- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
使用 Inception v3 网络对天气图像进行四分类识别:cloudy(多云)、rain(雨)、shine(晴)、sunrise(日出)
Inception v3 核心改进
- 将 5×5 卷积分解为两个 3×3 卷积,降低计算量
- 将 n×n 卷积分解为 1×n 和 n×1 卷积(非对称分解)
- 引入辅助分类器,提供额外梯度信息
- 使用 Batch Normalization 加速收敛
- 使用 RMSProp 优化器
1. 环境配置与库导入
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
from PIL import Image
import os
import pathlib
import warnings
from datetime import datetime
warnings.filterwarnings("ignore")
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
# 检查 PyTorch 版本
print(f"PyTorch 版本: {torch.__version__}")
print(f"TorchVision 版本: {torchvision.__version__}")
print(f"CUDA 可用: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"CUDA 版本: {torch.version.cuda}")
print(f"GPU 型号: {torch.cuda.get_device_name(0)}")
PyTorch 版本: 2.8.0+cu128
TorchVision 版本: 0.23.0+cu128
CUDA 可用: True
CUDA 版本: 12.8
GPU 型号: NVIDIA GeForce RTX 3080 Ti2. 设置 GPU / CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
使用设备: cuda3. 数据准备
3.1 识别数据路径
# 查看当前工作路径
print("当前工作路径:", os.getcwd())
# 定义数据目录
data_dir = pathlib.Path('./data/J7-data/')
# 获取类别名称
data_paths = list(data_dir.glob('*'))
classeNames = [path.name for path in data_paths]
print(f"类别数量: {len(classeNames)}")
print(f"类别名称: {classeNames}")
当前工作路径: /root/autodl-tmp/CNN
类别数量: 4
类别名称: ['cloudy', 'rain', 'shine', 'sunrise']3.2 查看示例图片
# 指定图像文件夹路径,查看第一个类别的图片
image_folder = str(data_dir / classeNames[0]) + '/'
# 获取文件夹中的所有图像文件
image_files = [f for f in os.listdir(image_folder) if f.endswith((".jpg", ".png", ".jpeg"))]
# 创建 Matplotlib 图像
fig, axes = plt.subplots(3, 8, figsize=(12, 5))
fig.suptitle(f'type: {classeNames[0]}, sum: {len(image_files)}', fontsize=14)
# 使用列表推导式加载和显示图像
for ax, img_file in zip(axes.flat, image_files[:24]):
img_path = os.path.join(image_folder, img_file)
img = Image.open(img_path)
ax.imshow(img)
ax.axis('off')
plt.tight_layout()
plt.show()
3.3 图像预处理
Inception v3 要求输入尺寸为 299×299(而非常见的 224×224),并且使用 ImageNet 的均值和标准差进行归一化。
total_datadir = './data/J7-data/'
# Inception v3 使用 299x299 输入尺寸
train_transforms = transforms.Compose([
transforms.RandomResizedCrop(299, scale=(0.8, 1.0)), # 随机裁剪到 299x299
transforms.RandomHorizontalFlip(p=0.5), # 50%概率水平翻转
transforms.ColorJitter(brightness=0.2, contrast=0.2), # 调整亮度/对比度
transforms.ToTensor(), # 转为 Tensor 并归一化到 [0,1]
transforms.Normalize( # ImageNet 标准化
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# 测试集不使用数据增强
test_transforms = transforms.Compose([
transforms.Resize([299, 299]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# 加载全部数据(训练集使用增强,后续再做 split)
total_data = datasets.ImageFolder(total_datadir, transform=train_transforms)
print(f"数据集总样本数: {len(total_data)}")
print(f"类别映射: {total_data.class_to_idx}")
数据集总样本数: 1125
类别映射: {'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3}3.4 划分训练集与测试集
# 80% 训练,20% 测试
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(f"训练集大小: {len(train_dataset)}")
print(f"测试集大小: {len(test_dataset)}")
# 测试集的 DataLoader 使用 test_transforms
# 注意:random_split 后整个数据集共享 transform,实际使用时建议分开设置
# 这里为了简洁,测试集也用训练增强(实际仅 eval 模式无 flip 影响)
batch_size = 32
train_dl = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True
)
test_dl = torch.utils.data.DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=True
)
# 查看一个 batch 的形状
for X, y in train_dl:
print(f"输入形状 [N, C, H, W]: {X.shape}")
print(f"标签形状: {y.shape}, 数据类型: {y.dtype}")
break
训练集大小: 900
测试集大小: 225
输入形状 [N, C, H, W]: torch.Size([32, 3, 299, 299])
标签形状: torch.Size([32]), 数据类型: torch.int644. 搭建 Inception v3 网络模型
以下从零实现 Inception v3 的完整架构,包括:
- BasicConv2d:Conv + BatchNorm + ReLU 基础模块
- InceptionA:标准 Inception 模块(5×5 分解为两个 3×3)
- InceptionB:非对称卷积分解(n×n → 1×n + n×1)
- InceptionC:扩展的非对称分解模块
- ReductionA / ReductionB:网格尺寸缩减模块
- InceptionAux:辅助分类器
-
InceptionV3:完整网络组装
class BasicConv2d(nn.Module):
"""基础卷积模块:Conv2d + BatchNorm2d + ReLU"""
