- 绪论
- 研究背景与意义
近年来,随着移动互联网技术的快速发展和智能终端的普及,社交媒体已成为公众获取信息、表达观点和参与社会事务的重要渠道。据中国互联网络信息中心发布的统计报告显示,截至2024年6月,我国网民规模达10.99亿,其中微博用户规模超过5.8亿,微博月活跃用户保持在5亿以上。微博以其开放性强、传播速度快、互动性高等特点,已成为网络舆情的主要发源地和传播阵地。重大突发事件、社会热点话题往往首先在微博平台发酵,随后扩散至其他媒体平台,形成广泛的社会影响。
网络舆情的快速传播既可能促进社会进步,也可能带来负面影响。一方面,舆情信息的及时获取和分析有助于政府部门了解民意、科学决策,有助于企业把握市场动态、优化产品服务;另一方面,虚假信息、负面舆情的肆意传播可能引发社会恐慌,损害个人或组织声誉,甚至影响社会稳定。因此,建立高效的网络舆情监测与分析系统,对于维护网络空间秩序、促进社会和谐发展具有重要意义。
传统的舆情监测主要依靠人工方式,由专业工作人员浏览各大网站和社交平台,筛选整理舆情信息并撰写分析报告。这种方式存在效率低、覆盖面窄、时效性差等问题,难以适应当前信息爆炸时代的舆情监测需求。随着自然语言处理技术和深度学习技术的发展,基于机器学习的自动舆情分析方法逐渐成为研究热点。情感分析作为舆情分析的核心技术之一,旨在通过计算机技术自动识别文本中蕴含的情感倾向,为舆情判断提供量化依据。
然而,中文微博文本的情感分析面临诸多挑战。微博文本通常较短,信息量有限,且存在大量网络用语、表情符号和非规范表达,传统基于词典或规则的方法难以有效处理。此外,中文语义复杂,同一句话在不同语境下可能表达截然不同的情感,这给情感分析带来了较大难度。现有研究多集中在算法层面的改进,缺乏将情感分析技术与实际应用场景相结合的完整解决方案,系统的实用性和可操作性有待提升。
基于上述背景,本文以微博平台为研究对象,设计并实现了一套基于LSTM深度学习模型的舆情分析系统。系统从前端界面到后端服务、从数据采集到情感分析、从可视化展示到预警通知,形成了完整的舆情监测分析链条,为解决实际舆情监测问题提供了可行方案。
-
- 国内外发展现状
情感分析作为自然语言处理的重要分支,其方法论经历了从"基于规则与词典1"到"基于统计机器学习2",再发展到当前"基于深度学习3"的演进历程。
(1)国外研究现状
情感分析的研究经历了明显的范式转移。早期研究主要基于情感词典与规则方法,如Turney(2002)提出的基于点互信息(PMI)的情感分类方法4,以及Liu等人构建的用于产品评论分析的情感词典。这些方法虽然直观,但难以应对语言的多义性和语境依赖性。
随着机器学习的发展,基于特征工程的统计学习方法成为主流。Pang等人(2002)开创性地将机器学习方法引入情感分析5,使用支持向量机(SVM)、朴素贝叶斯等分类器在电影评论数据集上取得了显著成果。此后,研究者不断探索更有效的特征表示方法,包括词袋模型、n-gram特征和TF-IDF加权方法。然而,这些方法仍然需要大量的人工特征工程,且难以捕捉深层的语义信息。
深度学习技术的突破为情感分析带来了革命性变化。首先是基于卷积神经网络(CNN)的方法,如Kim(2014)提出的TextCNN模型6,能够有效提取文本的局部特征。随后,循环神经网络(RNN)及其变体LSTM和GRU成为处理序列数据的标准选择。Tang等人(2015)提出的TD-LSTM和TC-LSTM模型7,专门针对Twitter等社交媒体短文本的情感分析,通过建模句子中的目标信息来提升分类性能。近年来,预训练语言模型如BERT、GPT系列在情感分析任务上取得了state-of-the-art的性能,Devlin等人(2018)提出的BERT模型8通过双向Transformer架构和掩码语言建模任务,在大规模语料上学习到了丰富的语义表示。
然而,大型预训练模型在实际应用中面临计算资源消耗大、推理速度慢、部署成本高等挑战。相比之下,LSTM模型在计算效率和模型可解释性方面仍具有明显优势,特别适合资源受限的应用场景。因此,针对特定领域和任务对LSTM模型进行优化,仍然是具有重要价值的研究方向
(2)国内研究现状
中文情感分析研究在借鉴国际先进技术的同时,面临着分词、语义理解等特有挑战。早期研究主要集中在情感资源建设方面,如哈尔滨工业大学信息检索研究室构建的《同义词词林》扩展版,以及大连理工大学情感词汇本体库,为基于词典的方法提供了重要基础。
随着深度学习的兴起,国内研究者积极探索适合中文文本的神经网络模型。在词向量表示方面,研究者们训练了面向中文的Word2Vec和GloVe词向量,并结合中文语言特点进行了优化。在模型架构方面,双向LSTM(Bi-LSTM)及其变体在中文情感分析任务中表现出色。例如,吴小华团队(2019)提出的基于Bi-LSTM和注意力机制的模型9,在多个中文情感分析数据集上取得了优于传统方法的效果。
特别针对微博文本的情感分析,研究者们提出了多种创新方法。谭皓等(2018)研究了微博文本中表情符号的情感作用10,提出了融合表情特征的情感分析方法;奚浩瀚团队(2015)针对微博文本的噪声问题11,设计了多级过滤和语义增强的预处理流程;刘慧清等人(2020)探索了跨领域情感分析方法12,解决微博数据标注不足的问题;唐晓波等13基于话题情感强度对微博舆情进行了深入分析,揭示了舆情演化的内在规律;宋蕾和张培晶14基于LDA主题建模方法,设计了微博舆情分析系统,为主题提取和舆情分析提供了新的思路;李芊15研究了基于深度学习的微博舆情分析方法,验证了深度学习模型在舆情分析中的有效性;王琳16基于改进主题提取和情感分析模型,对微博舆情演化过程进行了系统研究;成哲丞17研究了基于深度学习的微博舆情监测模型,为舆情监测提供了新的技术方案;王前威18基于新浪微博平台设计实现了网络舆情分析系统,验证了系统的实用性;杨柳19对微博舆情的算法分析与系统实现进行了系统研究,为后续系统开发提供了参考。这些研究为微博情感分析提供了重要的技术积累。
综合国内外研究现状可以看出,情感分析技术已经从简单的规则方法发展到复杂的深度学习模型。虽然预训练大模型代表了当前的技术前沿,但其在资源消耗、部署成本和可解释性方面的局限性,使得LSTM等传统深度学习模型在实际应用中仍然具有重要价值。在成熟的LSTM技术框架基础上,针对微博舆情分析这一特定应用场景,进行系统的工程化实现和针对性的优化改进。研究重点不在于提出全新的模型架构,而在于如何将现有技术有效集成到一个完整的应用系统中,并解决实际工程中的关键问题,包括数据获取、噪声处理、模型优化和结果可视化等。
-
- 论文研究目标和内容
