
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言
- [一. 滑动窗口:TCP 性能的基石](#一. 滑动窗口:TCP 性能的基石)
-
- [1.1 为什么需要滑动窗口](#1.1 为什么需要滑动窗口)
- [1.2 滑动窗口的工作原理](#1.2 滑动窗口的工作原理)
- [1.3 滑动窗口的核心细节](#1.3 滑动窗口的核心细节)
-
- [1.3.1 窗口大小的决定因素](#1.3.1 窗口大小的决定因素)
- [1.3.2 窗口的动态变化](#1.3.2 窗口的动态变化)
- [1.3.3 缓冲区的环形抽象](#1.3.3 缓冲区的环形抽象)
- [1.4 丢包处理:快重传与超时重传](#1.4 丢包处理:快重传与超时重传)
-
- [1.4.1 ACK 丢失](#1.4.1 ACK 丢失)
- [1.4.2 数据包丢失](#1.4.2 数据包丢失)
- [二. 拥塞控制:网络的 "交通警察"](#二. 拥塞控制:网络的 "交通警察")
-
- [2.1 为什么需要拥塞控制](#2.1 为什么需要拥塞控制)
- [2.2 拥塞控制的核心机制](#2.2 拥塞控制的核心机制)
-
- [2.2.1 慢启动 (Slow Start)](#2.2.1 慢启动 (Slow Start))
- [2.2.2 拥塞避免 (Congestion Avoidance)](#2.2.2 拥塞避免 (Congestion Avoidance))
- [2.2.3 拥塞发生时的处理](#2.2.3 拥塞发生时的处理)
- [2.3 拥塞控制的完整过程](#2.3 拥塞控制的完整过程)
- [三. 延迟应答:让窗口更大一点](#三. 延迟应答:让窗口更大一点)
-
- [3.1 延迟应答的原理](#3.1 延迟应答的原理)
- [3.2 延迟应答的实现机制](#3.2 延迟应答的实现机制)
- [四. 捎带应答:ACK 搭个顺风车](#四. 捎带应答:ACK 搭个顺风车)
-
- [4.1 捎带应答的原理](#4.1 捎带应答的原理)
- [4.2 捎带应答的优势](#4.2 捎带应答的优势)
- [五. 面向字节流:TCP 的本质特性](#五. 面向字节流:TCP 的本质特性)
-
- [5.1 TCP 缓冲区机制](#5.1 TCP 缓冲区机制)
- [5.2 全双工通信](#5.2 全双工通信)
- [5.3 读写不匹配的特性](#5.3 读写不匹配的特性)
- [六. 粘包问题:面向字节流的 "副作用"](#六. 粘包问题:面向字节流的 "副作用")
-
- [6.1 什么是粘包问题](#6.1 什么是粘包问题)
- [6.2 为什么会出现粘包问题](#6.2 为什么会出现粘包问题)
- [6.3 如何解决粘包问题](#6.3 如何解决粘包问题)
- [6.4 UDP 为什么没有粘包问题](#6.4 UDP 为什么没有粘包问题)
- [七. TCP 异常情况处理](#七. TCP 异常情况处理)
-
- [7.1 进程终止](#7.1 进程终止)
- [7.2 机器重启](#7.2 机器重启)
- [7.3 机器掉电 / 网线断开](#7.3 机器掉电 / 网线断开)
- [八. TCP vs UDP:没有最好,只有最合适](#八. TCP vs UDP:没有最好,只有最合适)
- [九. 经典面试题:用 UDP 实现可靠传输](#九. 经典面试题:用 UDP 实现可靠传输)
- [十. 经典面试题:HTTP获取网页的完整过程](#十. 经典面试题:HTTP获取网页的完整过程)
-
- [10.1 整体流程概览](#10.1 整体流程概览)
- [10.2 详细步骤拆解](#10.2 详细步骤拆解)
-
- [10.2.1 URL 解析](#10.2.1 URL 解析)
- [10.2.2 DNS 域名解析](#10.2.2 DNS 域名解析)
- [10.2.3 TCP 连接建立](#10.2.3 TCP 连接建立)
