
🎬 个人主页 :艾莉丝努力练剑
❄专栏传送门 :《C语言》《数据结构与算法》《C/C++干货分享&学习过程记录》
《Linux操作系统编程详解》《笔试/面试常见算法:从基础到进阶》《Python干货分享》
⭐️为天地立心,为生民立命,为往圣继绝学,为万世开太平
🎬 艾莉丝的简介:

文章目录
- 前言
-
- [一、 开头部分(框架引入)](#一、 开头部分(框架引入))
-
- [1. 导入语](#1. 导入语)
- [2. 核心知识点概览](#2. 核心知识点概览)
- [1 ~> epoll 两种工作触发模式](#1 ~> epoll 两种工作触发模式)
-
- [1.1 LT 水平触发(默认模式)](#1.1 LT 水平触发(默认模式))
-
- [1.1.1 工作规则](#1.1.1 工作规则)
- [1.1.2 特性与场景](#1.1.2 特性与场景)
- [1.2 ET 边缘触发](#1.2 ET 边缘触发)
-
- [1.2.1 开启方式](#1.2.1 开启方式)
- [1.2.2 工作规则](#1.2.2 工作规则)
- [1.2.3 强制要求](#1.2.3 强制要求)
- [1.2.4 特性与场景](#1.2.4 特性与场景)
- [1.3 模式对比实测现象](#1.3 模式对比实测现象)
- [1.4 EPOLLONESHOT 单次触发模式](#1.4 EPOLLONESHOT 单次触发模式)
- [2 ~> epoll 工作模式的核心概念与直观模型](#2 ~> epoll 工作模式的核心概念与直观模型)
-
- [2.1 两种模式的定义与核心差异](#2.1 两种模式的定义与核心差异)
- [2.2 具象化类比:快递派发模型](#2.2 具象化类比:快递派发模型)
-
- [2.2.1 LT 模式:持续通知的快递员](#2.2.1 LT 模式:持续通知的快递员)
- [2.2.2 ET 模式:仅通知一次的快递员](#2.2.2 ET 模式:仅通知一次的快递员)
- [2.3 硬件溯源:示波器电平原理](#2.3 硬件溯源:示波器电平原理)
- [3 ~> 两种模式的底层工作机制与风险分析](#3 ~> 两种模式的底层工作机制与风险分析)
-
- [3.1 LT 模式的工作逻辑](#3.1 LT 模式的工作逻辑)
- [3.2 ET 模式的工作逻辑](#3.2 ET 模式的工作逻辑)
-
- [3.2.1 ET 模式的核心风险:数据残留与逻辑死锁](#3.2.1 ET 模式的核心风险:数据残留与逻辑死锁)
- [4 ~> ET 模式与非阻塞文件描述符的绑定逻辑](#4 ~> ET 模式与非阻塞文件描述符的绑定逻辑)
-
- [4.1 核心结论](#4.1 核心结论)
- [4.2 完整推导逻辑](#4.2 完整推导逻辑)
-
- [4.2.1 为什么必须循环读取](#4.2.1 为什么必须循环读取)
- [4.2.2 为什么必须设置非阻塞](#4.2.2 为什么必须设置非阻塞)
- [4.2.3 ET 模式标准读取范式](#4.2.3 ET 模式标准读取范式)
- [4.3 面试核心考点完整答题逻辑](#4.3 面试核心考点完整答题逻辑)
- [5 ~> ET 模式高效性的原理](#5 ~> ET 模式高效性的原理)
-
- [5.1 第一层:通知效率提升](#5.1 第一层:通知效率提升)
- [5.2 第二层:TCP 滑动窗口优化](#5.2 第二层:TCP 滑动窗口优化)
- [5.3 补充:LT 与 ET 的工程约束差异](#5.3 补充:LT 与 ET 的工程约束差异)
- [6 ~> 两种模式的工程实践与代码框架](#6 ~> 两种模式的工程实践与代码框架)
-
- [6.1 核心维度对比](#6.1 核心维度对比)
- [6.2 事件注册代码实现](#6.2 事件注册代码实现)
- [6.3 核心事件循环框架](#6.3 核心事件循环框架)
- [7 ~> 通过EpollServer代码演示epoll的两种工作模式](#7 ~> 通过EpollServer代码演示epoll的两种工作模式)
-
- [7.1 代码(EpollServer.hpp)](#7.1 代码(EpollServer.hpp))
- [7.2 两种工作模式的演示](#7.2 两种工作模式的演示)
-
- [7.2.1 LT模式(默认模式)](#7.2.1 LT模式(默认模式))
- [7.2.2 ET模式(需要手动设置)](#7.2.2 ET模式(需要手动设置))
