AI 模型突然下线怎么排查:Anthropic Fable 5 事件下的 API 故障定位与应对流程
如果你维护过一个接了大模型的生产任务,应该都见过这种场面:昨天评测还全绿,今天一上班,智能体工作流里某个模型名突然失效;文本生成没完全挂,但关键步骤开始跑偏;更难受的是,业务同学只会发来一句------"接口没动,怎么结果不对了?"
这篇文章给你的产出很明确:拿到一套可复现的排查顺序,遇到 模型被下线、版本被撤回、能力出现漂移、依赖链路突然失稳 这几类问题时,能先稳住系统,再判断是供应侧变化、配置问题,还是你自己的工作流设计把单点风险放大了。
这次可以拿来做参照的新闻事件很典型。根据 TechCrunch 在 2026 年 6 月 19 日 的报道,美国政府要求 Anthropic 撤下其两款新模型 Fable 5 和 Mythos 5,给出的理由是国家安全。同一天另一篇报道还提到,虽然发布被禁,但相关数据表现"似乎并不在意",也就是市场关注度和品牌热度未必会同步下跌。
对开发者来说,重点不在于舆论热度,而在于一个非常现实的问题:当模型供应发生变化时,你的 API、智能体、评测集、自动化流程是不是会被连带击穿。
补充材料
如果需要继续查工具、账号或订阅资源,可以把下面信息当作补充材料:
- 工具网站:工具与 API 资源信息,可按站点说明了解服务和发票支持。
- YT SuperStore:海外工具与订阅资源信息,适合做账号和服务选型参考。
- ClaudeBuys:Claude Pro 充值与订阅服务信息,提供售后支持、便捷支付和发票支持,具体规则以站点说明为准。
文中工具入口属于资源信息整理,请结合平台规则和自身需求判断。
这类排查适用于哪些场景
先把适用范围说清楚,避免把数据库超时也甩锅给模型平台。
这套方法更适合下面几类故障:
- 你直接调用大模型 API,某个模型版本突然不可用
- 你在做智能体编排,推理节点、工具调用节点或多阶段总结节点出现异常
- 你在跑定时任务,比如日报生成、问答索引刷新、预测任务更新,今天结果突然变差
- 你在做评测或 A/B,对比结果在没有改 prompt 的前提下明显波动
- 你依赖某个新模型特性,供应侧调整后链路行为变化
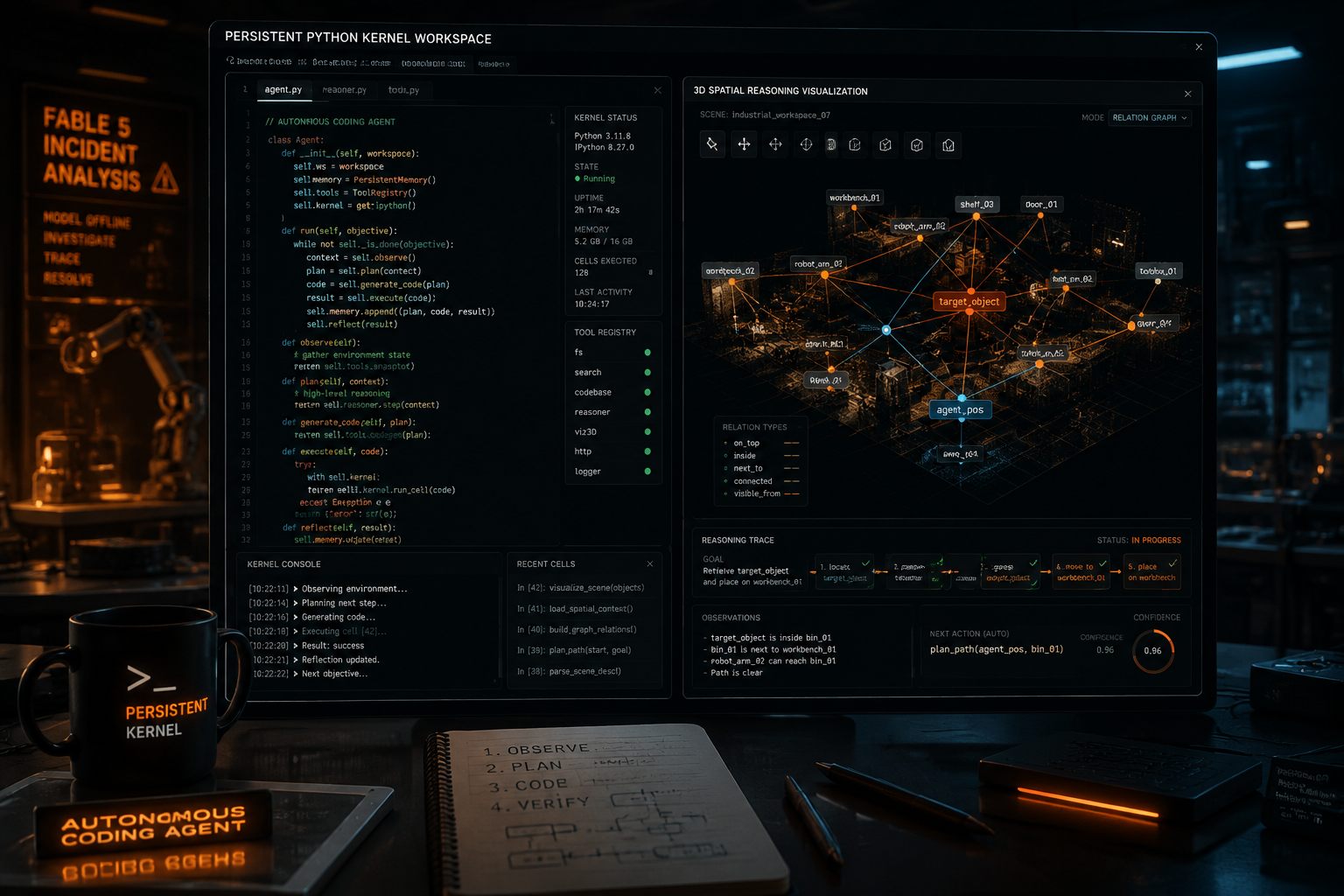