- [10.2.4 HTTP 请求发送](#10.2.4 HTTP 请求发送)
- [10.2.5 服务器处理请求](#10.2.5 服务器处理请求)
- [10.2.6 HTTP 响应接收](#10.2.6 HTTP 响应接收)
- [10.2.7 TCP 连接关闭](#10.2.7 TCP 连接关闭)
- [10.2.8 浏览器渲染页面](#10.2.8 浏览器渲染页面)
- [10.3 面试常考细节](#10.3 面试常考细节)
- [十一. 源码解读:TCP 头部结构](#十一. 源码解读:TCP 头部结构)
- 结尾
前言
TCP 作为互联网最核心的传输层协议,其设计哲学可以用一句话概括:在保证数据可靠传输的前提下,尽可能地提高网络传输效率。为了实现这一目标,TCP 引入了一系列复杂而精妙的机制。在上一篇文章中,我们详细讲解了 TCP 的连接管理、确认应答和超时重传等基础可靠性机制。今天,我们将深入探讨 TCP 的性能优化核心 ------ 滑动窗口、拥塞控制,以及在此基础上衍生的延迟应答、捎带应答等高级特性,同时分析 TCP 面向字节流的特性带来的粘包问题及解决方案。本文将严格按照 TCP 协议的设计逻辑展开,从底层原理到实际应用,结合 Linux 内核源码片段进行解读,帮助你彻底掌握 TCP 协议的精髓,从容应对各类技术面试。
一. 滑动窗口:TCP 性能的基石
1.1 为什么需要滑动窗口
在介绍滑动窗口之前,我们先回顾一下最基础的确认应答机制:发送方每发送一个数据段,就必须等待接收方的 ACK 确认,收到确认后才能发送下一个数据段。这种 "一发一收" 的模式虽然简单可靠,但存在一个致命的缺点 ------性能极差,尤其是在网络往返时间 (RTT) 较长的情况下。
举个例子:假设 RTT 为 100ms,每个数据段大小为 1KB,那么这种模式下的传输速率最多只有 10KB/s,这在今天的千兆网络环境下显然是不可接受的。
解决方案:一次发送多个数据段,将多个段的等待时间重叠在一起。这就是滑动窗口机制的核心思想。

1.2 滑动窗口的工作原理
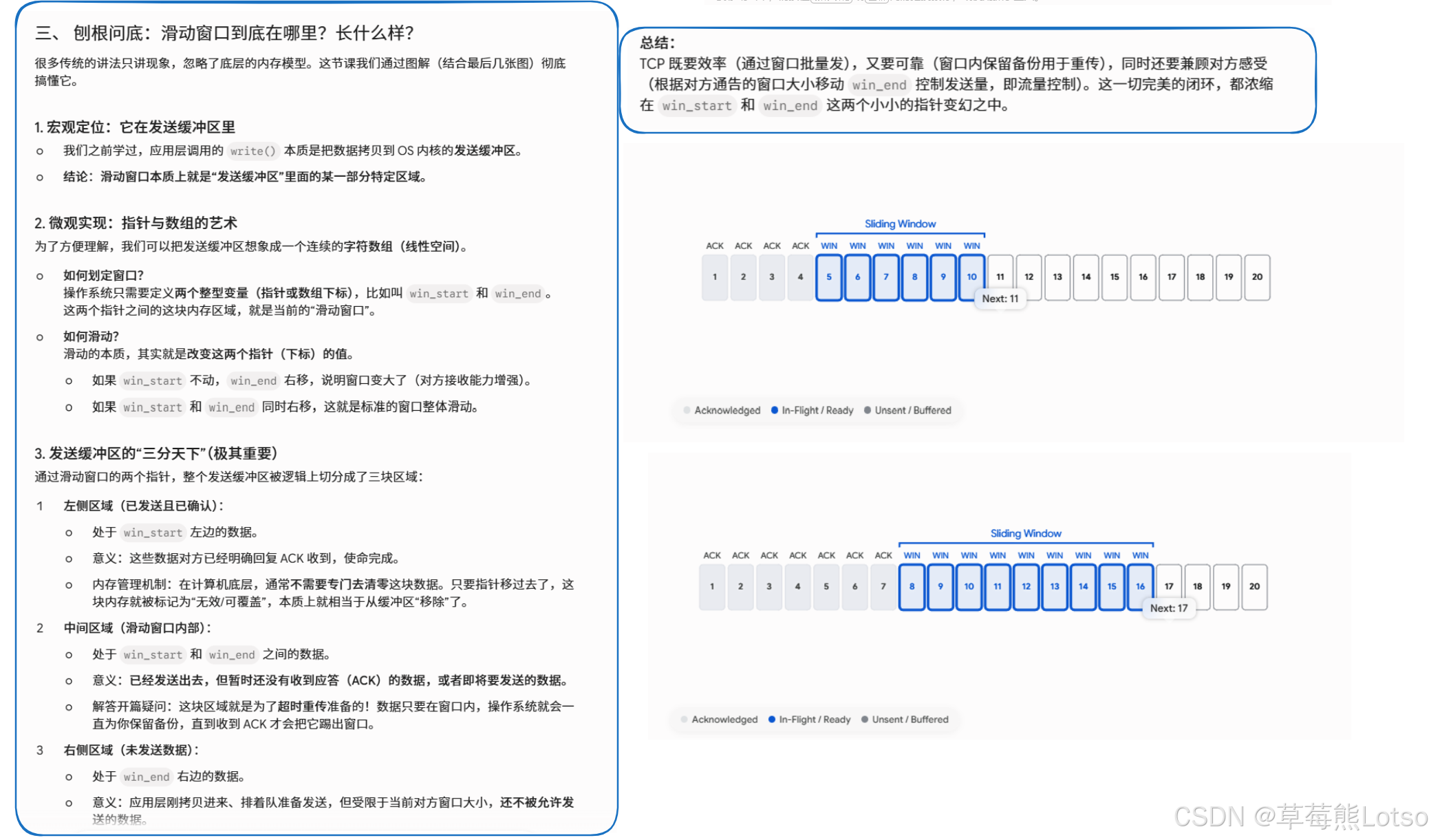
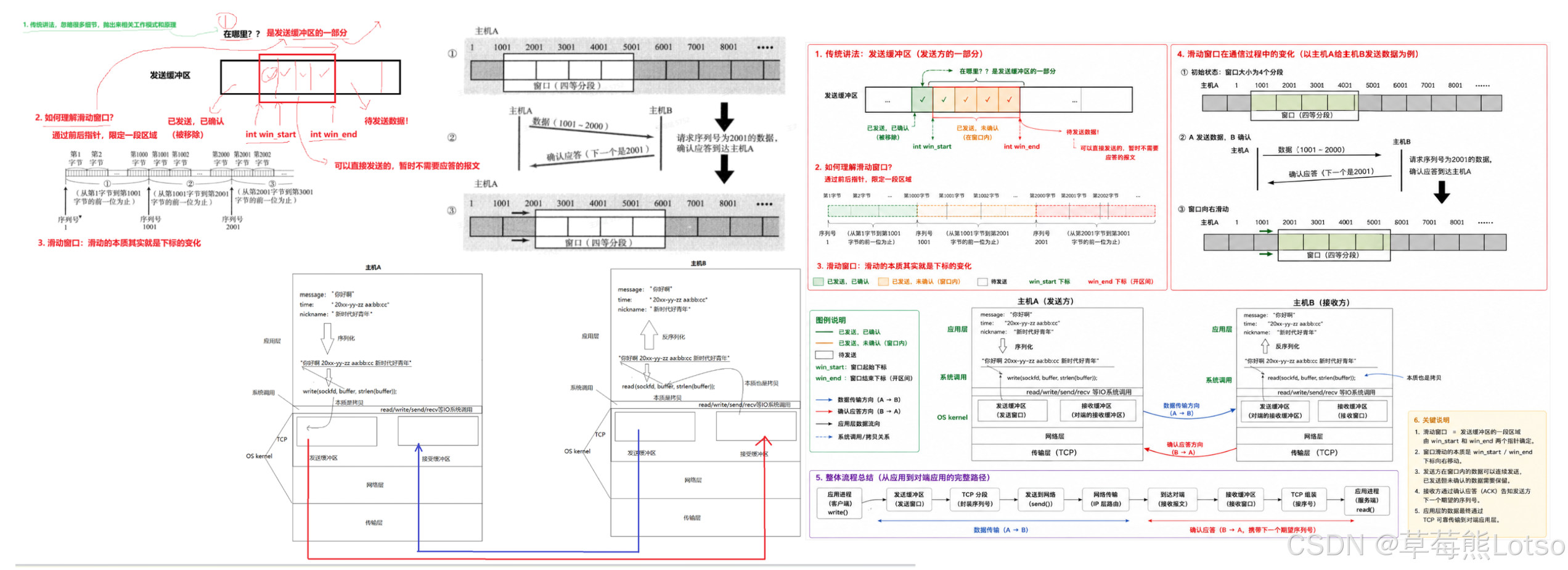
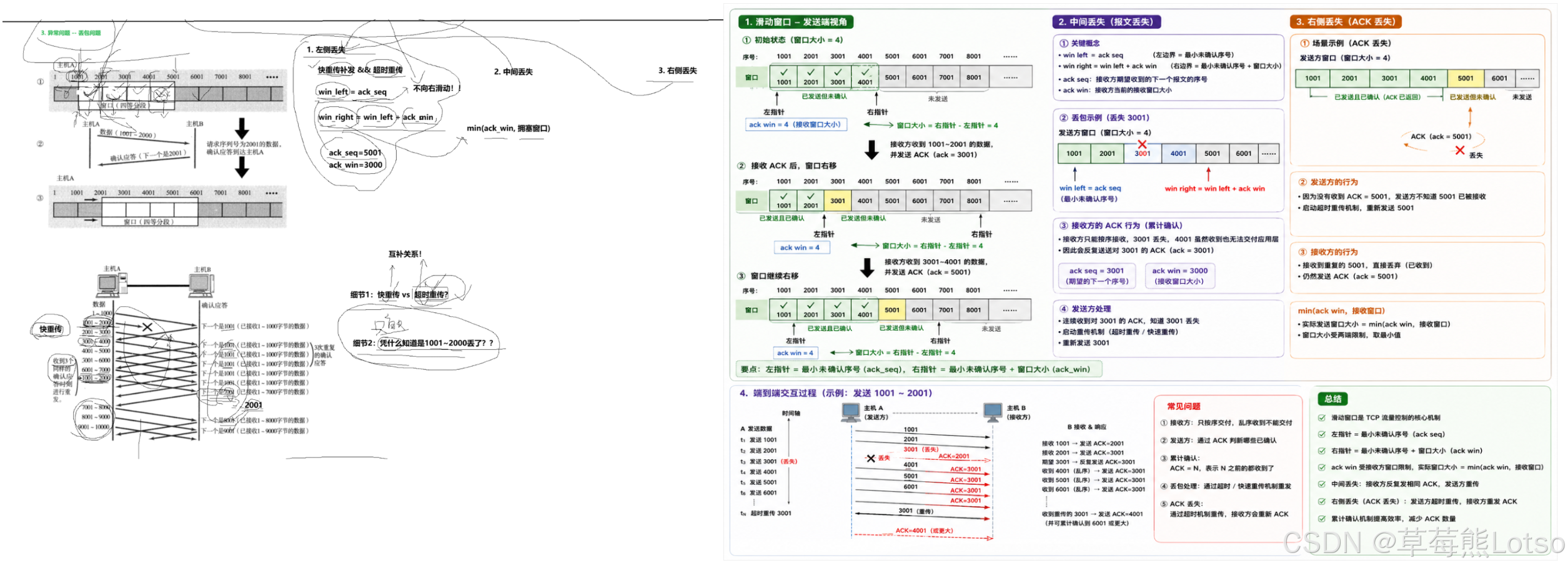
滑动窗口本质上是发送缓冲区中的一个可动态调整的区间,这个区间内的数据可以无需等待 ACK 确认而连续发送。窗口大小指的是无需等待确认应答而可以继续发送数据的最大值。
我们可以将发送缓冲区想象成一个线性的字符数组,通过两个指针 (win_left 和 win_right) 来界定滑动窗口的范围:
- win_left:指向已发送但未收到确认的第一个字节的序号
- win_right:指向可以发送的最后一个字节的下一个序号
滑动窗口将发送缓冲区分为三个部分:
- 已发送已确认:数据已经被接收方确认,可以从缓冲区中删除
- 已发送未确认:数据已经发送,但还没有收到接收方的确认
- 待发送:数据还没有发送,但可以在窗口滑动后发送
滑动的本质:当收到接收方的 ACK 确认时,win_left 指针会向右移动到确认序号的位置,同时 win_right 指针也会根据接收方通告的窗口大小相应地向右移动,这样窗口就整体向右滑动了。
1.3 滑动窗口的核心细节
1.3.1 窗口大小的决定因素
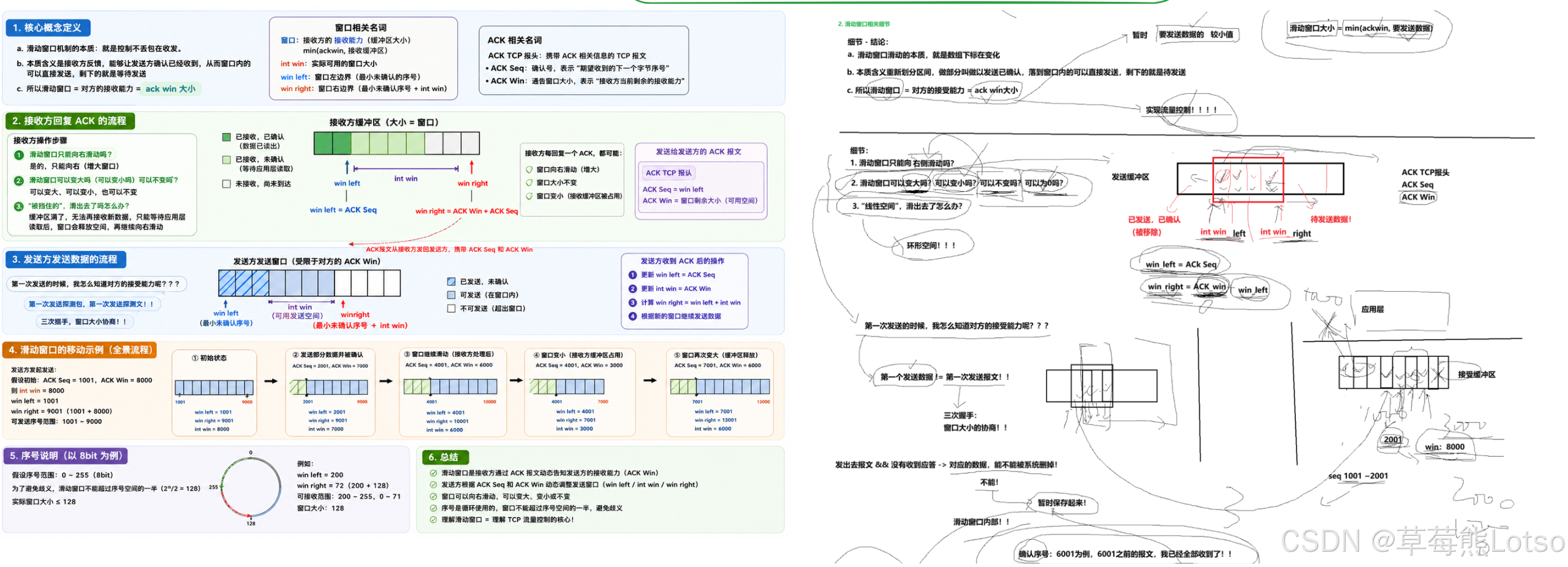
滑动窗口的大小不是固定不变的,它由两个因素共同决定:
- 接收方通告窗口 (ACK Win):接收方在 ACK 报头中携带的自己接收缓冲区的剩余空间大小
- 拥塞窗口 (Congestion Window):发送方根据网络拥塞情况估算的可以发送的数据量
实际发送窗口大小 = min (接收方通告窗口,拥塞窗口)
这一设计完美地兼顾了接收方的处理能力 和网络的承载能力,实现了 TCP 的流量控制功能。

1.3.2 窗口的动态变化
