目录
考试技巧
malloc之后记得free,指针用完记得NULL- 重新分配内存使用
realloc(void* ptr, size_t size) - 考试时写代码建议C和C++混合使用,哪个方便用哪个,比如cin永远比scanf舒服,printf有时候比cout舒服
- 头文件?和我的
#include <bits/stdc++.h>说去吧!
记得要using namespace std;
绪论
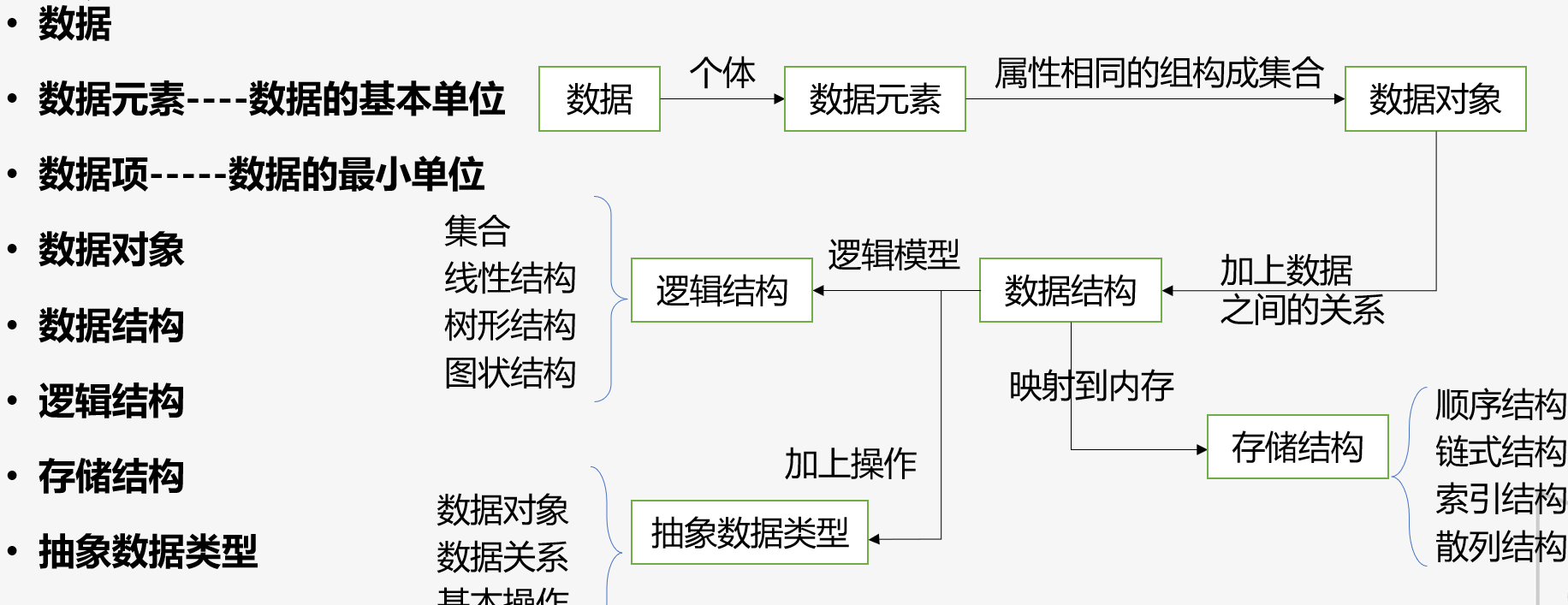
数据 > 数据对象 > 数据元素 > 数据项
用C++理解:
- 数据项 → \rightarrow → struct 的成员变量 (id, name, age)在内存中,你不能再把 id(学号)或者 age(年龄)拆分成更小的、具有业务含义的单位了。它们是描述一个学生的最小原子属性。
- 数据元素 → \rightarrow → 结构体变量 (stu1)当你在代码中执行传递、排序或查找时,通常是把 stu1 作为一个整体传给函数。例如:void printStudent(Student s),这里的参数 s 就是一个数据元素。
- 数据对象 → \rightarrow → 结构体数组/容器 (student_list)这是由相同类型(Student 类型)的元素组成的集合。它在逻辑上代表了"全体学生"这一概念。
- 数据 → \rightarrow → 整个内存上下文在上述代码中,除了 student_list,还存在 system_log(字符串)和 status_code(整型)。这所有能被操作系统和 CPU 识别、处理的二进制符号的集合,在宏观上统称为数据。
数据元素是数据的基本单位 (作为一个整体进行考虑和处理);
数据项是数据的不可分割的最小单位(构成了数据元素)。
逻辑结构与数据元素本身的形式、内容、相对位置、个数无关
逻辑上,数据分为线性和非线性
四种基本的存储结构:
顺序存储
链式存储
索引存储(有一个额外的索引表)
散列存储(参考哈希表)
抽象数据类型的三个组成部分分别为数据对象、数据关系和基本操作
算法的5个特性
- 有穷性
- 确定性
- 可行性
- 输入
- 输出
c
for(i=1; i<=n; i++)
for(j=1; j<=i; j++)
for(k=1; k<=j; k++)
x++;x++的语句频率是 n(n+1)(n+2)/6
考试时
简单的就直接推
遇到复杂的,找个数带进去算就行!
记得看清楚是时间复杂度还是空间复杂度!
顺序表(顺序存储)
这破玩意就是C语言里的数组,C++里的std::vector
这么熟悉的东西,我还能说什么? (What can I say?)
