前言
Java 8 是 Java 发展史上里程碑式版本,除 Lambda、函数式接口外,Stream API 是最实用、开发高频使用的重量级特性。 在 Stream 诞生前,处理集合只能依靠传统 for 循环,充斥大量样板代码;而 Stream 以声明式流式流水线处理数据,代码简洁易读、天然支持并行计算,是后端开发、面试必掌握核心知识点。
一、什么是 Stream API
1.核心定义
Stream 并非数据存储容器,它是一套集合数据处理流水线工具 ,将集合 / 数组数据当作流水线上的原料,链式串联过滤、转换、排序、分组等加工步骤,最终输出处理结果。 底层依托 Lambda + 四大核心函数式接口(Predicate/Function/Consumer/Supplier)实现声明式编程:只描述要做什么,不关心底层循环实现。
2.传统循环 VS Stream 直观对比
例子:过滤长度大于 3 的字符串、转大写、升序排序
1)传统 for 循环写法(命令式,样板代码多)
java
List<String> words = Arrays.asList("about", "peter", "lambda");
List<String> result = new ArrayList<>();
// 手动循环、判断、存入临时容器
for (String word : words) {
if (word.length() > 3) {
String upperCase = word.toUpperCase();
result.add(upperCase);
}
}
// 单独调用排序工具类
Collections.sort(result);2)Stream 流式写法(声明式,链式连贯)
java
List<String> result = words.stream()
.filter(word -> word.length() > 3) // 过滤
.map(String::toUpperCase) // 转换大写
.sorted() // 排序
.collect(Collectors.toList()); // 收集结果3.流水线执行模型
原始List → stream()创建流 → filter过滤 → map转换 → sorted排序 → collect收集 → 最终集合 整个流程像工厂流水线,代码可读性接近自然语言,多步骤数据处理无需拆分循环。

二、Stream 两大操作类型
Stream 操作分为中间操作 、终端操作 ,核心特性:中间操作惰性执行,只有终端操作触发才会真正运算。
1. 中间操作
特征:调用后返回 Stream<T>,可无限链式拼接;仅记录操作逻辑,不会遍历数据。 如果只写中间操作、无终端操作,代码完全不会执行:
java
List<Integer> numbers = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
// 仅中间操作,无终端操作,过滤、平方逻辑完全不执行
numbers.stream()
.filter(n -> n > 3)
.map(n -> n * n);常用中间操作
| 方法 | 作用 | 入参函数式接口 |
|---|---|---|
filter() |
按条件过滤元素 | Predicate<T> |
map() |
元素类型转换 | Function<T,R> |
sorted() |
自然 / 自定义排序 | 无 / Comparator<T> |
distinct() |
去重(重写 equals/hashCode) | - |
limit(N) |
截取前 N 个元素 | - |
skip(N) |
跳过前 N 个元素 | - |
flatMap() |
扁平化嵌套集合 | Function<T,Stream<R>> |
2. 终端操作(触发计算)
特征:返回非 Stream 类型(集合、数字、布尔、void);调用后流直接失效,一个流只能消费一次 。 给上面代码补充 collect() 终端操作后,流水线才会执行:
java
List<Integer> res = numbers.stream()
.filter(n -> n > 3)
.map(n -> n * n)
.collect(Collectors.toList()); // 终端操作,启动流水线常用终端操作清单
- 收集类:
collect()(业务最核心,转 List/Map/ 分组) - 遍历类:
forEach() - 统计类:
count()、max()、min()、sum()、summaryStatistics() - 匹配查找类:
anyMatch()、allMatch()、noneMatch()、findFirst() - 归约计算:
reduce()
三、常见场景
场景 1:二分分组 partitioningBy(返回 Map<Boolean, List<T>>)
适用场景:奇偶、合格 / 不合格、满足 / 不满足两类数据划分 需求:过滤大于 3 的数字、求平方,按奇偶拆分两组
注意:这里之所以能够分成奇偶两组,是因为Map的key为Boolean类型,只能存放true、false(true存放满足断言条件的元素、false存放不满足断言条件的元素),要和后面的groupingBy进行区分,这个是可以分任意多组
java
List<Integer> numbers = Arrays.asList(1,2,3,4,5,6);
Map<Boolean, List<Integer>> partitioned = numbers.stream()
.filter(n -> n > 3) // 中间:过滤>3
.map(n -> n * n) // 中间:平方转换
.collect(Collectors.partitioningBy(n -> n % 2 == 0));执行流程:原始 1,2,3,4,5,6 → 过滤 4,5,6 → 平方 16,25,36 最终结果:{true=[16,36], false=[25]}
true:偶数集合,false:奇数集合
场景 2:数值一键多维度统计 summaryStatistics(商品销售统计案例)
适用场景:电商商品销量列表,一次性统计总销量、总销售额、均价、最高 / 最低单品销量
java
// 商品销量记录
List<Integer> salesVolume = Arrays.asList(120, 35, 289, 76, 155, 92);
IntSummaryStatistics salesStats = salesVolume.stream()
.mapToInt(Integer::intValue)
.summaryStatistics();
System.out.println("商品总条数:" + salesStats.getCount());
System.out.println("全店总销量:" + salesStats.getSum());
System.out.println("单品平均销量:" + salesStats.getAverage());
System.out.println("最高单品销量:" + salesStats.getMax());
System.out.println("最低单品销量:" + salesStats.getMin());拓展搭配过滤:只统计销量大于 100 的爆款商品数据
java
IntSummaryStatistics hotSalesStats = salesVolume.stream()
.filter(v -> v > 100)
.mapToInt(Integer::intValue)
.summaryStatistics();场景 3:对象集合分组 groupingBy(学生班级分组统计案例)
实体类:
java
static class Student {
private String studentName; // 学生姓名
private Integer score; // 考试分数
private String className; // 班级
// 构造、getter省略
public Student(String studentName, Integer score, String className) {
this.studentName = studentName;
this.score = score;
this.className = className;
}
public String getStudentName() { return studentName; }
public Integer getScore() { return score; }
public String getClassName() { return className; }
