聊《前端转大模型:把关键流程跑顺》之前,先说一句实在的:别急着背概念,先看它在真实项目里到底解决什么问题。
摘要
本文概述文章目标、核心观点和实践价值。
上个月接了一个医疗咨询 AI 助手的项目,产品经理说"先做个 MVP,快速验证",前端部分本来很简单------一个对话框,一个输入框,后端用 Python FastAPI 接 GPT-4。结果开发到一半,医学问答需要展示推理过程(类似 deepseek 那个链式思考),用户上传的化验单图片也要能识别,还要实时流式输出。我花了三天把基础交互搭好,又花了整整一周解决流中断、多模态渲染、图片压缩的坑。今天聊一聊那次复盘里我实际做了什么取舍,希望对正在转型的前端朋友有用。
目录
- 前端的转型优势:你本来就在做"交互"
- AI 应用交互模式:别只看对话框
- 流式输出:从"收到就渲染"到"分片控制"
- 多模态体验:图片上传和压缩策略
- 作品集方向:从"页面还原"到"问题解决"
- 总结
前端的转型优势:你本来就在做"交互"
很多前端同学觉得转大模型要先啃数学 Python,但真实项目里最缺的是能把 AI 能力包装成"正常人能用的产品"的人。你看 ChatGPT 的 UI,核心交互没变:用户输入→处理→展示,只是数据源从后端 API 变成了流式 tokens。前端对状态管理、用户体验、响应式设计的理解,在 AI 应用里依然是核心竞争力。
那次项目里,后端同学用 WebSocket 推流,但页面频繁崩溃------因为他每推一个 token 就发一个消息,前端拼命 setState。我改成了批量收集 tokens 每 50ms 渲染一次,效果丝滑。这种优化后端不会管,产品也不懂,但前端一眼就能看出问题。
AI 应用交互模式:别只看对话框
很多人以为 AI 应用就是类似 ChatGPT 的对话框,但其实常见的交互模式有三种:
| 模式 | 例子 | 前端挑战 |
|------|------|----------|
| 问答型 | 客服机器人 | 流式输出 + 历史管理 |
| 创作型 | 文案生成、代码补全 | 增量渲染 + 可编辑 |
| 分析型 | 文档总结、图片识别 | 多模态输入 + 结果结构化 |