考试注意点:
- 写代码记得注意 函数参数是否为引用参数
- 大部分选择题 里的顺序表可以直接当成数组来理解
可复习的算法题:
- 线性表la和线性表lb中的数据元素按值非递减有序排列,现要求将la和lb归并为一个新的线性表lc,且lc中的元素仍按值非递减有序排列
- 一元多项式的运算
- 稀疏多项式的运算
- 设顺序表A有n+m个元素,前n个元素递增有序,后m个元素递减有序。设计一个算法,把这两部分合并成一个全部递增有序的顺序表,并分析算法的时间复杂度,要求空间复杂度为O(1)
静态顺序表:
c
#define ListSize 100 //最大允许长度
typedef struct {
ListData data[ListSize] ; //存储空间
int length; //当前元素个数
} SeqList;动态顺序表:
c
#define LIST_INIT_SIZE 10 // 线性表存储空间的初始分配量
#define LISTINCREMENT 5 // 线性表存储空间的分配增量
typedef struct
{
ListData *data; // 存储空间基址
int length; // 顺序表当前长度
int listsize; // 当前分配的存储容量(以sizeof(ListData)为单位)
}SqList;初始化线性表L (参数用引用)
cpp
Status InitList_Sq(SqList &L){ //构造一个空的顺序表L
L.elem = new ElemType[MAXSIZE]; //为顺序表分配空间
if(!L.elem)
exit(OVERFLOW); //存储分配失败
L.length = 0; //空表长度为0
return OK;
}初始化线性表L (参数用指针)
c
Status InitList_Sq(SqList *L){ //构造一个空的顺序表L
L-> elem = new ElemType[MAXSIZE]; //为顺序表分配空间
if(! L-> elem)
exit(OVERFLOW); //存储分配失败
L-> length = 0; //空表长度为0
return OK;
}顺序表(链式存储)-> 链表
链表有单链表、静态链表、循环链表、双向链表,大部分链表都挺简单的,不过多赘述
单链表
c
typedef char ListData;
typedef struct node { //链表结点
ListData data; //结点数据域
struct node * next; //结点链域
} ListNode;
typedef ListNode * LinkList; //链表头指针注意事项:
- 删除带头节点的单链表时,需要销毁头节点,防止内存泄漏
- 链表需要头节点的目的是:方便运算的实现
简答题:作用是为了对链表进行操作时,可以对空表、非空表的情况以及对首元结点进行统一处理,编程更方便。 - 顺序存储与静态存储的优缺点比较(简单,不赘述)
可复习算法题:
- 设有一个表头指针为L的无头结点的非空单链表。设计一个算法,将链表中所有结点的链接方向逆转,即要求仅利用原表的存储空间(也就是说,算法的空间复杂度为O(1))
静态链表
c
#define MAX_SIZE 100
typedef struct{
ElemType data; // 数据域
int cur; // 游标域
}component, SLinkList[MAX_SIZE];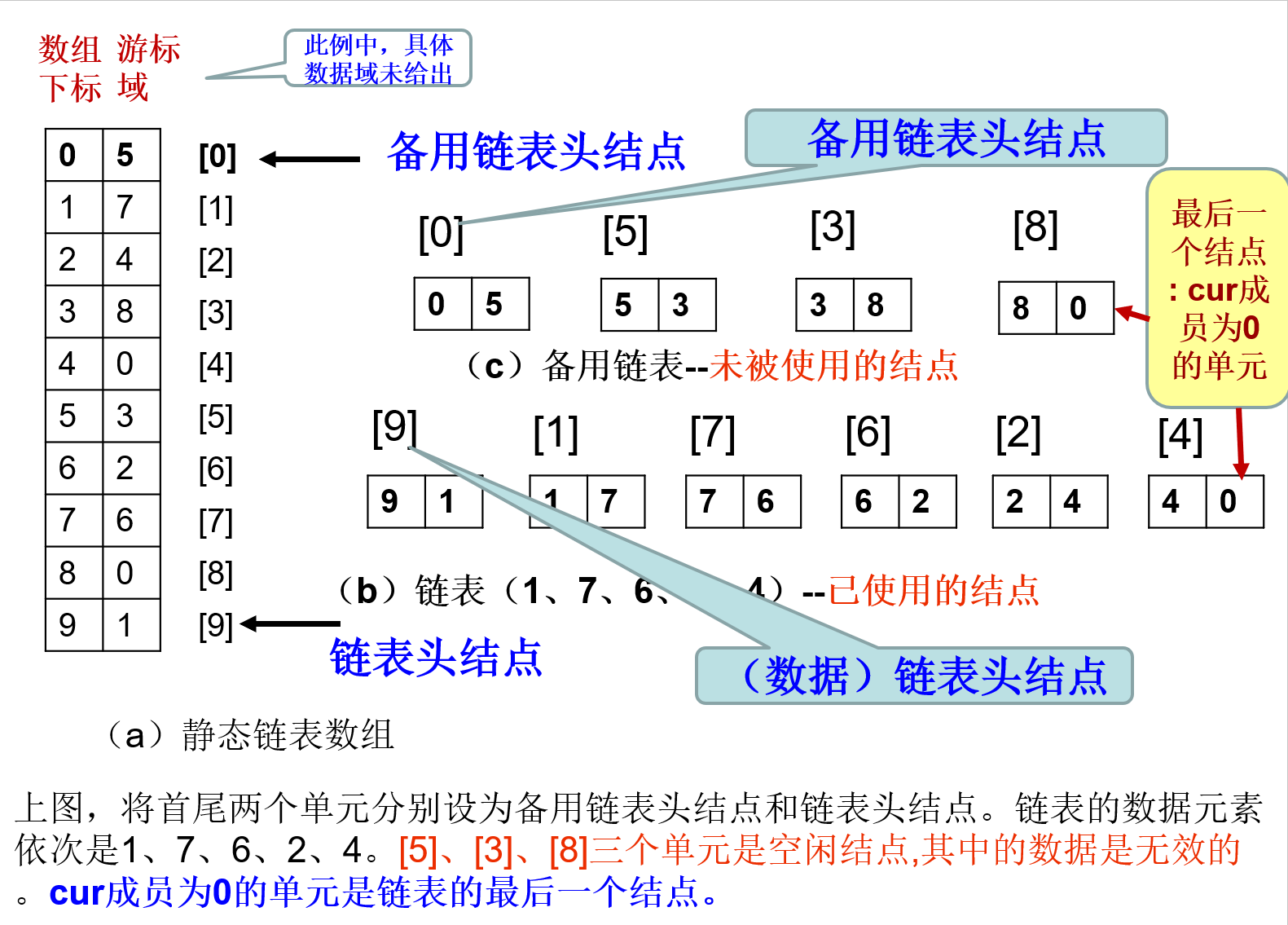
PPT第20页开始
cpp
// 寻找可用地址
int Malloc(SLinkList space)
{
int i = space[0].cur; //备用链表第一个结点的位置
if(i) //备用链表非空
space[0].cur = space[i].cur;
//备用链表的头结点指向原备用链表的第二个结点
return i; //返回新开辟结点的坐标
}
// 释放地址
void Free(SLinkList space, int k)
{
space[k].cur=space[0].cur;
