堆与优先级的艺术:从急诊分诊到Top-K,手写一个PriorityQueue
1. 面试真题引入
场景还原:某大厂二面现场。
面试官:给你 10 亿条搜索日志,找出搜索次数最多的前 100 个关键词,你会怎么做?
候选人:先统计频率,然后排序取前 100。
面试官:10 亿条数据全排序?内存和时间撑得住吗?
候选人 A:额......建大顶堆,每次弹出堆顶?
面试官:你建大顶堆需要 O(n) 建堆 + O(k log n) 弹出,n=10 亿时建堆本身就很昂贵。再想想,有没有更优雅的方案?
如果你也犹豫了,这篇文章就是为你准备的。Top-K 问题是面试中的超高频考点,其最优解"小顶堆 + 门槛淘汰"是检验你是否真正理解堆的一把标尺。我们从底层源码出发,一步步揭开堆的面纱。
2. 底层时空解构:二叉堆的源码级透视
2.1 堆是什么?------数组里藏着一棵树
堆(Heap)是一种完全二叉树 ,同时满足堆序性质:
- 小顶堆(Min-Heap):任意节点 ≤ 其子节点。根是最小值。
- 大顶堆(Max-Heap):任意节点 ≥ 其子节点。根是最大值。
关键创新在于数组存储 。对于索引 i 的节点:
| 关系 | 公式 |
|---|---|
| 父节点索引 | (i - 1) / 2 |
| 左子节点索引 | 2 * i + 1 |
| 右子节点索引 | 2 * i + 2 |
一棵树不用指针,靠下标计算就能完成父子定位------这就是堆的高效根源。
下面是一棵小顶堆在数组和树形两个视角下的对照:
数组视角:[2, 5, 8, 12, 9, 10, 15]
索引: 0 1 2 3 4 5 6
树形视角:
2
/ \
5 8
/ \ / \
12 9 10 15
验证:节点 5(索引 1)→ 左子 = 2×1+1=3 ✓(值为12),父 = (1-1)/2=0 ✓(值为2)类比:这就像学校体测排队------最矮的同学站在排头(根节点=堆顶=最值),后面的人层层递增。后面会详细展开这个类比。
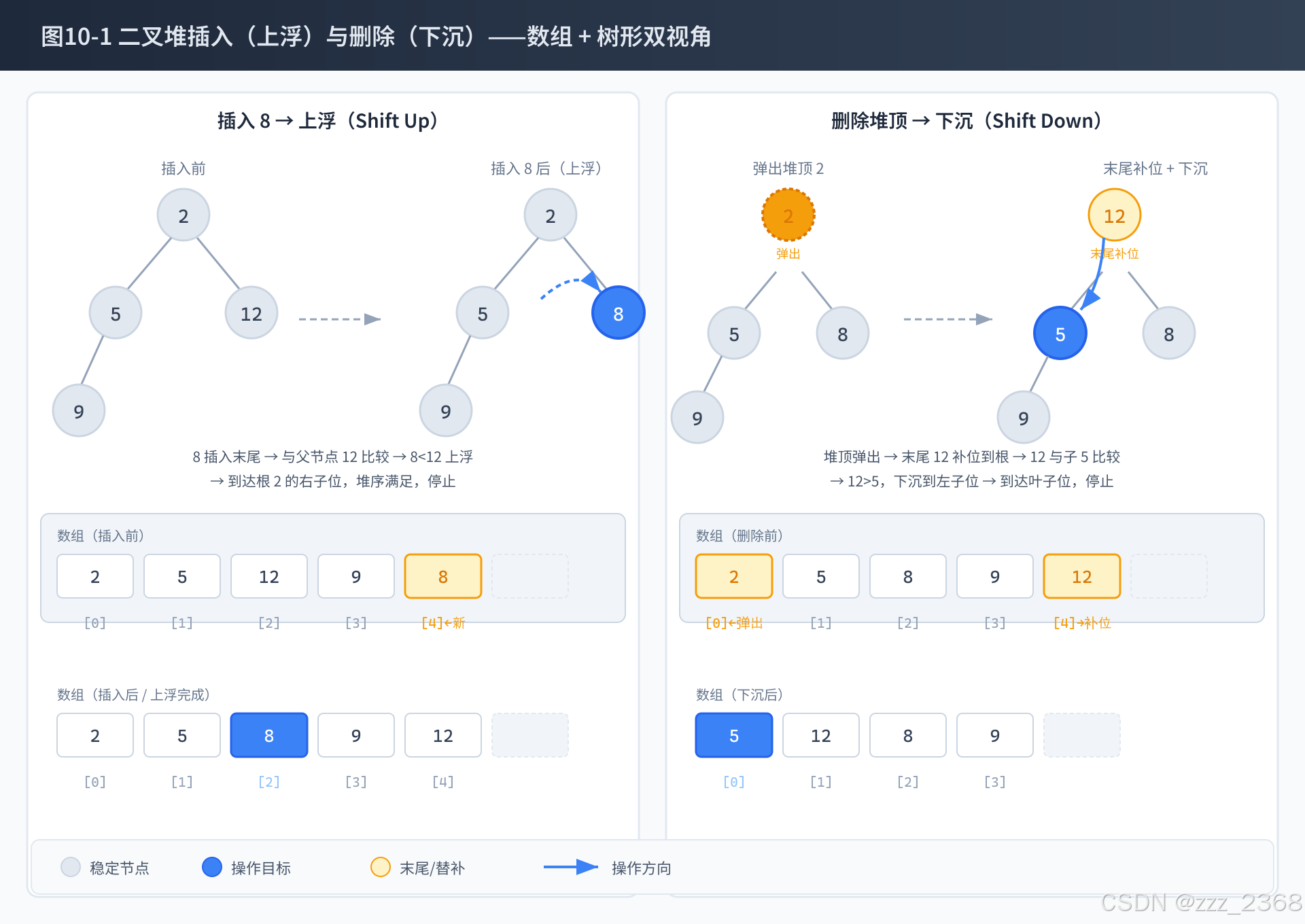
2.2 上浮与下沉:堆的核心操作
堆的所有操作都围绕两个原子动作展开。下面我们手写一份不依赖 JDK 任何类的纯手工二叉堆实现,彻底理解底层逻辑。
java
/**
* 手写小顶堆------零依赖,只有数组和两个核心操作
* 泛型 T 必须实现 Comparable,表示元素本身携带比较能力
*/
public class MinHeap<T extends Comparable<T>> {
private Object[] data; // 底层数组存储
private int size; // 当前元素个数
public MinHeap(int capacity) {
this.data = new Object[capacity];
this.size = 0;
}
// ==================== 下沉(Shift Down) ====================
/**
* 从上往下调整:当堆顶被替换为较大值时,
* 把它逐步"沉"到满足堆序的位置
*
* @param k 需要下沉的起始索引
*/
@SuppressWarnings("unchecked")
private void shiftDown(int k) {
T current = (T) data[k]; // 暂存当前元素
int half = size >>> 1; // 非叶子节点边界:size/2
while (k < half) { // 只对非叶子节点下沉
int child = (k << 1) + 1; // 左子索引:2*k+1
int right = child + 1; // 右子索引
// 选左右孩子中较小的那个
if (right < size
&& ((T) data[child]).compareTo((T) data[right]) > 0) {
child = right;
}
