目录
[1.1 何谓 AI ?(What is AI?)](#1.1 何谓 AI ?(What is AI?))
[1.1.1 以人为本:Turingˈtjʊərɪŋ测试法(Acting humanly: The Turing test approach)](#1.1.1 以人为本:Turing[ˈtjʊərɪŋ]测试法(Acting humanly: The Turing test approach))
[1.1.2 似人思考:认知建模法(Thinking humanly: The cognitive modeling approach)](#1.1.2 似人思考:认知建模法(Thinking humanly: The cognitive modeling approach))
[1.1.3 理性思考:"思考法则"法(Thinking rationally: The "laws of thought" approach)](#1.1.3 理性思考:“思考法则”法(Thinking rationally: The “laws of thought” approach))
[1.1.4 理性行动:理性智体法(Acting rationally: The rational agent approach)](#1.1.4 理性行动:理性智体法(Acting rationally: The rational agent approach))
[1.1.5 益机(Beneficial machines)](#1.1.5 益机(Beneficial machines))
[1.2 AI之基础(The Foundations of Artificial Intelligence)](#1.2 AI之基础(The Foundations of Artificial Intelligence))
[1.2.1 哲学(Philosophy)](#1.2.1 哲学(Philosophy))
[1.2.2 数学(Mathematics)](#1.2.2 数学(Mathematics))
[1.2.3 经济学(Economics)](#1.2.3 经济学(Economics))
[1.2.4 神经科学(Neuroscience)](#1.2.4 神经科学(Neuroscience))
[1.2.5 心理学(Psychology)](#1.2.5 心理学(Psychology))
[1.2.6 计算机工程(Computer engineering)](#1.2.6 计算机工程(Computer engineering))
[1.2.7 控制理论与控制论(Control theory and cybernetics)](#1.2.7 控制理论与控制论(Control theory and cybernetics))
[1.2.8 语言学(Linguistics)](#1.2.8 语言学(Linguistics))
[1.3 AI之历史(The History of Artificial Intelligence)](#1.3 AI之历史(The History of Artificial Intelligence))
[1.3.1 AI的诞生(The inception of artificial intelligence)(1943-1956)](#1.3.1 AI的诞生(The inception of artificial intelligence)(1943-1956))
[1.3.2 初期热情,极高期望(The Early enthusiasm, great expectations)(1952-1969)](#1.3.2 初期热情,极高期望(The Early enthusiasm, great expectations)(1952-1969))
[1.3.3 面对现实(A dose of reality)(1966-1973)](#1.3.3 面对现实(A dose of reality)(1966-1973))
[1.3.4 专家系统(Expert Systems)(1969-1986)](#1.3.4 专家系统(Expert Systems)(1969-1986))
[1.3.5 神经网络的回归(The return of neural networks)(1986-当前)](#1.3.5 神经网络的回归(The return of neural networks)(1986-当前))
[1.3.6 概率推理和机器学习(Probabilistic reasoning and machine learning)(1987-当前)](#1.3.6 概率推理和机器学习(Probabilistic reasoning and machine learning)(1987-当前))
[1.3.7 大数据(Big data)(2001-当前)](#1.3.7 大数据(Big data)(2001-当前))
[1.3.8 深度学习(Deep learning)(2011-当前)](#1.3.8 深度学习(Deep learning)(2011-当前))
[1.4 阶段性最高水平(The state of the Art)](#1.4 阶段性最高水平(The state of the Art))
[1.5 AI的风险与收益(The Risks and Benefits of AI)](#1.5 AI的风险与收益(The Risks and Benefits of AI))
第 1 章 导引( Introduction**)**
在本文中,我们将尝试解释为什么我们认为人工智能是一个非常值得研究的课题,并且我们将尝试确定它究竟是什么,这在开始研究之前是一件好事。
我们称自己为智人 (Homo sapiens)------智慧之人------因为智慧对我们至关重要。数千年来,我们一直试图理解自身的思维和行为方式------即,我们的大脑,这区区一小撮物质,是如何感知、理解、预测并操控一个远比自身庞大复杂得多的世界的。人工智能 (AI------artificial intelligence)领域不仅关注理解,更致力于构建智能实体------能够计算如何在各种全新情境下有效且安全地行动的机器。
调查显示,AI经常被评为最有趣、发展最快的领域之一,其年收入已超过万亿美元。AI专家李开复预测,AI的影响将"超过人类历史上任何事物"。此外,AI的智力前沿领域仍然广阔无垠。虽然物理学等传统学科的学生可能会觉得Galileo,Newton,居里夫人(Curie),Einstein等人已经发现了最伟大的思想,但AI领域仍然有很多机会等待全职的顶尖人才加入。
AI目前涵盖众多子领域,从一般层面(学习、推理、感知等)到具体层面(例如下棋、证明数学定理、作诗、开车或诊断疾病)。AI与任何智力活动都息息相关;它真是一个普适的领域。
1.1 何谓 AI ?( What is AI**?)**
我们已说过AI 很有趣,但我们没有具体说明它是何物。在历史上,研究人员探索过几种不同的AI版本。一些人将智能定义为对人类行为 (human performance)的忠实度(fidelity),而另一些人则倾向于使用一种抽象的、规范化的智能定义,称为理性 (rationality)------通俗地说,就是做"正确的事情" 。理性本身也存在不同的解读:一些人认为智能是内部思考过程和推理的属性,而另一些人则关注智能行为,一种外部特征。(注:在公众眼中,人们有时会将"人工智能"和"机器学习"这两个术语混淆。机器学习是 AI的一个子领域,它研究的是基于经验提升性能的能力。一些 AI系统使用机器学习方法来提升能力,而另一些则不使用。)
从这两个维度------人性(human)与理性(rational)以及思维(thought)与行为(behavior)------出发(注:我们并非暗示人类在字典意义上是"非理性的(irrational)",即"缺乏正常的思维清晰度"。我们只是承认,人类的决策并非总是数学上完美的),存在四种可能的组合,并且每种组合都有其拥护者和研究项目。所使用的方法必然不同:对类人智能的追求必须部分地成为一门与心理学相关的实证科学,涉及对实际人类行为和思维过程的观察和假设;而理性主义方法则结合了数学和工程学,并与统计学、控制论和经济学相联系。各个群体之间既有相互贬损,也有相互帮助。让我们来更详细地了解这四种方法。
1.1.1 以人为本: Turingˈtjʊərɪŋ测试法( Acting humanly: The Turing test approach**)**
Turing测试由Alan Turing于1950年提出,旨在通过思想实验来规避"机器能否思考?"这一哲学问题的模糊性。如果人类提问者在提出一些书面问题后,无法判断书面回答是出自人还是计算机,则该计算机通过了测试。第28章将详细讨论该测试,以及通过测试的计算机是否真的具备智能。目前,我们注意到,编写程序使计算机通过严格的测试本身就有很多值得研究的地方。计算机需要具备以下能力:
● 自然语言处理(natural language processing):用于成功地用人类语言进行交流;
● 知识表示(knowledge representation):用于存储已知或听到的内容;
● 自动推理(automated reasoning):用于回答问题并得出新的结论;
● 机器学习(machine learning): 用于适应新情况并检测和推断模式。
Turing认为,要展示智能,对人进行物理层面的模拟并非必要。然而,其他研究人员提出了"完全Turing测试"( Total Turing Test),该测试要求与现实世界中的物体及人类进行交互。若要通过完全Turing测试,机器人将需要:
● 利用计算机视觉( computer vision**)** 和语音识别来感知世界**;**
● 用于操控物体和移动的机器人技术(robotics)。
这六大领域构成了AI的主要部分。然而,AI研究人员在通过Turing测试上投入的精力却寥寥无几,因为他们认为,探究智能的底层原理更为重要。人类对"人造飞行"的探索之所以取得成功 ,正是因为工程师和发明家们不再单纯模仿鸟类,转而利用风洞并研究空气动力学。航空工程领域的著作从未将该领域的目标定义为制造出"飞行姿态与鸽子别无二致、甚至能骗过其他鸽子的机器"。
1.1.2 似人思考:认知建模法( Thinking humanly: The cognitive modeling approach**)**
要说一个程序像人类一样思考,我们必须了解人类是如何思考的。我们可以通过三种途径来了解人类的思维:
● 内省(introspection)(自我观察法)------试图捕捉流经脑海的思绪;
● 心理学实验(psychological experiments)------观察人的行为活动;
● 脑成像(brain imaging)------观察大脑的活动状态。
一旦我们拥有了关于心智(mind)的足够精确的理论,就有可能将该理论表述为计算机程序。如果该程序的输入输出行为与相应的人类行为相吻合,这就表明该程序中的某些机制也可能在人类身上发挥作用。
例如,开发了"通用问题求解器(General Problem Solver)"(GPS,Newell & Simon, 1961)的Allen Newell和Herbert Simon,并不满足于仅仅让程序正确地解决问题。他们更关注的是,将其推理步骤的顺序和时序与人类在解决相同问题时的表现进行比较。认知科学这一跨学科领域将AI中的计算机模型与心理学中的实验认知科学技术结合起来,旨在构建关于人类心智的精确且可验证的理论。
认知科学本身就是一个引人入胜的领域,足以支撑多部教科书和至少一部百科全书(Wilson 和 Keil,1999)。我们将不时探讨AI技术与人类认知之间的异同。然而,真正的认知科学必然建立在针对真实人类或动物的实验研究之上。我们将把这部分内容留给其他书籍,因为我们假定读者仅拥有一台计算机用于实验。
在AI发展的早期,人们往往混淆了不同的研究路径。当时,研究者常认为某种算法若能出色完成某项任务,便可作为人类认知表现的良好模型,反之亦然。如今,研究者已将这两类主张区分开来;这种区分促进了AI与认知科学的快速发展。这两个领域相互促进,在计算机视觉领域尤为显著------该领域将神经生理学证据融入了计算模型之中。近年来,神经影像技术与用于分析此类数据的机器学习技术相结合,已初步实现了"读心(read minds)"能力,即能够解读个体内心想法所蕴含的语义内容。反过来,这种能力也有助于我们进一步揭示人类认知的运作机制。
1.1.3 理性思考:"思考法则"法( Thinking rationally: The "laws of thought" approach**)**
古希腊哲学家Aristotle是最早试图将"正确的思考"------即无懈可击的推理过程------加以系统化的人之一。他的三段论 (syllogisms)为论证结构提供了范式,只要前提正确,便总能得出正确的结论。一个经典的例子是:从"Socrates是人"和"所有人都会死"这两个前提出发,得出"Socrates会死"的结论。(这个例子很可能出自Sextus Empiricus,而非Aristotle本人。)这些思考法则被认为支配着心智的运作;对它们的研究开创了逻辑学这一学科。
19世纪的逻辑学家们发展出一套精确的符号系统,用于描述世界中的对象及其相互关系。( 这与普通的算术符号形成对比,后者仅用于描述数字。) 到1965年,程序原则上可以解决任何用逻辑符号描述的可解问题。所谓AI领域的逻辑主义者希望以此为基础,构建智能系统,并传承所谓的逻辑主义传统。
按常规理解,逻辑需要关于世界的确定性知识------而这一条件在现实中往往难以满足。我们对政治或战争规则的了解,远不像对国际象棋或算术规则那样确切。**概率论填补了这一空白,使我们能够基于不确定信息进行严谨的推理。**它支持构建一个全面的理性思考模型,涵盖了从原始感知信息到理解世界运作机制,再到预测未来的全过程。然而,它无法直接产生智能行为;要实现这一点,我们需要一套关于理性行动的理论。仅靠理性思考是不够的。
1.1.4 理性行动:理性智体法( Acting rationally: The rational agent approach**)**
" 智能体"( agent ) 本质上就是能够采取行动的事物 (该词源自拉丁语 agere,意为"执行行为(do)")。当然,所有计算机程序都会执行某种操作,但计算机智能体被期望能做到更多:自主运行、感知环境、长期持续运行、适应变化,以及设定并追求目标。所谓"理性智能体",是指能够采取行动以实现最佳结果------或者在存在不确定性的情况下实现最佳预期结果------的智能体。
在AI研究的"思考法则"途径中,重点在于正确的推理。进行正确的推理有时是作为理性智能体(rational agent)的一个组成部分,因为理性行动的一种方式是推断出某项行动为最佳,并据此采取行动。在另一方面,也存在着并不涉及推理的理性行动方式。例如,因接触热炉而本能地缩回手便是一种反射动作,而这种反应通常比经过深思熟虑后采取的较慢行动更为有效。
通过Turing测试所需的各项能力,同时也赋予了智能体进行理性行动的能力。知识表示与推理使智能体能够做出明智的决策。我们需要能够生成通俗易懂的自然语言句子,以便在复杂的社会环境中应对自如。我们之所以需要学习,不仅是为了增长见识,更是因为它能提升我们采取有效行动的能力------尤其是在面对新情况时。
与其他方法相比,AI的"理性智能体"方法具有两大优势。首先,它比"思考法则"方法更具普适性,因为正确的推理仅仅是实现理性的多种可能机制之一。其次,它更有利于科学层面的发展。理性的标准在数学上定义明确且具有完全的普适性。我们往往可以根据这一规范进行反向推导,从而设计出能够被证明符合该标准的智能体------而如果目标是模仿人类行为或思考过程,这一点则几乎无法实现。
正因如此,基于"理性智能体"的方法在 AI 领域的大部分发展历程中一直占据主导地位。 在早期阶段,理性智能体构建于逻辑基础之上,通过制定明确的计划来实现特定目标。随后,基于概率论和机器学习的方法使得智能体能够在不确定性条件下做出决策,从而获得最佳的预期结果 。简言之, AI 的研究重点在于构建能够"做正确之事"的智能体;而何为"正确之事",则由我们为智能体设定的目标来定义 。这种通用范式应用极其广泛,甚至可以称为"标准模型"。它不仅主导了 AI 领域,还广泛存在于其他学科中:例如控制理论(控制器旨在最小化代价函数)、运筹学(策略旨在最大化奖励总和)、统计学(决策规则旨在最小化损失函数)以及经济学(决策者旨在最大化效用或某种社会福利指标)。
我们需要对标准模型进行一项重要修正,以考虑到这样一个事实:在复杂环境中,完全理性(即始终采取绝对最优行动)是不可行的,因为其所需的计算量实在太大。第6章和第16章探讨了"有限理性"的问题------即在没有足够时间进行所有理想计算的情况下,如何采取恰当的行动。不过,对于理论分析而言,完全理性往往仍是一个很好的出发点。
1.1.5 益机( Beneficial machines**)**
自诞生以来,"标准模型"一直是AI研究的有益指导,但从长远来看,它恐怕并非恰当的模型。原因在于,该模型预设了我们会向机器提供一个完全明确的目标。
对于像国际象棋或最短路径计算这类人为设定的任务,其目标是内置于任务之中的,因此适用标准模型。然而,当我们进入现实世界时,要完整且准确地界定目标就变得愈发困难。以自动驾驶汽车的设计为例,人们可能会认为其目标是安全抵达目的地。但在任何道路上行驶,都难免因其他驾驶员违规操作、设备故障等因素而面临受伤风险;因此,若将"安全"作为绝对目标,唯一的选择就是让车一直停在车库里。在向目的地推进与承担受伤风险之间,存在着一种权衡。该如何进行这种权衡呢? 此外,在多大程度上允许汽车采取可能令其他驾驶员感到恼火的行动?为了避免让乘客感到颠簸不适,汽车又应在加速、转向和制动方面做出多大程度的克制?这类问题很难在事先做出定论。在人机交互这一广泛领域中------自动驾驶汽车仅是其中的一个例子------这些问题尤为棘手。
如何确保我们真实的偏好与输入机器的目标相一致,这一难题称为**"价值对齐问题"** (value alignment problem):即输入机器的价值或目标必须与人类的价值或目标保持一致。如果我们是在实验室或模拟环境中开发AI系统------这也是该领域发展历程中的常态------那么对于设定错误的目标,有一个简单的补救办法:重置系统,修正目标,然后重新尝试。然而,随着该领域不断发展,具备更强能力的智能系统开始在现实世界中部署,这种方法便不再可行了。一旦系统带着错误的目标投入运行,就会产生负面后果;而且,系统的智能程度越高,这些负面后果也就越严重。
让我们回到看似简单明了的国际象棋例子,试想一下:如果机器足够智能,能够跳出棋盘的局限进行推理和行动,会发生什么?在这种情况下,它可能会试图通过各种手段来增加胜算,例如催眠或勒索对手,或者贿赂观众,让观众在对手思考时制造噪音。 (注:在最早的几本国际象棋著作之一中,Ruy Lopez(1561年)写道:"摆放棋盘时,务必让阳光直射对手的眼睛。") 它甚至可能试图劫持额外的算力供自己使用。这些行为并非"不智能"或"疯狂";它们只是将"获胜"设定为机器唯一目标的逻辑必然结果。
对于一台致力于实现既定目标的机器,我们无法预料它可能出现的所有异常行为。因此,有充分理由认为"标准模型"存在缺陷。 我们需要的并非那种仅仅在"追求自身目标"意义上具备智能的机器,而是能够追求"我们的"目标的机器。如果无法将这些目标完美地传达给机器,我们就需要一种新的范式:在这种范式下,机器致力于实现我们的目标,但对于这些目标究竟是什么,它自身却处于不确定的状态。当机器意识到自己并不完全了解目标时,它便有了采取谨慎行动的动力------例如征求许可、通过观察来了解我们的偏好,以及服从人类的控制。归根结底,我们需要的是能够被证明对人类有益的智能体。我们将在第 1.5 节进一步探讨这一话题。
1.2 AI 之基础( The Foundations of Artificial Intelligence**)**
本节简要回顾了那些为AI贡献了思想、观点和技术的学科的发展历程。像任何历史叙述一样,本节的重点在于少数几位人物、事件和思想,而忽略了其他同样重要的内容。我们将这段历史的梳理围绕一系列问题展开。我们绝无意给人留下这样的印象:这些问题是相关学科所探讨的全部内容,或者这些学科一直以来都是以实现AI为最终目标而努力的。
1.2.1 哲学( Philosophy**)**
● 能否利用规范规则得出有效的结论?
