本文基于对 Notion 公开前端产物的静态分析,所有指令名、变量名均为还原命名、行为等价,仅供学习与研究。文中区分了「逆向实抓」与「合理推断」,请放心食用。
在 Notion 里建一张表,加一个公式列,敲下:
text
prop("时薪") * prop("工时")回车,数字立刻出现。平平无奇------直到你打开 DevTools,在压缩后的前端代码里翻到一个 31KB 的模块,发现里面赫然躺着:一个词法分析器 、一个递归下降解析器 、一个把语法树编译成字节码 的编译器,以及一台逐条执行字节码的栈式虚拟机。
一个笔记软件,为了算一列公式,在你的浏览器里塞了一台虚拟机。
为什么?这篇文章就顺着这个问题,把这台 VM 逆向出来,再用不到 600 行 JavaScript 把它复刻一遍------重点是它最精彩的两个设计:用生成器实现「算到一半能挂起、取完数据再从原地继续」的求值 ,以及把 lambda 当作「字节码数据」在运行时重新喂回 VM。
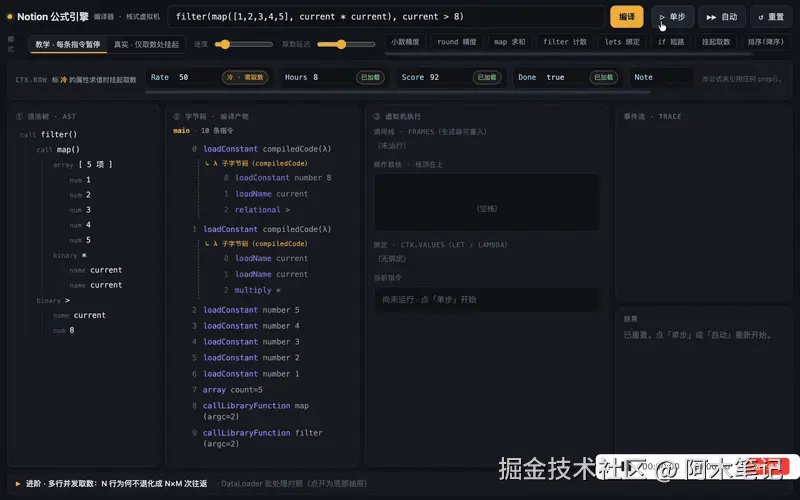
TL;DR
- 逆向对象是 Notion 前端两个 rspack 模块:
448187(VM + 编译器)与947152 / 942007(函数目录,命名空间formula2)。 - 它是一台纯 JavaScript 解释器 ,全程没有
WebAssembly。formula2暴露了 31 个算子 + 65 个函数 (map/filter/sort等列表高阶函数、let/lets绑定、正则字符串函数都在)。 - 栈上的每个值是带类型标签的「盒子」
{type, value}。 - 编译器把操作数逆序压栈 ;VM 主循环「
ip先自增、后分派」;if被编译成跳转字节码。 - 王牌是生成器 :求值到
prop("X")这种需要远端数据的地方就yield挂起,调度器取回数据后.next(data)让它从同一条指令继续。 - lambda 不是闭包,而是编译好的子字节码当成常量压栈 ;库函数执行时
yield*把它重新喂回 VM------所以 VM 必须是可重入的。 - 我把整套东西做成了一个可单步、全状态可视化 的教学网页(单文件 HTML,零依赖),源码在 GitHub。
一、为什么不直接 eval?