// 如果当前元素已经 ≤ 最小孩子,堆序满足,停止
if (current.compareTo((T) data[child]) <= 0) {
break;
}
// 否则最小孩子上移,k 下潜到孩子位置继续比较
data[k] = data[child];
k = child;
}
data[k] = current; // 放入最终位置
}
// ==================== 上浮(Shift Up) ====================
/**
* 从下往上调整:当新插入元素很小时,
* 把它逐步"浮"到满足堆序的位置
*
* @param k 需要上浮的起始索引(通常为新插入元素的索引)
*/
@SuppressWarnings("unchecked")
private void shiftUp(int k) {
T current = (T) data[k]; // 暂存新元素
while (k > 0) {
int parent = (k - 1) >>> 1; // 父节点索引:(k-1)/2
// 如果新元素 ≥ 父节点,堆序满足,停止
if (current.compareTo((T) data[parent]) >= 0) {
break;
}
// 否则父节点下移,k 上浮到父节点位置继续比较
data[k] = data[parent];
k = parent;
}
data[k] = current; // 放入最终位置
}
// ==================== 插入 ====================
public void offer(T element) {
if (size == data.length) {
throw new IllegalStateException("堆已满");
}
// 放入末尾,然后上浮
data[size] = element;
shiftUp(size);
size++;
}
// ==================== 删除堆顶 ====================
@SuppressWarnings("unchecked")
public T poll() {
if (size == 0) {
return null;
}
T result = (T) data[0]; // 保存堆顶
// 末尾元素补到堆顶,然后下沉
data[0] = data[size - 1];
data[size - 1] = null; // 帮助 GC
size--;
if (size > 0) {
shiftDown(0);
}
return result;
}
// ==================== 查看堆顶 ====================
@SuppressWarnings("unchecked")
public T peek() {
return size == 0 ? null : (T) data[0];
}
public int size() { return size; }
}图解视角还原------配合图 10-1 理解两个操作的动态过程:
2.3 JDK PriorityQueue 底层源码解读
了解了手写实现,再看 JDK 源码就一目了然。PriorityQueue 的核心成员:
java
public class PriorityQueue<E> extends AbstractQueue<E> {
transient Object[] queue; // 底层数组
int size; // 元素个数
private final Comparator<? super E> comparator; // 自定义比较器
// 默认构造------使用自然顺序,即小顶堆
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
}JDK 的实现和我们手写的版本惊人一致:
| 操作 | JDK 方法 | 核心逻辑 |
