Always-On生产实践:让Agent真正在业务中7×24运转
本文属于「Hermes Agent自进化智能体深度解析」系列 | 模块十二 · 第4篇
90%的Agent项目死在Demo到Production的鸿沟里
你见过这样的场景吗?------一个Agent Demo在演示时表现完美:精准匹配、流畅对话、自动执行。投资人连连点头,业务方信心满满,CTO当场拍板:"下周上线!"
然后呢?
第一天凌晨2:17,API超时,Agent卡死在半完成的任务里。第二天,内存泄漏导致OOM,整个Worker进程挂掉。第三天,一个未捕获的异常把脏数据写进了生产库。第四天,有人手动修改了Prompt但没记录,行为回不去了。第五天......没有第五天了,业务方说了句"还是算了吧",项目正式进入"技术债坟场"。
这不是段子。这是过去两年里绝大多数AI Agent项目的真实结局。Demo能证明可能性,但只有Production才能证明价值。 而从Demo到Production之间,隔着一条无数项目葬身其中的鸿沟。
这条鸿沟的本质是什么?不是技术不够炫,不是模型不够强,而是------没有人认真对待"长期运行"这件事。 一个7×24小时运转的Agent,和一个跑5分钟就关掉的Demo,根本不是同一个物种。
今天这篇文章,我们就来拆解Hermes Agent如何跨越这条鸿沟,实现真正的Always-On生产级运转。
Demo vs Production:你不知道的差距有多大
先看一张对比图,感受一下Demo和Production之间的真实差距:
┌─────────────────────┬──────────────────┬──────────────────────┐
│ 维度 │ Demo │ Production │
├─────────────────────┼──────────────────┼──────────────────────┤
│ 运行时长 │ 5-30分钟 │ 7×24×365 │
│ 错误处理 │ "出错了没关系" │ 每个错误都要有出路 │
│ 状态管理 │ 无状态即可 │ 必须持久化+可恢复 │
│ 可观测性 │ print就行 │ Metrics/Logs/Traces │
│ 变更方式 │ 改代码重启 │ 灰度+回滚+审计 │
│ 数据安全 │ Mock数据 │ 生产数据+隐私合规 │
│ 资源管理 │ 不用管 │ 容量规划+限流+降级 │
│ 故障影响 │ 一个人看到 │ 全业务链路 │
│ 人工干预 │ 随时手动修 │ 月干预<5次 │
│ 自进化能力 │ 不需要 │ 唯一的生存策略 │
└─────────────────────┴──────────────────┴──────────────────────┘关键洞察:Demo关心的是"能不能做",Production关心的是"坏了怎么办"。 一个Agent能不能上生产,不取决于它最好的时候有多好,而取决于它最差的时候有多安全。
Demo思维的核心问题在于"线性预期"------假设一切顺利。而Production思维的核心是"容错设计"------假设一切都会出错,然后让系统在出错时仍然安全、可恢复、可追溯。
Hermes Agent的自进化能力在Always-On场景下有一个天然优势:长期运行 = 长期进化。一个跑180天的Agent,积累了180天的执行轨迹、错误模式、修复经验。它不是在"保持运转",而是在"越跑越稳"。
生产级八个必须:上生产前的检查清单
将一个Agent部署到生产环境之前,必须通过以下八个维度的检查。任何一个缺失,都是未来的定时炸弹。
┌─────────────────────────────────────────────────────────────┐
│ Production-Ready 八维雷达图 │
│ │
│ 可稳定性 │
│ ★ │
│ /|\ │
│ 可恢复 ★─ ─ ─ ─ ★ 可观测 │
│ / | \ │
│ 安全加固 ★ | ★ 可回滚 │
│ \ | / │
│ 可治理 ★─ ─ ─ ─ ★ 可审计 │
│ \|/ │
│ 可扩展 ★ ★ 可进化 │
│ │
│ 全部★达标 = 可以上生产 │
│ 任一★缺失 = 继续打磨 │
└─────────────────────────────────────────────────────────────┘1. 稳定性(Stability)
Agent必须能在无人干预的情况下持续运行。核心指标:
- MTBF(Mean Time Between Failures):两次故障之间的平均时间,目标 > 72小时
- 成功率:Goal完成率 > 95%,单Step成功率 > 99%
- 资源稳定:内存不泄漏,连接池不耗尽,磁盘不爆满
实现手段:自动重试、降级执行、资源限额、定期GC。这些在#38容灾自愈进阶中已有详细拆解。
2. 可观测(Observability)
你看不见的东西,你就管不了。生产级Agent必须具备完整的可观测性:
- Metrics:执行耗时、成功率、Token消耗、队列深度
- Logs:结构化日志,每步操作可追溯
- Traces:跨Worker调用链路可视化
3. 可回滚(Rollback)
任何变更必须能在5分钟内回滚。包括:
- Skill版本回滚:
hermes skill rollback matching-engine v2.3.1 - Prompt版本回滚:Git-managed prompt templates
- 配置回滚:所有配置变更存储在版本控制中
- 数据回滚:关键操作前的snapshot + restore机制
4. 可审计(Auditability)
每一次关键操作都必须有审计记录:
Audit Log Schema:
timestamp: 2026-06-01T02:17:33Z
actor: agent:matching-worker-03
action: skill.execute
target: deep-matching-pipeline
version: v3.1.2
input_hash: sha256:a1b2c3...
