写在前面
算法分析的基本步骤是: 执行的频次有多少;每次执行的开销是多少。
比较复杂度:区分理论复杂度和实际复杂度
实际复杂度:包括额外空间开销等【比如当数据量较小的时候用插入排序而不是归并(需要递归,额外空间开销等,在CPU上执行更慢(小数据上))】
stable or not
stable:插入,归并,计数,LSD基数
not stable:堆排序
67Intractability(难解性)(P&NP)
Brute-force search:暴力求解
tractable可解的
Intractable(难解/不可解)
概念上理解即可,不需要深入理解
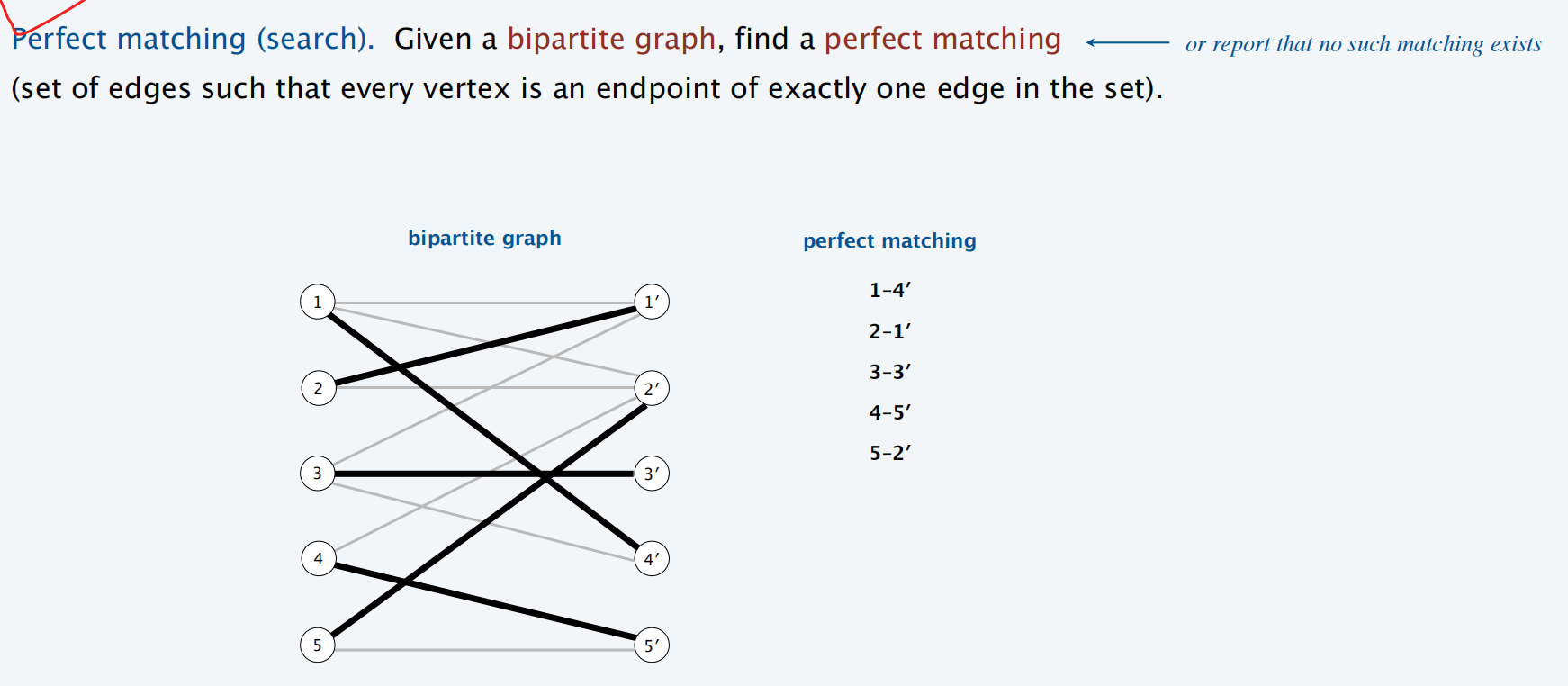
bipartite graph 的 perfect matching
def:
-
边独立(Disjoint Edges): 如果两条边没有共同的端点,就称它们是独立的。
-
匹配(Matching): 图中一个任意两条边都没有共同端点的边集合。这意味着,在匹配集合里,任何一个顶点最多只能连接一条边(即没有顶点被"脚踩两只船")。
-
完美匹配(Perfect Matching): 在匹配的基础上,要求所有顶点都必须被连上(即没有任何一个顶点被"剩下")。【本质是这样一个边的集合P,满足:没有点被剩下,没有点同时连接着P中的多条边】
找一个数的一个因子(nontrivial factor):difficlut
误区:统计是基于占用的比特位来计算的


SAT:布尔可满足性问题
问题定义 (Search Problem): 给定一个布尔方程组(a system of boolean questions),寻找一组使整个方程组都为真(true)的真值指派 (Satisfying Truth Assignment)。如果根本不存在这样的组合,则报告无解。


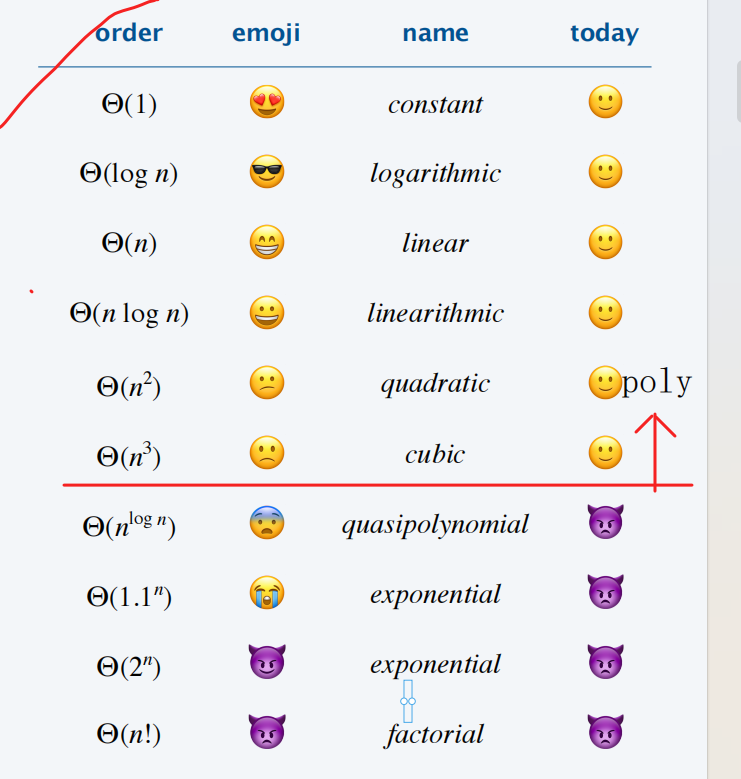
多项式时间定义 an^b(a,b are constant)

常用复杂度及其英语
注意:nlogn也是poly,2^n不是!

