount类) - [2.9.4 启动程序,利用`nc`输入数据,控制台查看结果](#2.9.4 启动程序,利用
nc输入数据,控制台查看结果) - [2.9.5 退出`nc`,程序结束](#2.9.5 退出
nc,程序结束)
- [2.9.1 利用`nc`产生流数据](#2.9.1 利用
- [3. 实战总结](#3. 实战总结)
1. 实战概述
- 本次实战基于Flink 2.2.0与Hadoop生态,构建了批流一体的词频统计系统。项目涵盖环境配置、Maven依赖管理及HDFS数据准备,核心实现了三种计算模式:基于BATCH的离线处理、基于FILE SOURCE的流式处理,以及利用NC指令模拟Socket实时数据流。通过对比不同模式下的数据处理逻辑与结果输出,深入掌握了Flink DataStream API的批流统一编程模型。
2. 实战步骤
2.1 准备数据文件
-
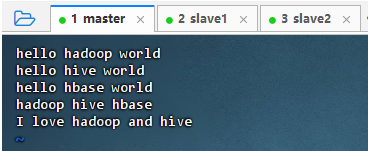
创建本地文件
- 执行命令:
vim words.txt
- 执行命令:
-
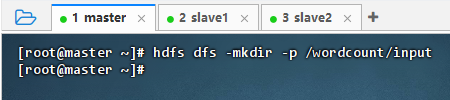
创建HDFS目录
- 执行命令:
hdfs dfs -mkdir -p /wordcount/input
- 执行命令:
-
上传文件到HDFS
- 执行命令:
hdfs dfs -put words.txt /wordcount/input

- 执行命令:
2.2 创建Maven项目
- 配置项目基本信息
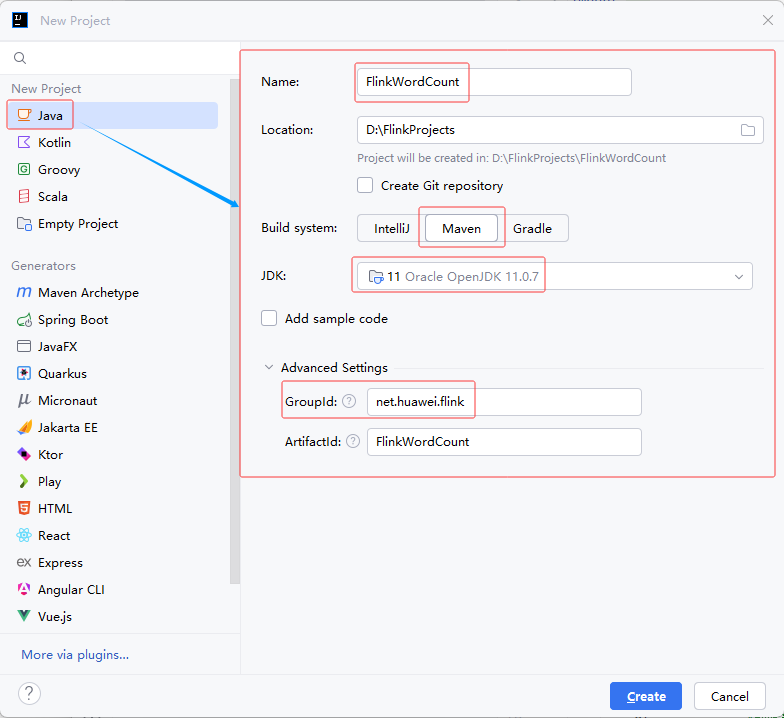
- 单击【Create】按钮,生成项目基本骨架
2.3 添加项目相关依赖
-
在
pom.xml文件里添加6个依赖 xml
xml<dependencies> <!-- 1. Flink 核心库 (包含 TextLineInputFormat) --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-core</artifactId> <version>2.2.0</version> </dependency> <!-- 2. Flink 流处理 API --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId> <version>2.2.0</version> </dependency> <!-- 3. Flink 客户端 (用于本地运行和提交) --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients</artifactId> <version>2.2.0</version> </dependency> <!-- 4. 