最朴素的实现是:把用户公式拼成 JS,丢给 eval 或 new Function。Notion 没这么做,原因有三个,每一个都直接逼出了「编译器 + 虚拟机」这套架构。
第一,同一个公式要在一整列上反复跑。 一个公式列有几千行,每行都要算一遍;筛选、排序、滚动都会触发重算。把公式编译一次得到字节码,然后这列的每一行复用同一份字节码------这就是 compile-once-run-many。每次都重新解析语法树是巨大的浪费。
第二,求值过程必须能「暂停」。 公式里可以写 prop("关联表").map(...),沿着 relation/rollup 去引用别的行、别的表。这些数据常常不在本地 ,要异步去取。如果用同步的 eval,碰到缺数据就只能阻塞或报错。Notion 要的是「同步的写法、异步的执行」:算到需要远端数据的那一刻,把整个求值过程冻结起来,去把数据取回来,再从冻结点继续。
第三,公式语言有 lambda。 map、filter、sort 的参数是一段「对每个元素都要重新跑一遍」的表达式。它需要被表示成一个可反复调用的独立执行单元。
这三条约束------高频重算、异步可挂起、列表 lambda------单靠递归解释一棵语法树是很难优雅满足的。于是就有了一台字节码虚拟机。这跟 SQLite 把 SQL 编译成字节码喂给它的虚拟机 VDBE 是同一个思路(顺带一提,Notion 原生端的本地存储正是 SQLite)。
二、流水线总览
一行公式从字符串到结果,要走五道工序:
词法和语法分析是教科书内容,本文不展开(我的复刻里是一个递归下降 + 优先级爬升的解析器)。真正有意思的是后三段:编译器、虚拟机、以及它们之间那条「挂起取数」的虚线。我们一段段拆。
三、值是带类型标签的「盒子」
第一个设计决定:栈上跑的不是裸 JS 值,而是统一的「盒子」------{type, value}。逆向出的类型有:
number、text(value 是富文本数组)、checkbox、date、person、block(行指针)、array、undefined,以及一个特别的 compiledCode(一段子字节码,后面讲 lambda 时会用到)。
为什么不用裸值?因为 1 + "x" 在公式里要做文本拼接、date < date 要走时区感知比较、undefined 在数值上下文里要当 0------运算的语义由类型决定。把类型随值一起带在盒子里,分派起来才干净。
配套的是一个看似普通、实则关键的栈类:
js
class Stack {
constructor() { this.u = []; }
push(v) { this.u.push(v); }
popValueOrCode() { return this.u.pop(); } // 允许弹出 compiledCode
popValue() { // 禁止弹出 compiledCode
const v = this.u.pop();
if (v && v.type === "compiledCode")
throw new Error("unexpected compiled code");
return v;
}
}注意它有两种弹出 。普通运算用 popValue:如果你试图把一段「代码」当成「值」去做加法,它直接抛错。而库函数取它的惰性参数(lambda)时用 popValueOrCode,允许拿到那段代码。这个区分,是整个 lambda 机制的支柱------记住它,第六节会回来。
四、第一个反直觉点:操作数逆序压栈
栈式 VM 的常识是:算 a - b,先把 a、b 压栈,再执行减法。但逆向出来的编译器,操作数是反着压的。
js
function compileBin(node) {
const { op } = node;
// ......除法、取模、and/or 走库函数,此处省略......
const t = (op === "+" || op === "-") ? "add"
: op === "*" ? "multiply"
: op === "^" ? "exponentiation"
: (op === "==" || op === "!=") ? "equality"
: "relational";
// 逆序压栈:先发射 rhs,再发射 lhs
return I(node.rhs).concat(I(node.lhs)).concat([{ type: t, op, node }]);
}I(rhs) 在前、I(lhs) 在后。以 1 - 2 为例,编译产物是:
text
0 loadConstant number 2 ← 先压右操作数
1 loadConstant number 1 ← 再压左操作数(它在栈顶)
2 add (op: "-")为什么要这样?因为栈是后进先出 。我们希望执行减法时,先弹出的是左操作数 。逆序压栈之后,左操作数 1 正好在栈顶,于是:
js
case "add": {
const a = frame.stack.popValue(); // 弹出 = 1(左操作数)
const b = frame.stack.popValue(); // 再弹 = 2(右操作数)
frame.stack.push(addOp(node, a, b)); // 算 a - b = -1,顺序正确
break;
}这个规则在二元运算、函数参数、数组字面量里是统一应用的(参数也逆序发射,执行时 pop 重建书写顺序)。它不影响结果,但你不知道这条约定的话,照着写出来的减法、除法会全部算反------这是逆向时一个很容易栽的坑。
五、VM 主循环:先自增,后分派
虚拟机的心脏是一个 while 循环。逆向出的版本有个细节:取出当前指令后,先把指令指针 ip 自增,再去分派执行。
js
function* F(instrs, ctx) {
const frame = { instrs, ip: 0, stack: new Stack(), ctx };
// ...把 frame 压入运行时 frames 栈,用于可视化...