output_hash: sha256:d4e5f6...
result: success
duration_ms: 1247
tokens_used: 3842
approver: auto-approved (risk_score=0.12)5. 可扩展(Scalability)
Agent必须能水平扩展。当任务量从每天100个增长到每天10000个时,不应该需要重写架构。核心设计:无状态Worker + 共享队列 + 弹性调度。
6. 可治理(Governance)
谁有权触发什么操作?谁能修改哪个Skill?谁审批上线?这些问题必须有明确的权限模型。Hermes的RBAC模型确保每个角色只拥有最小必要权限。
7. 可恢复(Recovery)
故障发生后的恢复速度直接决定业务影响。目标:RPO < 1分钟,RTO < 5分钟。关键设计:状态持久化 + Checkpoint + 自动Replay。
8. 可进化(Evolvability)
这是八个必须中最具Hermes特色的一个。生产级Agent不是"部署完就固定"的系统,而是一个持续进化的生命体。它必须具备:
- 从执行轨迹中自动学习新模式
- 从失败中自动提取改进策略
- 能力的渐进式升级(不是推翻重来)
- 进化过程中的质量保障(不能越进化越差)
检查清单速查:
| 检查项 | 达标标准 | 不达标风险 |
|---|---|---|
| MTBF > 72h | 凌晨电话不断 | |
| 三支柱可观测 | 黑箱调试,排障靠猜 | |
| 5分钟回滚 | 一次错误变更毁全局 | |
| 完整审计链 | 合规不过,甩锅无据 | |
| 水平扩展 | 业务增长=系统崩溃 | |
| RBAC权限模型 | 越权操作,安全事故 | |
| RTO < 5min | 业务中断,损失扩大 | |
| 自动进化闭环 | 能力停滞,竞争力衰减 |
日常运维:当Agent成为你的"数字员工"
Always-On不等于"部署完就不用管了"。就像管理一支团队一样,Agent需要日常运维来保持最佳状态。区别在于,Hermes Agent能自己完成大部分"自检",人类只需要关注异常。
┌──────────────────────────────────────────────────────────────┐
│ Always-On 日常运维全景图 │
│ │
│ 06:00 ┌──────────┐ 08:00 ┌───────────┐ 10:00 │
│ ────────►│ 健康检查 │────────►│ 容量评估 │──────────► │
│ │ HealthChk │ │ Capacity │ │
│ └──────────┘ └───────────┘ │
│ ▲ │ │
│ │ 14:00 ┌──────────┐ 16:00 ┌─────▼─────┐ │
│ │─────────────── │ 灰度发布 │────────►│ 效果观测 │ │
│ │ Canary │ │ Monitoring │ │
│ └──────────┘ └───────────┘ │
│ │
│ 22:00 ┌──────────┐ 02:00 ┌───────────┐ │
│ ────────►│ 日志归档 │────────►│ 深度自检 │──────── 自动 │
│ │ Archive │ │ DeepScan │ 循环 │
│ └──────────┘ └───────────┘ │
└──────────────────────────────────────────────────────────────┘健康检查(Health Check)
Hermes每15分钟执行一次自动健康检查,覆盖五个维度:
yaml
health_check:
schedule: "*/15 * * * *"
checks:
- name: worker_liveness
type: heartbeat
threshold: 60s # 超过60s无心跳 = 不健康
- name: queue_depth
type: metric
warn: 100 # 队列深度 > 100 警告
critical: 500 # 队列深度 > 500 严重
- name: error_rate
type: metric
warn: 5% # 错误率 > 5% 警告
critical: 15% # 错误率 > 15% 严重
- name: memory_usage
type: resource
warn: 75%
critical: 90%
- name: skill_health
type: functional
# 执行轻量级Skill验证,确认核心链路畅通容量规划(Capacity Planning)
不是等资源不够了才扩容,而是提前预判。Hermes基于历史数据预测未来7天的资源需求:
- Token消耗趋势:过去7天的Token日均消耗 + 增长率
- 任务队列预测:基于业务周期性(工作日vs周末)预测队列深度
