使用 RGB-D 相机进行自主机器人导航的动态物体检测与跟踪【文献解读】
论文标题 :Onboard Dynamic-Object Detection and Tracking for Autonomous Robot Navigation With RGB-D Camera
作者 :Zhefan Xu, Xiaoyang Zhan, Yumeng Xiu, Christopher Suzuki, Kenji Shimada
所属机构 :Department of Mechanical Engineering, Carnegie Mellon University, USA
发表平台 :IEEE Robotics and Automation Letters (RA-L)
DOI :10.1109/LRA.2023.3334683
一、研究背景与关键科学问题
1.1 核心挑战
在拥挤的室内环境中部署小型自主移动机器人(如重量<1.5 kg的视觉无人机),需要解决动态障碍物的实时感知与跟踪问题。具体面临三大技术瓶颈:
- 机载计算资源的硬约束:小型机器人搭载的机载计算机功耗仅10--20瓦,无法运行GPU密集型的3D点云学习算法(如PV-RCNN、SECOND等自动驾驶方案);
- RGB-D传感器的物理局限:以Intel RealSense D435i为代表的深度相机,理想深度范围为0.3--3.0米,超出此范围点云稀疏甚至缺失,导致传统几何检测方法失效;
- 深度传感噪声的非线性干扰:在弱纹理或反光表面,深度估计值存在显著噪声,容易导致非学习型检测器产生高频的假阳性/假阴性结果,严重干扰下游避障规划器的稳定性。
1.2 现有方法的局限性
现有基于RGB-D的检测与跟踪方法主要分为两类,均存在明显短板:
图像驱动方法(基于深度图/U-depth图,如6,13,14):
- 依赖U-depth图的直线分组和深度连续性搜索,计算高效但对噪声敏感;
- 在障碍物相互遮挡或纹理重复时,极易产生维度估计失真;
- 难以区分静态结构与动态实体,动态识别依赖启发式速度阈值。
点云驱动方法(基于聚类/特征匹配,如3,4,5):
- DBSCAN等聚类算法对点云密度要求高,远距离检测能力弱;
- 传统数据关联(如中心距离最近邻)在障碍物交叉靠近时(如人靠近墙壁)极易发生匹配错误(如图6所示);
- 大多数算法采用恒定速度模型,无法准确描述行人突然加减速的运动模式。
学习型方法的适用性局限:
- 尽管3D目标检测在自动驾驶领域成熟,但其依赖高线束LiDAR稠密点云和GPU加速推理,与小型机器人的轻量级需求严重不匹配。
1.3 本文解决的关键问题
如何在不依赖GPU加速、不增加计算负担的前提下,同时实现:
- 高检测精度:在传感器噪声干扰下提供稳定的3D包围盒;
- 鲁棒数据关联:避免障碍物ID切换与误匹配;
- 远距离感知增强:突破3米深度限制,将有效检测范围拓展至稀疏点云区域;
- 高效动态识别:准确区分静态结构与运动实体,为导航提供可靠避障指引。
二、研究方法与技术路线
2.1 整体系统架构
DODT系统采用模块化并行处理设计,输入为RGB-D图像,输出为动态障碍物的3D跟踪包围盒(含速度/加速度状态)。系统由三大核心流水线构成:
RGB-D图像输入
├── 检测模块(并行) ──► 集成融合 ──► 跟踪模块(特征关联+卡尔曼滤波) ──► 动态识别模块(两级判别) ──► 动态障碍物输出
│ ├── U-depth检测器 │ │ │
│ ├── DBSCAN检测器 │ │ │
│ └── YOLO-MAD (可选) │ │ │
└── 静态地图清理 ◄──────────────────────────────────────────────┘ │
