1. 有关JSON的序列化和反序列化
1.1 常规写法
java
@Test
void jacksonTest(){
ObjectMapper objectMapper=new ObjectMapper();
CommonResult<String> result=CommonResult.error(500,"系统错误");
String str;
// 序列化 对象->json
try {
str=objectMapper.writeValueAsString(result);
System.out.println(str);
}catch (JacksonException e){
throw new RuntimeException(e);
}
// 反序列化
try {
CommonResult<String> readResult =objectMapper.readValue(str,CommonResult.class);
System.out.println(readResult.getCode()+" "+readResult.getMsg());
}catch (JacksonException e){
throw new RuntimeException(e);
}
// List 序列化
List<CommonResult<String>> commonResults= Arrays.asList(
CommonResult.success("success1"),
CommonResult.success("success2")
);
try {
str =objectMapper.writeValueAsString(commonResults);
System.out.println(str);
}catch (JacksonException e){
throw new RuntimeException(e);
}
// 反序列化
JavaType javaType=objectMapper.getTypeFactory()
.constructParametricType(List.class,CommonResult.class);
try {
commonResults=objectMapper.readValue(str,javaType);
for (CommonResult<String> commonResult:commonResults){
System.out.println(commonResult.getData());
}
}catch (JacksonException e){
throw new RuntimeException(e);
}
}
缺陷:一直要写 try-catch,如果封装为方法接口,调用接口的时候也需要去抛异常
1.2 借鉴方法
在 package org.springframework.boot.json; 下的 JacksonJsonParser 类中有写序列化和反序列化的方法,反序列都只调用了一个方法:tryParse
java
@Override
public Map<String, Object> parseMap(@Nullable String json) {
return tryParse(() -> getJsonMapper().readValue(json, MAP_TYPE), Exception.class);
}
@Override
public List<Object> parseList(@Nullable String json) {
return tryParse(() -> getJsonMapper().readValue(json, LIST_TYPE), Exception.class);
}进入 tryParse 方法