滑动窗口的大小可以动态调整:
- 当接收方应用程序读取数据的速度很快时,接收缓冲区剩余空间变大,ACK Win 增大,滑动窗口也随之变大
- 当接收方应用程序读取数据的速度很慢时,接收缓冲区逐渐被填满,ACK Win 减小,滑动窗口也随之变小
- 当接收缓冲区完全被填满时,ACK Win 变为 0,此时发送方将停止发送数据,直到收到接收方的窗口更新通知
1.3.3 缓冲区的环形抽象
如果滑动窗口一直向右滑动,会不会超出线性缓冲区的边界?答案是不会。TCP 内核会将发送缓冲区逻辑上抽象成一个环形空间,通过模运算来处理指针的越界问题。这样,即使窗口一直滑动,也不会出现缓冲区越界的情况。

1.4 丢包处理:快重传与超时重传
滑动窗口机制下的丢包处理是 TCP 可靠性的关键。我们分两种情况讨论:
1.4.1 ACK 丢失
如果数据包已经成功到达接收方,但 ACK 确认报文在传输过程中丢失了,这种情况其实并不可怕。因为 TCP 的确认应答具有累积确认的特性:后续的 ACK 会自动确认之前所有的数据。
例如:发送方发送了 1-1000、1001-2000、2001-3000 三个数据段,前两个 ACK 丢失了,但第三个 ACK (确认序号为 3001) 成功到达,那么发送方就知道前三个数据段都已经被接收方成功接收了。
1.4.2 数据包丢失
如果数据包本身在传输过程中丢失了,TCP 会通过快重传机制来处理:
- 接收方收到了后续的数据段,但发现中间有一个数据段丢失了
- 接收方会连续发送三个相同的 ACK,确认序号指向丢失数据段的起始序号
- 发送方收到三个相同的 ACK 后,会立即重传丢失的数据段,而不需要等待超时定时器到期
快重传的优势:大大减少了重传的等待时间,提高了传输效率。
超时重传的作用:作为兜底机制,当快重传无法触发时 (例如丢失的是最后一个数据段,没有后续的数据段来触发重复 ACK),超时重传会保证数据最终能够被重传。
快重传与超时重传的关系:两者是互补关系,快重传保证了传输效率的上限,超时重传保证了传输可靠性的下限。

二. 拥塞控制:网络的 "交通警察"
2.1 为什么需要拥塞控制
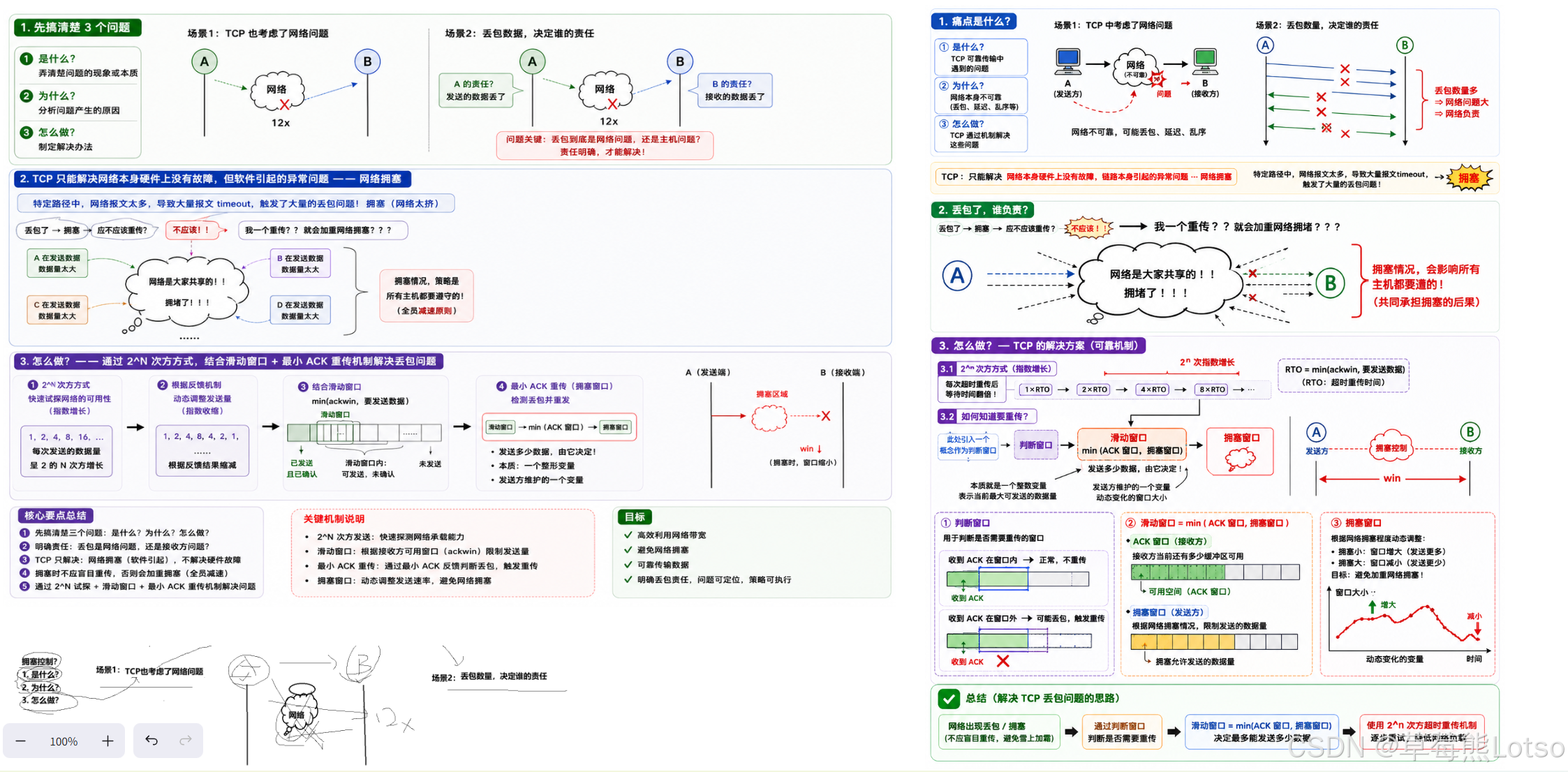
滑动窗口机制解决了接收方处理能力的问题,但没有考虑网络本身的承载能力。如果在网络已经拥塞的情况下,发送方仍然大量发送数据,会导致更多的数据包丢失,进而触发更多的重传,形成恶性循环,最终导致网络瘫痪。
TCP 的拥塞控制机制就是为了解决这个问题而设计的。它的核心思想是:发送方需要动态探测网络的拥塞情况,根据网络的实际承载能力调整发送速率 。

2.2 拥塞控制的核心机制
TCP 的拥塞控制主要由四个算法组成:慢启动 、拥塞避免 、快重传 和快恢复。我们重点讲解前两个。
2.2.1 慢启动 (Slow Start)
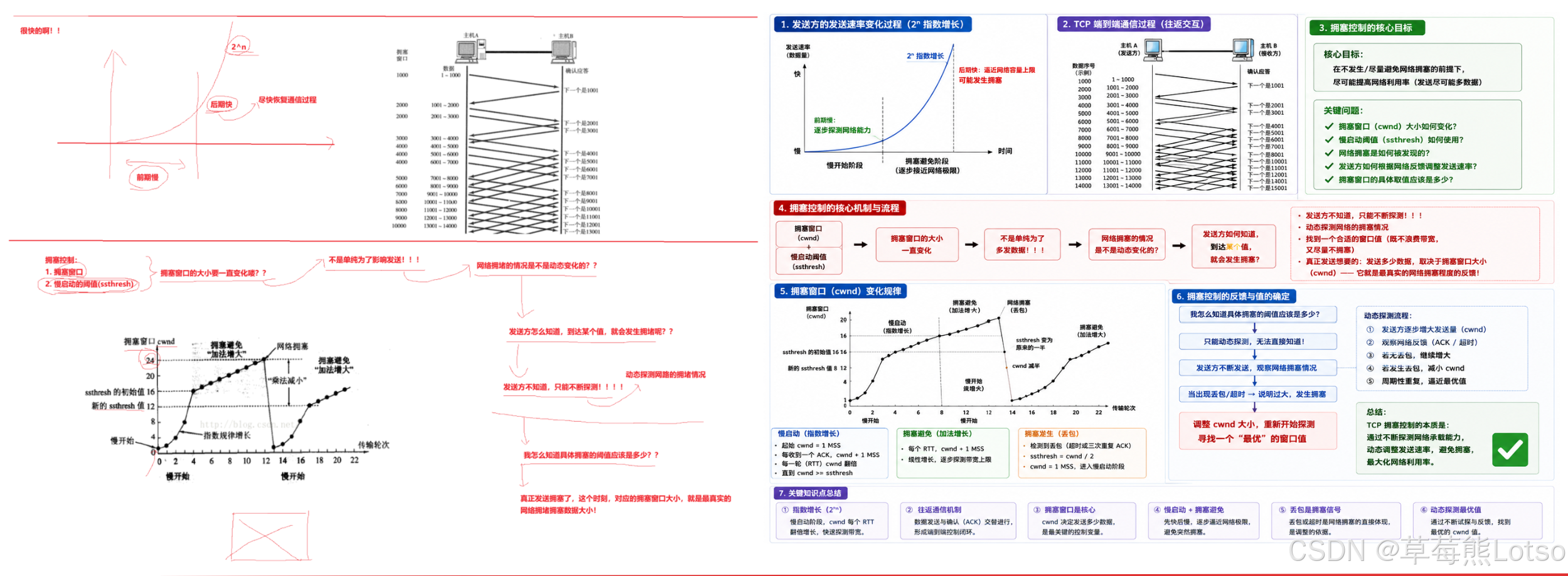
慢启动的 "慢" 并不是指增长速度慢,而是指初始发送速率慢。TCP 连接刚建立时,拥塞窗口 (cwnd) 的初始值为 1 个 MSS (最大报文段大小)。
慢启动的增长规则:
- 每收到一个 ACK 确认,拥塞窗口加 1
- 每经过一个 RTT,拥塞窗口翻倍 (指数增长)
这种指数级的增长速度非常快,能够迅速探测网络的可用带宽。但为了避免增长过快导致网络拥塞,TCP 引入了慢启动阈值 (ssthresh)。
2.2.2 拥塞避免 (Congestion Avoidance)
当拥塞窗口增长到慢启动阈值时,TCP 进入拥塞避免阶段。在这个阶段,拥塞窗口不再指数增长,而是线性增长:每经过一个 RTT,拥塞窗口增加 1 个 MSS。
这种线性增长的方式能够更加平稳地探测网络的剩余带宽,避免突然发送大量数据导致网络拥塞。
2.2.3 拥塞发生时的处理
当网络发生拥塞 (检测到丢包) 时,TCP 会执行以下操作:
- 将慢启动阈值 (ssthresh) 设置为当前拥塞窗口的一半
- 将拥塞窗口 (cwnd) 重置为 1 个 MSS