- [8 ~> epoll的两种工作模式:知识图谱](#8 ~> epoll的两种工作模式:知识图谱)
- [9 ~> 深度总结与核心考点复盘](#9 ~> 深度总结与核心考点复盘)
- 结尾

前言
一、 开头部分(框架引入)
1. 导入语
在 Linux 高性能网络编程体系中,epoll 是 IO 多路转接技术的工业级标准实现,而水平触发(LT)与边缘触发(ET)是 epoll 最核心的两种工作模式,二者直接决定了内核事件通知的行为逻辑、服务器的并发吞吐上限,以及上层应用的编码范式。本文从直观类比、硬件溯源、底层机制、工程约束、性能原理五个维度完整拆解两种模式的全部细节,覆盖面试核心考点与工程实践陷阱,适用于体系化复习与漏洞排查。
2. 核心知识点概览
bash
epoll 两种工作模式核心体系
┣━━ 基础概念层
┃ ┣━━ 🔹 水平触发(Level Triggered, LT)
┃ ┗━━ 🔹 边缘触发(Edge Triggered, ET)
┣━━ 直观模型与硬件溯源
┃ ┣━━ 快递派发类比模型
┃ ┃ ┣━━ LT:缓冲区有数据就持续通知
┃ ┃ ┗━━ ET:仅数据状态变化时通知一次
┃ ┗━━ 示波器电平原理
┃ ┣━━ LT:高电平持续触发
┃ ┗━━ ET:电平跳变沿触发
┣━━ 底层工作机制
┃ ┣━━ LT:数据非空则持续返回就绪事件
┃ ┣━━ ET:仅数据增量变化时触发一次
┃ ┗━━ 风险:ET未读完数据会残留且不再通知
┣━━ ET 模式工程约束
┃ ┣━━ 强制要求:文件描述符必须设为非阻塞
┃ ┣━━ 编码范式:循环读取直至返回 EAGAIN
┃ ┗━━ 风险根源:阻塞读无数据时会挂起进程
┣━━ 性能差异深层原理
┃ ┣━━ 通知效率:ET消除冗余通知,降低系统调用开销
┃ ┗━━ TCP优化:快速清空缓冲区,通告更大滑动窗口
┗━━ 工程实践对比
┣━━ LT:编码简单、兼容阻塞IO、稳定性高
┗━━ ET:编码要求高、性能上限高、强行为约束1 ~> epoll 两种工作触发模式
epoll 支持**水平触发(LT)与边缘触发(ET)**两种模式,select、poll 仅等价于 LT 模式。
1.1 LT 水平触发(默认模式)
1.1.1 工作规则
只要 fd 对应的缓冲区存在未处理的就绪数据 ,epoll_wait 就会持续返回该事件,直到数据被完全读取/状态恢复。
1.1.2 特性与场景
- 优点:逻辑简单、代码容错率高,阻塞/非阻塞 IO 均可配合使用。
- 缺点:若业务代码处理不及时,会导致
epoll_wait频繁触发事件,占用 CPU。 - 默认状态:epoll 不设置
EPOLLET标志时,即为 LT 模式。
1.2 ET 边缘触发
1.2.1 开启方式
在注册事件时,通过位或添加 EPOLLET 标志,示例:
c
ev.events = EPOLLIN | EPOLLET;1.2.2 工作规则
仅在 fd 状态发生突变的瞬间触发一次事件:例如空缓冲区收到数据、满缓冲区变为可写。若本次未读完数据,剩余数据不会再次触发事件。
1.2.3 强制要求
ET 模式必须配合非阻塞 IO使用。单次事件触发后,需要循环读写直到缓冲区无数据/无空间,否则会造成数据滞留。
1.2.4 特性与场景
- 优点:事件触发次数最少,CPU 占用低,适合超高并发场景。
- 缺点:代码复杂度高,对 IO 读写逻辑要求严格。
1.3 模式对比实测现象
- LT 模式:客户端发送一次数据,服务端若只读取部分内容,
epoll_wait会反复通知读事件,日志持续刷屏。 - ET 模式:客户端发送一次数据,仅在数据到达瞬间触发一次事件,剩余数据不会再次通知。
1.4 EPOLLONESHOT 单次触发模式
该标志可与 LT/ET 组合使用。事件触发后,该 fd 会被 epoll 自动屏蔽,不再接收任何事件。若需要继续监听,必须调用 epoll_ctl(EPOLL_CTL_MOD) 重新配置事件。常用于多线程模型,保证一个 fd 同一时间仅被一个线程处理。
2 ~> epoll 工作模式的核心概念与直观模型
2.1 两种模式的定义与核心差异
epoll 作为 Linux 内核提供的 IO 多路转接接口,核心能力是批量监控大量文件描述符的 IO 就绪状态,并将就绪事件返回给应用层。根据内核通知就绪事件的触发条件不同,划分为两种工作模式:
- 水平触发(Level Triggered, LT):只要文件描述符对应的内核缓冲区中存在未处理的数据,内核就会持续向应用层通知该文件描述符的就绪状态,直至数据被全部读取。