//回收结点的"游标"指向备用链表的第一个结点
space[0].cur=k;
//备用链表的头结点指向新回收的结点
}
// 构造空链表
void InitList(SLinkList L)
{
int i;
L[MAX_SIZE-1].cur=0;
//L的最后一个单元为空链表的表头
for(i=0; i<MAX_SIZE-2; i++)
//将其余单元链接成以[0]为表头的备用链表
L[i].cur=i+1;
L[MAX_SIZE-2].cur=0;
}
// 重置为空表
void ClearList(SLinkList L)
{ //初始条件:线性表L已存在。操作结果:将L重置为空表
int j, i=L[0].cur; //i指示备用链表第一个结点的位序
while(i)
{ j=i; //j指示当前结点的位序
i=L[i].cur; //i指向下一个结点的位序
}
L[j].cur=L[MAX_SIZE-1].cur;
//链表的第一个结点接到备用链表的尾部
L[MAX_SIZE-1].cur=0; //链表空
}
// 插入数据
Status ListInsert(SLinkList L, int i, Elem e)
//在L中第i个元素之前插入新的数据元素e
{int m, j, k=MAX_SIZE-1; //k指示表头结点的位序
if(i<1 || i>ListLength(L)+1) //i值不合法
return ERROR;
j=Malloc(L); //申请新单元
if(j) //申请成功
{ L[j].data=e; //将e赋值给新单元
for(m=1; m<i; m++) //k向后移动i-1个结点,使k指示第i-1个结点
k=L[k].cur; //指向下一个结点
L[j].cur=L[k].cur; //新单元指向第i-1个元素后面的元素(第i个元素)
L[k].cur=j; //第i-1个元素指向新单元
return OK;
}
return ERROR;
}
// 删除数据
Status ListDelete(SLinkList L, int i, ElemType &e)
{ //删除在L中第i个数据元素e,并返回其值
int j, k=MAX_SIZE-1; //k指示表头结点的位序
if(i<1 || i>ListLength(L)) //i值不合法
return ERROR;
for(j=1; j<i; j++) //移动i-1个元素,使k指向第i-1个元素
k=L[k].cur; //指向下一个元素
j=L[k].cur; //待删除元素(第i个元素)的位置赋给j
L[k].cur=L[j].cur; // 使第i-1个元素指向待删除元素的后继元素
e=L[j].data; //待删除元素的值赋给e
free(L, j); //释放待删除结点(回收到备用链表中)
return OK;
}循环链表
- 通常给出尾指针,方便表尾操作
可复习内容:
- 合并两个循环链表
- 约瑟夫环问题
循环单链表:
c
struct LNode
{ ElemType data;
LNode *next;
};
typedef LNode *LinkList;双向不循环链表
c
typedef struct DuLNode
{ ElemType data;
struct DuLNode *prior, *next;
}DuLNode, *DuLinkList;太简单了,我能说什么( What can I say? )
双向循环链表
c
typedef struct DuLNode
{ ElemType data;
struct DuLNode *prior, *next;
}DuLNode, *DuLinkList;可复习算法题:
- 设以带头结点的双向循环链表表示的线性表L =(a1, a2, ,..., an)。试写一时间复杂度O(n)的算法,将L 改造为(a1, a3, ,..., an, ,..., a4, a2)
- 设计一个算法,通过一趟遍历,将链表中所有结点的链接方向逆转,且仍利用原表的存储空间
- 将两个非递减的有序链表合并为一个非递增的有序链表。要求结果链表仍使用原来两个链表的存储空间,不另外占用其他的存储空间。表中允许有重复的数据