- 重新进入慢启动阶段
这个过程被称为乘法减小。通过这种方式,TCP 能够迅速降低发送速率,缓解网络拥塞。

2.3 拥塞控制的完整过程
TCP 拥塞控制的完整过程可以概括为:
- 慢启动阶段:cwnd 指数增长,直到达到 ssthresh
- 拥塞避免阶段:cwnd 线性增长,直到发生拥塞
- 拥塞处理阶段:ssthresh 减半,cwnd 重置为 1,重新进入慢启动
这个过程会不断循环,动态地调整发送速率,以适应网络状态的变化。
三. 延迟应答:让窗口更大一点
3.1 延迟应答的原理
延迟应答是 TCP 为了提高传输效率而设计的另一个重要机制。它的基本思想是:接收方收到数据后,不立即发送 ACK 确认,而是稍微等待一段时间。
为什么要这样做呢?我们来看一个例子:
- 假设接收端缓冲区大小为 1MB
- 一次收到了 500KB 的数据
- 如果立刻应答,返回的窗口大小就是 500KB
- 但如果接收端处理速度很快,10ms 之内就把 500KB 数据从缓冲区消费掉了
- 如果等待 200ms 再应答,返回的窗口大小就是 1MB
窗口越大,网络吞吐量就越大,传输效率就越高。延迟应答通过等待一段时间,让接收方有更多的时间处理数据,从而能够通告更大的窗口,提高整体传输效率。
3.2 延迟应答的实现机制
当然,并不是所有的数据包都可以无限期地延迟应答。TCP 通过两个限制条件来保证可靠性:
- 数量限制:每隔 N 个包就应答一次 (一般 N 取 2)
- 时间限制:超过最大延迟时间就应答一次 (一般取 200ms)
这两个条件是 "或" 的关系,只要满足其中一个,接收方就会发送 ACK 确认。

四. 捎带应答:ACK 搭个顺风车
4.1 捎带应答的原理
在延迟应答的基础上,TCP 又引入了捎带应答机制。在很多情况下,客户端和服务器在应用层是 "一发一收" 的模式:客户端给服务器发送一个请求,服务器给客户端返回一个响应。
捎带应答的思想是:将 ACK 确认报文和服务器的响应数据合并在同一个 TCP 报文段中发送。这样可以减少网络中传输的报文数量,进一步提高传输效率。
4.2 捎带应答的优势
- 减少报文数量:一个报文段既可以携带数据,又可以携带 ACK 确认
- 降低网络开销:减少了 TCP 报头的重复传输
- 提高传输效率:避免了单独发送 ACK 报文的额外开销
捎带应答是 TCP 中非常主流的内部策略,在实际应用中被广泛使用。

五. 面向字节流:TCP 的本质特性
5.1 TCP 缓冲区机制
创建一个 TCP socket 时,内核会同时为其创建一个发送缓冲区 和一个接收缓冲区:
- 调用 write () 时,数据会先写入发送缓冲区,然后由内核决定何时发送
- 如果发送的数据太长,会被拆分成多个 TCP 报文段发出
- 如果发送的数据太短,会先在缓冲区中等待,直到缓冲区长度合适或者其他合适的时机
- 接收数据时,数据会先到达内核的接收缓冲区,然后应用程序调用 read () 从缓冲区中读取数据
5.2 全双工通信
由于 TCP 连接同时拥有发送缓冲区和接收缓冲区,因此 TCP 是全双工的:在同一个连接上,双方可以同时发送和接收数据。
5.3 读写不匹配的特性
由于缓冲区的存在,TCP 程序的读和写不需要一一匹配:
- 写 100 个字节数据时,可以调用一次 write 写 100 个字节,也可以调用 100 次 write,每次写一个字节
- 读 100 个字节数据时,也完全不需要考虑写的时候是怎么写的,既可以一次 read 100 个字节,也可以一次 read 一个字节,重复 100 次
这种特性就是 TCP面向字节流的本质:TCP 只负责将字节流从一端可靠地传输到另一端,而不关心这些字节流的含义和边界。
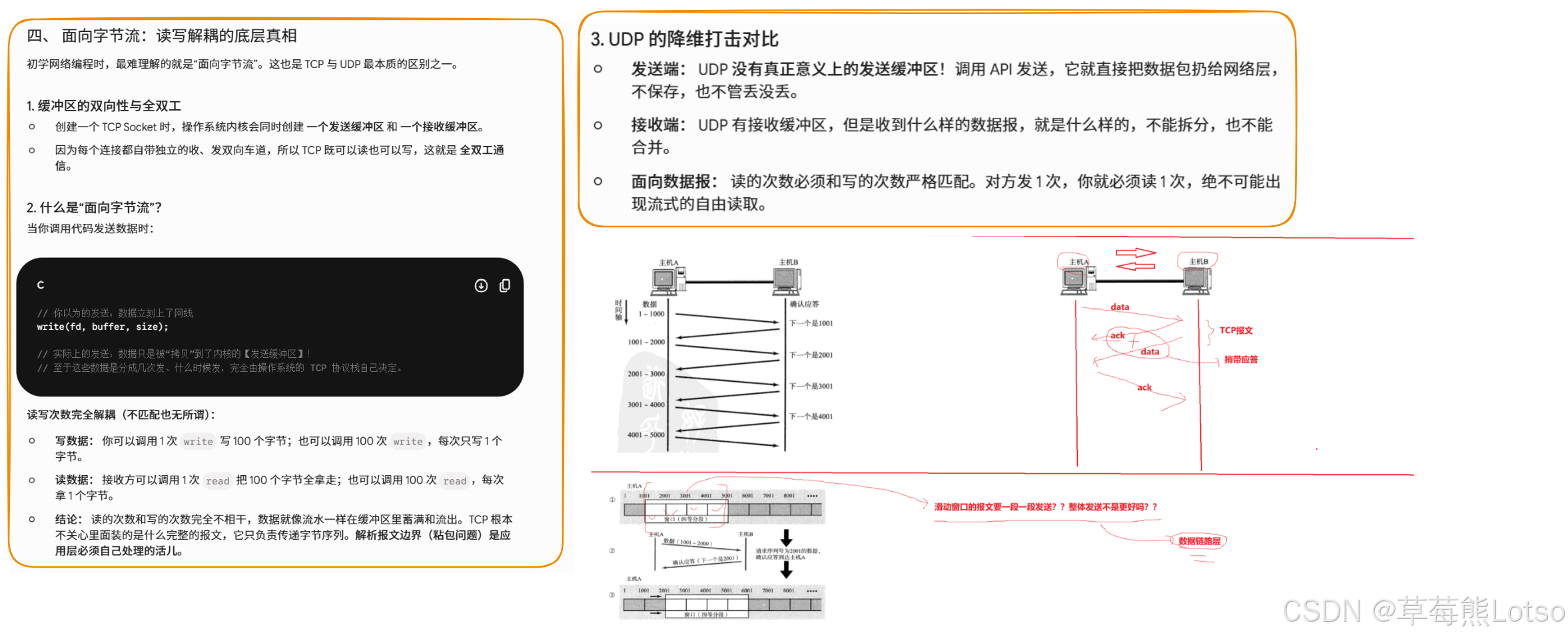
六. 粘包问题:面向字节流的 "副作用"
6.1 什么是粘包问题
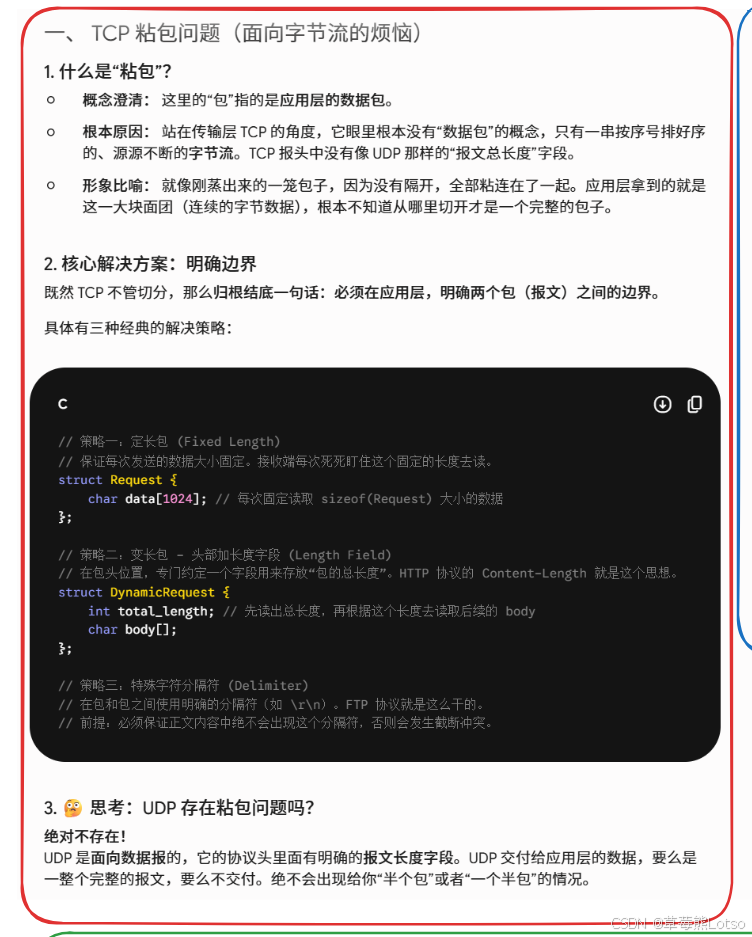
