容灾自愈进阶:六级容错体系的工程实现
「Hermes Agent自进化智能体深度解析」系列 | 模块十二 · 第3篇
凌晨3点,Agent失败了
凌晨3点17分。没有人在场。值班手机安静地躺在床头。但系统内部正在经历一场无声的风暴。
你的Hermes Agent正在执行第42号定时任务------将社交媒体匹配结果同步到客户CRM系统。一切本来按计划进行,直到第7步调用CRM API时,返回了一个从未见过的错误码:QUOTA_EXCEEDED_PERM。不是临时限流,不是网络抖动,是CRM服务商临时调整了配额策略。
Agent会怎么做?
- 如果它无限重试 → 浪费300秒超时窗口,后续14个定时任务全部延迟
- 如果它直接放弃 → 4200条匹配结果积压在队列中,客户早上9点打开系统看到的是空数据
- 如果它降级写入本地缓存 → 数据暂时安全,但同步延迟需要后续补偿
这不是一道理论选择题。这是真实发生在Hermes生产环境中的故障。 而系统在0.3秒内做出了正确决策:降级写入本地缓存,异步排队等待配额恢复,同时触发告警通知运维团队。早上7点42分,配额恢复,积压数据自动同步完成。客户打开系统时,一切如常。
没有人被电话吵醒。没有人需要紧急修复。系统自己搞定了。
这就是六级容错体系的真正价值------不是让系统不出错,而是让系统在出错时依然能交付确定性结果。 而更关键的是,每一次故障处理产生的数据,都在驱动容灾能力本身的自进化。今天要拆解的,正是这套从"被动挨打"到"主动自愈"的完整工程实现。
六级容错金字塔:从自动重试到复盘改进
Hermes的容错体系不是一张平面的检查清单,而是一座精密的金字塔------每一级都建立在前一级的基础之上,逐级升级,层层兜底。
╱╲
╱ ╲
╱ L6 ╲ 复盘改进 Postmortem
╱──────╲ ── 每次故障转化为进化数据
╱ ╲
╱ L5 ╲ 版本回滚 Rollback
╱────────────╲ ── 不良影响可回退
╱ ╲
╱ L4 ╲ 人工接管 Manual Override
╱──────────────────╲ ── 人始终有最终控制权
╱ ╲
╱ L3 ╲ 自动告警 Alert
╱────────────────────────╲ ── 通知人类介入
╱ ╲
╱ L2 ╲ 降级执行 Fallback
╱──────────────────────────────╲── 切换备用方案保交付
╱ ╲
╱ L1 ╲ 自动重试 Retry
╱────────────────────────────────────╲── 最基础的自愈手段
╱ ╲
╱ 通用基座 ╲
╱────────────────────────────────────────────╲
错误检测 → 错误分类 → 决策路由 → 执行 → 记录
╲────────────────────────────────────────────╱金字塔的核心逻辑是:低成本方案优先,高成本方案兜底。 L1重试的成本最低(几秒延迟),应首先尝试;如果L1解决不了,才升级到L2降级执行;以此类推,直到L6将故障数据反哺给自进化系统,让下一轮容灾更智能。
接下来逐级拆解每一层的工程实现。
Level 1:自动重试(Retry)------最廉价的自愈
原理
80%的临时性故障可以通过重试解决。网络抖动、服务短暂过载、DNS解析超时------这些都是"自愈型错误"。重试策略的核心不是"重不重试",而是何时重试、重试几次、什么错误才值得重试。
决策流程
┌─────────────────────────────────────────────────────────────────────┐
│ Level 1: Retry 决策流程 │
│ │
│ 操作执行 ──→ 失败? ──→ No ──→ 返回成功结果 │
│ │ │
│ Yes │
│ │ │
│ ┌──────┴───────┐ │
│ │ 错误分类器 │ │
│ │ │ │
│ │ 可重试? │ │
│ │ Timeout → ✅│ │
│ │ 5xx → ✅│ │
│ │ 429 → ✅│ │
│ │ 401/403 → ❌│ ← 认证失败不应重试 │
│ │ 404 → ❌│ ← 资源不存在不应重试 │
│ │ 400 → ❌│ ← 参数错误不应重试 │
│ └──────┬───────┘ │
│ │ │
│ 可重试 │ 不可重试 │
│ ↓ ↓ │
│ 重试次数<上限? 升级→ L2 │
│ │Yes │No │
│ ↓ └──→ 升级→ L2 │
│ 指数退避等待 │
│ (1s→2s→4s→8s) │
│ │ │
│ └──→ 重新执行操作 │
└─────────────────────────────────────────────────────────────────────┘YAML配置
yaml
retry_policy:
max_attempts: 3
backoff_strategy: "exponential"
base_delay_ms: 1000
max_delay_ms: 30000
jitter: true # 加入随机抖动防止惊群效应
retryable_errors:
- "ConnectionTimeout"
- "ReadTimeout"