本文的研究目标是设计并实现一套功能完善、性能可靠的微博舆情分析系统,将深度学习情感分析技术与实际应用场景相结合,为舆情监测提供智能化解决方案。具体研究内容包括:
(1)舆情数据的采集与预处理。研究微博数据的采集方法,构建包含评论内容、用户信息、发布时间等多维度信息的数据集,并进行数据清洗、分词、向量化等预处理操作。
(2)情感分析模型的构建与训练。采用Word2Vec模型进行词向量表示,构建双向LSTM神经网络进行情感分类,通过实验调整模型参数,优化模型性能。
(3)舆情分析系统的设计与开发。采用B/S架构,基于Flask框架开发后端服务,使用Bootstrap框架构建前端界面,实现用户端和管理端双端功能。
(4)系统功能的测试与验证。对系统各功能模块进行测试,验证系统的可靠性和实用性。
-
- 论文结构安排
本文共分为七章,各章内容安排如下:
第1章为绪论,介绍研究背景与意义、国内外发展现状、研究目标与内容以及论文结构安排。
第2章为相关技术及理论基础,介绍系统开发所涉及的关键技术,包括Flask框架、SQLite数据库、Bootstrap前端框架、LSTM神经网络、Word2Vec词向量模型等。
第3章为系统需求分析,从经济、技术、操作三个方面进行可行性分析,详细分析系统的业务流程、功能需求和非功能性需求。
第4章为系统设计,阐述系统总体架构设计、功能模块设计、数据库设计以及情感分析算法的设计与实现。
第5章为系统实现,介绍开发环境搭建,详细描述各功能模块的实现过程。
第6章为系统测试,对系统核心功能进行测试,验证系统是否满足设计要求。
第7章为总结与展望,总结全文工作,指出系统存在的不足,展望未来改进方向。
- 相关技术及理论基础
- Web开发技术
- Flask框架
- Web开发技术
Flask是一个轻量级的Python Web框架,由Armin Ronacher于2010年创建。与Django等全功能框架不同,Flask采用微框架设计理念,核心功能精简,通过扩展组件实现功能扩展。Flask具有以下特点:一是轻量灵活,核心代码简洁,开发者可以自由选择需要的组件;二是易于上手,文档完善,适合快速开发小型项目;三是扩展丰富,拥有大量第三方扩展,可以满足各种开发需求。
Flask框架采用Werkzeug WSGI工具箱和Jinja2模板引擎,提供了路由、请求处理、模板渲染、会话管理等基础Web开发功能23。本系统使用Flask 3.0版本,结合Flask-Login扩展实现用户认证,Flask-SQLAlchemy扩展实现数据库操作,Flask-Session扩展实现会话管理。Flask的蓝图机制使得项目结构清晰,便于代码组织和维护。
-
-
- SQLite数据库
-
SQLite是一款轻量级的嵌入式关系型数据库,由D. Richard Hipp于2000年发布。与MySQL、PostgreSQL等客户端/服务器架构的数据库不同,SQLite将整个数据库存储在单个磁盘文件中,无需独立的服务器进程,具有配置简单、部署方便、资源占用少等优点24,特别适合中小型应用开发和原型系统搭建。
SQLite支持完整的SQL标准语法,包括事务、触发器、视图等高级特性。本系统采用SQLite作为数据存储方案,通过SQLAlchemy对象关系映射框架进行数据库操作,实现了数据表的定义、数据的增删改查等功能。SQLite的单文件存储特性使得系统部署和迁移十分便捷,降低了运维成本。
-
-
- Bootstrap框架
-
Bootstrap是由Twitter公司开发的开源前端框架,提供了丰富的UI组件和响应式布局系统22。Bootstrap基于HTML、CSS、JavaScript构建,包含了按钮、表单、导航、模态框等常用组件,开发者可以快速搭建美观、一致的网页界面。
Bootstrap采用移动优先的响应式设计理念,通过栅格系统实现不同屏幕尺寸下的自适应布局。本系统使用Bootstrap 5版本,结合自定义CSS样式,实现了用户端和管理端的双端界面。Bootstrap提供的卡片、表格、徽章等组件被广泛应用于数据展示和信息呈现。
-
- 数据可视化技术
- ECharts图表库
- 数据可视化技术
ECharts是由百度公司开源的数据可视化图表库,基于JavaScript开发,能够流畅运行在PC端和移动端26。ECharts提供了折线图、柱状图、饼图、散点图、雷达图、地图等多种图表类型,支持交互操作和动画效果,广泛应用于数据分析和商业智能领域,如郑戟明和柳青27将ECharts应用于数据可视化课程教学,验证了其易用性和功能性;刘梦等32将ECharts可视化技术应用于数据管理平台,验证了其在数据展示方面的优势。
ECharts采用Canvas渲染,性能优异,能够处理大规模数据可视化需求。本系统使用ECharts 5版本,实现了情感分布柱形图、舆情趋势折线图、用户画像玫瑰图、关键词词云图、地区分布地图等多种可视化图表,直观展示舆情分析结果。
-
-
- 词云可视化
-
词云是一种将文本中词语按照出现频率以不同大小、颜色展示的可视化方式,能够直观呈现文本的主题和关键词分布25。词云中词语的字号越大,表示该词语在文本中出现的频率越高或权重越大。
本系统采用jieba分词工具对微博文本进行分词处理,统计词语频率,结合ECharts的词云扩展组件生成词云图,帮助用户快速了解舆情热点和核心话题。
-
- 自然语言处理技术
- 中文分词
- 自然语言处理技术
中文分词是中文自然语言处理的基础任务,将连续的中文文本切分为具有语义意义的词语序列。与英文等拉丁语系不同,中文文本词与词之间没有天然的分隔符,分词质量直接影响后续文本分析的效果。
jieba是目前应用最广泛的中文分词工具之一28,支持精确模式、全模式和搜索引擎模式三种分词模式。精确模式将文本切分为最合理的词语序列,适合文本分析任务;全模式扫描所有可能的词语组合,速度快但存在歧义;搜索引擎模式在精确模式基础上对长词进行再切分,提高召回率。本系统采用jieba的精确模式进行分词处理。
-
-
- SnowNLP情感分析
-
SnowNLP是一个Python编写的中文自然语言处理库,提供了分词、词性标注、情感分析、文本分类等功能。SnowNLP的情感分析功能基于情感词典和规则方法,能够快速计算文本的情感倾向得分20,得分范围从0到1,越接近0表示越负面,越接近1表示越正面。
SnowNLP的优点是使用简单、响应快速,适合实时情感分析场景。本系统在用户端的实时文本分析功能中使用SnowNLP进行情感分析,为用户提供即时的情感反馈。
-
- 深度学习技术
- Word2Vec词向量模型
- 深度学习技术