|---|---|---|
| 插入 | siftUp(int k, E x) |
从索引 k 开始,逐层与父节点比较上浮 |
| 删除堆顶 | siftDown(int k, E x) |
从索引 k 开始,逐层与较小子节点比较下沉 |
| 建堆 | heapify() |
从 size/2 往前,对每个非叶子节点执行下沉 |
三个关键设计细节值得注意:
- 默认小顶堆 :不传
Comparator时,元素按自然顺序排列,堆顶是最小值。这与很多人"堆顶应该是最大"的直觉相反。 - 动态扩容 :
grow()方法中,小容量时翻倍(oldCapacity < 64),大容量时增长 50%,无需手动管理容量。 - 无界队列 :
PriorityQueue理论上可以无限插入,不受初始容量限制(会自动扩容),这一点与ArrayBlockingQueue不同。
3. 原创工程案例:从代码到现实
案例一:医院急诊智能分诊系统
急诊室的核心规则:病情越严重,越优先处理。这正是小顶堆(优先级数值越小越优先)的用武之地。
java
/**
* 急诊患者------携带病情等级与到达时间
*/
class Patient implements Comparable<Patient> {
String name;
int severity; // 1=红区(危重)2=黄区(紧急)3=绿区(普通)
long arriveTime; // 到达时间戳,同等级下先到先处理
Patient(String name, int severity) {
this.name = name;
this.severity = severity;
this.arriveTime = System.currentTimeMillis();
}
@Override
public int compareTo(Patient other) {
// 先按病情(数越小越紧急),再按到达时间
if (this.severity != other.severity) {
return Integer.compare(this.severity, other.severity);
}
return Long.compare(this.arriveTime, other.arriveTime);
}
}
/**
* 急诊分诊调度中心
*/
public class EmergencyTriage {
private PriorityQueue<Patient> queue = new PriorityQueue<>();
// 新患者到达
public void arrive(Patient p) {
queue.offer(p);
System.out.printf("[入诊] %s(%d级)已加入等待队列,当前排队人数:%d\n",
p.name, p.severity, queue.size());
}
// 叫号下一个患者
public Patient callNext() {
Patient next = queue.poll();
if (next != null) {
System.out.printf("[叫号] %s(%d级)请到诊室就诊\n",
next.name, next.severity);
}
return next;
}
// 测试
public static void main(String[] args) {
EmergencyTriage triage = new EmergencyTriage();
// 模拟患者陆续到达
triage.arrive(new Patient("小王", 3)); // 绿区,普通
triage.arrive(new Patient("老李", 1)); // 红区,危重!
triage.arrive(new Patient("小张", 2)); // 黄区,紧急
triage.arrive(new Patient("老赵", 1)); // 红区,危重!