- Worker资源水位:CPU/内存/磁盘的使用趋势 + 预警线
- API Rate Limit余量:各外部API的调用频率 vs 配额
灰度发布(Canary Deployment)
任何Skill或配置变更,绝不全量上线。Hermes的灰度发布流程:
-
影子模式(Shadow):新版本在后台运行,结果不生效,只做对比
-
金丝雀模式(Canary):5%流量切到新版本,监控15分钟
-
渐进扩展:5% → 25% → 50% → 100%,每阶段观察指标
-
自动回滚:任何指标异常超过阈值,自动回滚到上一版本
灰度发布时间线(一次典型升级):
T+0min T+15min T+30min T+45min T+60min
┃ ┃ ┃ ┃ ┃
▼ Shadow ▼ Canary ▼ 25% ▼ 50% ▼ 100% → 全量上线
(对比) (5%) (扩量) (扩量) (完成)异常场景:
T+35min 错误率>8% → 自动回滚 → 回到v2.3.1 → 告警通知
变更管理:每一次改动都必须"有人负责"
在生产环境中,最大的风险不是外部故障,而是内部变更。一个不小心的Prompt修改,可能让Agent的行为完全偏离预期。
Hermes的变更管理核心设计是Human Approval Gate------关键变更必须经过人类审批。
Human Approval Gate设计
yaml
change_management:
approval_gates:
# 自动通过(低风险)
- category: skill_hotfix
risk_score_threshold: 0.2
auto_approve: true
notify: [dev-team]
# 需要一人审批(中风险)
- category: skill_update
risk_score_threshold: 0.5
require_approval: 1
approvers: [tech-lead]
timeout: 4h # 4小时未审批自动拒绝
# 需要两人审批(高风险)
- category: prompt_template_change
risk_score_threshold: 0.7
require_approval: 2
approvers: [tech-lead, product-owner]
timeout: 24h
# 禁止自动执行(极高风险)
- category: security_config_change
risk_score_threshold: 0.9
require_approval: 2
approvers: [cto, security-lead]
timeout: 48h
require_dry_run: true # 必须先在staging验证
risk_score_factors:
- affected_users_count: weight=0.3
- data_sensitivity: weight=0.3
- rollback_complexity: weight=0.2
- historical_failure_rate: weight=0.2关键设计原则:
- 风险量化:不是靠感觉决定需不需要审批,而是用Risk Score量化
- 超时机制:审批不能无限等待,超时自动拒绝比超时自动通过更安全
- Dry Run强制:高风险变更必须先在隔离环境验证
- 变更冻结窗口:业务高峰期(如促销期间)自动冻结所有非紧急变更
Deep Matching Always-On实战:一个真实系统的运转日志
让我们把视线拉回到Hermes系列的经典案例------Deep Matching社交媒体匹配系统,看它如何在Always-On模式下运转。
三大监控维度
Deep Matching在Always-On模式下,持续监控三个关键维度:
1. Matching Quality(匹配质量)
Deep Matching 每日质量报告 2026-06-01
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
总匹配数: 4,217
成功匹配率: 89.3% (目标: 85%)
用户满意度: 4.2/5.0
匹配后互动率: 67.8% (目标: 60%)
质量分数趋势: ↑ 2.1% (vs 上周)
异常匹配数: 12 (自动标记,待复核)
自进化动作:
- 基于上周反馈优化兴趣权重 ×1.3
- 新增"间歇性活跃"信号处理逻辑
- 淘汰低效匹配策略: proximity-only v12. Stale Profiles(过期画像)
用户画像是Deep Matching的核心资产,但画像是会过期的。一个三个月没更新的兴趣标签,可信度已经很低了。
yaml
stale_profile_detection:
check_schedule: "0 3 * * *" # 每天凌晨3点检查
stale_threshold_days: 30