- 边缘触发(Edge Triggered, ET):仅当文件描述符的状态发生跳变(即数据从无到有、数据量从少到多)的瞬间,内核才会向应用层发送一次就绪通知;若本次通知后应用层未将数据全部读取,内核不会再重复通知,直至下一次新数据到达。
2.2 具象化类比:快递派发模型
以快递员派发包裹的场景做映射理解:快递对应内核缓冲区的数据,快递员的通知电话对应内核的就绪事件,收件人对应应用层程序。
2.2.1 LT 模式:持续通知的快递员
该模式下的快递员责任心极强,只要三轮车上还留有收件人的未取包裹,就会反复拨打电话通知收件人取件;即便收件人每次只取走部分包裹,快递员也会持续致电,直至所有包裹全部被取走。 对应技术逻辑:只要接收缓冲区中存在未读数据,epoll_wait就会持续返回该文件描述符的就绪事件,应用层可以分多次读取数据,不存在数据遗漏的风险。
2.2.2 ET 模式:仅通知一次的快递员
该模式下的快递员仅在新包裹到达、包裹数量发生变化时拨打一次电话,无论收件人是否取件、是否取完,都不会再次致电;若收件人本次未取完包裹,只能等待下一批新包裹到达时,才会再次收到通知。 对应技术逻辑:仅当内核缓冲区的数据量发生增量变化时,才会触发一次就绪通知;若应用层本次未将缓冲区数据全部读取,剩余数据会一直驻留在内核缓冲区,且不会再触发新的就绪事件,存在数据残留甚至丢失的风险。
2.3 硬件溯源:示波器电平原理
两种模式的命名与设计逻辑,源自硬件电路与示波器中的电平触发机制,是软件设计对硬件思想的直接借鉴:
- 水平触发:对应示波器的高电平触发规则,只要信号维持在高电平区间,就会持续触发采样。对应到软件中,只要缓冲区数据非空(处于 "有数据" 的高电平状态),就持续触发就绪通知。
- 边缘触发:对应示波器的边沿触发规则,仅在信号从低电平跳转到高电平(上升沿)、或从高电平跳转到低电平(下降沿)的瞬间触发一次采样。对应到软件中,仅在数据状态发生跳变(无数据→有数据、少数据→多数据)的瞬间触发一次就绪通知。
3 ~> 两种模式的底层工作机制与风险分析
3.1 LT 模式的工作逻辑
LT 是 epoll 的默认工作模式,行为逻辑与 select、poll 保持一致,具备最好的兼容性:
- 当内核接收缓冲区收到新数据,缓冲区从空变为非空,
epoll_wait返回该文件描述符的读就绪事件。 - 若应用层本次只读取了部分数据,缓冲区仍有剩余数据,下一次调用
epoll_wait时,会立刻再次返回该文件描述符的就绪事件。 - 只要缓冲区数据未被清空,就绪通知就会持续触发,不存在数据被遗漏的可能。
LT 模式的编码门槛极低,兼容阻塞式 IO,应用层无需一次性读完所有数据,即便单次读取不完整,后续仍有机会继续读取,因此不易出现逻辑漏洞。
3.2 ET 模式的工作逻辑
ET 是 epoll 的高性能增强模式,触发条件严格限定为 "状态变化":
- 仅当缓冲区的数据量发生增量变化(新数据到达)时,才会产生一次就绪通知;数据被读取导致数据量减少,不会触发通知。
- 单次通知后,无论应用层是否读取数据、读取多少数据,内核都不会再重复发送该批次数据的就绪通知。
- 只有当下一批新数据到达,缓冲区数据量再次增加时,才会触发新的一次通知。
3.2.1 ET 模式的核心风险:数据残留与逻辑死锁
ET 模式存在明确的工程风险,若配合阻塞式 IO 使用,会直接导致数据残留,甚至引发业务逻辑死锁。 以典型的请求 - 响应模型为例:服务器需接收客户端 10KB 请求并处理完成后才返回响应,客户端只有收到响应后才会发送下一个请求:
- 客户端发送 10KB 数据到达服务器内核缓冲区,ET 模式触发一次就绪通知。
- 服务器使用阻塞
read,单次仅读取 1KB 数据,剩余 9KB 驻留在内核缓冲区。 - 由于缓冲区数据量没有发生新的增量变化,ET 模式不会再次触发就绪通知,
epoll_wait不会再返回该文件描述符。 - 服务器等待新的就绪通知来读取剩余 9KB 数据,而客户端等待服务器返回响应才会发送新数据,双方进入互相等待的死锁状态,9KB 数据永久残留。
该风险的本质是:ET 模式不会为 "已通知但未读完" 的数据重复发送事件,若应用层无法保证单次读完所有数据,就必须通过特定编码范式规避风险。
4 ~> ET 模式与非阻塞文件描述符的绑定逻辑
4.1 核心结论
在工程实践中,使用 ET 模式的 epoll,必须将对应的文件描述符设置为非阻塞模式。这并非接口语法的强制约束,而是避免进程挂起、保证数据完整读取的工程必要条件。
4.2 完整推导逻辑
4.2.1 为什么必须循环读取