我做的医疗助手是第一和第三的混合:用户问症状是问答型,上传化验单是分析型。最大的坑是把两种模式硬塞进同一个聊天界面。比如用户上传图片后,后端返回的结构化报告(表格+指标解读)和普通文本混在一起,渲染时 markdown 表格样式全乱套。最后我设计了两类消息气泡:文本气泡用简单的 Markdown 渲染,结构化气泡用独立组件(表格、标签列表),两种气泡通过消息 type 字段区分。

流式输出:从"收到就渲染"到"分片控制"
流式输出是转型后第一个要啃的硬骨头。前端用原生 fetch + ReadableStream 就能实现,但有几个细节容易翻车。
**踩坑 1:流中断后如何恢复?**
有一次用户网差,流到一半断了,页面只显示一半回答。我重试请求后,后端重新生成完整回答,但前端如果不清理旧对话框就会显示两段内容。方案:每次开始流式请求前,先清空当前消息的占位内容,后端返回时再从头渲染。
**踩坑 2:模拟思考过程的"打字机效果"**
产品要求显示 AI 正在思考(类似"."闪烁)。第一个版本用 setInterval 增加点号,但流式数据到达时状态冲突。后来改成用 CSS 动画 + 一个 isLoading 状态,流式开始后移除动画。
**代码块:React 中用 fetch 实现流式输出**
jsx
const [messages, setMessages] = useState([]);
const sendMessage = async (text) => {
const userMsg = { role: 'user', content: text };
const assistantMsg = { role: 'assistant', content: '' };
setMessages(prev => [...prev, userMsg, assistantMsg]);
const response = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ messages: [...messages, userMsg] })
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
let receiving = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
receiving += decoder.decode(value, { stream: true });
// 每50ms更新一次,避免频繁setState