def init(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).init()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)def forward(self, x): x = self.conv(x) x = self.bn(x) return F.relu(x, inplace=True)class InceptionA(nn.Module):
"""Inception 模块 A:将 5×5 卷积分解为两个 3×3 卷积"""
def init(self, in_channels, pool_features):
super(InceptionA, self).init()
# 分支1: 1x1 卷积
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1)# 分支2: 1x1 → 5x5 卷积 self.branch5x5_1 = BasicConv2d(in_channels, 48, kernel_size=1) self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2) # 分支3: 1x1 → 3x3 → 3x3 卷积(5×5 分解为两个 3×3) self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1) self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1) self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, padding=1) # 分支4: 平均池化 → 1x1 卷积 self.branch_pool = BasicConv2d(in_channels, pool_features, kernel_size=1) def forward(self, x): branch1x1 = self.branch1x1(x) branch5x5 = self.branch5x5_1(x) branch5x5 = self.branch5x5_2(branch5x5) branch3x3dbl = self.branch3x3dbl_1(x) branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl) branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl) branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1) branch_pool = self.branch_pool(branch_pool) outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool] return torch.cat(outputs, 1)class InceptionB(nn.Module):
"""Inception 模块 B:使用非对称卷积 1×n 和 n×1 分解"""
def init(self, in_channels, channels_7x7):
super(InceptionB, self).init()
# 分支1: 1x1 卷积
self.branch1x1 = BasicConv2d(in_channels, 192, kernel_size=1)# 分支2: 1x1 → 1x7 → 7x1 卷积 c7 = channels_7x7 self.branch7x7_1 = BasicConv2d(in_channels, c7, kernel_size=1) self.branch7x7_2 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3)) self.branch7x7_3 = BasicConv2d(c7, 192, kernel_size=(7, 1), padding=(3, 0)) # 分支3: 1x1 → 7x1 → 1x7 → 7x1 → 1x7 卷积 self.branch7x7dbl_1 = BasicConv2d(in_channels, c7, kernel_size=1) self.branch7x7dbl_2 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0)) self.branch7x7dbl_3 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3)) self.branch7x7dbl_4 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0)) self.branch7x7dbl_5 = BasicConv2d(c7, 192, kernel_size=(1, 7), padding=(0, 3)) # 分支4: 平均池化 → 1x1 卷积 self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1) def forward(self, x): branch1x1 = self.branch1x1(x) branch7x7 = self.branch7x7_1(x) branch7x7 = self.branch7x7_2(branch7x7) branch7x7 = self.branch7x7_3(branch7x7) branch7x7dbl = self.branch7x7dbl_1(x) branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl) branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl) branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl) branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl) branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1) branch_pool = self.branch_pool(branch_pool) outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool] return torch.cat(outputs, 1)class InceptionC(nn.Module):
"""Inception 模块 C:扩展的非对称分解,分支内并行 1×3 和 3×1"""
def init(self, in_channels):
super(InceptionC, self).init()
# 分支1: 1x1 卷积
self.branch1x1 = BasicConv2d(in_channels, 320, kernel_size=1)# 分支2: 1x1 → 1x3 和 3x1 并行 self.branch3x3_1 = BasicConv2d(in_channels, 384, kernel_size=1) self.branch3x3_2a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1)) self.branch3x3_2b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0)) # 分支3: 1x1 → 3x3 → 1x3 和 3x1 并行 self.branch3x3dbl_1 = BasicConv2d(in_channels, 448, kernel_size=1) self.branch3x3dbl_2 = BasicConv2d(448, 384, kernel_size=3, padding=1) self.branch3x3dbl_3a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1)) self.branch3x3dbl_3b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0)) # 分支4: 平均池化 → 1x1 卷积 self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1) def forward(self, x): branch1x1 = self.branch1x1(x) branch3x3 = self.branch3x3_1(x) branch3x3 = [ self.branch3x3_2a(branch3x3), self.branch3x3_2b(branch3x3), ] branch3x3 = torch.cat(branch3x3, 1) branch3x3dbl = self.branch3x3dbl_1(x) branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl) branch3x3dbl = [ self.branch3x3dbl_3a(branch3x3dbl), self.branch3x3dbl_3b(branch3x3dbl), ] branch3x3dbl = torch.cat(branch3x3dbl, 1) branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1) branch_pool = self.branch_pool(branch_pool) outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool] return torch.cat(outputs, 1)class ReductionA(nn.Module):
"""降维模块 A:将 35×35 网格缩减为 17×17"""
def init(self, in_channels):
super(ReductionA, self).init()
# 分支1: 3x3 卷积 stride=2
self.branch3x3 = BasicConv2d(in_channels, 384, kernel_size=3, stride=2)# 分支2: 1x1 → 3x3 → 3x3 stride=2 self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1) self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1) self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, stride=2) def forward(self, x): branch3x3 = self.branch3x3(x) branch3x3dbl = self.branch3x3dbl_1(x) branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl) branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl) branch_pool = F.max_pool2d(x, kernel_size=3, stride=2) outputs = [branch3x3, branch3x3dbl, branch_pool] return torch.cat(outputs, 1)class ReductionB(nn.Module):
"""降维模块 B:将 17×17 网格缩减为 8×8"""
def init(self, in_channels):
super(ReductionB, self).init()
# 分支1: 1x1 → 3x3 stride=2
self.branch3x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch3x3_2 = BasicConv2d(192, 320, kernel_size=3, stride=2)# 分支2: 1x1 → 1x7 → 7x1 → 3x3 stride=2 self.branch7x7x3_1 = BasicConv2d(in_channels, 192, kernel_size=1) self.branch7x7x3_2 = BasicConv2d(192, 192, kernel_size=(1, 7), padding=(0, 3)) self.branch7x7x3_3 = BasicConv2d(192, 192, kernel_size=(7, 1), padding=(3, 0)) self.branch7x7x3_4 = BasicConv2d(192, 192, kernel_size=3, stride=2) def forward(self, x): branch3x3 = self.branch3x3_1(x) branch3x3 = self.branch3x3_2(branch3x3) branch7x7x3 = self.branch7x7x3_1(x) branch7x7x3 = self.branch7x7x3_2(branch7x7x3) branch7x7x3 = self.branch7x7x3_3(branch7x7x3) branch7x7x3 = self.branch7x7x3_4(branch7x7x3) branch_pool = F.max_pool2d(x, kernel_size=3, stride=2) outputs = [branch3x3, branch7x7x3, branch_pool] return torch.cat(outputs, 1)class InceptionAux(nn.Module):
"""辅助分类器:在训练时提供额外的梯度信号"""
def init(self, in_channels, num_classes):
super(InceptionAux, self).init()
self.conv0 = BasicConv2d(in_channels, 128, kernel_size=1)
self.conv1 = BasicConv2d(128, 768, kernel_size=5)
self.conv1.stddev = 0.01
self.fc = nn.Linear(768, num_classes)
self.fc.stddev = 0.001def forward(self, x): # 输入: 17 x 17 x 768 x = F.avg_pool2d(x, kernel_size=5, stride=3) # 输出: 5 x 5 x 768 x = self.conv0(x) # 输出: 5 x 5 x 128 x = self.conv1(x) # 输出: 1 x 1 x 768 x = x.view(x.size(0), -1) # 768 x = self.fc(x) # num_classes return xclass InceptionV3(nn.Module):
"""Inception v3 完整网络"""
def init(self, num_classes=1000, aux_logits=True, transform_input=False):
super(InceptionV3, self).init()
self.aux_logits = aux_logits
self.transform_input = transform_input# ========== Stem 部分 ========== # 输入: 299 x 299 x 3 self.Conv2d_1a_3x3 = BasicConv2d(3, 32, kernel_size=3, stride=2) # 输出: 149 x 149 x 32 self.Conv2d_2a_3x3 = BasicConv2d(32, 32, kernel_size=3) # 输出: 147 x 147 x 32 self.Conv2d_2b_3x3 = BasicConv2d(32, 64, kernel_size=3, padding=1) # 输出: 147 x 147 x 64 # MaxPool: 73 x 73 x 64 self.Conv2d_3b_1x1 = BasicConv2d(64, 80, kernel_size=1) # 输出: 73 x 73 x 80 self.Conv2d_4a_3x3 = BasicConv2d(80, 192, kernel_size=3) # 输出: 71 x 71 x 192 # MaxPool: 35 x 35 x 192 # ========== Inception 模块组 ========== self.Mixed_5b = InceptionA(192, pool_features=32) # 输出: 35 x 35 x 256 self.Mixed_5c = InceptionA(256, pool_features=64) # 输出: 35 x 35 x 288 self.Mixed_5d = InceptionA(288, pool_features=64) # 输出: 35 x 35 x 288 # ========== 降维 A ========== self.Mixed_6a = ReductionA(288) # 输出: 17 x 17 x 768 self.Mixed_6b = InceptionB(768, channels_7x7=128) # 输出: 17 x 17 x 768 self.Mixed_6c = InceptionB(768, channels_7x7=160) # 输出: 17 x 17 x 768 self.Mixed_6d = InceptionB(768, channels_7x7=160) # 输出: 17 x 17 x 768 self.Mixed_6e = InceptionB(768, channels_7x7=192) # 输出: 17 x 17 x 768 # ========== 辅助分类器 ========== if aux_logits: self.AuxLogits = InceptionAux(768, num_classes) # ========== 降维 B ========== self.Mixed_7a = ReductionB(768) # 输出: 8 x 8 x 1280 self.Mixed_7b = InceptionC(1280) # 输出: 8 x 8 x 2048 self.Mixed_7c = InceptionC(2048) # 输出: 8 x 8 x 2048 # ========== 分类器 ========== self.fc = nn.Linear(2048, num_classes) def forward(self, x): if self.transform_input: x = x.clone() x[:, 0] = x[:, 0] * (0.229 / 0.5) + (0.485 - 0.5) / 0.5 x[:, 1] = x[:, 1] * (0.224 / 0.5) + (0.456 - 0.5) / 0.5 x[:, 2] = x[:, 2] * (0.225 / 0.5) + (0.406 - 0.5) / 0.5 # Stem x = self.Conv2d_1a_3x3(x) x = self.Conv2d_2a_3x3(x) x = self.Conv2d_2b_3x3(x) x = F.max_pool2d(x, kernel_size=3, stride=2) x = self.Conv2d_3b_1x1(x) x = self.Conv2d_4a_3x3(x) x = F.max_pool2d(x, kernel_size=3, stride=2) # Inception A 组 x = self.Mixed_5b(x) x = self.Mixed_5c(x) x = self.Mixed_5d(x) # 降维 A x = self.Mixed_6a(x) # Inception B 组 x = self.Mixed_6b(x) x = self.Mixed_6c(x) x = self.Mixed_6d(x) x = self.Mixed_6e(x) # 辅助分类器 if self.training and self.aux_logits: aux = self.AuxLogits(x) # 降维 B x = self.Mixed_7a(x) # Inception C 组 x = self.Mixed_7b(x) x = self.Mixed_7c(x) # 全局平均池化 + Dropout + 全连接 x = F.avg_pool2d(x, kernel_size=8) x = F.dropout(x, training=self.training) x = x.view(x.size(0), -1) x = self.fc(x) if self.training and self.aux_logits: return x, aux return x
4.1 实例化模型并查看结构
# 创建 Inception v3 模型,4 分类,启用辅助分类器
model = InceptionV3(num_classes=4, aux_logits=True).to(device)
print(model)
# 统计模型参数量
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"\n总参数量: {total_params:,}")
print(f"可训练参数量: {trainable_params:,}")
InceptionV3(
(Conv2d_1a_3x3): BasicConv2d(
(conv): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(Conv2d_2a_3x3): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(Conv2d_2b_3x3): BasicConv2d(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(Conv2d_3b_1x1): BasicConv2d(
(conv): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(80, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(Conv2d_4a_3x3): BasicConv2d(
(conv): Conv2d(80, 192, kernel_size=(3, 3), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(Mixed_5b): InceptionA(
(branch1x1): BasicConv2d(
(conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch5x5_1): BasicConv2d(
(conv): Conv2d(192, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch5x5_2): BasicConv2d(
(conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_1): BasicConv2d(
(conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_2): BasicConv2d(
(conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3): BasicConv2d(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_5c): InceptionA(
(branch1x1): BasicConv2d(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch5x5_1): BasicConv2d(
(conv): Conv2d(256, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch5x5_2): BasicConv2d(
(conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_1): BasicConv2d(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_2): BasicConv2d(
(conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3): BasicConv2d(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_5d): InceptionA(
(branch1x1): BasicConv2d(
(conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch5x5_1): BasicConv2d(
(conv): Conv2d(288, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch5x5_2): BasicConv2d(
(conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_1): BasicConv2d(
(conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_2): BasicConv2d(
(conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3): BasicConv2d(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_6a): ReductionA(
(branch3x3): BasicConv2d(
(conv): Conv2d(288, 384, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_1): BasicConv2d(
(conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_2): BasicConv2d(
(conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3): BasicConv2d(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_6b): InceptionB(
(branch1x1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_1): BasicConv2d(
(conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_3): BasicConv2d(
(conv): Conv2d(128, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_1): BasicConv2d(
(conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_3): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_4): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_5): BasicConv2d(
(conv): Conv2d(128, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_6c): InceptionB(
(branch1x1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_1): BasicConv2d(
(conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_2): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_3): BasicConv2d(
(conv): Conv2d(160, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_1): BasicConv2d(
(conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_2): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_3): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_4): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_5): BasicConv2d(
(conv): Conv2d(160, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_6d): InceptionB(
(branch1x1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_1): BasicConv2d(
(conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_2): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_3): BasicConv2d(
(conv): Conv2d(160, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_1): BasicConv2d(
(conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_2): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_3): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_4): BasicConv2d(
(conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_5): BasicConv2d(
(conv): Conv2d(160, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_6e): InceptionB(
(branch1x1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_2): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7_3): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_2): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_3): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_4): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7dbl_5): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(AuxLogits): InceptionAux(
(conv0): BasicConv2d(
(conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(conv1): BasicConv2d(
(conv): Conv2d(128, 768, kernel_size=(5, 5), stride=(1, 1), bias=False)
(bn): BatchNorm2d(768, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(fc): Linear(in_features=768, out_features=4, bias=True)
)
(Mixed_7a): ReductionB(
(branch3x3_1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_2): BasicConv2d(
(conv): Conv2d(192, 320, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7x3_1): BasicConv2d(
(conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7x3_2): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7x3_3): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch7x7x3_4): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_7b): InceptionC(
(branch1x1): BasicConv2d(
(conv): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_1): BasicConv2d(
(conv): Conv2d(1280, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_2a): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_2b): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_1): BasicConv2d(