ET 模式仅通知一次的特性,要求应用层在收到就绪通知后,必须将本次到达的所有数据全部从内核缓冲区读取到用户空间,否则剩余数据将无法再被触发读取。 由于应用层无法预先知道内核缓冲区中总共有多少数据,因此必须采用循环读取的方式,反复调用read接口,直至确认缓冲区已空。
4.2.2 为什么必须设置非阻塞
若文件描述符为阻塞模式,在循环读取的最后一轮,当内核缓冲区的数据已被全部读完时,read调用会进入阻塞状态,导致当前进程 / 线程被挂起,无法继续处理其他文件描述符的事件,整个事件循环直接卡死。 而将文件描述符设置为非阻塞后,当缓冲区无数据时,read会立即返回,并设置errno为EAGAIN或EWOULDBLOCK,以此作为数据读取完毕的标志,循环终止,进程可继续执行后续逻辑。
4.2.3 ET 模式标准读取范式
ET 模式下的读事件处理,必须遵循 "非阻塞 fd + 循环读取 + 错误码判断" 的固定范式,核心实现如下:
c
// ET模式读事件处理标准流程
void handle_read(int fd) {
char buf[BUFFER_SIZE];
while (1) {
ssize_t n = read(fd, buf, sizeof(buf));
if (n > 0) {
// 正常读取到数据,执行业务处理
process_data(buf, n);
} else if (n == 0) {
// 对端关闭连接,执行资源清理
close_connection(fd);
break;
} else {
// 非阻塞模式下缓冲区已空,本次读取结束
if (errno == EAGAIN || errno == EWOULDBLOCK) {
break;
}
// 发生真实读取错误,执行错误处理
handle_read_error(fd);
break;
}
}
}4.3 面试核心考点完整答题逻辑
为什么 ET 模式下必须将文件描述符设置为非阻塞模式,完整逻辑链如下:
- ET 模式仅在数据状态发生增量变化时触发一次通知,因此要求应用层必须在本次通知中读完所有缓冲区数据,否则剩余数据无法再被触发读取。
- 由于应用层无法预知缓冲区数据总量,必须采用循环读取的方式反复调用
read。 - 若文件描述符为阻塞模式,最后一次无数据的
read调用会导致进程阻塞挂起,整个事件循环失效。 - 因此必须将 fd 设置为非阻塞,通过
read返回EAGAIN来判定数据读取完毕,既保证数据全部读出,又避免进程阻塞。
5 ~> ET 模式高效性的原理
ET 模式被公认为高性能服务器的首选方案,其高效性并非单一因素决定,而是由两层机制共同作用的结果。
5.1 第一层:通知效率提升
LT 模式下,只要缓冲区有数据就会持续发送就绪通知,若应用层读取不及时,会产生大量重复的冗余通知,对应频繁的系统调用与内核态 / 用户态切换开销。 ET 模式仅在数据增量变化时发送一次通知,有效通知占比极高,彻底消除了重复通知带来的冗余系统调用开销,降低了内核的事件分发成本。
5.2 第二层:TCP 滑动窗口优化
ET 模式倒逼应用层尽快将数据从内核缓冲区读取到用户空间,使得接收缓冲区可以更快地腾出可用空间。 从 TCP 协议层面看,接收方会根据接收缓冲区的剩余空间向发送方通告窗口大小(Window Size)。接收缓冲区清空越快,可通告的窗口就越大,发送方就可以一次性发送更多的数据,从而提升单位时间内的网络传输吞吐量,降低 ACK 交互的频次开销。
5.3 补充:LT 与 ET 的工程约束差异
LT 模式同样可以采用非阻塞 + 循环读的编码方式,也能实现快速清空缓冲区的效果,但 LT 模式本身不会强制开发者这么做;而 ET 模式从机制上倒逼上层必须采用最优的读取范式。 在大型团队协作中,ET 模式的行为强约束更易保证代码的性能下限,这也是其工程层面的不可替代性。
6 ~> 两种模式的工程实践与代码框架
6.1 核心维度对比
| 对比维度 | 水平触发(LT) | 边缘触发(ET) |
|---|---|---|
| 触发条件 | 缓冲区非空则持续触发 | 仅数据量增量变化时触发一次 |
| 默认属性 | epoll 默认模式 | 需显式设置EPOLLET标志 |
| IO 兼容性 | 兼容阻塞 IO 与非阻塞 IO | 必须配合非阻塞 IO 使用 |
| 编码复杂度 | 低,逻辑简单不易出错 | 高,必须遵循循环读范式 |
| 数据安全性 | 无数据残留风险 | 编码不当易导致数据丢失 |
| 系统调用开销 | 存在冗余通知,开销较高 | 无冗余通知,开销更低 |