}测试数据:
java
List<Student> studentList = Arrays.asList(
new Student("小明", 88, "高一1班"),
new Student("小红", 95, "高一2班"),
new Student("小刚", 76, "高一1班"),
new Student("小丽", 91, "高一2班"),
new Student("小强", 65, "高一1班")
);1) 基础分组:按班级分组,每个班级对应全部学生列表
java
Map<String, List<Student>> classStudentMap = studentList.stream()
.collect(Collectors.groupingBy(Student::getClassName));2) 分组聚合:按班级分组,统计每个班级平均分
java
Map<String, Double> classAvgScoreMap = studentList.stream()
.collect(Collectors.groupingBy(
Student::getClassName,
Collectors.averagingInt(Student::getScore)
));3) 分组映射:按班级分组,仅收集该班所有学生姓名
Map<String, List<String>> classNameMap = studentList.stream()
.collect(Collectors.groupingBy(
Student::getClassName,
Collectors.mapping(Student::getStudentName, Collectors.toList())
));拓展进阶:分组 + 过滤,只统计各班及格(分数≥60)学生平均分
Map<String, Double> passAvgScore = studentList.stream()
.filter(s -> s.getScore() >= 60)
.collect(Collectors.groupingBy(
Student::getClassName,
Collectors.averagingInt(Student::getScore)
));拓展:Stream 的分组、聚合逻辑和 SQL 高度相似,开发中常用来处理数据库查询后的 List 数据,替代循环统计。
四、并行流 parallelStream:多核加速利器
1. 并行流作用
普通 stream() 是单线程串行处理;parallelStream() 自动利用多核 CPU,底层基于 JDK Fork/Join 框架,自动拆分任务、多线程并行计算,最后合并结果,一行代码实现并发处理。
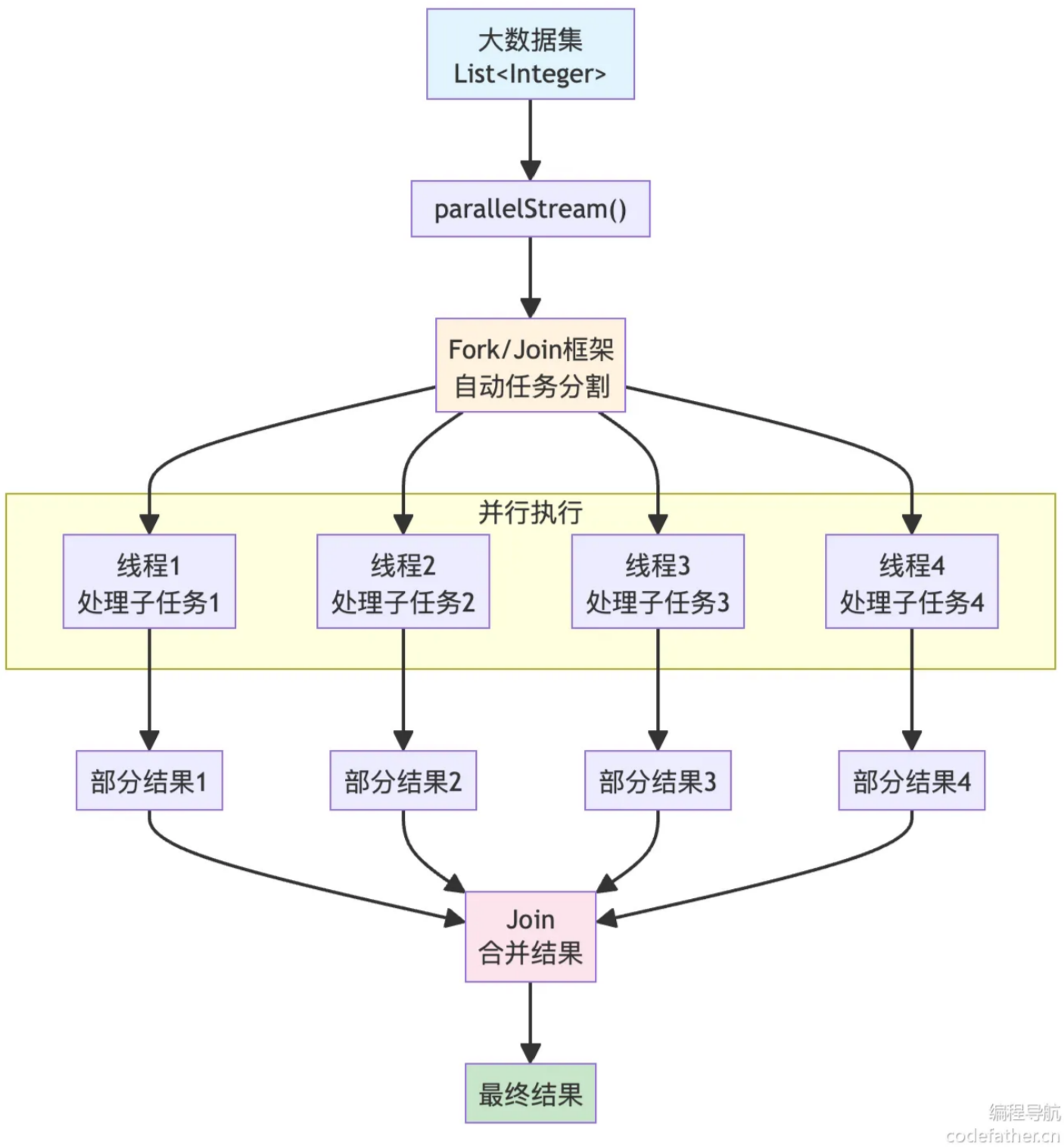
2. 使用示例:大数据量统计质数
// 生成1~10万数字集合
List<Integer> largeList = IntStream.rangeClosed(1, 100000)
.boxed()
.collect(Collectors.toList());
// 并行流统计质数总数
long parallelCount = largeList.parallelStream()
.filter(n -> isPrime(n)) // 自定义判断质数方法
.count();3. 生产环境慎用并行流的情况
-
共用全局线程池,阻塞会全局影响: 并行流默认使用
ForkJoinPool.commonPool(),线程数 = CPU 核心数 - 1;如果某个并行流发生 IO 阻塞、长时间占用线程,会拖慢项目中所有并行流任务。 -
小数据集 / 简单操作反而更慢: 线程创建、任务拆分、结果合并存在开销,数据量小、逻辑简单时,并行成本大于收益,速度不如串行流。
-
不保证有序: 并行遍历会打乱原有集合顺序,有序业务场景(分页、排序后遍历)禁止使用。
-
存在线程安全风险: 并行操作中不能直接操作非线程安全容器(ArrayList、HashMap),会出现并发异常;如需收集结果,使用线程安全收集器。
4.并行流适用场景
推荐:大数据量、CPU 密集型纯计算任务(数值运算、数据筛选转换)
禁止:IO 密集型任务(数据库查询、HTTP 接口调用)、有序业务、小数据集合