● 心智是如何从物质大脑中产生的?
● 知识从何而来?
● 知识如何转化为行动?
Aristotle(公元前 384--322 年)是首位制定出一套精确法则来规范心智理性层面运作的人。他构建了一套用于正确推理的非正规化三段论体系;原则上,只要给定初始前提,利用该体系便能机械地推导出结论。
Ramon Llull(约公元1232--1315年)设计了一套推理系统,并将其发表为《大艺》(Ars Magna 或 The Great Art,1305年)。Llull试图利用一种实际的机械装置来实现这套系统:即一套可以通过旋转形成不同排列组合的纸质圆盘。
大约在1500年,Leonardo da Vinci(1452--1519)设计了一款机械计算器,尽管他并未将其制造出来;近期的复原研究表明,该设计确实具备实际运作功能。已知最早的计算机器是由德国科学家 Wilhelm Schickard (1592--1635) 于1623年前后制造的。Blaise Pascal(1623--1662)于1642年制造了"Pascal计算器"(Pascaline),并写道它"所产生的效应,看起来比动物的一切行为都更接近于思维活动"。Gottfried Wilhelm Leibniz(1646--1716)制造过一种机械装置,旨在对概念而非数字进行运算,但其适用范围相当有限。Thomas Hobbes(1588--1679)在其1651年出版的《Leviathan》一书中,提出了"思考机"------即他所谓的"人造动物"------这一构想,并论证道:"心脏不就是发条吗?神经不就是一根根琴弦吗?关节不就是一个个齿轮吗?"他还提出,推理过程类似于数值计算:"因为'理性'......无非就是'计算',也就是加法与减法。"
声称心智至少在某种程度上遵循逻辑或数值规则运作,并构建能够模拟其中部分规则的物理系统,这是一回事;而断言心智本身就是这样一个物理系统,则是另一回事。René Descartes(1596--1650)首次明确探讨了心智与物质之间的区别。他指出,若以纯粹物理的视角看待心智,似乎就很难为自由意志留出空间。如果心智完全受物理定律支配,那么它所拥有的自由意志,便并不比一块"决定"向下坠落的石头更多。Descartes 是二元论(dualism)的倡导者。他主张,人类心智(或称灵魂、精神)中存在着一部分超脱于自然之外、不受物理定律约束的成分。相比之下,动物则不具备这种二元特性;它们可以视为机器。
二元论的另一种选择是唯物论,该理论认为,大脑遵循物理定律的运作构成了心智。自由意志仅仅是做出选择的主体感知到可用选项时所呈现的一种形式。"物理主义"和"自然主义"这两个术语也常用于描述这一与超自然相对立的观点。
既然存在一个能够驾驭知识的物质性心灵,接下来的问题便是确立知识的经验主义来源。经验主义运动(empiricism movement)始于Francis Bacon's(1561--1626)的《新工具》(Novum Organum)(注:《新工具》是对 Aristotle《工具论》(Organon)(即思维工具(instrument of thought))的更新),其特征体现为John Locke(1632--1704)的一句名言:"凡在理智中的,无不先见于感官(Nothing is in the understanding, which was not first in the senses)。"
David Hume(1711--1776)在其著作《人性论》(A Treatise of Human Nature)(Hume, 1739)中提出了如今称为"归纳原则"的观点:即一般性规则是通过接触其构成要素之间反复出现的关联而习得的。
在Ludwig Wittgenstein(1889--1951)和Bertrand Russell(1872--1970)研究工作的基础上,著名的"Vienna学派"(Vienna Circle,Sigmund, 2017)------一个于20世纪20年代和30年代在Vienna聚会的哲学家与数学家团体------发展出了逻辑实证主义学说。该学说主张,所有知识都可以通过逻辑理论来表征,而这些理论最终与对应于感官输入的"观察命题(observation sentences)"相联系;因此,逻辑实证主义结合了理性主义与经验主义。
Rudolf Carnap(1891--1970)与Carl Hempel(1905--1997)提出的证实理论,试图通过量化逻辑命题的"信念度"来分析人类如何从经验中获取知识;这种信念度取决于命题与证实或证伪它们的观察结果之间的联系。Carnap 的著作《世界的逻辑构造》( The Logical Structure of the World )(1928 年)或许是关于"心智即计算过程"这一理论的最早尝试。
关于心智的哲学图景,其最后一个要素是知识与行动之间的联系。这一问题对AI至关重要,因为智能不仅需要推理,还需要行动。此外,只有理解了行动如何获得正当性,我们才能明白如何构建一个其行动具有正当性(或理性)的智能体。
Aristotle(在《论动物的运动》(De Motu Animalium)中)提出,行动的合理性在于目标与对行动结果的认知之间存在逻辑联系:
那么,为什么思考有时伴随着行动,有时则不然;有时伴随着身体动作,有时则不然呢?这看起来与针对不变对象进行推理和推论时的情况几乎相同。但在那种情况下,终点是一个理论命题......而在此处,由两个前提得出的结论却是一种行动。......我需要遮盖物;斗篷是遮盖物。我需要一件斗篷。我必须制造我所需要的东西;我需要一件斗篷。我必须制造一件斗篷。于是,那个结论------即"我必须制造一件斗篷"------便是一种行动。
在《Nicomachus伦理学》(Nicomachean Ethics)(第III卷第3章,1112b)中,Aristotle进一步阐述了这一议题,并提出了一种算法:
我们所权衡的并非目的,而是手段。因为医生不会权衡是否要治愈病人,演说家也不会权衡是否要说服听众......他们预设了目的,转而考量如何实现它以及采取何种手段,并评估该手段是否能以最简便、最理想的方式达成目标;若只有一种实现途径,他们便会探究如何通过该途径达成,以及如何落实这一途径,直至追溯到最初的起因......分析过程中的最后一步,往往对应着实际生成过程中的第一步。一旦发现无法实现(例如急需资金却无法筹措),我们便会放弃探求;反之,若某事看似可行,我们便会着手尝试。
Aristotle的算法在2300年后由Newell和Simon在他们的"通用问题求解器"(General Problem Solver)程序中得以实现。如今,我们会将其称为一种贪婪回归规划系统(参见第11章)。在AI理论研究的最初几十年里,基于逻辑规划以实现明确目标的各种方法占据了主导地位。
单纯从"通过行动实现目标"的角度进行思考往往很有用,但有时并不适用。例如,如果存在多种实现目标的方式,就需要某种方法在其中做出选择。更重要的是,有时无法确切保证能实现目标,但仍必须采取行动。那么,该如何决策呢?Antoine Arnauld(1662年)在分析博弈中的理性决策概念时,提出了一种旨在最大化结果预期货币价值的定量公式。后来,Daniel Bernoulli(1738年)引入了更具普遍性的"效用"概念,用以衡量结果的内在主观价值。正如第15章所述,现代关于不确定性条件下的理性决策概念,涉及的是预期效用的最大化。
在伦理与公共政策领域,决策者必须考量多方个体的利益。Jeremy Bentham(1823年)和John Stuart Mill(1863年)倡导了功利主义思想 (utilitarianism:):即基于效用最大化的理性决策应当适用于人类活动的所有领域,包括代表众多群体所作出的公共政策决策。功利主义是后果论(consequentialism)的一种具体形式,该理论主张行为的是非对错取决于其预期结果。
相比之下,Immanuel Kant在1785年提出了一种基于规则的伦理学理论(即义务论伦理学)(deontological ethics)。在该理论中,"做正确的事"并非取决于行为后果,而是取决于规范正当行为的普遍社会法则------例如"不可撒谎"或"不可杀人"。因此,功利主义者可能会为了追求"利大于弊"的结果而说善意的谎言,但康德主义者则绝不会这样做,因为撒谎本身就是错误的。John Stuart Mill虽然认可规则的价值,但他将规则理解为一种高效的决策程序,而这些程序是基于对后果进行"第一性原理"推理后总结得出的。许多现代AI系统正是采用了这种方法。
1.2.2 数学( Mathematics**)**
● 得出有效结论的正式规则有哪些?
● 哪些问题是可计算的?
● 我们如何基于不确定信息进行推理?