- "ServiceUnavailable" # HTTP 503
- "TooManyRequests" # HTTP 429
- "InternalServerError" # HTTP 500
- "DNSResolutionError"
non_retryable_errors:
- "AuthenticationFailed" # HTTP 401/403 --- 重试也不会成功
- "ResourceNotFound" # HTTP 404 --- 资源不存在
- "BadRequest" # HTTP 400 --- 参数错误
- "QuotaExceeded" # 配额耗尽 --- 需要降级而非重试
per_service_overrides:
crm_api:
max_attempts: 5
base_delay_ms: 2000
llm_inference:
max_attempts: 2
base_delay_ms: 500核心代码片段
python
async def execute_with_retry(
operation: Callable,
context: dict,
policy: RetryPolicy
) -> RetryResult:
"""带智能重试的操作执行器"""
error_classifier = ErrorClassifier()
attempts = []
for attempt in range(1, policy.max_attempts + 1):
try:
result = await operation(context)
return RetryResult(
success=True,
attempts=attempt,
total_delay_ms=sum(a.delay for a in attempts)
)
except Exception as e:
error_type = error_classifier.classify(e)
# 不可重试的错误 → 立即升级
if not error_type.retryable:
return RetryResult(
success=False,
escalate_to="L2",
reason=f"Non-retryable error: {error_type.name}",
last_error=e
)
# 重试次数耗尽 → 升级
if attempt >= policy.max_attempts:
return RetryResult(
success=False,
escalate_to="L2",
reason=f"Max retries ({policy.max_attempts}) exceeded",
attempts_log=attempts,
last_error=e
)
# 计算退避时间(含抖动)
delay = policy.calculate_backoff(
attempt=attempt,
jitter=True
)
attempts.append(RetryAttempt(
number=attempt,
error=e,
error_type=error_type.name,
delay_ms=delay
))
await asyncio.sleep(delay / 1000)自进化钩子 :每次重试的结果都记录到Trajectory日志中。当系统积累足够数据后,它会自动学习哪些错误码在当前环境下更值得重试、最佳退避间隔是多少。这不是硬编码的策略------重试策略本身在进化。
Level 2:降级执行(Fallback)------保交付的底线
原理
当L1重试无法解决问题时,系统的目标从"恢复原方案"转向"保交付"。降级执行不是简单的"换个方案试试",而是一套精密的优先级排序系统------核心交付物不可妥协,非核心能力可以暂时牺牲。
决策流程
┌─────────────────────────────────────────────────────────────────────┐
│ Level 2: Fallback 降级决策树 │
│ │
│ L1重试失败 ──→ 查询Fallback链表 │
│ │ │
│ ┌──────────┴──────────┐ │
│ │ Fallback Priority │ │
│ │ │ │
│ │ ① 同功能备选端点 │ ── CRM主库不可用→尝试只读副本 │
│ │ ② 本地缓存读取 │ ── 远程API不可用→读本地缓存 │
│ │ ③ 降质服务调用 │ ── 全量数据不可用→返回摘要数据 │
│ │ ④ 异步队列延迟处理 │ ── 实时不可行→异步补偿 │
│ │ ⑤ 安全空值返回 │ ── 全部不可用→返回安全默认值 │
│ └──────────┬──────────┘ │
│ │ │
│ 逐级尝试,首个成功即止 │
│ │ │
│ ┌──────┴──────┐ │
│ │ 全部失败? │ │
│ │ │ │
│ No │ Yes│ │
│ ↓ ↓ │
│ 降级成功 升级→ L3 │
│ 标记降级状态 (触发告警) │
└─────────────────────────────────────────────────────────────────────┘YAML配置