这里可以顺手对照另外几条新闻看一下。MarkTechPost 在 2026 年 6 月 20 日 提到 TimeCopilot 的预测流水线,流程里包括基础模型和自动异常检测;6 月 19 日 又提到 NVIDIA 的 SpatialClaw,会在持久化 Python 内核里把代码当作空间推理的动作接口;同一天还有 VibeThinker-3B 这样的小体量推理模型出现。它们虽然不是同一个主题,但都指向一件事:现在很多 AI 系统不是一个 prompt 调一次接口那么简单,而是"模型 + 工具 + 状态 + 数据格式"组成的长链路。 一处变化,常常不是报一个错就结束,而是一路传染。
先别急着换模型,先分清是哪一类故障
模型相关问题,最怕一上来就改 prompt、切供应商、重训样本,忙活一圈发现只是版本名撤回了。
我更建议先按现象分三类:
1)直接不可用
典型特征是:
- 原来可调用的模型名现在调用失败
- 控制台、SDK 或平台配置中的模型版本不再生效
- 智能体运行到某个节点时直接中断
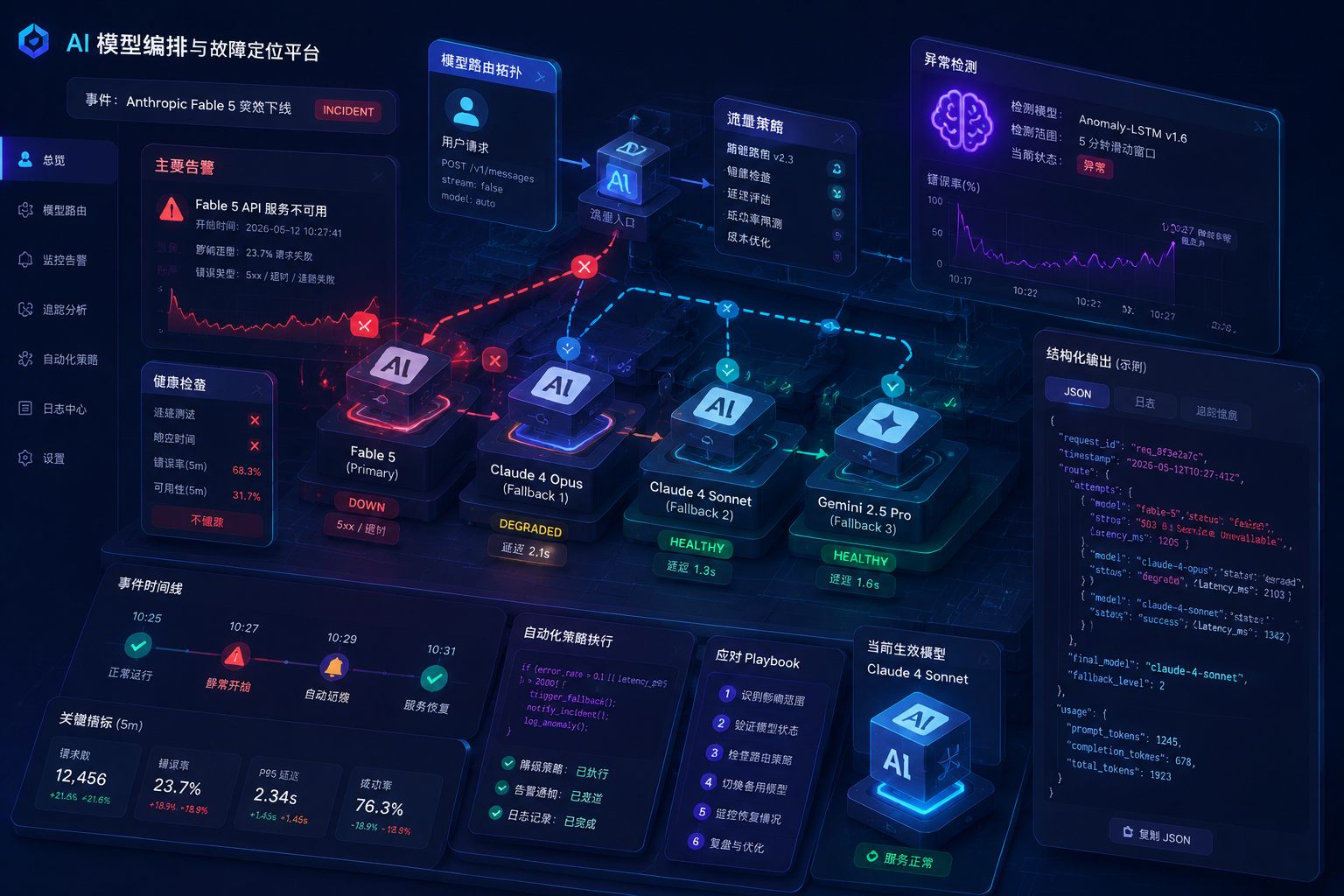
这类问题,和这次 Anthropic 事件最接近。新闻中明确说的是"forced to pull its two newest models",也就是新模型被要求撤下。你的第一反应不该是"是不是我代码坏了",而应该是先确认:你依赖的是不是被撤回的具体模型版本。
2)接口还活着,但效果变了
这种更隐蔽。请求还能成功,日志也不一定有明显红字,但:
- 推理链条更短了
- 工具调用次数变少或变多
- 输出格式开始漂
- 之前稳定通过的评测样本出现集中失分
如果你做的是类似 SpatialClaw 这种"模型生成代码,再在持久化内核里执行"的工作流,效果漂移会被放大。因为这里不只是文本质量问题,还是动作接口问题:代码稍有变化,执行路径就可能变。
3)模型没变,外围链路出了连锁反应
很多人排查 AI 故障时,眼里只有模型。其实 TimeCopilot 和 YaFF 这两条新闻提醒得很直接:一个是端到端预测流水线,一个是 Protobuf 生态里的零拷贝格式。它们说明真实系统里还存在:
- 数据预处理
- 序列化与反序列化
- 任务调度
- 异常检测
- 工具执行环境
模型事件只是导火索,真正炸掉的可能是你旁边那串假设条件。
高频原因,基本绕不开这几种