- 査找链表中倒数第k个位置上的结点
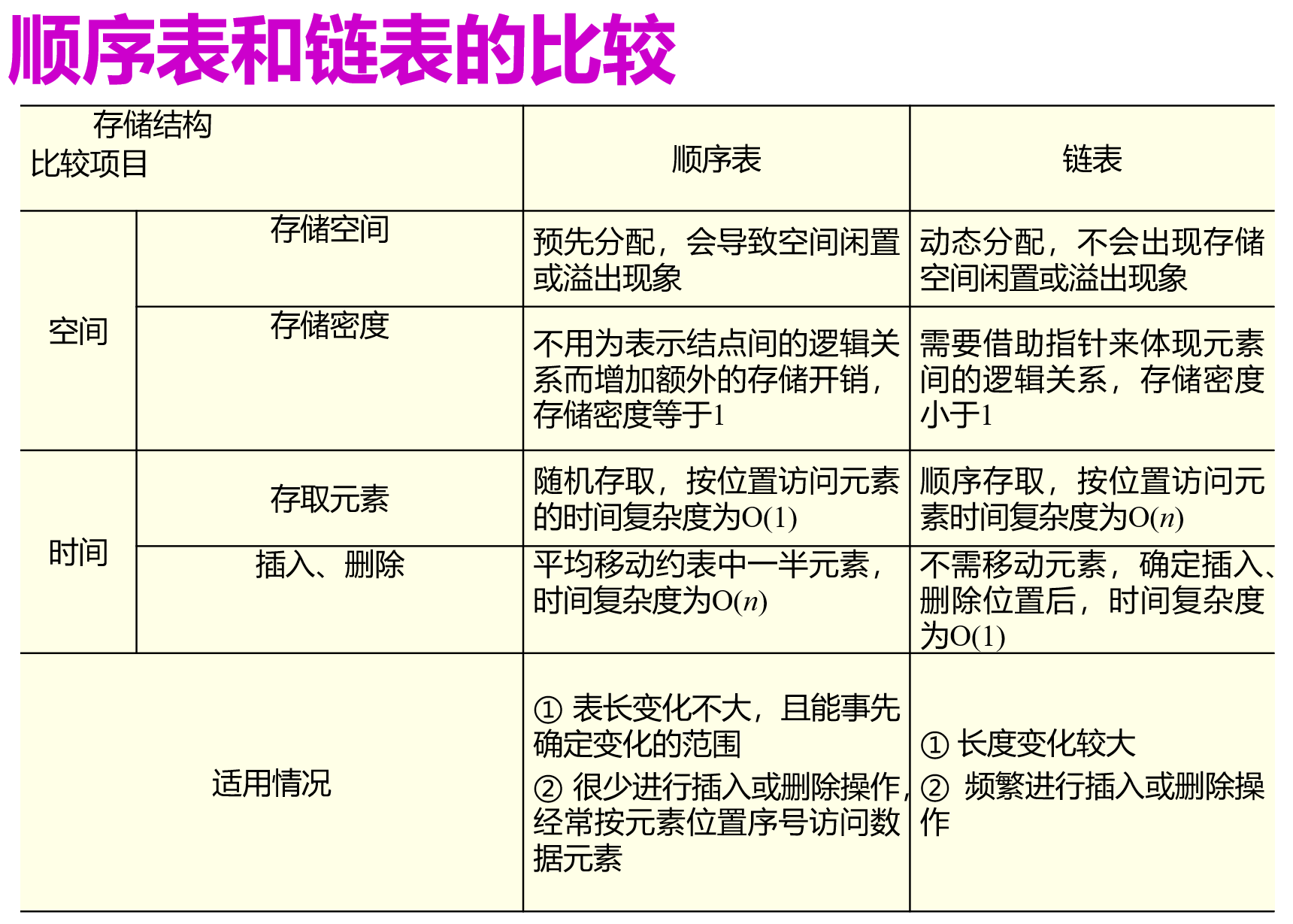
顺序表和链表的比较
栈
注意点:
- 非空栈中栈顶指针始终在栈顶元素的下一个位置上
- 使用realloc重新分配空间
- 有两种栈空、栈满的实现:
- top指向栈顶元素存储的下一个 存储单元的位置
空栈:base == top (top == 0)
满栈:top- base == stacksize (top == base+stacksize ) - top指向栈顶 元素的存储位置
空栈:top == -1
满栈:top == maxSize-1
- top指向栈顶元素存储的下一个 存储单元的位置
顺序存储实现:
c
#define maxSize 100
typedef char SElemType;
typedef struct {
SElemType elem[maxSize]; //定长数组
int top; //栈顶下标
} SeqStack;链式存储实现:
c
#define STACK_INIT_SIZE 100;//存储空间初始分配量
#define STACKINCREMENT 10;//存储空间分配的增量
typedef char SElemType;
typedef struct { //顺序栈定义
SElemType *base; //栈底指针
SElemType *top; //栈顶指针
int stacksize; //当前已分配的存储空间
} SqStack;可复习的算法题:
- 回文序列
- 括号匹配
队列
顺序队列/循环队列
注意点:
- 头指针指向队头元素
尾指针指向队尾元素的下一位置 - 当前队列尾指针等于数组的上界时,即使队列不满,再进行入队操作也会引起溢出,这种现象称为假溢出
- 循环队列中
- 队空:front == rear
- 队满:(rear+1)%M == front
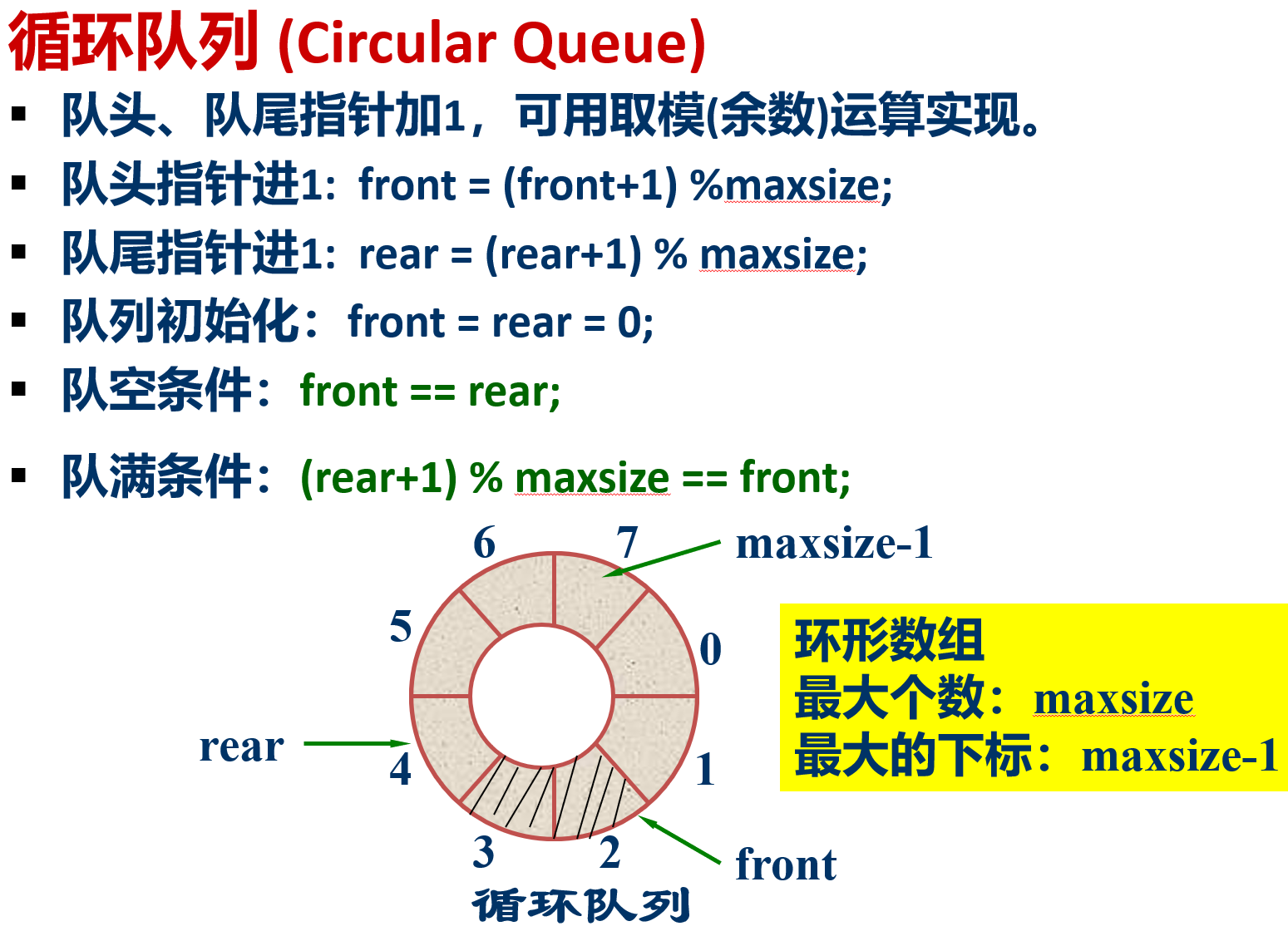
实现:
c
#define MAXSIZE 100 //最大长度
Typedef struct{
QElemType *data; //初始化的动态分配存储空间
int front; //头指针,指示队头位置
int rear; //尾指针,指示队尾位置
} SqQueue
可复习算法题:
- 打印杨辉三角
链式队列
c
typedef struct QNode { //链队结点
QElemType data; //结点数据
struct QNode *next; //结点链指针
} QNode, *QueuePtr;
typedef struct { //链队结构
QueuePtr front; //队头指针
QueuePtr rear; //队尾指针
} LinkQueue;可复习:
已知循环队列存储在一维数组A[0...n-1],且队列非空时,front和rear分别指向队头元素和队尾元素。
若初始时队列为空,且要求第一个进入队列的元素存储在A[0]处,则初始时front和rear的值分别是()
A. 0,0
B. 0,n-1
C. n-1,0
D. n-1,n-1
答案:B
[2014年]循环队列放在以为数组A[0...M-1]中,end1指向队头元素,end2指向队尾元素的后一个位置。
假设队列两端均可进行入队和出队操作,队列中最多能容纳M-1个元素。初始时为空。
下列判断队空和队满的条件中,正确的是()
A. 队空:end1==end2; 队满:end1==(end2+1)mod M
B. 队空:end1==end2; 队满:end1==(end1+1)mod (M-1)
C. 队空:end2==(end1+1)mod M 队满:end1==(end2+1)mod M
D. 队空:end1==(end2+1)mod M 队满:end1==(end1+1)mod (M-1)
答案:A可以复习一下 3-栈和队列-C.pptx 中的题目
数组
无敌了,说实话上课时听到这个名字时,我以为是同名的数据结构,没想到真就是数组......何意味?