yaml
fallback_chain:
task_id: "crm_sync_42"
priority: "delivery_first" # 交付优先
primary:
name: "CRM REST API 批量写入"
endpoint: "https://api.crm.example.com/v2/batch"
timeout_ms: 30000
fallbacks:
- name: "CRM 只读副本写入"
endpoint: "https://replica.crm.example.com/v2/batch"
degradation:
write_delay: "+500ms" # 副本同步延迟
consistency: "eventual" # 最终一致性
- name: "本地缓存暂存"
storage: "redis://cache-layer:6379/fallback_queue"
degradation:
availability: "delayed" # 延迟可用
sync_required: true # 需要后续补偿同步
- name: "异步队列延迟处理"
queue: "rabbitmq://fallback.exchange/crm_dlq"
degradation:
availability: "async"
max_delay: "4h" # 4小时内补偿
- name: "安全空值返回"
response: { "status": "degraded", "data": null }
degradation:
availability: "none"
user_impact: "部分功能暂不可用"
on_fallback_triggered:
- log: true
- flag_task_state: "DEGRADED"
- emit_metric: "fallback.activation"
- notify: ["observability_dashboard"]自进化钩子 :系统记录每次Fallback的实际表现------哪个降级方案成功了、延迟多少、数据一致性影响多大。随着数据积累,Fallback链表的顺序会被自动优化。系统逐渐学会:在特定环境下,直接跳到第3级降级比逐级尝试更快。
Level 3:自动告警(Alert)------通知人类介入
原理
当L1和L2都无法解决问题时,故障已经超出了系统自愈的能力范围。此时需要人类介入。但告警不是简单地"发一条消息"------好的告警系统应该自带上下文、自带诊断、自带建议,让人类接到告警时不需要从头排查。
YAML配置
yaml
alert_policy:
trigger_conditions:
- condition: "L1_retry_exhausted AND L2_fallback_exhausted"
severity: "HIGH"
channels: ["slack:#ops-critical", "sms:oncall", "email:team-lead"]
- condition: "L2_fallback_activated AND fallback_tier >= 3"
severity: "MEDIUM"
channels: ["slack:#ops-warnings", "email:team-lead"]
- condition: "same_error_pattern_count >= 3 in 1h"
severity: "HIGH"
channels: ["slack:#ops-critical", "sms:oncall"]
alert_template:
header: |
🚨 [{{ severity }}] {{ task_name }} --- {{ error_category }}
body: |
任务: {{ task_id }} / {{ task_name }}
时间: {{ timestamp }}
错误: {{ last_error_message }}
L1 尝试: {{ retry_attempts }}次(全部失败)
L2 降级: {{ fallback_tier_used }}({{ fallback_result }})
影响范围: {{ affected_scope }}
预计影响: {{ estimated_impact }}
建议操作:
{{ suggested_actions }}
诊断链接: {{ dashboard_url }}
日志链接: {{ log_url }}
快速回滚: {{ rollback_command }}
auto_diagnostics: true # 自动附加诊断信息
auto_suggested_actions: true # 基于历史数据推荐操作
escalation_timeout: "30m" # 30分钟未处理则升级自进化钩子 :每次告警发出后,系统追踪人类花了多长时间响应、采取了什么操作、操作是否成功。这些数据被送入自进化引擎,系统学会了什么告警真正紧急、什么告警可以合并、什么告警其实可以自动处理而不需要打扰人类。
Level 4:人工接管(Manual Override)------人始终有最终控制权
原理
