Java 23 种设计模式:从踩坑到精通 | 享元模式 ------ 内存吃不消?试试共享细粒度对象
摘要 :当系统需要创建大量细粒度对象且大部分状态可共享时,重复
new会迅速耗尽内存并拖垮性能。享元模式通过"共享"机制,将对象的状态分为内部状态(不可变的共享部分)和外部状态(随场景变化的上下文),让大量对象复用同一实例,将内存占用从"数量级"降到"种类级"。本文从文本编辑器的字符渲染和围棋落子场景出发,完整讲解享元模式的线程安全实现、内外部状态分离的权衡、与对象池/单例的严格区分,并结合Integer.valueOf()、字符串常量池、Record 类等现代 Java 实践,帮你掌握"用共享换性能"的优化之道。
📖 《Java 23 种设计模式:从踩坑到精通》开篇:系列介绍与目录 | 上一篇:外观模式 | 当前:享元模式 | 下一篇:代理模式
🔗 返回系列总目录
1. 从"一篇文章十万个字符对象"的 OOM 说起
假设你在开发一个富文本编辑器,每个字符都是一个 Character 对象,包含字符内容、字体、字号、颜色等属性。如果一篇文章有 10 万个字符,直接 new 出 10 万个 Character 对象:
java
for (char c : text.toCharArray()) {
characters.add(new Character(c, font, size, color));
}很快你就会遇到 OutOfMemoryError。然而仔细观察会发现:这 10 万个字符中,大部分重复出现------英文字母只有 26 个,中文字符虽多但常用字也就几千。真正需要反复创建的是"字符本身",而字体、颜色等属性是可复用的。
假设每个 Character 对象约 40 字节(对象头 + 字段),10 万个对象 ≈ 4MB。使用享元后,仅 8 个共享实例 ≈ 320 字节,外部状态引用(每字符 8 字节)≈ 800KB,总计不到 1MB,节省约 80% 内存。对于百万级文本,收益是指数级的。
享元模式(Flyweight Pattern)正是针对这类场景:运用共享技术有效地支持大量细粒度对象,将对象的状态分为内外部,让共享的部分只保留一份,从而将内存占用从"数量级"降到"种类级"。
1.1 你的场景该不该用享元?
| 判断标准 | 是 → 用享元 | 否 → 用其他方式 |
|---|---|---|
| 系统需要创建大量相似对象,且内存成为瓶颈 | ✅ | ❌ |
| 对象的大部分状态可提取为不可变的共享部分 | ✅ | ❌ |
| 对象创建成本高,重复创建不划算 | ✅ | ❌ |
| 对象状态几乎全部随场景变化,无法分离共享部分 | ❌ | 直接 new 或考虑对象池 |
2. 模式定义与 UML 结构
享元模式 运用共享技术有效地支持大量细粒度对象,通过共享已经存在的同类对象来减少内存消耗和创建开销。它属于 结构型设计模式。
标准享元模式的 UML 类图:
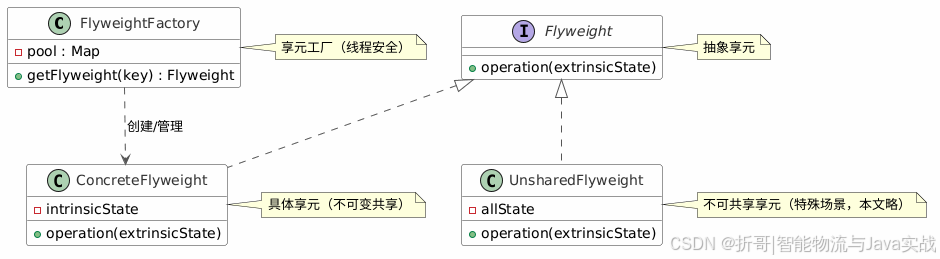
📝 本系列示例聚焦共享享元 ,
UnsharedFlyweight仅在混合场景(如部分对象需独立状态)中使用,日常开发中接触较少。
四个角色:
- Flyweight(抽象享元):定义对象的接口,接收外部状态;
- ConcreteFlyweight(具体享元) :实现抽象享元,内部状态是不可变的共享部分。不可变性是享元模式的生命线------如果内部状态可变,共享就会导致数据污染;
- UnsharedConcreteFlyweight(不可共享的具体享元):特定场景下不需要共享的享元子类(本文略);
- FlyweightFactory(享元工厂) :创建并管理享元对象,维护一个享元池(通常为
ConcurrentHashMap),当客户端请求时先在池中查找,存在则返回已有对象,否则创建并放入池中。
💡 享元模式的灵魂在于"区分内外部状态" :内部状态 是对象可共享的部分,不随环境变化,必须不可变 ;外部状态是对象依赖的场景上下文,由客户端在调用时动态传入。两者分离得越清晰,共享收益越大。
3. 代码实现:文本编辑器中的字符享元
3.1 抽象享元
java
public interface TextCharacter {
// 外部状态:字符显示的具体位置(行、列)
void display(int row, int col);
}3.2 具体享元
