作者:来自 Elastic Sachin Frayne
Jingra 是一个开源基准测试框架,它在 Elasticsearch、OpenSearch 和 Qdrant 上运行相同的向量搜索工作负载,从而让你能够在相同且可复现的条件下比较不同搜索引擎的性能。
通过面向 Search AI 的这套**自助式实践学习课程** 亲自体验向量搜索。你现在可以开始**免费的云试用** ,或者在你的**本地机器**上试用 Elastic。
不要再猜测你的**向量搜索** 基准测试结果是否准确。Jingra 是一个开源、配置驱动的框架,它消除了隐藏的预热假设、不一致的数据集,以及对于索引何时真正准备好接受查询 这一问题的模糊定义。它在 Elasticsearch、OpenSearch 和 Qdrant 上运行相同的数据集、工作负载、参数扫描以及报告流水线,生成可复现的召回率与延迟对比曲线,让你能够重新运行、比较并信任这些结果。
Jingra 如何对向量搜索引擎进行基准测试:三个阶段
Jingra 将基准测试组织为三个阶段:Load、Eval 和 Analyze。这种结构的目标很简单:在可控且可复现的条件下,使用相同的数据集、工作负载和报告流水线来衡量每个引擎。
| 阶段 | 作用 |
|---|---|
| Load | 导入数据;等待索引就绪 |
| Eval | 执行预热和测量;支持参数扫描 |
| Analyze | 生成召回率曲线、延迟图和 CSV 文件 |
1. Load:建立一个已知状态
Load 阶段使用可配置的并行度将数据集导入被测试的引擎中。更重要的是,它让你可以在评估开始之前明确决定 "ready(就绪)" 的定义。在实践中,完成数据导入并不总意味着系统已经进入稳定状态。Elasticsearch 可能仍在后台进行 segment 合并,而 Qdrant 也有各自的后处理优化行为。这些后台任务可能会显著影响查询延迟。
Jingra 通过 await_index_ready 设置将这一决策显式化。如果启用,评估会等待索引达到你希望测量的状态,而不是假设仅仅完成 document(文档)导入就已经足够。
示例加载配置:
load:
threads: 4
batch_size: 100
queue_capacity: 100
await_index_ready: true2. Eval:捕获真实的性能权衡
Eval 阶段将查询工作负载分为两个步骤:warmup(预热)和 measurement(测量)。在预热阶段,Jingra 会在开始收集任何结果之前,将配置的查询执行固定次数。它不会在预热和测量之间清除缓存或重置引擎状态。测量阶段会在预热迭代完成后直接开始。
这种设计使基准行为变得明确:Jingra 测量的是预热之后的稳态性能,而不是冷启动延迟。将 warmup 与 measurement 分离,可以减少首次运行带来的影响,同时不需要在两个阶段之间增加额外的协调逻辑。
Jingra 还支持参数扫描,因此你不必只得到单一的基准点,而是可以在一次运行中生成跨多个配置的召回率与延迟曲线。
召回率与延迟的参数扫描示例:
param_groups:
recall@10:
- { size: 10, k: 10, num_candidates: 10, oversample: 1 }
- { size: 10, k: 20, num_candidates: 20, oversample: 1 }
- { size: 10, k: 50, num_candidates: 50, oversample: 1 }
- { size: 10, k: 100, num_candidates: 100, oversample: 1 }
- { size: 10, k: 200, num_candidates: 200, oversample: 1 }
- { size: 10, k: 500, num_candidates: 500, oversample: 1 }
- { size: 10, k: 1000, num_candidates: 1000, oversample: 1 }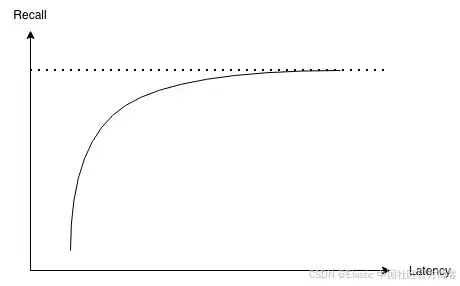 图1:渐近召回率与延迟曲线,该曲线趋近于一个极限;更高的 num_candidates 和 k 会以时间成本换取更接近该极限的结果。
图1:渐近召回率与延迟曲线,该曲线趋近于一个极限;更高的 num_candidates 和 k 会以时间成本换取更接近该极限的结果。
3. Analyze:结构化报告
在评估完成之后,Jingra 的 Analyze 阶段会生成召回率曲线、延迟图以及结构化 CSV 文件,以便进一步分析。结果可以写入不同的输出目标,包括用于快速迭代的控制台输出,或用于长期存储和仪表盘分析的 Elasticsearch 索引。
配置驱动的向量搜索基准测试
Jingra 采用 YAML 配置驱动,而不是硬编码的基准逻辑。这使得基准定义可以轻松提交和复用,同时将连接凭证保留在环境变量中。
在不同引擎之间切换也非常简单。例如,你可以将 engine: qdrant 替换为 engine: elasticsearch,并将 Jingra 指向不同的集群。
Jingra 如何确保基准结果准确且可复现?