Word2Vec是由Google公司于2013年提出的词向量表示模型,能够将词语映射到低维连续向量空间,使得语义相近的词语在向量空间中距离较近21。Word2Vec提供了两种训练架构:CBOW(Continuous Bag of Words)和Skip-gram。CBOW模型根据上下文词语预测目标词,Skip-gram模型根据目标词预测上下文词语。
词向量表示相比传统的独热编码具有维度低、能够表达语义关系等优点。本系统使用Skip-gram架构训练Word2Vec模型,词向量维度设为100,将微博文本转换为向量表示后输入LSTM网络进行情感分类。
-
-
- LSTM神经网络
-
长短期记忆网络(Long Short-Term Memory,LSTM)是一种特殊的循环神经网络,由Hochreiter和Schmidhuber于1997年提出。LSTM通过引入门控机制解决了传统RNN在处理长序列时的梯度消失和梯度爆炸问题,能够有效捕获长距离依赖关系。LSTM通过刻意的设计来实现学习序列关系的同时,又能够避免长期依赖的问题。它的结构示意图如下图2.1所示。
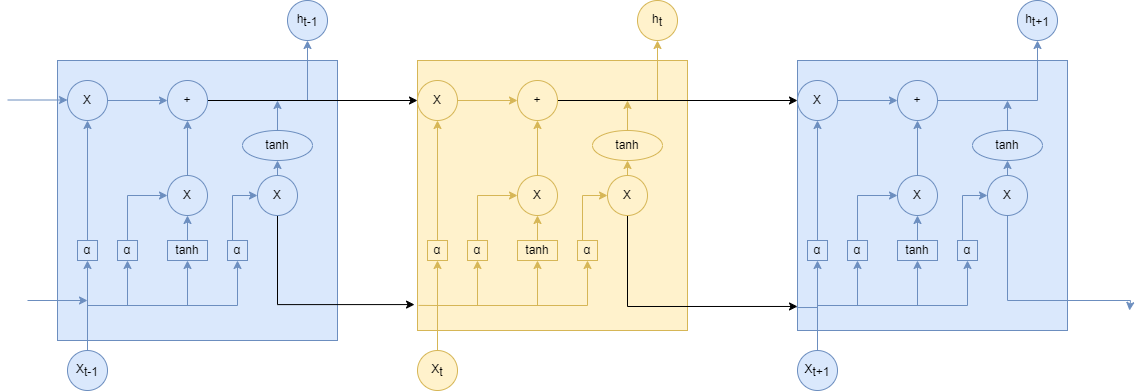
图 21 LSTM结构图
在LSTM的结构示意图中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。其中"+"号代表着运算操作(如矢量的和),而矩形代表着学习到的神经网络层。汇合在一起的线表示向量的连接,分叉的线表示内容被复制,然后分发到不同的位置。其实LSTM的本质就是一个带有tanh激活函数的简单RNN,如下图2.2遗忘门图所示:
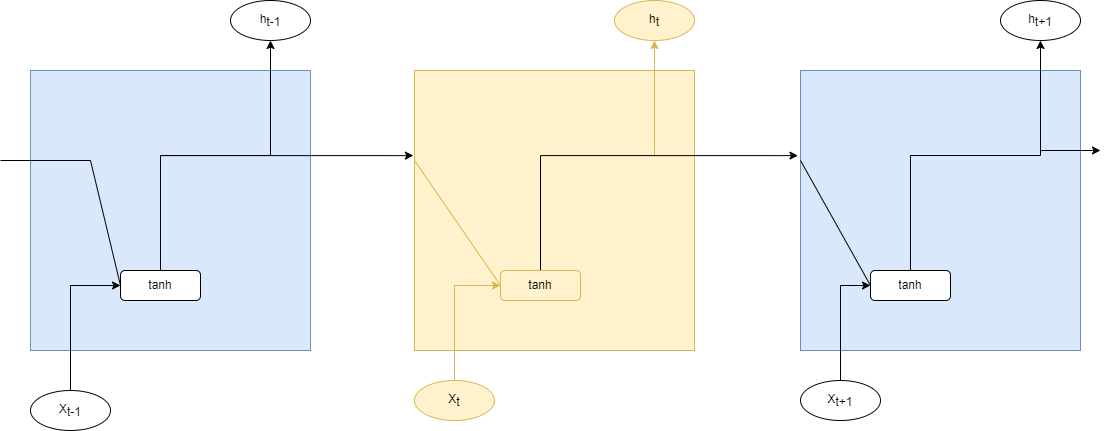
图 22 遗忘门图
LSTM这种结构的原理是引入一个称为细胞状态的连接。这个状态细胞用来存放想要的记忆的东西(对应简单LSTM结构中的h,只不过这里面不再只保存上一次状态了,而是通过网络学习存放那些有用的状态),同时在加入三个门分别是:
遗忘门:决定什么时候将以前的状态忘记。
输入门:决定什么时候将新的状态加进来。
输出门:决定什么时候需要把状态和输入放在一起输出。
从字面上可以看出,由于三个门的操作,LSTM在状态的更新和状态是否要作为输入。下图2-3所示为遗忘门的操作,遗忘门决定模型会从细胞状态中丢弃什么信息。
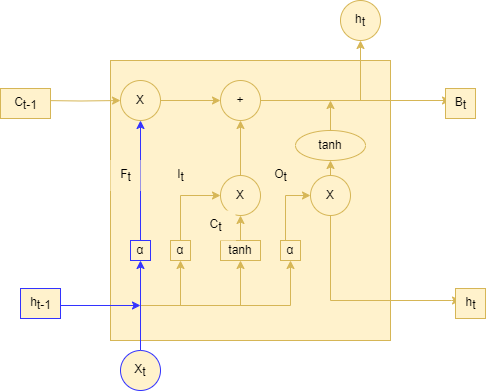
图 23 遗忘门操作流程图
遗忘门公式:
遗忘门会读取前一序列模型的输出和当前模型的输入来控制细胞状态中的每个数是否保留。
例如:在一个语言模型的例子中,假设细胞状态会包含当前主语的性别,于是根据这个状态便可以选择正确的代词。当我们看到新的主语时,应该把新的主语在记忆中更新。遗忘门的功能就是先去记忆中找到一千那个旧的主语(并没有真正执行忘记的操作,只是找到而已)。
在上图的LSTM的遗忘门中,代表遗忘门的输出,α代表激活函数,代表遗忘门的权重,代表当前模型的输入,代表前一个序列模型的输出,代表遗忘门的偏置.
输入门可以分为两部分功能,一部分是找到那些需要更新的细胞状态。另一部分是把需要更新的信息更新到细胞状态里.如下图2-4输入门结构图所示:
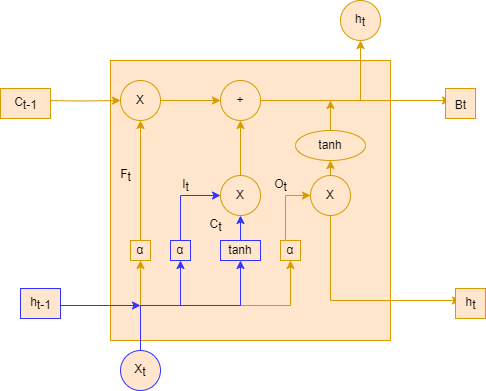
图 24 输入门图
在上面输入门的结构中,代表要更新的细胞状态,α代表激活函数,代表当前模型的输入,代表前一个序列模型的输出,代表计算的权重,代表计算的偏置,代表使用tanh所创建的新细胞状态,代表计算的权重,代表计算的偏置。
遗忘门找到了需要忘掉的信息后,在将它与旧状态相乘,丢弃确定需要丢弃的信息。(如果需要丢弃对应位置权重设置为0),然后,将结果加上 * 使细胞状态获得新的信息。这样就完成了细胞状态的更新,如下图2-5输入门的更新图所示:
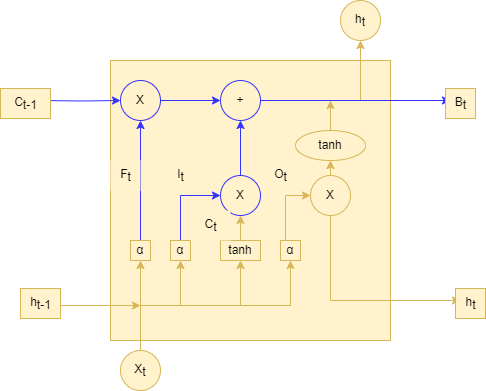
图 25 输入门更新图
如下图2-6LSTM的输出门结构图所示,在输出门中,通过一个激活函数层(实际使用的是Sigmoid激活函数)来确定哪个部分的信息将输出,接着把细胞状态通过tanh进行处理(得到一个在-1~1的值),并将它和Sigmoid门的输出相乘,得出最终想要输出的那个部分,例如,在语言模型中,假设已经输入了一个代词,便会计算出需要输出一个与该代词相关的信息(词向量):
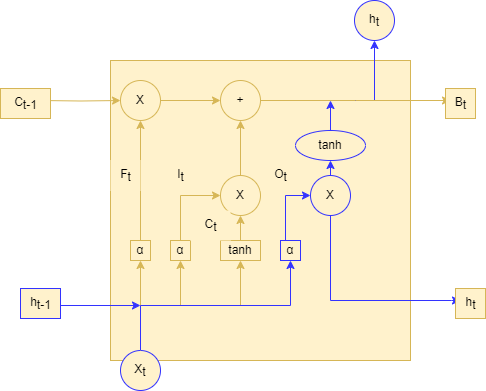
图 26 LSTM的输出门结构图
表示sigmoid激活函数,*表示逐元素乘法。双向LSTM(Bi-LSTM)通过两个LSTM层分别处理前向和后向序列,能够同时捕获上下文信息29,在情感分析任务中表现优于单向LSTM。例如杨秀璋等30基于改进LDA-CNN-BiLSTM模型进行社交媒体情感分析,验证了BiLSTM的有效性;李丽华31提出了基于情感增强的双向图卷积方面级情感分析模型,进一步提升了情感分类性能。
本系统采用双向LSTM网络进行情感分类,网络结构包括LSTM层、全连接层和Dropout层,输出层使用Softmax激活函数进行三分类(负面、中性、正面)。
-
- 本章小结
本章介绍了系统开发所涉及的关键技术。在Web开发方面,采用了Flask轻量级框架、SQLite嵌入式数据库和Bootstrap前端框架;在数据可视化方面,使用了ECharts图表库和词云技术;在自然语言处理方面,介绍了jieba分词工具和SnowNLP情感分析库;在深度学习方面,阐述了Word2Vec词向量模型和LSTM神经网络的原理。这些技术的综合应用为系统开发奠定了技术基础。
- 系统需求分析
- 可行性分析
- 经济可行性分析
- 可行性分析
本系统的开发和运行成本主要包括以下几个方面:硬件方面,系统可部署在普通服务器或云服务器上,对硬件配置要求不高,现有硬件设施基本能够满足需求;软件方面,系统采用的Flask框架、SQLite数据库、Bootstrap前端框架等均为开源软件,无需支付软件授权费用;人力方面,开发人员具备Python Web开发和深度学习相关技术储备,开发周期可控。从效益角度分析,系统能够自动化完成舆情监测和分析工作,大幅降低人工成本,提高工作效率。系统提供的情感分析、舆情预警等功能具有较高的实用价值,能够帮助用户及时发现舆情动态、做出科学决策。系统从经济上是可行的。
-
-
- 技术可行性分析
-
本系统采用的技术方案成熟可靠,具有充分的技术支撑。Flask框架是Python生态中最流行的Web框架之一,拥有完善的文档和活跃的社区支持,开发人员对其有深入理解和丰富使用经验。SQLite数据库稳定可靠,广泛应用于各类中小型系统。Bootstrap前端框架提供了丰富的UI组件,能够快速构建响应式界面。
