在实时数据处理场景中,如果想要动态捕获数据库中(如:MySQL)增删改查数据可以通过canal/maxwell这些数据同步工具来实现,这些工具底层通过监控数据库binlog日志将变化数据监控到消息中间件中(如:Kafka),然后Flink再通过读取消息中间件中的数据进行业务处理进而将结果Sink到目标端。
以上动态捕获数据库中数据使用到了第三方工具,如canal、Kafka等,从Flink1.11版本开始,我们可以直接通过FlinkCDC完成以上数据同步场景,大大简化使用技术组件的复杂度,使动态捕获数据库数据变的容易简单,本章节我们将对FlinkCDC技术进行讲解。
FlinkCDC简介
FlinkCDC(Flink Change Data Capture)是一个基于Apache Flink的开源项目,用于实时捕获和处理数据库中的数据变化。它的主要目标是将数据库中的变更事件流(如INSERT、UPDATE和DELETE操作)捕获并转换成实时流数据,以便进行实时数据分析、ETL(Extract, Transform, Load)操作以及其他数据处理任务。
FlinkCDC官网地址:https://ververica.github.io/flink-cdc-connectors/,文档地址:https://ververica.github.io/flink-cdc-connectors/master/
Flink CDC使用场景
FlinkCDC可以看做自定义的Flink DataSource,可以直接对接外部存储库捕获变事件交由Flink进行处理。FlinkCDC利用Debezium(监控数据库数据变化的工具)作为捕获数据变更的引擎,Debezium负责实际的CDC(Change Data Capture,变更数据捕获)操作,而Flink对捕获的变更事件进行进一步的流数据处理。
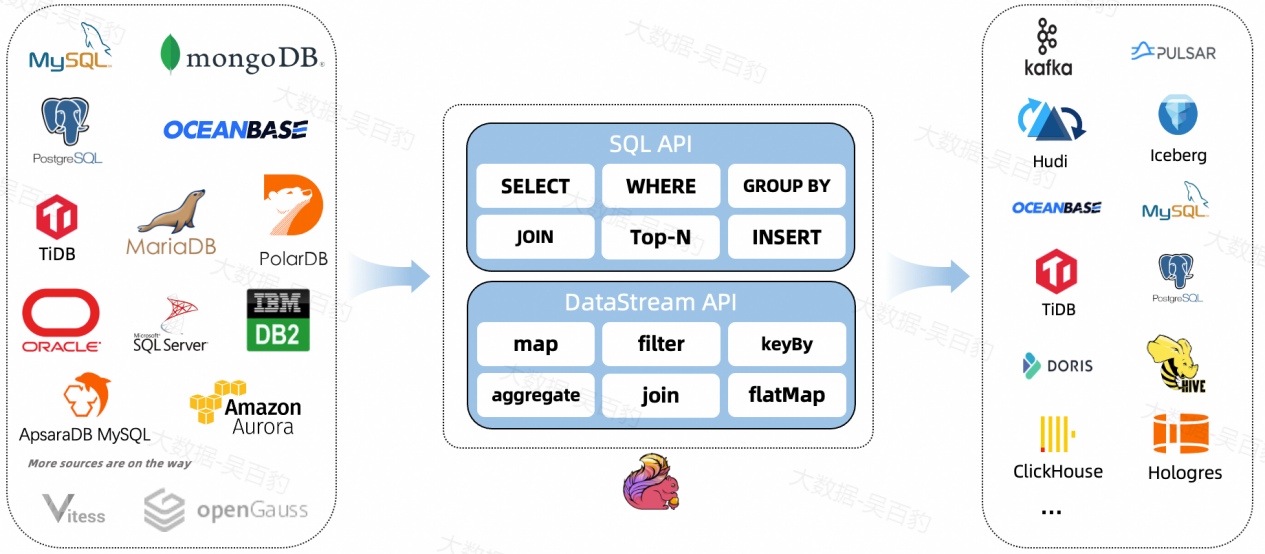
FlinkCDC是通过各种Connector来捕获各类数据库数据,不仅仅限于mysql数据库,还支持mongodb、oceanbase、oracle、postgres、sqlserver、tidb、db2、vitess等数据库。FlinkCDC主要用于构建实时数据管道、数据仓库同步、实时分析等场景。
FlinkCDC特点
FlinkCDC有如下特点:
-
支持读取数据库快照,即使出现故障也支持exactly-once读取数据库binlog。
-
在Flink DataStream API中使用FlinkCDC,支持单个作业监控多个数据库和表的binlog数据变化,而无需部署Debezium和Kafka。
-
在Flink Table/SQL API中,支持使用SQL DDL创建CDC源,监控单表的binlog变化。
下表是FlinkCDC 各Connector支持的特性:
| Connector | 无锁读 | 并行读 | exactly-once语义 | 增量快照读 |
|---|---|---|---|---|
| mongodb-cdc | ✅ | ✅ | ✅ | ✅ |
| mysql-cdc | ✅ | ✅ | ✅ | ✅ |
| oracle-cdc | ✅ | ✅ | ✅ | ✅ |
| postgres-cdc | ✅ | ✅ | ✅ | ✅ |
| sqlserver-cdc | ✅ | ✅ | ✅ | ✅ |
| oceanbase-cdc | ❌ | ❌ | ❌ | ❌ |
| tidb-cdc | ✅ | ❌ | ✅ | ❌ |
| db2-cdc | ❌ | ❌ | ✅ | ❌ |
| vitess-cdc | ✅ | ❌ | ✅ | ❌ |
Flink CDC 版本与Flink版本对应关系如下,在使用Flink CDC过程中需要特别注意版本匹配。本书中我们将基于Flink CDC 2.4.1版本进行讲解。
| Flink CDC Version | Flink Version |
|---|---|
| 1.0.0 | 1.11.* |
| 1.1.0 | 1.11.* |
| 1.2.0 | 1.12.* |
| 1.3.0 | 1.12.* |
| 1.4.0 | 1.13.* |
| 2.0.* | 1.13.* |
| 2.1.* | 1.13.* |
| 2.2.* | 1.13.,1.14. |
| 2.3.* | 1.13.,1.14.,1.15.*,1.16.0 |
| 2.4.* | 1.13.,1.14. ,1.15.,1.16.,1.17.0 |
MySQL CDC Connector
我们将以常见的MySQL CDC Connector为例来讲解Flink CDC的使用,并着重介绍MySQL CDC Connector中的一些特性。
MySQL CDC Connector使用
MySQL CDC Connector可以基于Flink DataStram API和Table/SQL API中同步MySQL数据库数据。只要MySQL开启了binlog功能,MySQL CDC Connector支持从mysql中全量或者增量进行数据读取,下面分别进行案例演示。由于java代码和Scala代码编写FlinkCDC程序类似,这里只给出java代码案例。
环境准备
无论是在基于DataStream API还是SQL API使用FlinkCDC都需要在maven项目中导入mysql-cdc依赖,如下:
<!--Flink MySQL CDC Connector依赖包 -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>${mysql.cdc.version}</version>
</dependency>在MySQL CDC Connector 2.1版本前使用MySQL CDC Connector需要在项目中额外导入MySQL的mysql-connector-java驱动包,从MySQL CDC Connector2.1版本后,我们只需要导入flink-connector-mysql-cdc依赖包即可,这里我们使用的是2.4.1版本,所以不再需要额外导入mysql-connector-java驱动包。此外还需要根据使用的DataStream或者Table/SQL API 导入Flink对应依赖包。
注意:如果使用MySQL CDC Connector2.1后的版本,需要去掉项目依赖中存在的mysql-connector-java驱动包。
开启MySQL binlog
MySQL CDC Connector底层会通过MySQL binlog来捕获数据变更,所以需要在MySQL中开启binlog,步骤如下:
1) 登录mysql查看MySQL是否开启binlog日志
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';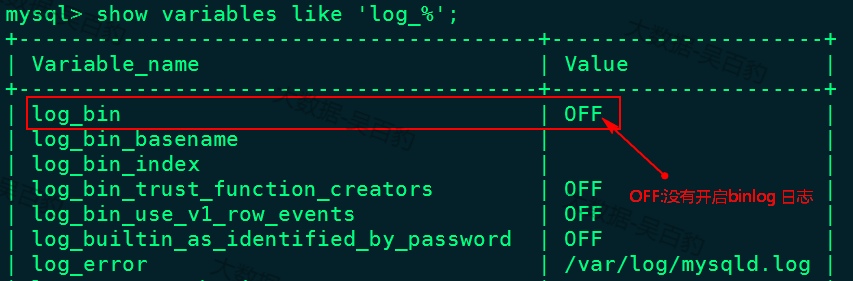
2) 开启mysql binlog日志
在/etc/my.cnf文件中mysqld下写入以下内容:
[mysqld]
# 随机指定一个不能和其他集群中机器重名的字符串,配置 MySQL replaction 需要定#义,不要和 canal 的 slaveId 重复
server-id=123
#配置binlog日志目录,配置后会自动开启binlog日志,并写入该目录
log-bin=/var/lib/mysql/mysql-bin