首先要明确:粘包问题中的 "包",指的是应用层的数据包,而不是 TCP 的报文段。
由于 TCP 是面向字节流的,它没有报文边界的概念。站在应用层的角度,看到的只是一串连续的字节数据,不知道从哪个部分开始到哪个部分是一个完整的应用层数据包。这就是粘包问题。
6.2 为什么会出现粘包问题
粘包问题的根本原因是 TCP 的面向字节流特性:
- 发送方可能将多个应用层数据包合并成一个 TCP 报文段发送
- 接收方可能将多个 TCP 报文段的数据合并在一起交给应用层
6.3 如何解决粘包问题
解决粘包问题的核心思想是:在应用层明确两个包之间的边界。常见的解决方案有三种:
- 定长包:约定每个应用层数据包的大小是固定的,接收方每次按固定大小读取即可
- 长度字段:在应用层数据包的头部添加一个长度字段,指明整个数据包的长度
- 特殊分隔符:在包和包之间使用特殊的分隔符,只要保证分隔符不会出现在正文中即可
6.4 UDP 为什么没有粘包问题
UDP 是面向数据报的,每个 UDP 报文段都有明确的长度字段。UDP 会将完整的报文段一次性交付给应用层,要么收到完整的 UDP 报文,要么不收,不会出现 "半个" 报文的情况。因此,UDP 不存在粘包问题。
七. TCP 异常情况处理
TCP 协议考虑了各种可能的异常情况,并提供了相应的处理机制:
7.1 进程终止
进程终止会释放文件描述符,内核会自动发送 FIN 报文,开始四次挥手过程,和正常关闭连接没有区别。
7.2 机器重启
机器重启时,操作系统会自动杀掉所有进程,释放所有文件描述符,同样会自动进行四次挥手,正常关闭连接。
7.3 机器掉电 / 网线断开
这种情况比较特殊,因为掉电的一方没有机会发送 FIN 报文。此时:
- 接收方认为连接还在
- 一旦接收方有写入操作,会发现连接已经不存在,发送 RST 报文重置连接
- 即使没有写入操作,TCP 内置的保活定时器会定期询问对方是否还在,如果对方不在,也会释放连接
保活机制的局限性:TCP 的保活定时器默认是分钟级或小时级的,检测周期很长。因此,在实际应用中,通常会在应用层实现自己的保活机制。


八. TCP vs UDP:没有最好,只有最合适
很多人会问:TCP 是可靠的,是不是 TCP 一定优于 UDP?答案是否定的。TCP 和 UDP 各有优缺点,适用于不同的场景。
| 特性 | TCP | UDP |
|---|---|---|
| 可靠性 | 可靠,保证数据按序到达 | 不可靠,可能丢包、乱序 |
| 连接性 | 面向连接,需要三次握手建立连接 | 无连接,不需要建立连接 |
| 传输效率 | 较低,有额外的开销 | 较高,没有额外的开销 |
| 流量控制 | 支持 | 不支持 |
| 拥塞控制 | 支持 | 不支持 |
| 适用场景 | 文件传输、重要状态更新、HTTP/HTTPS 等 | 视频传输、语音通话、游戏、广播等 |
归根结底,TCP 和 UDP 都是程序员的工具,选择哪一个取决于具体的需求场景。

九. 经典面试题:用 UDP 实现可靠传输
这是网络编程中最经典的面试题之一。其实,这个问题的本质是让你解释 TCP 的可靠性机制是如何实现的。
用 UDP 实现可靠传输,就是要在应用层实现 TCP 的核心可靠性机制:
- 引入序列号:为每个数据包分配一个唯一的序列号,保证数据按序到达
- 引入确认应答:接收方收到数据包后,发送 ACK 确认
- 引入超时重传:发送方发送数据包后启动定时器,如果超时没有收到 ACK,就重传数据包
- 实现滑动窗口:提高传输效率
- 实现拥塞控制:避免网络拥塞
十. 经典面试题:HTTP获取网页的完整过程
这是网络编程领域最高频的面试题之一,没有之一。它综合考察了 DNS 域名系统、TCP 传输控制协议、HTTP 应用层协议以及浏览器渲染原理等多个核心知识点,能够全面反映面试者对计算机网络体系结构的理解程度。
下面我们将从用户在浏览器地址栏输入 URL 并按下回车键的那一刻开始,一步步拆解整个过程的每一个细节。
10.1 整体流程概览
HTTP 获取网页的完整过程可以分为以下 7 个核心步骤:
- URL 解析:浏览器解析用户输入的 URL,提取出协议、域名、端口、路径等信息
- DNS 域名解析:将域名转换为对应的 IP 地址
- TCP 连接建立:与服务器建立 TCP 连接(三次握手)
- HTTP 请求发送:向服务器发送 HTTP 请求报文
- 服务器处理请求:服务器处理请求并生成 HTTP 响应报文
- HTTP 响应接收:客户端接收 HTTP 响应报文
- TCP 连接关闭:数据传输完成后关闭 TCP 连接(四次挥手)
- 浏览器渲染页面:浏览器解析 HTML、CSS、JavaScript 并渲染页面
10.2 详细步骤拆解
10.2.1 URL 解析
当用户在浏览器中输入http://www.example.com/index.html并按下回车键时,浏览器首先会对这个 URL 进行解析,提取出以下关键信息:
- 协议 :
http(表示使用 HTTP 协议) - 域名 :
www.example.com - 端口:默认 80 端口(HTTP 协议默认端口,HTTPS 默认 443 端口)
- 路径 :
/index.html(请求的资源路径)
如果 URL 中没有指定端口,浏览器会使用对应协议的默认端口。
10.2.2 DNS 域名解析
计算机网络中只能识别 IP 地址,不能直接识别域名。因此,浏览器需要将域名www.example.com转换为对应的 IP 地址,这个过程就是 DNS 域名解析。
DNS 解析采用递归查询 + 迭代查询相结合的方式:
- 浏览器缓存查询:浏览器首先检查自己的 DNS 缓存,看是否有该域名对应的 IP 地址
- 操作系统缓存查询:如果浏览器缓存中没有,检查操作系统的 DNS 缓存
- 本地 DNS 服务器查询:如果操作系统缓存中没有,向本地 DNS 服务器(通常由 ISP 提供)发送递归查询请求
- 根 DNS 服务器查询:如果本地 DNS 服务器缓存中没有,向根 DNS 服务器发送迭代查询请求
- 顶级域 DNS 服务器查询:根 DNS 服务器返回顶级域 DNS 服务器(.com 服务器)的地址
- 权威 DNS 服务器查询 :顶级域 DNS 服务器返回
example.com的权威 DNS 服务器地址 - 获取 IP 地址 :权威 DNS 服务器返回
www.example.com对应的 IP 地址
整个 DNS 解析过程是 UDP 协议的典型应用场景。
10.2.3 TCP 连接建立
获取到服务器的 IP 地址后,浏览器会与服务器的 80 端口建立 TCP 连接。这个过程就是我们之前详细讲解过的TCP 三次握手:
- 客户端向服务器发送 SYN 报文(同步报文段),请求建立连接
- 服务器收到 SYN 报文后,向客户端发送 SYN+ACK 报文,确认客户端的连接请求,并同时请求与客户端建立连接
- 客户端收到 SYN+ACK 报文后,向服务器发送 ACK 报文,确认服务器的连接请求
三次握手完成后,TCP 连接正式建立,双方可以开始传输数据。
注意 :在 HTTP/1.1 中,默认开启了长连接 (Keep-Alive),多个 HTTP 请求可以复用同一个 TCP 连接,避免了频繁建立和关闭 TCP 连接的开销。
10.2.4 HTTP 请求发送
TCP 连接建立后,浏览器会向服务器发送 HTTP 请求报文。一个完整的 HTTP 请求报文由以下四个部分组成:
-
请求行 :包含请求方法、请求路径和 HTTP 版本
1.PlainGET /index.html HTTP/1.1 -
请求头 :包含一系列键值对,向服务器传递客户端的信息
1.PlainHost: www.example.com User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3 Accept-Encoding: gzip, deflate Connection: keep-alive -
空行:用于分隔请求头和请求体
-
请求体:POST 请求会携带请求体,GET 请求没有请求体