65Randomness
划分:随机的&确定的算法
随机性和stable是什么关系:是两个完全不同的概念
不stable的算法也可以是确定性的,因为随机性必须要有概率、有shuffle这样的操作
例子:下面讲的算法,除了随机快速排序(pivot划分成左右两个子数组,随机选择,所以是随机的)之外,都是确定性算法
uniform distribution:均匀分布

Knuth shuffle:随机排序的实现
在这个过程中,数组被切分为两部分:左边是已经洗牌完毕的区域,右边是还未处理的原始区域。每次迭代,算法都把右边区域的第一个元素,随机插入到左边已洗好的区域中。

对比:LV&MC
拉斯维加斯:结果绝对正确,但耗时看运气。


| 特性 | 拉斯维加斯算法 (Las Vegas) | 蒙特卡洛算法 (Monte Carlo) |
|---|---|---|
| 正确性 | 100% 绝对正确 | 可能出错(概率可控) |
| 运行时间 | 随机、不固定(平均很快,最坏很慢) | 绝对固定(通常非常快) |
| 核心关注点 | 怎么用随机性规避最坏时间复杂度 | 怎么用随机性在有限时间内逼近答案 |
| 典型例子 | 随机化快速排序 (Quicksort)、Quickselect | 之前作业里的渗透阈值模拟 (Percolation) |
13_45DynamicProgramming动态规划memoization
**动机:**问题解决过程中存在overlapping(重复计算)【重叠子问题】
**第一步:**确定什么是子问题(或者说dpi代表什么)
**状态转移:**从dpn-x得到dpn,转移的方式很多,包括但不限于加减乘除、min-max操作
**tip:**在构造状态转移方程的时候,可以大胆假设dpn-x已经求好了(把他当成已知条件),专注于在dpn-x已经求好这一条件下的状态转移。
**边界处理:**最小子问题的默认值
具体实现还要考虑:
3️⃣确定子问题的计算顺序 (Determine the subproblem order)
- 核心动作:决定是自底向上(Tabulation,填表)还是自顶向下。如果是填表,必须严格保证在计算当前状态时,它所依赖的所有子状态都已经全部计算完毕。
4️⃣计算最优值并缓存结果 (Compute optimal values while caching results)
-
核心动作:真正执行计算。
-
Memoization (记忆化搜索):自顶向下递归,查表防止重复计算。
-
Tabulation (迭代填表):自底向上循环,直接顺序推导。
-
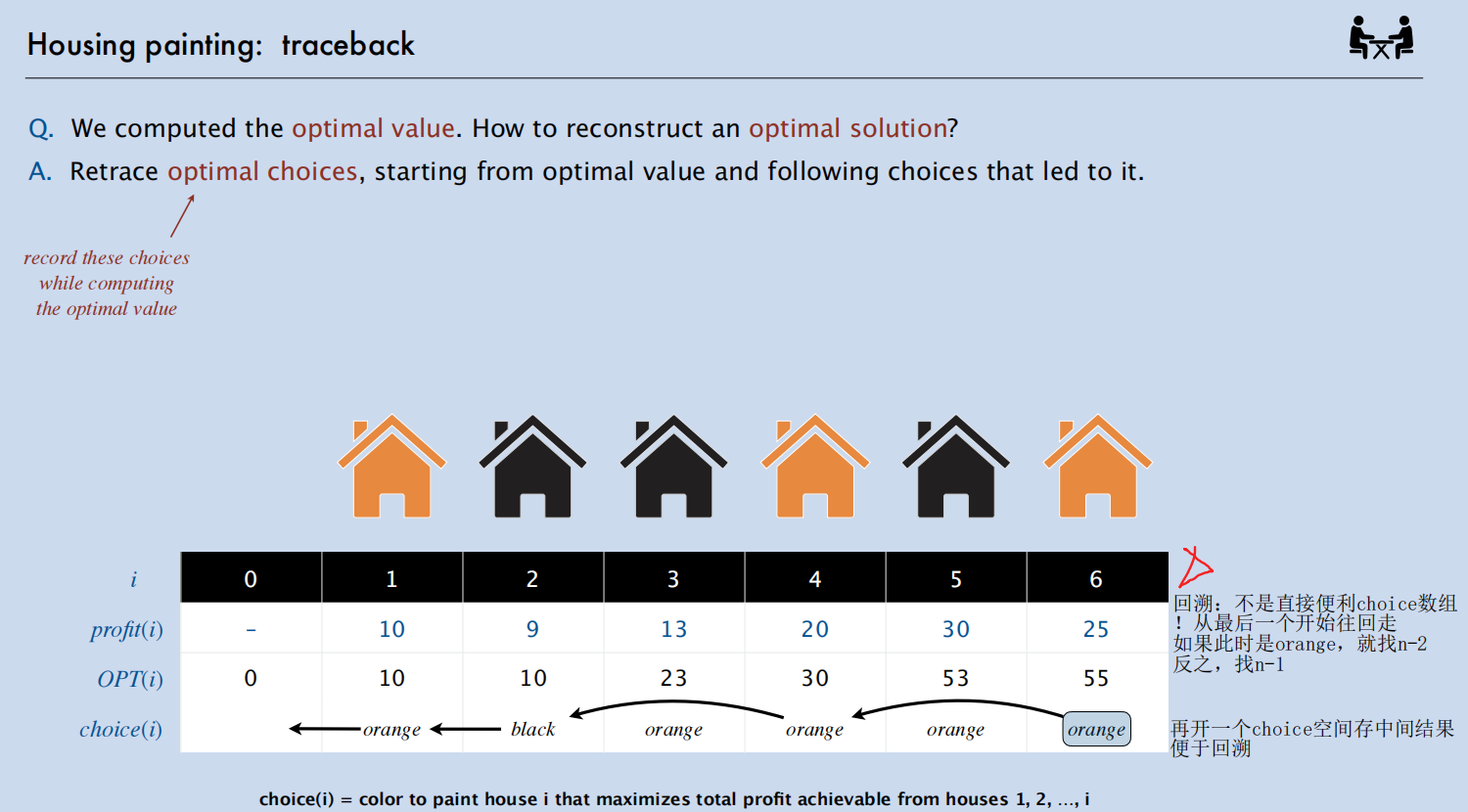
考虑回溯:很多时候我们不仅需要最大价值(比如 3天 或 50元),还需要知道具体怎么凑出来的(比如具体走哪条路、选了哪些物品)。这需要用到 Backtracing (回溯)。
斐波那契数组:
递归实现:

归并实现:

线性时间,常量空间
只维护f,g两个变量
过程演示(以 n=5 为例):
| 迭代次数 | f(当前项) | g(下一项) |
|----------|-------------|-------------|
| 初始 | 0 | 1 |
| i=0 | 1 | 1 |
| i=1 | 1 | 2 |
| i=2 | 2 | 3 |
| i=3 | 3 | 5 |
| i=4 | 5 | 8 |
上图下方进一步优化:【没有重点讲】

房子喷漆问题
题目:给定一排 n 栋黑色房子,每栋房子 i 粉刷成橙色可以获得利润 profit(i),约束条件是不能粉刷相邻的两栋房子,目标是最大化总利润。

动态规划方法推导:

所有合法方案的可能性推导:斐波那契数列变体
不能粉刷相邻房子的方案数,是 n 的指数级(O (2ⁿ)),增长极快。

递归完成之后回溯

找零钱问题【下面的选项B就是最经典的解法】
动态规划可以保证全局最优,但是贪心法不能保证


动态规划在最短路径中的利用【DAG最短路径算法】
由于 DAG 没有环,因此我们可以先对图进行拓扑排序,得到一个节点序列,保证所有边 u→v 中 u 排在 v 前面。 进行拓扑排序的意义在于,在计算 distTo(v) 时,所有 v 的前驱节点 u 的 distTo(u) 都已经计算完成,无需回溯。