java
protected final <T> T tryParse(Callable<T> parser, Class<? extends Exception> check) {
try {
return parser.call();
}
catch (Exception ex) {
// 判断是否为预料中的异常
if (check.isAssignableFrom(ex.getClass())) {
throw new JsonParseException(ex);
}
ReflectionUtils.rethrowRuntimeException(ex);
throw new IllegalStateException(ex);
}
}return parser.call(); 调用 Lambda 表达式(有抛出异常)
将所有的异常在 tryParse 中进行了catch
tryParse 方法在内部捕获了所有异常(包括受检异常),然后根据条件:
-
如果是"预期"的异常(
check.isAssignableFrom(ex.getClass())),包装成JsonParseException(假设它继承RuntimeException) -
如果不是,则用
ReflectionUtils.rethrowRuntimeException(ex)或抛出IllegalStateException(都是非受检异常)
不需要 try-catch,也不需要 throws 。因为 tryParse 方法没有声明任何受检异常(它只抛出运行时异常),编译器不会强制你捕获
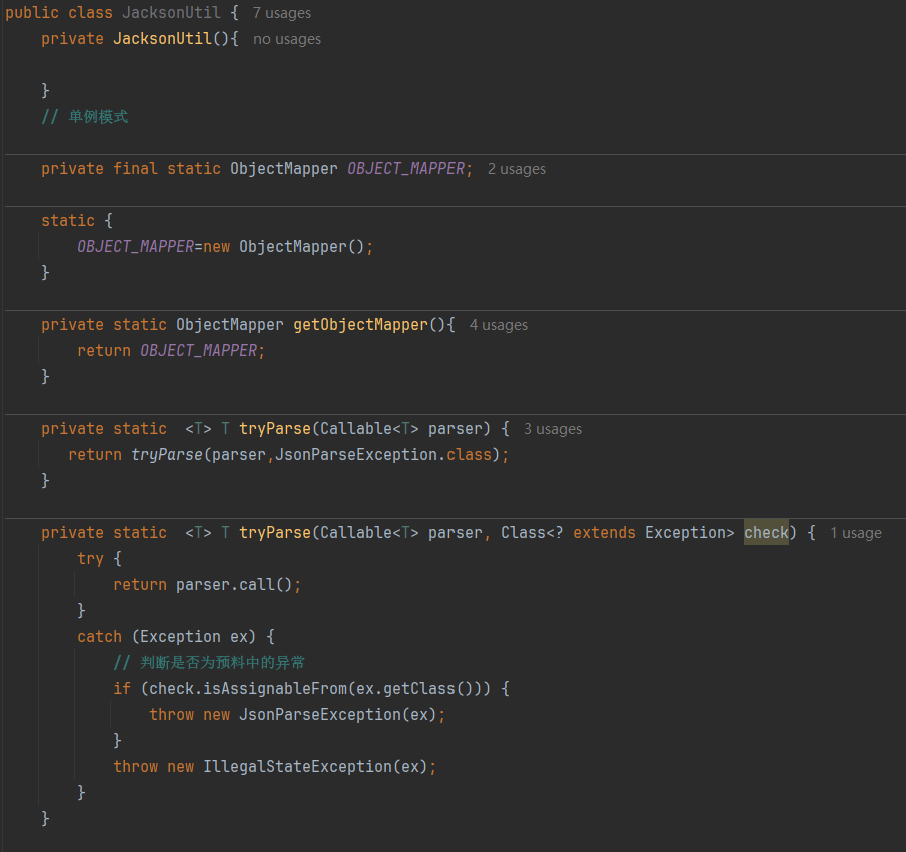
1.3 实现代码
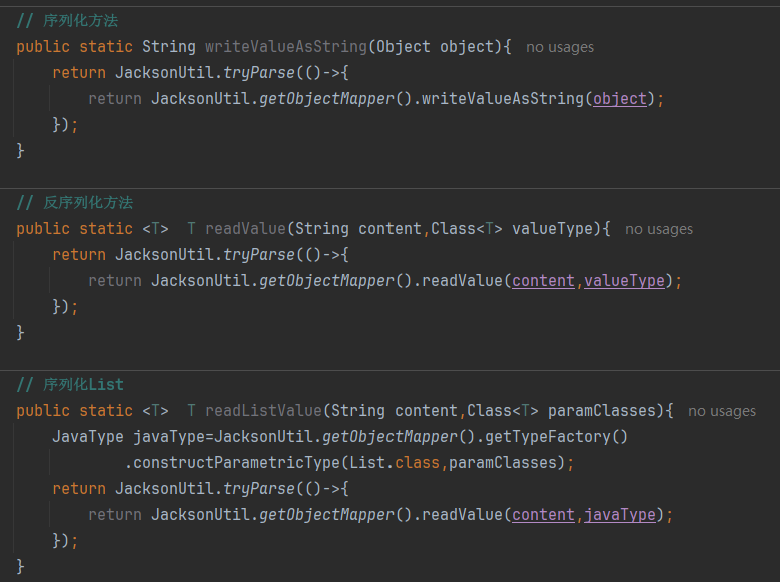
1.4 测试代码
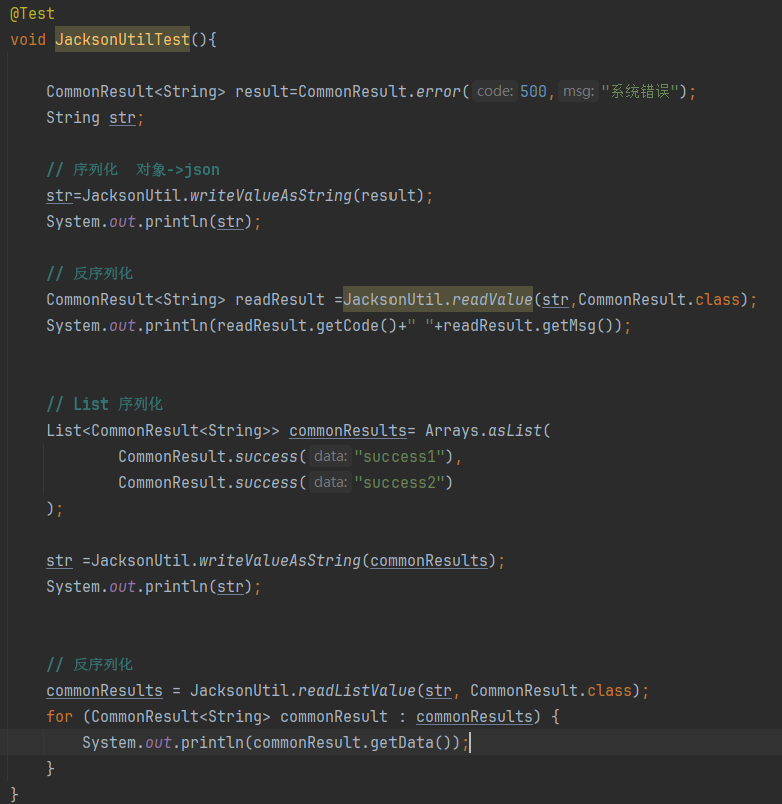