文件连接器 (提供 FileSource) --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-files</artifactId> <version>2.2.0</version> </dependency> <!-- 5. Flink Hadoop 兼容包 --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-hadoop-compatibility_2.12</artifactId> <version>1.18.0</version> </dependency> <!-- 6. Hadoop 客户端 --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.4</version> </dependency> </dependencies> -
刷新项目依赖
2.4 创建日志属性文件
-
在
resources目录里创建log4j.properties文件 shell
shelllog4j.rootLogger=error, stdout, logfile log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/flink.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
2.5 创建HDFS配置文件
-
在
resources目录里创建hdfs-site.xml文件 xml
xml<?xml version="1.0" encoding="utf-8" ?> <configuration> <property> <name>dfs.client.use.datanode.hostname</name> <value>true</value> </property> </configuration> -
设置
dfs.client.use.datanode.hostname属性值为true,用于启用客户端通过 DataNode 主机名(而非 IP)访问 HDFS,常用于集群网络配置或主机名解析场景。
2.6 在源程序目录里创建包
- 创建
net.huawei.flink.wc包
2.7 词频统计 - 批处理模式
2.7.1 创建BatchWordCount类
-
在
net.huawei.flink.wc包里创建BatchWordCount类 java
javapackage net.huawei.flink.wc; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.connector.file.src.FileSource; import org.apache.flink.connector.file.src.reader.TextLineInputFormat; import org.apache.flink.core.fs.Path; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * 功能:采用批处理模式进行词频统计 * 作者:华卫 * 日期:2026年06月19日 */ public class BatchWordCount { public static void main(String[] args) throws Exception { // 创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置为批处理模式 env.setRuntimeMode(RuntimeExecutionMode.BATCH); // 定义文件路径 String inputPath = "hdfs://master:9000/wordcount/input/words.txt"; // 构建文件源 FileSource<String> source = FileSource.forRecordStreamFormat( new TextLineInputFormat(), new Path(inputPath) ).build(); // 从源读取数据 DataStream<String> inputStream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "file-source"); // 词频统计逻辑 DataStream<Tuple2<String, Integer>> resultStream = inputStream .flatMap(new MyFlatMapper()) .keyBy(value -> value.f0) .sum(1); // 输出结果 resultStream.print(); // 执行作业 env.execute("Batch Word Count"); } /** * 自定义 FlatMap 算子,用于实现词频统计中的"拆分"与"标记"逻辑 */ static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> { /** * 核心处理逻辑:将输入的一行文本拆分为多个单词,并输出标准化的键值对 * * @param value 输入的一条数据记录,即从文件读取到的一行完整文本字符串 * @param out Flink 提供的收集器,用于将处理后的结果发射到下游算子 * 由于是 FlatMap,这里可以调用多次 collect() 输出一条或多条数据 */ @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { // 1. 