1️⃣标准,但构建反向表比较繁琐


2️⃣更简单实现

| 特性 | Dijkstra 算法 | DAG 最短路算法 |
|---|---|---|
| 核心驱动机制 | 贪心策略,每次从优先队列里挑当前距离最小的节点。 | 严格遵循拓扑排序的顺序,不需要维护优先队列。 |
| 负权边支持 | ❌ 无法正确处理负权边。 | 能完美支持负权边(只要无环即可)。 |
| 时间复杂度 | O(E \\log V)(使用二叉堆)。 | \\Theta(E + V)(线性时间,效率极高)。 |
PS:最长路径算法可轻松转化得到

动态规划问题中的求最值规问题约到DAG最短路径问题
本质还是要确定dpi的意义,然后列出状态转移方程,状态转移
一般规约思路:
- 最短路径问题-最值求解问题
- 图的边权-求最值的对象

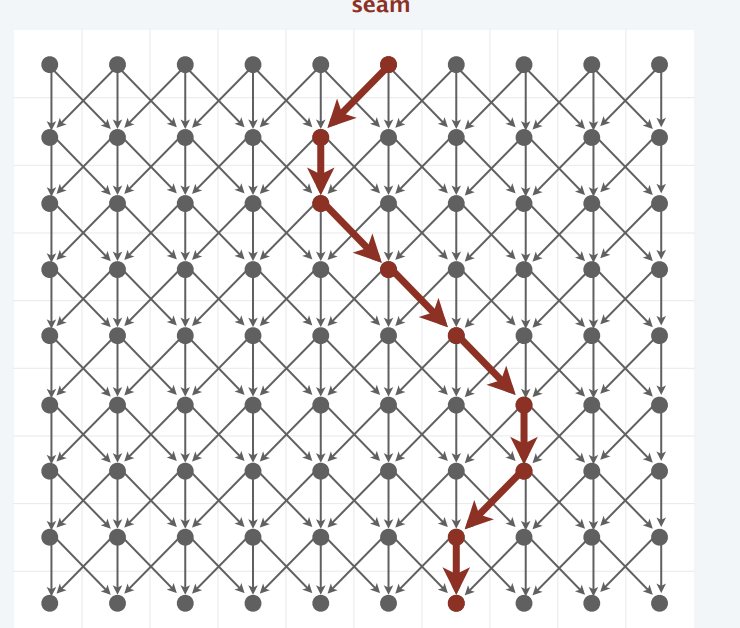
Seam Carving【图像缩放技术】
动态规划(DP)在计算机视觉领域最精妙、最著名的实际应用之一:智能图像缩放(Content-aware resizing) ,也被称为 Seam Carving(缝隙裁剪) 算法。

算法核心:如何把它映射成一张 DAG?
为了找到那条"最不重要"的缝隙,算法直接把整张图片看作了一张网格图(Grid Graph):
**节点(Vertices):**像素点
图片的每一个像素 (x, y) 就是图中的一个节点。
边(Edges):向下的 3 种选择
为了让裁剪出的缝隙从上到下保持连续(不能这里挖一个像素,那里挖一个像素,否则画面会断裂),算法规定:每一个像素只能连向它正下方、左下方、右下方的 3 个邻居像素。
-
SW(South-West,左下)
-
S(South,正下)
-
SE(South-East,右下)
这构成了天然的有向无环图(DAG),因为边永远从上指向下,绝不可能往回指。
点权/边权(Weight):"能量函数(Energy Function)"
怎么衡量一个像素"重不重要"?看它周围的颜色变化剧烈程度(通常利用 Sobel 算子求梯度)。
-
如果一个像素和周围像素颜色差异极大(比如衣服和背景的交界处、人的五官),说明它是边缘/重要信息,能量值很高。
-
如果一个像素和周围基本一样(比如大片的蓝天、白墙),说明它是冗余信息,能量值很低。
12_55【需要听老师讲,题没弄懂】
RLE
RLE)是一种针对连续重复数据的无损压缩算法,核心逻辑是:把「连续重复的比特」,用「重复次数 + 数据值」的方式来表示。
新的编码长度,取决于最大连续出现的长度

压缩率 16/40 = 40%
重要例题:理解为什么要留一种编码作为"分隔符"