2. SLF4J+logback的配置
2.1 新增 application.properties 配置
java
## logback xml ##
logging.config=classpath:logback-spring.xml
spring.profiles.active=dev
# 部署后需要变成
# spring.profiles.active=test2.2 新增 logback-spring.xml
java
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="60 seconds" debug="false">
<springProfile name="dev"............2.3 自定义过滤器
java
public class InfoLevelFilter { // 定义一个名为 InfoLevelFilter 的过滤器类
public FilterReply decide(ILoggingEvent iLoggingEvent) {
// decide 方法是 Logback 过滤器的核心,每次产生日志事件时都会调用
// 参数 iLoggingEvent 代表一条待输出的日志事件(包含级别、内容、时间等)
if(iLoggingEvent.getLevel().toInt() == Level.INFO_INT) {
// 如果这条日志的级别转换成整数后,等于 INFO 级别的整数值
return FilterReply.ACCEPT; // 接受:这条日志会被输出
}
return FilterReply.DENY; // 否则拒绝:这条日志不会被输出
}
}Logback 就是 Java 应用中最常用的高性能日志框架,它实现了 SLF4J,配置简单、功能强大,是生产环境日志管理的首选方案之一
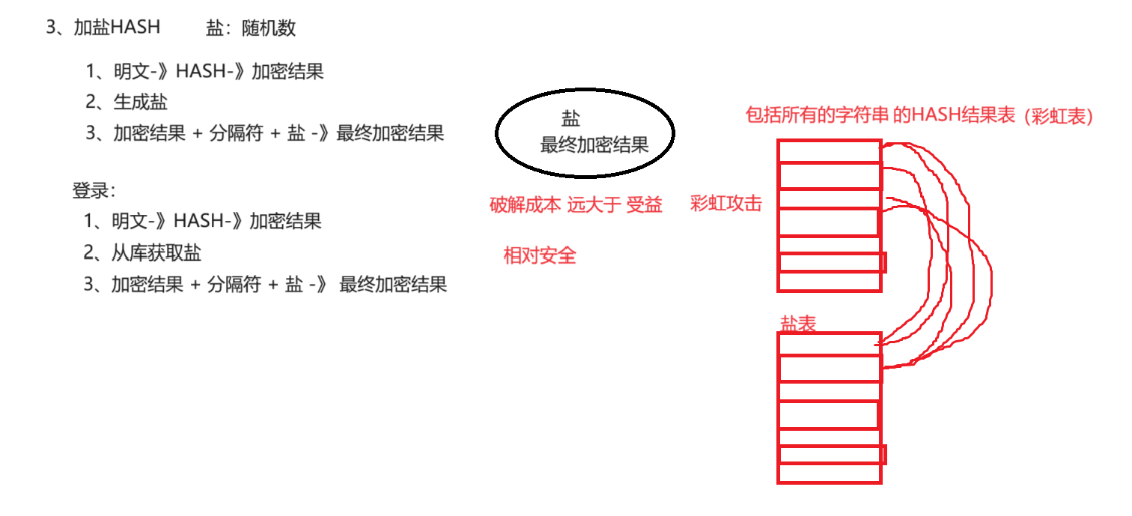
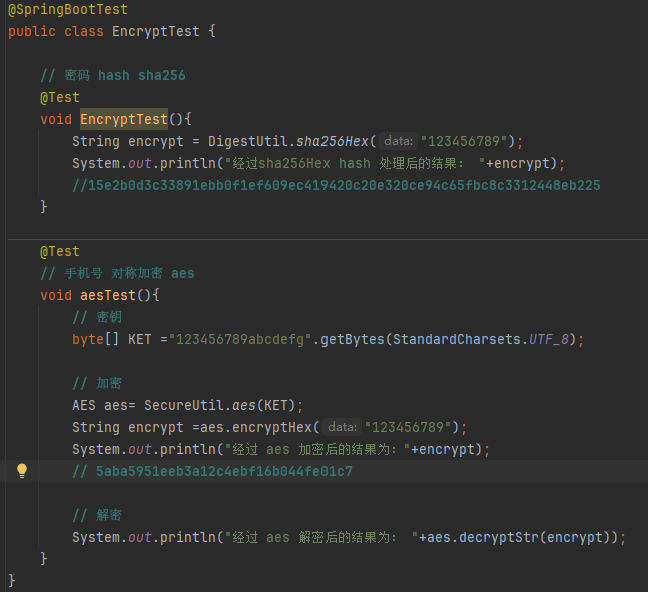
3. 加密
国产Java工具类库Hutool,对文件、流、加密解密、转码、正则、线程、XML等JDK方法进行了封 装,开箱即用



4. TypeHandler
TypeHandler:简单理解就是当处理某些特定字段时,我们可以实现⼀些方法,让Mybatis遇到这些 特定字段可以自动运行处理
4.1 编写一个实体类,凡是此实体类的数据都表示需要加解密的
java
@Data
public class Encrypt {
private String value;
public Encrypt() {}
public Encrypt(String value) {
this.value = value;
}
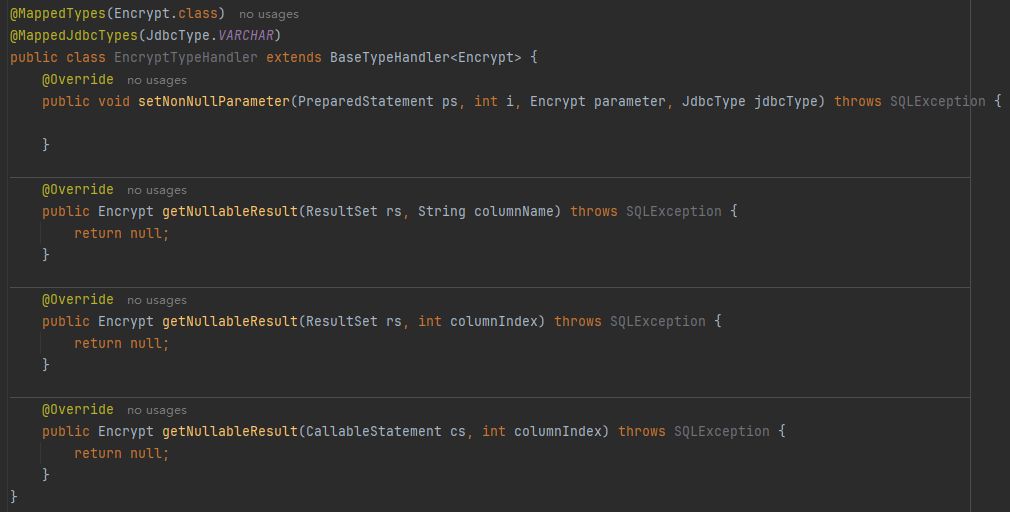
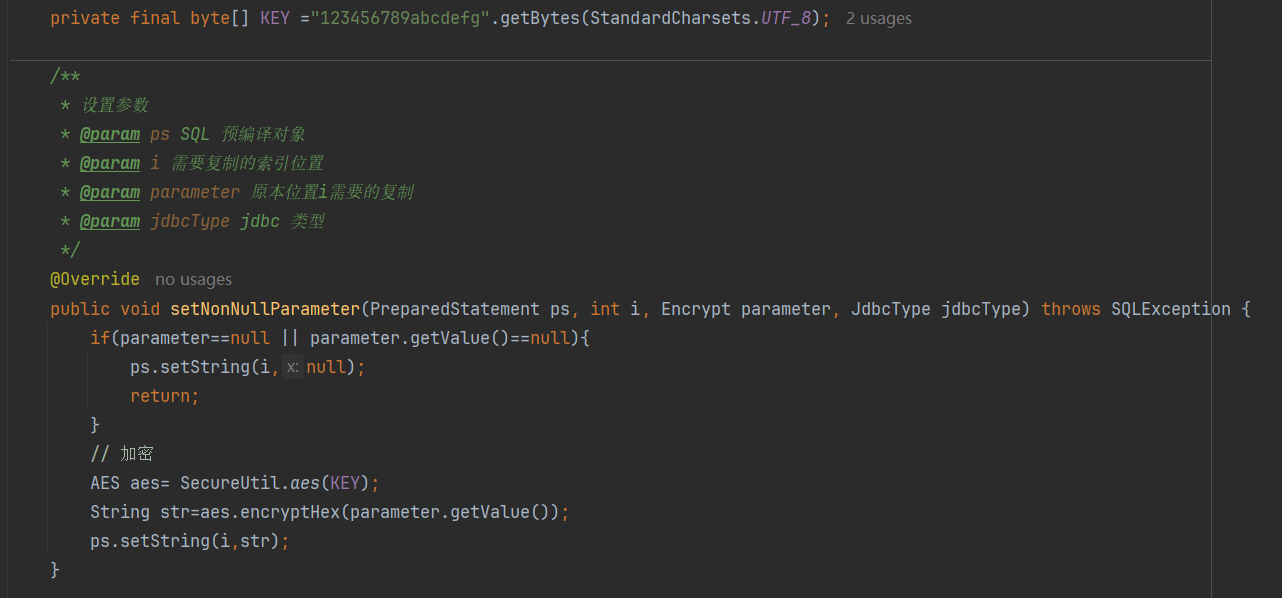
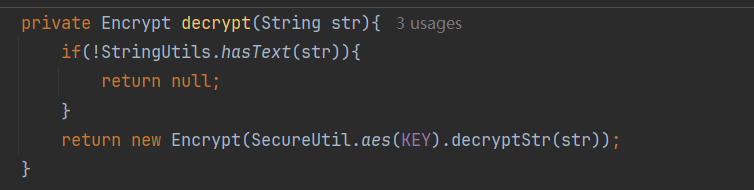
}4.2 编写一个加解密的TypeHandler
@MappedTypes:表示该处理器处理的java类型是什么
@MappedJdbcTypes:表示处理器处理的Jdbc类型
5. Redis的简单使用
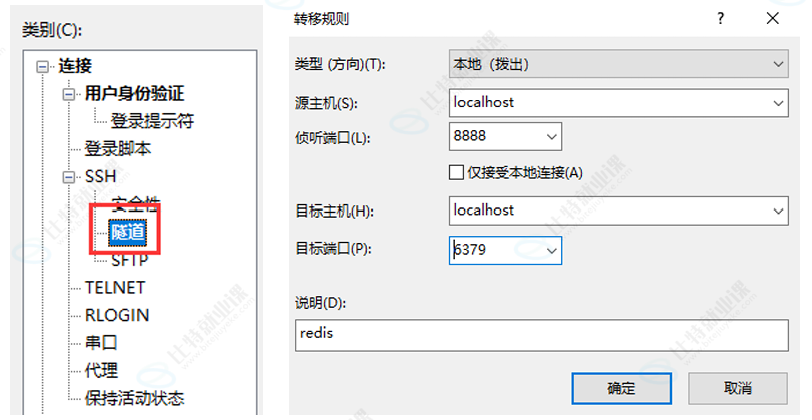
Redis 服务器安装在云服务器上,而我们编写的代码则是在本地主机. 要想让本地主机能访问redis,需要把redis的端⼝通过云服务器后台页面的"防火墙"/"安全组"放开 端口到公网上.但是这个操作非常危险(黑客会顺着redis端口进来). 因此我们可以使用端口转发的方式,直接把服务器的redis端口映射到本地.