# 选择 ROW 模式
binlog-format=ROW3) 重启mysql 服务,重新查看binlog日志情况
[root@node2 ~]# service mysqld restart
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';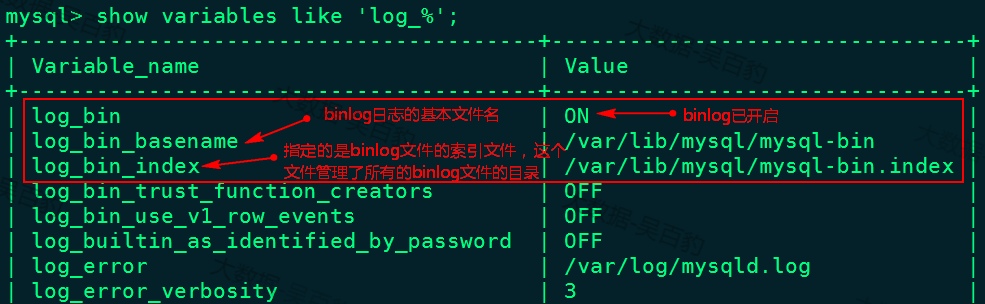
基于DataStream API使用
基于Flink DataStream API 通过MySQL CDC Connector获取MySQL中的数据代码如下:
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("node2") //设置MySQL hostname
.port(3306) //设置MySQL port
.databaseList("db1") //设置捕获的数据库
.tableList("db1.tbl1,db1.tbl2") //设置捕获的数据表
.username("root") //设置登录MySQL用户名
.password("123456") //设置登录MySQL密码
.deserializer(new JsonDebeziumDeserializationSchema()) //设置序列化将SourceRecord 转换成 Json 字符串
.startupOptions(StartupOptions.initial())
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//开启checkpoint
env.enableCheckpointing(5000);
env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(),"MySQL Source")
.setParallelism(4)
.print();
env.execute();在DataStream API中通过MySQL CDC Connector可以监控多个MySQL数据库及多个表,以上代码中监控MySQL db1数据库中的tbl1和tbl2两张表CDC事件。编写以上代码需要注意以下几点:
-
在MySQL CDC Connector 2.4.0版本之前,监控MySQL的表需要有主键,从2.4.0版本开始支持监控无主键表,但需要设置"scan.incremental.snapshot.chunk.key-column"参数,详细参考无主键表内容。
-
MySQL CDC Connector监控表时多个表使用逗号隔开,并且每个表必须指定所属库。
-
代码中设置startupOptions(StartupOptions.initial())表示代码在第一次启动时对受监视的数据库表执行初始快照,并继续读取最新binlog。StartupOptions其他配置项后续小节还会讲解。
-
Flink中必须设置checkpiont,不设置checkpoint将无法正常监控输出binlog日志变更数据。
代码运行之前需要保证MySQL中存在db1库及tbl1和tbl2表,如果没有通过以下语句进行创建。
mysql> create database db1;
mysql> use db1;
mysql> create table tbl1(id int primary key,name varchar(255),age int);
mysql> create table tbl2(id int primary key,name varchar(255),score int);代码执行后,可以对tbl1和tbl2表进行插入、修改、删除操作:
#向表tbl1中插入数据
mysql> insert into tbl1 values (1,'zs',18),(2,'ls',19),(3,'ww',20);
#向表tbl1中更新id为2的数据
mysql> update tbl1 set name = 'lisi',age='20' where id = 2;
#删除表tbl1中id为3的数据
mysql> delete from tbl1 where id =3;
#向表tbl2中插入数据
mysql> insert into tbl2 values (1,'zs',100),(2,'ls',200),(3,'ww',300);代码执行后随着向MySQL中操作不同,输出结果如下:
#向表tbl1中插入数据
8> {"before":null,"after":{"id":2,"name":"ls","age":19},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1696941931000,"snapshot":"false","db":"db1","sequence":null,"table":"tbl1","server_id":123,"gtid":null,"file":"mysql-bin.000001","pos":8040,"row":1,"thread":77,"query":null},"op":"c","ts_ms":1696941931728,"transaction":null}
7> {"before":null,"after":{"id":1,"name":"zs","age":18},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1696941931000,"snapshot":"false","db":"db1","sequence":null,"table":"tbl1","server_id":123,"gtid":null,"file":"mysql-bin.000001","pos":8040,"row":0,"thread":77,"query":null},"op":"c","ts_ms":1696941931725,"transaction":null}
1> {"before":null,"after":{"id":3,"name":"ww","age":20},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1696941931000,"snapshot":"false","db":"db1","sequence":null,"table":"tbl1","server_id":123,"gtid":null,"file":"mysql-bin.000001","pos":8040,"row":2,"thread":77,"query":null},"op":"c","ts_ms":1696941931728,"transaction":null}
#修改表tbl1 id为2的数据
{"before":{"id":2,"name":"ls","age":19},"after":{"id":2,"name":"lisi","age":20},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1696941936000,"snapshot":"false","db":"db1","sequence":null,"table":"tbl1","server_id":123,"gtid":null,"file":"mysql-bin.000001","pos":8331,"row":0,"thread":77,"query":null},"op":"u","ts_ms":1696941937208,"transaction":null}