线性表结构是数组结构的一个特例
数组结构是线性表结构的扩展
习题
需要理解:
- 寻址公式(可类比操作系统中的磁盘寻址公式,不过这个更简单)
- 会寻址,通过一个下标的地址求另一个下标的地址
- 考试记得看清题目是 行优先存储 还是 列优先存储 !

做题技巧:
以列为主时,将两个数字互换位置就变成行为主了,比如第二题求 列为主的A[5,8] 直接变成 行为主的A[8,5]
前提是数组的行与列起始下标相同! 比如这道题都是1开始
求数组地址和求存储首地址不一样!注意区分

代码实现
c
# include<stdarg.h> //标准头文件
//提供宏va_start,va_arg和va_end用于存取可变长参数表
# define MAX_ARRAY_DIM 8 //数组维数的最大值
typedef struct{
ElemType * base; //数组元素基址,由InitArray 分配
int dim; //数组维数
int *bounds; //数组维界基址,由InitArray分配
int *constants; //数组映像函数常量基址,由InitArray分配
}Array;- base:数组元素基址,以二维数组A为例,将数组(按行或者按列)拉成一个向量L所组成的线性结构的首地址。
- bounds:数组维界基址,指向一个一维数组B,它存放了数组A各维度元素的数目。假设数组A是(3,4,5)大小的, 则数组B=3,4,5。
- constants:数组映像函数常量基址,指向一个数组C, 它存放了"数组A各个维度上的数字加1时, 元素在线性结构L上所移动的距离"
constantsi = constansi+1 * boundsi+1
计算多维数组的地址

矩阵压缩存储
对数学不好的我来说,这部分真的纯折磨
对称矩阵
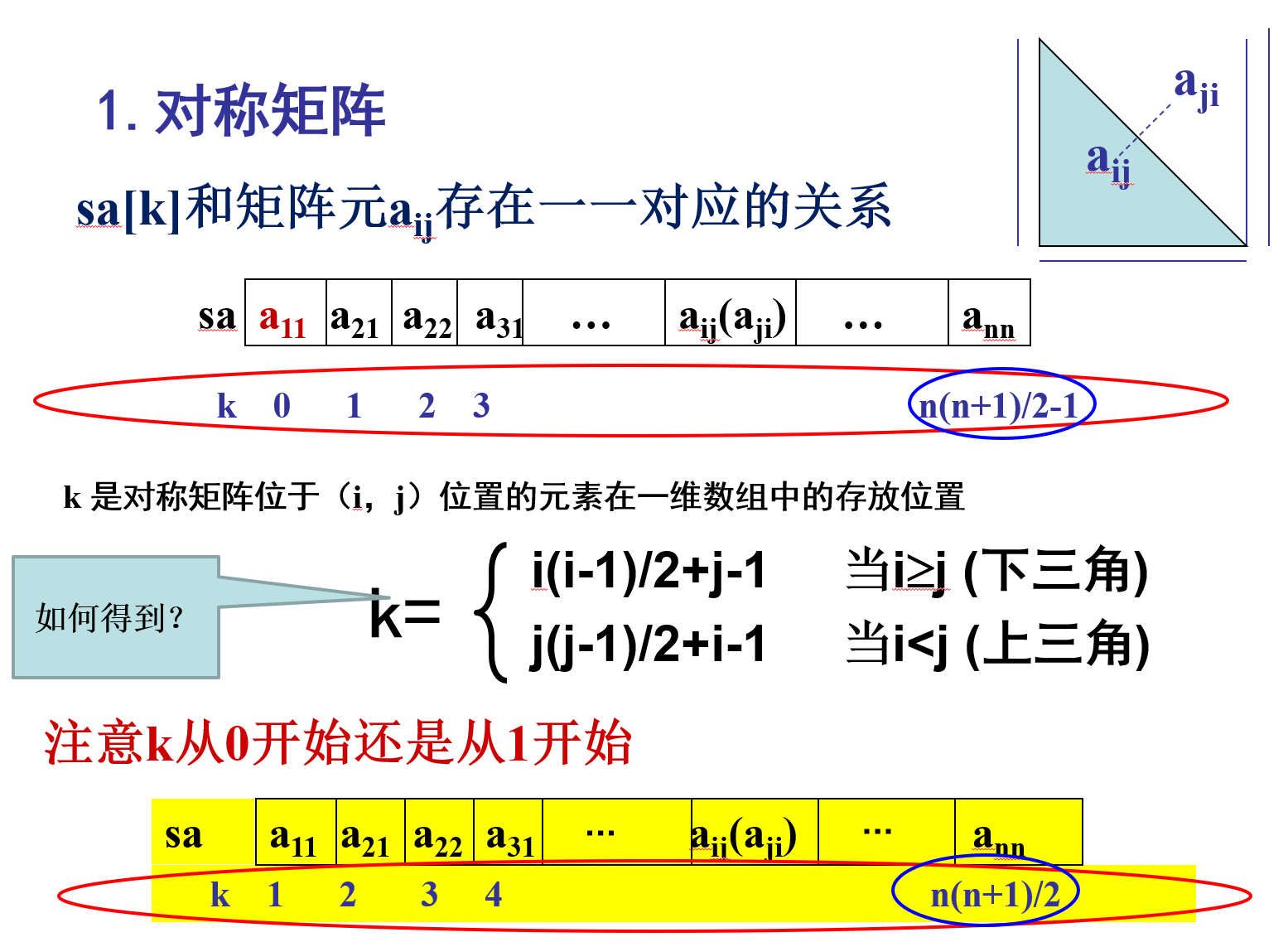

三角矩阵
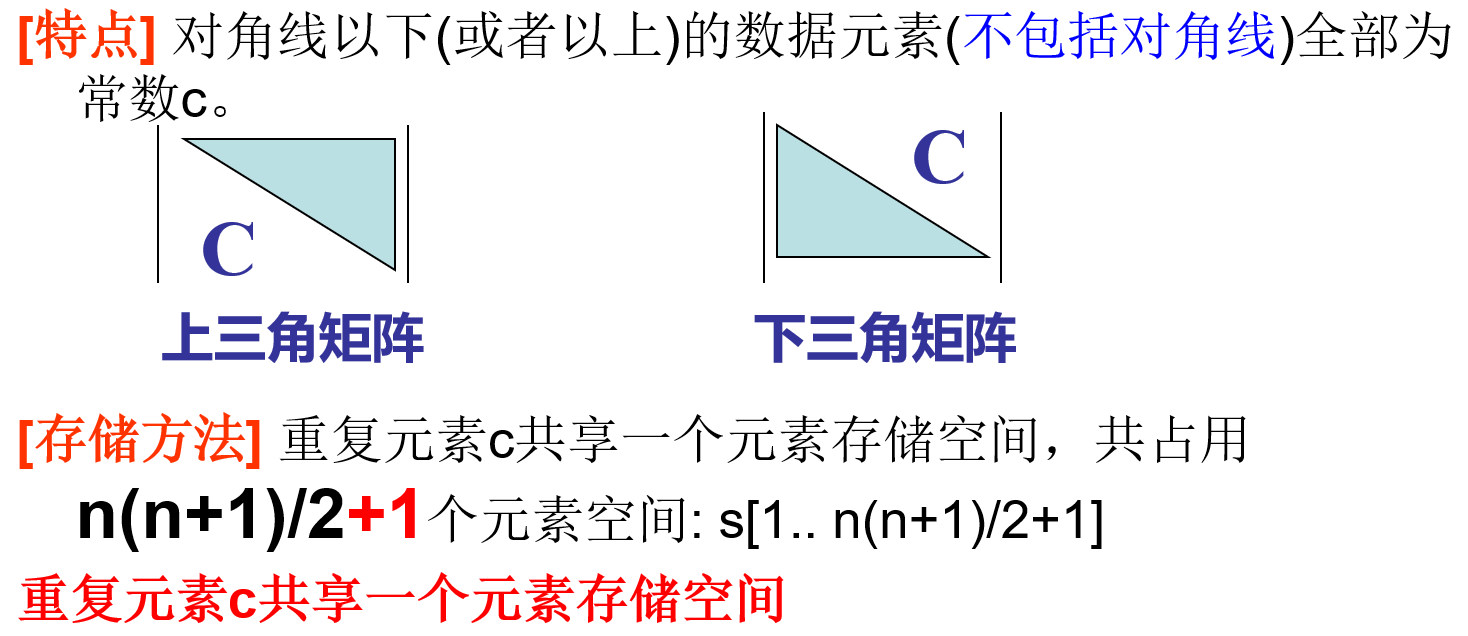

这部分线性代数中矩阵学得好的同学比较容易理解,对我来说纯折磨,我是再无话说了,再无话说,速速动手,看看PPT背下来公式得了