模式串查找SA
思想:对所有后缀数组排序,关注其中前缀部分等于P(模式串)的哪些,因为整体经过排序,所以他们(前缀相同的)肯定分布在一块,SA就是要找到这个区间的左边界和右边界,这个区间内就是前缀为P的。
- SAs存的是(在后缀数组中)排序为s的后缀所对应在T中的真实下标
- sp,st是利用二分法找左边界过程中的子区间的左右边界
- ep,et是利用二分法找右边界过程中的子区间的左右边界
cpp
Algorithm SASearch(P, SA, T)
// T: 长度为 n 的文本串, P: 长度为 m 的模式串
// SA: T 的后缀数组
1. sp <- 1, st <- n + 1
找左边界
2. While sp < st do
3. s <- floor((sp + st) / 2)
4. if P > T[SA[s], SA[s] + m - 1]
5. then sp <- s + 1
6. else st <- s
7. ep <- sp - 1, et <- n
在剩余区间中找右边界
8. While ep < et do
9. e <- ceil((ep + et) / 2) //ceil就是向上取整函数
10. if P = T[SA[e], SA[e] + m - 1]
11. then ep <- e
12. else et <- e - 1
13. return (sp, ep)Analysis
输入变量中,T 是原文本,P 是待查找的模式串,SA 是已经按字典序排好序的后缀数组。
因为 SA 是严格有序的,所以原串中所有以 P 为前缀的后缀,在 SA 数组里一定会紧紧挨在一起,形成一个连续的区间 [sp, ep]。整个算法的核心机制就是跑两次二分查找,分别锁定这个区间的左右边界。
1. 寻找左边界(Line 1-6)
-
目标 :找到第一个以
P为前缀的后缀的索引sp(Start Pointer)。 -
机制 :在
[1, n+1]区间内二分。每次取中点s,提取该后缀的前 m 个字符与P进行字典序比较。如果P字典序更大(第4行),说明匹配项在右侧,左指针推进(sp <- s + 1);否则说明目标在当前位置或更左侧,右边界收缩(st <- s)。最终sp会精准停在匹配区间的起始位置。
2. 寻找右边界(Line 7-12)
-
目标 :找到最后一个以
P为前缀的后缀的索引ep(End Pointer)。 -
机制 :在
[sp-1, n]区间内二分。因为左边界已经确定为sp,所以搜索起点直接复用。 -
精妙之处 :第9行在计算中点
e时,使用了向上取整ceil。这里设计很精妙,由于我们要找的是右边界,当P刚好等于目标前缀时(第10行),左指针会直接跃迁到e(ep <- e)。如果向下取整,当ep和et只差 1 时会陷入死循环,使用ceil完美规避了这个问题。如果不匹配,说明找过了头,右指针往回缩(et <- e - 1)。
我们可以用如下结构直观理解这两次二分的作用域:
SA 数组下标 对应的后缀 (假设 P="ab")
------------------------------------
... | ...
[sp - 1] | "aa..." <- 字典序小于 P
[sp] | "aba..." <- 第一段二分找到的左边界
... | "abb..."
[e] | "abc..." <- 第二段二分游标在区间内跳跃
... | "abz..."
[ep] | "abz..." <- 第二段二分找到的右边界
[ep + 1] | "ac..." <- 字典序大于 P
... | ...Effect
算法最终返回一个元组 (sp, ep)。
这个返回值直接框定了所有成功匹配的后缀范围。如果 sp > ep,说明文本 T 中根本不存在模式串 P;如果 sp <= ep,那么 P 在原串中出现的总次数就是 ep - sp + 1。
通过这种两次二分的隔离机制,无论 P 在原文本中出现了多少次,单次搜索的时间复杂度都被极其稳定地限制在了 O(m \\log n),完美利用了后缀数组的预处理价值。
cpp
#include <iostream>
#include <string>
#include <vector>
using namespace std;
// 核心函数:在文本 T 中利用后缀数组 SA 搜索模式串 P
pair<int, int> SASearch(const string& P, const vector<int>& SA, const string& T) {
int n = T.length();
int m = P.length();
// 1. 寻找左边界 (Start Pointer)
int sp = 0, st = n; // C++ 为 0-index,搜索区间为 [0, n)
while (sp < st) {
int s = sp + (st - sp) / 2; // 默认向下取整
// 提取后缀的前 m 个字符(如果后缀长度不足 m,substr 会自动截取到末尾)
string suffix_prefix = T.substr(SA[s], m);
if (P > suffix_prefix) {
sp = s + 1;
} else {
st = s;//当P=suffix_prefix时默认改区间右边界st,从而保证最终收敛到全局左边界
}
}
// 2. 寻找右边界 (End Pointer)
int ep = sp - 1, et = n - 1;
while (ep < et) {
// 向上取整的整型实现:加上 1 使得偏向右侧中点
int e = ep + (et - ep + 1) / 2;
string suffix_prefix = T.substr(SA[e], m);
if (P == suffix_prefix) {
ep = e;
} else {
et = e - 1;
}
}
return {sp, ep};
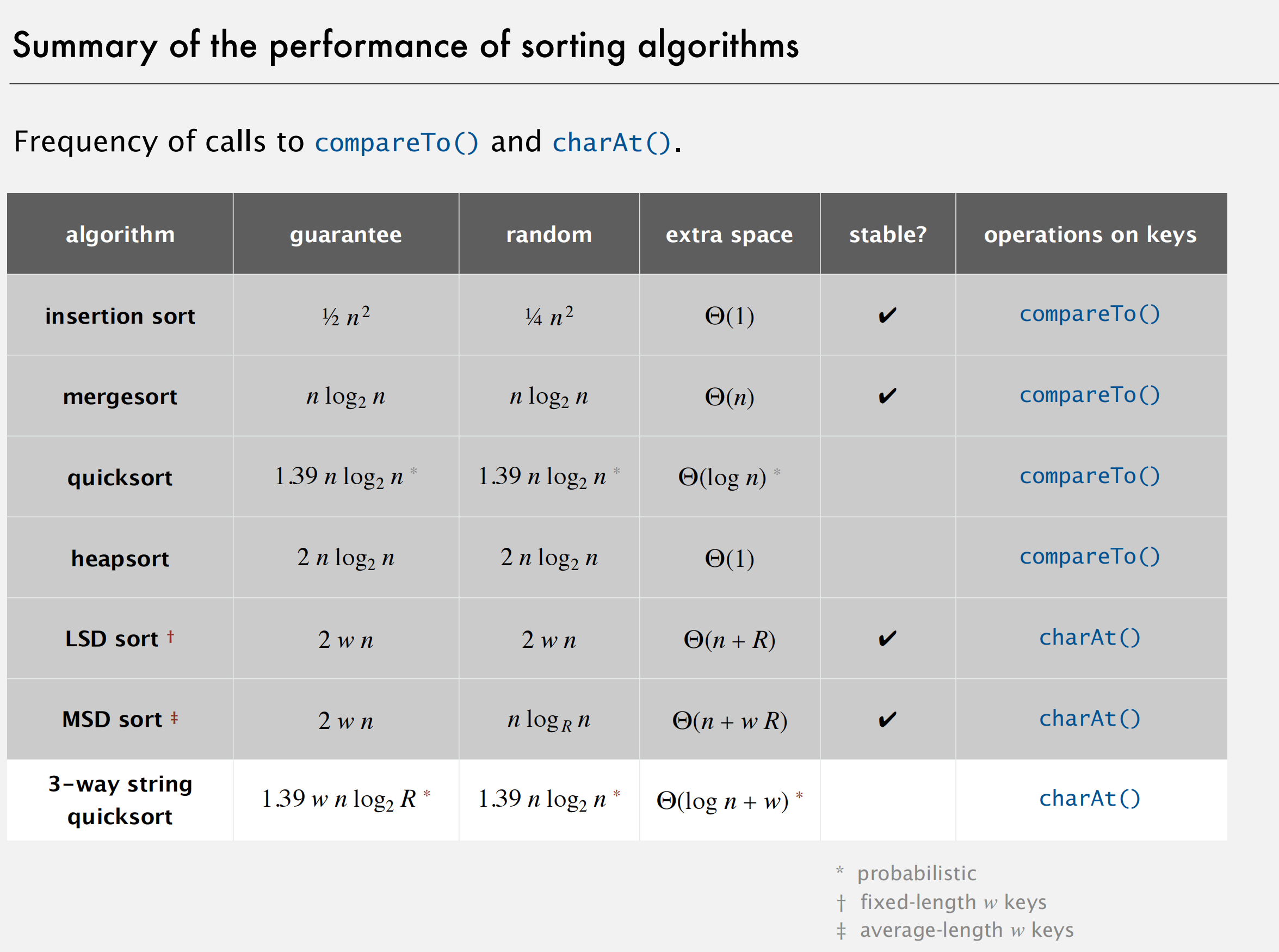
}11_51StringSorts 20后面是自学的
索引计数排序
计数排序是一种非比较排序 ,它的时间复杂度是 O(n + k),特别适合固定长度的整数数据(这也为后面的LSD打下了基础)
- 统计频次:开一个计数数组,统计每个数值出现多少次;
- 求前缀和 :把计数数组变成「每个值最后应该排在哪个下标位置」;
- 回填(这里的描述和课件相反,课件是正序) :从原数组从后往前 遍历,按前缀和给的位置放元素,放一个就前缀和减一,保证稳定。