actions:
- tier_1 (30-60 days): 降低画像权重,标记为"可能过期"
- tier_2 (60-90 days): 触发轻量级画像刷新(分析近期行为)
- tier_3 (90+ days): 标记为"不可用",从匹配池中移除
auto_refresh:
enabled: true
method: analyze_recent_behavior # 用近期行为自动更新画像
max_refresh_per_day: 500 # 每天最多自动刷新500个画像3. Failed Jobs(失败任务)
每一个失败的匹配任务都要有完整的错误上下文,不能只是一行Error Log:
Failed Job Detail:
job_id: match-20260601-0317-afk9
failure_point: compatibility_scoring
error_type: TimeoutError
context:
user_a_id: usr_28kx9
user_b_id: usr_73mnp
step: "计算深层兼容性分数"
timeout_at: 30s
retry_count: 2/3
auto_action: 降级到快速匹配算法 → 成功
quality_impact: 匹配置信度从 0.92 降到 0.78(可接受)
escalation: 无需人工干预注意最后一行------系统自动降级处理后成功了,匹配质量虽然略有下降但仍在可接受范围内。这就是Always-On的核心设计哲学:不是不犯错,而是犯了错有出路。
安全加固:Secret管理与权限最小化
一个7×24运转的Agent,暴露面远大于一个临时Demo。安全不是可选项,而是生存前提。
Secret管理
永远不要把API Key、数据库密码、OAuth Token硬编码在任何地方。Hermes的Secret管理采用三层架构:
┌──────────────────────────────────────────────┐
│ Secret 管理三层架构 │
│ │
│ Layer 1: Vault(保险箱) │
│ ├─ HashiCorp Vault / AWS Secrets Manager │
│ ├─ 所有Secret的Ground Truth │
│ └─ 自动轮转 + 访问审计 │
│ │
│ Layer 2: Injection(注入层) │
│ ├─ 运行时通过Environment Variable注入 │
│ ├─ Agent代码永远不直接接触Secret原文 │
│ └─ 每个Worker只获取自己需要的Secret │
│ │
│ Layer 3: Audit(审计层) │
│ ├─ 每次Secret访问都记录日志 │
│ ├─ 异常访问模式自动告警 │
│ └─ Secret轮转历史完整可追溯 │
└──────────────────────────────────────────────┘权限最小化(Least Privilege)
每个Agent Worker只拥有完成其任务所需的最小权限集合:
yaml
# matching-worker 的权限配置
worker: matching-worker-03
permissions:
databases:
- name: user_profiles
access: read-only # 只读,不需要写
columns: [public_fields] # 只能访问公开字段
- name: match_results
access: read-write # 需要写入匹配结果
columns: [all]
apis:
- name: embedding_service
rate_limit: 1000/min
- name: notification_service
methods: [send_match_notification] # 只能发匹配通知
files:
- path: /data/models/matching/
access: read-only
- path: /tmp/matching-worker/
access: read-write
# 绝对禁止的操作
denied:
- direct_database_drop
- user_data_export
- system_config_modify
- other_worker_impersonate关键原则:宁可多配一条deny规则,也不要给一个"万能权限"。 在Always-On场景下,任何一次权限滥用都可能被放大成灾难。
震撼时刻:Day 1到Day 180的真实进化曲线
现在到了这篇文章最重要的部分------一张真实的数据曲线。这不是理论推演,而是Deep Matching系统从上线第一天到第180天的核心指标变化:
MTBF(平均无故障时间)进化曲线
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