5.1 测试
java
@SpringBootTest
public class RedisTest {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
void redisTest(){
stringRedisTemplate.opsForValue().set("key1","value1");
System.out.println("从Redis获取值:"+stringRedisTemplate.opsForValue().get("key1"));
}
}启动redis service redis-server start

6. RabbitMQ
6.1 什么是MQ
MQ(Message queue),本质是一个队列,FIFO先入先出,只不过队列中存放的内容是消息(message),消息可以非常简单,比如只包含文本的字符串,JSON等,也可以很复杂,比如内嵌对象
MQ多用于分布式系统之间进行通信
系统之间的调用通常有两种方法
- 同步通信
直接调用对方的服务,数据从一段发出后立即就可以达到另一端

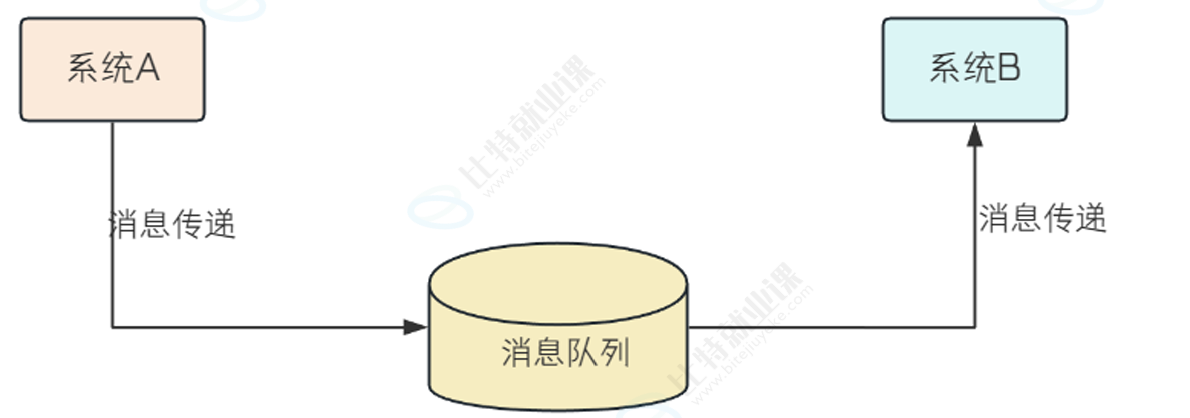
- 异步通信
数据从一段出发后,先进入一个容器进行临时存储,当达到某种条件后,再由这个容器发送给另一端,容器的一个具体实现就是MQ
RabbitMQ 就是MQ的一种实现
6.2 MQ的作用
MQ主要工作是接收并转发消息,在不同的应用场景下可以展现不同的作用
-
异步解耦:在业务流程中,一些操作可能非常耗时,但并不需要即使返回结果,可以借助MQ把这些操作异步化,不如用户注册后发送注册短信或邮件通知,可以作为异步处理,不必等待这些操作完成后才告知用户注册成功
-
流量削峰:在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见,如果以能处理这类峰值为标准投入资源,无疑是巨大的浪费,使用MQ能够使关键组件支撑突发访问压力,不会因为突发流量而崩溃
-
异步通信:在很多时候不需要立即处理消息,MQ提供了异步处理机制,允许应用把一些信息放入MQ中,但并不立即处理它,在需要的时候再慢慢处理
-
消息发布:当多个系统需要对同一数据做出响应时,可以使用MQ进行消息分发
-
延迟通知:在需要特定时间发布通知的场景中,可以使用MQ的延迟消息功能
-
......