java
public class ConcreteCharacter implements TextCharacter {
private final char symbol; // 内部状态:字符本身,可共享,不可变
private final String font; // 内部状态:字体,可共享
private final int size; // 内部状态:字号,可共享
public ConcreteCharacter(char symbol, String font, int size) {
this.symbol = symbol;
this.font = font;
this.size = size;
}
@Override
public void display(int row, int col) {
System.out.println("在 (" + row + ", " + col + ") 显示字符 '"
+ symbol + "', 字体: " + font + ", 字号: " + size);
}
}💡 Java 17+ 的现代化写法 :享元对象天然不可变,非常适合用 Record 类(Java 16+)简化:
javapublic record TextCharFlyweight(char symbol, String font, int size) implements TextCharacter { @Override public void display(int row, int col) { System.out.println("在 (" + row + ", " + col + ") 显示字符 '" + symbol + "'"); } }Record 自动生成不可变字段、
equals/hashCode,并明确表达"此对象不可变"的设计意图,是享元模式的绝佳搭档。
3.3 享元工厂
java
import java.util.concurrent.ConcurrentHashMap;
public class CharacterFactory {
private static final ConcurrentHashMap<String, TextCharacter> pool = new ConcurrentHashMap<>();
public static TextCharacter getCharacter(char symbol, String font, int size) {
String key = symbol + "_" + font + "_" + size;
// computeIfAbsent 是原子操作,避免先 get 再 put 的竞态条件
return pool.computeIfAbsent(key, k -> {
System.out.println("创建新享元: " + k);
return new ConcreteCharacter(symbol, font, size);
});
}
public static int getPoolSize() {
return pool.size();
}
}⚠️ 踩坑提醒 :不要先用
get()判断再put()------这不是原子操作,高并发下仍会创建重复实例。computeIfAbsent是标准的线程安全写法。
3.4 客户端调用
java
public class Editor {
public static void main(String[] args) {
String text = "Hello World";
String font = "Arial";
int size = 12;
int col = 0;
for (char c : text.toCharArray()) {
TextCharacter tc = CharacterFactory.getCharacter(c, font, size);
tc.display(1, col++);
}
System.out.println("\n享元池内对象数: " + CharacterFactory.getPoolSize());
}
}输出(部分):
创建新享元: H_Arial_12
创建新享元: e_Arial_12
创建新享元: l_Arial_12
创建新享元: o_Arial_12
...