#删除表tbl1中id为3的数据
{"before":{"id":3,"name":"ww","age":20},"after":null,"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1696941941000,"snapshot":"false","db":"db1","sequence":null,"table":"tbl1","server_id":123,"gtid":null,"file":"mysql-bin.000001","pos":8612,"row":0,"thread":77,"query":null},"op":"d","ts_ms":1696941941399,"transaction":null}
#向表tbl2中插入数据
4> {"before":null,"after":{"id":1,"name":"zs","score":100},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1696941947000,"snapshot":"false","db":"db1","sequence":null,"table":"tbl2","server_id":123,"gtid":null,"file":"mysql-bin.000001","pos":8877,"row":0,"thread":77,"query":null},"op":"c","ts_ms":1696941947366,"transaction":null}
5> {"before":null,"after":{"id":2,"name":"ls","score":200},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1696941947000,"snapshot":"false","db":"db1","sequence":null,"table":"tbl2","server_id":123,"gtid":null,"file":"mysql-bin.000001","pos":8877,"row":1,"thread":77,"query":null},"op":"c","ts_ms":1696941947366,"transaction":null}
6> {"before":null,"after":{"id":3,"name":"ww","score":300},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1696941947000,"snapshot":"false","db":"db1","sequence":null,"table":"tbl2","server_id":123,"gtid":null,"file":"mysql-bin.000001","pos":8877,"row":2,"thread":77,"query":null},"op":"c","ts_ms":1696941947366,"transaction":null}当停止代码再次执行后,会重新读取快照binglog数据并输出,结果如下:
#tbl1中两条数据
7> {"before":null,"after":{"id":2,"name":"lisi","age":20},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":0,"snapshot":"false","db":"db1","sequence":null,"table":"tbl1","server_id":0,"gtid":null,"file":"","pos":0,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1697007381829,"transaction":null}
8> {"before":null,"after":{"id":1,"name":"zs","age":18},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":0,"snapshot":"false","db":"db1","sequence":null,"table":"tbl1","server_id":0,"gtid":null,"file":"","pos":0,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1697007381827,"transaction":null}
#tbl2中插入的3条数据
5> {"before":null,"after":{"id":2,"name":"ls","score":200},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":0,"snapshot":"false","db":"db1","sequence":null,"table":"tbl2","server_id":0,"gtid":null,"file":"","pos":0,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1697007381829,"transaction":null}
3> {"before":null,"after":{"id":1,"name":"zs","score":100},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":0,"snapshot":"false","db":"db1","sequence":null,"table":"tbl2","server_id":0,"gtid":null,"file":"","pos":0,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1697007381827,"transaction":null}
4> {"before":null,"after":{"id":3,"name":"ww","score":300},"source":{"version":"1.9.7.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":0,"snapshot":"false","db":"db1","sequence":null,"table":"tbl2","server_id":0,"gtid":null,"file":"","pos":0,"row":0,"thread":null,"query":null},"op":"r","ts_ms":1697007381829,"transaction":null}基于SQL API使用
基于Flink SQL API 通过MySQL CDC Connector获取MySQL中的数据代码如下:
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//设置checkpoint