哲学家们确立了AI的一些基本理念,但要实现向一门正式科学的跨越,则需要将逻辑与概率数学化,并引入一个新的数学分支------计算。
形式逻辑 (formal logic)的思想可以追溯到古希腊、印度和中国的哲学家 ,但其数学层面的发展实际上始于George Boole(1815--1864)的工作,他阐明了命题逻辑(即Boole逻辑)的细节(Boole, 1847)。1879年, Gottlob Frege (1848--1925) 将 Boole 逻辑扩展至包括对象与关系,从而创立了当今广泛使用的一阶逻辑(注: Frege's提出的一阶逻辑符号------文本和几何特征的神秘组合------从未流行过**)**。一阶逻辑不仅在AI研究的早期阶段发挥了核心作用,还推动了Gödel和Turing的研究工作------正如后文所述,这些工作构成了计算本身的基石。
概率论可视为逻辑在信息不确定情况下的推广------这对 AI 而言至关重要。 Gerolamo Cardano(1501--1576)最早构想了概率的概念 ,并将其描述为博弈事件中各种可能结果的体现 。1654年,Blaise Pascal(1623--1662)在致Pierre Fermat(1601--1665)的一封信中,阐述了如何预测一场未完成博弈的后续走向,并据此计算参与者的预期收益。概率论迅速成为定量科学中不可或缺的一部分,有助于处理不确定的测量结果和不完备的理论。Jacob Bernoulli(1654--1705,Daniel的叔叔)、Pierre Laplace(1749--1827)等人进一步发展了该理论,并引入了新的统计方法。Thomas Bayes (1702--1761) 提出了一项根据新证据更新概率的法则; Bayes 法则已成为 AI 系统中的一项关键工具。
**概率论的数学规范化与数据的可获取性相结合,促成了统计学这一学科的诞生。**其早期应用之一是John Graunt于1662年对伦敦人口普查数据进行的分析。Ronald Fisher被公认为第一位现代统计学家(Fisher, 1922)。他将概率、实验设计、数据分析和计算等领域的理念融会贯通------例如,1919年时,尽管"MILLIONAIRE"这款机械计算器(这是首款具备乘法运算功能的计算器)的价格超过了他的年薪,他仍坚持认为没有它便无法开展工作(Ross, 2012)。
算法 (algorithm)的历史与数字的历史同样悠久,但人们普遍认为,第一个具有实质意义的算法是用于计算最大公约数的Euclid算法。"算法"(algorithm)一词源自9世纪数学家Muhammad ibn Musa al-Khwarizmi,他的著作还将阿拉伯数字和代数引入了欧洲。Boole等人探讨了用于逻辑推演的算法;到了19世纪末,人们已开始致力于将一般的数学推理规范化为逻辑推演。
Kurt Gödel(1906--1978)证明了,对于Frege和Russell体系下的一阶逻辑,存在一种能证明其中任何真命题的有效程序;然而,一阶逻辑却无法涵盖刻画自然数所需的数学归纳法原理。1931年, Gödel 揭示了演绎推理确实存在局限性。他的不完备性定理表明,在任何强度至少相当于 Peano 算术( Peano arithmetic ,即关于自然数的基础理论)的形式理论中,必然存在一些真命题,这些命题在该理论内部无法得到证明。
这一基本结果也可以解读为:某些定义在整数上的函数无法用算法来表示------即,它们是不可计算的。这促使Alan Turing(1912--1954)试图精确界定哪些函数是可计算的(即能够通过有效过程进行计算)。"Church--Turing论题"(Church--Turing thesis)提出,将一般意义上的"可计算性"等同于Church--Turing机所能计算的函数(Turing, 1936)。Turing还证明了存在某些Turing机无法计算的函数。例如,对于给定的程序和输入,没有任何机器能够普遍判定该程序最终会给出结果,还是会无限运行下去。
尽管可计算性对于理解计算至关重要,但**"易解性"** (tractability)这一概念对AI的影响更为深远。概括而言,如果求解某类问题实例所需的时间随实例规模呈指数级增长,则称该问题为"难解问题"( intractable)。复杂度在多项式增长与指数增长之间的区别,最早是在20世纪60年代中期被明确提出的(Cobham, 1964; Edmonds, 1965)。这一区分之所以重要,是因为指数级增长意味着,即使是规模适中的实例,也无法在合理的时间内求解。
由 Cook (1971 年)和 Karp (1972 年)开创的 NP 完全性理论,为分析问题的可解性(即是否易于求解)奠定了基础:任何能归约到NP完全问题类的问题类,都很可能是难以求解的。 (尽管尚未从数学上证明NP完全问题必然难以求解,但大多数理论家都持此观点。) 这些结论与大众媒体在早期计算机问世时所表现出的乐观态度形成了鲜明对比------当时人们将计算机誉为"电子超级大脑",甚至称其"比Einstein还快"!尽管计算机的运算速度不断提升,但智能系统的特征仍将是资源的审慎利用以及某种程度上的"不完美" 。通俗地说,整个世界就是一个极其庞大的问题实例!
1.2.3 经济学( Economics**)**
● 我们应该如何根据自己的喜好做出决定?
● 当其他人可能不认同我们的做法时,我们应该如何做?
● 当收益可能要很久以后才能实现时,我们应该如何做?
经济学作为一门学科始于1776年,当时Adam Smith(1723--1790)出版了《国民财富的性质和原因的研究》(简称《国民财富论》)( An Inquiry into the Nature and Causes of the Wealth of Nations)。Smith提出,经济是由许多追求自身利益的个体行为主体构成的。然而,Smith并非将追求经济利益的贪婪视为一种道德立场:他在早先(1759年)的著作《道德情操论》(The Theory of Moral Sentiments)开篇便指出,关心他人的福祉是每一个人自身利益中不可或缺的一部分。
大多数人认为经济学是关于金钱的学科;事实上,针对不确定性条件下决策的首次数学分析------即Arnauld于1662年提出的"最大期望值"公式------确实探讨的是赌局的货币价值。Daniel Bernoulli在1738年指出,该公式在涉及大额资金(例如海上贸易探险投资)时似乎并不适用。为此,他提出了一项基于"最大化期望效用"的原则,并通过阐述"随着财富增加,新增货币量的边际效用会递减"这一观点,解释了人们的投资选择行为。
Léon Walras发音为"Valrasse"(1834--1910)为效用理论奠定了一个更具普遍性的基础,其依据是针对涉及任何结果(而不仅仅是货币结果)的博弈或赌局所持有的偏好。这一理论随后得到了Ramsey(1931)的改进,并由John von Neumann和Oskar Morgenstern在他们合著的《博弈论与经济行为》(The Theory of Games and Economic Behavior)(1944)一书中进一步完善。经济学不再仅仅是对金钱的研究,而是对欲望与偏好的研究。
决策论 (Decision theory)结合了概率论与效用论 (utility theory),为不确定性环境下的个体决策(无论是经济决策还是其他类型的决策)提供了一个规范化且完备的框架------即适用于那些可以用概率描述来恰当刻画决策者所处环境的情形。这种理论适用于"大型"经济体,其中每一个主体无需关注其他主体的具体行为。而在"小型"经济体中,情况更像是一场博弈 (game):一个参与者的行为可能会显著影响另一个参与者的效用(无论是正面还是负面影响)。Von Neumann和Morgenstern在发展博弈论(game theory)的过程中(另见 Luce 和 Raiffa,1957)得出了一个令人惊讶的结论:对于某些博弈,理性主体应当采取随机化的策略(或者至少看起来是随机化的策略)。与决策论不同,博弈论并未就如何选择行动提供明确的指导方针。在AI领域,涉及多个主体的决策问题是在多智能体系统(第 17 章)这一框架下进行研究的。
除少数例外,经济学家并未探讨上述第三个问题:**当行动的收益并非立即可见,而是源于一系列先后采取的行动时,应如何做出理性决策。**这一课题在运筹学领域得到了深入研究;运筹学起源于二战期间英国为优化雷达部署所开展的工作,后来在民用领域获得了广泛应用。Richard Bellman(1957年)的工作将一类称为"Markov决策过程"的序贯决策问题进行了规范化定义;我们将在第16章,以及第23章(在强化学习的框架下)对这一问题进行探讨。
经济学和运筹学领域的研究极大地丰富了我们对"理性智体"(rational agents)的理解,然而多年来, AI的研究却沿着截然不同的路径发展。造成这种状况的一个原因,在于做出理性决策往往涉及极高的复杂性。AI先驱Herbert Simon(1916--2001)因其关于"满意"(satisficing)的早期研究而荣获1978年Nobel经济学奖;该研究表明,基于"满意"原则的模型------即做出"足够好"的决策,而非费力计算最优决策------能更准确地描述人类的实际行为(Simon, 1947)。自20世纪90年代以来,人们对应用于AI的决策理论技术重新产生了浓厚兴趣。
1.2.4 神经科学( Neuroscience**)**
● 大脑如何处理信息?
神经科学是对神经系统(尤其是大脑)的研究。尽管大脑产生思维的具体机制仍是科学界的一大未解之谜,但人们早在几千年前就已认识到大脑具有产生思维的功能------这主要源于人们观察到头部遭受重创会导致精神功能丧失。人们很早就意识到人类大脑具有某种独特性;早在公元前335年左右,Aristotle就曾写道:"在所有动物中,就体型比例而言,人类拥有最大的大脑。"(注:后来发现树鼩(qú)和一些鸟类的大脑/身体比例超过了人类)然而,直到18世纪中叶,大脑才被广泛公认为意识的所在地。在此之前,人们曾推测意识可能存在于心脏或脾脏等部位。
1861年,Paul Broca(1824--1880)对脑损伤患者失语症(言语功能障碍)的研究,标志着对大脑功能组织结构研究的开端;他发现左半球存在一个负责言语生成的局部区域------如今称为"Broca区"(Broca's area)(注:许多人将Alexander Hood(1824年)视为可能的早期来源)。当时,人们已知大脑主要由神经细胞(即神经元)构成,但直到1873年,Camillo Golgi(1843--1926)才开发出一种能够观察单个神经元的染色技术(见图1.1)。Santiago Ramón y Cajal(1852--1934)在其关于神经元组织结构的开创性研究中运用了这一技术(注:Golgi坚持认为大脑的功能主要是在神经元所嵌入的连续介质中实现的,而Cajal则提出了"神经元学说"。两人于1906年共同获得Nobel奖,但在领奖演说中却针锋相对)。如今,人们普遍认为认知功能源于这些结构内部的电化学活动;换言之,由简单的细胞构成的系统能够产生思维、行为和意识 。正如John Searle(1992)言简意赅地指出的那样:大脑产生了心智。
目前,我们已掌握了一些关于大脑区域与受其控制或向其输送感觉信号的身体部位之间映射关系的数据。此类映射关系可在短短数周内发生剧烈变化,且某些动物似乎拥有多重映射。此外,对于当某一大脑区域受损时其他区域如何接管其功能,我们尚无充分的了解 ;而在单个记忆如何存储或更高级的认知功能如何运作方面,也几乎没有任何相关理论。
对完整大脑活动的测量始于1929年Hans Berger发明脑电图仪(EEG)之时。功能性磁共振成像(fMRI)技术的发展(Ogawa等,1990;Cabeza和Nyberg,2001)为神经科学家提供了前所未有的、细节丰富的大脑活动图像,使得人们能够进行与正在进行的认知过程以有趣方式相对应的测量。此外,神经元活动的单细胞电记录技术的进步以及光遗传学方法(Crick,1999;Zemelman等,2002;Han和Boyden,2007)的出现,进一步丰富了这些研究手段;光遗传学技术不仅能测量,还能控制那些经过改造而具有光敏特性的单个神经元。
脑机接口(brain-machine interfaces)(Lebedev 和 Nicolelis,2006)的开发,无论是用于脑机接口感知还是运动控制,不仅有望帮助残疾人士恢复功能,而且还有助于我们了解神经系统的诸多方面。这项研究的一项重要发现是,大脑能够自我调节,从而成功地与外部设备连接,实际上将其视为另一个感觉器官或肢体。
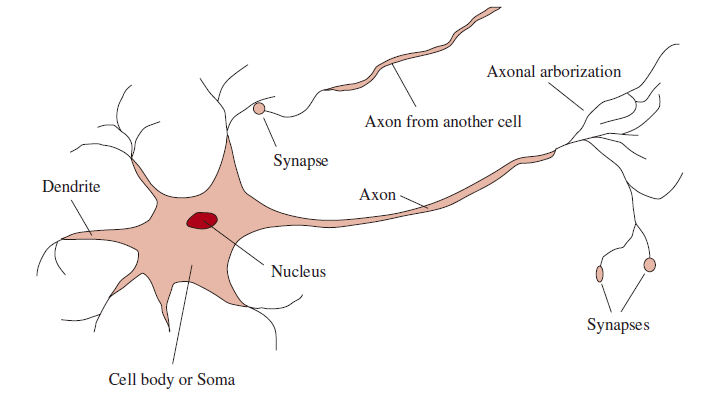
说明:
Dendrite ------ 树突
Synapse ------ 突触
Axon from another cell ------ 来自另一个细胞的触突
Axonal arborization ------ 轴突树状分支
Axon ------ 轴突
Nucleus ------ 核
Cell body or Soma ------ 胞体
Synapses ------ 突触
-------------------------图 1.1:神经细胞(即神经元)的构成部分。每个神经元都包含一个胞体(soma),其中含有细胞核。从胞体向外延伸出若干被称为"树突"的纤维,以及一根称为"轴突"的长纤维。轴突的延伸距离很长,远超本示意图中的比例所示。通常,轴突长度为1厘米(约为胞体直径的100倍),但最长可达1米。神经元通过称为"突触"的连接点,与其他10到100,000个神经元建立联系。信号通过复杂的电化学反应在神经元之间传递。这些信号既能短期调控大脑活动,也能促成神经元连接方式的长期改变;人们认为,这些机制构成了大脑学习活动的基础。绝大多数信息处理过程发生在大脑皮层(即大脑的最外层)。其基本组织单元似乎是一种直径约0.5毫米的组织柱,包含约20,000个神经元,并贯穿皮层的整个深度(在人类大脑中约为4毫米)。-------------------------
人脑与数字计算机的特性存在一定差异。图1.2显示,计算机的周期时间比人脑快一百万倍。不过,人脑通过远超高端个人电脑的存储容量和互连规模弥补了这一差距------尽管最强大的超级计算机在某些指标上已能与人脑匹敌。未来学家们高度重视这些数据,并指出"奇点( singularities**)**"即将来临:届时,计算机的性能将达到超越人类的水平(Vinge, 1993; Kurzweil, 2005; Doctorow and Stross, 2012),并在此基础上实现自我快速迭代与提升。然而,单纯比较这些原始数据并无太大意义。即便拥有一台容量近乎无限的计算机,我们在理解智能方面仍需取得进一步的概念性突破(见第29章)。简言之,若缺乏正确的理论,更快的机器只会让你更快地得出错误的答案。

说明:
Cycle time ------ 周期时间
----------------------图 1.2:对顶尖超级计算机 Summit(Feldman, 2017)、2019 年的典型个人计算机以及人脑进行的一项粗略比较。数千年来,人脑的算力并无显著变化;相比之下,超级计算机的性能却突飞猛进:从 20 世纪 60 年代的每秒百万次浮点运算(megaFLOPs),发展到 80 年代的每秒十亿次(gigaFLOPs)、90 年代的每秒万亿次(teraFLOPs)、2008 年的每秒千万亿次(petaFLOPs),直至 2018 年达到每秒百亿亿次(exaFLOPs,即 1 exaFLOP = 每秒 次浮点运算)。--------------
1.2.5 心理学( Psychology**)**
● 人类和动物如何思考与行动?