| 性能上限 | 较低 | 更高,适用于高并发场景 |
| 适用场景 | 业务复杂、追求稳定性 | 高性能框架、极致并发优化 |
6.2 事件注册代码实现
默认情况下,向 epoll 实例中添加文件描述符为 LT 模式;若需启用 ET 模式,需在事件字段中按位或上EPOLLET标志:
cpp
// 添加监听套接字到epoll(默认LT模式)
struct epoll_event ev;
ev.events = EPOLLIN; // 监听读事件,默认水平触发
ev.data.fd = listen_sock;
int ret = epoll_ctl(epfd, EPOLL_CTL_ADD, listen_sock, &ev);
// 启用边缘触发模式
struct epoll_event et_ev;
et_ev.events = EPOLLIN | EPOLLET; // 读事件 + 边缘触发
et_ev.data.fd = conn_sock;
epoll_ctl(epfd, EPOLL_CTL_ADD, conn_sock, &et_ev);6.3 核心事件循环框架
epoll 的核心事件循环逻辑如下,两种模式的差异仅体现在事件处理函数的内部实现:
cpp
const int MAX_EVENTS = 1024;
struct epoll_event revs[MAX_EVENTS];
int timeout = -1; // 阻塞等待,直到有事件就绪
while (true) {
int n = epoll_wait(epfd, revs, MAX_EVENTS, timeout);
if (n == 0) {
// 超时,无就绪事件
continue;
} else if (n < 0) {
// 调用出错,处理错误逻辑
if (errno == EINTR) continue; // 被信号中断,重试
break;
}
// 遍历所有就绪事件,逐个处理
for (int i = 0; i < n; ++i) {
int sockfd = revs[i].data.fd;
if (revs[i].events & EPOLLIN) {
// 读事件就绪,根据模式调用对应处理函数
handle_io_event(sockfd);
}
// 其他事件处理(EPOLLOUT、EPOLLERR等)
}
}7 ~> 通过EpollServer代码演示epoll的两种工作模式
7.1 代码(EpollServer.hpp)
cpp
#pragma once
#include <iostream>
#include <memory>
#include <sys/epoll.h>
#include "Socket.hpp"
static const uint16_t gport = 8080;
static const int gsize = 128;
static const int gnum = 64;
class EpollServer
{
public:
EpollServer(uint16_t port = gport)
: _port(port),
_listensockfd(std::make_unique<TcpSocket>())
{
// 监听套接字
_listensockfd->BuildSocketMethod(_port);
// 创建epoll模型
_epfd = epoll_create(gsize);
if(_epfd < 0)
{
// 创建epoll失败
LOG(LogLevel::ERROR) << "epoll_creare error";
exit(1);
}
LOG(LogLevel::INFO) << "listen sockfd: " << _listensockfd->Socketfd() << "epfd: " << _epfd; // 走到这步就创建成功了
}
void Accepter()
{
InetAddr clientaddr;
int sockfd = _listensockfd->Accepter(&clientaddr);
LOG(LogLevel::INFO) << "sockfd is : " << sockfd << "client addr: " << clientaddr.StringAddress();
// 能不能recv(sockfd)? 不能! 因为还没有把这个sockfd添加到epoll中! 只能等到下次事件就绪了才能recv了!