LSD 基数排序
- 从右向左,逐字节地进行排序,因此取R = 256(2^8)
- 对每字节的内部排序,用计数排序这个方法,复杂度是O(n+256)
- 所以总共的时间复杂度是 字节数*n
优势:LSD(Least Significant Digit)基数排序特别适合固定长度的整数数据(本质上是内部的计数排序特别适合)。对于 32 位整数,它只需执行约 4 次计数排序(每次处理 8 位)
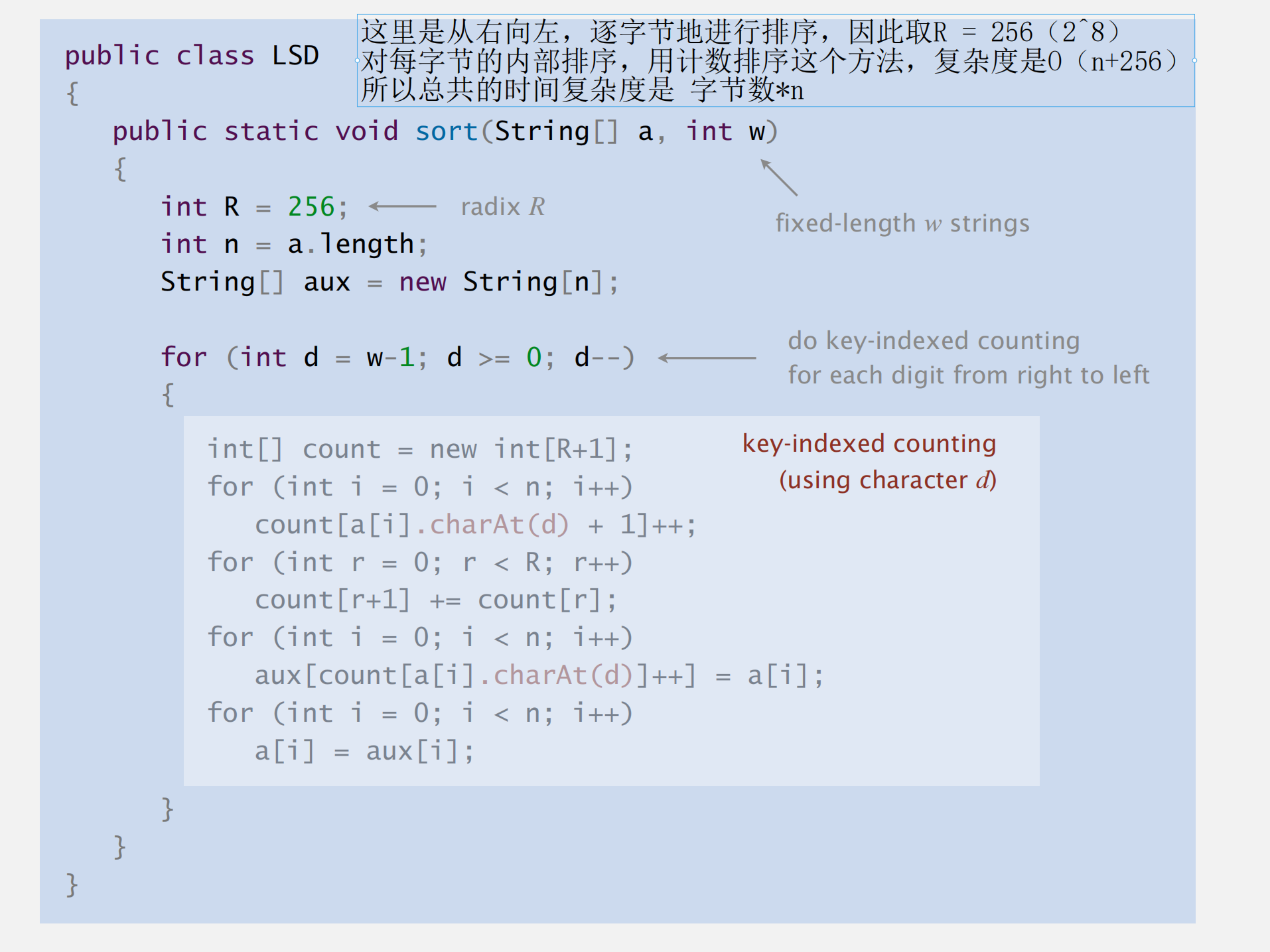
注意:LSD只是强调了排序的顺序(从右向左排),但是对每一位,可以用任意的stable算法来进行排序。(正式是用计数排序来操作)

MSD
- 对比:LSD 是从右往左、一轮轮处理所有数据;
- MSD 是从左往右,先按最高位把数据分到不同的 "桶" 里,再对每个桶递归处理下一位。
这就像查字典:先按首字母分成 26 个组,再对每个组按第二个字母细分,以此类推。
和 LSD 的计数排序逻辑几乎一样,但有两点关键区别:
- 它只处理当前子数组
[lo..hi],而不是整个数组 - 计数排序完成后,数组按第
d位分成了R个 "桶",每个桶里的元素当前位相同
复杂度:
- 对于固定长度字符串,总复杂度仍是 O(w·n),和 LSD 一样是线性时间
- 但在实际中,MSD 会提前终止(短的字符串或相同前缀的子数组),平均性能可能更好

对比例题:关键看MSD的递归深度
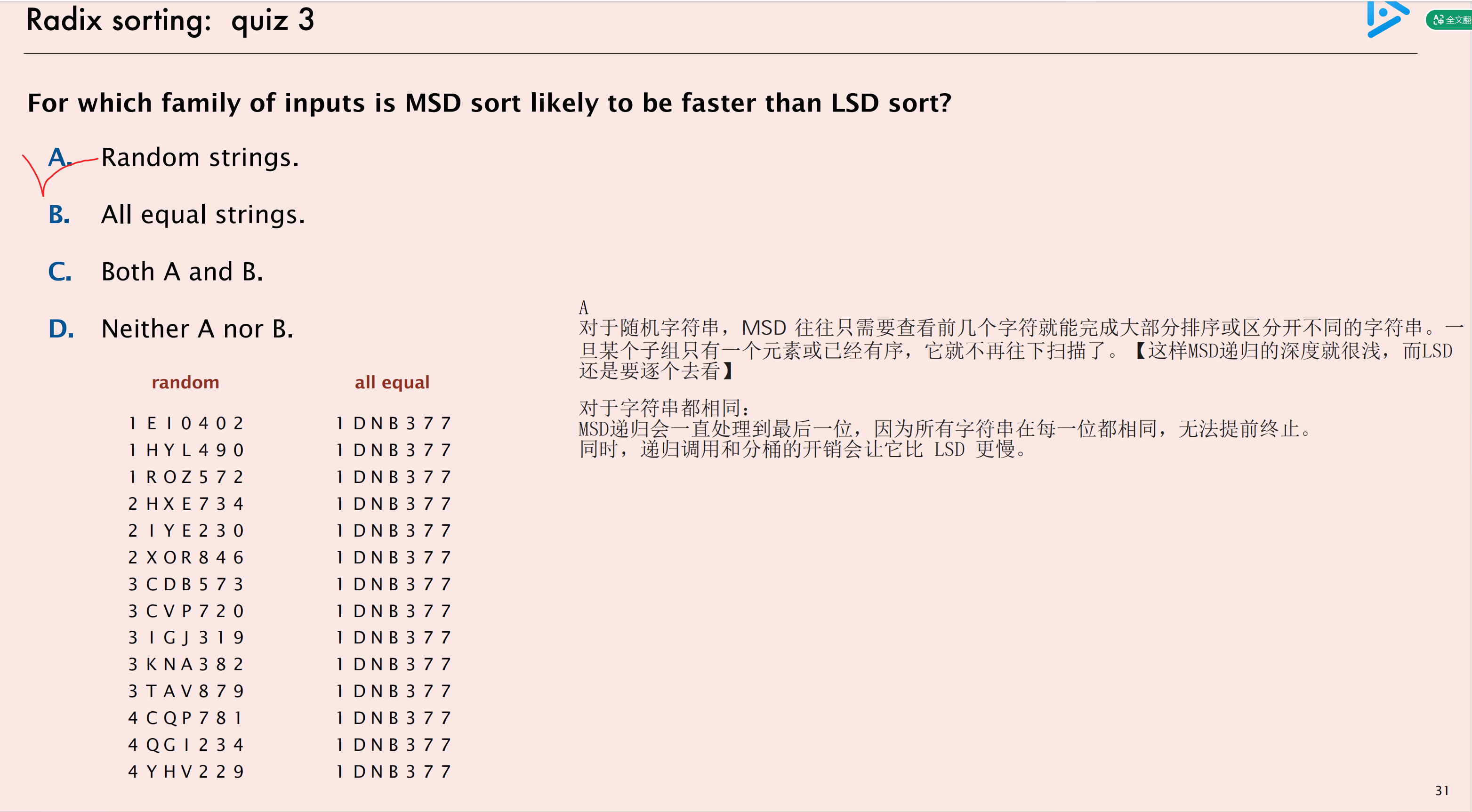
3way string quicksort
递归处理,传递参数:+当前排序按照哪一位d,排序组内范围lo-hi
按当前字符分三堆:小、等、大 → 小和大继续按这一位排 ,相等的直接排下一位(++d)!