// 按优先级叫号------危重患者先看病
System.out.println("\n===== 开始叫号 =====");
Patient next;
while ((next = triage.callNext()) != null) {
// 持续叫号直到队列为空
}
}
}运行结果:
[入诊] 小王(3级)已加入等待队列,当前排队人数:1
[入诊] 老李(1级)已加入等待队列,当前排队人数:2
[入诊] 小张(2级)已加入等待队列,当前排队人数:3
[入诊] 老赵(1级)已加入等待队列,当前排队人数:4
===== 开始叫号 =====
[叫号] 老李(1级)请到诊室就诊 ← 先到先得?不是,危重优先!
[叫号] 老赵(1级)请到诊室就诊 ← 同为红区,按到达时间排序
[叫号] 小张(2级)请到诊室就诊
[叫号] 小王(3级)请到诊室就诊compareTo 中先比 severity 再比 arriveTime 的设计保证了:病情第一、时间第二------这正是堆排序规则在现实场景中的直观映射。
案例二:热搜排行榜 Top-10 实时维护
每条热搜词条有实时热度值。我们用一个固定容量为 10 的小顶堆持续维护当前 Top-10------堆顶就是第 10 名的热度门槛。
java
/**
* 实时热搜 Top-10 维护系统
*/
public class HotSearchTopK {
// 小顶堆维护 Top-10:堆顶是门槛(当前第10名)
private PriorityQueue<Entry> topK;
private int k;
static class Entry implements Comparable<Entry> {
String keyword;
int heat; // 热度值
Entry(String keyword, int heat) {
this.keyword = keyword;
this.heat = heat;
}
@Override
public int compareTo(Entry other) {
return Integer.compare(this.heat, other.heat); // 小顶堆
}
@Override
public String toString() {
return String.format("%s(%d)", keyword, heat);
}
}
public HotSearchTopK(int k) {
this.k = k;
this.topK = new PriorityQueue<>(k);
}
// 新词条进入------和堆顶门槛比较
public void add(Entry e) {
if (topK.size() < k) {
// 还没满,直接进堆
topK.offer(e);
} else if (e.heat > topK.peek().heat) {
// 比门槛高:淘汰门槛,新词入堆
Entry eliminated = topK.poll();
topK.offer(e);
System.out.printf("[替换] %s 淘汰,%s 入榜\n", eliminated, e);
} else {
// 不达门槛,直接淘汰
System.out.printf("[淘汰] %s 热度不够,被拒之门外\n", e);
}
}
// 输出当前 Top-K(按热度降序)
public void printTopK() {
// 复制到列表排序后输出(不影响原堆结构)
List<Entry> sorted = new ArrayList<>(topK);
sorted.sort((a, b) -> Integer.compare(b.heat, a.heat));
System.out.println("\n===== 当前热搜 Top-" + k + " =====");
for (int i = 0; i < sorted.size(); i++) {
System.out.printf(" #%d %s\n", i + 1, sorted.get(i));
}
}
public static void main(String[] args) {
HotSearchTopK hotSearch = new HotSearchTopK(3); // 示范 Top-3
hotSearch.add(new Entry("高考成绩", 980));