为了获得确定性且可信的结果,设计上做了以下关键取舍:
-
不使用固定 sleep 进行协调。 Jingra 使用同步原语和就绪检查,而不是任意延迟,从而让基准执行更具确定性。
-
在集成测试中使用真实引擎。 测试套件直接使用 Testcontainers 运行 Elasticsearch、OpenSearch 和 Qdrant,而不是依赖 mock。
-
默认值贴近真实运行状态。 Jingra 不会在未显式要求时假设理想化的索引状态。
-
严格的质量门禁。 项目通过 JaCoCo 在每次构建中强制执行完整的指令覆盖和分支覆盖。
Jingra 使用 Java 构建,因为 Java 很适合这类基础设施软件:它拥有成熟的并发原语、强大的测试工具,以及成熟且被广泛理解的运行时模型。同时,这也是作者最熟悉的语言,使其能够更专注于基准方法论,而不是实现细节。
如何使用 Jingra 运行向量搜索基准测试?
为了快速开始,Jingra GitHub 仓库提供了一组端到端演示,覆盖常见的基准测试场景。这些演示会启动一个引擎、下载公开数据集、进行索引,并通过 Docker Compose 运行评估,因此不需要预先存在的集群。
前置条件:
-
Java 21
-
Maven
-
Docker
-
make
最快的尝试方式是运行其中一个端到端演示:
cd demos/vector-search
make elasticsearch # starts elasticsearch, loads data, runs benchmark, tears down对于自定义场景,你可以克隆仓库、构建镜像,并直接使用你自己的配置运行:
docker run --rm \
-e ELASTICSEARCH_URL \
-v "$PWD/config.yaml:/config/jingra.yaml:ro" \
<your-tag> load /config/jingra.yaml该演示会生成结构化输出,Jingra可以将其转换为召回率、延迟和吞吐量图表。下面的示例仅用于说明:它使用非常小的数据集,并刻意放大工作负载,以便演示能够快速生成可见曲线。这些数值用于展示报告流程,但不应被解读为生产环境性能的代表。
| RecallAtN | Engine | ParamKey | Recall | Recall Rounded | Latency_Avg | Latency_P95 | Throughput | Speedup |
|---|---|---|---|---|---|---|---|---|
| recall@10 | elasticsearch | k=10_num_candidates=10_oversample=1_size=10 | 0.9948 | 0.99 | 0.9602 | 1.1642 | 907.8117 | |
| recall@10 | elasticsearch | k=20_num_candidates=20_oversample=1_size=10 | 0.9973 | 1 | 1.0704 | 1.5249 | 818.5483 | |
| recall@10 | elasticsearch | k=50_num_candidates=50_oversample=1_size=10 | 0.9988 | 1 | 1.1183 | 1.4607 | 787.7582 | |
| recall@10 | elasticsearch | k=100_num_candidates=100_oversample=1_size=10 | 0.9993 | 1 | 1.1017 | 1.3583 | 802.9065 | |
| recall@10 | elasticsearch | k=200_num_candidates=200_oversample=1_size=10 | 0.9995 | 1 | 1.2505 | 1.5671 | 713.8778 | |
| recall@10 | elasticsearch | k=500_num_candidates=500_oversample=1_size=10 | 0.9995 | 1 | 1.4175 | 1.7896 | 636.0211 | |