while (frame.ip < instrs.length) {
const T = instrs[frame.ip];
frame.ip++; // ★ 先自增,后分派
switch (T.type) {
case "loadConstant": frame.stack.push(T.value); break;
case "loadName": frame.stack.push(lookupBinding(ctx, T.name)); break;
case "loadToken": frame.stack.push(yield* resolveToken(T, ctx)); break; // 可挂起
case "add": { const a = frame.stack.popValue(), b = frame.stack.popValue();
frame.stack.push(addOp(T.node, a, b)); break; }
case "multiply": { const a = frame.stack.popValue(), b = frame.stack.popValue();
frame.stack.push(mulOp(a, b)); break; }
case "relational": { const a = frame.stack.popValue(), b = frame.stack.popValue();
frame.stack.push(yield* relOp(T.node, a, b)); break; } // 可挂起
case "array": { const vs = []; for (let i = 0; i < T.count; i++) vs.push(frame.stack.popValue());
frame.stack.push({ type: "array", values: vs }); break; }
case "relativeJump": frame.ip += T.offset; break;
case "jumpIfTruthy": { const c = frame.stack.popValue(); if (truthy(c)) frame.ip += T.offset; break; }
case "callLibraryFunction": { const args = [];
for (let i = 0; i < T.argCount; i++) args.push(frame.stack.popValueOrCode());
frame.stack.push(yield* T.fn.eval(args, ctx)); break; } // 可挂起 + 可重入
case "runLets": frame.stack.push(yield* runLets(T, ctx)); break;
}
}
return frame.stack.popValue();
}(上面为聚焦主线略去了少量错误守卫,完整版见仓库。)
「先自增后分派」的意义,在跳转指令上才显出来:jumpIfTruthy 的偏移量 offset 是相对已经自增过的 ip 计算的。复刻时如果偏移基准算错一格,整段跳转会错位。这就引出下一节。
注意 switch 里有好几个 yield*------它们是这台 VM 能「挂起」和「重入」的入口,是后两节的主角。
六、if 被编译成跳转------顺便揭穿一个误解
公式里的 if(条件, 真值, 假值),不是一个普通函数 。如果它是函数,那么调用前两个分支都得先求值(参数总是先于调用被算出来),if 就失去短路能力了。逆向出的做法是:编译器把 if 直接展开成跳转字节码。
js
function compileIf(node) {
const cond = emit(node.args[0]);
const thenBC = emit(node.args[1]);
const elseBC = emit(node.args[2]);
return [
...cond,
{ type: "jumpIfTruthy", offset: elseBC.length + 1 }, // 条件为真 → 跳过 else 段
...elseBC,
{ type: "relativeJump", offset: thenBC.length }, // else 执行完 → 跳过 then 段
...thenBC,
];
}布局是「条件 → 跳转 → else 段 → 无条件跳转 → then 段」。条件为真时跳过整个 else 段、落到 then 段;为假时顺序落入 else 段、执行完再无条件跳过 then 段。两个分支永远只走一个------这才是真正的短路。ifs(多路条件)则被递归地拆成嵌套的 if。
反过来,and / or 是急性求值的普通函数。 它们的参数在调用前就已经被全部算到栈上了,所以 and/or 不短路 。在公式引擎里,唯一的短路控制流来自 if/ifs 的跳转。这个区别,不看字节码是不会注意到的。
七、王牌:用生成器做一台「可挂起」的虚拟机
现在来到全篇最漂亮的设计。