(conv): Conv2d(1280, 448, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(448, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_2): BasicConv2d(
(conv): Conv2d(448, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3a): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3b): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(1280, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(Mixed_7c): InceptionC(
(branch1x1): BasicConv2d(
(conv): Conv2d(2048, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_1): BasicConv2d(
(conv): Conv2d(2048, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_2a): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3_2b): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_1): BasicConv2d(
(conv): Conv2d(2048, 448, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(448, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_2): BasicConv2d(
(conv): Conv2d(448, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3a): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch3x3dbl_3b): BasicConv2d(
(conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch_pool): BasicConv2d(
(conv): Conv2d(2048, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(fc): Linear(in_features=2048, out_features=4, bias=True)
)
总参数量: 24,354,536
可训练参数量: 24,354,5365. 训练模型
5.1 设置超参数
Inception v3 论文推荐使用 RMSProp 优化器。
# 超参数设置
epochs = 30
learn_rate = 1e-4
batch_size = 32
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 使用 RMSProp 优化器(Inception v3 论文推荐)
opt = torch.optim.RMSprop(model.parameters(), lr=learn_rate, alpha=0.9, eps=1.0, weight_decay=1e-5)
# 学习率调度器:每 8 个 epoch 学习率衰减为原来的 0.96
scheduler = torch.optim.lr_scheduler.StepLR(opt, step_size=8, gamma=0.96)
# 辅助分类器的损失权重
AUX_WEIGHT = 0.35.2 训练函数
Inception v3 在训练时启用了辅助分类器(aux_logits=True),因此模型输出为 (main_output, aux_output),需要分别计算损失并加权求和。
def train(dataloader, model, loss_fn, optimizer):
"""训练函数,支持 Inception v3 辅助分类器"""
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
# 前向传播
output = model(X)
# Inception v3 训练时返回 (main_output, aux_output)
if model.aux_logits:
main_output, aux_output = output
loss_main = loss_fn(main_output, y)
loss_aux = loss_fn(aux_output, y)
# 总损失 = 主分类器损失 + 0.3 * 辅助分类器损失
loss = loss_main + AUX_WEIGHT * loss_aux
# 用主输出计算准确率
pred = main_output
else:
loss = loss_fn(output, y)
pred = output
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test(dataloader, model, loss_fn):
"""测试函数(评估时辅助分类器不启用)"""
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 评估模式:模型只返回主输出
target_pred = model(imgs)
# 注意:eval 模式下 aux_logits 不生效,只返回 main output
if isinstance(target_pred, tuple):
target_pred = target_pred[0]
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss5.3 开始训练
# 初始化记录列表
train_loss = []
train_acc = []
test_loss = []
test_acc = []
# 早停参数
best_test_acc = 0
patience = 10
counter = 0
# 创建模型保存目录
os.makedirs('model', exist_ok=True)
for epoch in range(epochs):
# ===== 训练阶段 =====
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
# ===== 测试阶段 =====
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# 更新学习率
scheduler.step()
# 记录
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 早停判断
if epoch_test_acc > best_test_acc:
best_test_acc = epoch_test_acc
counter = 0
# 保存最优模型和优化器状态
torch.save({
'epoch': epoch + 1,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': opt.state_dict(),
'best_acc': best_test_acc,
}, "model/J7_best_model.pth")
else:
counter += 1
if counter >= patience:
print(f"早停于第 {epoch+1} epoch,最优测试准确率:{best_test_acc*100:.2f}%")
break
# 获取当前学习率
current_lr = scheduler.get_last_lr()[0]
template = ('Epoch:{:2d}, Train_acc:{:.2f}%, Train_loss:{:.3f}, '
'Test_acc:{:.2f}%, Test_loss:{:.3f}, LR:{:.2e}')
print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss,
epoch_test_acc * 100, epoch_test_loss, current_lr))
print('训练完成!')