科学的心理学的起源通常追溯至德国物理学家Hermann von Helmholtz(1821--1894)及其学生Wilhelm Wundt(1832--1920)的工作。Helmholtz将科学方法应用于人类视觉的研究,其著作《生理光学手册》(Handbook of Physiological Optics)被誉为"关于人类视觉物理学与生理学最重要的专著"(Nalwa, 1993, 第15页 )。1879年,Wundt在Leipzig大学建立了世界上第一个实验心理学实验室。Wundt坚持采用严格控制的实验方法:在实验中,参与者需执行知觉或联想任务,同时对自身的思维过程进行内省(introspection)。这种严格的控制在推动心理学成为一门科学方面发挥了重要作用,但由于所得数据具有主观性,实验者几乎不可能通过实验证伪自己的理论。
在另一方面,研究动物行为的生物学家因缺乏内省数据,从而发展出一种客观的研究方法; H. S. Jennings在其1906年具有影响力的著作《低等生物的行为》( Behavior of the Lower Organisms)中对此进行了阐述。以John Watson(1878--1958)为首的行为主义运动将这一观点应用于人类研究,并因内省法无法提供可靠证据为由,摒弃了任何涉及心理过程的理论。行为主义者坚持只研究客观可测量的变量:即施加于动物的感知(或刺激)以及动物随之产生的动作(或反应)。尽管行为主义在研究大鼠和鸽子方面取得了丰硕成果,但在理解人类方面却成效有限。
将大脑视为信息处理装置的认知心理学 (cognitive psychology),其渊源至少可以追溯到William James(1842--1910)的著作。Helmholtz也坚持认为,知觉涉及某种形式的无意识逻辑推理。在美国,认知观点曾一度被行为主义掩盖,但在Frederic Bartlett(1886--1969)领导的剑桥大学应用心理学研究室(Applied Psychology Unit),认知建模研究却得以蓬勃发展。Bartlett的学生兼继任者Kenneth Craik于1943年发表的《解释的本质》(The Nature of Explanation)一书,有力地恢复了"信念"和"目标"等"心理"术语的合法性;他论证道,这些术语与用压力和温度来描述气体一样具有科学性------尽管气体本身是由既无压力也无温度属性的分子构成的。
Craik明确了基于知识的智能体运作的三个关键步骤:(1) 必须将刺激转化为内部表征;(2) 认知过程对该表征进行操作,从而推导出新的内部表征;(3) 随后将这些表征重新转化为行动。他清晰地阐述了为何这种设计对于智能体而言是优秀的:
如果生物体在其头脑中构建了外部现实及其自身可能采取的行动的"小比例模型",它便能够尝试各种备选方案并从中选出最佳方案,在未来情境发生之前就做出反应,利用过往经验来应对当下与未来,从而以更全面、更安全、更胜任的方式应对其面临的各种紧急情况。(Craik, 1943)
1945年Craik因自行车事故去世后,Donald Broadbent接手并延续了他的研究工作;Broadbent所著的《知觉与交流》(Perception and Communication,1958年)是最早将心理现象建模为信息处理过程的著作之一。与此同时,在美国,计算机建模技术的发展促成了认知科学这一学科的诞生。该学科的开端通常被认为可以追溯到1956年9月在麻省理工学院(MIT)举行的一次研讨会------而就在仅仅两个月前, AI这一领域才刚刚宣告"诞生"。
在这次研讨会上,George Miller发表了《神奇的数字七》( The Magic Number Seven),Noam Chomsky发表了《语言的三种模型》(Three Models of Language),Allen Newell和Herbert Simon则发表了《逻辑理论机》(The Logic Theory Machine)。这三篇具有深远影响的论文展示了如何利用计算机模型分别探讨记忆、语言和逻辑思维等心理学课题。如今,心理学界普遍(尽管并非绝对一致)持有一种观点,即"认知理论应当像计算机程序一样"(Anderson, 1980);换言之,认知理论应以信息加工的方式来描述某种认知功能的运作过程。
在本综述中,我们将人机交互(HCI)领域归入心理学范畴。作为人机交互领域的先驱之一, Doug Engelbart大力倡导"智能增强"(Intelligence Augmentation,简称 IA,而非 AI)的理念。他主张计算机应当增强人类的能力,而非仅仅实现任务自动化以取代人类工作。1968年,Engelbart在被称为"演示之母"(the mother of all demos)的著名演示中,首次展示了计算机鼠标、窗口系统、超文本以及视频会议技术------所有这些展示旨在呈现人类知识工作者在智能增强技术的辅助下,能够共同实现怎样的成就。
如今,我们更倾向于将 IA ( 智能增强)和 AI ( 人工智能)视为同一事物的两个方面:前者侧重于人类的掌控,后者则侧重于机器表现出的智能行为。要使机器真正服务于人类,两者缺一不可。
1.2.6 计算机工程( Computer engineering**)**
**●**我们如何构建一台高效的计算机?
现代数字电子计算机是由三个处于第二次世界大战交战状态国家的科学家独立且几乎同时发明的。第一台投入使用的计算机是机电式的"Heath Robinson"机(注:一台以某位英国漫画家名字命名的复杂机器;这位漫画家笔下常描绘出各种异想天开、复杂得荒谬的装置,用于完成涂抹吐司黄油之类的日常琐事),由Alan Turing的团队于1943年建造,其唯一目的是破译德国的加密信息。1943年,同一团队又开发出了"巨人"(Colossus)机,这是一台基于真空管的强大通用计算机(注:战后,Turing希望利用这些计算机进行AI研究------例如,他构思了最早的国际象棋程序(Turing 等, 1953)------但英国政府阻挠了这项研究)。第一台投入使用的可编程计算机是Z-3,由德国人Konrad Zuse于1941年发明。Zuse还发明了浮点数以及第一种高级编程语言------Plankalkül。第一台电子计算机ABC(计算机)则是由John Atanasoff及其学生Clifford Berry于1940年至1942年间在爱荷华州立大学组装完成的。Atanasoff的研究并未获得多少支持或认可;真正成为现代计算机最具影响力先驱的,是ENIAC(电子数值积分计算机)------它是由包括John Mauchly和J. Presper Eckert在内的团队在宾夕法尼亚大学作为一项秘密军事项目的一部分而开发出来的。
自那时起,每一代计算机硬件都在速度和容量上实现了提升,同时价格不断下降------这一趋势概括为"摩尔定律"。在2005年左右之前,性能大约每18个月翻一番;此后,由于功耗问题的限制,制造商转而增加CPU核心数量,而非继续提高时钟频率。目前的普遍预期是,未来功能的提升将主要源于大规模并行处理------这与人脑的运作特性形成了一种奇妙的契合。此外,新的硬件设计理念也应运而生:在应对充满不确定性的现实世界时,我们并不需要64位精度的数值;仅需16位(如bfloat16格式)甚至8位精度便已足够,且能实现更快的处理速度。
我们才刚刚开始看到专为AI应用优化的硬件,例如图形处理单元(GPU)、张量处理单元(TPU)和晶圆级引擎(WSE)。从20世纪60年代到2012年左右,用于训练顶级机器学习应用的算力增长遵循摩尔定律。然而,2012年情况发生了变化:从2012年到2018年,算力增长了30万倍,相当于每100天左右就翻一番(Amodei 和 Hernandez,2018)。一个在2014年需要整整一天才能完成训练的机器学习模型,到了2018年仅需两分钟即可完成(Ying 等人,2018)。尽管目前尚不具备实用性,但量子计算有望为某些重要类别的AI算法带来更大幅度的加速。
当然,在电子计算机出现之前,就已经有了计算装置。本书第24页曾讨论过最早的自动化机器,它们可追溯至17世纪。第一台可编程机器是一台织布机,由Joseph Marie Jacquard(1752--1834)于1805年发明;该机器利用穿孔卡片来存储编织图案所需的指令。
19世纪中叶,Charles Babbage(1792--1871)设计了两款计算机器,但均未最终建成。"差分机"(Difference Engine)旨在为工程和科学项目计算数学用表;它最终于1991年被制造出来并成功运行(Swade, 2000)。Babbage设计的"分析机"(Analytical Engine)则更为宏大:它具备可寻址存储器、基于雅卡尔穿孔卡片的存储程序功能以及条件跳转功能。它是第一台具备通用计算能力的机器。
Babbage的同事Ada Lovelace(诗人Byron勋爵之女)洞察了该机器的潜力,将其描述为一台"会思考的......或会推理的机器",能够对"宇宙间万事万物"进行推理(Lovelace, 1843)。她还预见到了AI领域可能出现的炒作周期,并写道:"应当警惕人们对分析机能力的夸大其词。"遗憾的是,Babbage的机器和Lovelace的思想在很大程度上被人们遗忘了。
AI的发展也得益于计算机科学中的软件领域,该领域提供了编写现代程序(以及相关论文)所需的操作系统、编程语言和工具。不过,这也是一个"债务"已获偿还的领域:AI领域的研究开创了许多理念,这些理念随后反哺了主流计算机科学,其中包括分时系统、交互式解释器、配备窗口和鼠标的个人计算机、快速开发环境、链表数据类型、自动存储管理,以及符号式、函数式、声明式和面向对象编程的关键概念。
1.2.7 控制理论与控制论( Control theory and cybernetics**)**
● 人造物如何能够自主运作?
亚历山大城(Alexandria)的Ktesibios(约公元前250年)制造了第一台具有自动控制功能的机器:一种配备了能保持恒定流速调节装置的水钟。这项发明改变了人们对人造装置功能潜力的定义;在此之前,只有生物体才能根据环境变化调整自身的行为。其他自动调节反馈控制系统的例子包括James Watt(1736--1819)发明的蒸汽机调速器,以及Cornelis Drebbel(1572--1633)发明的恒温器(Drebbel也是潜水艇的发明者)。James Clerk Maxwell(1868年)开创了控制系统的数学理论。
Norbert Wiener(1894--1964)是战后控制理论发展史上的核心人物。Wiener是一位才华横溢的数学家,在对生物与机械控制系统及其与认知的联系产生兴趣之前,曾与Bertrand Russell等人共事。正如Craik(他也曾将控制系统作为心理学模型)一样,Wiener及其同事Arturo Rosenblueth和Julian Bigelow对当时占主导地位的行为主义正统观念提出了挑战(Rosenblueth 等, 1943)。他们认为,目的性行为源于一种旨在最小化"误差"(即当前状态与目标状态之间的差异)的调节机制。20世纪40年代末,Wiener与Warren McCulloch、Walter Pitts及约John von Neumann共同组织了一系列具有深远影响的会议,探讨了控制论(Cybernetics)以及认知的新型数学与计算模型。Wiener的著作《控制论》(1948年)不仅成为畅销书,更唤起了公众对AI机器可能性的关注。
与此同时,在英国,W. Ross Ashby也率先提出了类似的观点(Ashby, 1940)。Ashby、 Alan Turing、Grey Walter等人组建了"比率俱乐部"(Ratio Club),其成员包括那些"在Wiener的著作问世之前就已经有了Wiener式思想的人"。 Ashby在其著作《大脑的设计》( Design for a Brain,1948年、1952年)中进一步阐述了他的观点:即通过使用包含适当反馈回路的稳态装置(homeostatic devices)来实现稳定的适应性行为,从而创造出智能。
现代控制理论(control theory)(尤其是其中的随机最优控制分支)致力于设计能够使随时间推移的**"代价函数"** (cost function)最小化 的系统。这与AI的标准模型------即设计表现最优的系统------大致相符。既然AI与控制理论的奠基人之间联系密切,为何这两个领域却截然不同呢?答案在于:研究人员所熟悉的数学技术,与各自领域的世界观所涵盖的问题范畴之间,存在着紧密的耦合关系。微积分和矩阵代数是控制理论的工具,适用于描述那些由固定的一组连续变量构成的系统;而AI的创立,在某种程度上正是为了摆脱这些被视为局限性的束缚。逻辑推理和计算工具使AI研究人员能够探讨语言、视觉和符号规划等问题,而这些问题完全超出了控制理论家的研究范畴。
1.2.8 语言学( Linguistics**)**
● 语言与思维有何关联?