在情感分析方面,LSTM神经网络在文本情感分析领域已有大量成功应用案例,相关技术成熟稳定。PyTorch深度学习框架提供了完善的LSTM实现,模型训练和部署流程清晰。Word2Vec词向量模型能够有效表示文本语义,为情感分析提供高质量特征输入。系统涉及的各项技术均已在工业界得到广泛应用验证,技术文档丰富,遇到问题可以方便地寻求解决方案。系统从技术上是可行的。
-
-
- 操作可行性分析
-
本系统采用B/S架构,用户通过浏览器即可访问使用,无需安装客户端软件,操作门槛低。系统界面设计简洁直观,功能布局合理,用户能够快速上手使用。用户端提供了文本分析、情感分析、舆情可视化等功能,操作流程清晰,符合用户使用习惯。
管理端界面提供了用户管理、内容管理、预警处理等功能,采用表格、卡片等常见UI组件,管理员能够方便地进行各项管理操作。系统支持移动端访问,管理员可以随时随地处理舆情预警和用户举报。系统界面友好、操作简便,用户无需专业培训即可正常使用,从操作上是可行的。
-
- 需求分析
- 业务流程分析
- 需求分析
微博舆情分析系统的核心业务是对微博文本进行情感分析,判断其情感倾向,并据此生成舆情报告和预警信息。系统分为用户端和管理端两部分,分别面向普通用户和管理员提供服务。
用户端核心业务流程如下:
用户进入系统后,首先进行文本情感分析。用户输入或粘贴待分析的文本内容,系统调用情感分析模块对文本进行处理,计算情感得分并判断情感类别(正面、中性、负面),将分析结果以可视化方式呈现给用户。分析结果包括情感得分、情感类别、关键词等信息。
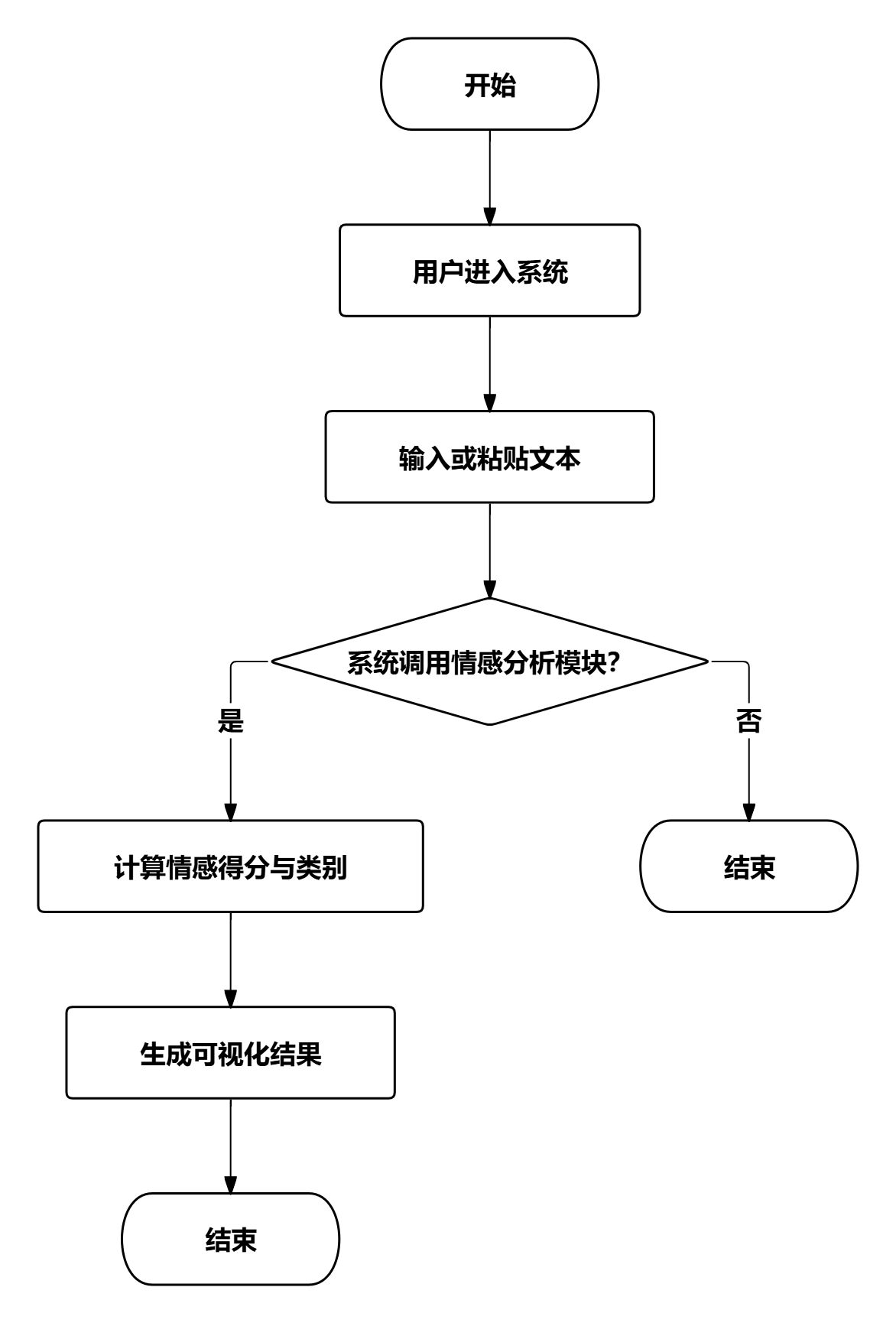
图31用户端核心业务流程图
舆情浏览业务流程中,用户可以查看系统已分析的舆情数据,包括情感分布统计、舆情趋势变化、热门话题词云等内容。系统通过图表、表格等形式直观展示舆情信息,帮助用户了解舆情整体状况。
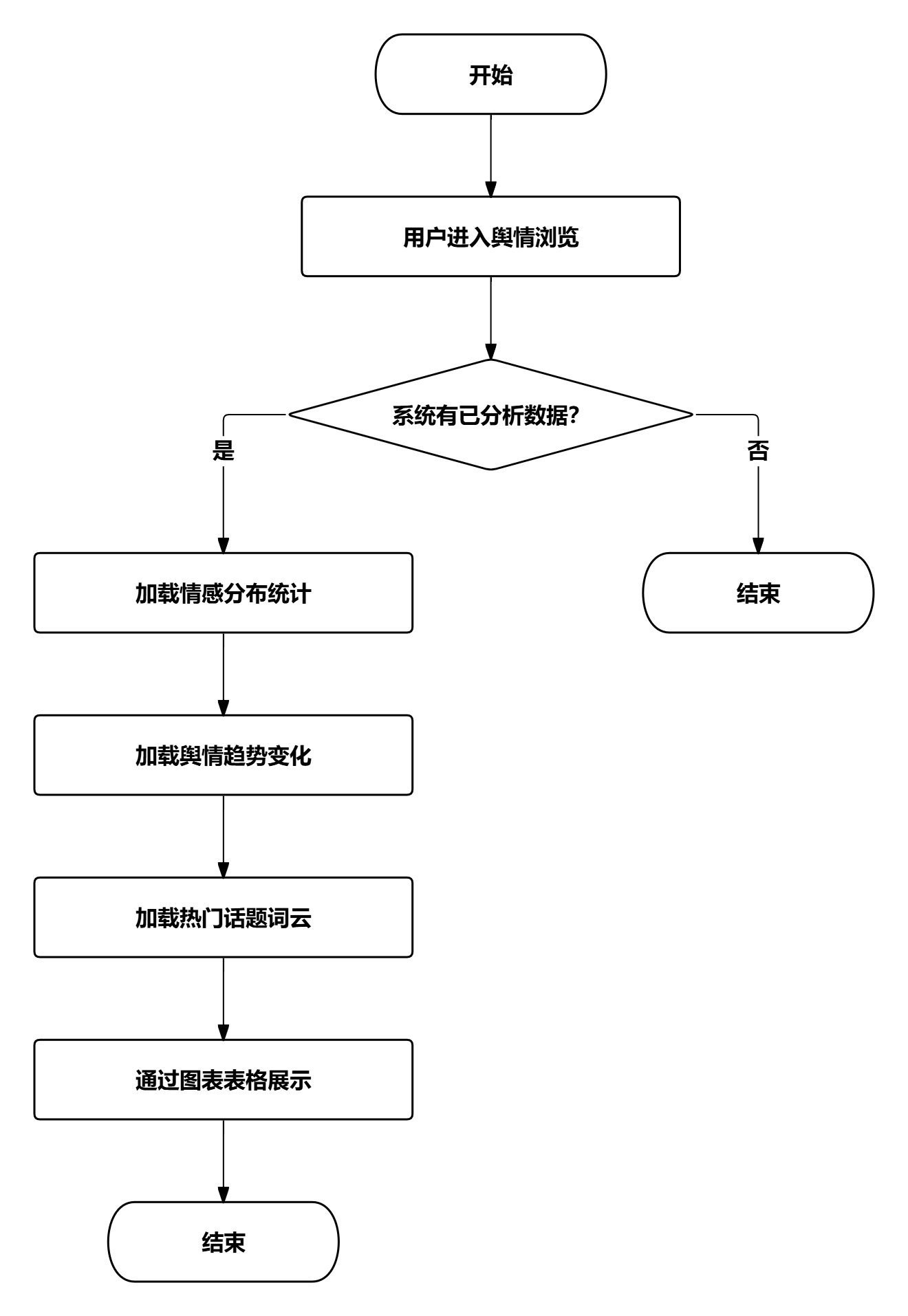
图 32舆情浏览业务流程图
舆情举报业务流程中,用户发现不当言论或需要关注的舆情内容时,可以提交举报信息。用户填写举报类型、紧急程度、举报内容、举报原因等信息,系统将举报记录保存至数据库,管理员后续进行审核处理。
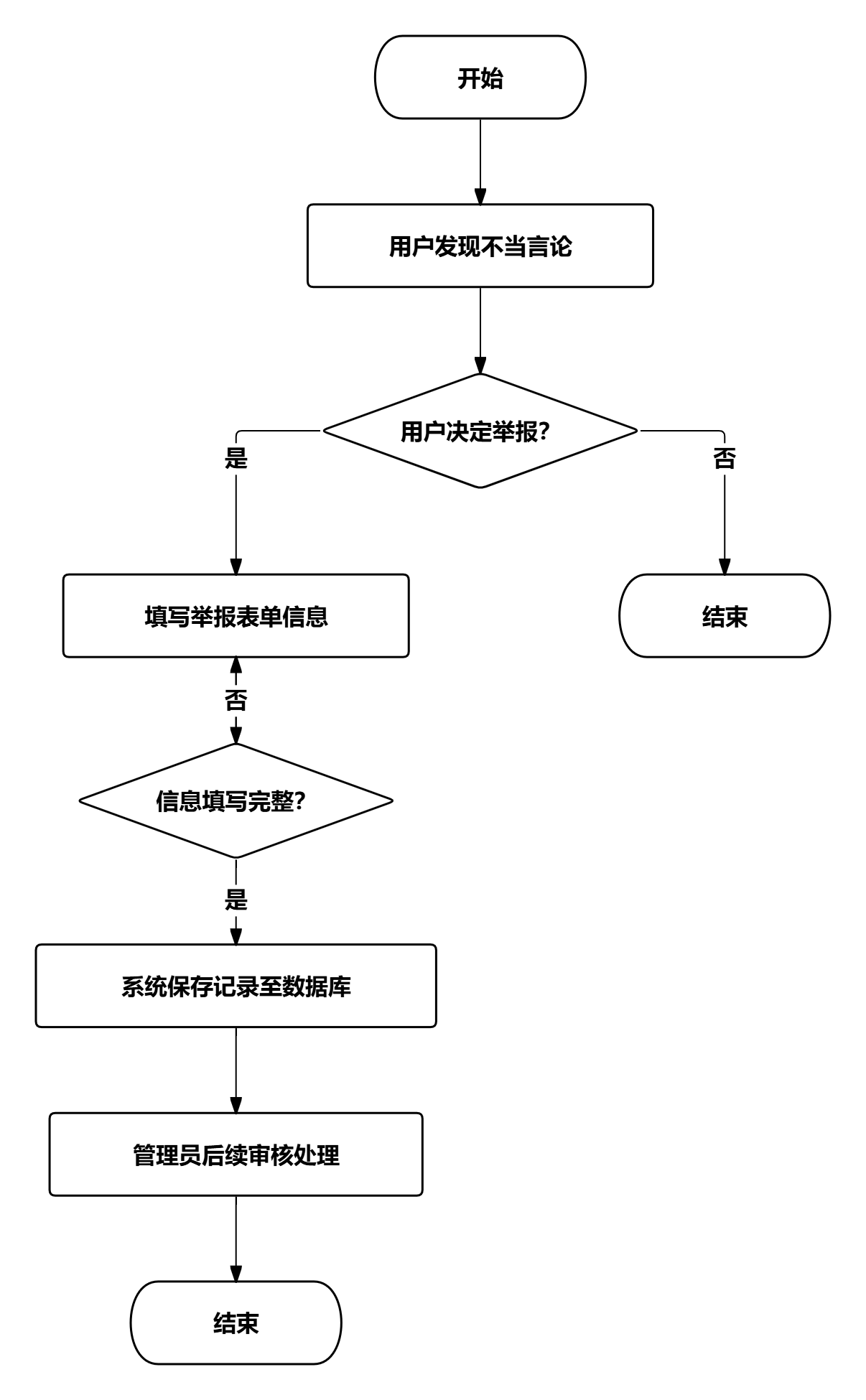
图 33舆情举报业务流程图
管理端核心业务流程如下:
管理员登录系统后,可以查看系统整体数据统计,包括用户数量、博文数量、评论数量、预警数量等指标。管理员对用户进行管理,包括查看用户列表、启用或禁用用户账户。
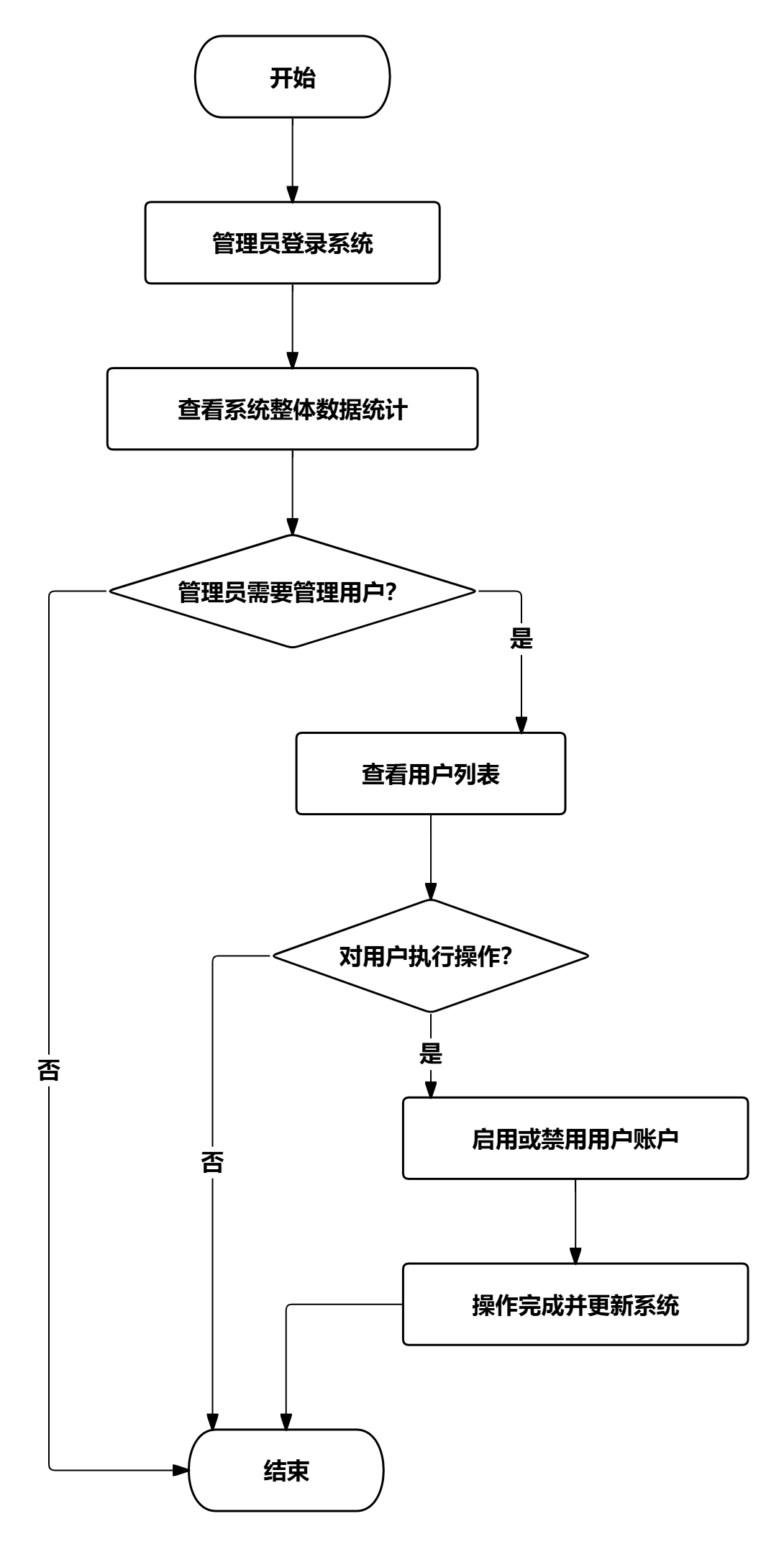
图 34管理端核心业务流程图
舆情预警处理业务流程中,系统根据情感分析结果自动生成预警信息,管理员查看预警列表,判断预警的严重程度和真实性,对预警进行标记处理或忽略操作。
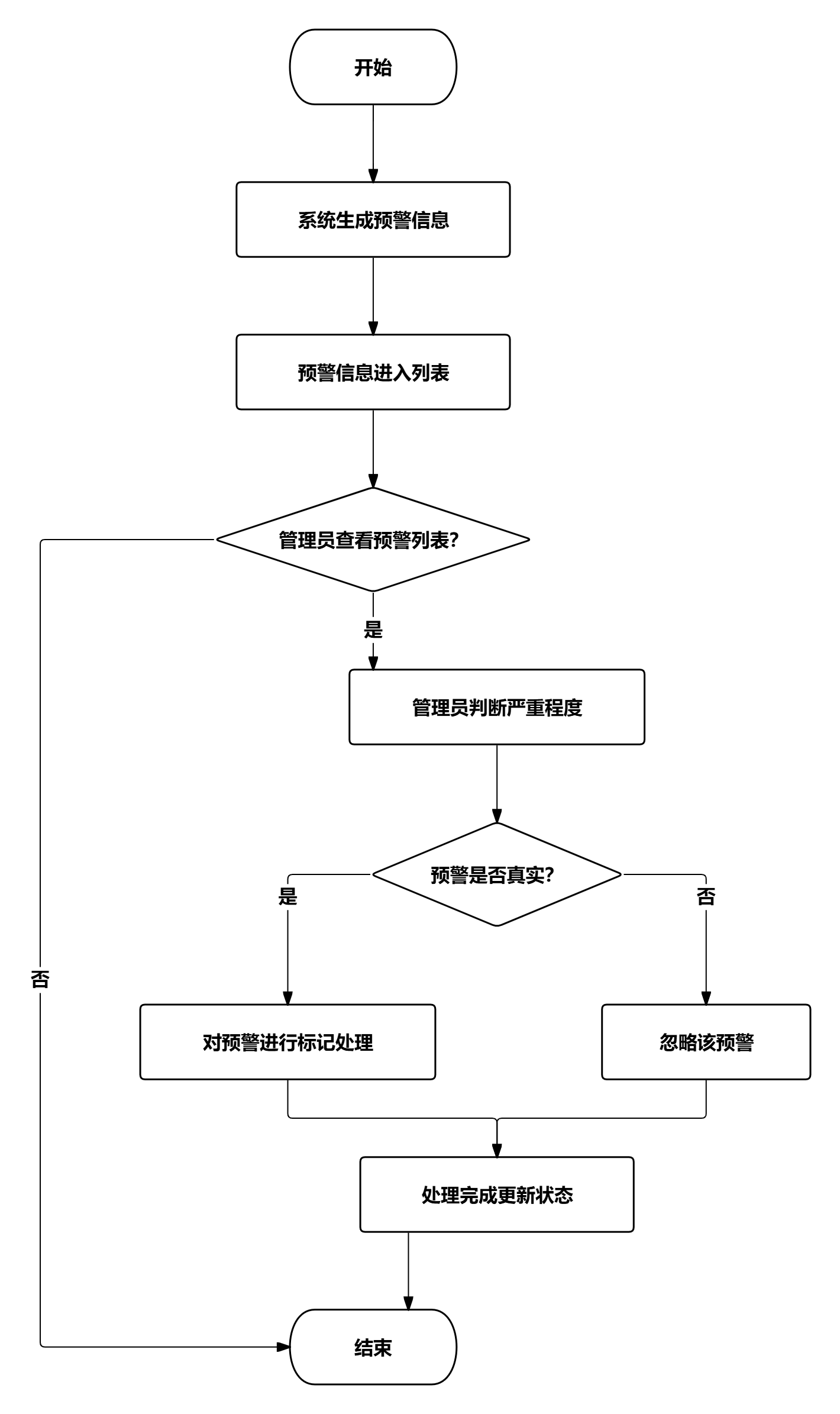
图 35舆情预警处理业务流程图
举报处理业务流程中,管理员查看用户提交的举报记录,审核举报内容的真实性,对举报进行处理或忽略,并可添加处理备注。处理结果将更新举报记录状态。
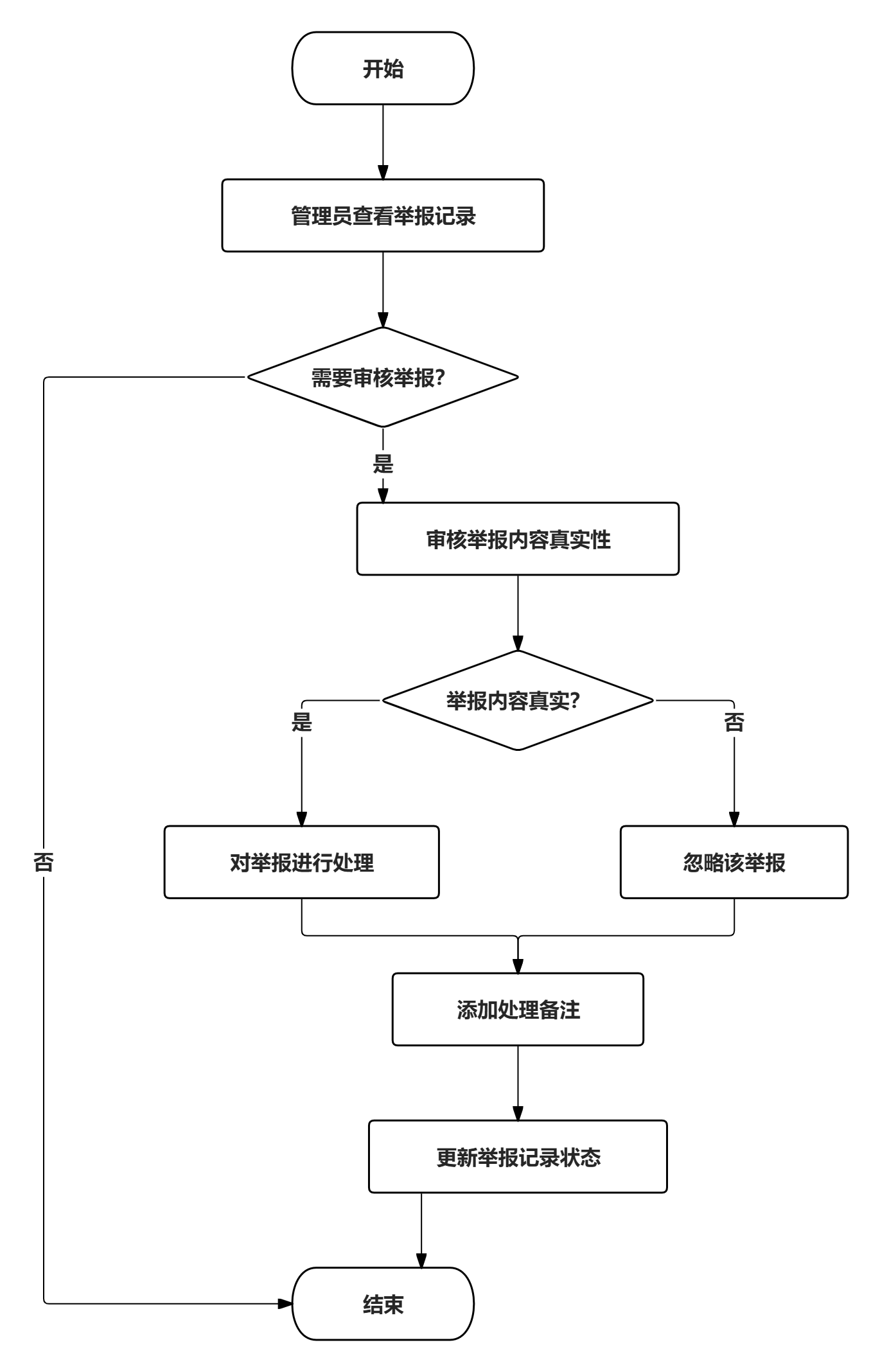
图 36举报处理业务流程图
-
-
- 功能需求分析
-
根据用户角色和业务场景,系统功能分为用户端功能和管理端功能两部分。
用户端主要功能包括:
(1)文本情感分析功能:用户输入文本内容,系统实时分析情感倾向,返回情感得分、情感类别、关键词等结果,支持查看历史分析记录。
(2)舆情可视化展示功能:以图表形式展示舆情数据,包括情感分布柱形图、舆情趋势折线图、用户画像玫瑰图、关键词词云图、地区分布地图等,帮助用户直观了解舆情状况。
(3)舆情举报功能:用户提交不当言论或关注内容的举报信息,填写举报类型、紧急程度、举报原因等,查看个人举报记录和处理状态。
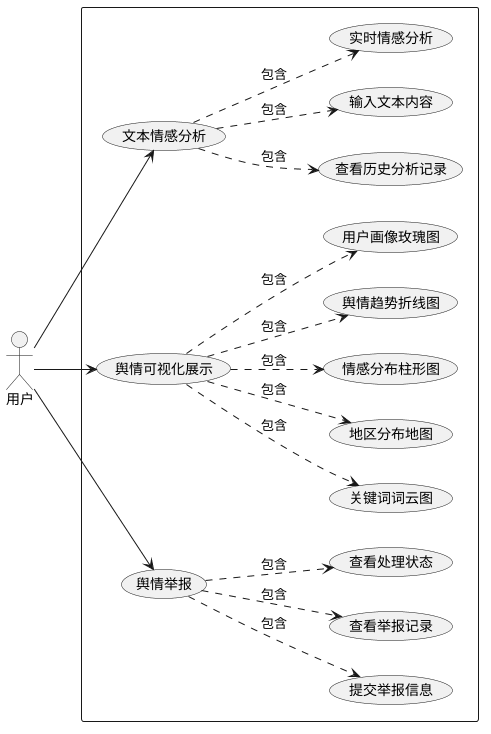
图 37用户用例图
管理端主要功能包括:
(1)用户管理功能:查看系统用户列表,包括用户名、邮箱、角色、状态等信息,支持启用或禁用用户账户。
(2)博文管理功能:查看系统采集的微博博文数据,包括博文内容、发布者、发布时间、互动数据等,支持按条件筛选和删除操作。
(3)评论管理功能:查看微博评论数据,包括评论内容、评论者、评论时间、情感标签等,支持筛选和管理操作。
(4)舆情预警管理功能:查看系统生成的预警信息,包括预警类型、预警等级、预警描述等,支持处理或忽略预警操作。
(5)举报管理功能:查看用户提交的举报记录,审核举报内容,进行处理或忽略操作,可添加处理备注。
(6)LSTM训练结果展示功能:查看情感分析模型的训练过程和评估结果,包括训练损失曲线、混淆矩阵、ROC曲线等,了解模型性能指标。
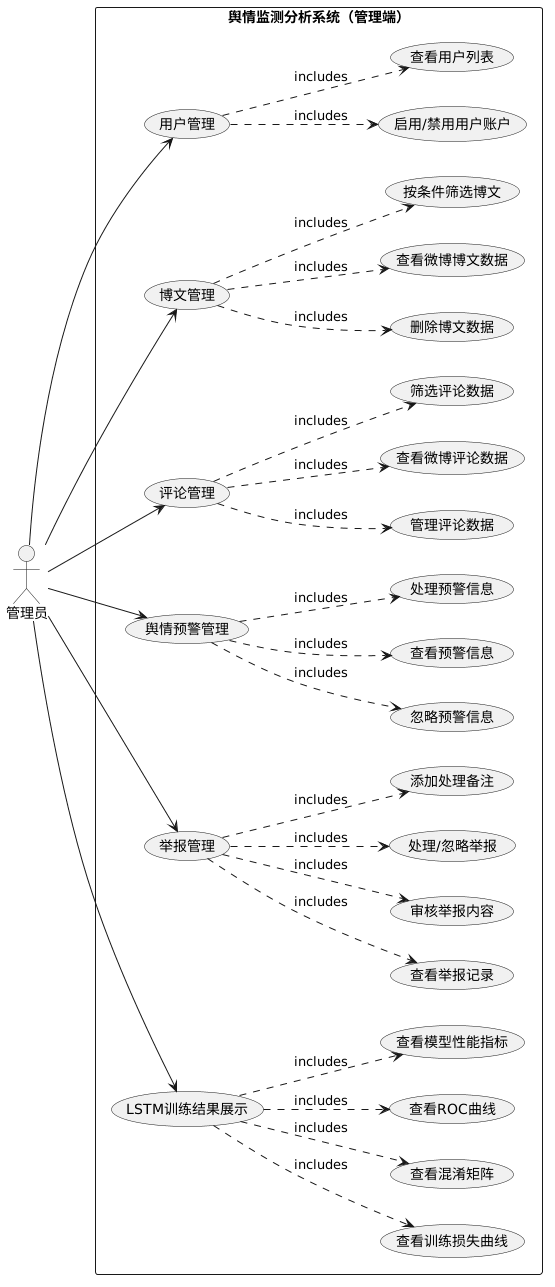
图 38管理员用例图图
-
-
- 非功能性需求分析
-
(1)性能需求:系统响应时间应在合理范围内,页面加载时间不超过3秒,情感分析接口响应时间不超过2秒。系统应支持多用户并发访问,在20个并发用户情况下系统运行正常。
(2)可靠性需求:系统应稳定可靠,平均无故障运行时间不低于720小时。系统应具备数据备份和恢复机制,防止数据丢失。异常情况下系统应能够优雅降级,避免崩溃。
(3)安全性需求:系统应实现用户身份认证和授权机制,不同角色用户只能访问其权限范围内的功能。用户密码应加密存储,敏感数据传输应使用加密协议。系统应防范SQL注入、XSS攻击等常见安全威胁。
(4)可维护性需求:系统代码结构清晰,遵循编码规范,便于后续维护和升级。系统应提供必要的日志记录,便于问题定位和排查。系统应预留扩展接口,便于功能扩展。
(5)易用性需求:系统界面设计应简洁美观,操作流程直观,符合用户使用习惯。系统应提供操作提示和错误反馈,帮助用户正确使用系统。系统应支持主流浏览器,兼容不同屏幕尺寸。
-
- 本章小结
本章从经济、技术、操作三个维度对系统进行了可行性分析,论证了系统开发的可行性。在需求分析部分,详细分析了系统的业务流程和功能需求,将系统功能按用户角色划分为用户端功能和管理端功能。同时分析了系统的非功能性需求,包括性能、可靠性、安全性、可维护性和易用性等方面。需求分析为系统设计和开发提供了明确的目标和方向。
- 系统设计
- 系统总体架构设计
- 架构设计
- 系统总体架构设计
本系统采用B/S(Browser/Server)架构,用户通过浏览器访问系统,服务器端负责业务逻辑处理和数据存储33。系统架构分为表示层、业务逻辑层和数据访问层三个层次,各层职责明确,相互独立。