▼
避障规划器输入整体框架:
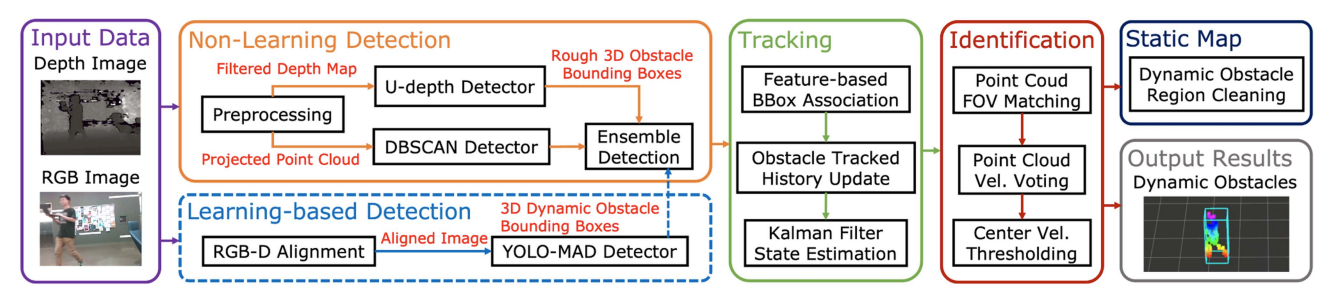
2.2 问题形式化
本文将动态障碍物检测与跟踪建模为时变状态估计与数据关联问题:
- 状态空间 :每个障碍物在全局地图坐标系下的状态定义为 X=x,y,x˙,y˙,x¨,y¨T\mathbf{X} = x, y, \\dot{x}, \\dot{y}, \\ddot{x}, \\ddot{y}^TX=x,y,x˙,y˙,x¨,y¨T(位置、速度、加速度);
- 观测模型 :通过三个异构检测器获取带噪声的3D包围盒观测值 ZtZ_tZt;
- 关联模型:利用点云统计特征构建相似度矩阵,确定当前帧观测与历史轨迹的对应关系;
- 估计器:采用恒定加速度卡尔曼滤波器,递推更新障碍物状态。
2.3 集成检测算法:多低精度检测器的共识机制
本文的核心算法创新之一,是通过**配对互验证(Pairwise Mutual Validation)**机制融合多个低精度检测器的输出。算法流程如下(对应原文Algorithm 1):
| 步骤 | 操作 | 数学/逻辑描述 |
|---|---|---|
| ① | 获取检测器A结果 Bd1B_{d1}Bd1、检测器B结果 Bd2B_{d2}Bd2 | 并行运行 |
| ② | 对每个 bd1∈Bd1b_{d1} \in B_{d1}bd1∈Bd1,在 Bd2B_{d2}Bd2 中寻找最大IoU匹配 bmatch1b_{match1}bmatch1 | IoU(bd1,bmatch1)>阈值IoU(b_{d1}, b_{match1}) > \text{阈值}IoU(bd1,bmatch1)>阈值 |
| ③ | 反向验证:在 Bd1B_{d1}Bd1 中寻找 bmatch1b_{match1}bmatch1 的最大IoU匹配 bmatch2b_{match2}bmatch2 | 双向一致性检查 |
| ④ | 判定互匹配条件:bmatch2==bd1b_{match2} == b_{d1}bmatch2==bd1 | 确保互为最优 |
| ⑤ | 融合:位置取平均,尺寸取最大值 | 保守性融合策略 |
设计原理:U-depth检测器的误差主要源于深度图像噪声,DBSCAN的误差主要源于点云边界不确定性,两者误差源异构。只有当两者对同一障碍物的空间位置产生"共识"时,才将该检测视为有效,从而大幅滤除非结构化噪声。
2.4 基于统计特征的鲁棒数据关联
核心痛点:传统中心距离关联方法(如图6所示)在行人靠近墙壁时,因当前行人中心(B)距离墙壁中心©比距离历史行人中心(A)更近,导致错误关联。
本文解决方案:构建多维统计特征向量,实现几何与物理属性的联合匹配。
特征向量定义 (式3):
feat(Oi)=pos(i),dim(i),len(i),std(i) \text{feat}(O_i) = \\text{pos}(i), \\text{dim}(i), \\text{len}(i), \\text{std}(i) feat(Oi)=pos(i),dim(i),len(i),std(i)
其中 pos(i)\text{pos}(i)pos(i) 为中心位置,dim(i)\text{dim}(i)dim(i) 为三维尺寸,len(i)\text{len}(i)len(i) 为点云数量,std(i)\text{std}(i)std(i) 为点云空间标准差。
相似度计算 (式4):
sim(Oi,Oj)=exp(−∣∣feat(Oi)−feat(Oj)∣∣22) \text{sim}(O_i, O_j) = \exp\left(-||\text{feat}(O_i) - \text{feat}(O_j)||_2^2\right) sim(Oi,Oj)=exp(−∣∣feat(Oi)−feat(Oj)∣∣22)