1957年, B. F. Skinner出版了《言语行为》(Verbal Behavior)一书。该书由这一领域的顶尖专家撰写,全面而详尽地阐述了语言习得的行为主义观点。然而颇为奇特的是,一篇针对该书的书评竟与原书一样声名大噪,甚至在很大程度上扼杀了人们对行为主义的兴趣。这篇书评的作者是语言学家Noam Chomsky,他当时刚刚出版了阐述自己理论的著作------《句法结构》( Syntactic Structures)。Chomsky指出,行为主义理论未能解释语言中的创造性------即儿童如何能够理解并造出他们从未听过的句子。相比之下,Chomsky的理论------建立在可追溯至古印度语言学家Panini(约公元前350年)的句法模型之上------则能对此做出解释;而且与以往的理论不同,该理论具有足够的严谨形式,原则上可以通过计算机程序来实现。
现代语言学与 AI**几乎在同一时期"诞生"并共同发展,最终在一个被称为"计算语言学"或"自然语言处理"的交叉领域汇合。**事实证明,理解语言这一问题远比1957年时人们预想的要复杂得多。理解语言不仅需要掌握句法结构,还需要理解相关的主题内容与语境。这一点看似显而易见,但在20世纪60年代之前,人们对此并未有广泛的认识。早期的知识表示研究(即探索如何将知识转化为计算机可用于推理的形式)很大程度上与语言相关,并深受语言学研究的启发;而语言学研究本身,又与数十年来关于语言的哲学分析工作有着紧密的联系。
1.3 AI 之历史( The History of Artificial Intelligence**)**
要快速概括 AI 发展史上的里程碑,列举 Turing 奖得主是一个很好的切入点:
Marvin Minsky(1969年)和John McCarthy(1971年),因确立了基于表征与推理的该领域基础而获奖; Allen Newell与Herbert Simon(1975年),因提出问题求解与人类认知的符号模型而获奖;Ed Feigenbaum与Raj Reddy(1994年),因开发出能够编码人类知识以解决现实世界问题的专家系统而获奖;Judea Pearl(2011年),因开发出能以原则性方式处理不确定性的概率推理技术而获奖;最后是Yoshua Bengio、Geoffrey Hinton和Yann LeCun(2019年),他们使"深度学习"(多层神经网络)成为现代计算的关键组成部分。本节余下部分将详细阐述AI发展史上的各个阶段。
1.3.1 AI的诞生( The inception of artificial intelligence**)(1943-1956)**
如今普遍被视为AI领域的开山之作,是由Warren McCulloch和Walter Pitts于1943年完成的。受Pitts的导师Nicolas Rashevsky(1936年、1938年)数学建模工作的启发,他们综合了三个方面的知识:关于大脑神经元基本生理与功能的知识、Russell与Whitehead提出的命题逻辑形式化分析,以及Turing的计算理论。他们提出了一种人工神经元模型,其中每个神经元的状态定义为"开启"(on)或"关闭"(off);当受到足够数量的邻近神经元刺激时,神经元便会切换至"开启"状态。神经元的状态被构想为"在事实上等同于一个表述其充分刺激条件的命题"。例如,他们证明了任何可计算函数均可通过某种互连的神经元网络进行计算,且所有的逻辑连接词(如"AND"、"OR"、"NOT"等)均能通过简单的网络结构来实现。McCulloch和Pitts还提出,经过适当定义的网络具备学习能力。Donald Hebb(1949年)展示了一种用于调整神经元间连接强度的简单更新规则。这一规则如今称为"Hebb学习"(Hebbian learning),至今仍是一个极具影响力的模型。
1950年,哈佛大学的两名本科生Marvin Minsky(1927--2016)和Dean Edmonds建造了第一台神经网络计算机。这台称为SNARC的机器使用了3000个真空管以及一个来自B-24轰炸机的闲置自动驾驶仪装置,以模拟一个包含40个神经元的网络。后来,Minsky在普林斯顿大学研究了神经网络中的通用计算问题。当时,负责评审他博士论文的委员会对这类研究是否应被归类为数学持怀疑态度,但据von Neumann曾对此评价道:"如果现在还不是,将来总有一天会是的。"
还有许多其他可归类为AI早期成果的例子,其中包括1952年由曼彻斯特大学的Christopher Strachey和IBM的Arthur Samuel各自独立开发的两个跳棋程序。然而, Alan Turing的构想最具影响力。他早在1947年就在伦敦数学学会就这一主题发表演讲,并在1950年发表的论文《计算机器与智能》(Computing Machinery and Intelligence)中阐述了一项极具说服力的研究议程。他在文中提出了Turing测试、机器学习、遗传算法和强化学习等概念。正如第28章所述,他还针对人们对AI可行性提出的诸多质疑一一进行了回应。此外,他提出,与其通过人工编程来赋予机器智能,不如通过开发学习算法并对机器进行"教导"来实现人类水平的AI,这样做会更容易。在随后的演讲中,他曾警示称,实现这一目标未必对人类有益。
1955 年,达特茅斯学院的John McCarthy说服了Minsky、Claude Shannon和
Nathaniel Rochester帮助他聚集了对自动机理论感兴趣的美国研究人员,神经网络和智力研究。他们在1956 年夏天的达特茅斯组织了为期两个月的研讨会。共有 10 名与会者,其中包括来自卡内基理工学院的Allen Newell和Herbert Simon(注:现为卡内基梅隆大学(CMU))、来自普林斯顿大学的 Trenchard More、Arthur Samuel 来自 IBM 的 Ray Solomonoff 和 来自麻省理工学院的Oliver Selfridge。提案中写道(注:这是 McCarthy 提出的" AI " 这一术语的首次正式使用。也许"计算理性"一词会更精确且不那么令人感到威胁,但"AI"这一说法最终沿用了下来。在达特茅斯会议五十周年之际,McCarthy表示,他当时之所以避免使用"计算机"或"计算"这类字眼,是出于对Norbert Wiener的尊重,因为Wiener当时大力推崇的是模拟控制论装置,而非数字计算机):
我们提议,于1956年夏季在新罕布什尔州汉诺威市的达特茅斯学院,开展一项为期两个月、由10人参与的AI研究。这项研究将基于这样一个假设:学习的各个方面或智能的任何其他特征,原则上都可以被精确地描述,从而使机器能够对其进行模拟。研究将探讨如何让机器使用语言、形成抽象概念、解决目前仅限于人类处理的问题,以及实现自我改进。我们认为,如果能组织一批精心挑选的科学家在夏季共同致力于这些课题,就有望在其中一个或多个问题上取得重大进展。
尽管有这种乐观的预测,达特茅斯(Dartmouth)研讨会并未带来任何突破性进展。Newell和Simon展示了当时或许最成熟的成果------一个名为"逻辑理论家"(Logic Theorist,简称 LT)的数学定理证明系统。Simon声称:"我们发明了一种能够进行非数值思维的计算机程序,从而解决了那个由来已久的'身心问题'。"(注:Newell和西蒙Simon还发明了一种名为 IPL 的表处理语言,用于编写 LT 程序。由于没有编译器,他们是手工将其转换为机器码的。为了避免出错,他们采取了并行工作的方式:在编写每条指令时,互相报出二进制数值,以确保彼此的记录完全一致。) 研讨会结束后不久,该程序便能够证明Russell与Whitehead所著《数学原理》( Principia Mathematica )第二章中的大部分定理。据说,当得知 LT 针对其中一个定理给出的证明比《数学原理》中的证明更为简练时,Russell感到非常高兴。《符号逻辑杂志》( Journal of Symbolic Logic )的编辑们却不以为然,他们拒收了一篇由Newell、Simon和"逻辑理论家"共同署名的论文。
1.3.2 初期热情,极高期望 ( The Early enthusiasm, great expectations**)(1952-1969)**
20世纪50年代的知识界普遍倾向于认为"机器永远无法做到X "。(参见第28章,其中列出了Turing收集的一长串X 。) AI研究人员自然而然地以展示一个又一个X来回应这种观点。他们尤其关注那些被认为能够体现人类智能的任务,包括游戏、谜题、数学和智商测试。John McCarthy将这一时期称为"看,妈,不用手!" 时代。
继 LT 取得成功之后Newell和Simon又开发了"通用问题求解器"(General Problem Solver,简称 GPS)。与 LT 不同,该程序从设计之初就旨在模拟人类解决问题的过程。在它所能处理的有限类别的难题中,程序考量子目标及可能行动的顺序,与人类处理同样问题时的思路惊人地相似。因此,GPS 很可能是第一个体现"像人一样思考"这一理念的程序。GPS 及其后续程序作为认知模型所取得的成功,促使Newell和Simon(1976)提出了著名的"物理符号系统假说"(physical symbol system hypothesis)。该假说指出:"物理符号系统具备实现通用智能行为的必要且充分的手段。"其含义是:任何表现出智能的系统(无论是人类还是机器),其运作必然依赖于对由符号构成的数据结构进行操作。我们稍后将会看到,这一假说曾受到来自多方面的挑战。
在IBM,Nathaniel Rochester及其同事开发了最早的一批AI程序。Herbert Gelernter于1959年构建了"几何定理证明器",该程序能够证明许多数学系学生觉得相当棘手的定理。这项工作是现代数学定理证明器的先驱。
在这一时期的所有探索性工作中,从长远来看,最具影响力的或许是Arthur Samuel在跳棋(checkers/draughts)领域的研究。Samuel利用我们如今称为"强化学习"(见第23章)的方法,开发出的程序学会了达到高水平业余玩家水准的棋艺。他借此推翻了"计算机只能按指令行事"的观点:他的程序很快就学会了比其创造者更出色的下棋技巧。该程序于1956年在电视上进行了演示,引起了强烈反响。像Turing一样,Samuel也面临着难以获得计算机使用时间的困境。他利用夜间时间,在IBM制造工厂仍处于测试阶段的机器上进行工作。Samuel的程序是后来许多系统的先驱,例如跻身世界顶尖双陆棋(backgammon)高手行列的TD-GAMMON(Tesauro, 1992),以及击败人类围棋世界冠军并震惊世界的AlphaGo(Silver等, 2016;见第6章)。
1958年,John McCarthy在AI领域做出了两项重要贡献。在麻省理工学院(MIT) AI实验室的第1号备忘录中,他定义了高级语言Lisp,该语言随后成为此后30年间AI领域的主流编程语言。在一篇题为《具有常识的程序》(Programs with Common Sense)的论文中,他提出了一种基于知识和推理的AI系统构想。该论文描述了"建议接受者"(Advice Taker)这一假想程序,它能够掌握关于世界的常识,并利用这些知识推导出行动计划。文中通过简单的逻辑公理阐释了这一概念,这些公理足以生成一个前往机场的行动计划。该程序还被设计为能够在正常运行过程中接受新的公理,从而使其无需重新编程即可在新的领域具备相应的能力。"建议接受者"体现了知识表示与推理的核心原则:即对世界及其运作方式进行形式化、显式的表示,并利用演绎过程对这些表示进行操作,是极具价值的。这篇论文影响了AI的发展历程,至今仍具有重要意义。
1958年也是Marvin Minsky转入MIT的一年。然而,他与McCarthy最初的合作并未持续多久。McCarthy侧重于形式逻辑中的表示与推理,而Minsky则更关注如何让程序实际运行,并最终形成了反逻辑的观点。1963年,McCarthy在Stanford大学创办了AI实验室。他计划利用逻辑构建终极的"建议接受者"(Advice Taker)系统,这一计划因J. A. Robinson于1965年提出的归结法(resolution method,一种针对一阶逻辑的完备定理证明算法;参见第9章)而得到了推进。Stanford大学的研究工作强调逻辑推理的通用方法。逻辑的应用实例包括Cordell Green开发的问答与规划系统(Green, 1969b),以及Stanford研究所(SRI)的Shakey机器人项目。后者(将在第26章中进一步讨论)是首个展示了逻辑推理与物理行动完全集成的项目。
在MIT,Minsky指导了一批学生,他们选择了一些看似需要智能才能解决的有限问题。这些有限的领域后来称为"微观世界"(microworlds)。James Slagle开发的 SAINT 程序(1963年)能够求解大学一年级课程中常见的闭式微积分积分问题;Tom Evans开发的 ANALOGY 程序(1968年)能够解决智商测试中常见的几何类比问题;Daniel Bobrow开发的 STUDENT 程序(1967年)则能求解代数应用题,例如下面这道题:
如果Tom获得的客户数量是他投放的广告数量的 20% 的平方的两倍,且他投放的广告数量为 45,那么Tom获得的客户数量是多少?
最著名的微观世界是"积木世界"(blocks world),它由放置在桌面(或更常见的是桌面模拟环境)上的一组实体积木构成,如图1.3所示。在该世界中,一项典型任务是利用机械手(每次只能抓取一块积木)按特定方式重新排列这些积木。积木世界是众多开创性研究的舞台,其中包括 David Huffman (1971) 的视觉项目、David Waltz (1975) 关于视觉与约束传播的研究、Patrick Winston (1970) 的学习理论、Terry Winograd (1972) 的自然语言理解程序,以及 Scott Fahlman (1974) 的规划器。
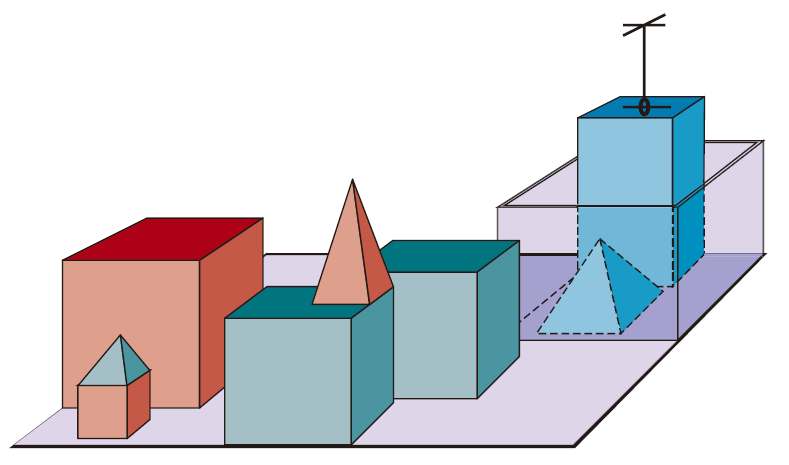
----------------------------图 1.3:"积木世界"中的一个场景。SHRDLU(Winograd, 1972)刚刚完成了"找到一个比你手中积木更高的积木,并将其放入盒子里"这一指令。------------------------------------
基于 McCulloch 和 Pitts 神经网络的早期研究也蓬勃发展。Shmuel Winograd 和 Jack Cowan(1963)的研究表明,大量单元可以共同表征单个概念,从而相应地提高了系统的健壮性和并行性。Bernie Widrow(Widrow 和 Hoff,1960;Widrow,1962)改进了 Hebb 的学习方法,并将其网络称为"自适应线性单元"(Adaline);Frank Rosenblatt(1962)则提出了"感知机"(Perceptron)。感知机收敛定理(Block 等人,1962)指出,只要存在匹配的解,该学习算法就能调整感知机的连接强度,使其与任何输入数据相匹配。