创建新享元: W_Arial_12
创建新享元: r_Arial_12
创建新享元: d_Arial_12
享元池内对象数: 8Hello World 共 11 个字符,但字母 l 和 o 重复,享元池中只存在 8 个实例。若文章更长,内存节省效果非常显著。
3.5 进阶思考:内部状态的粒度权衡
在实际编辑器中,同一字符在不同位置可能有不同字体或字号。若将 font、size 全部作为内部状态,组合数 = 字符数 × 字体数 × 字号数,享元池会急速膨胀,反而失去共享优势。
取舍建议:
| 策略 | 内部状态 | 享元池大小 | 适用场景 |
|---|---|---|---|
| 激进共享 | 仅 char symbol |
极小(几千) | 纯文本编辑器 |
| 适度共享 | symbol + font |
中等 | 字体种类少的场景 |
| 不共享 | --- | --- | 每个字符字体/字号/颜色都不同 |
💡 精通之道 :享元模式不是"所有属性都该共享",而是在"共享收益"与"外部状态管理复杂度"之间找到平衡。极端情况下,只有
char symbol是内部状态,其余全部作为外部状态传入display()。
4. 代码实现:围棋棋子的享元(经典面试场景)
围棋有 361 个交叉点,黑白两色棋子。棋子的颜色 是内部状态(只有黑/白两种),位置是外部状态。若每落一子创建一个对象,整盘棋会创建数百个对象。用享元只需两个实例。
4.1 抽象享元
java
public interface ChessPiece {
void place(int x, int y); // 外部状态:落子位置
}4.2 具体享元(用 Record 简化)
java
public record ChessPieceImpl(String color) implements ChessPiece {
@Override
public void place(int x, int y) {
System.out.println(color + "子落在 (" + x + ", " + y + ")");
}
}4.3 享元工厂
java
public class ChessPieceFactory {
private static final ConcurrentHashMap<String, ChessPiece> pool = new ConcurrentHashMap<>();
public static ChessPiece getChessPiece(String color) {
return pool.computeIfAbsent(color, k -> {
System.out.println("创建新享元: " + color + "子");
return new ChessPieceImpl(color);
});
}
public static int getPoolSize() {
return pool.size();
}
}4.4 客户端
java
public class GoGame {
public static void main(String[] args) {
ChessPiece black1 = ChessPieceFactory.getChessPiece("黑");
ChessPiece black2 = ChessPieceFactory.getChessPiece("黑");
ChessPiece white1 = ChessPieceFactory.getChessPiece("白");
black1.place(3, 4);
black2.place(15, 16);
white1.place(7, 8);
System.out.println("\n享元池大小: " + ChessPieceFactory.getPoolSize()); // 2
System.out.println("黑子是否为同一实例? " + (black1 == black2)); // true
}
}整盘棋局无论落多少子,内存中只有两个 ChessPieceImpl 实例,位置信息由客户端动态传入。
5. 进阶:避免享元池自身成为内存泄漏源
如果内部状态组合无限增长(如用户自定义颜色、动态字体),享元池可能持续膨胀。高级享元工厂可使用 弱引用缓存,当对象不再被外部引用时自动回收:
java
public class WeakReferenceFlyweightFactory {
private static final ConcurrentHashMap<String, WeakReference<TextCharacter>> pool =
new ConcurrentHashMap<>();
public static TextCharacter getCharacter(char symbol, String font, int size) {
String key = symbol + "_" + font + "_" + size;
// 使用 computeIfAbsent 保证原子性,避免竞态条件