告警发出后,人工可以通过Manual Override机制接管Agent控制权。这不是"紧急制动开关",而是一套精密的远程操控协议------人类可以精细到任意粒度地干预Agent的执行,从暂停单个步骤到完全接管整个工作流。
核心接口
yaml
manual_override:
access_control:
auth: "rbac + 2fa"
allowed_roles: ["ops_lead", "system_admin", "oncall_engineer"]
operations:
- name: "pause_task"
description: "暂停当前任务,保留现场"
params: ["task_id", "reason"]
- name: "resume_task"
description: "恢复被暂停的任务"
params: ["task_id", "resume_from_step"]
- name: "modify_params"
description: "修改后续步骤的执行参数"
params: ["task_id", "step_id", "new_params"]
- name: "skip_step"
description: "跳过当前失败步骤,继续后续流程"
params: ["task_id", "step_id", "skip_reason"]
- name: "force_rerun"
description: "强制重新执行指定步骤"
params: ["task_id", "step_id", "override_params"]
- name: "cancel_task"
description: "永久取消任务"
params: ["task_id", "cancel_reason"]
- name: "full_takeover"
description: "完全接管Agent控制,手动执行每一步"
params: ["task_id"]
audit_trail: true # 所有操作留痕
session_timeout: "2h" # 接管会话超时
auto_release_on_fix: true # 问题修复后自动释放控制权关键设计 :所有Manual Override操作都完整记录到Trajectory日志中。这不仅是审计需要------人类的修复操作本身就是最珍贵的进化数据。系统会分析人类做了什么、为什么这么做、效果如何,将这些知识沉淀为未来的自动化能力。今天需要人工接管的场景,明天可能就不需要了。
Level 5:版本回滚(Rollback)------不良影响可回退
原理
当错误的执行已经产生了不良影响------比如同步了脏数据、部署了有缺陷的配置------系统需要能够快速回退到安全状态。回滚不是"Ctrl+Z",而是一套状态快照+逆向操作+一致性验证的三重保障机制。
YAML配置
yaml
rollback_policy:
snapshot:
trigger: "pre_execution" # 每次执行前自动快照
storage: "s3://hermes-snapshots/"
retention: "30d"
contents:
- "database_state_checksum"
- "config_version"
- "file_system_diff"
- "queue_state_dump"
rollback_triggers:
- condition: "verification_failed" # 执行后验证不通过
auto_rollback: true
timeout: "5m"
- condition: "data_integrity_check_failed" # 数据一致性校验失败
auto_rollback: true
timeout: "10m"
- condition: "manual_trigger" # 人工触发回滚
auto_rollback: false
require_approval: "ops_lead"
rollback_steps:
- name: "halt_all"
action: "停止所有相关的自动化任务"
timeout: "30s"
- name: "restore_snapshot"
action: "从最近的快照恢复状态"
verify: "checksum_match"
- name: "validate_integrity"
action: "验证恢复后的数据完整性"
checks:
- "row_count_consistency"
- "foreign_key_integrity"
- "business_rule_validation"
- name: "generate_report"
action: "生成回滚报告"
content:
- "回滚原因"
- "影响范围评估"
- "数据损失评估"
- "恢复确认"
- name: "await_confirmation"
action: "等待人工确认后恢复自动化"
timeout: "24h"
post_rollback:
quarantine_failed_data: true # 隔离导致回滚的数据用于分析