6.3 为什么选择RabbitMQ
6.3.1 Kafka
Kafka一开始的目的就是用于日志的收集和传输,追求高吞吐量,性能卓越,单机吞吐达到十万级,在日志领域比较成熟,功能较为简单,主要支持简单的MQ功能,如果有日志采集需求,首选
6.3.2 RocketMQ
RocketMQ采用java语言开发,由阿里巴巴开源,后捐赠给了Apache
它在设计时借鉴了Kafka,并做出了一些自己的改进,青出于蓝而胜于蓝,经过多年双十一的洗礼,在可用性、可靠性以及稳定性方面都有出色的表现,适合对于可靠性要求高,且并发比较大的场景,但支持的客户端语言不多,且社区活跃度一般
6.3.3 RabbitMQ
采用Erlang语言开发,MQ功能比较完备,且几乎支持所有的主流语言,开源提供的界面也十分友好,性能较好,社区活跃度高,比较适合中小型公司,数据量没那么大,且并发没那么高的场景
7. 设计模式
7.1 关于状态转换的常规写法
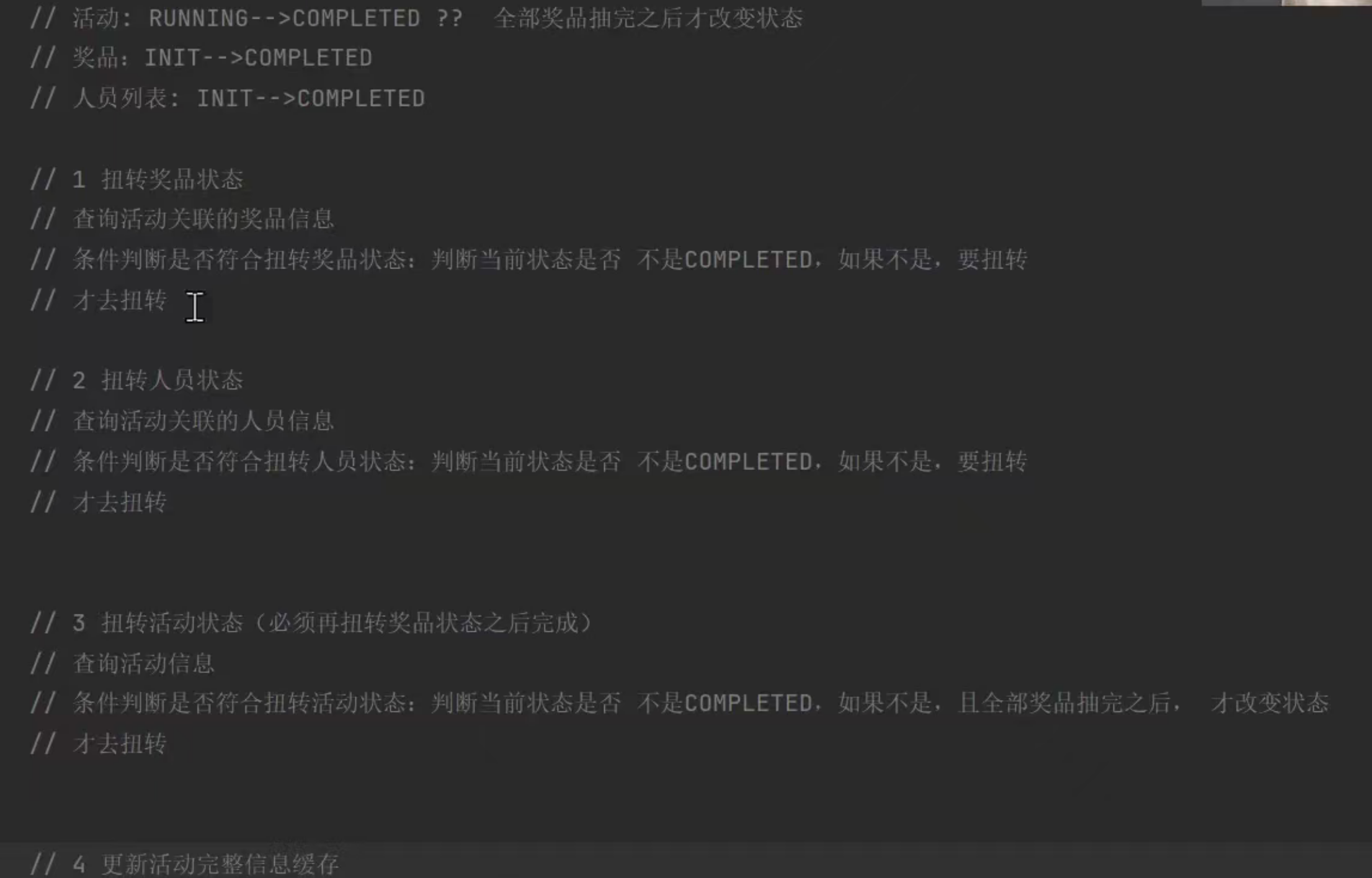
7.2 问题:
- 存在多个处理对象的顺序关系需要维护:奖品+活动状态扭转,活动需要依赖奖品状态改变而改变。可以看出请求依赖于多个决策点,因此处理顺序很重要,不易维护
- 需要动态改变算法或行为:是否可以扭转的条件,若将来会发生改变,在这里不易维护
- 系统的灵活性和拓展性无法体现
- 处理请求的复杂性不易维护
7.3 解决方案:
- 策略模式:定义AbstractActivityOperator策略类,和其策略实现类PrizeOperator,ActivityOperator和UserOperator。每个具体的操作类都实现了AbstractActivityOperator定义的接口,代表了不同的状态转换策略
- 责任链模式:定义ActivityStatusManager接口类,在ActivityStatusManagerImpl实现中,通过遍历operatorMap中的所有操作符(策略),并按照一定的顺序执行,形成一个责任链,每个操作符判断是否是自己的责任,如果是,则处理请求
责任链模式是一种行为设计模式,它允许将一个请求沿着处理着对象组成的链进行传递。每个处理者对象都有责任去处理请求,或者将它传递给链中的下一个处理者。请求的传递一直进行,知道有一个处理着对象对请求进行了处理,或者知道链的末端仍然未有处理者处理的请求
责任链在项目中的实现
- 请求的创建:ConvertActivityStatusDTO 是请求对象,包含了状态转换所需的所有信息
- 处理者对象:AbstractActivityOperator及其子类PrizeOperator,ActivityOperator和UserOperator,它们实现了needConvert和convertStatus方法,用以判断是否需要处理请求以及执行处理