// sockfd,读取数据? 不能! 因为还没有把这个sockfd添加到epoll中! 只能等到下次事件就绪了才能recv了!
// IO = 等 + 拷贝,把sockfd托管给epoll!等事件就绪了,才去recv数据! 这样就不会阻塞了! 这就是IO多路复用的核心思想!
struct epoll_event ev;
ev.events = EPOLLIN; // 监听读事件
ev.data.fd = sockfd; // 用户数据
int m = epoll_ctl(_epfd,EPOLL_CTL_ADD,sockfd,&ev);
// 至此红黑树就有两个节点了!一个是listen sockfd,一个是刚刚accept到的sockfd!
// 当这两个sockfd有事件就绪了,都会通知我们!我们就可以去处理了!
// 因为全是回调,没有循环,节点越来越多,但是我们不需要担心,因为红黑树的查找效率是O(logN),
// 所以即使有成千上万个节点,我们也能在很短的时间内找到我们需要的节点!这就是epoll的优势!所以我们不需要担心节点越来越多了!
// 我们只需要关注事件就绪了就去处理就好了!
// 即钓鱼的鱼竿数量多了,单位时间上鱼的概率高了!
(void)m;
LOG(LogLevel::DEBUG) << "epoll_ctl add event: " << sockfd;
}
void IOHandler(int fd)
{
// 怎么读呢?直接读取就可以了!因为这个fd已经被epoll托管了!
// 当这个fd有数据就绪了,epoll就会通知我们!我们就可以去读取数据了!这就是IO多路复用的核心思想!
char buffer[1024]; // BUG!
ssize_t n = recv(fd,buffer,sizeof(buffer) - 1,0);
if(n > 0)
{
buffer[n] = 0;
LOG(LogLevel::INFO) << "client say# " << buffer;
std::string echo_string = "echo# ";
echo_string += buffer;
// 直接发送回去!因为这个fd已经被epoll托管了!当这个fd有数据就绪了,epoll就会通知我们!
// 我们就可以去发送数据了!这就是IO多路复用!
send(fd,echo_string.c_str(),echo_string.size(),0);
}
else if(n == 0)
{
// 客户端关闭了连接
int n = epoll_ctl(_epfd,EPOLL_CTL_DEL,fd,nullptr); // 要删除fd,必须保证fd本身是合法的!
// 如果fd已经被关闭了,那么这个fd就不合法了!所以要先关闭fd,再删除fd!这样就不会出问题了!
LOG(LogLevel::INFO) << "client quit,epoll_ctl del event: " << fd;
close(fd);
}
else
{
// 读取数据失败了
int n = epoll_ctl(_epfd,EPOLL_CTL_DEL,fd,nullptr); // 要删除fd,必须保证fd本身是合法的!
// 如果fd已经被关闭了,那么这个fd就不合法了!所以要先关闭fd,再删除fd!这样就不会出问题了!
LOG(LogLevel::INFO) << "recv error,epoll_ctl del event: " << fd;
close(fd);
}
}
void EventHandler(struct epoll_event revs[],int ready_num)
{
for(int i = 0;i < ready_num;i++)
{
uint32_t events = revs[i].events; // 哪些事件就绪了
int fd = revs[i].data.fd; // 哪一个fd
if(events & EPOLLIN)
{
// 处理读事件
// listen sockfd | normal sockfd
if(fd == _listensockfd->Socketfd())
{
// new link ready!
Accepter(); // 这部分代码封装到Accepter函数中了
}
else
{
// normal data ready!
// 读写我依旧觉得碍事,封装一下
IOHandler(fd); // 这部分代码封装到IOHandler函数中了
}
}
else if(events & EPOLLOUT)
{
// TODO
// 处理写事件,这里先实现的前面的读事件,后续再实现写事件
}
}
}
void Dispatcher()
{
// 将listen sockfd添加到epoll中!