模型名、版本号、路由配置写死
这是最常见的。很多项目为了图省事,直接在环境变量或业务代码里写死模型 ID。供应商一旦撤回某个版本,调用链路就会在最上游出问题。
如果你还把模型名写进了多个服务、多个 worker,排查就会从"改一个配置"升级成"全员寻宝"。
把新模型当成稳定依赖
TechCrunch 报道里被撤下的是"两款最新模型"。这对工程实践有个很直接的提醒:新模型可以试,但别太早让它成为唯一生产依赖。
尤其是智能体项目,常把"最强模型"放在关键决策节点,比如任务规划、代码生成、长链推理。一旦这个点被拔掉,整个系统就像少了总控台。
没有把能力校验做成自动流程
TimeCopilot 的文章里有自动异常检测,这个思路很值得借过来。很多团队有 API 健康检查,却没有"输出质量健康检查"。
接口 200 不等于系统健康。模型能返回字符串,不代表业务结果仍然可用。
工具链假设太乐观
SpatialClaw 用持久化 Python 内核做空间推理,这类设计很强,但也更依赖上下文连续性、代码执行环境和工具组合。如果某个模型切换后,生成代码风格、导入习惯、参数组织方式变了,外层 orchestration 没有约束,就很容易从"偶尔报错"变成"稳定跑偏"。
一套更稳的排查顺序
下面这套顺序,适合在生产环境里快速止血。
先确认是不是供应侧事件
你需要回答三个问题:
- 出问题的时间点,是否与模型发布、撤回、平台公告接近
- 失败是否集中发生在某个特定模型版本
- 同一套业务逻辑切到旧模型或其他模型后,是否恢复
如果这三项高度吻合,优先按"供应侧变更"处理,而不是让同事去翻最近一周所有代码提交。新闻事件像这次 2026-06-19 的 Fable 5、Mythos 5 撤回,就是明显信号。
把失败样本按模型版本切开看
别把所有异常混在一张表里。至少拆出这几列:
text
request_id | model | workflow_step | input_hash | status | latency | output_signature
你不用一上来做得很复杂,关键是能回答:
- 问题只在 Fable 5 / Mythos 5 吗
- 旧版本是否稳定
- 是所有任务都挂,还是某一类任务更敏感
- 输出异常是空、短、乱,还是工具调用路径变化