setMessages(prev => {
const last = prev[prev.length - 1];
return [...prev.slice(0, -1), { ...last, content: receiving }];
});
}
};注意:这里没有用 useRef 缓存 receiving 和节流,实际项目中需要配合 useRef + 定时批量更新,避免性能问题。
多模态体验:图片上传和压缩策略
用户上传的化验单图片经常拍得很模糊、文件太大(好几 MB),后端 OCR 模型很容易超时。前端需要做三件事:压缩、旋转校正、格式转换。
**取舍一:本地压缩 vs 服务端压缩**
一开始想把压缩丢给后端,但上传大文件本身就是慢。后来前端用 Canvas 把图片转成 WebP,宽度控制在 1024px,文件大小从 4MB 降到 200KB,上传速度和 OCR 准确率都提升了。
**取舍二:图片预览和状态管理**
上传图片后需要展示缩略图,但用户可能连续上传多张。我设计了一个临时图片队列,每张图片在发送前还需要用户确认(点击"发送"才真正提交到 API)。这样用户可以从相册选多张,然后逐一删除,最后发送。
**代码块:用 Canvas 压缩图片**
javascript
function compressImage(file, maxWidth = 1024, quality = 0.8) {
return new Promise((resolve) => {
const reader = new FileReader();
reader.onload = (e) => {
const img = new Image();
img.onload = () => {
const canvas = document.createElement('canvas');
const ratio = Math.min(maxWidth / img.width, 1);
canvas.width = img.width * ratio;
canvas.height = img.height * ratio;
const ctx = canvas.getContext('2d');
ctx.drawImage(img, 0, 0, canvas.width, canvas.height);