前向预测修正 :在进行特征比对前,利用卡尔曼滤波对上一时刻障碍物位置进行线性传播预测,使用预测位置替换特征向量中的历史位置,提高动态场景下的关联准确率。
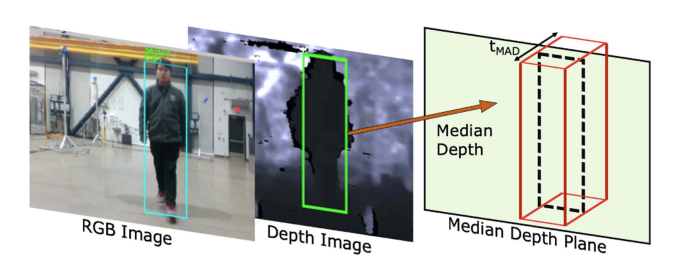
2.5 YOLO-MAD辅助模块:基于MAD的3D包围盒估计
为解决非学习方法远距离失效问题,本文引入一个可选的、轻量级学习模块作为辅助。
核心原理 :利用YOLOFastestDet在RGB图像上获取2D检测框,随后在对应的深度图像区域 RboxR_{box}Rbox 内,通过中位数绝对偏差(Median Absolute Deviation, MAD) 鲁棒估计深度范围:
- 计算中位深度 d~\tilde{d}d~ 和 MAD 值: MAD=median(∣di−d~∣)\text{MAD} = \text{median}(|d_i - \tilde{d}|)MAD=median(∣di−d~∣);
- 定义有效搜索区间: SMAD={di ∣ d~−n⋅MAD≤di≤d~+n⋅MAD}S_{MAD} = \{d_i \,|\, \tilde{d} - n\cdot\text{MAD} \le d_i \le \tilde{d} + n\cdot\text{MAD}\}SMAD={di∣d~−n⋅MAD≤di≤d~+n⋅MAD};
- 在 SMADS_{MAD}SMAD 内搜索最小深度 dmind_{min}dmin 和最大深度 dmaxd_{max}dmax,计算障碍物厚度;
- 结合中位深度平面的像素三角化,输出3D包围盒。
优势:MAD对离群点(如背景穿透噪声和前景飞点)具有极强的鲁棒性,使得该模块即使在点云稀疏区域(>3m)也能提供有效的检测结果(如图8所示),有效拓展了系统的感知范围。
2.6 两级动态障碍物识别机制
本文采用速度粗筛 + 点云细投票的两级判别策略,降低因状态估计噪声导致的误识别:
第一级(速度阈值):
- 若障碍物中心速度 Vcenter<TvelV_{center} < T_{vel}Vcenter<Tvel,直接判定为静态,跳过第二级。
第二级(点云动态投票):
- 对每个障碍物的有效点 pi,jp_{i,j}pi,j,在 tn−kt_{n-k}tn−k 时刻通过最近邻搜索寻找对应点,计算单点速度 VvoteV_{vote}Vvote;
- 无效点剔除条件:
- 速度方向与中心速度方向夹角 >90∘> 90^\circ>90∘(式10);
- 该点在历史时刻因视角变化而不可见(新出现点,见图7);
- 有效点中,若 Vvote>TvoteV_{vote} > T_{vote}Vvote>Tvote 则投动态票;
- 若动态票数占比 Nvote/Nvalid>TratioN_{vote} / N_{valid} > T_{ratio}Nvote/Nvalid>Tratio,判定为动态障碍物。
若启用YOLO-MAD模块:直接利用其2D目标检测的类别先验(如"person")跳过上述投票流程,优先判定为动态实体。
2.7 恒定加速度卡尔曼滤波器
相较于前期工作采用的恒定速度模型(CV)4,6,14,本文采用**恒定加速度模型(CA)**提升状态估计精度。
状态转移矩阵 (式7):