hotSearch.add(new Entry("梅西退役", 860));
hotSearch.add(new Entry("新手机发布", 720));
// 热度 820,大于堆顶 720(门槛),替换入榜
hotSearch.add(new Entry("暴雨预警", 820));
// 热度 500,小于堆顶 820(新门槛),直接淘汰
hotSearch.add(new Entry("谁谁恋情", 500));
hotSearch.printTopK();
}
}运行结果:
[替换] 新手机发布(720) 淘汰,暴雨预警(820) 入榜
[淘汰] 谁谁恋情(500) 热度不够,被拒之门外
===== 当前热搜 Top-3 =====
#1 高考成绩(980)
#2 梅西退役(860)
#3 暴雨预警(820)效率分析:每次插入/淘汰只需 O(log K),K=10 时几乎可视为常数操作。如果暴力全排序,每次都是 O(n log n)。
4. 避坑指南:从 C/Python 转 Java 最容易踩的三个坑
坑1:PriorityQueue 默认是小顶堆
这是 C++ 程序员转 Java 最频繁的"工伤事故"。C++ 的 std::priority_queue 默认是大顶堆:
cpp
// C++:默认大顶堆,top() 返回最大值
priority_queue<int> pq; // 大顶堆!而 Java 是小顶堆:
java
// Java:默认小顶堆,peek() 返回最小值
PriorityQueue<Integer> pq = new PriorityQueue<>(); // 小顶堆!记忆技巧 :Java 的 PriorityQueue 配合 Comparable 使用------a.compareTo(b) < 0 表示 a 排在前面,所以"小的排前面"→ 小顶堆。
坑2:把堆当成排序数组来遍历
PriorityQueue 的 toString() 或 toArray() 不保证有序 。只有 peek() 和 poll() 返回的元素才保证堆序:
java
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.offer(5); pq.offer(1); pq.offer(3);
System.out.println(pq); // [1, 5, 3] ← 这不是排序结果!
System.out.println(pq.peek()); // 1 ← 堆顶确实是最小的堆只需保证父子间的偏序关系,兄弟节点之间没有顺序约束。
坑3:想让自定义类进堆,忘写 compareTo
PriorityQueue 需要知道怎么比较元素。如果自定义类没有实现 Comparable,也不传 Comparator,运行时直接抛 ClassCastException:
java
class Task { int priority; } // 没实现 Comparable
PriorityQueue<Task> pq = new PriorityQueue<>();
pq.offer(new Task()); // ❌ ClassCastException!解法 :要么 implements Comparable<Task>,要么构造时传 Comparator。
5. 面试连环炮:Top-K 题花式追问
面试最容易从这里发起连续追问,下面是两道必答题及高分话术。
第一炮:前K大,建大顶堆还是小顶堆?
面试官:求海量数据中前 K 个最大的数,应该建什么堆?为什么?
高分话术:
应该建小顶堆,大小只维护 K。堆顶永远存着当前 Top-K 中最小的那个值------它就是"门槛"。新元素和堆顶比较:大于门槛才能入堆(替换掉旧门槛),小于等于门槛直接丢弃。
时间复杂度 O(n log K),空间复杂度 O(K)。对比全排序 O(n log n),当 K 远小于 n 时优势巨大------比如 10 亿数据取 Top-100,K=100 时 logK 只有约 7,几乎可视为线性。
反过来,求前 K 小的数 就建大顶堆 ,堆顶是当前 K 个中最"大"的门槛。口诀:求大用小,求小用大------求前K大时用小顶堆淘汰小的,求前K小时用大顶堆淘汰大的。
第二炮:堆排序 O(n log n) 很稳定,为什么工程中更常用快排?
面试官:堆排序理论上 O(n log n) 很稳定,但为什么实际工程里更常用快速排序?