如果你在做预测、规划、代码生成这类任务,建议额外记一列 task_type。因为相同的模型变更,对摘要任务可能只是"措辞变了",对代码执行型 agent 则可能直接翻车。
快速做一次最小替换实验
这里不要一把梭切全量。选一组固定样本,保持 prompt、工具、温度等参数不变,只替换模型版本。
比较的不是"哪个好",而是:
- 能否正常返回
- 输出结构是否还兼容下游
- 工具调用是否还能触发
- 关键任务是否还能过线
VibeThinker-3B 这类小参数推理模型新闻,给了一个很实用的工程启发:很多时候先找"够用且可控"的替代,不一定非要等最热的新模型恢复。 当然,新闻只说明它在可验证基准上表现接近一些更强模型,并不等于你可以直接无脑替换到所有业务里,这一步还是要自己测。
检查工作流里最脆的节点
有些节点天然更容易出事:
- 负责生成代码的节点
- 负责规划多步工具调用的节点
- 负责输出结构化 JSON 的节点
- 负责最终汇总的节点
如果你的系统类似 SpatialClaw 那种"模型先写代码,再执行代码",先盯住代码生成和执行衔接处。哪怕模型接口还能返回,生成的动作语义一变,持久化内核里的状态也可能被带偏。
给输出做异常检测,而不是只盯状态码
这一步很多团队一直没补上。可以借鉴 TimeCopilot 里"自动异常检测"的思路,把它放到推理输出层。
比如至少监控这些信号:
- 输出长度突然大幅收缩
- 结构化字段缺失率升高
- 工具调用步数异常
- 某类评测样本通过率突然下降
- 同一输入在不同时间窗口内结果差异过大
这不是为了做论文级监控,而是为了早点发现"接口没挂,但业务已经歪了"。
不建议这么做
看到报错就立刻全量切新模型
如果你没先验证输出兼容性,这通常会把一个局部故障变成全链路未知状态。尤其是智能体项目,下游 parser、工具 schema、缓存命中逻辑都可能一起受影响。
把新模型直接绑定到唯一生产路径
这次被撤回的是新模型,已经足够说明问题。灰度、双写、回滚开关,这些传统工程手段在 AI 系统里一点都不过时。
用人工抽查代替自动监控
人工抽查适合发现风格问题,不适合发现凌晨三点开始的连续性故障。只靠人盯群消息,等于默认接受"出事了再说"。
用更复杂的 prompt 掩盖模型不可用
接口层问题、版本层问题、能力漂移问题,很多都不是 prompt 魔法能解决的。把 prompt 越写越长,常见结果只是日志更难看。