72h ┤ ╭────
│ ╭─────╯
│ ╭─────╯
48h ┤ ╭─────╯
│ ╭─────╯
│ ╭─────╯
24h ┤ ╭─────╯
│ ╭────╯
4h ┤─╯
│
┼────┬────┬────┬────┬────┬────┬────┬────→
D1 D15 D30 D60 D90 D120 D150 D180
月人工干预次数进化曲线
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
47次 ┤╮
│ ╲
│ ╲
30次 ┤ ╲
│ ╲
│ ╲
15次 ┤ ╲
│ ╲╲
5次 ┤ ╲╲
│ ╲╲
3次 ┤ ╲─────── (稳定在3次/月)
┼────┬────┬────┬────┬────┬────┬────┬────→
D1 D15 D30 D60 D90 D120 D150 D180数据解读:
- MTBF从4小时增长到72小时 --- 增长了18倍。这不是因为系统"不犯错"了,而是因为系统学会了"自己修"。90%的故障在第60天之后都能被自动处理,只有10%需要人工介入。
- 月人工干预从47次降到3次 --- 这些干预不再是因为系统"坏了",而是因为业务需求发生了系统未曾见过的变化。剩下的3次干预本身也在变成新的训练数据,推动下一次进化。
- 进化的加速度 --- 前30天最痛苦,人工干预密集。但从第60天开始,曲线明显加速下行。原因是自进化飞轮已经积累了足够的执行轨迹和错误模式,开始产生"复利效应"。
这就是自进化的力量:系统不是被你修好的,而是它自己变好的。 你需要做的,只是在早期给它足够的关注和正确的信号反馈。到了后期,你会发现系统比你自己更了解它的边界在哪里。
从Day 1到Day 180的旅程告诉我们一个深刻的道理:Always-On不是目的,持续进化才是目的。一个7×24运转的Agent如果不具备自进化能力,那它只是在重复犯错。只有当长期运行和自进化形成闭环时,Always-On才真正有意义。
总结与预告
这篇文章我们拆解了从Demo到Production的完整路径:
- 鸿沟认知 --- Demo和Production是两个完全不同的物种,90%的项目死在这个认知差上
- 八个必须 --- 稳定性、可观测、可回滚、可审计、可扩展、可治理、可恢复、可进化,缺一不可
- 日常运维 --- 健康检查、容量规划、灰度发布,让Agent持续保持在最佳状态
- 变更管理 --- Human Approval Gate确保每次改动都有人负责
- Deep Matching实战 --- 匹配质量、过期画像、失败任务三大维度的Always-On监控
- 安全加固 --- Secret三层管理和权限最小化
- 进化数据 --- 180天MTBF增长18倍,月干预从47次降到3次
但有一个关键问题我们还没有深入回答:当没有人在看的时候,谁来保证Agent产出的质量? 健康检查确保Agent在"跑",但谁确保它跑得"对"?
下一篇,我们将进入模块十二的最后一篇------#40 自动化质量保障体系,拆解当Agent真正7×24无人值守运转时,如何用Quality Gate、测试金字塔、Drift Detection和自动Code Review构建一套无人值守的质量防线。
这篇的震撼时刻已经告诉了我们答案的方向------180天后,月人工干预降到3次。那3次不是质量出了问题,而是业务变了。质量保障本身也被自动化了。怎么做到的?下篇见分晓。
延伸阅读与交流
本文涉及的Hermes Agent自进化智能体技术体系,目前已有系统化的深度学习资源可供参考。中国通信工业协会通信和信息技术创新人才培养工程项目办公室将于近期组织相关技术专题分享,围绕本文讨论的AI原生架构、智能体工作流、自进化数据层等方向展开系统讲解。
专题信息
- 主题:AI原生Hermes自进化智能体系统
- 时间:2026年7月4-5日(周末)
- 形式:线上直播
- 内容方向:AI原生架构 · Hermes智能体拆解 · 全栈扩展 · 智能自动化 · 产品级实战 · Context Engine · 自进化数据层
分享嘉宾
王老师(Gavin),Agentic AI企业联合创始人兼CTO,十余年硅谷AI系统工程经验。长期深耕NLP、强化学习、可控AI与智能体系统架构,提出"语言即控制(Language as Control)"原创范式,在RLHF、PPO、DPO、GRPO等方向有系统化工程实践,推动智能体技术在社交媒体、医疗、金融、法律、教育等专业场景落地。
技术交流
- 联系人:Sam
- WeChat:NLP_ChatGPT_LLM
- Hermes Agent技术文档:https://hermes-agent.nousresearch.com/docs/
























2026年重磅喜讯! 喜报!热烈祝贺Gavin大咖人工智能领域经典著作《企业级ChatGPT AI大模型应用开发实战(1000分钟视频)》中国水利水电出版社发行上市!