struct epoll_event ev;
ev.events = EPOLLIN; // 监听读事件
ev.data.fd = _listensockfd->Socketfd(); // 用户数据
int n = epoll_ctl(_epfd,EPOLL_CTL_ADD,_listensockfd->Socketfd(),&ev);
if(n >= 0)
{
LOG(LogLevel::DEBUG) << "epoll_ctl add : " << _listensockfd->Socketfd() << " success";
}
// timeout: -1表示永远等待,0表示不等待,>0表示等待的时间,单位是毫秒
// int timeout = 2000;
// timeout为0就是非阻塞一直轮询,但是也可以获取新连接
// int timeout = 0;
int timeout = -1; // 永远等待,直到有事件就绪了才返回
struct epoll_event revs[gnum];
while(true)
{
int n = epoll_wait(_epfd,revs,gnum,timeout);
if(n == 0)
{
LOG(LogLevel::INFO) << "time out...";
}
else if(n < 0)
{
LOG(LogLevel::ERROR) << "epoll_wait...";
break;
}
else
{
// EventHandler(revs,n); // 事件处理函数调用
LOG(LogLevel::DEBUG) << "有事件就绪了......"; // LT模式
}
}
}
~EpollServer()
{}
private:
uint16_t _port;
// 监听套接字
std::unique_ptr<Socket> _listensockfd;
// 需要一个句柄
int _epfd;
};有事件就绪,我故意不处理。处理的哪个函数我注释掉了:
不处理怎么办?试一下看看。
7.2 两种工作模式的演示
7.2.1 LT模式(默认模式)
cpp
ev.events = EPOLLIN;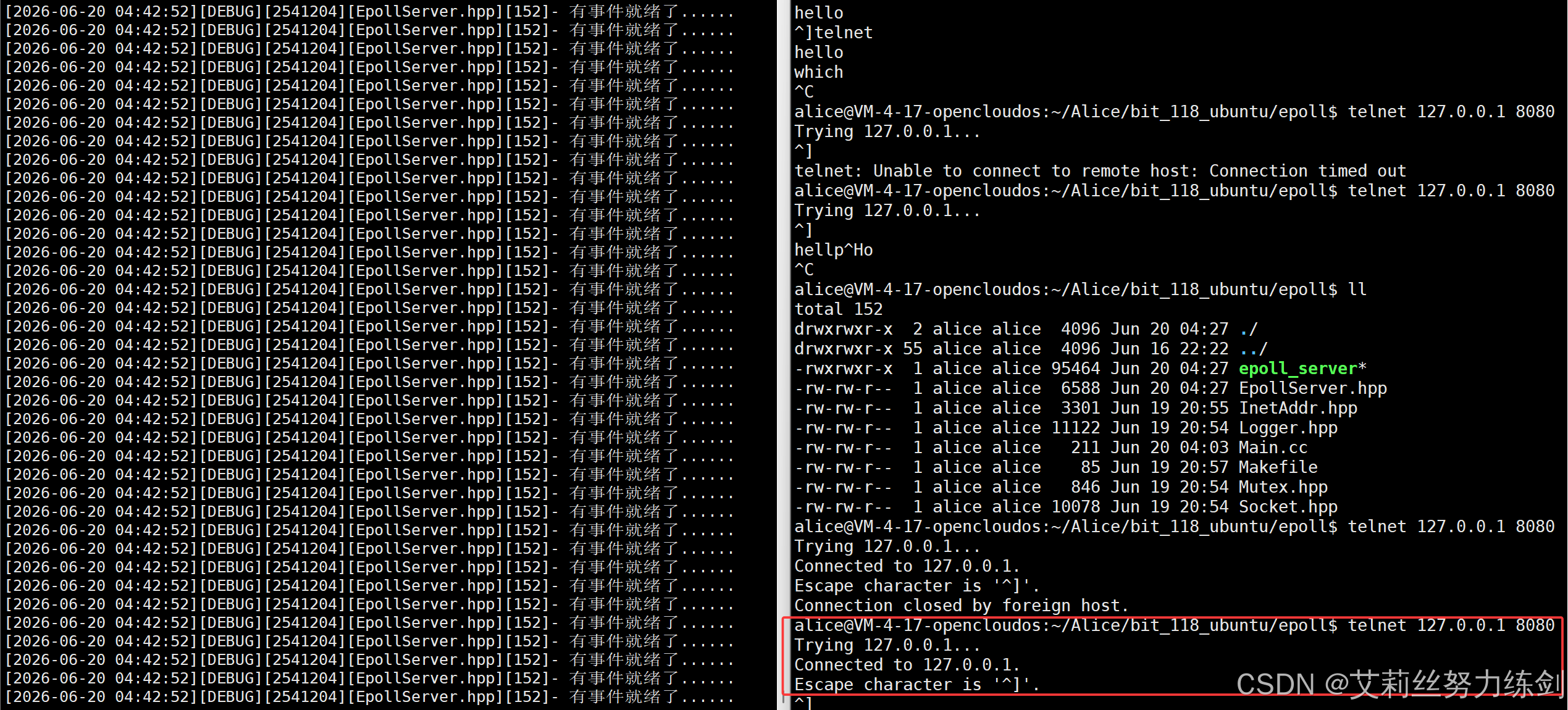
一旦连接上就会快速的刷屏,服务器一直告诉我"有事件就绪了",这种就是LT(水平触发)。
select、poll的工作模式类似于一种LT模式。
7.2.2 ET模式(需要手动设置)
cpp
ev.events = EPOLLIN | EPOLLET;
// 监听读事件,边缘触发模式(LT模式是默认的,ET模式需要我们自己设置),
// 像这里这样我就是设置了ET模式了!ET模式需要我们自己设置,LT模式是默认的!