A=10Δt0Δt2/20010Δt0Δt2/20010Δt000010Δt000010000001 \mathbf{A} = \begin{bmatrix} 1 & 0 & \Delta t & 0 & \Delta t^2/2 & 0 \\ 0 & 1 & 0 & \Delta t & 0 & \Delta t^2/2 \\ 0 & 0 & 1 & 0 & \Delta t & 0 \\ 0 & 0 & 0 & 1 & 0 & \Delta t \\ 0 & 0 & 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 0 & 0 & 1 \end{bmatrix} A= 100000010000Δt010000Δt0100Δt2/20Δt0100Δt2/20Δt01
观测噪声计算 :为保证观测值平滑,速度与加速度观测值并非直接采用相邻帧差分,而是利用多个 δt\delta tδt 时间窗口的差分结果进行平滑处理后输入滤波器。
2.8 实验设计与评估指标
硬件平台:
- 两台定制四旋翼无人机,分别搭载 Intel NUC(CPU推理)和 NVIDIA Jetson Xavier NX(边缘计算);
- 真值系统:OptiTrack 运动捕捉系统(亚毫米级精度)。
对比算法:
- Method I 4:基于点云聚类 + 中心距离关联 + 恒定速度;
- Method II 14:基于U-depth + 椭圆拟合;
- Method III 6:基于U-depth + 速度阈值动态识别。
评估指标:
- 位置估计误差(RMSE);
- 速度估计误差(RMSE);
- 假阳性率(FPR):静态障碍物被误判为动态的比例。
消融实验设计:
- DODT w/o Ens:关闭集成检测,仅使用U-depth;
- DODT w/o FAT:关闭特征关联与CA模型,改用中心距离+CV模型。
三、主要创新点与学术贡献
3.1 创新点总结
| 序号 | 创新点 | 技术内涵 | 解决的瓶颈问题 |
|---|---|---|---|
| 1 | 异构检测器集成策略 | 基于IoU双向互验证的保守融合机制,联合U-depth与DBSCAN的异构优势 | 单一检测器对传感器噪声敏感,误检率高 |
| 2 | 统计特征数据关联 | 引入点云尺寸、密度、标准差等多维特征构建相似度矩阵,取代中心距离 | 障碍物靠近时ID频繁切换与匹配错误 |
| 3 | MAD驱动的轻量3D检测 | 将2D目标检测器扩展为3D检测器,采用中位数绝对偏差鲁棒估计深度范围 | RGB-D相机远距离(>3m)检测失效 |
| 4 | 两级动态投票机制 | 速度阈值初筛 + 点云逐点投票,配合无效点剔除策略 | 传感器噪声引起的动态误判 |
3.2 与现有方法的定量对比优势
| 方法 | 位置误差 (m) | 速度误差 (m/s) | 假阳性率 (%) | 计算平台要求 |
|---|---|---|---|---|
| Method I 4 | 0.21 | 0.31 | 8.2 | 中等 |
| Method II 14 | 0.19 | 0.28 | 9.5 | 低 |
| Method III 6 | 0.15 | 0.22 | 6.8 | 低 |
| DODT (本文) | 0.11 | 0.23 | 3.1 | 低(CPU实时) |
关键分析:
- 本文取得最低位置误差(0.11 m),验证了集成检测与特征关联对空间定位精度的显著提升;
- 速度误差(0.23 m/s)与最优方法持平,但假阳性率(3.1%)大幅降低,表明动态识别机制在保持召回率的同时有效抑制了噪声误报;
- 消融实验显示:集成检测使FPR下降约60%,特征关联使位置误差降低约25%。
3.3 运行效率与部署灵活性
| 硬件平台 | 模块状态 | 总推理耗时 | 等效帧率 |
|---|---|---|---|
| Intel NUC | 关闭YOLO-MAD | 4.76 ms | ~210 Hz |