高分话术:
核心原因在于 CPU 缓存不友好。快速排序对数组是连续访问(分区时左右指针逐步移动),数据局部性极好,缓存命中率高。
堆排序在 shiftDown 过程中,每次比较都需要跳转到
2*i+1的子节点位置------这是跳跃式访问,破坏了空间局部性,导致大量缓存未命中。同时,快排的常数因子更小------交换操作集中在数组局部区域,而堆排序每次交换跨越距离大。综合下来,快排在实际工程中的平均表现优于堆排序。
不过堆排序有它的不可替代性:它能高效找出第 K 大/小的值,且空间复杂度严格 O(1)------不需要递归栈空间。
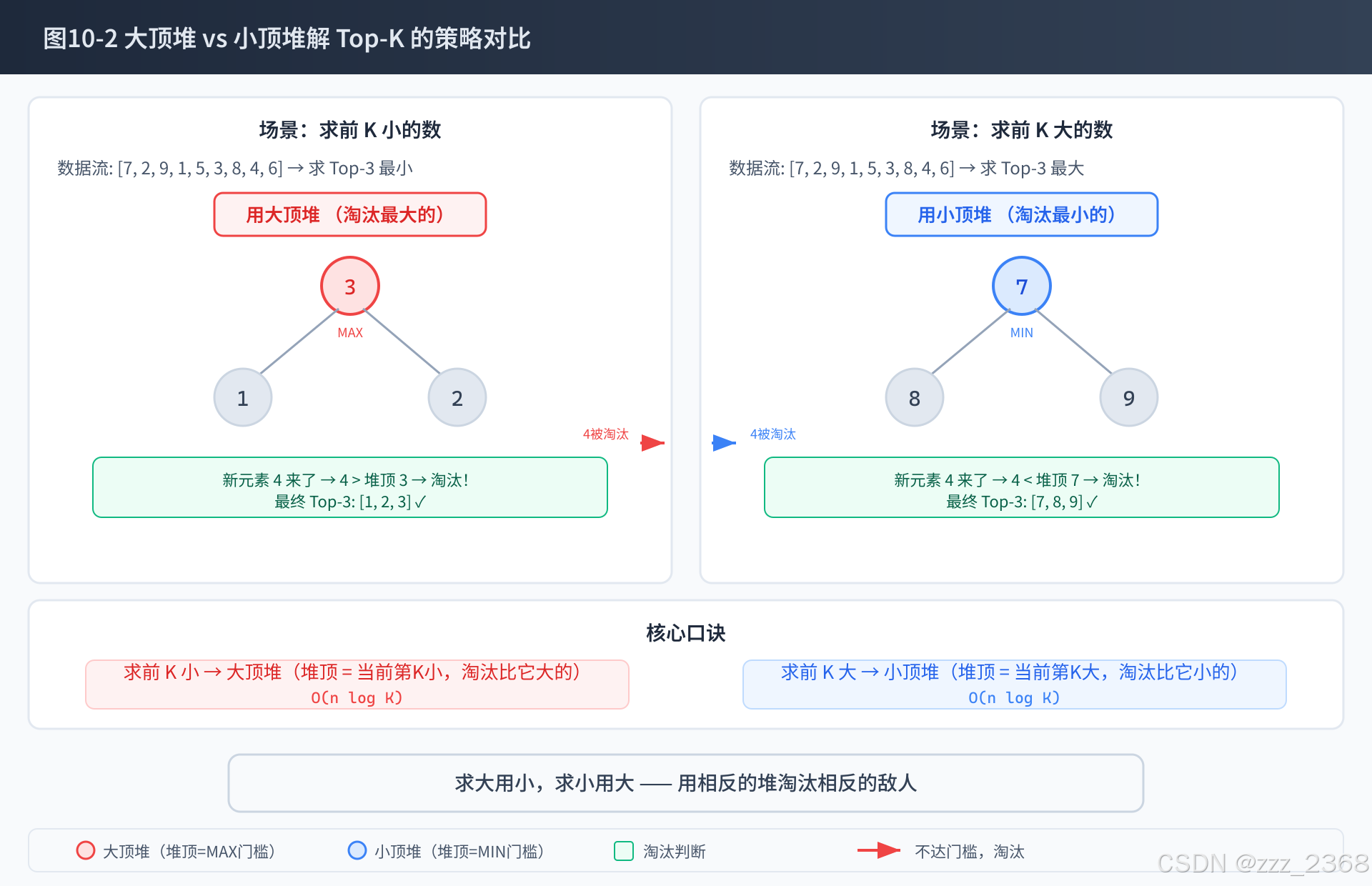
6. 通俗类比
把"堆"比作学校体测排队:
- 最矮的站在排头 → 小顶堆(堆顶=最小值=门槛)
- 新来的同学和排头比身高 → 新元素和堆顶比大小
- 比排头还矮 → 换人(进入堆)。比排头高 → 站队尾去(被淘汰)
- 排头就是"第 1 矮",换成 Top-K 就是"第 K 大/小"的门槛
这个类比的核心洞察是:堆的堆顶不是你想要的最终答案,它只是你用来快速筛选的"门槛"。