回想第一节的动机二:求值碰到远端数据要能暂停。Notion 的实现是------VM 主体 F 是一个生成器函数 (function*)。当执行到 loadToken(也就是读 prop("X"))而本地没有这条记录时,它不阻塞、不报错,而是 yield 出一个「我需要这个记录」的请求:
js
function* resolveToken(T, ctx) {
if (T.token.kind === "property") {
const data = yield { t: "fetch", pointer: ctx.rowPointer, property: T.token.name };
if (data == null) throw new Error("MissingThisRow"); // 取不到 → 结构化错误
return data; // 取到 → 作为值盒子返回,压栈
}
}yield 之后,这个生成器就地冻结 ------它的指令指针 ip、操作数栈、整条调用栈,全被 JavaScript 运行时原样保存在生成器对象里。外层的调度器(驱动循环)接管:
js
async function drive(bytecode, ctx) {
const gen = F(bytecode, ctx);
let injected;
for (;;) {
const { value: ev, done } = injected === undefined ? gen.next() : gen.next(injected);
injected = undefined;
if (done) return ev; // 求值完成,ev 是结果盒子
if (ev.t === "fetch") {
const box = await getRecord(ev.pointer, ev.property); // 本地命中就立即返回,缺数据就走网络
injected = box; // 把数据通过 .next(box) 喂回挂起点
}
}
}关键在 gen.next(injected):传给 next 的值,会成为生成器内部那个 yield 表达式的返回值。也就是说,数据取回来后,VM 从那条 loadToken 的同一位置继续往下跑,仿佛中间什么都没发生。
一句话总结这个机制:生成器捕获的那个挂起态,本身就是一个可以冻结、可以解冻的调用栈。 当数据本来就在本地时,整个过程一次 yield 都不发生,纯同步,零开销;只有真要去远端取数时才挂起。这就是「同步的写法、异步的执行」。
我在复刻的教学工具里,把这个「冻结」做成了一个会盖在虚拟机面板上的覆盖层:求值撞到一个标记为「冷」的属性时,整台 VM 的
ip、栈、调用栈定格不动,取数返回后再「解冻」从原地继续。看一眼那个动画,比读十遍文字都直观。
八、lambda 的真相:不是闭包,是「字节码即数据」
map([1,2,3], current * current) 里的 current * current,是一段要对每个元素都重跑的代码。Notion 怎么表示它?
不是闭包。逆向出的答案更硬核:编译时把这段表达式单独编译成一串子字节码,包成一个 compiledCode 盒子,当成常量压栈。
js
function compileCall(node) {
const fn = LIB[node.name];
const args = node.args.slice();
let out = [];
for (let k = args.length - 1; k >= 0; k--) { // 参数同样逆序压栈
const an = args[k];
if (fn.lazy && fn.lazy.has(k)) { // 该形参是「惰性/代码」参数?
// 不直接发射这段表达式,而是把它编译成子字节码,作为常量压栈
out.push({ type: "loadConstant",
value: { type: "compiledCode", instructions: I(an) } });
} else {
out = out.concat(I(an)); // 普通参数照常发射
}
}
out.push({ type: "callLibraryFunction", name: node.name, argCount: args.length, fn });
return out;
}每个库函数自带一张「哪些参数是惰性的」表(比如 map 的第 2 个参数)。惰性参数不会被立即求值,而是变成一颗 compiledCode「代码弹珠」躺在栈上。
到了运行时,map 的实现用 popValueOrCode(还记得第三节那两种弹出吗?)把这颗代码弹珠取出来,然后对每个元素,yield* 把这段子字节码重新喂回 VM 主体 F 跑一遍 ,跑之前往上下文里注入两个绑定------当前元素 current 和下标 index:
js
function* runLambda(codeBox, el, idx, ctx) {
const childCtx = {
...ctx,
values: [{ kind: "Binding", id: "current", value: el },
{ kind: "Binding", id: "index", value: num(idx) },
...ctx.values],