tableEnv.getConfig().getConfiguration().setLong("execution.checkpointing.interval", 5000L);
tableEnv.executeSql("" +
"CREATE TABLE mysql_binlog (" +
" id INT," +
" name STRING," +
" age INT," +
" PRIMARY KEY(id) NOT ENFORCED" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = 'node2'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = '123456'," +
" 'database-name' = 'db1'," +
" 'table-name' = 'tbl1'" +
")");
tableEnv.executeSql("select * from mysql_binlog").print();在Flink SQL API中通过MySQL CDC Connector只能监控一个MySQL数据库和一个表,也可以使用正则方式匹配多个库和多个表,如下示例:
CREATE TABLE products (
db_name STRING METADATA FROM 'database_name' VIRTUAL,
table_name STRING METADATA FROM 'table_name' VIRTUAL,
operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL,
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = '(^(test).*)',
'table-name' = '(t[5-8]|tt)'
);以上示例中进行库表匹配时,会使用正则表达式 database-name\\.table-name 来与MySQL表的全限定名做匹配,"(^(test).*)"表示匹配以test开头的库,"(t5-8|tt)"表示匹配t5、t6、t7、t8、tt表。
在编写以上SQL API代码需要注意以下几点:
-
需要指定Connector为mysql-cdc。
-
需要设置checkpoint。
以上代码执行后之前有tbl1表对应的binlog数据,所以会进行全量数据同步,然后继续增量同步:
+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 2 | lisi | 20 |
| +I | 1 | zs | 18 |继续向表tbl1中做增删改查操作:
#向表tbl1中新插入数据
mysql> insert into tbl1 values (4,'ml',21),(5,'tq',22),(6,'gb',23);
#修改表tbl1中id为4的数据
mysql> update tbl1 set name = 'maliu',age='30' where id = 4;
#删除表tbl1中id为5的数据
mysql> delete from tbl1 where id =5;结果输出如下:
+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 2 | lisi | 20 |
| +I | 1 | zs | 18 |
| +I | 4 | ml | 21 |
| +I | 5 | tq | 22 |
| +I | 6 | gb | 23 |
| -U | 4 | ml | 21 |
| +U | 4 | maliu | 30 |
| -D | 5 | tq| 22|全量+增量快照读取
MySQL CDC Connector就是一个Flink Source连接器,它将首先读取表快照(全量数据同步)数据,然后继续读取binglog(增量数据同步)数据。在1.x版本存在以下痛点问题:
-
全量 + 增量读取的过程需要保证所有数据的一致性,因此需要通过加锁保证,但是加锁在数据库层面上是一个十分高危的操作。底层 Debezium 在保证数据一致性时,需要对读取的库或表加锁,全局锁可能导致数据库锁住,表级锁会锁住表的读,DBA 一般不给锁权限。
-
不支持水平扩展,因为 Flink CDC 底层是基于 Debezium,起架构是单节点,所以Flink CDC 只支持单并发。在全量阶段读取阶段,如果表非常大 (亿级别),读取时间在小时甚至天级别,用户不能通过增加资源去提升作业速度。
-
全量读取阶段不支持 checkpoint:CDC 读取分为两个阶段,全量读取和增量读取,1.x版本全量读取阶段是不支持 checkpoint 的,因此会存在一个问题:当我们同步全量数据时,假设需要 5 个小时,当我们同步了 4 小时的时候作业失败,这时候就需要重新开始,再读取 5 个小时。
从MySQL CDC Connector 2.0版本起解决了以上问题,在读取快照数据时不需要数据库锁权限、支持并发数据读取、支持全量读取阶段的checkpoint。
MySQL CDC Connector 2.0版本全量和增量读取数据的工作原理如下:当MySQL CDC Connector Source启动时,并行读取表的全量快照,然后以单并行度的方式读取表的binlog进行增量同步数据。
在全量同步数据阶段,根据表的主键和表行的大小将快照划分成多个分片(chunk), 默认情况下,MySQL CDC source 会识别表的主键列,并使用主键中的第一列作为用作分片列,多个chunk由并行的任务进行并行任务读取处理,这里我们不需要了解chunk底层详细实现细节,只需要知道通过这种方式实现多并行快照读取即可。读取快照期间Flink支持chunk级别的checkpoint,所以数据同步过程中如果发生故障,可以基于checkpoint进行状态恢复并继续从最后完成的chunk中同步数据。
当所有chunk读取完成后,表示所有快照同步完成,此刻Source将使用单个任务读取binlog增量数据。为了保证快照记录和 binlog 记录的全局数据顺序,MySQL CDC将开始读取数据直到快照块完成后并有一个完整的 checkpoint,以确保所有快照数据已被下游消费,在binlog增量同步阶段 Source 可以支持行级别的 checkpoint。
Flink 定期为 Source 执行 checkpoint,在故障转移的情况下,作业将重新启动并从最后一个成功的 checkpoint 状态恢复,并保证Exactly-once语义。
启动模式
使用MySQL CDC Connector时可以设置监测数据库和表的启动模式,在DataStream API中使用方式如下:
MySQLSource.builder()
.startupOptions(StartupOptions.earliest()) // 从最早位点启动
.startupOptions(StartupOptions.latest()) // 从最晚位点启动
.startupOptions(StartupOptions.specificOffset("mysql-bin.000003", 4L) // 从指定 binlog 文件名和位置启动
.startupOptions(StartupOptions.timestamp(1667232000000L) // 从时间戳启动
...