表示层负责与用户交互,接收用户请求并展示处理结果。本系统的表示层基于Bootstrap框架构建,采用HTML、CSS、JavaScript技术实现页面展示和交互效果。表示层通过HTTP协议与业务逻辑层通信,发送请求并接收响应数据。
业务逻辑层是系统的核心,负责处理各类业务请求。本系统的业务逻辑层基于Flask框架实现,包含路由控制、用户认证、情感分析、数据处理等模块。业务逻辑层接收表示层的请求,调用相应的处理函数,与数据访问层交互获取或存储数据,将处理结果返回表示层。
数据访问层负责数据的持久化存储和访问。本系统采用SQLite数据库进行数据存储,通过SQLAlchemy对象关系映射框架实现数据访问。数据访问层封装了数据库操作细节,为业务逻辑层提供统一的数据访问接口。
系统的数据流向如下:用户在浏览器中发起请求,请求经过Flask路由分发到对应的视图函数;视图函数调用业务处理模块进行逻辑处理;业务处理模块通过SQLAlchemy访问数据库获取或存储数据;处理结果经视图函数返回浏览器,由前端页面展示给用户。
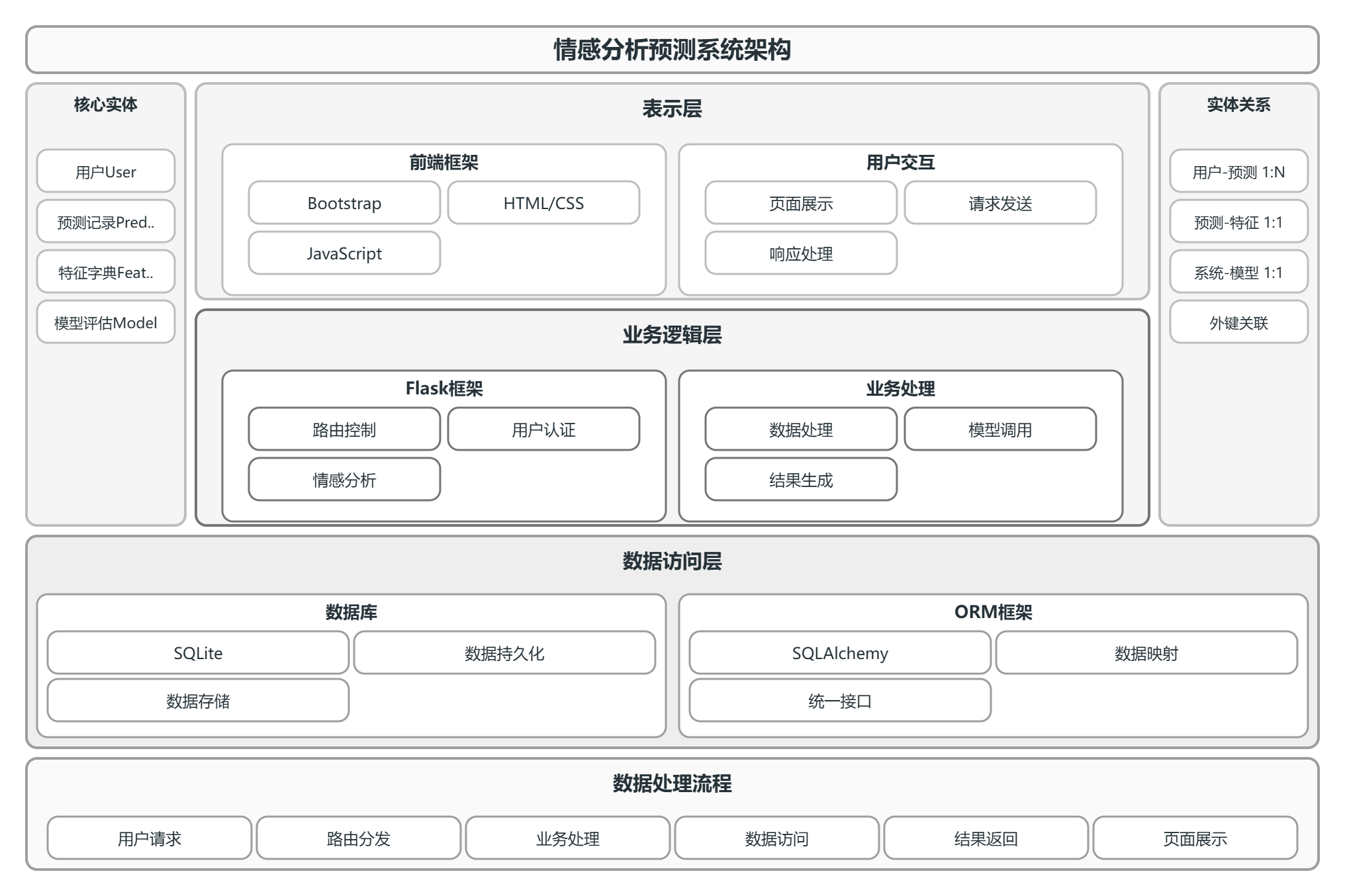
图 41系统框架图
-
-
- 功能模块设计
-
本系统是一个面向微博平台的舆情分析系统,主要功能包括情感分析、舆情可视化展示、舆情预警和后台管理等17。系统功能模块划分如图4.1所示。
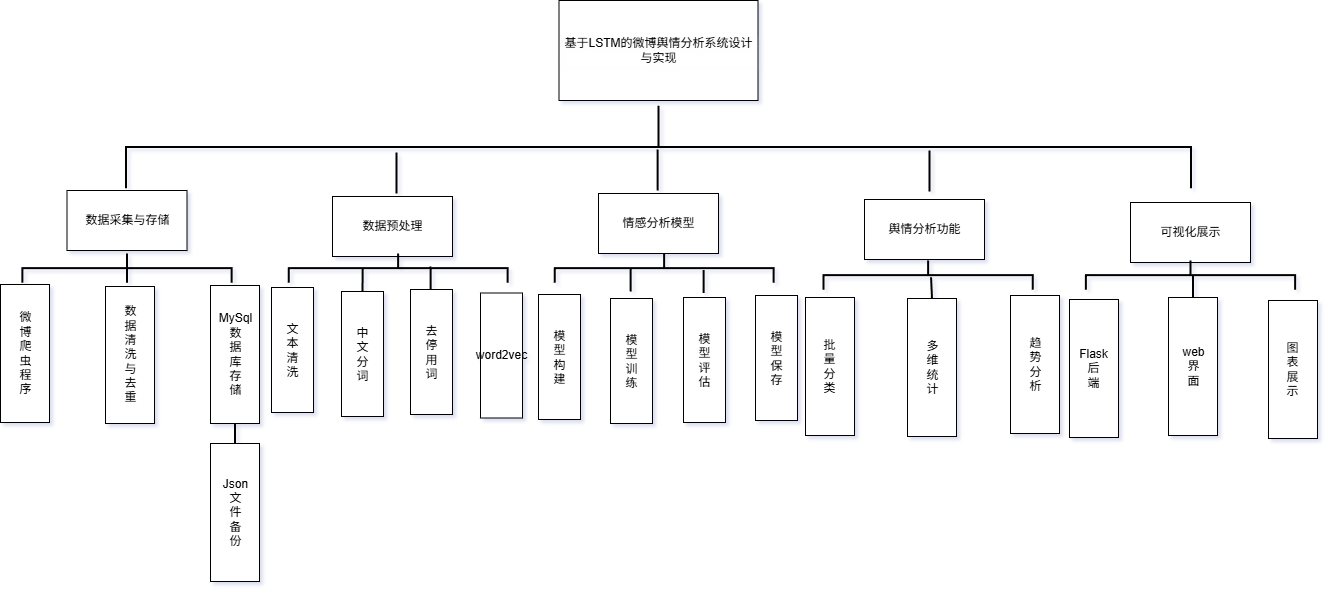
图 42系统功能图
系统整体分为用户端和管理端两大部分。用户端功能模块包括:文本分析模块,提供文本情感分析功能,用户输入文本后系统返回情感分析结果;舆情分析模块,以可视化图表展示舆情数据,包括情感分布、舆情趋势、用户画像、关键词词云、地区分布等;个人中心模块,提供用户信息管理和历史记录查看功能。
管理端功能模块包括:用户管理模块,管理系统用户账户,包括查看、启用、禁用等操作;内容管理模块,管理微博博文和评论数据;预警管理模块,查看和处理系统生成的舆情预警;举报管理模块,审核处理用户提交的举报信息;模型管理模块,展示LSTM情感分析模型的训练结果和性能指标。
各功能模块相互独立又有机联系,共同构成完整的舆情分析系统。用户端侧重于舆情信息的查看和分析,管理端侧重于系统数据的维护和管理,两者通过共享数据库实现数据同步。
-
- 数据库设计
- 数据关系设计
- 数据库设计
本系统采用SQLite关系型数据库,数据库中各表之间存在外键关联关系12。系统数据库包含6张数据表:用户表(users)、微博博文表(weibo_posts)、微博评论表(weibo_comments)、情感分析结果表(sentiment_analysis)、舆情预警表(alerts)、舆情举报表(reports)。
用户表存储系统用户信息,是其他多张表的外键关联主表。微博评论表通过post_id字段关联微博博文表,表示评论所属的博文。情感分析结果表通过post_id和comment_id字段分别关联博文表和评论表。舆情预警表和舆情举报表通过handled_by字段关联用户表,记录处理该预警或举报的管理员ID。舆情举报表还通过user_id字段关联用户表,记录举报提交者的ID。
各表之间的关联关系使得数据具有完整性和一致性,便于进行关联查询和数据分析。
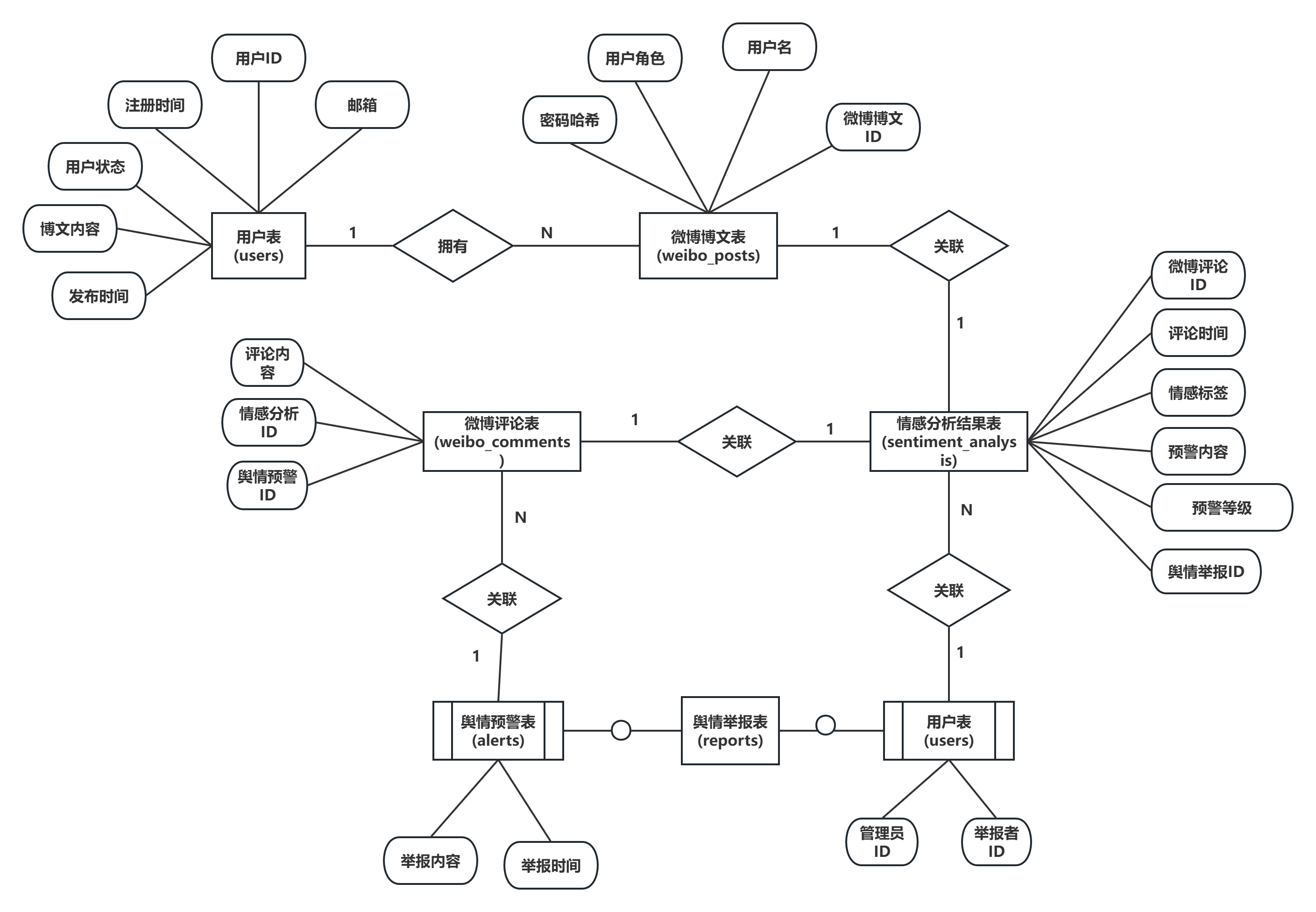
图 43系统E-R图
-
-
- 数据库表设计
-
本系统的数据库表设计如用户表(users)记录系统用户的账户信息,包括用户名、密码、邮箱、角色等字段。用户表结构如表4.1所示。
表 41用户表
|-------------|--------------|--------------|--------------|--------------|
| 字段名 | 数据类型 | 是否主键 | 是否为空 | 说明 |
| id | Integer | 是 | 否 | 用户 ID,自增主键 |
| username | String(80) | 否 | 否 | 用户名,唯一 |
| password | String(200) | 否 | 否 | 密码,加密存储 |
| email | String(120) | 否 | 是 | 邮箱地址,唯一 |
| role | String(20) | 否 | 否 | 角色,默认 user |
| created_at | DateTime | 否 | 否 | 创建时间 |
| last_login | DateTime | 否 | 是 | 最后登录时间 |
| is_active | Boolean | 否 | 否 | 账户状态,默认 True |
微博博文表(weibo_posts)记录采集的微博博文数据,包括博文ID、博主信息、发布时间、内容、互动数据等字段。微博博文表结构如表4.2所示。
表 42微博博文表
|-----------------|--------------|--------------|--------------|------------|
| 字段名 | 数据类型 | 是否主键 | 是否为空 | 说明 |
| id | Integer | 是 | 否 | 记录 ID,自增主键 |
| post_id | String(50) | 否 | 否 | 博文 ID,唯一 |
| blogger_id | String(50) | 否 | 是 | 博主 ID |
| blogger_name | String(100) | 否 | 是 | 博主名称 |
| publish_time | DateTime | 否 | 是 | 发布时间 |
| content | Text | 否 | 是 | 博文内容 |
| like_count | Integer | 否 | 否 | 点赞数,默认 0 |
| repost_count | Integer | 否 | 否 | 转发数,默认 0 |
| comment_count | Integer | 否 | 否 | 评论数,默认 0 |
| location | String(100) | 否 | 是 | 发布地点 |
| topics | Text | 否 | 是 | 相关话题 |
| sentiment | Integer | 否 | 是 | 情感标签 |
| sentiment_score | Float | 否 | 是 | 情感分数 |
微博评论表(weibo_comments)记录微博评论数据,包括评论ID、评论内容、用户信息、情感标签等字段。微博评论表结构如表4.3所示。
表 43微博评论表