按空格分割字符串,获取该行包含的所有单词数组 // 注意:生产环境中通常建议使用正则 "\\s+" 以兼容多个连续空格或制表符 String[] words = value.split(" "); // 2. 遍历单词数组,将每个单词转换为 (word, 1) 的形式 for (String word : words) { // 3. 构建元组并输出 // f0 代表单词本身(作为后续 keyBy 的分组依据) // f1 代表初始计数 1(作为后续 sum 聚合的基础值) out.collect(Tuple2.of(word, 1)); } } } } -
代码说明 :该程序使用 Flink 2.2.0 的 DataStream API 实现批处理词频统计。通过
FileSource读取 HDFS 文本文件,设置RuntimeExecutionMode.BATCH为批处理模式。核心流程为:读取文本行 →flatMap拆分为 (单词, 1) 键值对 →keyBy按单词分组 →sum聚合计数 →print输出结果。
2.7.2 运行程序,查看结果
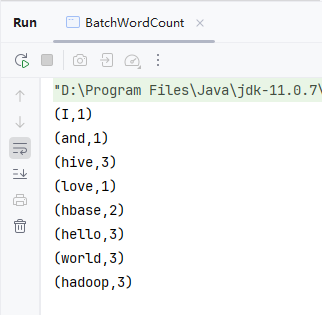
- 运行
BatchWordCount类
2.8 词频统计 - 流处理模式
2.8.1 创建StreamingWordCount类
-
在
net.huawei.flink.wc包里创建StreamingWordCount类 java
javapackage net.huawei.flink.wc; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.connector.file.src.FileSource; import org.apache.flink.connector.file.src.reader.TextLineInputFormat; import org.apache.flink.core.fs.Path; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * 功能:采用流处理模式进行词频统计 * 作者:华卫 * 日期:2026年06月19日 */ public class StreamingWordCount { public static void main(String[] args) throws Exception { // 创建执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置为流处理模式 env.setRuntimeMode(RuntimeExecutionMode.STREAMING); // 