| recall@10 | elasticsearch | k=1000_num_candidates=1000_oversample=1_size=10 | 0.9995 | 1 | 1.7012 | 2.0929 | 58.7924 |
从这个输出中,Jingra 可以生成图表,例如:
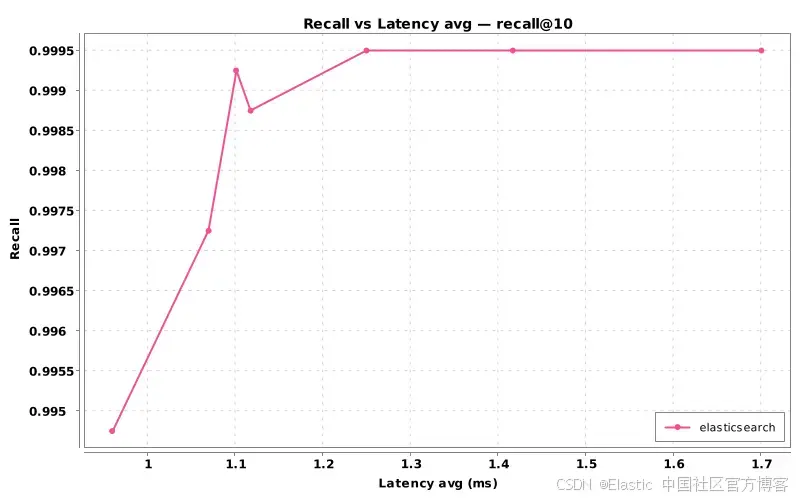 Figure 2:召回率与延迟曲线,显示更高的搜索开销如何提升召回率,同时增加延迟。
Figure 2:召回率与延迟曲线,显示更高的搜索开销如何提升召回率,同时增加延迟。
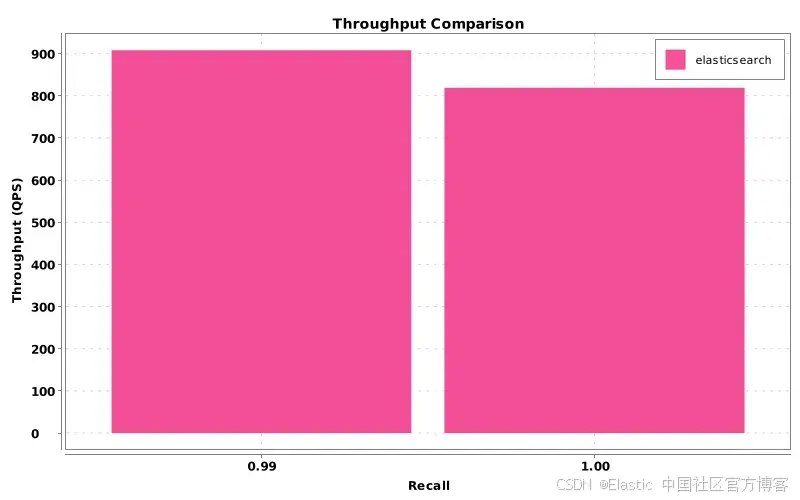 图3:吞吐量图,显示这些相同参数变化在每秒查询数中的成本。
图3:吞吐量图,显示这些相同参数变化在每秒查询数中的成本。
在这个演示中,工作负载被刻意配置为 100 次预热轮次和 100 次测量轮次。这并不是为了模拟生产流量,而只是为了在一个非常小的数据集上更方便地展示这些权衡曲线,否则它们会执行得过快而无法观察。
在生产级基准测试中,你应该使用更大的数据集、真实的并发度,以及符合实际工作负载的查询量。该演示的目的是展示基准测试流程和输出格式,而不是建立性能基线。
这些演示目前每次只专注于单个引擎。未来版本将增加引擎之间的对比演示,以及同一引擎内部不同配置之间的 profile 对比。
结论:运行你自己的向量搜索基准测试
如果你想在自己的数据上比较向量搜索引擎,Jingra 提供了一种可重复的方法,而无需你自己构建整套测试框架。只需运行一个演示,在你的工作负载上执行,然后在相同条件下比较各个引擎。
该项目是开源的,采用 Apache 2.0 许可协议,可在 GitHub 上获取。
常见问题
什么是 Jingra,它用于基准测试什么?
Jingra 是一个用于在 Elasticsearch、OpenSearch 和 Qdrant 之间运行可复现向量搜索基准测试的开源框架。它对所有引擎使用相同的数据集、工作负载和报告流水线,使跨引擎比较一致且可信。它采用 Apache 2.0 许可协议并在 GitHub 上提供。
为什么不同公开研究中的向量搜索基准结果会不一致?
大多数公开基准测试都存在隐藏假设差异:例如索引何时被认为已就绪、预热查询次数,以及后台优化任务是否已完成。Jingra 通过配置显式化这些选择:await_index_ready、预热轮次和测量轮次都在 YAML 中定义,并且可跨运行复现。
Jingra 如何处理 Elasticsearch 和 Qdrant 的后置索引优化?
这两个引擎在文档导入后都会进行后台处理(Elasticsearch 进行 segment 合并,Qdrant 执行自身优化),这些任务可能显著影响查询延迟。Jingra 的 await_index_ready 设置会在索引达到预期测量状态之前阻止评估阶段开始,而不是在最后一个文档索引完成后立即开始查询。
如何用 Jingra 生成召回率与延迟曲线?
Jingra 支持参数扫描:你可以在 param_groups 块中定义多个 num_candidates 和 k 配置,单次运行会评估所有组合。Analyze 阶段随后生成召回率与延迟曲线,展示随着搜索开销增加,召回率提升但延迟增加的关系。
是否可以在没有现有集群的情况下运行 Jingra 基准测试?
可以。Jingra GitHub 仓库中的演示使用 Docker Compose 启动引擎、下载公开数据集、完成索引并通过一个 make 命令运行完整基准测试,无需预先存在 Elasticsearch、OpenSearch 或 Qdrant 集群。
Jingra 支持哪些引擎?
Jingra 目前支持 Elasticsearch、OpenSearch 和 Qdrant,未来计划支持更多引擎。同时也计划加入引擎之间对比以及同一引擎不同配置之间的对比演示。
Jingra 适合生产级基准测试吗?
Jingra 面向生产级研究设计,但当前演示使用小数据集和刻意放大的工作负载以快速生成可视曲线。要获得有意义的生产级对比,应使用更大的数据集、真实并发度以及符合实际业务的查询负载。
原文:Vector search benchmarking with Jingra: A reproducible framework - Elasticsearch Labs