复杂度:
10_44 Shortest Paths(就是SPT):讲到p40好像就没讲了
(PS:ST是生成树)
SPT 和 MST 关系:完全两回事,没有必然包含 / 等价关系
先记全称:
- SPT :Shortest Path Tree 最短路径树(单源到所有点最短路)
- MST :Minimum Spanning Tree 最小生成树(整张图连通总边权最小)
车载系统,属于single destination:from every vertex to one destination
因为司机中途走错路了可以马上更新路径
- 起点:当前车辆位置(随时变)
- 终点:用户设置的目的地(固定)
edgeTo1:到1的路径上的最后那条边(方便从1回溯)
结论:从一个起点 s 到所有节点的最短路径,一定会构成一棵「有向树」,绝对不会是普通图
更新最短路径的过程叫做"松弛"【relaxing】
松弛操作:试图通过边 u→v,优化从起点到 v 的最短路径。
relax all edges incidentfrom v. 松弛所有从 v 出发的边。
incident to the vertex:指向这个顶点
Bellman-Fold
// 外层循环:执行 V-1 轮(i从1到G.V()-1,共V-1次),
//第 k 轮循环(从 1 开始)后,可以保证:所有最多经过 k 条边的最短路径,都已经被算出来。
for (int i = 1; i < G.V(); i++)
// 中层循环:遍历每个顶点 v
for (int v = 0; v < G.V(); v++)
// 内层循环:遍历顶点 v 的所有邻接边 e(即对每条边执行松弛)
for (DirectedEdge e : G.adj(v))
relax(e); // 执行松弛操作算法的每一轮 "松弛",本质上是在确定路径上第 k 步能到达的最远距离。
- 第 1 轮松弛 :我们能找到所有只经过 1 条边的最短路径。
- 第 2 轮松弛 :我们能找到所有经过 2 条边的最短路径。
- ...
- 第 k 轮松弛:可以保证:所有最多经过 k 条边的最短路径,都已经被算出来。
因为最短路径最多只有 V−1 条边,所以我们只需要执行 V−1 轮。

代码实现中的优化:
1️⃣如果节点 v 的最短距离 distTov 在第 i 轮没有变化,那么第 i+1 轮完全不需要松弛 v 的任何出边。(因为他一定不会带给相邻节点变化)
2️⃣队列实现

贝尔曼福德算法要求:有环可以,只要环的权值之和是正的
解释:
- 因为如果非正,那么转一圈权值更小了,永远找不到最短路径
- 如果是非负权环,那么最短路径一定不包含环,不然去掉环权重更小
对比迪杰斯特拉:要求所有权值非负
迪杰斯特拉
Dijkstra 是典型的贪心算法:每次从未标记顶点 中,选择 distTo 值最小的顶点 v,将其加入 S,然后松弛所有从 v 出发的边(更新邻居的 distTo 和 edgeTo)。
对比:
- Dijkstra :累加路径,关心从起点走过来一共多远
- Prim :只看单边,关心连进集合最便宜的一条边
类方法说明见下

复杂度分析:delMin的复杂度是logV(d叉堆,V节点的复杂度是dlogV,d是常数的话就是logV)

类方法说明(
IndexMinPQ接口)
方法 作用 对应 Dijkstra 中的场景 IndexMinPQ(int n)创建一个索引范围为 0,1,...,n-1的优先队列初始化,容量为图的顶点数 V void insert(int i, Key key)将键 key与索引i关联并插入队列第一次访问顶点 i时,插入其距离值int delMin()删除值最小的键,并返回其关联的索引 取出当前距离源点最近的未标记顶点 void decreaseKey(int i, Key key)将索引 i对应的键值更新为更小的key松弛边时,更新顶点 i的最短距离boolean isEmpty()判断队列是否为空 判断所有顶点是否都已标记处理完成
维护两个数组:distTo和edgeTo【物理意义distTow:从s,经过当前所有的已标记的点,能到w的最短路径,以及这个路径上离w最近的节点(edgeTo)】