1.3.3 面对现实 ( A dose of reality**)(1966-1973)**
从一开始,AI研究人员就毫不避讳地预言自己即将取得的成功。Herbert Simon 1957年发表的以下言论常被引用:
我无意让您感到惊讶或震惊------但若要用最简单的话来概括,那就是:当今世界上已存在能够思考、学习和创造的机器。而且,它们从事这些活动的能力将迅速增强,直至在不久的将来,它们所能处理的问题范围将与人类心智所涉足的领域相当。
"可见的未来(visible future)"这一说法较为模糊,但Simon也做出过更具体的预测:十年内,计算机将成为国际象棋冠军,并由机器证明一项重要的数学定理。这些预测最终得以实现(或大致实现),但耗时近四十年,而非十年。Simon之所以过于乐观,是因为早期AI系统在处理简单案例时表现出了良好的前景;然而,在面对更复杂的难题时,这些早期系统几乎无一例外地遭遇了失败。
导致这一失败主要有两个原因。首先,许多早期的 AI 系统主要基于关于人类如何执行任务的"基于知识的内省"( informed introspection ) ,而非基于对任务本身的仔细分析------即分析何为解决方案,以及算法需要具备何种能力才能可靠地生成此类解决方案。
导致失败的第二个原因是,人们未能充分认识到 AI 试图解决的许多问题具有极大的复杂性和棘手性。 早期的多数问题求解系统采用的策略是尝试各种不同的步骤组合,直至找到解决方案。这种策略起初行之有效,因为所谓的"微观世界"中包含的对象极少,相应的可能动作也寥寥无几,所需的求解序列自然也就很短。在计算复杂性理论问世之前,人们普遍认为,要将系统扩展到规模更大的问题,只需依靠更快的硬件和更大的内存即可。例如,随着归结原理(resolution)在定理证明领域的应用,人们曾一度充满乐观,但当研究人员发现无法证明涉及数十个以上事实的定理时,这种乐观情绪很快便消退了。程序在理论上能够找到解决方案,并不意味着它具备在实际操作中找到该方案所需的任何机制。
关于计算能力无限的错觉,并不仅仅局限于解决特定问题的程序 。早期的机器进化实验(machine evolution)(现称为"遗传编程(genetic programming)")(Friedberg, 1958; Friedberg 等人, 1959)基于一个无疑正确的理念:即通过对机器码程序进行一系列适当的小规模变异,便能生成一个针对特定任务具有良好性能的程序。当时的构想是,结合选择机制尝试随机变异,从而保留那些看似有用的变异。然而,尽管投入了数千小时的 CPU 运行时间,却几乎未见成效。
未能有效应对"组合爆炸"是 Lighthill 报告(1973)中对 AI 的主要批评之一,该报告也成为英国政府决定停止资助除两所大学以外的所有大学的 AI 研究的依据。(口述传统描绘了一幅略有不同且更为生动的图景,其中涉及政治野心和个人恩怨,但此处不赘述。)
第三个困难源于用于生成智能行为的基本结构所存在的某些根本性局限。 例如,Minsky和Papert在1969年出版的《感知机》(Perceptrons)一书中证明:尽管感知机(一种简单的神经网络形式)能够学会其所能表征的任何事物,但它们能表征的内容却非常有限。具体而言,无法通过训练让一个双输入感知机识别出其两个输入端信号是否不同。尽管他们的研究结果并不适用于更复杂的多层网络,但神经网络领域的研究经费很快便缩减至几乎为零。具有讽刺意味的是,那些在20世纪80年代末及2010年代引发神经网络研究热潮的"反向传播"学习算法,其实早在20世纪60年代初就已经在其他研究背景下被开发出来了( Kelley , 1960; Bryson , 1962) 。
1.3.4 专家系统 ( Expert Systems**)(1969-1986)**
AI研究最初十年间形成的问题求解图景,是利用一种通用搜索机制,试图将基础推理步骤串联起来以构建完整解法。这类方法称为"弱方法"(weak methods),因为尽管它们具有通用性,却无法有效应对规模宏大或难度极高的问题实例。与弱方法相对的策略,是利用更强大的、特定领域的知识;这种知识支持更大跨度的推理步骤,并能更轻松地处理特定专业领域内的常见情况。可以说,要解决一个难题,往往需要预先对答案有相当程度的了解。
DENDRAL 程序(Buchanan 等人,1969 年)是采用这种方法的一个早期范例。该程序由Stanford的研究人员开发,团队成员包括 Ed Feigenbaum(Herbert Simon 的学生)、Bruce Buchanan(由哲学家转型的计算机科学家)以及 Joshua Lederberg(Nobel奖获得者、遗传学家);他们联手致力于解决如何根据质谱仪提供的信息推断分子结构的问题。该程序的输入数据包括分子的元素组成式(例如 以及质谱图------该图谱显示了分子在受到电子束轰击时所产生的各种碎片片段的质量。例如,质谱图中可能会在 m = 15 处出现一个峰值,这对应于甲基 (
) 碎片的质量。
该程序的初级版本会生成所有符合给定分子式的可能结构,预测每种结构对应的质谱图,并将其与实际质谱图进行比对。显而易见,对于中等大小的分子而言,这种方法在计算上是不可行的。DENDRAL 项目的研究人员咨询了分析化学家,发现他们的分析方法是寻找质谱图中那些指示分子内常见亚结构的典型峰型(或称"峰模式")。例如,识别酮基 (C = O,重为 28 ) 时会用到以下规则:
[ 若 M 为整个分子的质量,且在 和
处出现两个峰,满足:
(a) ;(b)
处为高峰;(c)
处为高峰;以及
(d) 和
中至少有一个对应高峰则该分子中存在酮基。]
识别出分子中包含特定的子结构,能极大地缩小可能的候选范围。据其开发者所述,DENDRAL 之所以强大,是因为它所蕴含的质谱分析相关知识并非基于"第一性原理",而是体现为高效的"操作指南"(即"食谱式"规则)( Feigenbaum 等人,1971)。DENDRAL 的意义在于,它是首个成功的知识密集型系统:其专业能力源自大量专用规则。1971 年,斯坦福大学的费根鲍姆(Feigenbaum)等人启动了启发式编程项目(Heuristic Programming Project,简称 HPP),旨在探索专家系统这一新方法在多大程度上可应用于其他领域。
下一个重大成果是用于诊断血液感染的 MYCIN 系统。MYCIN 包含约 450 条规则,其诊断表现可与某些专家媲美,且明显优于初级医生。它与 DENDRAL 相比,主要有两点不同。首先,与 DENDRAL 的规则不同,MYCIN 的规则并非基于某种通用理论模型推导而来,而是必须通过对专家进行大量访谈来获取。其次,这些规则必须能够反映医学知识中固有的不确定性。MYCIN 引入了一种称为"确定性因子"(certainty factors,见第 13 章)的不确定性计算方法;在当时看来,这种方法能很好地模拟医生评估证据对诊断结果影响的方式。
第一个成功的商业专家系统 R1 在数字设备公司(Digital Equipment Corporation,简称 DEC)投入运行(McDermott, 1982)。该程序协助配置新计算机系统的订单;到 1986 年,它估计每年为公司节省 4000 万美元。截至 1988 年,DEC 的AI团队已部署了 40 个专家系统,另有更多系统正在开发中。杜邦公司(DuPont)当时有 100 个系统在使用,500 个在开发。几乎每一家美国大型企业都拥有自己的AI团队,并且要么正在使用、要么正在研究专家系统。
领域知识的重要性在自然语言理解领域也显而易见。尽管Winograd的 SHRDLU 系统取得了成功,但其方法并未能推广到更通用的任务中:在处理诸如歧义消解之类的问题时,它依赖于简单的规则,而这些规则仅适用于"积木世界"这一极小范围的场景。
包括MIT的Eugene Charniak和Yale大学的Roger Schank在内的几位研究人员提出,要实现稳健的语言理解,需要具备关于世界的通用知识以及利用这些知识的通用方法。( Schank甚至更进一步,声称"根本不存在所谓的句法",这一言论激怒了许多语言学家,但也确实引发了一场有益的讨论。) Schank及其学生开发了一系列旨在理解自然语言的程序(Schank 和Abelson, 1977; Wilensky, 1978; Schank 和 Riesbeck, 1981)。然而,这些工作的重点不在于语言本身,而在于如何表示和推理语言理解所需的知识。
针对现实世界问题的应用广泛增长,促使人们开发出了多种多样的知识表示和推理工具。其中一些基于逻辑------例如,Prolog 语言在欧洲和日本广受欢迎,而 PLANNER 系列语言则在美国流行。另一些工具则遵循Minsky提出的"框架"(frames)概念(1975),采用了结构化更强的框架方法:将关于特定对象和事件类型的各种事实组合起来,并将这些类型组织成类似于生物分类学的大型分类层级结构。 1981年,日本政府宣布了"第五代"计算机项目,这是一项为期十年的计划,旨在构建能够运行Prolog语言的大规模并行智能计算机;按今天的币值计算,该项目的预算超过13亿美元。作为回应,美国组建了微电子与计算机技术公司(MCC),这是一个旨在确保国家竞争力的联合体。在这两个案例中,AI都是更广泛研发工作的一部分,这些工作还涵盖了芯片设计和人机接口研究等领域。在英国, Alvey 报告恢复了此前因 Lighthill 报告而被取消的资金支持。然而,无论是在实现新的 AI 能力方面,还是在产生经济影响方面,这些项目最终都未能达到其宏伟目标。
总体而言,AI行业经历了迅猛发展,市场规模从1980年的几百万美元激增至1988年的数十亿美元;期间涌现出数百家公司,致力于开发专家系统、视觉系统、机器人以及专用于这些领域的软硬件产品。
然而紧随其后的是一段被称为"AI寒冬"的时期,许多公司因未能兑现当初夸大的承诺而纷纷倒闭。事实证明,构建和维护针对复杂领域的专家系统困难重重:一方面,这些系统所采用的推理方法在面对不确定性时往往失效;另一方面,系统自身也无法从经验中进行学习。
1.3.5 神经网络的回归 ( The return of neural networks**)(1986-** 当前)
20 世纪80年代中期,至少有四个不同的研究小组重新发现了最初于20世纪60年代提出的反向传播( back-propagation ) **学习算法。**该算法被应用于计算机科学和心理学领域的诸多学习问题中,而相关研究成果在《并行分布式处理》(Parallel Distributed Processing,Rumelhart 和 McClelland,1986年)一书中的广泛传播,引发了极大的轰动。
这些所谓的联结主义(connectionist)模型,在某些人眼中被视为Newell和Simon所推崇的符号模型,以及McCarthy等人所倡导的逻辑主义方法的直接竞争对手。人类在某种层面上处理符号,这似乎是不言而喻的------事实上,人类学家Terrence Deacon在其著作《符号物种》(The Symbolic Species,1997年)中提出,这正是人类的本质特征。然而,作为20世纪80年代及2010年代神经网络复兴时期的领军人物,Geoff Hinton却将符号形容为"AI界的以太"(luminiferous aether of AI)------这一比喻指的是19世纪许多物理学家曾认为电磁波借以传播的那种实际上并不存在的介质。诚然,仔细审视便会发现,我们在语言中命名的许多概念,并不具备早期AI研究者所期望以公理化形式捕捉的那种逻辑上明确定义的必要与充分条件。联结主义模型构建内部概念的方式或许更为灵活且不那么精确,因而更能适应现实世界错综复杂的特性。此外,它们还具备从样本中学习的能力:它们能够将预测输出值与问题的真实值进行比较,并调整自身参数以减小误差,从而提高在未来样本上的表现。
1.3.6 概率推理和机器学习 ( Probabilistic reasoning and machine learning**)(1987-** 当前)
专家系统的脆弱性促成了一种更具科学性的新方法:该方法采用概率而非Boole逻辑,利用机器学习而非人工编码,并依据实验结果而非哲学论断(Cohen, 1995)(注:有人将这一转变描述为"整洁派"(neats)战胜了"粗放派"(scruffies)------前者主张AI理论应建立在严谨的数学基础之上,而后者则倾向于尝试各种构想、编写程序,再评估哪些方法行之有效。这两种路径都很重要。向"整洁"风格的转变,意味着该领域已达到了一定的稳定与成熟水平;而当前对深度学习的重视,或许标志着"粗放派"风格的某种回归)。相比于提出全新的理论,基于现有理论进行构建变得更为普遍;论点的确立更多地建立在严谨的定理或扎实的实验方法之上,而非仅仅依赖直觉;同时,研究也更注重展示与现实世界应用的关联,而非局限于简单的演示性示例。
使用共享基准(benchmark)问题集来展示进展已成为常态,其中包括:用于机器学习数据集的加州大学欧文分校(UC Irvine)存储库,用于规划算法的国际规划竞赛(IPC),用于语音识别的 LibriSpeech 语料库,用于手写数字识别的 MNIST 数据集,用于图像目标识别的 ImageNet 和 COCO,用于自然语言问答的 SQuAD,用于机器翻译的 WMT 竞赛,以及用于bool可满足性求解器的国际 SAT 竞赛。
AI **的创立,部分源于对控制理论和统计学等既有领域局限性的反叛,但在这一时期,它也吸纳了这些领域的积极成果。**正如David McAllester(1998)所言:
在AI发展的早期,人们曾一度认为,诸如"框架"(frames)和"语义网络"(semantic networks)等新型符号计算形式,使得许多经典理论变得过时。这种观点导致了一种孤立主义倾向,使AI在很大程度上与计算机科学的其他领域相互脱节。如今,这种孤立主义正逐渐被摒弃。**人们已认识到:机器学习不应脱离信息论,不确定性推理不应脱离随机建模,搜索不应脱离经典优化与控制,而自动推理也不应脱离规范化方法与静态分析**。
语音识别领域很好地体现了这一模式。20世纪70年代,人们尝试了各种各样的架构与方法。其中许多方法往往带有临时性且不够稳健,仅在少数精心挑选的样本上有效。到了20世纪80年代,基于隐Markov模型(HMM)的方法开始占据主导地位。HMM主要有两点值得关注:首先,它们建立在严谨的数学理论之上,这使得语音研究人员能够利用其他领域数十年积累的数学成果;其次,它们是通过在海量真实语音数据语料库上进行训练而构建的,这确保了系统的稳健性,并且在严格的盲测中,HMM的表现也稳步提升。得益于此,语音技术及相关的手写字符识别技术得以成功转型,广泛应用于工业和消费领域。 值得注意的是,当时并无科学依据表明人类是利用HMM 来识别语音的;HMM的作用在于为理解和解决这一问题提供了一个数学框架。然而,我们将在1.3.8节看到,深度学习的出现打破了这一既有的认知格局。