内容提要
本书内容基于作者在硅谷 ChatGPT 项目及企业培训中的实战经验凝练而成,重点介绍企业级 ChatGPT 开发的核心技术、案例研究及最佳实践。全书共 16 章,分为基础篇和实战篇两大部分。
基础篇:
介绍 ChatGPT 底层架构 Transformer 技术及源码实现、GPT 的内部机制及源码实现、GPT 系列模型原理与应用:从 GPT-2 到 GPT-4 等内容。
实战篇:
介绍基于 ChatGPT 的端到端语音聊天机器人项目实战,企业级 ChatGPT 开发的三大核心内部机制及案例实战,ChatGPT 插件的内部机制、源码及案例实战,ChatGPT 提示词开发实战,思维链及 ReAct 解析与实战,提示词本质解析及评估实战与源码解析,LangChain 大模型框架的七大核心组件及案例解析(上、下),LangChain 代理深入解析及源码解析,AutoGPT 源码解析及综合案例实战,使用 LangChain 构建问答聊天机器人案例实战,构建基于大模型的自治代理案例,Llama 2 模型与 LangChain 项目详解。书中每个知识点均配有相应的实现代码和实例。
本书适合有一定 Python 基础的 ChatGPT 爱好者阅读,主要面向从事大模型应用开发、机器学习、数据挖掘或深度学习的专业人员,高等院校相关专业的师生,以及相关领域的科研人员。
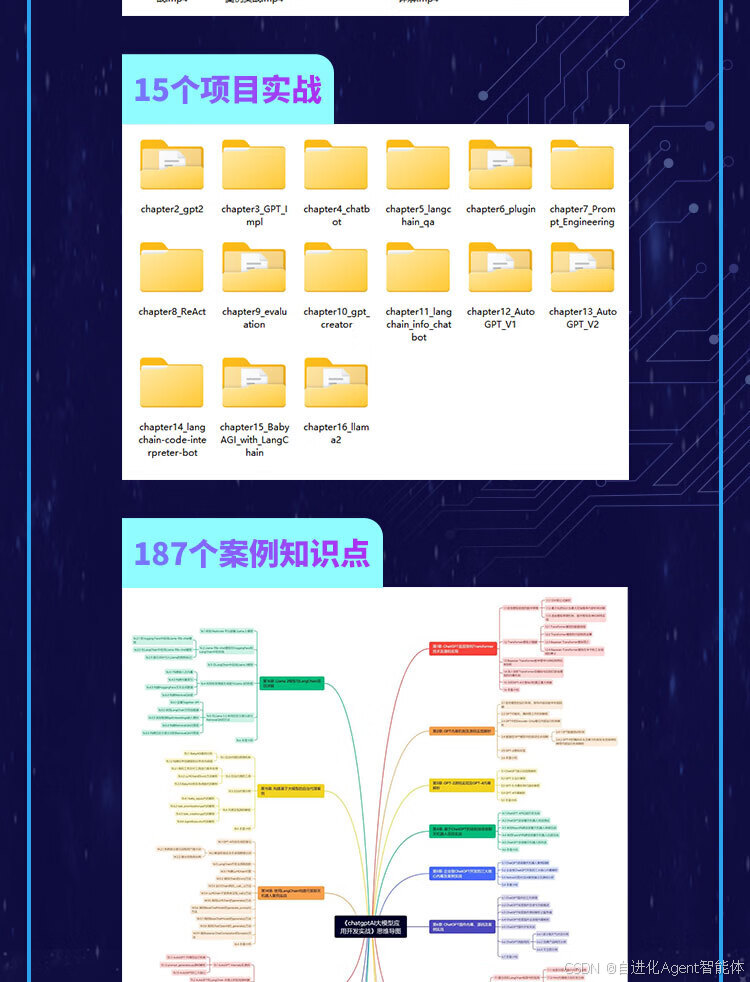
本书附赠丰富的学习资源,具体如下:①同步学习资源,即 16 集同步教学视频,视频时长共计约 1000 分钟;②教师授课的辅助资源,即 187 个案例知识点、15 个项目实战的全部源代码。
前言
在当今快速发展的科技时代,人工智能(artificial intelligence,AI)技术正以惊人的速度改变着人们的生活和工作方式。在这个新时代的浪潮中,大模型技术成为AI领域的一颗耀眼新星。ChatGPT作为大模型技术的重要应用之一,正在引领着人机交互领域的革新浪潮。本书将带领读者深入探索大模型新时代,通过ChatGPT实战项目和内部解析,深入掌握基于ChatGPT的大模型应用开发领域的关键技术,并解密ChatGPT的底层架构和实现原理。
本书主要内容
本书通过ChatGPT实战项目的方式,为读者呈现一个全面、系统的学习路径,从基础知识的介绍开始,带领读者深入了解ChatGPT的工作原理和实际应用。本书非常适合具备Python基础的读者学习。
全书共16章,分为基础篇和实战篇两大部分。
基础篇包括第1~3章;实战篇包括第4~16章。
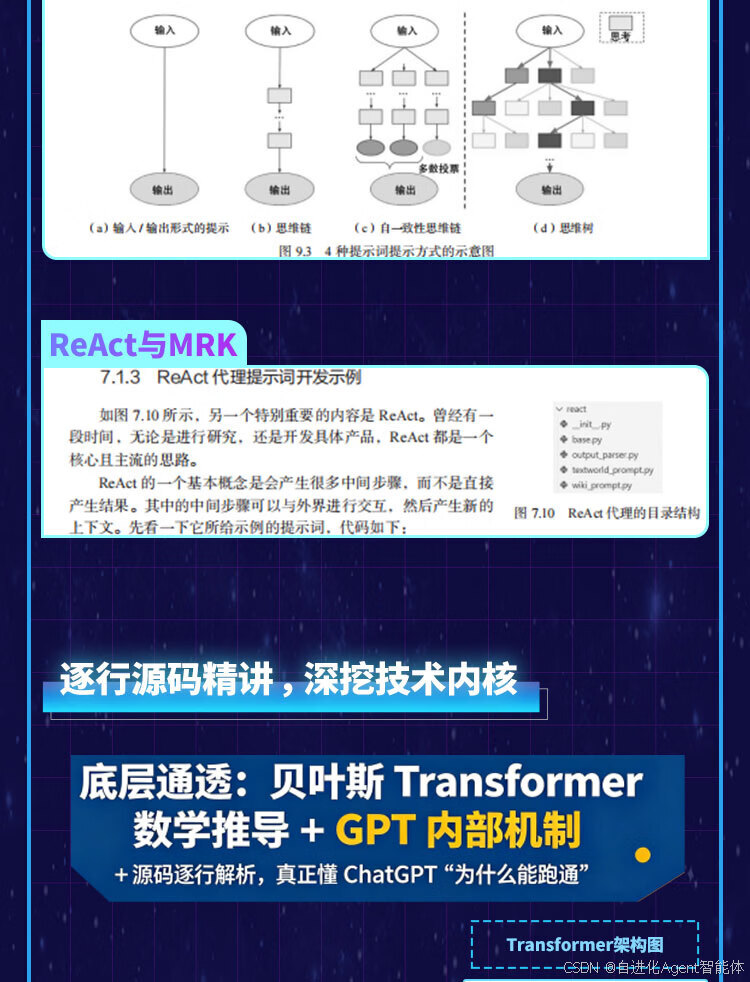