稀疏矩阵
c
#define MAXSIZE 100 //非零元个数的最大值
typedef struct {
int i,j; // 行下标,列下标
ElemType e; // 非零元素值
}Triple;
typedef struct {
Triple data[MAXSIZE+1]; //非零元三元组表,data[0]未用
int mu,nu, tu; //矩阵的行数、列数和非零元个数
}TSMatrix;TODO
十字链表
TODO
广义表
一个概念更广泛的顺序表,可以参考一下python?我不太确定
里面的每一个元素可以是原子,也可以是子表。
它是线性表的推广 ,但是本质是非线性结构 ,属于线性与非线性之间
广度看第一层的元素个数,深度看有几层括号
表LS = (a1, a2, ..., an) 的第一个表元素a1 称为广义表的表头(head),除此之外,其它表元素组成的表 (a2, ..., an)称为广义表的表尾(tail)
要注意:取出表尾时,会额外加上一层括号!
再看一眼概念:其它元素组成的表 称为表尾,因此取表尾会套括号
考试技巧:每次GetTail之后默认都加一个GetHead就行

头尾链表法
代码实现:
c
typedef enum {ATOM, LIST} ElemTag; // 0:原子, 1:子表
typedef struct GLNode {
ElemTag tag; // 公共部分,标志域,用于区分原子结点和表结点
union{ // 原子结点和表结点的联合部分
AtomType atom; // 原子结点的数据域
struct {struct GLNode *hp, *tp;} ptr;
// ptr是表结点的指针域, ptr.hp和ptr.tp分别指向表头和表尾
};
} *GList; //广义表类型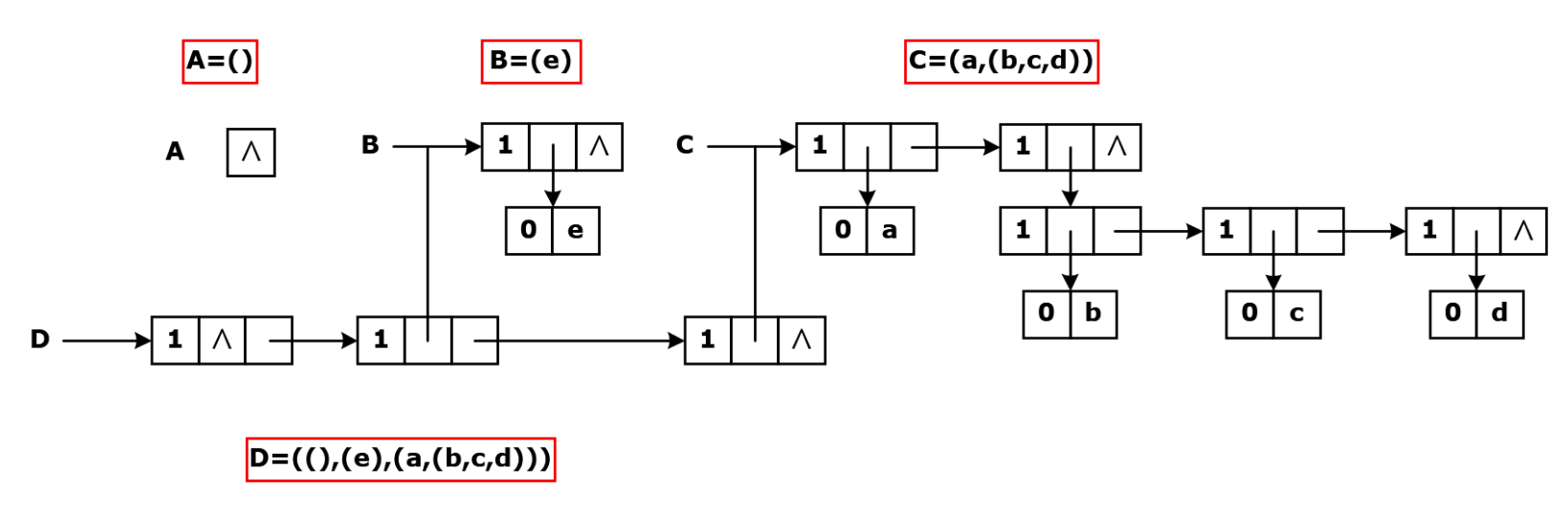
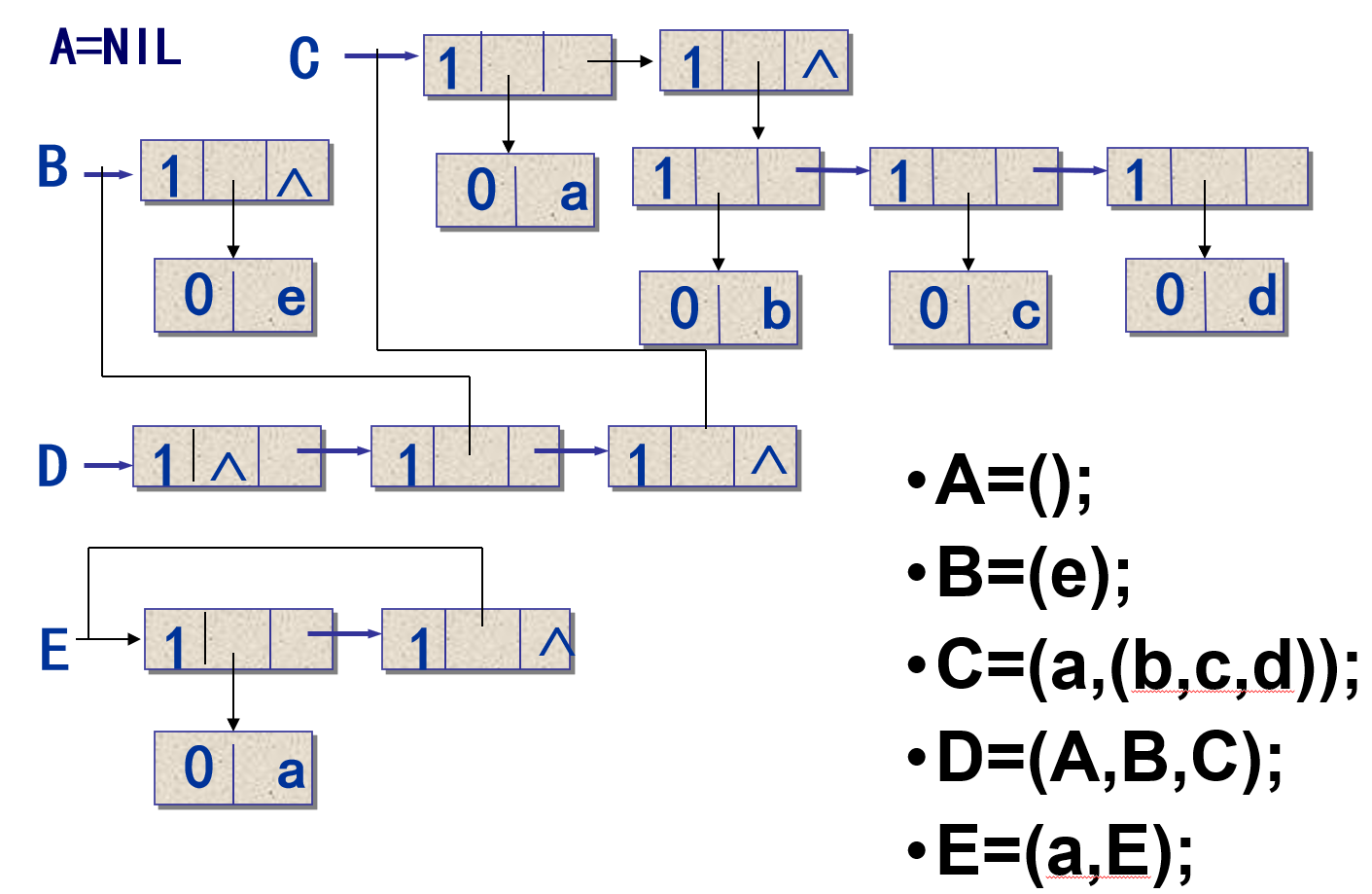
扩展线性链表
c