1988年是AI与其他领域(包括统计学、运筹学、决策理论和控制理论)建立联系的重要一年。Judea Pearl于1988年出版的《智能系统中的概率推理》(Probabilistic Reasoning in Intelligent Systems)一书,促使AI领域重新接纳了概率论和决策理论。Pearl提出的Bayes网络,**为表示不确定性知识提供了一种严谨且高效的规范化方法,同时也为概率推理提供了实用的算法。**本书第12、13、14、15和18章涵盖了这一领域的内容,以及极大地增强了概率规范化方法表达能力的一些较新进展;第21章则阐述了如何从数据中学习Bayes网络及相关模型的方法。
1988 年的另一项重大贡献来自 Rich Sutton,他将强化学习 ------这一早在 20 世纪 50 年代就已应用于 Arthur Samuel 跳棋程序的概念------与运筹学领域发展的 Markov决策过程( MDP ) **理论联系了起来。**随后,大量研究致力于将AI规划与 MDP 相结合;与此同时,强化学习不仅在机器人技术和过程控制领域获得了应用,也确立了深厚的理论基础。
AI 领域重新重视数据、统计建模、优化和机器学习,其结果之一便是促成了计算机视觉、机器人学、语音识别、多智能体系统及自然语言处理等分支领域的逐步回归与融合------这些领域此前已在一定程度上脱离了 AI的核心范畴。这一重新整合的过程带来了显著成效,既体现在应用层面(例如,实用型机器人的部署在这一时期大幅增加),也体现在对AI核心问题的理论理解更加深入。
1.3.7 大数据 ( Big data**)(2001-** 当前)
计算能力的显著提升与万维网的诞生,促成了超大规模数据集的形成------这一现象通常被称为"大数据" 。这些数据集涵盖了数以万亿计的文本词汇、数十亿张图像、数十亿小时的语音与视频内容,以及海量的基因组数据、车辆追踪数据、点击流数据、社交网络数据等。
这促使人们开发出专门利用超大规模数据集的学习算法 。在这类数据集中,绝大多数样本往往是未标注的;例如,在 Yarowsky (1995) 关于词义消歧的开创性研究中,数据集并未标注"plant"一词的出现是指"植物"还是"工厂"。然而,只要数据集规模足够大,合适的学习算法就能以超过 96% 的准确率识别出句子中该词的特定含义。此外, Banko 和 Brill (2001) 指出,通过将数据集规模扩大两到三个数量级所带来的性能提升,要超过通过微调算法所能获得的任何改进。
在计算机视觉任务(例如修补照片中的缺失区域------这些缺失可能是由照片破损或抹去昔日友人造成的)中,似乎也存在类似的现象。Hays 和 Efros(2007)开发了一种巧妙的方法,通过融合相似图像中的像素来实现这一目标;他们发现,当仅使用包含数千张图像的数据库时,该技术的效果并不理想,但一旦图像数量达到数百万量级,其质量便实现了质的飞跃。此后不久, ImageNet 数据库( Deng 等人,2009)中数千万张图像的可用性,引发了计算机视觉领域的革命。
大数据的普及以及向机器学习的转型,助力AI重获商业吸引力(Havenstein, 2005; Halevy 等人, 2009)。大数据是IBM的Watson系统在2011年《危险边缘》(Jeopardy!)智力竞赛中击败人类冠军的关键因素,这一事件极大地改变了公众对AI的认知。
1.3.8 深度学习 ( Deep learning**)(2011-** 当前)
" 深度学习"这一术语指的是利用多层简单且可调节的计算单元进行的机器学习 。早在20世纪70年代,人们便已开展了此类网络的相关实验;到了20世纪90年代,卷积神经网络在手写数字识别任务中取得了一定成效( LeCun 等人,1995年)。然而,直到2011年,深度学习方法才真正迎来爆发式发展,这一进程首先始于语音识别领域,随后扩展到了视觉物体识别领域。
在2012年的ImageNet竞赛中------该竞赛要求将图像归入一千个类别(如犰狳(qiú yú)、书架、开瓶器等)之一------由多伦多大学Geoffrey Hinton团队开发的深度学习系统(Krizhevsky等人,2013)展现出了显著优于以往系统的性能;而以往系统主要依赖于人工设计的特征。自那时起,深度学习系统在某些视觉任务上的表现已超越人类(尽管在另一些任务上仍落后于人类)。在语音识别、机器翻译、医学诊断和游戏对弈等领域,也取得了类似的进展。利用深度网络来表示评估函数,是AlphaGo能够战胜顶尖人类围棋选手的重要因素(Silver等人,2016, 2017, 2018)。
这些显著成就引发了学生、企业、投资者、政府、媒体及公众对AI的浓厚兴趣。几乎每周都有关于AI新应用的消息传出,显示其性能已接近甚至超越人类水平;随之而来的,往往是关于技术将加速突破抑或将迎来新一轮"AI寒冬"的种种推测。
深度学习高度依赖强大的硬件 。普通计算机的 CPU 每秒可执行 或
次运算,而运行在专用硬件(如 GPU、TPU 或 FPGA)上的深度学习算法每秒可能执行
到
次运算,且这些运算大多表现为高度并行化的矩阵和向量操作。当然,深度学习也依赖于海量训练数据的可用性以及一些算法技巧(参见第 22 章)。
1.4 阶段性最高水平( The state of the Art**)**
Stanford大学的"AI百年研究"项目(简称 AI100)召集专家小组,就AI领域的最新进展撰写报告。该项目 2016 年的报告(Stone 等人,2016;Grosz 和 Stone,2018)指出:"预计未来AI应用将大幅增加,涵盖自动驾驶汽车、医疗诊断与精准治疗,以及针对老年护理的物理辅助技术等领域。"报告还强调:"社会正处于一个关键时刻,需要决定如何部署基于AI的技术,以促进而非阻碍自由、平等和透明等民主价值观。"AI100 还通过 aiindex.org 发布"AI指数"(AI Index),以追踪技术进展。以下是 2018 年及 2019 年AI指数报告中的部分亮点(除非另有说明,否则均以 2000 年的数据为基准进行比较):
● 出版物:2010年至2019年间, AI领域的论文数量增长了20倍,达到每年约20,000篇。最热门的类别是机器学习( arXiv.org上的机器学习论文数量在2009年至2017年间每年翻一番)。计算机视觉和自然语言处理紧随其后,位列热门领域。
● 舆论倾向:关于AI 的新闻报道中,约70%持中立态度,但持正面基调的报道比例从2016年的12%上升至2018年的30%。最受关注的问题集中在伦理方面,特别是数据隐私和算法偏见。
● 学生:与2010年的基准水平相比,美国AI相关课程的注册人数增长了5倍,国际范围内则增长了16倍。AI 已成为计算机科学专业中最热门的细分方向。
● 多样性:全球AI领域的教授中,男性约占80%,女性约占20%。这一比例在博士生群体及企业招聘中也大致相同。
● 会议:自2012年以来,NeurIPS会议的参会人数增长了800%,达到13,500人。其他AI会议的参会人数也保持着约30%的年增长率。
● 产业:美国的AI初创企业数量增长了20倍,总数超过800家。
● 国际化:中国每年的论文发表量已超过美国,且与整个欧洲的总量相当。然而,在经引用加权的影响力方面,美国作者仍领先中国作者50%。在AI人才招聘数量增长最快的国家中,包括新加坡、巴西、澳大利亚、加拿大和印度。
● 视觉:物体检测的错误率(以 LSVRC------大规模视觉识别挑战赛------的成绩为例)从 2010 年的 28% 降至 2017 年的 2%,已超越人类水平。开放式视觉问答(VQA)的准确率自 2015 年以来从 55% 提升至 68%,但仍落后于人类 83% 的水平。
● 速度:仅在过去两年间,图像识别任务的训练时间就缩短了 100 倍。顶级 AI 应用所使用的算力每 3.4 个月翻一番。
● 语言:以斯坦福问答数据集(SQuAD)上的 F1 分数衡量,问答准确率从 2015 年的 60 分提升至 2019 年的 95 分;在 SQuAD 2.0 版本上,进步更为迅速,仅用一年时间就从 62 分提升至 90 分。这两项得分均已超越人类水平。
● 人类基准:据报道,截至 2019 年,AI 系统在以下领域已达到或超越人类水平:国际象棋、围棋、扑克、吃豆人(Pac-Man)、《危险边缘》(Jeopardy!)、ImageNet 物体检测、特定领域的语音识别、特定领域的中英互译、《雷神之锤 III》(Quake III)、《Dota 2》、《星际争霸 II》(StarCraft II)、各类雅达利(Atari)游戏、皮肤癌检测、前列腺癌检测、蛋白质折叠以及糖尿病视网膜病变诊断。
AI系统究竟何时(如果真能实现的话)才能在广泛的任务中达到人类水平的表现?Ford(2018)采访了多位AI专家,发现他们给出的预期年份跨度很大,从2029年到2200年不等,平均值为2099年。在另一项类似调查( Grace等人,2017)中,50% 的受访者认为这一目标可能在2066年实现,尽管也有10%的人认为最早可能在2025年实现,还有少数人认为"永远不会"实现。对于实现这一目标究竟需要根本性的新突破,还是只需对现有方法进行改进,专家们的意见也不尽相同。不过,不必过于看重这些预测;正如Philip Tetlock(2017)在预测世界大事领域所展示的那样,专家的预测表现并不比业余人士强。
未来的AI系统将如何运作?目前尚无定论。正如本节所述,该领域在发展过程中曾采纳过几种不同的主导理念:最初是关于机器智能是否可能实现的大胆构想;随后是认为可以通过将专家知识编码为逻辑规则来实现智能;接着是认为对世界进行概率建模将成为主要手段;而最近的趋势则是利用机器学习构建模型------这些模型可能完全不基于任何已被充分理解的理论。至于下一个主导模型会是什么,只有未来才能揭晓。
如今的AI能做些什么?也许不像某些过于乐观的媒体报道所描绘的那样无所不能,但它确实已经具备了强大的能力。以下是一些例子:
(1) **机器人车辆(**Robotic vehicles):
自动驾驶车辆的历史可以追溯到20世纪20年代的无线电遥控汽车,但真正无需特殊引导装置的自主道路驾驶演示,则始于20世纪80年代(Kanade等人,1986年;Dickmanns和Zapp,1987年)。继2005年DARPA"大挑战赛"(Grand Challenge,全程132英里)中在土路上成功演示驾驶,以及2007年"城市挑战赛"(Urban Challenge)中在有交通流的街道上成功演示驾驶之后,自动驾驶汽车的研发竞赛便全面展开。2018年,Waymo的测试车辆在公共道路上的行驶里程达到1000万英里且未发生重大事故,期间人类驾驶员平均每行驶6000英里才需接管一次控制权。此后不久,该公司便开始提供商业化自动驾驶出租车服务。
在空中,自主固定翼无人机自2016年起便在卢旺达执行跨区域血液运输任务;四旋翼无人机则能做出惊人的特技飞行动作,在探索建筑物的同时构建三维地图,并能自主编队。
(2) 腿部运动应用(Legged locomotion):
由 Raibert 等人(2008 年)开发的四足机器人 BigDog 颠覆了我们对机器人运动方式的既有认知------它不再像好莱坞电影中的机器人那样步态缓慢、腿部僵硬且左右摇摆,而是展现出极似动物的运动形态,甚至能在遭受推搡或在结冰水坑上打滑时迅速恢复平衡。而人形机器人 Atlas 不仅能在崎岖不平的地形上行走,还能跳上箱体并完成后空翻动作( Ackerman 和 Guizzo,2016 年)。
(3) 自主规划与调度(Autonomous planning and scheduling):
在距离地球一亿英里的太空中,NASA 的"远程智体"(Remote Agent)程序成为了首个控制航天器操作调度的机载自主规划程序(Jonsson 等人, 2000)。该程序根据地面设定的高层目标生成任务计划,并监控计划的执行情况------即在问题发生时对其进行检测、诊断及恢复处理。如今,EUROPA 规划工具包(Barreiro 等人, 2012)被用于 NASA 火星探测器的日常运行,而 SEXTANT 系统(Winternitz, 2017)则实现了在全球 GPS 系统覆盖范围之外的深空自主导航。
在1991年波斯湾危机期间,美军部署了"动态分析与重规划工具"(DART,Cross 和Walker, 1994),用于自动化的物流规划与运输调度。该系统涉及多达5万辆(架)次的车辆、货物及人员,且必须统筹考虑起点、终点、路线、运输能力、港口与机场吞吐能力,并解决各项参数之间的冲突。美国国防高级研究计划局(DARPA)指出,仅这一项应用所带来的效益,就足以抵消DARPA在AI领域长达30年的全部投入。
Uber 等网约车公司和谷歌地图(Google Maps)等地图服务每天为数亿用户提供行车路线指引,并综合考虑当前及预测的未来交通状况,迅速规划出最佳路线。
(4) 机器翻译(Machine translation):
如今,在线机器翻译系统已支持阅读 100 多种语言的文档------涵盖了全球 99% 以上人口的母语------并每天为数亿用户处理数千亿词汇的翻译。尽管这些系统尚不完美,但通常足以满足理解需求。对于拥有海量训练数据的亲缘关系密切的语言(如法语和英语),在特定领域内的翻译质量已接近人类水平(Wu 等人, 2016b)。
(5) 语音识别(Speech recognition):
2017年,微软展示了其会话语音识别系统,该系统在Switchboard任务(涉及电话对话转录)中的词错误率已降至5.1%,达到了与人类相当的水平( Xiong 等, 2017)。如今,全球约三分之一的计算机交互是通过语音而非键盘进行的;Skype提供十种语言的实时语音互译功能。Alexa、Siri、Cortana和Google等平台提供的智能助手能够回答问题并为用户执行任务;例如,Google Duplex服务利用语音识别和语音合成技术,能够代表用户进行流畅对话并预订餐厅。
(6) 推荐系统(Recommendations):
Amazon、Facebook、Netflix、Spotify、YouTube 和Walmart等公司利用机器学习技术,根据用户过往的活动记录以及其他相似用户的行为,来推荐用户可能感兴趣的内容。推荐系统领域历史悠久( Resnick 和 Varian ,1997),但随着深度学习新方法的出现,该领域正在发生迅速变化;这些新方法不仅分析历史记录和元数据,还能分析内容本身(如文本、音乐和视频)(van den Oord 等人,2014;Zhang 等人,2017))。垃圾邮件过滤也可视为一种推荐(或"反向推荐")形式;目前的 AI 技术能过滤掉超过 99.9% 的垃圾邮件,此外,电子邮件服务还能推荐潜在的收件人以及可能的回复文本。