第1章 ChatGPT底层架构Transformer技术及源码实现,详解最大似然估计、最大后验概率、贝叶斯Transformer及自编码与自回归语言模型的内部机制。
第2章 GPT的内部机制及源码实现,剖析GPT运行机制、掩码机制、Decoder-Only模式,详解数据流动生命周期及GPT-2源码。
第3章 GPT系列模型原理与应用:从GPT-2到GPT-4,解析ChatGPT提示词流程、GPT-2运行机制,可视化解读GPT-3/4的内部机制。
第4章 基于ChatGPT的端到端语音聊天机器人项目实战,涵盖ChatGPT API开发、前后端构建(ReAct+FastAPI)及项目优化。
第5章 企业级ChatGPT开发的三大核心内部机制及案例实战,解析企业级开发核心,演示Notion问答对话AI案例。
第6章 ChatGPT插件的内部机制、源码及案例实战,详解插件工作原理、检索插件源码及全流程开发实战。
第7章 ChatGPT提示词开发实战,基于LangChain框架的提示词、思维链、链式提示词及模型评估开发。
第8章 思维链及ReAct解析与实战,剖析思维链推理、ReAct技术原理、框架源码及案例实战。
第9章 提示词本质解析及评估实战与源码解析,包含问答评估、代理评估源码解析及提示词本质探讨。
第10~11章 LangChain大模型框架的七大核心组件及案例解析(上、下),涵盖模型、词嵌入、提示词、内存、回调、数据连接、代理等核心组件及聊天机器人综合案例。
第12章 LangChain代理深入解析及源码解析,详解代理工作原理及AutoGPT源码解析。
第13章 AutoGPT源码解析及综合案例实战,剖析AutoGPT内部机制及其在LangChain代理、内存、PromptGenerator中的应用。
第14章 使用LangChain构建问答聊天机器人案例实战,涵盖GPT-4代码生成全流程及LangChain开发实战。
第15章 构建基于大模型的自治代理案例,详解自治代理原理、工具、示例及开源实现源码。
第16章 Llama 2模型与LangChain项目详解,包括模型部署(Replicate)、Hugging Face/LangChain实践、检索增强生成及自定义提示词RetrievalQA开发。
本书特色
●深入探索,全面剖析。
本书涵盖ChatGPT案例实战、LangChain项目实战及框架源码解析等多个层面的内容。每章都深入探讨相关技术与案例,并提供源码解析,使读者能够全面了解ChatGPT和LangChain等技术的内部机制与开发原理,为实际项目的应用提供有力指导。
●实战剖析,项目揭秘。