trigger_postmortem: true # 自动触发L6复盘自进化钩子 :回滚本身会产生大量高质量数据------什么样的错误导致了回滚、回滚是否完全恢复、回滚过程的耗时。这些数据被送入Postmortem引擎(L6),转化为系统级改进方案。每一次回滚,都在降低未来回滚的概率。
Level 6:复盘改进(Postmortem)------故障转化为进化燃料
原理
六级容错体系的最高层不是"处理故障",而是消灭故障 。每一次故障的完整生命周期------从错误发生到最终恢复------都被系统性地提炼为进化数据。这是自进化的核心闭环:故障产生数据 → 数据驱动改进 → 改进消灭同类故障。
YAML配置
yaml
postmortem:
trigger: "any L3+ incident" # L3及以上故障自动触发复盘
auto_generated_report:
sections:
- name: "incident_summary"
content:
- incident_id
- severity
- duration
- affected_tasks
- affected_users
- name: "timeline"
source: "trajectory_log"
format: "precise_to_second"
auto_annotate: true # 自动标注关键决策点
- name: "root_cause_analysis"
method: "five_whys" # 5-Why根因分析法
depth: 5
cross_reference: # 交叉引用历史同类故障
- "similar_incidents_last_90d"
- "same_error_pattern_history"
- name: "fault_handling_evaluation"
metrics:
- "L1_retry_success_rate"
- "L2_fallback_effectiveness"
- "alert_response_time"
- "time_to_recovery"
- "data_loss_assessment"
- name: "evolution_action_items"
auto_generate: true
categories:
- skill_improvement # Skill层面改进
- config_tuning # 配置参数优化
- fallback_chain_update # 降级链表调整
- alert_rule_refinement # 告警规则精化
- monitoring_gap # 监控盲区补充
evolution_feedback:
target: "self_evolution_engine"
data_types:
- "failure_pattern"
- "recovery_effectiveness"
- "human_intervention_quality"
- "rollback_completeness"完整Postmortem报告示例
yaml
# 自动生成的Postmortem报告
incident_id: "INC-20260601-042"
severity: "MEDIUM"
duration: "4h25m"
recovery_method: "L2 Fallback → 异步队列补偿"
timeline:
- "03:17:02 CRM API 返回 QUOTA_EXCEEDED_PERM"
- "03:17:02 L1 Retry 跳过(错误分类:不可重试)"
- "03:17:03 L2 Fallback 启动:本地缓存暂存"
- "03:17:04 4200条匹配结果写入Redis fallback队列"
- "03:17:04 任务状态标记为 DEGRADED"
- "03:17:05 L3 Alert 发送至 #ops-warnings"
- "07:42:00 CRM配额自动恢复"
- "07:42:01 异步补偿任务自动触发"
- "07:44:33 4200条数据同步完成,数据一致性验证通过"
- "07:44:34 任务状态恢复为 NORMAL"
root_cause: |
CRM服务商在未提前通知的情况下调整了API配额策略。
原配额:10,000次/小时 → 新配额:5,000次/小时。
当前同步任务在高峰时段的API调用量为8,200次/小时,超出新配额。
evolution_actions:
- type: "config_tuning"
description: "将CRM同步任务拆分为两个批次,错峰执行"
priority: "HIGH"
auto_apply: true
- type: "fallback_chain_update"
description: "新增配额预检步骤,在执行前探测配额余量"
priority: "MEDIUM"
auto_apply: true
- type: "alert_rule_refinement"
description: "QUOTA类错误不应触发L3告警,降级为L2内部消化"
priority: "LOW"