};
return yield* F(codeBox.instructions, childCtx); // ★ VM 重新调用自己
}yield* F(...) 这一句,就是 VM 在执行库函数的过程中,又递归地驱动了一个新的 VM 帧 。这正是为什么主循环里那么多 yield*、为什么 VM 必须是可重入的生成器:lambda 的执行 = 子字节码 + 再次进入 VM。
光说不够,看一段我的复刻在跑 sum(map([1, 2], current * 10)) 时,逐指令打印的真实执行轨迹(精简了列):
text
0 ip=0 loadConstant compiledCode(λ) stack:[] frames:[main]
1 ip=1 loadConstant number 2 stack:[λ] frames:[main]
2 ip=2 loadConstant number 1 stack:[λ 2] frames:[main]
3 ip=3 array count=2 stack:[λ 2 1] frames:[main]
4 ip=4 callLibraryFunction map stack:[λ [1 2]] frames:[main]
5 ip=0 loadConstant number 10 stack:[] frames:[main › λ current=1 [#0]]
6 ip=1 loadName current stack:[10] frames:[main › λ current=1 [#0]]
7 ip=2 multiply stack:[10 1] frames:[main › λ current=1 [#0]]
8 ip=0 loadConstant number 10 stack:[] frames:[main › λ current=2 [#1]]
9 ip=1 loadName current stack:[10] frames:[main › λ current=2 [#1]]
10 ip=2 multiply stack:[10 2] frames:[main › λ current=2 [#1]]
11 ip=5 callLibraryFunction sum stack:[[10 20]] frames:[main]
RESULT 30看第 5 行那一刻:frames 从 [main] 长出了 [main > lambda current=1 [#0]]------VM 重入了自己,调用栈多了一层 lambda 帧,current 被绑成了第一个元素。第 7 行栈是 [10 1],正应了第四节的逆序压栈:先弹 1(即 current)、后弹 10,算 current * 10。两个元素各跑完一遍 lambda 帧后,回到 main,sum 把 [10, 20] 折叠成 30。
map/filter/find/some/every/sort 全都共用这一套底座。let/lets 也是类似套路:编译成一条 runLets 指令,逐个求值绑定、压进 ctx.values 头部,loadName 再反查。
九、算术里的小心思:整数走快路、小数才付精度税
被坑过 0.1 + 0.2 !== 0.3 的人都知道浮点的麻烦。表格软件对数值精度是较真的。逆向出的加法语义是这样权衡的:
js
function addOp(node, a, b) {
const op = node.op === "-" ? "-" : "+";
const aNum = a.type === "number" || a.type === "undefined";
const bNum = b.type === "number" || b.type === "undefined";
if (op === "+" && aNum && bNum) { // 两边都是数(undefined 当 0)
const x = a.type === "undefined" ? 0 : a.value;
const y = b.type === "undefined" ? 0 : b.value;
return num(isInt(x) && isInt(y) ? x + y // 整数 → 原生加法(快路径)
: decAdd(x, y)); // 含小数 → 任意精度加法(慢路径)
}
// 减法同构;任一边不是纯数字 → 转富文本后拼接成 text
return txt(boxToText(a) + boxToText(b));
}精髓在那个三元表达式:两个操作数都是整数,就走原生 + (比任意精度库快一个数量级,而整数运算的 JS 原生结果是精确的);只要含小数,才切到任意精度路径 ,保证 0.1 + 0.2 得到 0.3 而不是 0.30000000000000004。常见的整数运算不为不存在的精度问题买单,小数才付这份「精度税」。-、*、^ 都是同样的整数快路径 + 慢路径分流。
其余几个语义也值得记一笔:除法零除返回 undefined(不是 Infinity);round 的精度参数必须是整数且绝对值 ≤ 12(每个函数都自带参数类型校验和结构化错误);min/max 返回原始盒子以保留类型。
十、海量派生为什么不退化成 N*M 次往返?