typedef enum {ATOM, LIST} ElemTag; // 0:原子, 1:子表
typedef struct GLNode {
ElemTag tag; // 公共部分,标志域,用于区分原子结点和表结点
union{ // 原子结点和表结点的联合部分
AtomType atom; // 原子结点的值域
struct GLNode *hp; // 表结点的表头指针
};
struct GLNode *tp; //相当于线性链表的next,指向下一个元素结点
} *GList; //广义表类型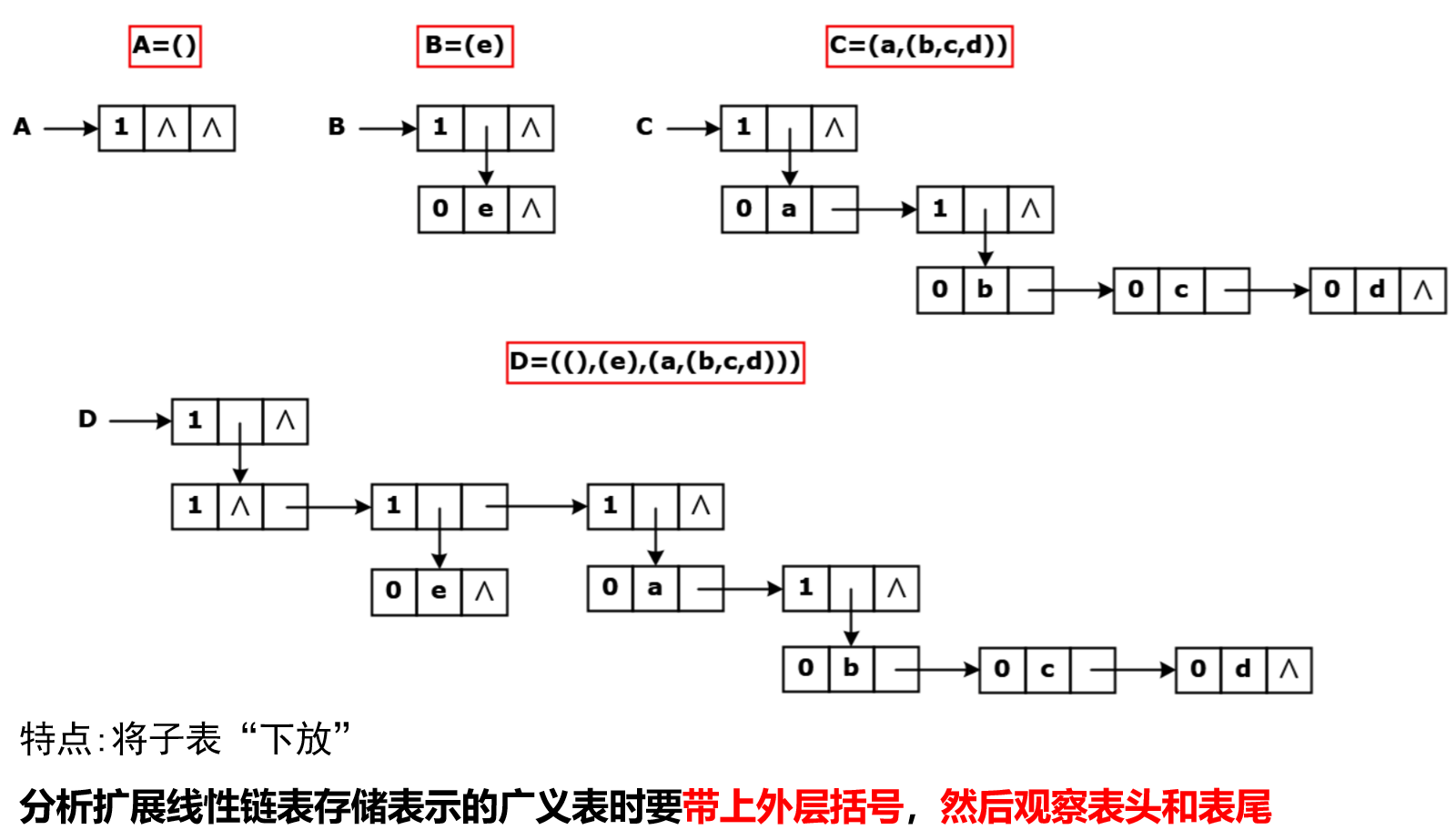
树
概念复习:
- 结点(node)---表示树中的元素,包括数据项及若干指向其子树的分支
- 结点的度(degree)---结点拥有的子树个数
- 叶子(leaf)------度为0的结点,也称为终端结点
- 非终端结点(分支结点)------度不为0的结点
- 树的度--- 一棵树中最大的结点度数(子树数)
- 孩子(child)---结点的子树的根称为该结点的孩子(结点)
- 双亲(parents)---孩子结点的上一层结点叫该结点的~(父结点)
- 兄弟(sibling)------同一双亲的孩子互称兄弟(结点)
- 结点的层次(level)------从根结点算起,根为第一层,其它结点的层次为其双亲结点的层数加1
- 树的深度(树高depth)---树中结点的最大层次数
- 堂兄弟--其双亲在同一层的结点互称为堂兄弟。
- 结点的祖先---从根结点到该结点所经分支上的所有结点
- 结点的子孙---以某结点为根的子树中的任一结点都称之为该结点的子孙
- 有序树和无序树:树中各结点的子树从左到右有次序(不能互换),称该树为有序树,否则为无序树(有序树:第一个孩子、第二个孩子...)
- 森林(forest)---m(m>=0)棵互不相交的树构成的集合
二叉树
二叉树是有序树
性质:
- 在二叉树的第 i 层上至多有
2i-1个结点。 (i≥1) - 深度为 k 的二叉树上至多含