在这个过程中,TCP 的滑动窗口 、确认应答 、超时重传等机制会保证 HTTP 请求报文可靠、高效地传输到服务器。
10.2.5 服务器处理请求
服务器收到 HTTP 请求报文后,会进行以下处理:
- 解析请求报文:提取请求方法、请求路径、请求头等信息
- 路由匹配:根据请求路径匹配对应的处理程序
- 处理请求:执行相应的业务逻辑,可能会查询数据库、读取文件等
- 生成 HTTP 响应报文:将处理结果封装成 HTTP 响应报文
一个完整的 HTTP 响应报文也由四个部分组成:
-
状态行 :包含 HTTP 版本、状态码和状态描述
1.PlainHTTP/1.1 200 OK -
响应头 :包含一系列键值对,向客户端传递服务器的信息
1.PlainServer: nginx/1.14.0 Date: Sat, 30 May 2026 12:00:00 GMT Content-Type: text/html; charset=utf-8 Content-Length: 1234 Connection: keep-alive -
空行:用于分隔响应头和响应体
-
响应体 :包含请求的资源内容,这里就是
index.html的 HTML 代码
10.2.6 HTTP 响应接收
客户端收到 HTTP 响应报文后,会进行以下处理:
- 解析响应报文:提取状态码、响应头和响应体
- 状态码判断 :根据状态码判断请求是否成功
- 200:请求成功
- 301/302:重定向
- 404:资源不存在
- 500:服务器内部错误
- 处理响应体:如果请求成功,将响应体中的 HTML 代码交给浏览器渲染引擎
同样,TCP 的各种可靠性机制会保证 HTTP 响应报文可靠地传输到客户端。
10.2.7 TCP 连接关闭
数据传输完成后,TCP 连接需要关闭。这个过程就是我们之前讲解过的TCP 四次挥手:
- 客户端向服务器发送 FIN 报文,请求关闭连接
- 服务器收到 FIN 报文后,向客户端发送 ACK 报文,确认客户端的关闭请求
- 服务器发送完所有数据后,向客户端发送 FIN 报文,请求关闭连接
- 客户端收到 FIN 报文后,向服务器发送 ACK 报文,确认服务器的关闭请求
四次挥手完成后,TCP 连接正式关闭。
注意:如果使用了 HTTP 长连接,TCP 连接不会立即关闭,而是会保持一段时间,等待后续的 HTTP 请求复用这个连接。
10.2.8 浏览器渲染页面
浏览器收到 HTML 代码后,会开始渲染页面:
- HTML 解析:将 HTML 代码解析成 DOM 树
- CSS 解析:将 CSS 代码解析成 CSSOM 树
- 渲染树构建:将 DOM 树和 CSSOM 树结合,构建成渲染树
- 布局:计算渲染树中每个节点的位置和大小
- 绘制:将渲染树中的节点绘制到屏幕上
- JavaScript 执行:如果页面中有 JavaScript 代码,会在适当的时机执行
如果页面中还有图片、CSS、JavaScript 等外部资源,浏览器会再次发起 HTTP 请求获取这些资源,这个过程和上面的步骤类似。
10.3 面试常考细节
- DNS 解析为什么使用 UDP 协议?
- UDP 协议开销小,速度快
- DNS 查询通常只需要一个请求和一个响应,不需要建立连接
- 如果 DNS 查询失败,可以通过超时重传机制来保证可靠性
- TCP 三次握手为什么不能改成两次?
- 防止已失效的连接请求报文段突然又传送到了服务器,导致服务器错误地建立连接
- 保证双方都知道对方的接收和发送能力正常
- TCP 四次挥手为什么不能改成三次?
- 因为 TCP 是全双工的,双方都需要独立地关闭连接
- 服务器收到客户端的 FIN 报文后,可能还有数据没有发送完,不能立即关闭连接
- HTTP 长连接和短连接的区别?
- 短连接:每次 HTTP 请求都需要建立一个新的 TCP 连接,请求完成后立即关闭连接
- 长连接:多个 HTTP 请求可以复用同一个 TCP 连接,减少了建立和关闭连接的开销