.build()在SQL API中使用方式如下:
CREATE TABLE mysql_source (...) WITH (
'connector' = 'mysql-cdc',
'scan.startup.mode' = 'earliest-offset', -- 从最早位点启动
'scan.startup.mode' = 'latest-offset', -- 从最晚位点启动
'scan.startup.mode' = 'specific-offset', -- 从特定位点启动
'scan.startup.specific-offset.file' = 'mysql-bin.000003', -- 在特定位点启动模式下指定 binlog 文件名
'scan.startup.specific-offset.pos' = '4', -- 在特定位点启动模式下指定 binlog 位置
'scan.startup.mode' = 'timestamp', -- 从特定位点启动
'scan.startup.timestamp-millis' = '1667232000000' -- 在时间戳启动模式下指定启动时间戳
...)启动模式可以有如下5种模式:
-
initial (默认):在第一次启动时对受监视的数据库表执行初始快照,并继续读取最新的 binlog。
-
earliest-offset:跳过快照阶段,从可读取的最早 binlog 位点开始读取。与initial相比这种方式会将数据库对应表所有操作都会读取出来,而initial只会读取到操作后的最终结果。
-
latest-offset:首次启动时,从不对受监视的数据库表执行快照, 连接器仅从 binlog 的结尾处开始读取,这意味着连接器只能读取在连接器启动之后的数据更改。
-
specific-offset:跳过快照阶段,从指定的 binlog 位点开始读取。位点可通过 binlog 文件名和位置指定,或者在 GTID 在集群上启用时通过 GTID 集合指定。
-
timestamp:跳过快照阶段,从指定的时间戳开始读取 binlog 事件。
无主键数据同步
MySQL CDC Connector从2.4.0版本开始支持无主键表数据同步,使用无主键表必须设置"scan.incremental.snapshot.chunk.key-column"参数,且只能选择非空类型的一个字段,以便数据全量同步时划分chunk支持多并行。
使用无主键表时,可以指定"scan.incremental.snapshot.chunk.key-column"参数为索引列加快查询速度。MySQL CDC Connector在无主键表数据同步时,如果指定的列不存在更新操作,此时可以保证Exactly-once语义;如果指定的列存在更新操作,此时只能保证At least once语义,但可以结合下游,通过指定下游主键,结合幂等性操作来保证数据的正确性。
无主键表数据同步与有主键表数据同步类似,需要指定"scan.incremental.snapshot.chunk.key-column"参数,在DataStream API 和 SQL API中参数设置方式不同,下面通过一个案例来分别演示。
首先在MySQL中创建db2.test表,并插入数据:
mysql> create database db2;
mysql> use db2;
mysql> create table db2.tbl(id int,name varchar(255),age int);MySQL无主键表数据同步DataStream API 代码中通过chunkKeyColumn方法来指定划分chunk的列:
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("node2") //设置MySQL hostname
.port(3306) //设置MySQL port
.databaseList("db2") //设置捕获的数据库
.tableList("db2.tbl") //设置捕获的数据表
.username("root") //设置登录MySQL用户名
.password("123456") //设置登录MySQL密码
.deserializer(new JsonDebeziumDeserializationSchema()) //设置序列化将SourceRecord 转换成 Json 字符串
//设置chunk key column
.chunkKeyColumn(new ObjectPath("db2","tbl"),"id")
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//开启checkpoint
env.enableCheckpointing(5000);
env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(),"MySQL Source")
.setParallelism(4)
.print();
env.execute();MySQL无主键表数据同步 SQL API代码中只需要在DDL语句中指定"scan.incremental.snapshot.chunk.key-column"参数即可:
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//设置checkpoint
tableEnv.getConfig().getConfiguration().setLong("execution.checkpointing.interval", 5000L);
tableEnv.executeSql("" +
"CREATE TABLE mysql_binlog (" +
" id INT," +
" name STRING," +
" age INT," +
" PRIMARY KEY(id) NOT ENFORCED" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = 'node2'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = '123456'," +
" 'database-name' = 'db2'," +
" 'table-name' = 'tbl'," +
" 'scan.incremental.snapshot.chunk.key-column' = 'id' " +
")");
tableEnv.executeSql("select * from mysql_binlog").print();以上代码编写完成后,向MySQL db2.tbl表中输入如下数据,可以看到DataStream和SQL 代码会输出数据同步结果。
mysql> insert into db2.tbl values (1,'zs',18),(2,'ls',19),(3,'ww',20);
mysql> update db2.tbl set name = 'lisi',age='200' where id = 2;
mysql> delete from db2.tbl where id =3;MySQL CDC Connector案例
Exactly-once案例
Flink CDC 大部分Connector在同步数据库数据时都支持Exactly-once语义保证,但需要在代码中设置checkpoint并在任务意外停止重启后基于checkpoint进行状态恢复,这样重启后的Flink CDC程序就能接着挂掉之前读取到的binlog位置继续同步binlog数据,做到exactly-once数据同步语义。
下面以MySQL CDC Connector为例来演示Flink CDC任务从checkpoint中恢复状态并继续同步数据,步骤如下。
1) MySQL中创建库和表
mysql> use db3;
mysql> create table db3.test(id int primary key,name varchar(255),age int);2) 编写MySQL CDC Connector代码并打包
这里使用DataStream API 编写代码,代码中进行checkpoint相关配置,代码如下:
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("node2") //设置MySQL hostname
.port(3306) //设置MySQL port
.databaseList("db3") //设置捕获的数据库
.tableList("db3.test") //设置捕获的数据表
.username("root") //设置登录MySQL用户名
.password("123456") //设置登录MySQL密码
.deserializer(new JsonDebeziumDeserializationSchema()) //设置序列化将SourceRecord 转换成 Json 字符串
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//开启checkpoint
env.enableCheckpointing(5000);
//设置checkpoint Storage存储为hdfs
env.getCheckpointConfig().setCheckpointStorage("hdfs://mycluster/flinkcdc-cks");
//设置checkpoint清理策略为RETAIN_ON_CANCELLATION,默认也是不清空
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(),"MySQL Source")
.setParallelism(4)
.print();
env.execute();代码编写完成后打jar包,并将jar包传入node5 节点中,后续基于Yarn进行Flink任务提交,这里将jar上传至node5 /root/flink-jar-test/目录中。
3) 基于Yarn提交Flink任务
启动HDFS和Yarn集群,通过如下命令基于Yarn提交Flink CDC 任务:
[root@node5 ~]# cd /software/flink-1.17.1/bin/
[root@node5 bin]# ./flink run-application -t yarn-application -c com.mashibing.flinkjava.code.chapter11.datastreamapi.ExactlyOnceTest /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar 任务提交运行后,可以在HDFS中看到checkpoint目录自动创建:
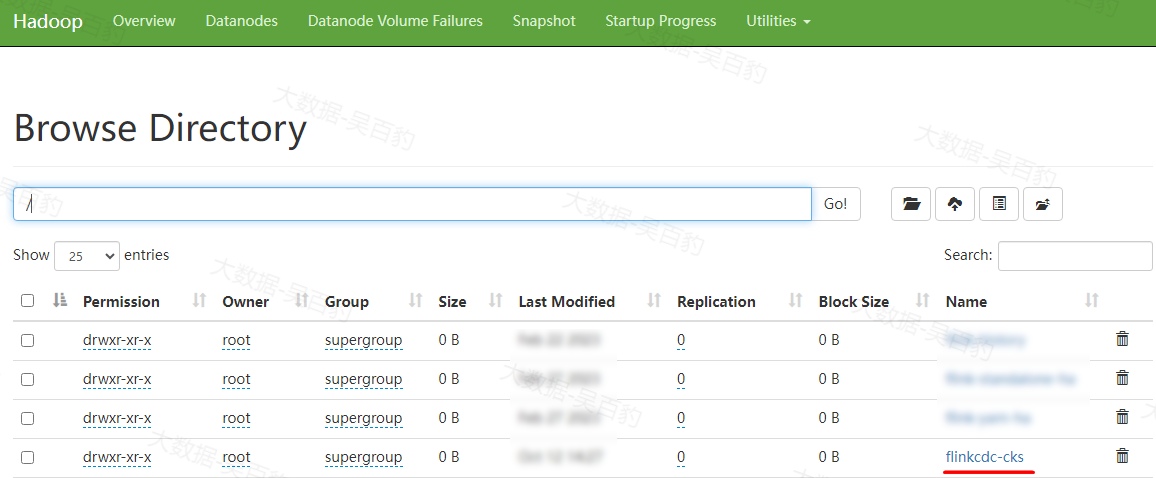
向MySQL db3.test表中进行如下操作:
mysql> insert into db3.test values (1,'zs',18),(2,'ls',19),(3,'ww',20);
mysql> update db3.test set name = 'lisi',age='200' where id = 2;
mysql> delete from db3.test where id = 3;可以看到对应Flink CDC 任务同步数据如下:

4) 基于checkpoint重启flink CDC 任务
在Flink WebUI中取消任务执行,并继续向MySQL db3.test表进行如下操作:
mysql> insert into db3.test values (10,'zs',18),(20,'ls',19),(30,'ww',20);
mysql> delete from db3.test where id = 2;基于Checkpoint保存的状态数据重启Flink任务,需要通过-s参数指定checkpoint路径。
[root@node5 bin]# ./flink run-application -t yarn-application -s hdfs://mycluster//flinkcdc-cks/08201dc3da5b6e457754198c66ee2ee0/chk-69 -c com.mashibing.flinkjava.code.chapter11.datastreamapi.ExactlyOnceTest /root/flink-jar-test/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar 任务重启后,可以看到Flink CDC 任务同步数据日志如下:

以上输出结果说明重启后的Flink CDC exactly-once同步了在任务挂掉期间操作MySQL对应表的binlog数据。在Flink SQL CDC中设置状态方式一样,这里不再进行演示。
MySQL CDC 同步数据到HBase
MySQL CDC Connector从MySQL中同步数据后可以写出到任意目标端。这里演示通过MySQL CDC Connector 同步MySQL数据到HBase分布式数据库中。
首先启动HBase集群,在HBase中创建对应的HBase目标表:
create 'tbl_cdc','cf1'然后编写MySQL CDC Connector代码,这里介绍DataStream API 代码及SQL API 代码两种方式。
DataStream API 代码
DataStream API中通过MySqlSource对象创建好CDC数据源后,对获取的json数据进行处理,根据MySQL binlog日志中的操作类型来决定向HBase对应表增删改操作。
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("node2") //设置MySQL hostname
.port(3306) //设置MySQL port
.databaseList("db1") //设置捕获的数据库
.tableList("db1.tbl1") //设置捕获的数据表
.username("root") //设置登录MySQL用户名
.password("123456") //设置登录MySQL密码
.deserializer(new JsonDebeziumDeserializationSchema()) //设置序列化将SourceRecord 转换成 Json 字符串
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//开启checkpoint
env.enableCheckpointing(5000);
//转换数据为 JsonObject 类型
SingleOutputStreamOperator<JSONObject> ds = env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
.map(new MapFunction<String, JSONObject>() {
@Override
public JSONObject map(String value) throws Exception {
return new JSONObject(value);
}
});
//将数据写出到HBase
ds.addSink(new RichSinkFunction<JSONObject>() {
org.apache.hadoop.hbase.client.Connection conn = null;
//在Sink 初始化时调用一次,这里创建 HBase连接
@Override
public void open(Configuration parameters) throws Exception {
org.apache.hadoop.conf.Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","node3,node4,node5");
conf.set("hbase.zookeeper.property.clientPort","2181");
//创建连接
conn = ConnectionFactory.createConnection(conf);
}
//Sink数据时,每条数据插入时调用一次