设置并行度为2 env.setParallelism(2); // 定义文件路径 String inputPath = "hdfs://master:9000/wordcount/input/words.txt"; // 构建文件源 FileSource<String> source = FileSource.forRecordStreamFormat( new TextLineInputFormat(), new Path(inputPath) ).build(); // 从源读取数据 DataStream<String> inputStream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "file-source"); // 词频统计逻辑 DataStream<Tuple2<String, Integer>> resultStream = inputStream .flatMap(new MyFlatMapper()) .keyBy(value -> value.f0) .sum(1); // 输出结果 resultStream.print(); // 执行作业 env.execute("Streaming Word Count"); } /** * 自定义 FlatMap 算子,用于实现词频统计中的"拆分"与"标记"逻辑 */ static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> { /** * 核心处理逻辑:将输入的一行文本拆分为多个单词,并输出标准化的键值对 * * @param value 输入的一条数据记录,即从文件读取到的一行完整文本字符串 * @param out Flink 提供的收集器,用于将处理后的结果发射到下游算子 * 由于是 FlatMap,这里可以调用多次 collect() 输出一条或多条数据 */ @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { // 1. 按空格分割字符串,获取该行包含的所有单词数组 // 注意:生产环境中通常建议使用正则 "\\s+" 以兼容多个连续空格或制表符 String[] words = value.split(" "); // 2. 遍历单词数组,将每个单词转换为 (word, 1) 的形式 for (String word : words) { // 3. 构建元组并输出 // f0 代表单词本身(作为后续 keyBy 的分组依据) // f1 代表初始计数 1(作为后续 sum 聚合的基础值) out.collect(Tuple2.of(word, 1)); } } } } -
代码说明 :该代码实现了基于 Flink 流处理的词频统计功能。程序首先配置并行度为 2,通过