(7) 游戏游玩(Game playing):
1997年,当"深蓝"(Deep Blue)击败国际象棋世界冠军Garry Kasparov时,那些坚信人类智力优越性的人将希望寄托在了围棋上。天体物理学家兼围棋爱好者Piet Hut曾预测,计算机要在围棋上战胜人类,还需要"一百年,甚至更久"。然而仅仅20年后,AlphaGo便超越了所有人类棋手(Silver 等, 2017)。世界冠军柯洁评价道:"去年,它下棋时还带有相当浓厚的人类风格;但今年,它已宛如围棋之神。"AlphaGo的成功,既得益于对数十万局人类棋手过往对局的学习,也归功于团队中顶尖围棋高手所贡献的精炼棋艺智慧。
后续开发的程序 AlphaZero 未使用任何人类输入信息(仅包含游戏规则),却能仅通过自我对弈进行学习,从而在围棋、国际象棋和日本将棋项目中击败所有人类及机器对手 (Silver 等人, 2018)。与此同时,AI 系统已在多种游戏中击败了人类冠军,这些游戏涵盖了《危险边缘》(Jeopardy!)(Ferrucci等人, 2010)、扑克 (Bowling 等人, 2015; Moravčík等人, 2017; Brown 和 Sandholm, 2019) 以及电子游戏《Dota 2》(Fernandez 和 Mahlmann, 2018)、《星际争霸 II》(Vinyals 等人, 2019) 和《雷神之锤 III》(Jaderberg 等人, 2019)。
(8) 图像理解(Image understanding):
计算机视觉研究人员并未止步于在极具挑战性的 ImageNet 物体识别任务中超越人类水平,而是转而攻克难度更高的图像描述(image captioning)难题。一些令人印象深刻的例子包括:"一个人在土路上骑摩托车"、"两张披萨放在炉灶烤箱上"以及"一群年轻人正在玩飞盘游戏"(Vinyals 等人,2017b)。然而,目前的系统远非完美:例如,一个被识别为"装满各种食物和饮料的冰箱"的物体,实际上却是一个被许多小贴纸部分遮挡的"禁止停车"标志。
(8) 医药卫生(Medcine):
在诊断多种疾病(尤其是基于医学影像的诊断)时,AI算法的表现已能媲美甚至超越医学专家。相关案例包括阿尔茨海默病(Ding 等人, 2018)、转移性癌症(Liu 等人, 2017; Esteva 等人, 2017)、眼科疾病(Gulshan 等人, 2016)及皮肤病(Liu 等人, 2019c)。一项系统综述与荟萃分析(Liu 等人, 2019a)显示,AI程序的诊断表现平均而言与医疗专业人员相当。当前,医疗AI领域的一个重点在于促进人机协作。例如,LYNA系统在诊断转移性乳腺癌时实现了99.6%的总体准确率------这一表现优于未获辅助的人类专家------但人机结合模式的效果更佳(Liu 等人, 2018; Steiner 等人, 2018)。
目前,这些技术的广泛应用所面临的制约因素已不再是诊断准确率,而是需要证明其能改善临床预后,并确保透明度、无偏见以及数据隐私安全(Topol, 2019)。2017年,仅有两款医疗AI应用获得美国食品药品监督管理局(FDA)批准;这一数字在2018年增至12款,且呈持续增长态势。
(8) 气候科学(Climate science):
一个科学家团队凭借一种深度学习模型荣获2018年Gordon Bell 奖,该模型能够发掘出此前隐藏在气候数据中的关于极端天气事件的详细信息。他们利用配备专用GPU硬件的超级计算机,实现了每秒百亿亿次( )运算的性能,这也是首个达到这一算力水平的机器学习程序(Kurth 等人, 2018)。Rolnick等人(2019)列出了一份长达60页的清单,详述了利用机器学习应对气候变化的各种途径。
这些仅仅是当今存在的各类AI系统中的几个例子。它们并非魔法或科幻产物,而是科学、工程与数学的结晶------而本书正是对这些领域的入门介绍。
1.5 AI的风险与收益( The Risks and Benefits of AI**)**
被誉为科学方法奠基人的哲学家Francis Bacon曾在其著作《古人的智慧》(The Wisdom of the Ancients)(1609年)中指出,"机械技艺的用途具有两面性,既能带来补救之益,也可能造成伤害之害。"随着AI在经济、社会、科学、医疗、金融及军事领域发挥日益重要的作用,我们有必要审视它所带来的"伤害与补救"------用现代术语来说,即风险与收益。此处概述的主题将在第28章和第29章中进行更深入的探讨。
先谈谈收益:简言之,我们整个文明都是人类智慧的结晶。如果我们能利用远超人类水平的机器智能,人类的雄心壮志便能突破既有上限,达到新的高度。AI与机器人技术有望将人类从繁琐重复的劳动中解放出来,并大幅提升商品与服务的产出,从而开启一个和平与富足的时代。此外,加速科学研究的能力或许能带来治愈疾病的良方,并为气候变化及资源短缺等问题提供解决方案。正如谷歌DeepMind首席执行官Demis Hassabis所言:"先攻克AI,再利用AI去解决其他一切问题。"
然而,在我们要真正"攻克AI"之前,便已面临因滥用AI(无论是有意还是无意)而产生的风险。其中一些风险已显而易见,而另一些则根据当前趋势极有可能发生:
● 致命性自主武器(Lethal autonomous weapon):
联合国将此类武器定义为能够在无需人工干预的情况下,定位、选择并消灭人类目标的武器。人们对这类武器的主要担忧之一在于其可扩展性:由于无需人工监督,一小群人便可针对任何基于可行识别标准界定的人类目标,部署数量不限的此类武器。自主武器所需的技术与自动驾驶汽车所需的技术相似。关于致命性自主武器潜在风险的非正式专家讨论于2014年在联合国启动,并于2017年进入由政府专家组主导的正式条约筹备阶段。
● 监控与说服(Surveillance and persuasion):
尽管由安保人员监控电话线路、视频监控画面、电子邮件及其他通讯渠道既昂贵又繁琐,且有时在法律上存在争议,但利用AI技术(涵盖语音识别、计算机视觉和自然语言理解)却能以可扩展的方式对个人进行大规模监控,并识别出受关注的活动。通过利用机器学习技术,针对个人定制社交媒体上的信息流,可以在一定程度上改变并控制政治行为------这一问题在2016年以来的各项选举中已变得显而易见。
● 偏见决策(Biased decision making):
在评估假释或贷款申请等任务中,若疏忽大意或蓄意滥用机器学习算法,可能导致基于种族、性别或其他受保护类别产生偏见的决策。这些数据本身往往就反映了社会中普遍存在的偏见。
● 就业影响(Impact on employment):
关于机器取代人力的担忧由来已久。这一问题错综复杂:机器虽承担了原本可能由人类完成的部分工作,但也提高了人类的生产效率,从而增强了其就业竞争力;同时,机器提升了企业的盈利能力,进而使其有条件支付更高的工资。此外,机器的应用还能让一些原本因成本过高而不可行的经济活动变得切实可行。尽管机器的使用总体上增加了社会财富,但往往会导致财富从劳动力向资本转移,从而进一步加剧不平等现象。历史上,诸如机械织布机发明之类的技术进步曾严重冲击就业市场,但人们最终总能找到新的工作机会。然而,AI未来也可能涉足这些新兴工作领域。这一议题正迅速成为全球经济学家与各国政府关注的焦点。
● 关键型安全应用(Safety-critical applications):
随着AI技术的进步,它们正越来越多地应用于自动驾驶和城市供水管理等高风险、安全攸关的领域。致命事故的发生凸显了对采用机器学习技术开发的系统进行形式化验证与统计风险分析的难度。AI领域需要制定相应的技术与伦理标准,其严谨程度至少应与工程和医疗保健等同样关乎人命的领域现行标准相当。
● 网络安全(Cybersecurity):
AI技术在防御网络攻击方面大有裨益------例如通过检测异常行为模式------但它们也会增强恶意软件的效力、生存能力及扩散能力。例如,强化学习方法已被用于开发高效工具,以实施自动化的、针对特定对象的勒索及网络钓鱼攻击。
我们将在第 28.3 节更深入地探讨这些议题。随着AI系统能力日益增强,它们将承担更多以往由人类担任的社会角色。正如人类过去曾利用这些角色进行不当行为或作恶一样,可以预见,人类也可能滥用处于这些角色中的AI系统,从而引发更严重的危害。上述所有例子都凸显了治理乃至最终实施监管的重要性。目前,研究界及参与AI 研发的主要企业已针对AI相关活动制定了自愿性治理原则(见第 28.3 节)。各国政府和国际组织正着手建立咨询机构,旨在针对各类具体应用场景制定适宜的监管法规,应对其带来的经济与社会影响,并利用AI的能力来解决重大的社会问题。
从长远来看,情况会怎样?我们能否实现那个由来已久的目标------创造出与人类智能相当甚至更胜一筹的智能?而一旦实现,又将如何?
在AI发展史的大部分时间里,这些问题都被日常工作中那些旨在让AI系统展现出哪怕一丝智能迹象的繁重任务所掩盖。正如任何广泛的学科一样,绝大多数AI研究人员都专注于某个特定子领域------例如博弈、知识表示、计算机视觉或自然语言理解------并且往往基于这样一种假设:这些子领域的进展将有助于实现AI的更宏大目标。Nils Nilsson(1995年)------SRI(斯坦福研究所)"Shakey"项目的早期负责人之一------曾提醒学界关注这些宏大目标,并警告称各个子领域有沦为"为研究而研究"之目标的风险。后来,一些具有影响力的AI奠基人,包括John McCarthy(2007年)、Marvin Minsky(2007年)和Patrick Winston,Beal & Winston(2009年),都认同Nilsson的警告。他们主张,AI不应仅仅关注特定应用中可量化的性能指标,而应回归其本源,致力于实现Herb Simon所描述的愿景,即创造出"能够思考、学习和创造的机器"。他们将这一努力方向称为"人级AI"(Human-Level AI,简称HLAI),意指机器应当能够学会人类所能做的任何事情。他们于2004年召开了首次研讨会(Minsky 等人, 2004)。另一项目标类似的倡议------通用AI(AGI)运动(Goertzel & Pennachin, 2007)------则于2008年召开了首次会议,并创办了《通用AI期刊》(Journal of Artificial General Intelligence)。
大约在同一时期,人们开始担忧,创造AI超级智能(ASI)------即远超人类能力的智能------可能并非明智之举(Yudkowsky, 2008; Omohundro, 2008)。Turing(1996)本人在1951年于曼彻斯特发表的一次演讲中也提出了同样的观点,其灵感源自Samuel Butler( 1863)早先提出的思想(注:早在1847年,《初阐释者》(Primitive Expounder)杂志的编辑Richard Thornton就曾猛烈抨击过机械计算器:"人类心智......跑到了自身的前头,通过发明机器来代行思考,从而消除了自身存在的必要性......然而,谁又能断言,当此类机器日臻完善时,它们不会构想出某种方案来弥补自身的所有缺陷,进而炮制出超越凡人理解范畴的种种思想呢!"):
一旦机器思维的方式开启,很可能用不了多久,它就会超越我们那微弱的能力......因此,在某个阶段,我们恐怕不得不预料到机器会接管控制权------正如Samuel Butler在《Erewhon》一书中所描述的那样。
随着深度学习领域的最新进展、Nick Bostrom所著《超级智能》(2014年)等书籍的出版,以及斯Stephen Hawking、Bill Gates、Martin Rees和Elon Musk等人的公开表态,这些担忧变得愈发普遍。
对于制造超智能机器这一构想,人们普遍感到不安,这在情理之中。我们可以将其称为"大猩猩问题":大约七百万年前,一种现已灭绝的灵长类动物发生了演化,其一支演化成了大猩猩,另一支则演化成了人类。
如今,大猩猩对人类这一支系恐怕并不怎么乐见;它们对自己未来的命运几乎没有任何掌控权。如果制造出超人类AI的后果是人类丧失对自己未来的掌控权,那么我们或许应该停止AI的研发,并相应地放弃它可能带来的种种益处。这正是Turing发出警告的核心所在:我们能否驾驭那些比我们更聪明的机器,这一点尚无定论。
如果超人类AI是一个来自外太空的"黑箱",那么在打开它时保持谨慎确实是明智之举。但事实并非如此:AI系统是由我们设计的;因此,如果它们最终真的像Turing所预言的那样"夺取了控制权",那将是设计失误导致的结果。
为了避免这种结果,我们需要了解潜在失败的根源。Norbert Wiener(1960年)在目睹Arthur Samuel编写的跳棋程序学会击败其创造者之后,开始思考AI的长期未来,并曾这样说道:
如果我们为了实现某种目的而使用一种机械手段,且无法有效干预其运作......那么我们最好确信无疑:赋予该机器的目标,正是我们真正想要实现的目标。
许多文化中都有关于人类向神灵、精灵、魔法师或魔鬼提出某种请求的神话传说。在这些故事中,人们总是如愿以偿地得到了自己字面上所要求的东西,但随后便追悔莫及。如果故事中还有第三个愿望,那通常就是为了撤销前两个愿望。我们将这种现象称为"迈达斯国王问题"(King Midas problem):希腊神话中的迈达斯国王曾许愿让自己触碰的一切都变成黄金,但当他触碰到食物、饮料和亲人时,便后悔不已。(注:如果迈达斯遵循基本的安全原则,并在许愿时加上"撤销"和"暂停"按钮,他的处境会好得多。)
我们在第 1.1.5 节中曾探讨过这一问题,当时指出有必要对"向机器输入固定目标"这一标准模式进行重大调整。解决Wiener所面临困境的办法,根本不在于向机器输入某种确定的"目标"。相反,我们需要的是这样一种机器:它们致力于实现人类的目标,但同时也清楚自己并不确切知道这些目标究竟是什么。
或许有些遗憾的是,迄今为止几乎所有的AI研究都是在"标准模型"框架下进行的,这意味着本版中的绝大部分技术内容都反映了这一理论框架。不过,在新框架下也已经取得了一些初步成果。在第15章中,我们证明了:当且仅当机器对人类的目标不确定时,它才会有积极的动机允许自己被关闭。在第17章中,我们构建并研究了"辅助博弈"(assistance games);这类博弈从数学上描述了这样一种情境:人类拥有某个目标,机器试图实现该目标,但起初并不确定该目标具体为何。在第23章中,我们阐述了"逆向强化学习"的方法,这种方法使机器能够通过观察人类的选择来进一步了解人类的偏好。在第28章中,我们探讨了两个主要难题:首先,我们的选择是基于偏好做出的,而这一过程涉及极其复杂的认知架构,难以进行逆向推导;其次,人类自身------无论是作为个体还是群体------未必拥有始终如一的偏好,因此,AI系统究竟应当为我们做什么,往往并不明确。