诚实声明:这一节描述的是 VM 之上的调度层 ,属于合理推断 + 业界标准做法,不是从那两个模块逐字逆出的。前面九节都有实抓代码支撑,这节没有,请区别对待。
第七节解决了「一个单元格挂起取数」。但一张大表有成百上千个派生单元格,每个都可能挂起、都要请求关系记录。如果每个请求各自单独往返,那就是 N 行 x M 条关系 = N*M 次网络调用,必然卡死。
标准解法是在 VM 之上放一个调度层 ,把同一轮里所有挂起的请求收集、去重、合并成一次批量取数 (就是 DataLoader 那套)。多个生成器各自挂在自己的 yield 上,调度器把它们的数据需求并起来、去重、一次性取回,再唤醒全部挂起的生成器。
text
4 个派生格,各自挂起,需要的关系记录有重叠
R1:[a b c] R2:[b c d] R3:[c d e] R4:[a e]
│ │ │ │
└──── 收集 + 去重 → {a b c d e} ───────┘
│
一次批量取数(1 次往返)
│
└──── 唤醒全部挂起的生成器,各自恢复 ────┘
朴素:3+3+3+2 = 11 次往返 合并后:1 次往返注意:底层用的还是第七节那套完全相同的挂起/恢复协议,区别只在 VM 之上的调度层是否合并请求。再叠加依赖图标脏 + 拓扑重算(只重算受影响的单元格)、视口懒求值(只算屏幕上可见的行)、服务端聚合下推等手段,「断网只挂掉一个格子、而不是整张表」才成为可能。
十一、我把它做成了一个能单步的「虚拟机示波器」
读到这你大概已经有画面了。但「字节码逆序压栈」「生成器挂起恢复」「VM 重入自己跑 lambda」这些,光看文字总隔一层。所以我把整套引擎复刻了一遍(不到 600 行、零运行时依赖),又给它套了一个可视化外壳------一台「虚拟机示波器」:
- 三段流水线一屏可见:左边语法树、中间字节码(lambda 的子字节码可以展开)、右边虚拟机执行。
- 逐指令单步 ,或按速度自动播放。当前
ip高亮,对应的语法树节点同步点亮。 - 操作数栈画成物理盘片 ,按类型着色,
push/pop带动画;调用栈帧实时显示main > lambda current=... [#i]的重入层级。 - 两种模式:教学模式每条指令都暂停;真实模式只在取数处挂起------直接把「真实 VM 只在哪儿停」摆给你看。
- 挂起/恢复的「冻结」动画:把某个属性标成「冷·需取数」,求值撞上它时整台 VM 定格、弹出覆盖层,取数返回后再解冻继续。
- 还有个进阶面板演示第十节的请求合并:N 行如何不退化成 N*M 次往返。
为了靠谱,引擎在 Node 里跑了 37 个公式/错误/挂起用例全过,整页又用 jsdom 做了端到端冒烟(单步执行、lambda 重入、冻结覆盖层、结果正确)全过。
我把它整理成了一个开箱即跑的小工程:
text
notion-vm/
├── build.sh # 组装 src/* → dist/notion-vm.html
├── src/{engine,ui}.js, style.css, body.html
├── test/{test.js, step_smoke.js, dom_smoke.mjs}
└── dist/notion-vm.html # 自包含单文件,浏览器直接打开
bash
npm run build # 从源码重建单文件 HTML
npm test # 37 个公式/错误/挂起用例(纯 node,无需装依赖)在线 Demo 与完整源码:github.com/fluffyox/no...
收尾:它到底是什么?
逆完这一圈,很容易冒出一个念头:Notion 是不是一个跑在浏览器里的迷你操作系统?哲学层面确实有几分像------一切皆 block(一切皆文件)、字节码 VM(用户态运行时)、权限分级、事务队列(调度器)、GC......
但要较真的话,它更像一个带内嵌运行时的、local-first 的数据库:没有硬件、没有内存保护、权威数据在服务端,公式语言也不是图灵完备的------它是一门受限的领域 DSL,不是通用编程语言。这台 VM 的存在,不是为了「能算任何东西」,而是为了让「一列公式在几千行上反复、可暂停、可沿关系链取数地求值」这件事,变得高效而可控。
一个笔记软件的公式栏,背后是一套相当完整的编译器 + 虚拟机工程。下次你在 Notion 里敲下一个公式,不妨想想:那一刻,你的浏览器里有一台小小的虚拟机,正把你的字符串编译成字节码、逐条执行,碰到要去远端取的数据就优雅地冻结自己,等数据回来再从原地醒来。
如果这篇对你有用,欢迎点赞 / 收藏 / 关注。逆向与复刻的全部代码都在 GitHub 仓库 里,欢迎对着字节码自己玩。