-
Dijkstra 是典型的贪心算法:每次从未标记顶点 中,选择
distTo值最小的顶点v,将其加入S,然后松弛所有从v出发的边(更新邻居的distTo和edgeTo)。这里的 "局部最优",就是 "当前离源点最近的未标记顶点"。 -
贪心的全局最优保证:不是 所有贪心策略都能保证全局最优,但 Dijkstra 在非负权图上可以做到。
-
证明:induction【数学归纳法】:
-
induction base:distTos = 0成立
-
假设现在已标记的点成立,证明新加入的点也成立
-
一、核心区别
| 维度 | SPT 最短路径树 | MST 最小生成树 |
|---|---|---|
| 目标 | 固定一个源点 ,保证源到每个点路径最短 | 不固定源点,保证整棵树所有边权总和最小 |
| 关注点 | 单点到各点路径长度 | 整张图全局总权重 |
| 结构 | 以源为根的有向 / 无向树 | 无向连通生成树,无根概念 |
0943Trees(ST&MST)
- square:平方
- square root:平方根
ST的三个核心性质【解题重点!】
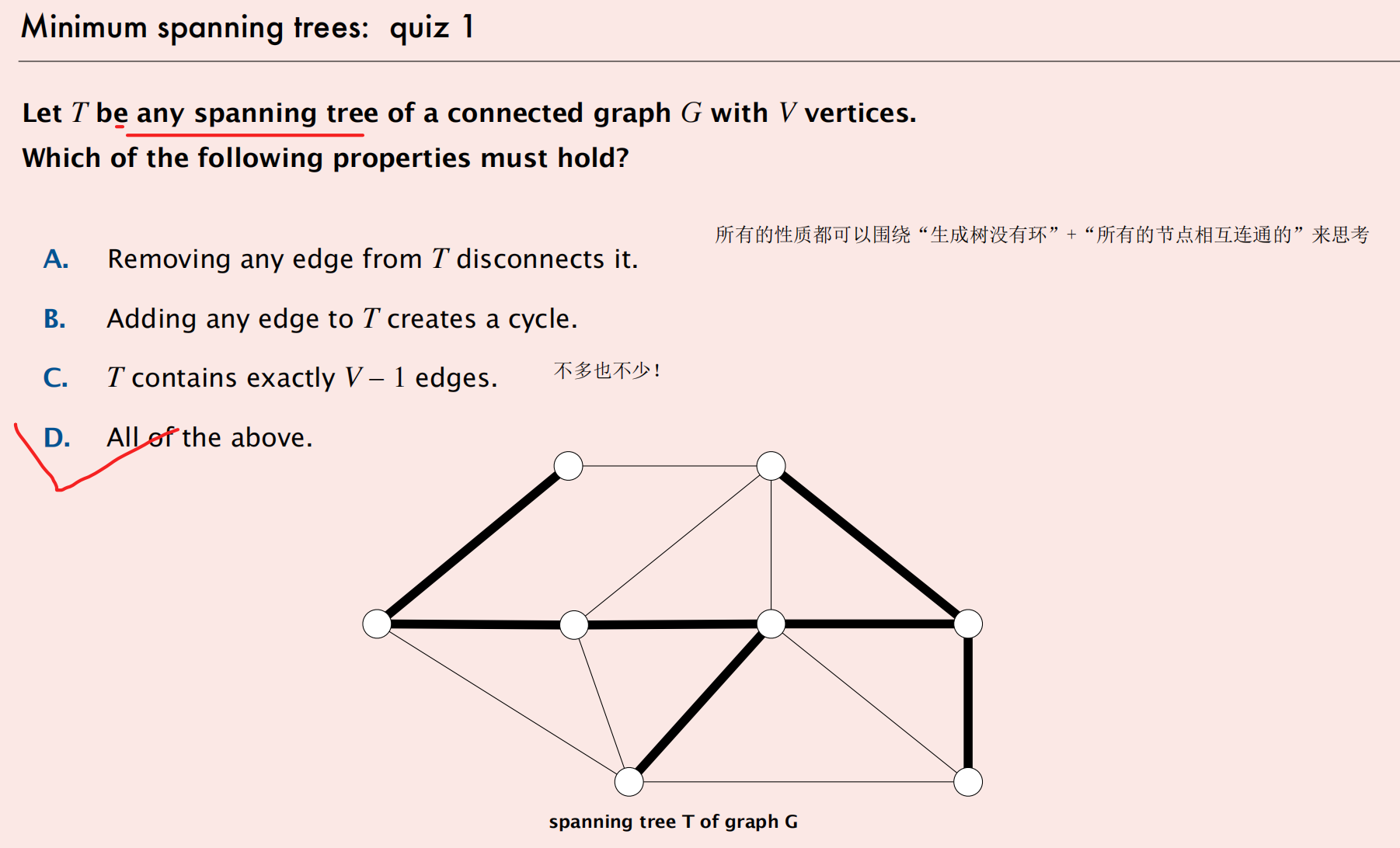
Kruskal:带权无向连通图
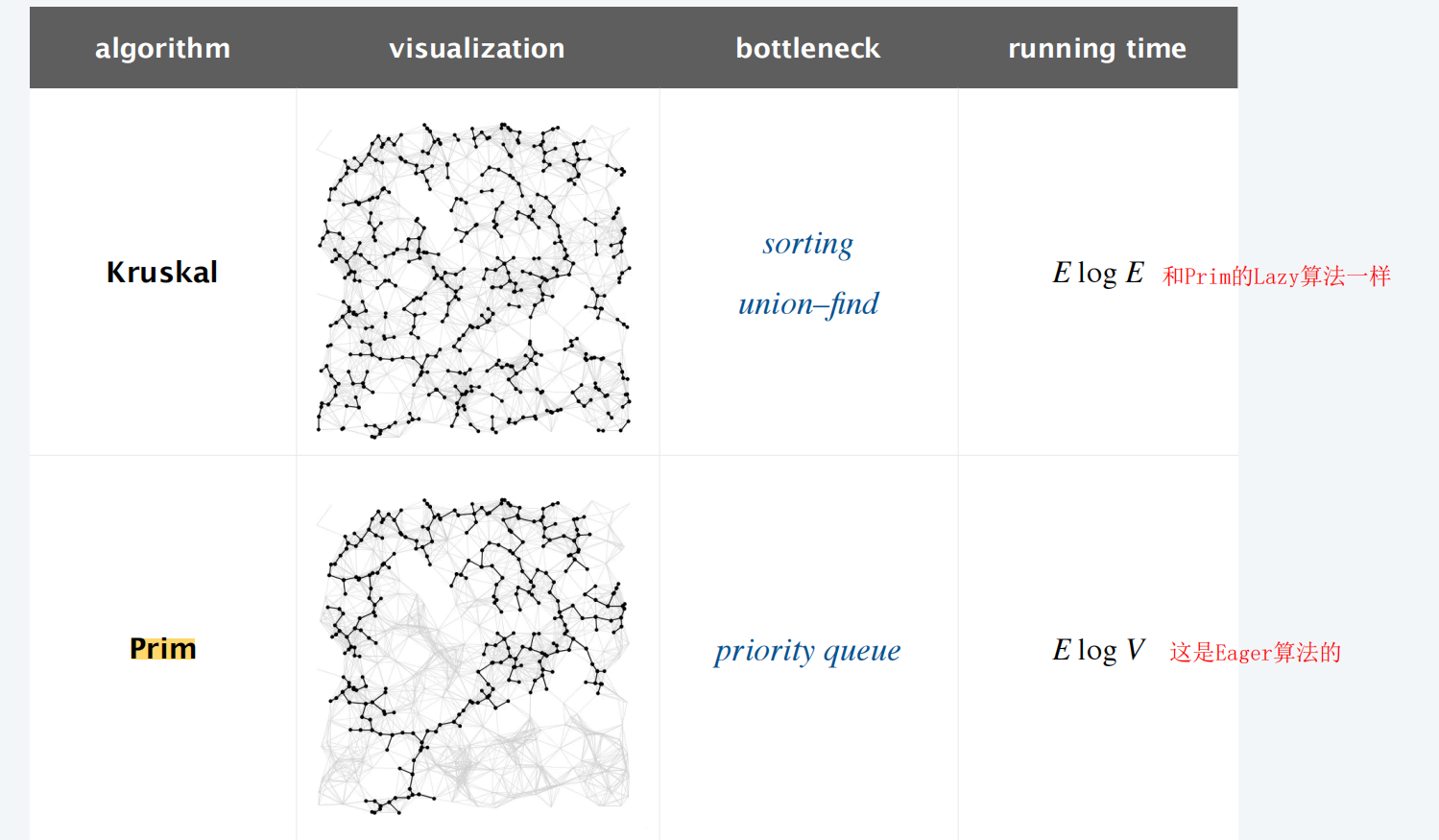
贪心策略:从小到大选边,不构成环就选,直到连通所有点。 本质:按边权升序排序,依次加边,用并查集判环。
复杂度分析:
复杂度主要来自两部分:
- 对所有边排序 ElogE
- 查找,归并 近似常数
合起来接近 O(ElogE)

开销分析:ElogE

Prim:
Prim:从一个起点开始,每次贪心地选「连接已选集合、权值最小的那条边」,把新节点拉进来,直到所有点都加入。
Lazy版:


Prim:Eager
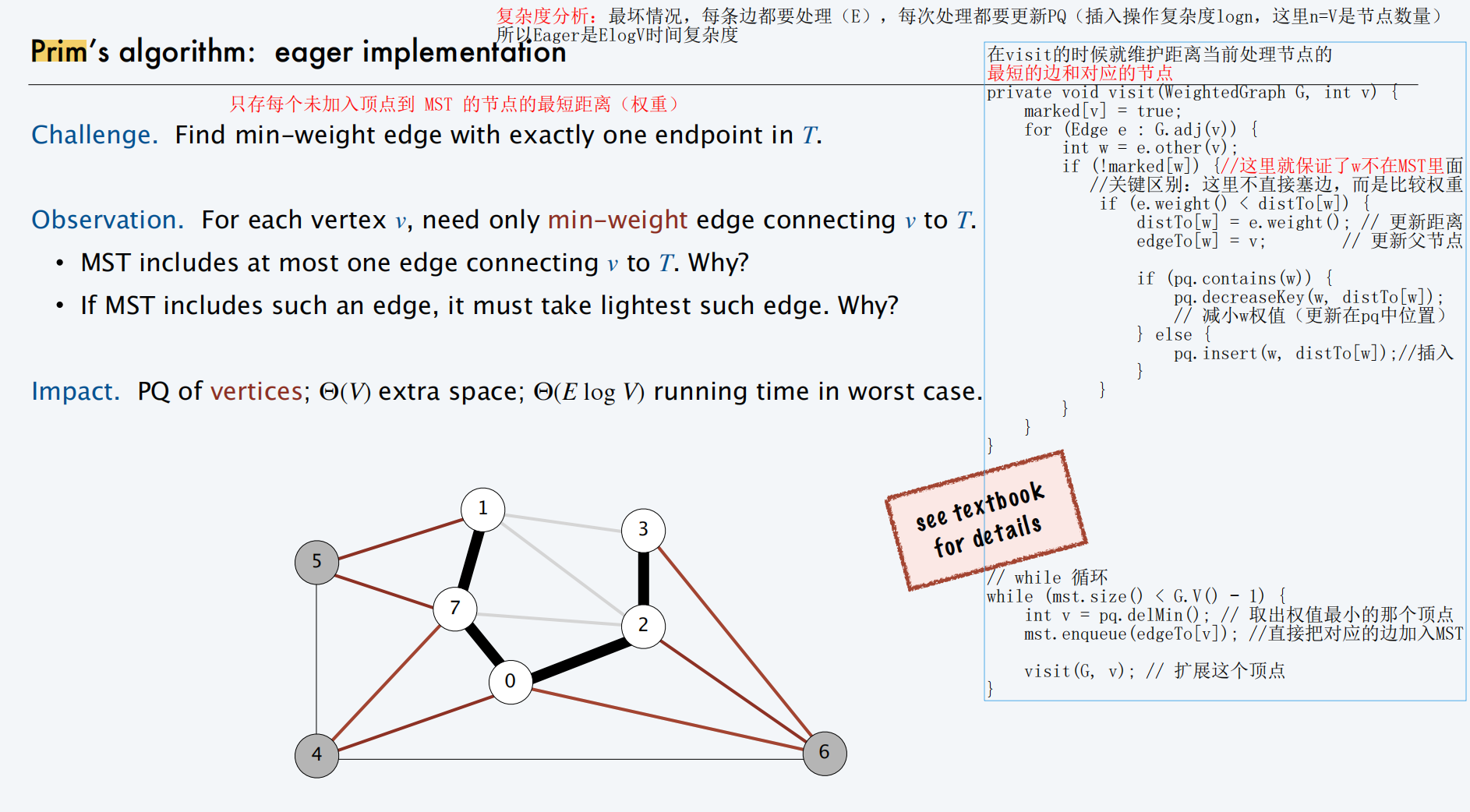 对比:
对比:
- Lazy 在
visit里 :只是无脑把边加入队列(pq.insert(e)),不管好坏。 - Eager 在
visit里 :做了择优判断 。- 它维护了
distTo[]数组,记录每个点到 MST 的当前最小距离。 - 如果新发现的边权(
e.weight())比之前记录的更小( weight < distTow) ,才更新队列(decreaseKey)。 - 如果新边权更大 ,直接 忽略,不加入队列。
- 它维护了
0904Graph



Priority Queue 【底层是堆】
- swim
- sink
选择:关键看,变化之后,影响了上面(父节点)还是下面(子节点),如果让当前节点和父节点的关系变得不确定, 就要swim;反之(与孩子节点)就要sink
delMin操作复杂度:logn【其中n是堆的节点的数量】
insert也是!logn
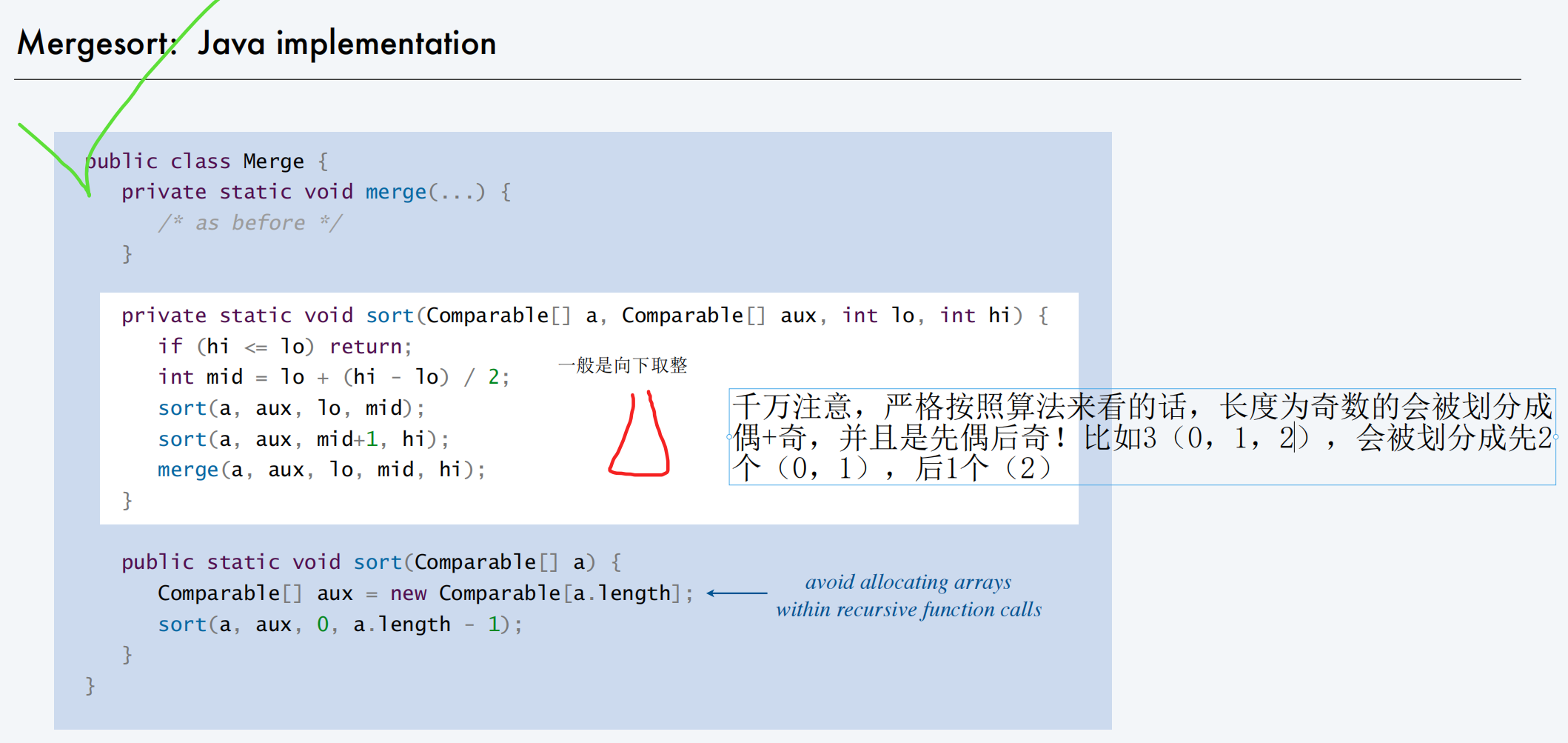
Mergesort【第三次作业,2.2】