FileSource从 HDFS 读取文本文件作为数据源。接着利用自定义的MyFlatMapper将每行文本拆分为单词并标记为(word, 1)格式。随后使用keyBy按单词分组,并通过sum(1)算子实时累加计数。最终结果通过控制台打印输出,展示了流式计算中数据的动态处理过程。
2.8.2 运行程序,查看结果
- 运行
StreamingWordCount类
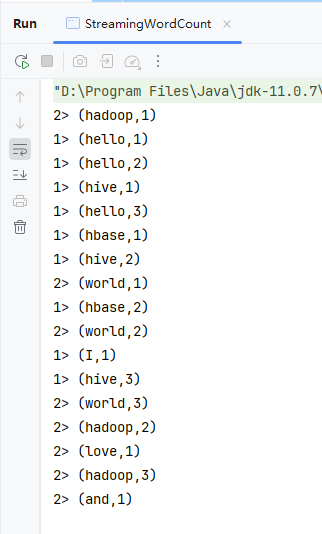
- 运行结果展示了 Flink 流处理程序在并行度为 2 时的实时词频统计输出。每条记录格式为
(单词, 当前累计次数),前缀数字(如1>、2>)代表处理该数据的并行线程 ID。由于数据被分发到两个线程处理,相同单词的计数可能在不同线程中交替出现,但每个线程内部保持状态累加。例如,hello先在1>线程从 1 累加到 3,而hadoop在2>线程从 1 累加到 3。这体现了流处理中"状态管理"与"并行计算"的特性:即使数据分散处理,每个 key 的聚合状态仍被准确维护,最终结果在逻辑上是全局一致的。
2.9 词频统计 - 处理流数据
2.9.1 利用nc产生流数据
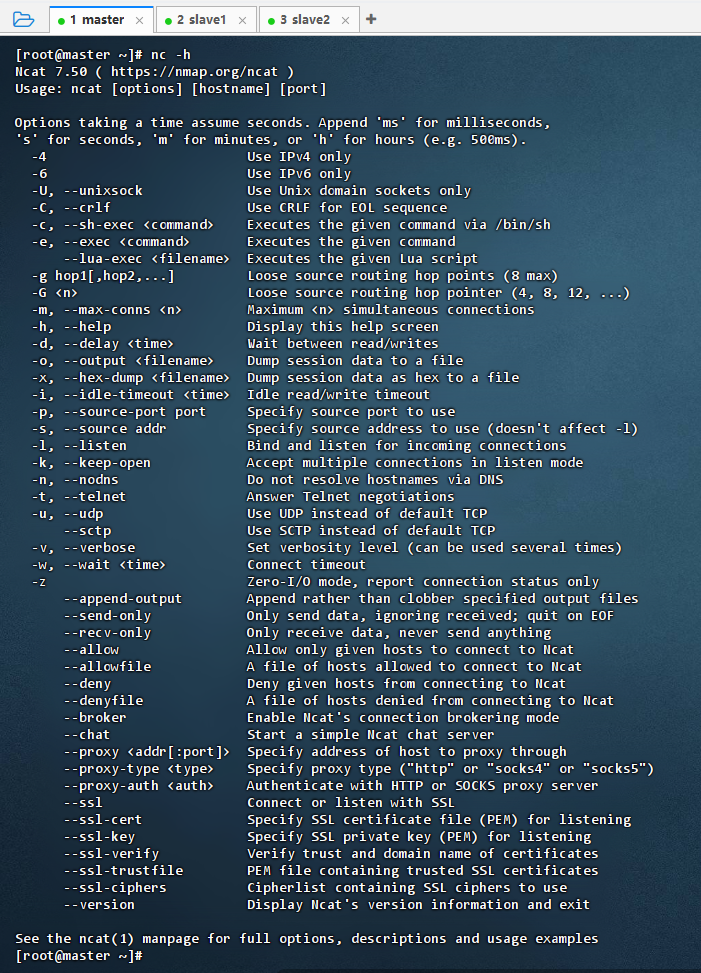
- 文件充其量只能算有界数据流,如何才能产生无界数据流呢?可以利用Kafka消息队列,当然为了简单起见,我们采用
nc来产生流数据。nc是款非常实用的网络工具,它能够建立并接受传输控制协议(TCP)和用户数据报协议(UDP)的连接。小巧而功能强大,被誉为网络安全界的"瑞士军刀"。nc被设计成一个可靠的后端(back-end) 工具,拥有功能丰富的网络调试和开发工具,它可以通过手工或者脚本与应用层的网络应用程序或服务进行交互,可以帮你轻易的建立几乎任何类型的连接,同时还可以当服务器使用,能监听任意指定端口的连接请求,并可做同样的读写操作。 - 执行命令:
nc -h
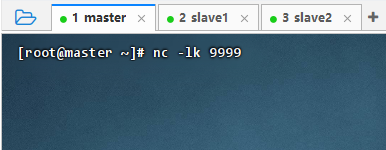
2.9.2 启动nc监听端口并保持开放
- 启动
nc,监听9999端口,保持开放,可以不断写入数据
2.9.3 创建StreamingDataWordCount类
-
在
net.huawei.flink.wc包里创建StreamingDataWordCount类 java
javapackage net.huawei.flink.wc; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * 功能:对流数据进行词频统计 * 作者:华卫 * 日期:2026年06月19日 */ public class StreamingDataWordCount { public static void main(String[] args) throws Exception { // 1. 