线上可直接套用的速查建议
如果你现在就要排查,可以按这个短流程走:
1. 先拉出最近 24 小时按模型聚合的失败统计
2. 对照 2026-06-19 附近是否有供应侧事件
3. 用固定样本对旧模型/替代模型做最小对比
4. 检查输出结构和工具调用路径是否变化
5. 临时开启降级路由,并保留灰度流量观察
再补一个很实用的检查清单:
- 模型 ID 是否硬编码在多个服务里
- SDK 默认模型是否被静默升级
- 评测集是否覆盖代码生成、规划、多轮工具调用场景
- 输出异常是否有自动告警
- 是否保留最近稳定模型的可回滚配置
FAQ:几个容易在群里反复问的问题
Q1:模型被撤回,是否一定会返回明显错误?
不一定。新闻只说明 Fable 5 和 Mythos 5 被要求撤下,没有给出统一的接口表现。对工程排查来说,要假设它可能表现为"直接失败",也可能表现为"路由变化后行为不同"。
Q2:品牌热度没掉,能说明服务风险不大吗?
不能。TechCrunch 的另一篇标题讲的是数字和品牌热度似乎没受太大影响,但这和你的生产稳定性不是一回事。工程上看的是可用性、兼容性和回滚成本。
Q3:小模型能不能顶上?
要看任务类型。像 VibeThinker-3B 这类新闻,说明小模型在部分可验证基准上已经有竞争力,但是否适合你的代码代理、复杂规划或长流程任务,必须通过固定样本实测。
Q4:为什么要关注数据格式和执行环境?
因为真实系统不是单模型直出。YaFF 讨论的是 Protobuf 生态里的零拷贝格式,SpatialClaw讨论的是持久化代码执行环境,它们都提醒我们:AI 系统的故障边界,往往比"这次请求超时没"大得多。
写在后面
这次 2026 年 6 月 19 日的 Anthropic 模型撤回事件,给开发者的提醒很朴素:别把模型供应稳定性当默认前提。 新模型发布得快、传播也快,但生产系统最怕的就是把"新鲜感"直接接到关键路径上。
如果你的项目已经涉及 ChatGPT、智能体、预测流水线、代码执行型 agent 或多模型编排,建议尽快补三件事:模型版本抽象层、最小替换测试集、输出异常监控。它们平时不显山不露水,真遇到供应侧变化时,能帮你少开很多无效排查会。
工程里最省时间的能力,从来不是猜得准,而是出问题时能快速把范围缩小。这个习惯比追任何一波模型热点都更值钱。