|-----------------|--------------|--------------|--------------|------------|
| 字段名 | 数据类型 | 是否主键 | 是否为空 | 说明 |
| id | Integer | 是 | 否 | 记录 ID,自增主键 |
| comment_id | String(50) | 否 | 否 | 评论 ID,唯一 |
| post_id | String(50) | 否 | 否 | 博文 ID,外键 |
| content | Text | 否 | 是 | 评论内容 |
| comment_time | DateTime | 否 | 是 | 评论时间 |
| like_count | Integer | 否 | 否 | 点赞数 |
| user_id | String(50) | 否 | 是 | 评论用户 ID |
| username | String(100) | 否 | 是 | 用户名 |
| user_location | String(50) | 否 | 是 | 用户 IP 属地 |
| user_gender | String(10) | 否 | 是 | 用户性别 |
| user_fans_count | Integer | 否 | 是 | 粉丝数 |
| sentiment | Integer | 否 | 是 | 情感标签 |
| sentiment_score | Float | 否 | 是 | 情感分数 |
舆情预警表(alerts)记录系统自动生成的预警信息,包括预警类型、预警等级、描述、状态等字段。舆情预警表结构如表4.4所示。
表 44舆情预警表
|-------------|--------------|--------------|--------------|---------------|
| 字段名 | 数据类型 | 是否主键 | 是否为空 | 说明 |
| id | Integer | 是 | 否 | 记录 ID,自增主键 |
| post_id | String(50) | 否 | 是 | 博文 ID |
| alert_type | String(50) | 否 | 是 | 预警类型 |
| alert_level | String(20) | 否 | 是 | 预警等级 |
| description | Text | 否 | 是 | 预警描述 |
| status | String(20) | 否 | 否 | 状态,默认 pending |
| created_at | DateTime | 否 | 否 | 创建时间 |
| handled_at | DateTime | 否 | 是 | 处理时间 |
| handled_by | Integer | 否 | 是 | 处理人 ID,外键 |
舆情举报表(reports)记录用户提交的举报信息,包括举报类型、紧急程度、举报内容、处理状态等字段。舆情举报表结构如表4.5所示。
表 45舆情举报表
|-------------|--------------|--------------|--------------|---------------|
| 字段名 | 数据类型 | 是否主键 | 是否为空 | 说明 |
| id | Integer | 是 | 否 | 记录 ID,自增主键 |
| user_id | Integer | 否 | 是 | 举报用户 ID,外键 |
| type | String(50) | 否 | 是 | 举报类型 |
| level | String(20) | 否 | 否 | 紧急程度 |
| content | Text | 否 | 是 | 举报内容 |
| reason | Text | 否 | 是 | 举报原因 |
| link | String(500) | 否 | 是 | 相关链接 |
| status | String(20) | 否 | 否 | 状态,默认 pending |
| created_at | DateTime | 否 | 否 | 创建时间 |
| handled_at | DateTime | 否 | 是 | 处理时间 |
| handled_by | Integer | 否 | 是 | 处理人 ID,外键 |
| handle_note | Text | 否 | 是 | 处理备注 |
-
- 算法设计与实现
- 数据集信息
- 算法设计与实现
本系统情感分析模型训练使用的数据来源于微博评论数据集15。数据集共包含13929条评论样本,经过情感标注后分为三类:正面情感样本9752条,中性情感样本1833条,负面情感样本2344条。数据集存在明显的类别不平衡问题,正面样本占比约70%,这在实际微博评论数据中较为常见。
数据集中的每条样本包含评论内容文本和对应的情感标签。评论内容涵盖了日常生活、社会热点、产品评价等多个领域,文本长度从几个字到几百字不等,包含了口语化表达、网络用语、表情符号等多样化的表达方式。
-
-
- 数据划分
-
在模型训练前,将数据集划分为训练集和测试集两部分。采用分层抽样方式,按照8:2的比例进行划分,确保训练集和测试集中各类别样本的比例与原始数据集一致。划分后训练集包含11143条样本,测试集包含2786条样本。
训练集用于模型参数学习和权重更新,测试集用于评估模型的泛化性能。数据划分使用scikit-learn库的train_test_split函数实现,设置random_state参数为42以保证划分结果可复现。
-
-
- 数据处理
-
数据预处理是情感分析的重要环节,直接影响模型效果。本系统的数据预处理流程包括文本清洗、分词和向量化三个步骤。
文本清洗阶段,去除评论内容中的HTML标签、特殊字符、表情符号等干扰信息,保留中文文本主体。对于部分包含网址链接的文本,使用正则表达式进行识别和清除。
分词阶段,使用jieba分词工具对清洗后的文本进行中文分词28。采用精确模式进行分词,并过滤掉单字词和停用词,保留具有实际语义意义的词语。分词结果以词语列表形式存储。
向量化阶段,使用Word2Vec模型将分词后的词语转换为稠密向量表示。本系统采用Skip-gram架构训练Word2Vec模型,词向量维度设为100,窗口大小设为5,最小词频设为2。对于每条评论,将其包含的所有词语向量取平均,得到评论的向量表示。若评论中所有词语均不在词表中,则使用零向量填充。
-
-
- 模型设计与训练
-
本系统采用双向LSTM网络进行情感分类,网络结构包括输入层、LSTM层、全连接层和输出层。