// 所以如果不设置的话就是LT模式了!我发现:
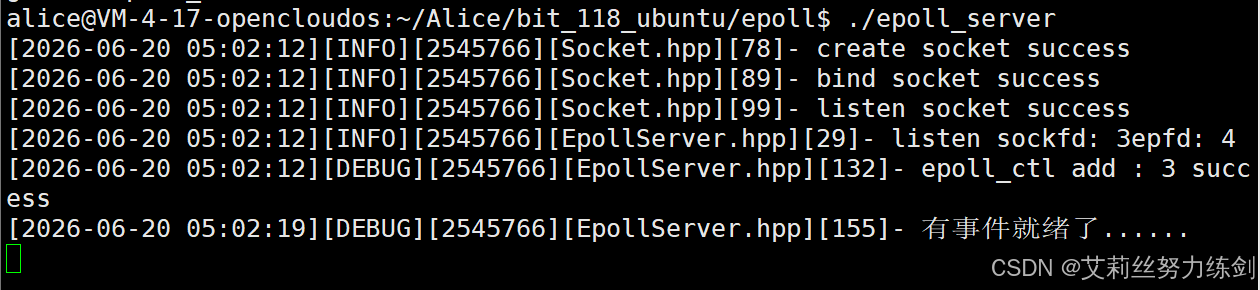
服务器只是说了一次 ------这种工作模式就是ET。
8 ~> epoll的两种工作模式:知识图谱

9 ~> 深度总结与核心考点复盘
本文完整拆解了 epoll 两种工作模式的全部核心逻辑,其本质是 "易用性" 与 "高性能" 之间的权衡,核心考点与重难点可归纳为以下四点:
- 触发机制本质差异 LT 的核心是 "状态"------ 只要处于 "有数据" 的状态就持续通知;ET 的核心是 "变化"------ 只有发生 "数据新增" 的状态跳变才通知一次。这是所有衍生特性的根源,也是理解两种模式的根本出发点。
- ET 非阻塞的强制逻辑 这是网络编程面试的高频必考题。完整逻辑链必须覆盖四个节点:ET 仅通知一次 → 必须一次性读完所有数据 → 只能通过循环读实现 → 阻塞读在无数据时会挂起进程 → 必须用非阻塞 + EAGAIN 判断结束。缺少任意一环都属于逻辑不完整。
- ET 高效性的两层原理 切勿仅回答 "通知次数少" 这一表层原因。完整答案必须包含两个层面:一是减少冗余系统调用,降低内核事件分发成本;二是倒逼快速清空接收缓冲区,扩大 TCP 通告窗口,提升网络传输吞吐量。第二层是多数学习者容易遗漏的深层原理。
- 工程选型原则 LT 胜在稳定、编码简单、不易出错,适合业务逻辑复杂、迭代速度快的场景;ET 胜在性能上限高、行为强约束,适合高并发、高性能的底层网络框架,如 Nginx、Redis 均默认采用 ET 模式。实际选型中,若无极致性能需求,LT 模式的工程稳定性更优。
结尾
uu们,本文的内容到这里就全部结束了,艾莉丝在这里再次感谢您的阅读!
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| ### 艾莉丝努力练剑 C/C++ & Linux 底层探索者 | 一个正在努力练剑的技术博主 *** ** * ** *** 👀 【关注】 跟随我一起深耕技术领域,见证每一次成长。 ❤️ 【点赞】 让优质内容被更多人看见,让知识传递更有力量。 ⭐ 【收藏】 把核心知识点存好,在需要时随时查、随时用。 💬 【评论】 分享你的经验或疑问,评论区一起交流避坑! 不要忘记给博主"一键四连"哦! "今日练剑达成!"  "技术之路难免有困惑,但同行的人会让前进更有方向。" |
"技术之路难免有困惑,但同行的人会让前进更有方向。" |
结语:希望对学习Linux相关内容的uu有所帮助,不要忘记给博主"一键四连"哦!
往期回顾:
【Linux网络】多路转接epoll(一):epoll理论 + 编写v1版本代码
🗡博主在这里放了一只小狗,大家看完了摸摸小狗放松一下吧!🗡 ૮₍ ˶ ˊ ᴥ ˋ˶₎ა