auto_apply: false # 需人工确认这是自进化的终极闭环:故障不是终点,而是下一次进化的起点。系统从"CRM配额超限"中学到的不是"这个错误码怎么处理",而是"API配额类故障应该预检而非事后处理"的通用策略。这个策略可以迁移到所有涉及外部API调用的场景中。
震撼时刻:自愈本身在进化
现在来到这篇博客的震撼时刻。
以下是一家企业部署Hermes六级容错体系后,6个月的完整自愈能力进化数据 。它揭示了一个令人惊叹的事实:不仅系统在自愈,"自愈能力本身"也在自愈。
╔══════════════════════════════════════════════════════════════════════════╗
║ ║
║ 六级容错体系 · 6个月自愈能力进化追踪 ║
║ 数据来源: 某企业 Hermes 集群 6个月运行日志 ║
║ ║
╠══════════════════════════════════════════════════════════════════════════╣
║ ║
║ 指标 第1月 第3月 第6月 变化趋势 ║
║ ────────────────────────────────────────────────────────────────── ║
║ Level 1 自愈成功率 65% 78% 94% ▲ +29pts ║
║ (重试解决的比例) ║
║ ║
║ Level 2 降级成功率 82% 88% 96% ▲ +14pts ║
║ (降级保交付的比例) ║
║ ║
║ L3+ 告警触发次数 47次 22次 8次 ▼ -83% ║
║ (需要人类介入的次数) ║
║ ║
║ 平均恢复时间(MTTR) 38min 12min 3.2min ▼ -92% ║
║ ║
║ 人工介入率 35% 14% 4% ▼ -31pts ║
║ ║
║ 回滚次数 5次 2次 0次 ▼ -100% ║
║ ║
║ ═══════════════════════════════════════════════════════════════════ ║
║ ║
║ 关键洞察: ║
║ ║
║ 1. Level 1 自愈成功率从 65% 进化到 94% ║
║ → 系统学会了"什么错误值得重试、什么错误应直接降级" ║
║ → 不再在不可重试的错误上浪费时间 ║
║ → 重试策略的参数(退避间隔、次数上限)被自动优化 ║
║ ║
║ 2. L3+ 告警从 47次 降到 8次 ║
║ → 原来需要人类介入的场景,80%已被系统自行消化 ║
║ → 人类的精力被释放到真正需要判断力的决策上 ║
║ ║
║ 3. 第6个月零回滚 ║
║ → 不是因为不出错了------是因为所有错误在L1/L2就被处理了 ║
║ → 系统的"第一道防线"变得极其强大 ║
║ ║
║ ═══════════════════════════════════════════════════════════════════ ║
║ ║
║ 终极洞察: ║
║ ║
║ 自愈能力的进化速度在加速------ ║
║ 第1月→第3月:L1成功率提升13pts(+6.5pts/月) ║
║ 第3月→第6月:L1成功率提升16pts(+5.3pts/月) ║
║ ║
║ 虽然绝对速度在放缓(边际递减), ║
║ 但每次提升的"含金量"在增加------ ║
║ 从65%到78%解决的是容易的问题, ║
║ 从78%到94%解决的是那些曾经必须人类才能判断的难题。 ║
║ ║
║ 系统正在攻克自愈能力的"最后一公里"。 ║
║ ║
╚══════════════════════════════════════════════════════════════════════════╝Level 1自愈成功率从65%进化到94%------这意味着什么?
在第1个月,系统遇到100次故障,其中65次通过重试解决,35次需要升级到L2甚至更高级别。到第6个月,100次故障中94次在L1就被解决,只有6次需要升级。不是故障变少了------而是系统学会了更聪明地处理故障。
它学会了什么?
ConnectionTimeout在凌晨3点的重试成功率是92%,但在下午2点只有61%------它调整了不同时段的重试策略429 TooManyRequests配合Retry-After: 3600头时,不应该在60秒内重试,而应该等到服务端指定的时间------它学会了尊重服务端的节流信号QUOTA_EXCEEDED_PERM看起来像临时错误,但"PERM"后缀意味着它是永久性的------它学会了区分临时限流和策略性配额调整
这些不是人类教给系统的。这些是系统从6个月的故障处理数据中自己学到的。 每一次故障都在为下一次故障提供更精准的决策依据。自愈本身在进化------这正是"自进化"这个名字的终极含义。
从"怕出错"到"不怕出错"再到"出错了更好"
回顾六级容错体系的工程实现:
- Level 1 自动重试:最廉价的自愈,80%的临时故障在此解决。关键是智能分类------什么错误值得重试、什么错误不该重试
- Level 2 降级执行:保交付的底线。从备选端点到本地缓存到异步队列,逐级降级,核心交付物不可妥协
- Level 3 自动告警:通知人类介入。好告警自带上下文、自带诊断、自带建议,让人类秒级理解问题
- Level 4 人工接管:人始终有最终控制权。从暂停单步到完全接管,粒度自由选择