- HTTPS 和 HTTP 的区别?
- HTTPS 在 HTTP 和 TCP 之间加入了 SSL/TLS 层,提供了数据加密、身份认证和数据完整性保护
- HTTPS 默认使用 443 端口,HTTP 默认使用 80 端口
- HTTPS 需要申请 SSL 证书,HTTP 不需要
总结
HTTP 获取网页的过程是一个非常复杂但又非常基础的过程,它涉及到计算机网络体系结构的各个层次。理解这个过程,不仅能够帮助你深入理解 TCP 和 HTTP 协议的工作原理,还能够帮助你在实际开发中排查网络问题,优化网站性能。在面试中,面试官不仅会问整个流程,还会针对某个具体的步骤进行深入提问,比如 TCP 三次握手的细节、DNS 解析的过程、HTTP 请求和响应报文的结构等。因此,你需要对每个步骤都有深入的理解。
十一. 源码解读:TCP 头部结构
我们来看一下 Linux 内核中 TCP 头部的定义 (位于include/linux/tcp.h):
c
struct tcphdr {
__be16 source; // 源端口号
__be16 dest; // 目的端口号
__be32 seq; // 32位序号
__be32 ack_seq; // 32位确认序号
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u16 res1:4, // 保留位
doff:4, // TCP头部长度(以32位字为单位)
fin:1, // FIN标志位
syn:1, // SYN标志位
rst:1, // RST标志位
psh:1, // PSH标志位
ack:1, // ACK标志位
urg:1, // URG标志位
ece:1, // ECE标志位
cwr:1; // CWR标志位
#elif defined(__BIG_ENDIAN_BITFIELD)
__u16 doff:4,
res1:4,
cwr:1,
ece:1,
urg:1,
ack:1,
psh:1,
rst:1,
syn:1,
fin:1;
#else
#error "Adjust your <asm/byteorder.h> defines"
#endif
__be16 window; // 16位窗口大小
__sum16 check; // 16位校验和
__be16 urg_ptr; // 16位紧急指针
};关键字段解读:
doff:TCP 头部长度,以 32 位字 (4 字节) 为单位。没有选项的 TCP 头部长度是 20 字节 (doff=5),最大长度是 60 字节 (doff=15)- 标志位:
ACK:确认号是否有效SYN:请求建立连接FIN:通知对方本端要关闭连接RST:对方要求重新建立连接PSH:提示接收端应用程序立刻从 TCP 缓冲区把数据读走URG:紧急指针是否有效
window:接收方通告的窗口大小,用于流量控制
核心考点总结:
- 滑动窗口的工作原理和窗口大小的决定因素
- 快重传和超时重传的区别与联系
- 拥塞控制的四个阶段和核心算法
- 延迟应答和捎带应答的原理和优势
- 粘包问题的产生原因和解决方案
- TCP 异常情况的处理机制
- TCP 与 UDP 的区别和适用场景
- 用 UDP 实现可靠传输的基本思路
结尾
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:TCP 协议之所以复杂,是因为它要在不可靠的网络层之上,提供一个可靠、高效、有序的字节流传输服务。本文详细讲解了 TCP 的滑动窗口、拥塞控制、延迟应答、捎带应答等核心机制,分析了面向字节流特性带来的粘包问题及解决方案,同时介绍了 TCP 的异常处理机制和 TCP 与 UDP 的对比。掌握这些知识点,不仅能够让你深入理解 TCP 协议的工作原理,还能帮助你在网络编程中写出更加高效、稳定的代码,同时从容应对各类技术面试。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