| Intel NUC | 开启YOLO-MAD | 19.12 ms | ~50 Hz |
| Xavier NX | 关闭YOLO-MAD | 16.7 ms | ~60 Hz |
| Xavier NX | 开启YOLO-MAD | 40.08 ms | ~25 Hz |
关键结论 :YOLO-MAD占据75.7%(NUC)和59.5%(Xavier)的计算资源,但作为可选辅助模块,用户可根据算力预算灵活启用。在最轻量级配置下,系统可达210Hz的超高速检测帧率,远超传统方法。
3.4 涌现行为与物理实验验证
手持实验:
- 在多行人圆周运动场景中,系统成功维持多目标跟踪,历史轨迹平滑连续(绿色曲线);
- 在长距离跟随实验中,系统展示了利用YOLO-MAD在稀疏点云区域(>3m)稳定检测的能力(图8紫色包围盒)。
自主导航实验:
- 机器人在15米路径中遭遇随机行走的行人;
- 系统实时输出动态障碍物状态,轨迹规划器28,29据此进行B样条轨迹重规划,实现高效避障;
- 实验表明动态障碍物区域被成功从静态占据网格地图中"擦除",确保了静态地图的时效性。
3.5 技术贡献的学术意义
- 重新定义轻量化感知的边界 :本研究证明,在不依赖GPU和LiDAR的前提下,通过精巧的多模态异构传感器融合策略(深度图+点云+RGB语义),小型机器人同样可以实现高精度动态障碍物感知;
- 数据关联范式的革新 :首次在机载RGB-D系统中引入统计特征关联,将关联依据从单一的几何距离扩展为物理属性分布,为资源受限平台下的多目标跟踪提供了新思路;
- 学习型方法的辅助定位:将学习型检测器(YOLO)从"主力"降级为"可选用增援",这种设计理念为计算资源动态分配提供了工程范本。
四、局限性与未来方向
4.1 当前局限
- 固有的视野与遮挡问题:RGB-D相机视角有限(通常H×V: 87°×58°),且易受遮挡,当障碍物离开视野或被完全遮挡时,系统必然丢失跟踪(本文实验中也观察到该现象);
- 2.5D感知的本质限制:系统依赖2.5D高程/深度信息,无法感知悬空障碍物(如伸出的手臂、电线)或凹陷地形,可能导致避障失败;
- 动态环境中的静态地图维护:系统假设环境背景为静态,当背景发生永久性变化(如搬运家具),静态地图无法自动更新,需依赖SLAM回环检测;
- 对极端光照的鲁棒性:RGB-D相机在强光或全暗环境下性能急剧下降,本文未做针对性处理。
4.2 未来研究方向
- 多RGB-D相机融合感知:通过多视角相机系统扩大感知视野,利用重叠区域信息缓解遮挡导致的跟踪丢失;
- 基于Transformer的端到端跟踪:借鉴AME-2的注意力机制思路,探索使用自注意力进行更鲁棒的全局数据关联;
- 动态环境建图一体化:将本系统的动态障碍物输出与语义SLAM(如DS-SLAM21)结合,实现动静分离的全场景地图构建;
- 事件相机补充:引入事件相机应对高动态光照变化和高速运动场景,弥补RGB-D相机的曝光延迟缺陷。
五、结论
本文提出的DODT系统,通过异构检测器集成策略 显著提升了噪声环境下的检测鲁棒性,通过统计特征关联与恒定加速度卡尔曼滤波 实现了低算力平台上的高精度多目标跟踪,并通过可选的YOLO-MAD辅助模块 扩展了感知距离。在Intel NUC和Jetson Xavier NX上的实验表明,该系统实现了0.11 m的最低位置误差和3.1%的最低假阳性率,且在最轻量级配置下帧率可达210 Hz。物理导航实验进一步验证了该系统能够使小型自主机器人(<1.5kg)在拥挤室内环境中实时调整轨迹,安全避让动态行人。该工作为资源严重受限的移动机器人平台提供了一套兼具理论严谨性与工程实用性的动态感知解决方案。