- Level 5 版本回滚:不良影响可回退。快照+逆向操作+一致性验证的三重保障
- Level 6 复盘改进:故障转化为进化燃料。5-Why根因分析,跨故障交叉引用,自动生成改进方案
在模块五#13中我们介绍了容灾设计的六层概念框架。本篇则将其推进到了可部署、可配置、可自进化的工程实现------每一层都有精确的YAML配置、决策流程图和代码实现。更重要的是,每一层都内嵌了自进化钩子:故障数据不仅在解决当前问题,更在驱动容灾能力本身的持续进化。
6个月的数据证明了一个令人震撼的结论:一个配备了自进化容错体系的Agent,不仅不会因为故障而变弱,反而会因为故障而变强。 传统系统视故障为敌人,自进化系统视故障为教师。
但这引出了一个更大的问题:当容灾、可观测性、自动化工作流全部就绪后,如何将它们整合为一个真正7x24小时无人值守运转的生产系统?Always-On不是一个配置开关,而是一整套运维哲学和工程实践。
下一篇#39,我们将进入Always-On生产实践------看Hermes如何在真实的生产环境中实现真正的"永远在线",从基础设施到任务编排到安全防线的完整工程落地。
延伸阅读与交流
本文涉及的Hermes Agent自进化智能体技术体系,目前已有系统化的深度学习资源可供参考。中国通信工业协会通信和信息技术创新人才培养工程项目办公室将于近期组织相关技术专题分享,围绕本文讨论的AI原生架构、智能体工作流、自进化数据层等方向展开系统讲解。
专题信息
- 主题:AI原生Hermes自进化智能体系统
- 时间:2026年7月4-5日(周末)
- 形式:线上直播
- 内容方向:AI原生架构 · Hermes智能体拆解 · 全栈扩展 · 智能自动化 · 产品级实战 · Context Engine · 自进化数据层
分享嘉宾
王老师(Gavin),Agentic AI企业联合创始人兼CTO,十余年硅谷AI系统工程经验。长期深耕NLP、强化学习、可控AI与智能体系统架构,提出"语言即控制(Language as Control)"原创范式,在RLHF、PPO、DPO、GRPO等方向有系统化工程实践,推动智能体技术在社交媒体、医疗、金融、法律、教育等专业场景落地。
技术交流
- 联系人:Sam
- WeChat:NLP_ChatGPT_LLM
- Hermes Agent技术文档:https://hermes-agent.nousresearch.com/docs/
























2026年重磅喜讯! 喜报!热烈祝贺Gavin大咖人工智能领域经典著作《企业级ChatGPT AI大模型应用开发实战(1000分钟视频)》中国水利水电出版社发行上市!
内容提要
本书内容基于作者在硅谷 ChatGPT 项目及企业培训中的实战经验凝练而成,重点介绍企业级 ChatGPT 开发的核心技术、案例研究及最佳实践。全书共 16 章,分为基础篇和实战篇两大部分。
基础篇:
介绍 ChatGPT 底层架构 Transformer 技术及源码实现、GPT 的内部机制及源码实现、GPT 系列模型原理与应用:从 GPT-2 到 GPT-4 等内容。
实战篇:
介绍基于 ChatGPT 的端到端语音聊天机器人项目实战,企业级 ChatGPT 开发的三大核心内部机制及案例实战,ChatGPT 插件的内部机制、源码及案例实战,ChatGPT 提示词开发实战,思维链及 ReAct 解析与实战,提示词本质解析及评估实战与源码解析,LangChain 大模型框架的七大核心组件及案例解析(上、下),LangChain 代理深入解析及源码解析,AutoGPT 源码解析及综合案例实战,使用 LangChain 构建问答聊天机器人案例实战,构建基于大模型的自治代理案例,Llama 2 模型与 LangChain 项目详解。书中每个知识点均配有相应的实现代码和实例。
本书适合有一定 Python 基础的 ChatGPT 爱好者阅读,主要面向从事大模型应用开发、机器学习、数据挖掘或深度学习的专业人员,高等院校相关专业的师生,以及相关领域的科研人员。
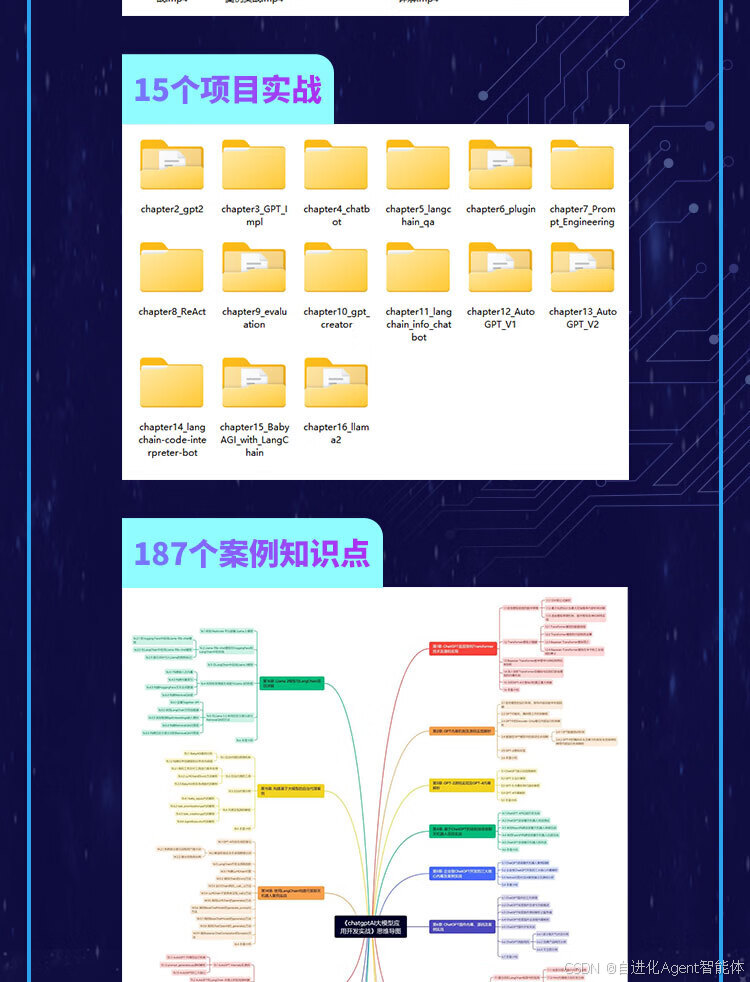
本书附赠丰富的学习资源,具体如下:①同步学习资源,即 16 集同步教学视频,视频时长共计约 1000 分钟;②教师授课的辅助资源,即 187 个案例知识点、15 个项目实战的全部源代码。
前言
在当今快速发展的科技时代,人工智能(artificial intelligence,AI)技术正以惊人的速度改变着人们的生活和工作方式。在这个新时代的浪潮中,大模型技术成为AI领域的一颗耀眼新星。ChatGPT作为大模型技术的重要应用之一,正在引领着人机交互领域的革新浪潮。本书将带领读者深入探索大模型新时代,通过ChatGPT实战项目和内部解析,深入掌握基于ChatGPT的大模型应用开发领域的关键技术,并解密ChatGPT的底层架构和实现原理。
本书主要内容
本书通过ChatGPT实战项目的方式,为读者呈现一个全面、系统的学习路径,从基础知识的介绍开始,带领读者深入了解ChatGPT的工作原理和实际应用。本书非常适合具备Python基础的读者学习。
全书共16章,分为基础篇和实战篇两大部分。
基础篇包括第1~3章;实战篇包括第4~16章。