@Override
public void invoke(JSONObject currentOne, Context context) throws Exception {
String op = currentOne.getString("op");
//增加或者更新
if("c".equals(op)||"u".equals(op)){
JSONObject insertJsonObj = currentOne.getJSONObject("after");
//准备rowkey
String rowKey = insertJsonObj.getString("id");
//获取列
String id = rowKey;
String name = insertJsonObj.getString("name");
String age = insertJsonObj.getString("age");
//获取表对象
Table table = conn.getTable(TableName.valueOf("tbl_cdc"));
//创建Put对象
Put p = new Put(Bytes.toBytes(rowKey));
//添加列
p.addColumn(Bytes.toBytes("cf1"),Bytes.toBytes("id"),Bytes.toBytes(id));
p.addColumn(Bytes.toBytes("cf1"),Bytes.toBytes("name"),Bytes.toBytes(name));
p.addColumn(Bytes.toBytes("cf1"),Bytes.toBytes("age"),Bytes.toBytes(age));
//插入数据
table.put(p);
//关闭表对象
table.close();
}
//删除
if("d".equals(op)){
JSONObject insertJsonObj = currentOne.getJSONObject("before");
//准备rowkey
String rowKey = insertJsonObj.getString("id");
Table table = conn.getTable(TableName.valueOf("tbl_cdc"));
Delete del = new Delete(Bytes.toBytes(rowKey));
del.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("id"));
del.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("name"));
del.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("age"));
// 删除指定列族
// del.addFamily(Bytes.toBytes("cf1"));
// 删除rowkey数据
table.delete(del);
//关闭表对象
table.close();
}
}
//在Sink 关闭时调用一次,这里关闭HBase连接
@Override
public void close() throws Exception {
//关闭连接
conn.close();
}
});
env.execute();以上代码中监控MySQL db1.tbl1表中数据到HBase tbl_cdc中,监控MySQL binlog 中增删改对应binlog数据如下:
#增加的数据
{"before":null,"after":{"id":3,"name":"ww","age":20},...,"op":"c","ts_ms":1696941931728,"transaction":null}
#修改的数据
{"before":{"id":2,"name":"ls","age":19},"after":{"id":2,"name":"lisi","age":20},...,"op":"u","ts_ms":1696941937208,"transaction":null}
#删除的数据
{"before":{"id":3,"name":"ww","age":20},"after":null,...,"op":"d","ts_ms":1696941941399,"transaction":null}代码中可以根据返回的debezium-json格式数据中的op操作来判断对应增删改操作,进而向HBase中增删改数据。
代码编写完成后,删除MySQL中db1.tbl1表并重建:
use db1;
drop table tbl1;
create table tbl1(id int primary key,name varchar(255),age int);启动代码,等待连接上HBase,然后向MySQL db1.tbl1表中进行如下数据操作,可以在HBase中查询到对应增删改数据:
#向mysql中插入数据
mysql> insert into db1.tbl1 values (1,'zs',18),(2,'ls',19),(3,'ww',20);
#查询HBase表 tbl_cdc数据如下
hbase:805:0> scan 'tbl_cdc'
ROW COLUMN+CELL
1 column=cf1:age, timestamp=... ....249, value=18
1 column=cf1:id, timestamp=... ....249, value=1
1 column=cf1:name, timestamp=... ....249, value=zs
2 column=cf1:age, timestamp=... ....257, value=19
2 column=cf1:id, timestamp=... ....257, value=2
2 column=cf1:name, timestamp=... ....257, value=ls
3 column=cf1:age, timestamp=... ....262, value=20
3 column=cf1:id, timestamp=... ....262, value=3
3 column=cf1:name, timestamp=... ....262, value=ww
#修改表中数据
mysql> update db1.tbl1 set name = 'lisi',age='20' where id = 2;
#查询HBase表tbl_cdc数据如下
hbase:806:0> scan 'tbl_cdc'
ROW COLUMN+CELL
1 column=cf1:age, timestamp=... ....249, value=18
1 column=cf1:id, timestamp=... ....249, value=1
1 column=cf1:name, timestamp=... ....249, value=zs
2 column=cf1:age, timestamp=... ....520, value=20
2 column=cf1:id, timestamp=... ....520, value=2
2 column=cf1:name, timestamp=... ....520, value=lisi
3 column=cf1:age, timestamp=... ....262, value=20
3 column=cf1:id, timestamp=... ....262, value=3
3 column=cf1:name, timestamp=... ....262, value=ww
#删除表中数据
mysql> delete from tbl1 where id = 3;
#查询HBase表tbl_cdc数据如下
hbase:807:0> scan 'tbl_cdc'
ROW COLUMN+CELL
1 column=cf1:age, timestamp=... ....249, value=18
1 column=cf1:id, timestamp=... ....249, value=1