创建流处理执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 设置并行度 env.setParallelism(2); // 3. 读取socket文本流数据 DataStream<String> inputStream = env.socketTextStream("master", 9999); // 4. 处理数据流,按空格拆分,转换成(word,1)二元组进行统计 DataStream<Tuple2<String, Integer>> resultStream = inputStream.flatMap(new MyFlatMapper()) // 传入实现FlatMapFunction接口的自定义类 .keyBy(value -> value.f0) // 按照第一个位置的数据分区 .sum(1); // 对第二个位置上的数据求和 // 5. 输出结果流 resultStream.print(); // 6. 执行任务 env.execute("Streaming Data Word Count"); } /** * 自定义 FlatMap 算子,用于实现词频统计中的"拆分"与"标记"逻辑 */ static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> { /** * 核心处理逻辑:将输入的一行文本拆分为多个单词,并输出标准化的键值对 * * @param value 输入的一条数据记录,即从文件读取到的一行完整文本字符串 * @param out Flink 提供的收集器,用于将处理后的结果发射到下游算子 * 由于是 FlatMap,这里可以调用多次 collect() 输出一条或多条数据 */ @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { // 1. 按空格分割字符串,获取该行包含的所有单词数组 // 注意:生产环境中通常建议使用正则 "\\s+" 以兼容多个连续空格或制表符 String[] words = value.split(" "); // 2. 遍历单词数组,将每个单词转换为 (word, 1) 的形式 for (String word : words) { // 3. 构建元组并输出 // f0 代表单词本身(作为后续 keyBy 的分组依据) // f1 代表初始计数 1(作为后续 sum 聚合的基础值) out.collect(Tuple2.of(word, 1)); } } } } -
代码说明 :该代码实现了基于 Flink 的实时 Socket 流词频统计。程序创建并行度为 2 的执行环境,通过