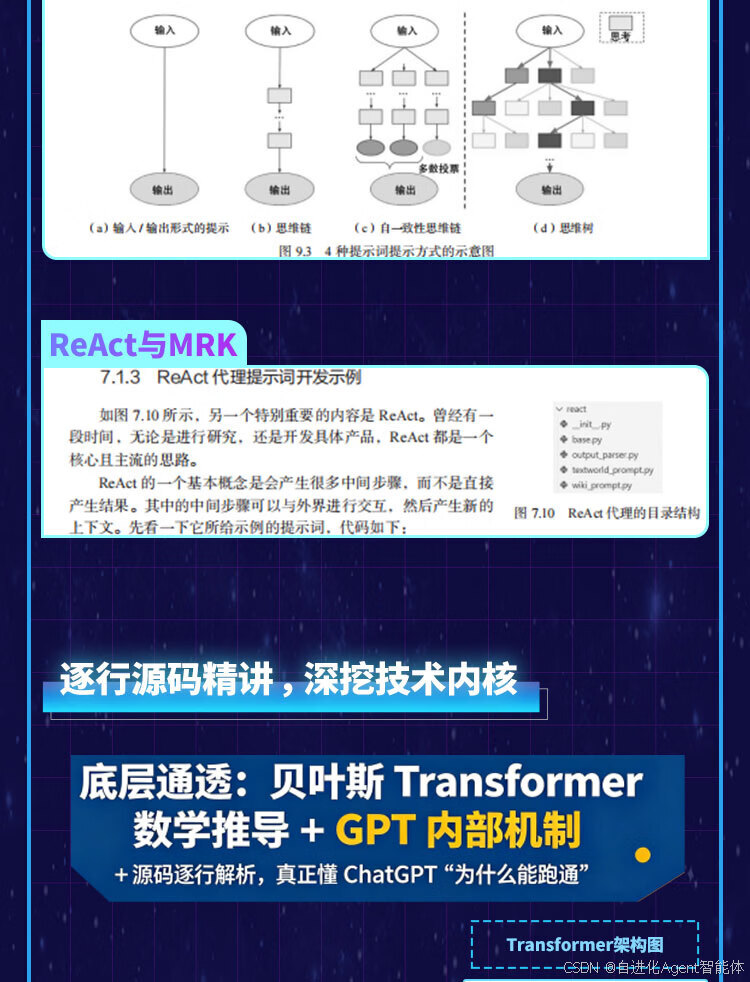
第1章 ChatGPT底层架构Transformer技术及源码实现,详解最大似然估计、最大后验概率、贝叶斯Transformer及自编码与自回归语言模型的内部机制。
第2章 GPT的内部机制及源码实现,剖析GPT运行机制、掩码机制、Decoder-Only模式,详解数据流动生命周期及GPT-2源码。
第3章 GPT系列模型原理与应用:从GPT-2到GPT-4,解析ChatGPT提示词流程、GPT-2运行机制,可视化解读GPT-3/4的内部机制。
第4章 基于ChatGPT的端到端语音聊天机器人项目实战,涵盖ChatGPT API开发、前后端构建(ReAct+FastAPI)及项目优化。
第5章 企业级ChatGPT开发的三大核心内部机制及案例实战,解析企业级开发核心,演示Notion问答对话AI案例。
第6章 ChatGPT插件的内部机制、源码及案例实战,详解插件工作原理、检索插件源码及全流程开发实战。
第7章 ChatGPT提示词开发实战,基于LangChain框架的提示词、思维链、链式提示词及模型评估开发。
第8章 思维链及ReAct解析与实战,剖析思维链推理、ReAct技术原理、框架源码及案例实战。
第9章 提示词本质解析及评估实战与源码解析,包含问答评估、代理评估源码解析及提示词本质探讨。
第10~11章 LangChain大模型框架的七大核心组件及案例解析(上、下),涵盖模型、词嵌入、提示词、内存、回调、数据连接、代理等核心组件及聊天机器人综合案例。
第12章 LangChain代理深入解析及源码解析,详解代理工作原理及AutoGPT源码解析。
第13章 AutoGPT源码解析及综合案例实战,剖析AutoGPT内部机制及其在LangChain代理、内存、PromptGenerator中的应用。
第14章 使用LangChain构建问答聊天机器人案例实战,涵盖GPT-4代码生成全流程及LangChain开发实战。
第15章 构建基于大模型的自治代理案例,详解自治代理原理、工具、示例及开源实现源码。
第16章 Llama 2模型与LangChain项目详解,包括模型部署(Replicate)、Hugging Face/LangChain实践、检索增强生成及自定义提示词RetrievalQA开发。
本书特色
●深入探索,全面剖析。
本书涵盖ChatGPT案例实战、LangChain项目实战及框架源码解析等多个层面的内容。每章都深入探讨相关技术与案例,并提供源码解析,使读者能够全面了解ChatGPT和LangChain等技术的内部机制与开发原理,为实际项目的应用提供有力指导。
●实战剖析,项目揭秘。
本书每章都提供具体的案例实战与项目解析,引导读者通过实际操作和代码理解技术细节和底层逻辑。通过理论结合实践的方式,使读者能够更好地运用所学知识,深入了解项目和框架的实现细节。
●前沿突破,技术驱动。
本书介绍了一系列突破性的技术,如ChatGPT、LangChain、Transformer、Prompt、Llama 2、AutoGPT、BabyAGI、CoT、ToT、ReAct、MRKL等。通过对这些技术的深入剖析,读者可以了解相关技术的发展和应用,并了解它们在实际项目中的具体应用场景和效果。
●源码解析,细致讲解。
本书对LangChain框架的关键技术进行了逐行源码剖析。读者可以深入理解源码实现和机制原理,从而更好地理解技术细节和底层逻辑,并将其应用于实际开发工作中。
本书还为读者提供了丰富的知识和实用的技能,帮助读者在ChatGPT和LangChain领域取得突破性的进展。无论是初学者还是有一定经验的开发者,都可以从本书中获得有价值的学习资源。
配套资源
为便于教与学,本书配有同步教学视频(约1000分钟)、源代码、数据集、教学课件、教学大纲、安装程序。
作者简介
王家林
美国斯坦福大学计算机专业毕业。曾在美国担任硅谷顶级机器学习和人工智能实验室主任、杰出AI工程师及首席机器学习工程师,专精于对话式人工智能(conversational AI)。现担任硅谷某知名对话机器人公司CTO,自2019年起专注于基于红队测试(red teaming)的责任型AI(responsible AI),并热衷于构建生成式AI/大语言模型教练系统(GenAI/LLM coaching systems)。在硅谷任职期间,曾领导多个GenAI/LLM解决方案项目,成功平衡企业业务需求下的大模型推理(reasoning)系统与幻觉(hallucinations)及偏见(biases)风险的最小化。
作为数据科学、机器学习、NLP、ChatGPT及大模型等领域25本书的主要作者,王家林对利用人工智能提供解决方案,以及通过机器学习驱动的NLP与LLM流程帮助组织实现数据驱动决策充满热情。他曾领导Apple、PayPal、Chase Bank、Faethm、LinkedIn等公司的11个重大NLP项目。
在NLP、对话式AI、大数据及基于AWS的无服务器(serverless)技术方面,拥有丰富的机器学习咨询经验。
段智华
中国电信股份有限公司上海分公司高级工程师。长期从事大模型与智能体技术领域,专注Agentic AI、Harness Agent等前沿方向研究。
新书购买链接
《企业级ChatGPT AI大模型应用开发实战(1000分钟视频)》