- 责任链的维护:operatorMap是一个包含所有处理者对象的映射,它按照sequence()方法返回的顺序维护了责任链
- 请求的传递:在processStatusConversion方法中,通过迭代器遍历operatorMap,对每个操作符实例调用needConvert方法来判断是否需要由当前操作符处理请求
- 处理请求:如果needConvert返回true,则调用convertStatus方法来处理请求
- 终止责任链:一旦请求被某个操作符处理,迭代器中的该操作符将被移除,防止请求被重复处理,并且终止了对该操作符的责任链
- 异常处理:如果在责任链中的任何点上请求处理失败,则抛出异常,这可以看做是责任链的终止
通过这种方法,责任链模式允许系统在运行时根据请求的类型动态的选择处理者,而不需要修改其他处理者的代码,从而提高了系统的灵活性和可维护性
理解6的移除机制:
1. 副本机制(关键)
代码第一行使用了 Map<String,AbstractActivityOperator> curMap = new HashMap<>(operatorMap);。
这里创建的是一个浅拷贝(副本) 。后续所有对 curMap 的增删改,都不会影响原始的 operatorMap,但会影响这个副本本身。
2. 第一次调用(处理 sequence = 1)
调用 processConvertStatus(convertActivityStatusDTO, curMap, 1) 时:
-
迭代器获取了
curMap的全部元素。 -
当找到
sequence() == 1且需要转换的策略时,执行iterator.remove()。 -
Java 迭代器的
remove()方法会直接从集合(curMap)中物理删除该键值对。
第一次调用结束,此时 curMap 里所有 sequence = 1 的元素都已经被删干净了。
3. 第二次调用(处理 sequence = 2)
调用 processConvertStatus(convertActivityStatusDTO, curMap, 2) 时:
-
传入的还是同一个
curMap对象(引用没变)。 -
虽然循环判断里有
operator.sequence() != sequence,就算不删除,也会因为sequence=1 != 2而continue跳过它们。 -
但更关键的是 :由于第一次迭代器的物理删除,第二次调用时,迭代器从头遍历
curMap,根本遍历不到 sequence = 1 的对象,因为它们已经不在了。