本书每章都提供具体的案例实战与项目解析,引导读者通过实际操作和代码理解技术细节和底层逻辑。通过理论结合实践的方式,使读者能够更好地运用所学知识,深入了解项目和框架的实现细节。
●前沿突破,技术驱动。
本书介绍了一系列突破性的技术,如ChatGPT、LangChain、Transformer、Prompt、Llama 2、AutoGPT、BabyAGI、CoT、ToT、ReAct、MRKL等。通过对这些技术的深入剖析,读者可以了解相关技术的发展和应用,并了解它们在实际项目中的具体应用场景和效果。
●源码解析,细致讲解。
本书对LangChain框架的关键技术进行了逐行源码剖析。读者可以深入理解源码实现和机制原理,从而更好地理解技术细节和底层逻辑,并将其应用于实际开发工作中。
本书还为读者提供了丰富的知识和实用的技能,帮助读者在ChatGPT和LangChain领域取得突破性的进展。无论是初学者还是有一定经验的开发者,都可以从本书中获得有价值的学习资源。
配套资源
为便于教与学,本书配有同步教学视频(约1000分钟)、源代码、数据集、教学课件、教学大纲、安装程序。
作者简介
王家林
美国斯坦福大学计算机专业毕业。曾在美国担任硅谷顶级机器学习和人工智能实验室主任、杰出AI工程师及首席机器学习工程师,专精于对话式人工智能(conversational AI)。现担任硅谷某知名对话机器人公司CTO,自2019年起专注于基于红队测试(red teaming)的责任型AI(responsible AI),并热衷于构建生成式AI/大语言模型教练系统(GenAI/LLM coaching systems)。在硅谷任职期间,曾领导多个GenAI/LLM解决方案项目,成功平衡企业业务需求下的大模型推理(reasoning)系统与幻觉(hallucinations)及偏见(biases)风险的最小化。
作为数据科学、机器学习、NLP、ChatGPT及大模型等领域25本书的主要作者,王家林对利用人工智能提供解决方案,以及通过机器学习驱动的NLP与LLM流程帮助组织实现数据驱动决策充满热情。他曾领导Apple、PayPal、Chase Bank、Faethm、LinkedIn等公司的11个重大NLP项目。
在NLP、对话式AI、大数据及基于AWS的无服务器(serverless)技术方面,拥有丰富的机器学习咨询经验。
段智华
中国电信股份有限公司上海分公司高级工程师。长期从事大模型与智能体技术领域,专注Agentic AI、Harness Agent等前沿方向研究。
新书购买链接
《企业级ChatGPT AI大模型应用开发实战(1000分钟视频)》