WeakReference<TextCharacter> ref = pool.computeIfAbsent(key, k ->
new WeakReference<>(new ConcreteCharacter(symbol, font, size))
);
TextCharacter cached = ref.get();
if (cached == null) {
// 引用已被GC回收,需要重新创建并替换
cached = new ConcreteCharacter(symbol, font, size);
pool.put(key, new WeakReference<>(cached));
}
return created;
}
}⚠️ 弱引用缓存是"精通级"优化手段,仅在内部状态组合极大且内存敏感时使用。常规场景用
computeIfAbsent即可。
6. 优缺点一览
| 优点 | 缺点 |
|---|---|
| 大幅减少内存占用:将复杂度从数量级降到种类级 | 代码复杂度增加:需区分内外部状态,设计难度上升 |
| 提高性能:减少对象创建和 GC 压力 | 外部状态管理成本高:客户端须管理外部状态,可能增加耦合 |
| 符合单一职责原则:将状态分离到不同层次 | 享元对象必须不可变:若内部状态可变,共享会导致数据污染 |
7. 享元模式 vs 对象池 vs 单例
| 对比维度 | 享元模式 | 对象池 | 单例模式 |
|---|---|---|---|
| 共享粒度 | 同一类型不可变内部状态的对象 | 任意对象复用 | 全局唯一实例 |
| 对象是否相同 | 多个客户端拿到同一引用(== 相同) | 客户端拿到不同实例,但池化管理 | 全局唯一 |
| 对象可变性 | 不可变(核心约束) | 可变,用完归还 | 通常持有全局状态 |
| 生命周期 | 常驻内存,一般不销毁 | 借出→归还→复用 | 常驻内存 |
| 典型应用 | Integer.valueOf()、字符串常量池 |
数据库连接池、线程池 | Runtime、Spring 单例 Bean |
💡 享元关注"不可变共享",对象池关注"复用归还"。连接池本质是对象池模式 ,虽然借鉴了享元的复用思想,但连接对象是有状态、可变的,不属于享元模式。
Integer.valueOf()是标准的享元------Integer对象不可变,且缓存范围固定。
8. 框架与实践中的应用
8.1 JDK 中的享元:Integer.valueOf(int)
Integer 对 -128 ~ 127 范围的整数进行了预创建固定范围 的享元缓存。调用 valueOf() 时先查缓存,命中则返回同一个实例。
java
Integer a = Integer.valueOf(100);
Integer b = Integer.valueOf(100);
System.out.println(a == b); // true,享元生效
Integer c = Integer.valueOf(200);
Integer d = Integer.valueOf(200);
System.out.println(c == d); // false,超出缓存范围💡 JDK IntegerCache 是预创建固定范围 的享元,加载时一次性创建
-128~127共 256 个对象;自定义享元工厂通常是懒加载动态创建的。两者在生命周期管理上有本质区别。
8.2 字符串常量池与 String.intern()
JVM 字符串常量池是享元思想的体现,相同内容的字符串字面量在常量池中只存一份。String.intern() 可手动将字符串放入常量池。
java
String a = "hello";
String b = new String("hello").intern();
System.out.println(a == b); // true⚠️
intern()需谨慎使用------JDK 6 及之前将 intern 字符串存储在 PermGen(永久代),过度使用可能导致 OOM。JDK 7+ 移入堆,风险降低,但仍可能增加 GC 压力。
8.3 Spring 单例 Bean
Spring 容器中的 singleton 作用域 Bean 是一种特殊的享元:所有依赖该 Bean 的组件共享同一个实例,容器本身充当享元工厂。
9. AI 时代的享元模式
在 AI 辅助编程中,你可以这样描述需求:
生成代码 Prompt :
"我有一个文本编辑器,需要渲染大量字符。请基于享元模式设计一个
CharacterFactory,使用ConcurrentHashMap+computeIfAbsent保证线程安全。将内部状态(字符、字体)与外部状态(行、列)分离。享元对象使用 Java 17 的 Record 实现,确保不可变性。"
代码审查 Prompt :"请审查这段享元模式代码,检查:1)是否所有内部状态字段都是不可变的?2)享元工厂是否线程安全?3)是否存在过度分离状态导致外部状态管理过于复杂?"
逆向 Prompt(AI 检测坏味道) :"请分析以下代码,判断是否过度使用了享元模式------是否内部状态划分过于细碎导致享元池膨胀?是否外部状态管理成本已超过内存节省收益?"