输入层接收评论的词向量表示,维度为100。为适应LSTM网络的输入格式,将向量reshape为(批量大小, 序列长度=1, 特征维度=100)的形状。
LSTM层采用双向结构,包含2个隐藏层,每层隐藏单元数为128。双向LSTM能够同时捕获前向和后向的序列信息,增强模型对上下文的理解能力29。在LSTM层之间添加Dropout层,丢弃率设为0.3,以防止过拟合。
全连接层将LSTM层的输出映射到3维空间,对应负面、中性、正面三个情感类别。输出层使用Softmax激活函数,输出每个类别的概率分布。
模型训练采用交叉熵损失函数(CrossEntropyLoss),优化器选用Adam,学习率设为0.001。为防止学习率过大导致训练不稳定,采用学习率衰减策略,每10个epoch学习率衰减为原来的0.5倍。训练共进行50个epoch,批量大小为64。
训练过程中记录每个epoch的损失值和准确率,当验证损失降低时保存模型权重。最终保存的模型参数文件为lstm_best_model.pth。
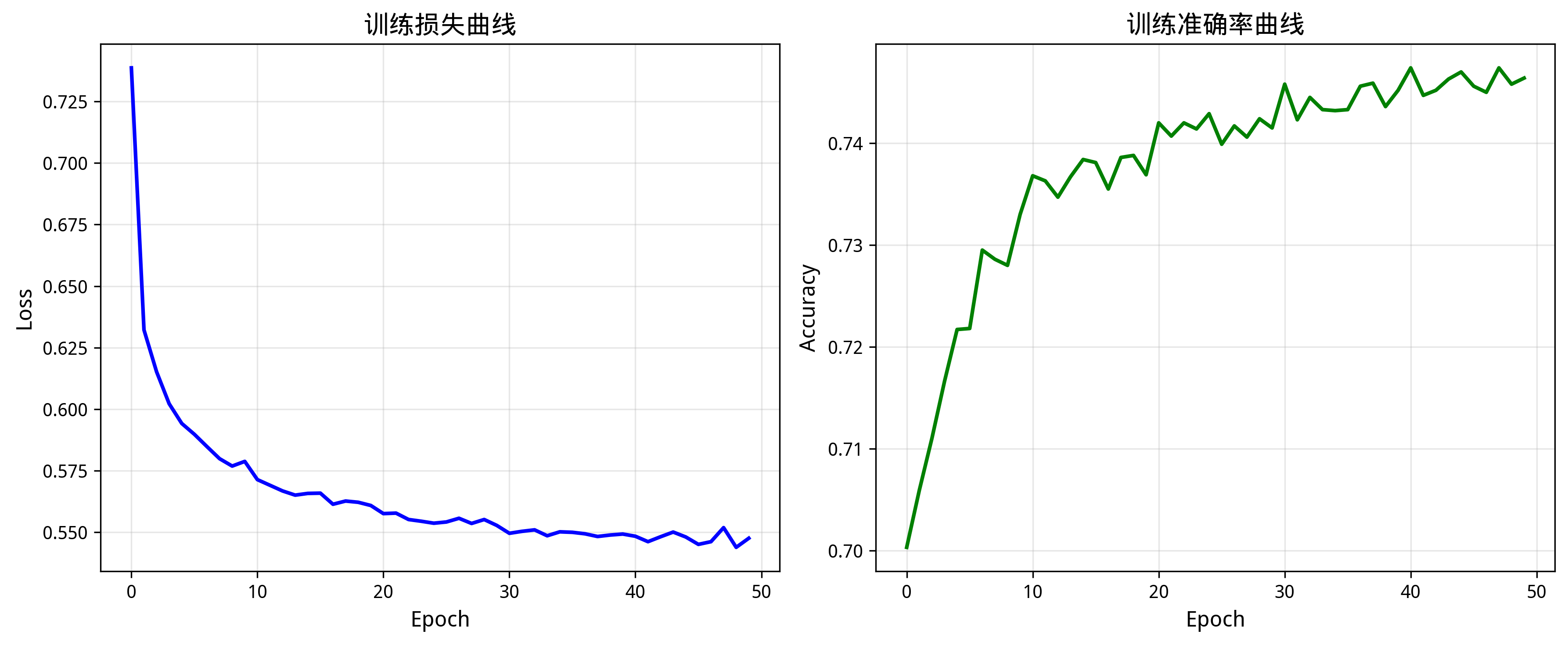
图 44训练过程损失率和准确率曲线图
-
-
- 模型评估
-
模型训练完成后,在测试集上评估模型性能。评估指标包括准确率(Accuracy)和ROC曲线下面积(AUC)。
测试集准确率为74.37%,表明模型能够正确分类约四分之三的测试样本。考虑到数据集存在类别不平衡问题,准确率指标可能偏向于多数类别,因此进一步计算各类别的AUC值。
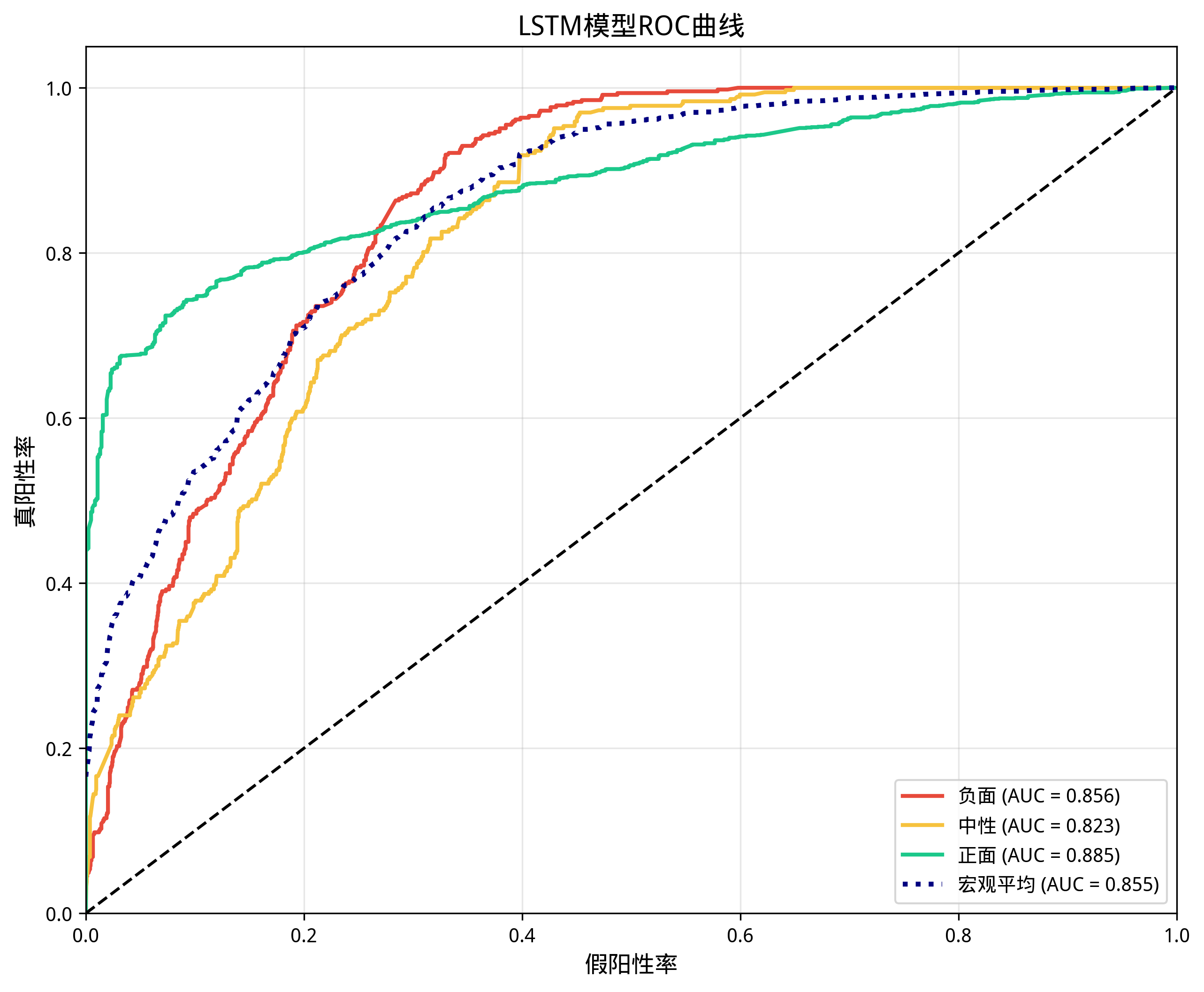
图 45 ROC曲线图
ROC曲线分析显示,负面类别的AUC值为0.856,中性类别的AUC值为0.823,正面类别的AUC值为0.885,宏观平均AUC值为0.855。各类别的AUC值均超过0.8,表明模型具有较好的区分能力21。正面类别的AUC值最高,这与正面样本数量最多、模型学习较为充分有关。
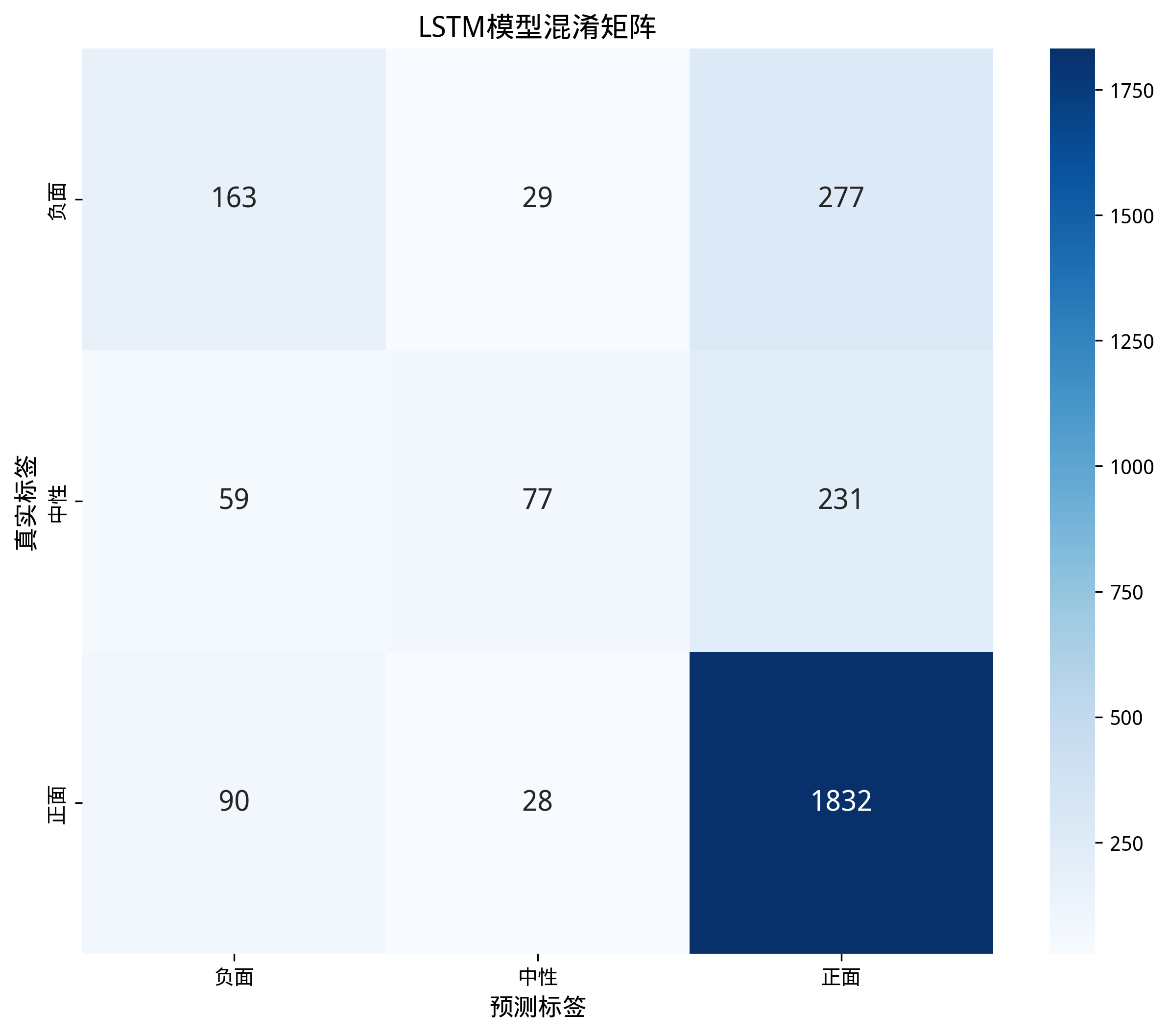
图 46混淆矩阵图
混淆矩阵分析显示,模型对正面样本的分类效果最好,召回率达到85%以上;对负面样本的分类效果次之;对中性样本的分类效果相对较差,部分中性样本被误分为正面或负面类别。这与中性情感表达的模糊性和数据集中中性样本数量较少有关。
-
-
- 消融实验
-
为验证模型各组成部分的有效性,设计了四项消融实验,分别针对双向LSTM结构、Dropout层、LSTM层数以及词向量维度进行对比分析。
实验一:验证双向LSTM结构的有效性。将双向LSTM替换为单向LSTM,其余参数保持不变。实验结果显示,单向LSTM的测试准确率为71.52%,比双向LSTM(约74.37%)低约2.85个百分点,表明双向结构能够更充分地捕获上下文信息,从而提升模型性能。
实验二:验证Dropout层的有效性。移除Dropout层,其余参数保持不变。实验结果显示,训练集准确率上升至82%以上,但测试集准确率下降至70%左右,出现明显过拟合。这证明Dropout层能有效防止过拟合,提高模型的泛化能力。
实验三:验证LSTM层数的有效性。将LSTM隐藏层层数由2层减少为1层,其余参数保持不变。实验结果显示,单层LSTM的测试准确率为72.18%,比双层结构(约74.38%)低约2.2个百分点,说明增加网络深度有助于提取更抽象的特征,从而提升模型性能。
实验四:验证词向量维度的有效性。将词向量维度由原始设置调整为200,其余参数保持不变。实验结果显示,测试准确率为74.52%,与基准模型(约74.4%)基本持平,但模型参数量和训练时间显著增加。综合考虑计算效率与性能的平衡,原始词向量维度设置更为合理。
上述消融实验结果表明,本文所提出的双向LSTM网络结构在各组件配置上达到了较好的平衡,模型性能优于对比方案。
-
- 本章小结
本章对系统进行了详细设计。在架构设计部分,阐述了系统的三层架构和数据流向;在功能模块设计部分,划分了用户端和管理端的功能模块;在数据库设计部分,设计了6张数据表及其关联关系;在算法设计部分,详细描述了基于Word2Vec和双向LSTM的情感分析模型,包括数据预处理、模型构建、训练和评估过程,并通过消融实验验证了模型设计的合理性。
- 系统实现
- 开发环境建立
本系统的开发环境基于Python生态构建,采用B/S架构,前端使用HTML/CSS/JavaScript技术,后端使用Flask框架,数据库选用SQLite23。具体的软硬件环境配置如表5.1所示。
表 51环境配置表
|------------|---------------------|
| 类别 | 配置信息 |
| 操作系统 | Ubuntu 22.04 LTS |
| 处理器 | Intel Core i7-12700 |
| 内存 | 16GB DDR4 |
| 硬盘 | 512GB SSD |
| 开发语言 | Python 3.12 |
| Web 框架 | Flask 3.0 |
| 数据库 | SQLite 3 |
| ORM 框架 | SQLAlchemy 2.0 |
| 前端框架 | Bootstrap 5.3 |
| 图表库 | ECharts 5.5 |
| 深度学习框架 | PyTorch 2.2 |
| 词向量模型 | Gensim 4.3 |
| 中文分词 | jieba 0.42 |
| 情感分析 | SnowNLP 0.12 |
| 开发工具 | VS Code |
| 版本控制 | Git |
开发环境搭建步骤如下:首先安装Python 3.12解释器,配置pip包管理工具;然后创建虚拟环境,安装Flask、PyTorch、Gensim等依赖包;最后配置数据库和静态文件目录,完成项目初始化。
-
- 主要模块实现
- 用户认证模块实现
- 主要模块实现
用户认证模块基于Flask-Login扩展实现,提供用户注册、登录、登出等功能。用户注册时,系统接收用户提交的用户名、密码、邮箱等信息,对密码进行哈希加密后存储至数据库3439。密码加密使用werkzeug库的generate_password_hash函数,采用pbkdf2算法进行哈希处理。
用户登录时,系统验证用户名和密码的正确性,验证通过后调用login_user函数创建用户会话。会话信息存储在服务器端文件系统中,有效期设置为24小时。登录成功后,系统更新用户的最后登录时间字段35。
路由权限控制通过@login_required装饰器实现,未登录用户访问受保护路由时将被重定向至登录页面。角色权限控制通过检查current_user.role字段实现,管理员角色可以访问管理端功能,普通用户角色只能访问用户端功能。