canvas.toBlob((blob) => resolve(blob), 'image/webp', quality);
};
img.src = e.target.result;
};
reader.readAsDataURL(file);
});
}作品集方向:从"页面还原"到"问题解决"
前端转型做 AI 产品工程师,简历上写"精通 React/Vue"没有用,面试官更想看你是怎么把 AI 能力做成可用的功能。
我建议准备 **2-3 个小项目**,每个项目突出一个交互痛点:
重点展示流式渲染优化、消息历史管理、思考状态展示。可以加上"用户反馈"按钮(点赞/点踩),这是真实产品常用但容易被忽略的功能。
- **项目 1:流式聊天机器人**
上传 PDF/图片,AI 分析后返回结构化结果。前端要做加载态、拖拽上传、预览、结果分区展示(文本摘要、表格、图表)。我那个医疗项目里,结果分区用了 flex 布局 + 粘性标题,用户反馈"像在用专业病历系统"。
- **项目 2:多模态文档问答**
比如做一个简单的"天气查询 + 计算器"助理。用户问"明天北京适合穿什么",AI 内部调用天气 API 和温度计算函数。前端需要展示函数调用步骤(类似 OpenAI 的 tool_calls 可视化)。这个方向很加分,因为涉及到多轮对话的中间状态渲染。
- **项目 3:AI 工具调用(Function Calling)**
记得每个项目都要写 README,说明你做了什么选择(为什么用 SSE 不用 WS,为什么图片压缩到 1024px),面试官最喜欢听你怎么"取舍"。
总结
前端转大模型不需要学完所有 AI 知识,先把"关键流程"跑顺:流式输出、多模态输入处理、思考过程渲染、错误恢复。这些是每一个 AI 应用都会遇到的普适问题。那次医疗项目复盘后,我最大的感受是:前端在 AI 项目里不是"页面搬运工",而是"交互设计师 + 体验保障者"。把这一套流程练熟了,面试时自然有底气。
对了,代码别忘了用 useRef 管理流缓存,别问我怎么知道的。
资料展示
下面是我整理的AI大模型学习资料和工具包预览,适合收藏后按主题逐步学习。
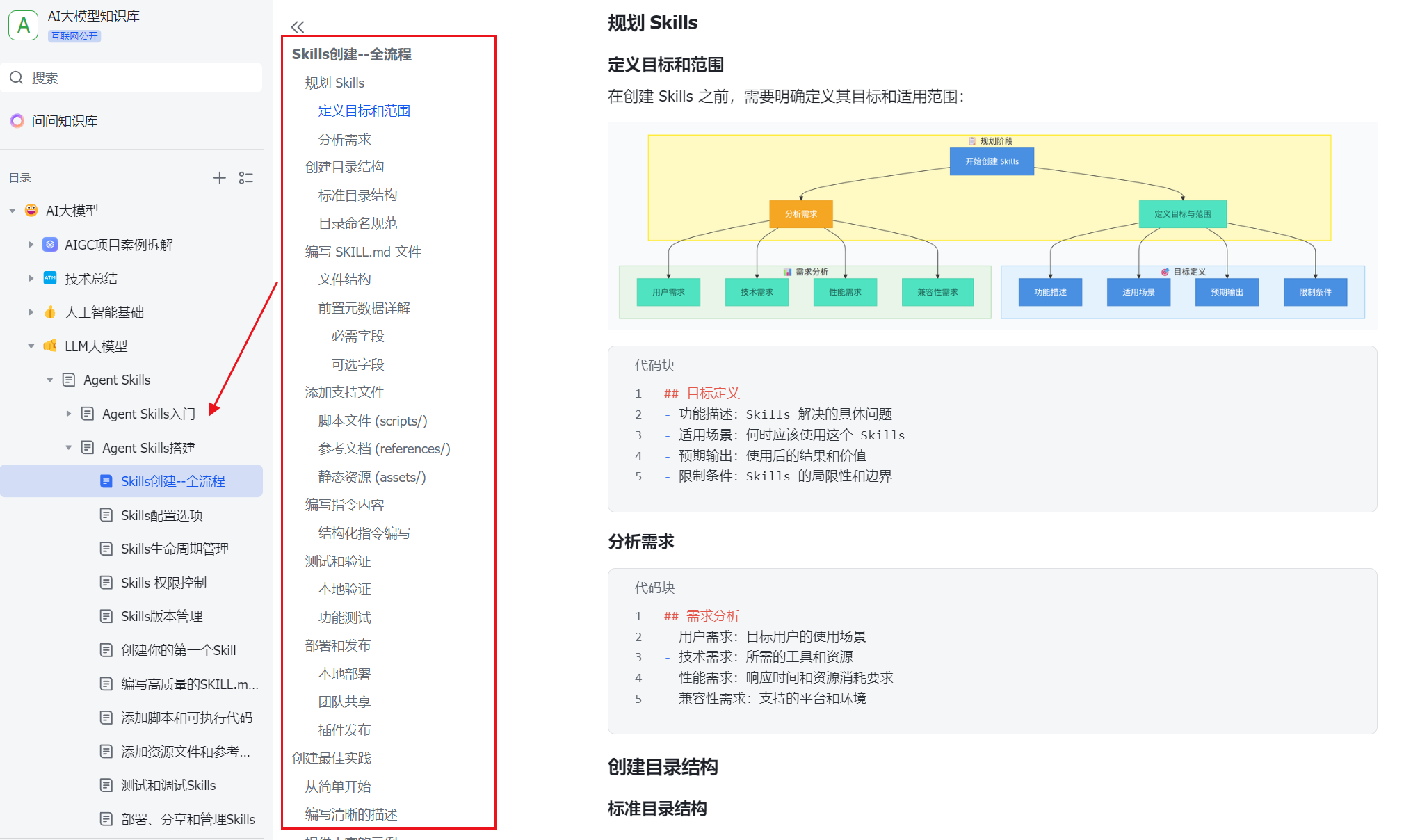
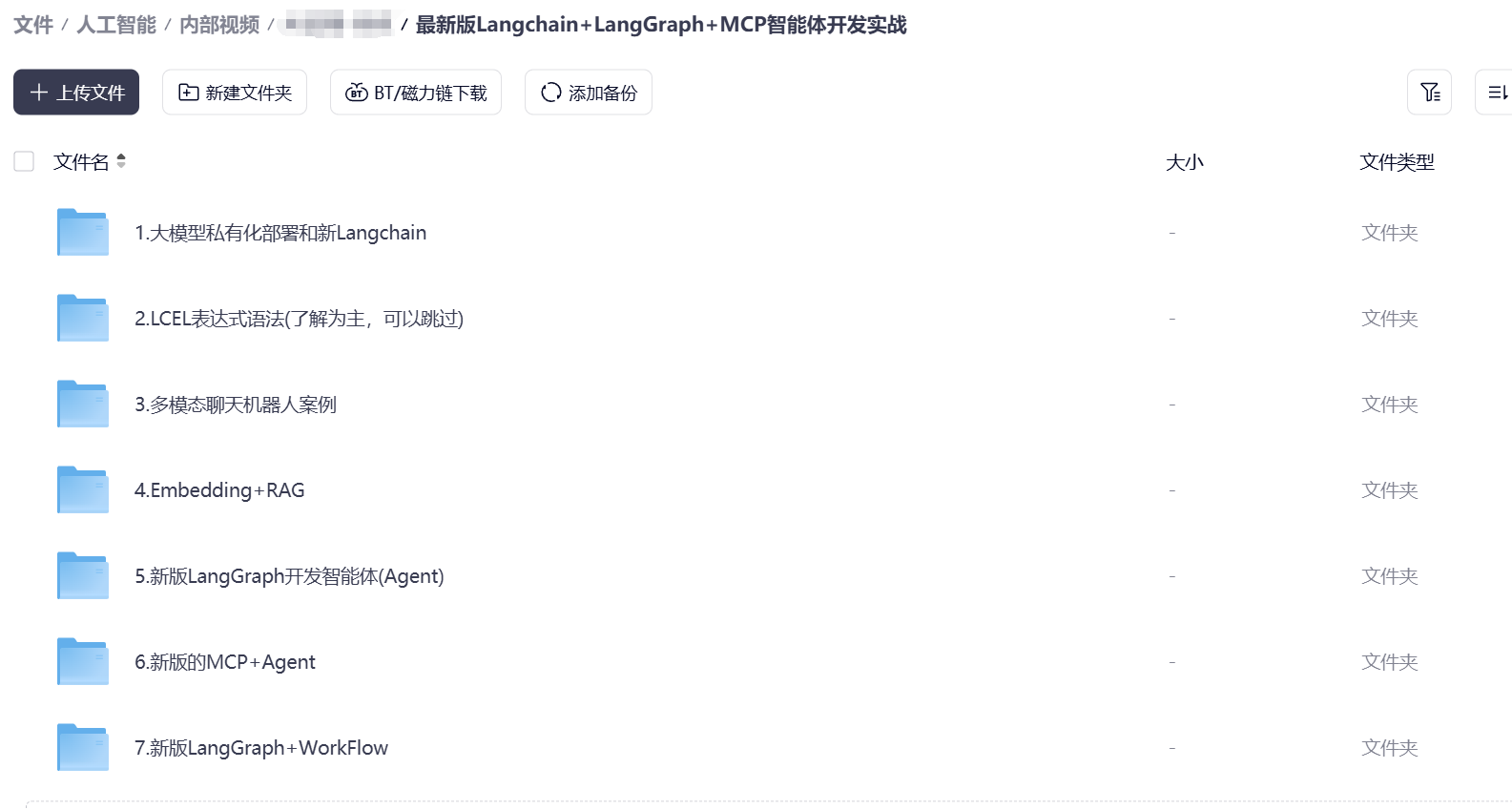
如果你想看完整资料目录,可以在评论区留言「资料」;也欢迎告诉我你更关注AI大模型里的哪类内容。