10. 常见误区与面试高频题
❌ 误区1:享元就是对象池
享元的共享对象不可变 ,外部状态由客户端管理;对象池的对象可变,用完归还。连接池是对象池,不是享元。
❌ 误区2:所有对象都该享元化
只有创建成本高、数量大且具有大量重复的细粒度对象才适合享元。滥用会增加不必要的代码复杂度。
❌ 误区3:享元工厂用 HashMap 就够了
多线程下 HashMap 有竞态条件。必须使用 ConcurrentHashMap 配合 computeIfAbsent 等原子操作,而非先 get 再 put。
❌ 误区4:享元对象的内部状态可以修改
这是最致命的踩坑点。 如果内部状态可变,共享就会导致数据污染------A 客户端修改了共享对象,B 客户端看到的就是脏数据。享元对象必须不可变。
💡 面试高频追问
Integer.valueOf()用了什么模式? → 享元模式,缓存-128~127的整数对象。- 内部状态和外部状态的区别? → 内部状态不可变、可共享;外部状态由客户端保存,随场景变化。
- 享元模式和单例模式有什么区别? → 享元可以有多个共享实例(每种内部状态一个),单例全局只有一个。
- 字符串常量池是享元吗? → 是。
String.intern()需注意 JDK 6/7 的内存差异。
🎉 恭喜 :如果你能立刻说出享元模式的"内外部状态不可变分离"原则,并用
Integer.valueOf()或围棋棋子举例,且能区分享元与对象池的差异,你已经掌握了享元模式的核心。面试中遇到"如何优化大量重复对象的内存占用",这就是你的王牌答案。
11. 六大设计原则在享元模式中的体现
| 设计原则 | 在享元模式中的体现 |
|---|---|
| 单一职责原则(SRP) | 享元对象只负责内部状态,外部状态由客户端管理 |
| 开闭原则(OCP) | 新增享元类型只需扩展工厂,无需修改现有享元类 |
| 里氏替换原则(LSP) | 所有具体享元都遵循抽象享元接口,可相互替换 |
| 依赖倒置原则(DIP) | 客户端依赖抽象享元接口,不依赖具体享元 |
| 接口隔离原则(ISP) | 抽象享元接口只定义必要方法,外部状态通过参数传入 |
| 迪米特法则(LoD) | 客户端只与享元工厂交互,不知内部池化细节 |
12. 总结
享元模式是"用空间换时间"的经典反例------通过增加少许代码复杂度,换取内存空间的极大节约。它在 JDK 的 Integer 缓存、字符串常量池以及各种需要大量细粒度对象的场景中发挥着至关重要的作用。
✅ 最终建议 :当系统存在大量相似对象,且其中大部分状态可提取为不可变 的共享部分时,果断使用享元模式。使用
ConcurrentHashMap+computeIfAbsent保证线程安全。享元对象建议使用 Java Record 实现不可变性。切忌滥用------若内外部状态分离不清晰,或享元池过度膨胀,享元模式反而会适得其反。对于有状态可变的复用场景,对象池才是正确答案。
🧭 《Java 23 种设计模式:从踩坑到精通》快速导航
- 开篇:系列介绍与目录
- 上一篇:外观模式 ------ 给复杂系统装一个"一键启动"
- 当前:享元模式 ------ 内存吃不消?试试共享细粒度对象(你在这里)
- [下一篇:代理模式 ------ 你的 AOP 就是用代理实现的](#下一篇:代理模式 —— 你的 AOP 就是用代理实现的) 🚧 即将发布
- 创建型模式汇总:单例、工厂、建造者、原型
- 结构型模式汇总:适配器、装饰器、代理......
- 行为型模式汇总:观察者、策略、模板方法......
🔔 关注《Java 23 种设计模式:从踩坑到精通》,用 25 篇文章彻底吃透设计模式。
📦 福利预告 :全系列代码及 UML 源码将在完结时统一打包开放,点击「关注」「收藏」第一时间获取。
🚀 下一篇:代理模式 ------ 你的 AOP 就是用代理实现的!🚧 即将发布,敬请关注!
📌 除了设计模式,我也在深挖智能物流实战 (WMS、托盘调度、机器学习落地)。欢迎点击头像,看看专栏 《出版社物流WMS智能调度实战》、 《电商多平台电子面单对接实战》。
技术相通,思路可鉴。