1 column=cf1:name, timestamp=... ....249, value=zs
2 column=cf1:age, timestamp=... ....520, value=20
2 column=cf1:id, timestamp=... ....520, value=2
2 column=cf1:name, timestamp=... ....520, value=lisi SQL API代码
SQL API中使用MySQL CDC Connector较为简单,通过DDL构建MySQL源表和HBase 目标表后,直接查询源表数据插入到目标表即可。由于SQL 中监控MySQL binlog日志数据本身就是变更日志流,可以监控增删改日志,直接将变更日志流写入HBase中就会自动在HBase表中进行数据的增删改操作。
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//设置checkpoint
tableEnv.getConfig().getConfiguration().setLong("execution.checkpointing.interval", 5000L);
tableEnv.executeSql("" +
"CREATE TABLE mysql_binlog (" +
" id INT," +
" name STRING," +
" age INT," +
" PRIMARY KEY(id) NOT ENFORCED" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = 'node2'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = '123456'," +
" 'database-name' = 'db1'," +
" 'table-name' = 'tbl1'" +
")");
//HBase Sink ,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table HBaseSinkTbl (" +
" rk string," +
" cf1 ROW<id string, name string,age string>," +
" PRIMARY KEY (rk) NOT ENFORCED " +
") with (" +
" 'connector' = 'hbase-2.2'," +
" 'table-name' = 'tbl_cdc'," +
" 'zookeeper.quorum' = 'node3:2181,node4:2181,node5:2181'" +
")"
);
//sql将MySQL数据写入到hbase表中
tableEnv.executeSql("" +
"insert into HBaseSinkTbl " +
"select CAST(id AS STRING) AS rk, ROW(CAST(id AS STRING),name,CAST(age AS STRING)) as cf1 from mysql_binlog"
);编写以上代码需要注意通过DDL创建HBase表需要指定主键列,该列自动被选择作为rowkey,此外列族列的名称要和HBase tbl_cdc表中的列族名称一致。为了能直观的在HBase中看到对应结果,这里所有写入HBase表tbl_cdc的列都设置为字符串类型。
在运行代码前,删除重建MySQL db1.tbl1表和HBase中tbl_cdc表,操作如下:
#删除重建MySQL db1.tbl1表
mysql> drop table tbl1;
mysql> create table tbl1(id int primary key,name varchar(255),age int);
#删除重建HBase tbl_cdc表
hbase:808:0> disable 'tbl_cdc'
hbase:809:0> drop 'tbl_cdc'
hbase:810:0> create 'tbl_cdc','cf1'运行代码后,向MySQL db1.tbl1表中进行如下数据操作,可以在HBase中查询到对应增删改数据:
#向mysql中插入数据
mysql> insert into db1.tbl1 values (1,'zs',18),(2,'ls',19),(3,'ww',20);
#查询HBase表 tbl_cdc数据如下
hbase:805:0> scan 'tbl_cdc'
ROW COLUMN+CELL
1 column=cf1:age, timestamp=... ....249, value=18
1 column=cf1:id, timestamp=... ....249, value=1
1 column=cf1:name, timestamp=... ....249, value=zs
2 column=cf1:age, timestamp=... ....257, value=19
2 column=cf1:id, timestamp=... ....257, value=2
2 column=cf1:name, timestamp=... ....257, value=ls
3 column=cf1:age, timestamp=... ....262, value=20
3 column=cf1:id, timestamp=... ....262, value=3
3 column=cf1:name, timestamp=... ....262, value=ww
#修改表中数据
mysql> update db1.tbl1 set name = 'lisi',age='20' where id = 2;
#查询HBase表tbl_cdc数据如下
hbase:806:0> scan 'tbl_cdc'
ROW COLUMN+CELL
1 column=cf1:age, timestamp=... ....249, value=18
1 column=cf1:id, timestamp=... ....249, value=1
1 column=cf1:name, timestamp=... ....249, value=zs
2 column=cf1:age, timestamp=... ....520, value=20
2 column=cf1:id, timestamp=... ....520, value=2
2 column=cf1:name, timestamp=... ....520, value=lisi
3 column=cf1:age, timestamp=... ....262, value=20
3 column=cf1:id, timestamp=... ....262, value=3
3 column=cf1:name, timestamp=... ....262, value=ww
#删除表中数据
mysql> delete from tbl1 where id = 3;
#查询HBase表tbl_cdc数据如下
hbase:807:0> scan 'tbl_cdc'
ROW COLUMN+CELL
1 column=cf1:age, timestamp=... ....249, value=18
1 column=cf1:id, timestamp=... ....249, value=1
1 column=cf1:name, timestamp=... ....249, value=zs
2 column=cf1:age, timestamp=... ....520, value=20
2 column=cf1:id, timestamp=... ....520, value=2
2 column=cf1:name, timestamp=... ....520, value=lisi 以上通过DataStream API 和 SQL API 完成了将MySQL 数据同步到HBase操作,两类代码中都需要设置checkpoint,这样可以在Flink CDC 任务意外中断重启后恢复binlog数据读取位置,保证Exactly-once语义。