学习内容:
了解为什么使用 Kafka
关于大数据和消息系统的常见误区
帮助推动消息传递、流媒体和物联网数据处理的实时事件用例
Kafka是什么?
Kafka 定义为一个分布式流媒体平台,它主要有三个功能
-
像消息队列一样读取和写入记录
-
以容错方式存储记录
-
处理实时发生的流
官方网址为:https://kafka.apache.org/intro/
Kafka 的消息传递至少可以采用以下三种交互方式
-
至少发送一次语义消息,根据需要持续发送,直到被确认
-
至多一次语义消息仅发送一次,并在故障发送时不会重发
-
一次性语义消息仅被消费者看到一次
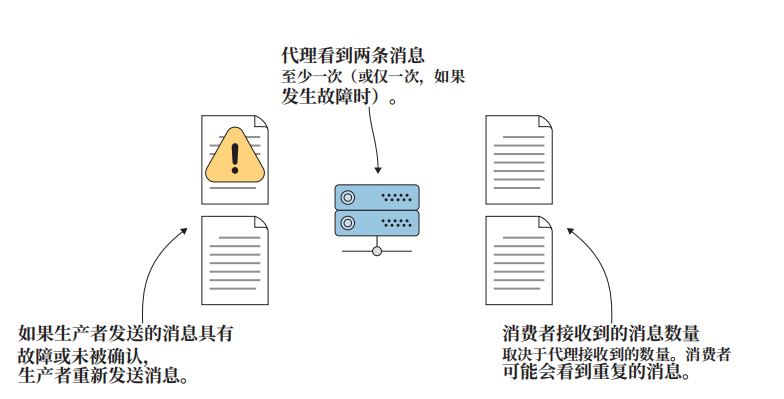
至少一次语义,在这种情况下,可以将Kafka配置为允许消息生产者多次发送相同的消息,并确保消息写入代理。如果消息未收到确认已写入代理,生产者可以重新发送消息。对于那些不可错过的消息,例如有人支付了发票,这种保证可以在消费者端进行一些过滤,但这是安全传递方式之一
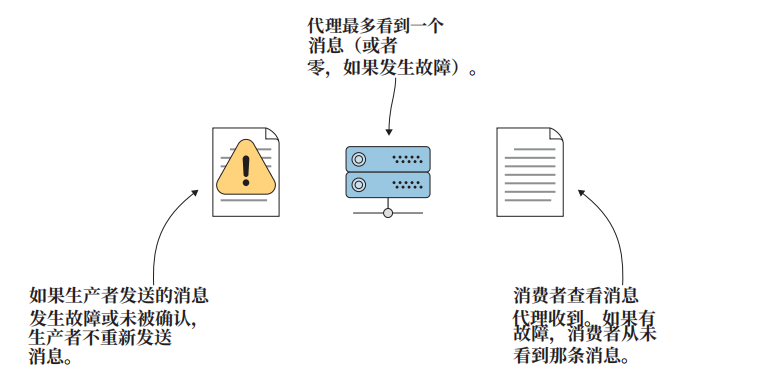
至多一次语义是指消息生产者可能只发送一次消息,不会重试。发生故障时,生产者会继续推进,而不是尝试重新发送该消息。
为什么有人会对丢失一条消息感到无所谓?例如,网站在跟踪访客页面浏览量时,可能会认为在处理数百万个页面浏览事件中丢失几个消息是可以接受的。保持系统高效运行,而不是等待确认,可能会带来超时丢失数据的成本
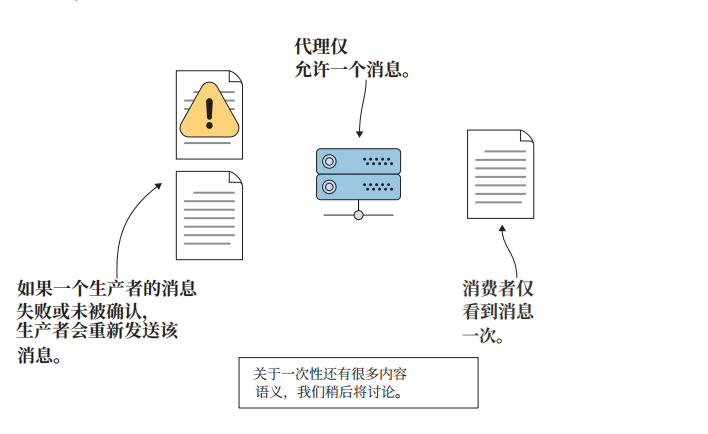
准确的一次性语义在很多用例中是理想的,这似乎是一个合理的保证,可以消除重复消息,让重复消息成为过去式。但是,大多数开发者都希望在消费端发送一条消息,并接收同样的消息
Kafka使用
我们以一个 HR 系统为例。员工可以在系统中提交带薪假期申请;如果你习惯用 CRUD 系统来理解,假期申请的提交不仅会由薪资部门处理,还可能用于项目计划,以预测工作进展。
你会把这两个应用联系在一起吗?如果薪资系统出现故障,会影响预测工具的可用性吗?
而使用 Kafka 可以将一些旧设计中紧密相连的应用程序分离开来,让您的数据接口变成 Kafka,而不是众多的 API 和数据库
总结
-
Apache Kafka 是流式处理平台,可高速海量事件处理。
-
可作为消息总线,但该用法仅为其能力子集,原生具备完整实时数据处理能力。
-
独立大数据中间件,依托分布式、容错架构实现高扩展、高持久化集群,适配现代数据基础设施底座需求。
-
适配物联网等高吞吐流式场景,可将传统离线批处理业务转为实时计算,低延迟输出数据处理结果。