socketTextStream监听 master 节点的 9999 端口获取实时数据流。利用自定义MyFlatMapper将文本按空格拆分并标记为(word, 1)格式,随后按单词分组(keyBy)并进行累加求和(sum)。最终结果实时打印输出,展示了从网络端口读取无界数据并进行动态聚合的完整流程。
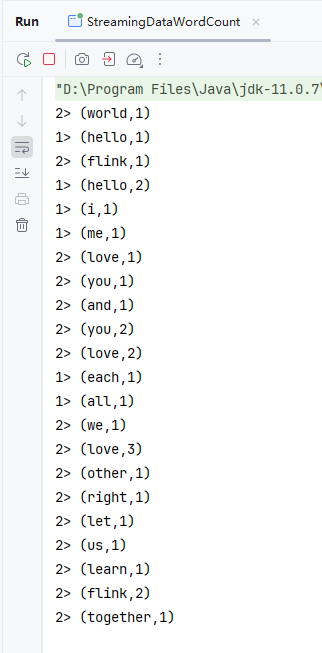
2.9.4 启动程序,利用nc输入数据,控制台查看结果
-
启动
StreamingDataWordCount类,利用nc输入几行数据,在控制台查看词频统计结果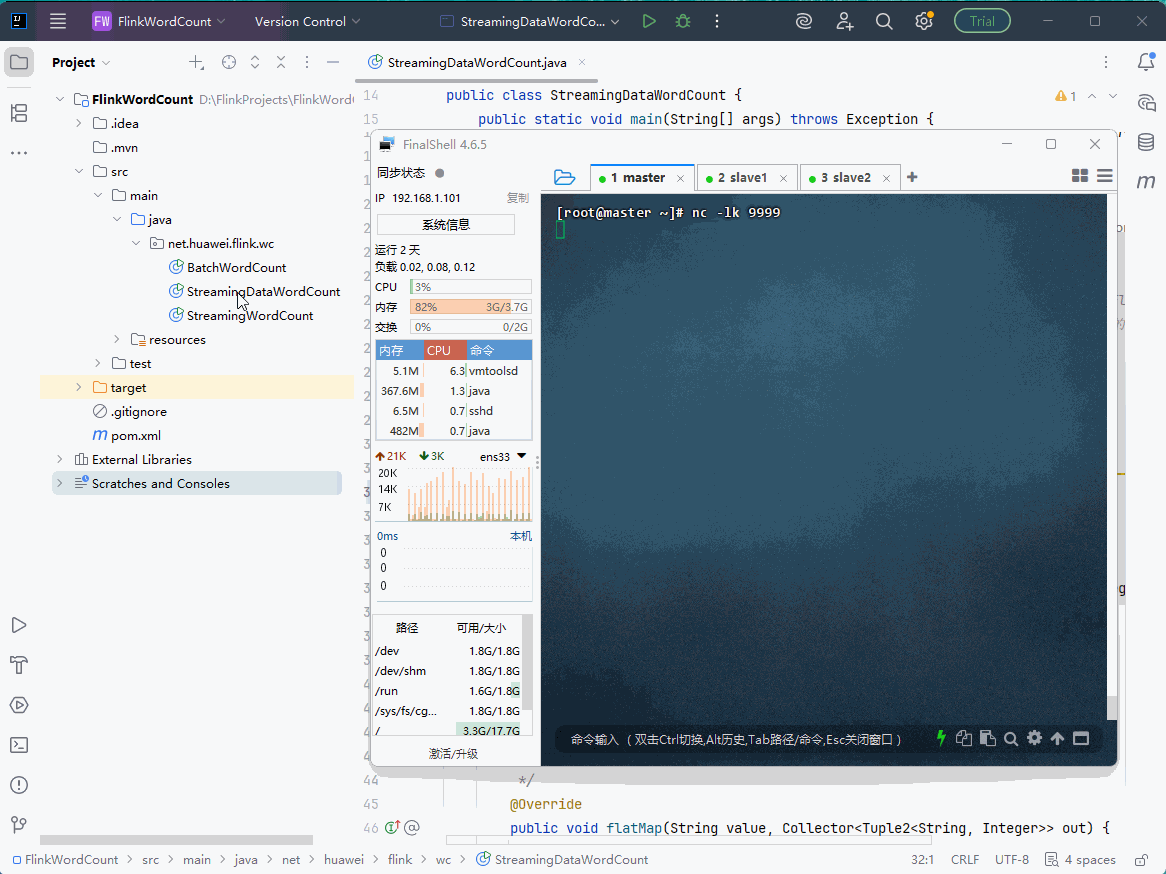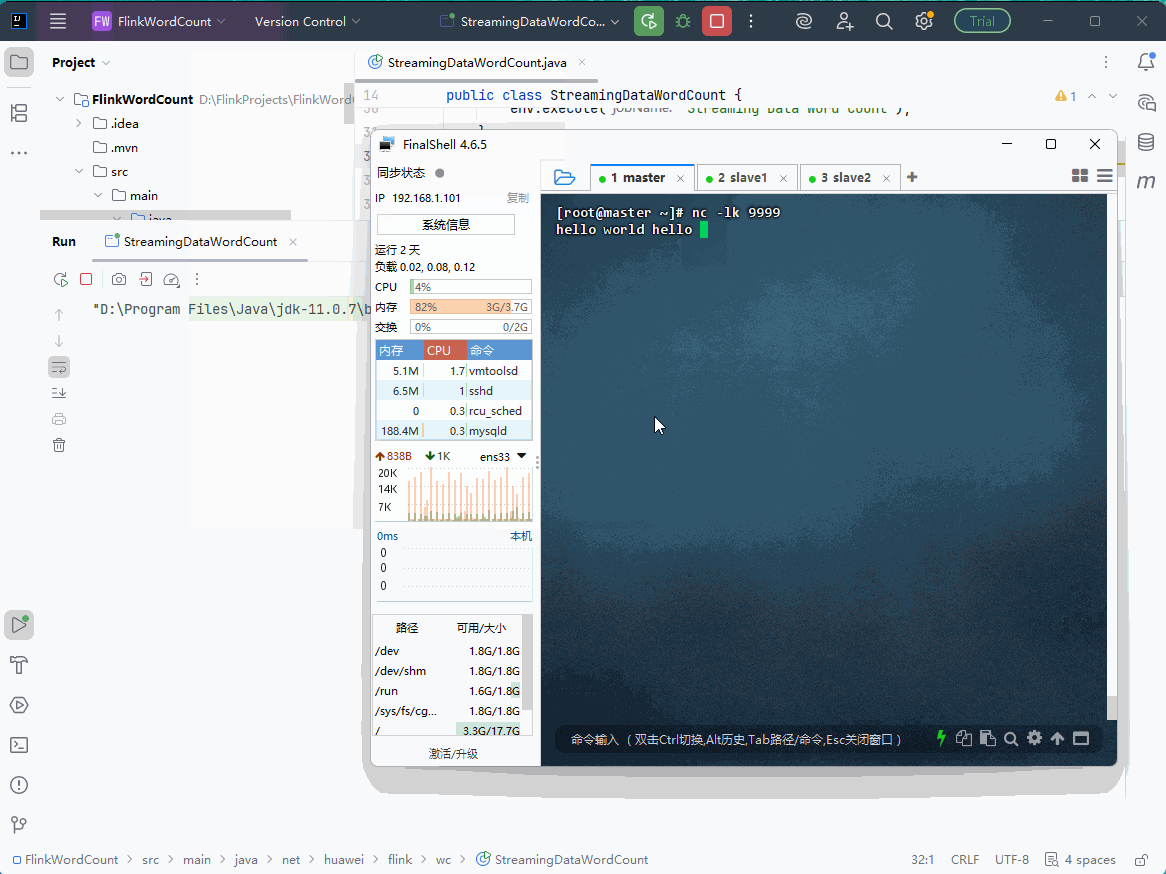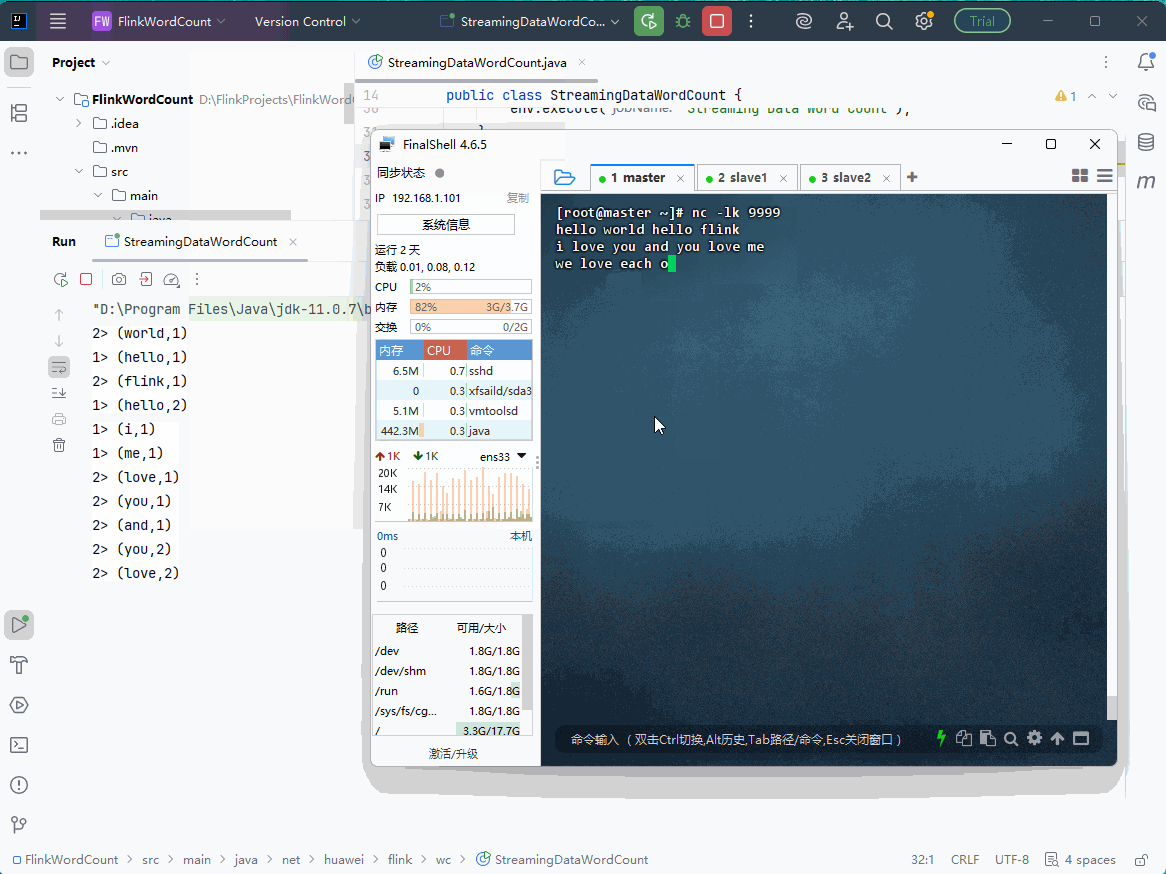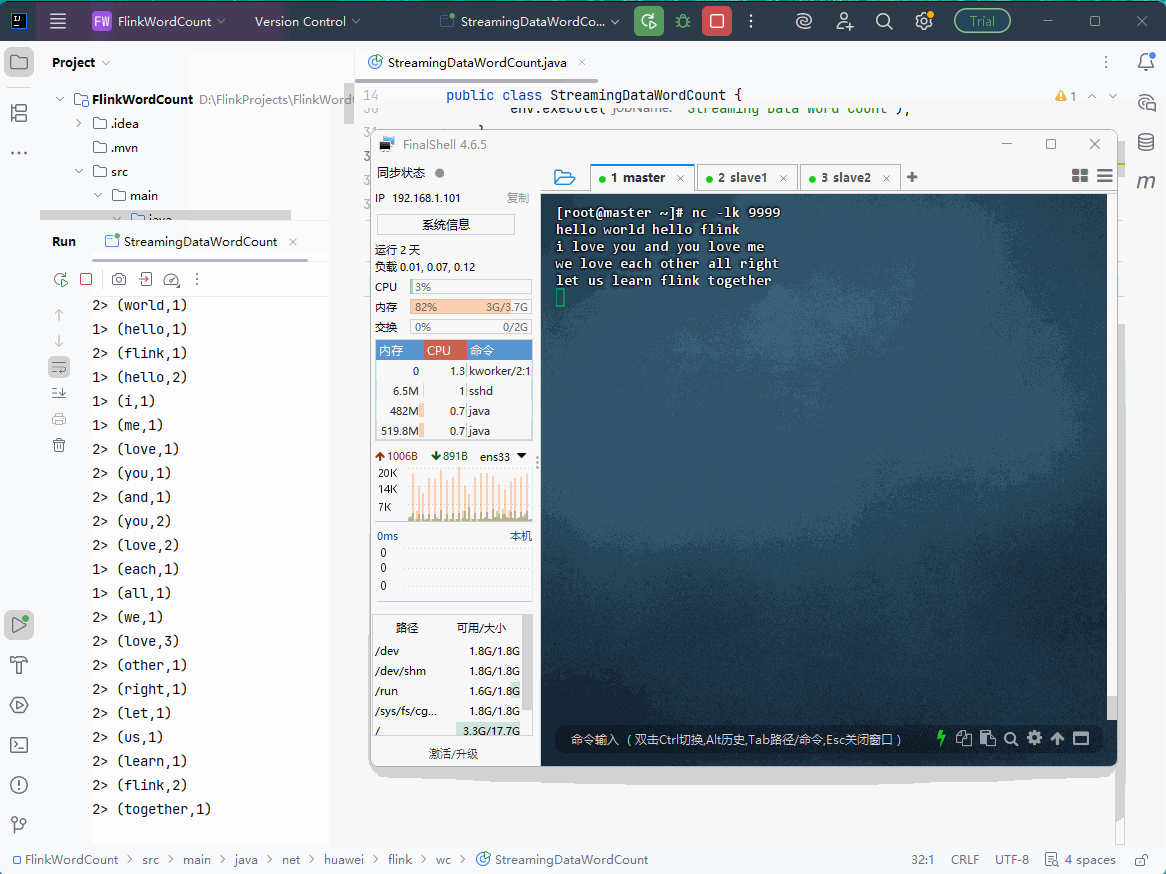
-
查看
nc输入的数据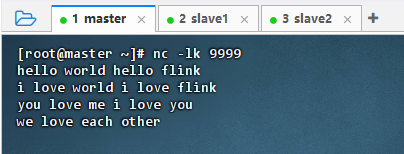
-
查看控制台输出的词频统计结果
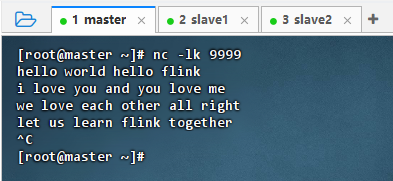
2.9.5 退出nc,程序结束
- 切换到
nc窗口,按Ctrl + C结束nc进程
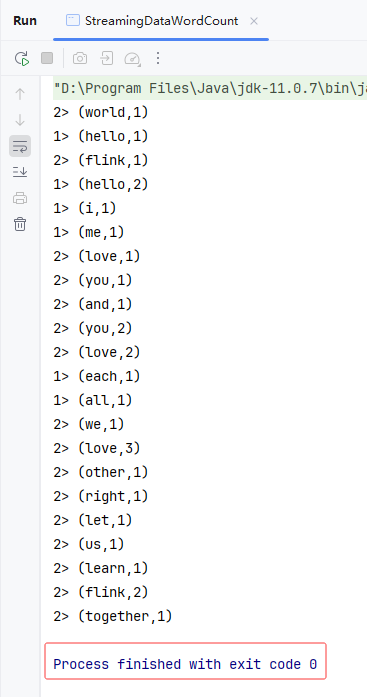
- 此时,程序正常结束
3. 实战总结
-
本次实战基于Flink 2.2.0版本,系统性地完成了从环境搭建到批流一体词频统计的全过程开发。在环境准备阶段,通过Maven精准引入了
flink-core、flink-streaming-java及flink-hadoop-compatibility等核心依赖,并配置了Log4j日志与HDFS客户端参数,确保了本地开发环境与集群环境的兼容性。 -
在核心编码环节,我深入实践了Flink的批流统一API。首先,在批处理模式(BATCH)下,利用
FileSource读取HDFS有界数据,验证了离线计算的最终一致性;其次,在流处理模式(STREAMING)下,通过RuntimeExecutionMode.STREAMING配置,观察了数据的增量计算过程。特别在实时流处理环节,利用nc命令模拟Socket数据源,成功构建了无界数据流,直观展示了Flink在并行度设置下的数据分发与状态累加机制。 -
通过对比三种模式的运行结果,我深刻理解了Flink中
keyBy与sum算子在不同执行环境下的行为差异,掌握了FlatMapFunction自定义数据清洗逻辑的编写规范。本次实践不仅强化了DataStream API的编程能力,更对Flink"批是流的特例"这一核心理念有了具象化的认知,为后续构建复杂实时数仓打下了坚实基础。