2k-1个结点(k≥1) - 对任何一棵二叉树T,若它含有n0 个叶子结点、n2 个度为 2 的结点,则必存在关系式:
n0 = n2+1
(在树中:n0=n2+...+(m-1)*nm+1)
满二叉树
深度为k且有2 k-1个结点的二叉树称为满二叉树
完全二叉树
若设二叉树的深度为h,则共有h层。除第 h 层外,其它各层 (0 ~ h-1) 的结点数都达到最大个数,第 h 层从右向左连续缺若干结点,这就是完全二叉树
特点:
- 叶子结点只可能在层次最大的两层上出现
- 对任一结点,若其右分支下子孙的最大层次为 l,则其左分支下子孙的最大层次必为 l 或 l +1
性质1:

性质2:

求解方法归纳

二叉树的存储
顺序存储
c
#define MAX_TREE_SIZE 100 // 二叉树的最大结点数
#define TElemType char //二叉树的数据元素类型:char
typedef TElemType SqBiTree[MAX_TREE_SIZE];
// 二叉树顺序存储的数据类型定义,char一维数组
// 0号单元存储根结点
SqBiTree bt; // 定义一个二叉树顺序存储的数据类型变量bt链式存储 - 二叉
c
#define TElemType char //二叉树的数据元素类型:char
typedef struct BiTNode { // 结点结构
TElemType data;
struct BiTNode *lchild, *rchild; // 左右孩子指针
} BiTNode, *BiTree;链式存储 - 三叉
c
typedef struct TriTNode { // 结点结构
TElemType data;
struct TriTNode *lchild, *rchild;
// 左右孩子指针
struct TriTNode *parent; //双亲指针
} TriTNode, *TriTree;二叉树的遍历
前序:根节点在前面
中序:根节点在中间
后序:根节点在后面
层次:按行遍历
这里要复习一下关于遍历的实现等知识,内容较多,作为期末笔记不宜展开......
线索二叉树
// TODO