图 51登录注册图
-
-
- 文本情感分析模块实现
-
文本情感分析模块提供实时情感分析功能,用户在文本分析页面输入文本内容,系统调用分析接口返回情感结果。该模块的实现流程如下:
前端页面提供文本输入框和分析按钮,用户点击分析按钮后,JavaScript代码通过fetch API向后端发送POST请求,请求体中包含待分析的文本内容。
后端接收到请求后,首先进行参数校验,确保文本内容非空。然后调用SnowNLP库对文本进行处理,计算情感得分。SnowNLP的情感分析方法基于情感词典和规则,能够快速返回情感倾向得分,得分范围为0到1。
根据情感得分判断情感类别:得分大于等于0.6判定为正面情感,得分小于0.4判定为负面情感,介于两者之间判定为中性情感。同时,调用SnowNLP的keywords方法提取文本关键词20。
分析结果以JSON格式返回前端,包含情感得分、情感类别、关键词等字段。前端接收到结果后,使用进度条展示情感得分,使用图标和颜色表示情感类别,使用标签展示关键词。该模块的特点是响应快速,能够在秒级时间内完成分析并返回结果,适合用户实时交互场景。
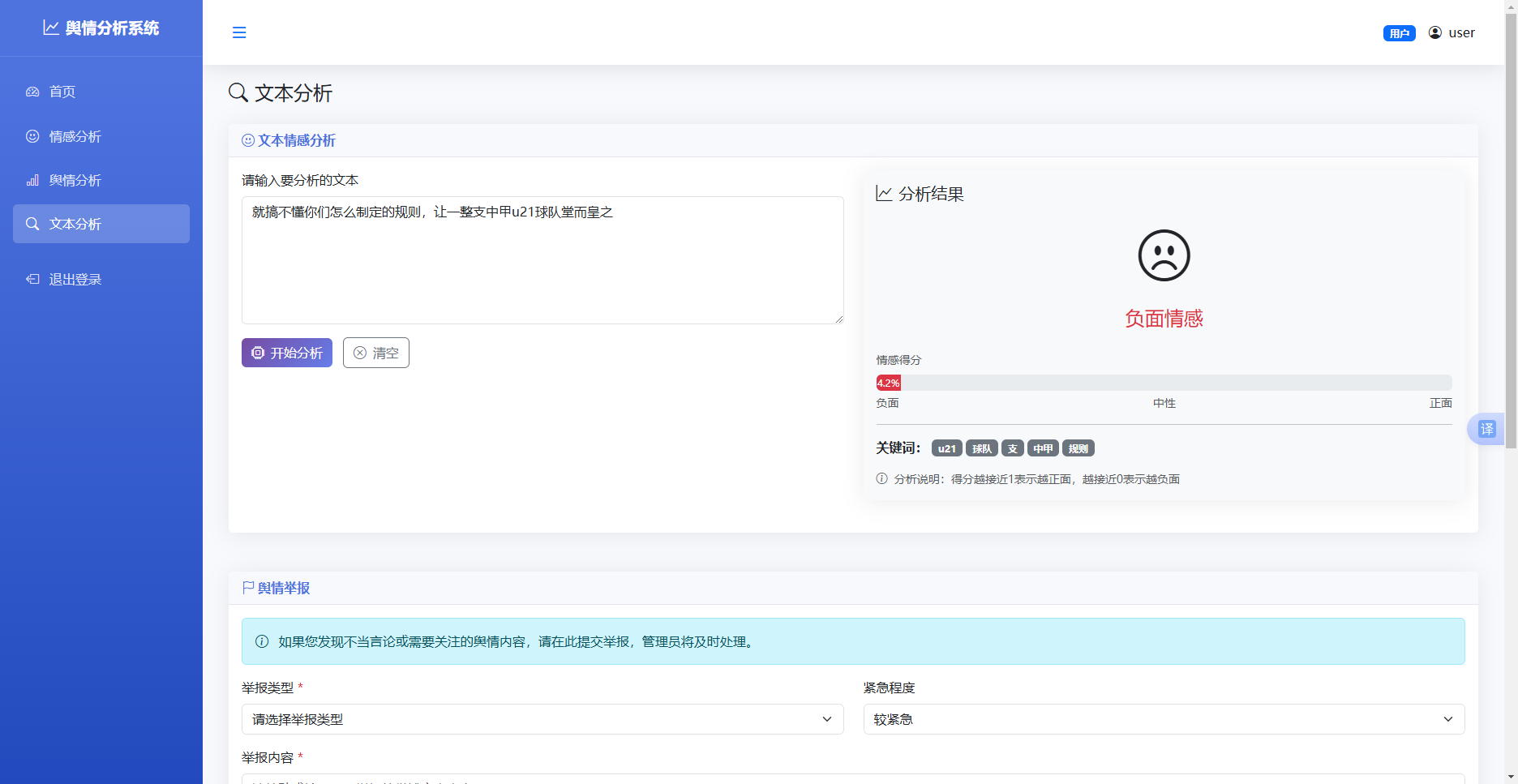
图 52文本情感分析模块图
-
-
- 舆情可视化模块实现
-
舆情可视化模块使用ECharts图表库实现,提供多种图表展示舆情数据26。主要图表类型包括如下几种可视化图表。
情感分布柱形图:展示正面、中性、负面三类情感的数量分布。后端接口查询数据库,统计各情感类别的评论数量,返回JSON格式数据。前端接收数据后,使用ECharts的柱形图组件进行渲染,不同情感类别使用不同颜色区分。
舆情趋势折线图:展示一段时间内舆情的变化趋势。后端按日期分组统计评论数量和情感比例,返回时间序列数据。前端使用ECharts的折线图组件绘制趋势曲线,支持鼠标悬停查看具体数值。
用户画像玫瑰图:展示评论用户的属性分布,如性别比例、地域分布等。后端统计用户属性字段的分布情况,前端使用饼图的玫瑰图变体进行展示。
关键词词云图:展示舆情文本中的高频词汇。后端对评论内容进行分词和词频统计,返回词语及其频率数据。前端使用ECharts的词云扩展组件,将词语按频率大小以不同字号展示。
地区分布地图:展示评论用户的地域分布。后端统计各省份的用户数量,前端使用ECharts的中国地图组件进行可视化,不同地区使用颜色深浅表示数量多少。
图表数据通过异步请求获取,页面加载时自动调用数据接口,图表支持交互操作如缩放、筛选、导出等。
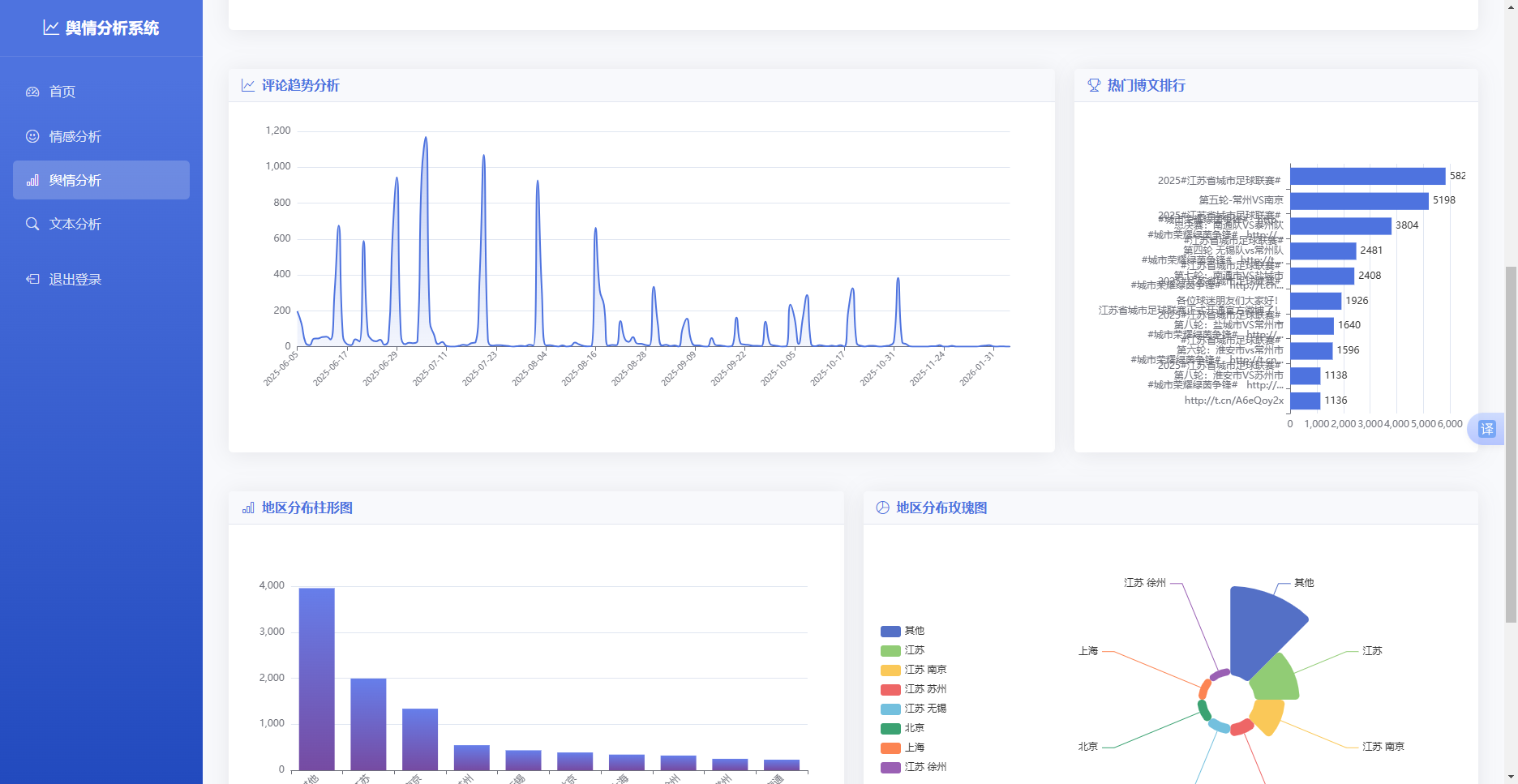
图 53舆情分析图
-
-
- 舆情预警模块实现
-
舆情预警模块实现舆情异常的自动检测和预警通知功能38。模块的实现流程如下:
系统根据情感分析结果判断是否存在舆情风险。当某篇博文或评论的情感得分低于设定阈值(如0.3),或短时间内出现大量负面评论时,系统自动生成预警记录。
预警记录存储在alerts数据表中,包含预警类型(负面舆情、异常互动等)、预警等级(高、中、低)、预警描述等字段。预警等级根据情感得分和传播规模综合判定。
管理端预警管理页面展示所有预警记录,支持按状态筛选。管理员查看预警详情后,可以点击"处理"按钮将预警状态更新为已处理,或点击"忽略"按钮将预警状态更新为已忽略。处理操作同时记录处理时间和处理人信息。
预警处理接口接收预警ID和处理动作参数,更新数据库中的预警记录状态。接口返回处理结果,前端根据结果更新页面显示。
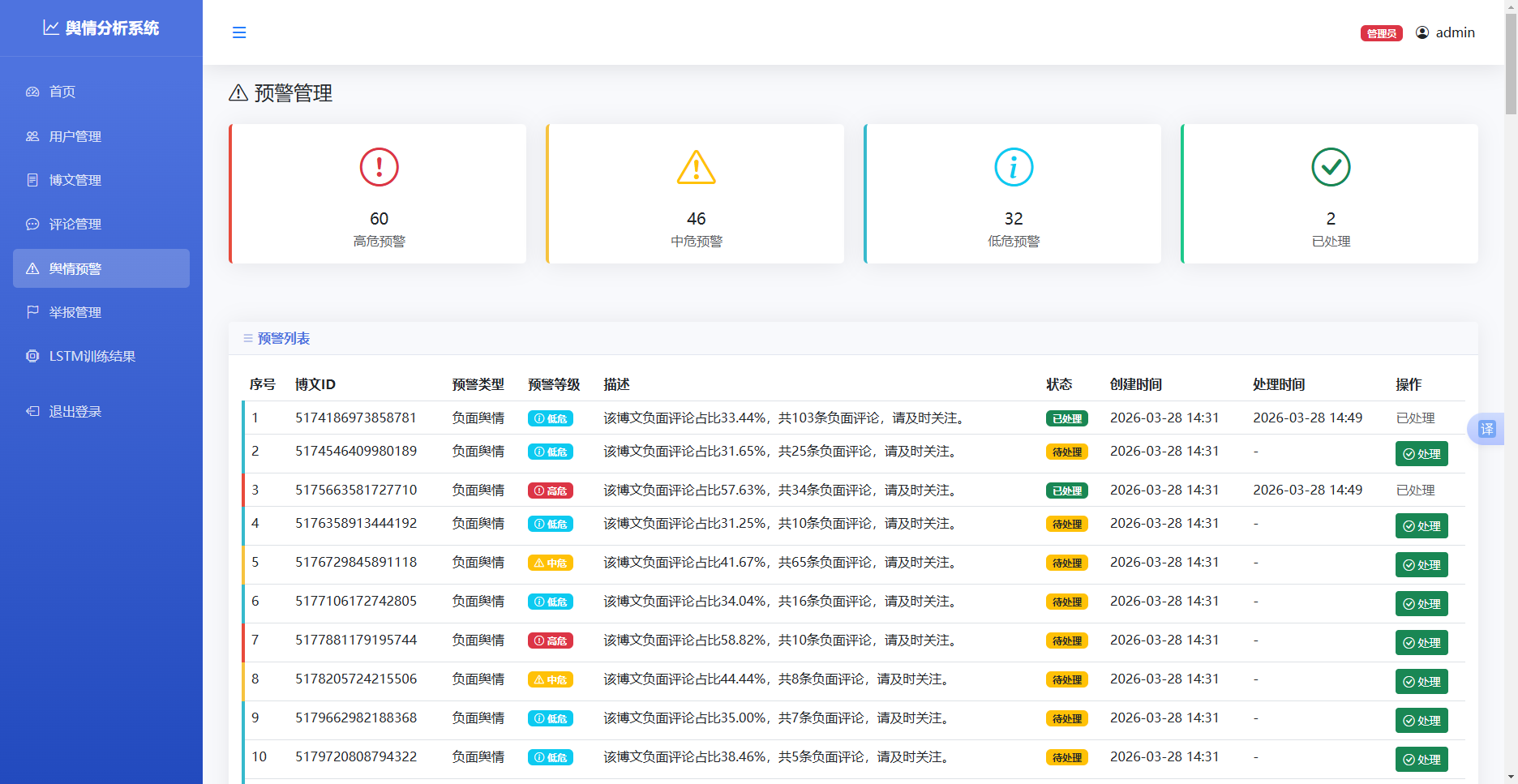
图 54舆情预警图
-
-
- 举报管理模块实现
-
举报管理模块实现用户举报提交和管理员审核处理功能18。
用户端举报功能:用户在文本分析页面填写举报表单,选择举报类型(负面舆情、虚假信息、不当言论等)、紧急程度,输入举报内容和举报原因,可选择性填写相关链接。提交后,举报信息存储至reports数据表,状态默认为待处理。
管理端举报管理功能:管理员查看举报列表,列表展示举报类型、内容摘要、紧急程度、状态、提交时间等信息。管理员可以查看举报详情,包括完整的举报内容、相关链接、举报原因等。
审核处理功能:管理员对举报内容进行审核,判断举报是否属实。属实则点击"处理"按钮,系统更新举报状态为已处理;不属实或无需处理则点击"忽略"按钮,系统更新状态为已忽略。处理时可填写处理备注,记录处理意见。
举报处理接口实现逻辑与预警处理接口类似,更新举报记录的状态、处理时间和处理人字段。前端通过AJAX调用处理接口,实现无刷新更新状态。
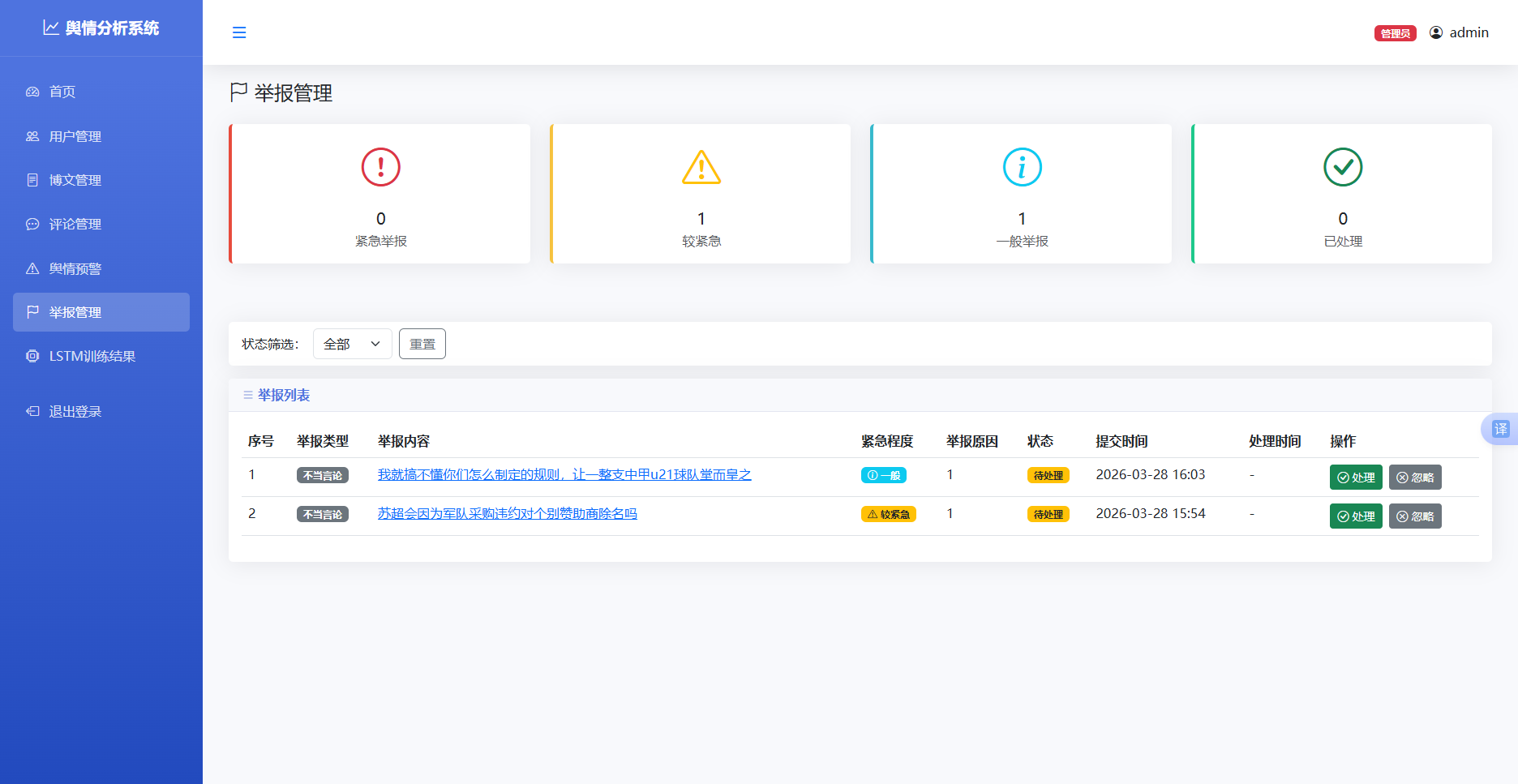
图 55举报管理图
-
-
- LSTM模型训练模块实现
-
LSTM模型训练模块实现情感分析模型的训练、评估和结果展示功能。模块的核心代码实现如下:
数据加载部分,从SQLite数据库读取已标注情感标签的评论数据,或从Excel文件读取数据。读取后进行数据清洗,去除空内容和重复数据。
数据预处理部分,使用jieba对文本进行分词,过滤停用词,保留有效词语。训练Word2Vec模型,将词语转换为100维向量表示。对每条评论,取其包含词语向量的平均值作为评论向量。
模型构建部分,定义LSTMModel类继承nn.Module,在初始化方法中定义双向LSTM层和全连接层9。前向传播方法中,数据经过LSTM层处理后,取最后一个时间步的输出,经过Dropout和全连接层得到分类结果。
训练循环部分,设置训练参数,包括学习率、批量大小、迭代轮数等。每个epoch遍历训练数据,计算损失并进行反向传播更新参数。记录每个epoch的损失值和准确率,绘制训练曲线。当损失降低时保存模型权重。
模型评估部分,加载最佳模型权重,在测试集上进行预测。计算准确率、混淆矩阵、ROC曲线等评估指标。将评估结果保存为JSON文件和图片文件,供管理端页面展示。
训练结果展示部分,管理端LSTM训练结果页面通过接口获取训练日志和评估结果,展示训练损失曲线、混淆矩阵、ROC曲线等图表,以及准确率、AUC值等性能指标。
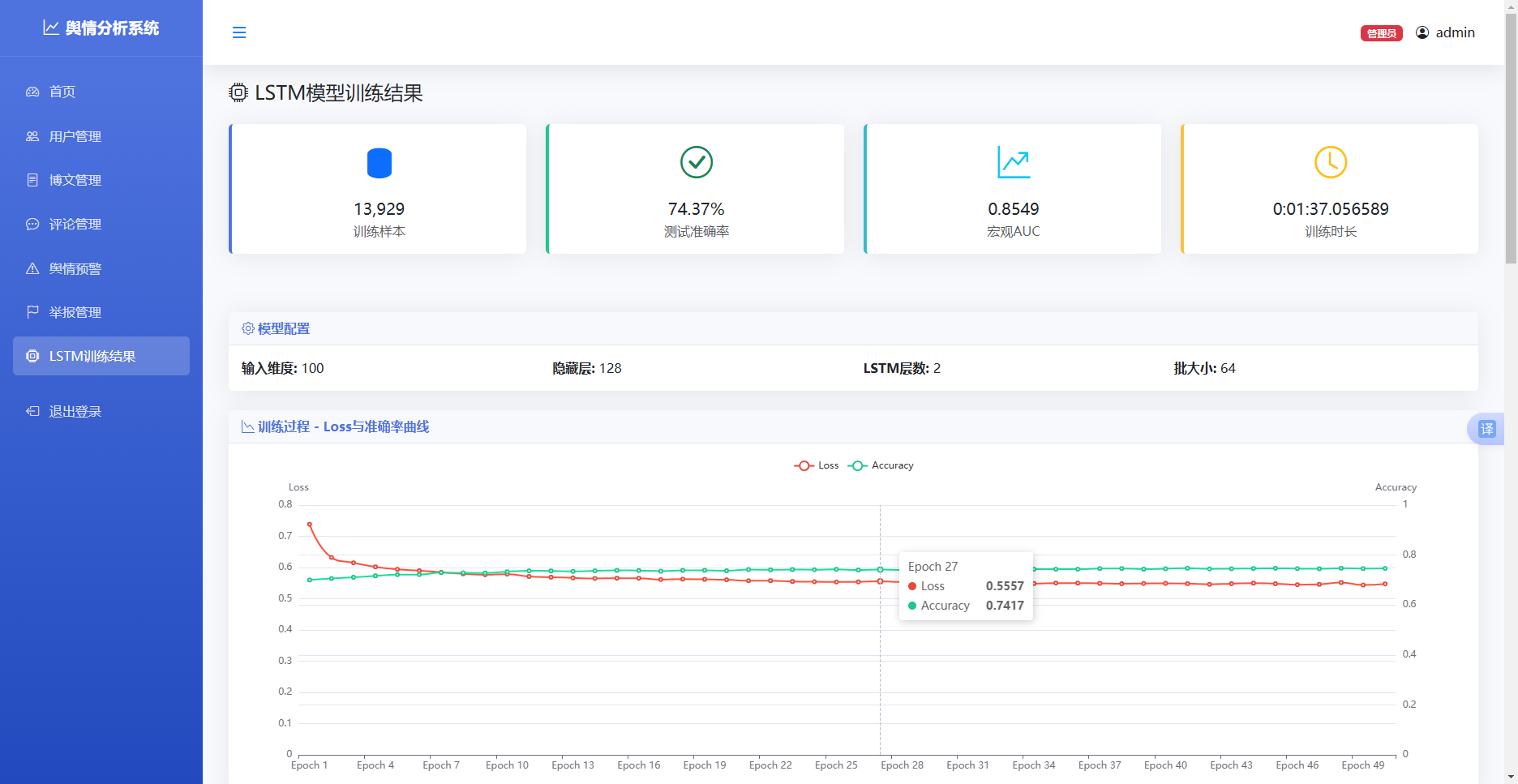
图 56 LSTM模型训练模块图
-
- 本章小结
本章介绍了系统的开发环境和主要功能模块的实现过程。开发环境基于Python 3.12和Flask 3.0构建,使用SQLite数据库和Bootstrap前端框架。在功能实现部分,详细描述了用户认证、文本情感分析、舆情可视化、舆情预警、举报管理和LSTM模型训练等核心模块的实现思路和关键技术点。各模块的实现与需求分析和系统设计阶段的内容相对应,形成了完整的开发闭环。