print(f'最优测试准确率: {best_test_acc*100:.2f}%')
Epoch: 1, Train_acc:25.33%, Train_loss:1.883, Test_acc:29.78%, Test_loss:1.380, LR:1.00e-04
Epoch: 2, Train_acc:29.44%, Train_loss:1.809, Test_acc:32.89%, Test_loss:1.385, LR:1.00e-04
Epoch: 3, Train_acc:38.00%, Train_loss:1.757, Test_acc:36.00%, Test_loss:1.267, LR:1.00e-04
Epoch: 4, Train_acc:39.56%, Train_loss:1.721, Test_acc:49.33%, Test_loss:1.288, LR:1.00e-04
Epoch: 5, Train_acc:40.33%, Train_loss:1.697, Test_acc:51.11%, Test_loss:1.248, LR:1.00e-04
Epoch: 6, Train_acc:41.00%, Train_loss:1.657, Test_acc:56.44%, Test_loss:1.229, LR:1.00e-04
Epoch: 7, Train_acc:49.00%, Train_loss:1.631, Test_acc:56.44%, Test_loss:1.208, LR:1.00e-04
Epoch: 8, Train_acc:49.89%, Train_loss:1.595, Test_acc:55.11%, Test_loss:1.208, LR:9.60e-05
Epoch: 9, Train_acc:51.00%, Train_loss:1.576, Test_acc:58.22%, Test_loss:1.154, LR:9.60e-05
Epoch:10, Train_acc:53.11%, Train_loss:1.540, Test_acc:56.44%, Test_loss:1.135, LR:9.60e-05
Epoch:11, Train_acc:55.00%, Train_loss:1.494, Test_acc:55.56%, Test_loss:1.006, LR:9.60e-05
Epoch:12, Train_acc:56.78%, Train_loss:1.472, Test_acc:56.44%, Test_loss:1.122, LR:9.60e-05
Epoch:13, Train_acc:56.22%, Train_loss:1.443, Test_acc:57.33%, Test_loss:1.032, LR:9.60e-05
Epoch:14, Train_acc:55.56%, Train_loss:1.419, Test_acc:60.89%, Test_loss:1.083, LR:9.60e-05
Epoch:15, Train_acc:58.89%, Train_loss:1.382, Test_acc:60.00%, Test_loss:0.979, LR:9.60e-05
Epoch:16, Train_acc:60.44%, Train_loss:1.368, Test_acc:61.33%, Test_loss:0.899, LR:9.22e-05
Epoch:17, Train_acc:58.89%, Train_loss:1.340, Test_acc:63.11%, Test_loss:1.048, LR:9.22e-05
Epoch:18, Train_acc:61.11%, Train_loss:1.350, Test_acc:64.44%, Test_loss:0.990, LR:9.22e-05
Epoch:19, Train_acc:62.22%, Train_loss:1.308, Test_acc:61.33%, Test_loss:1.008, LR:9.22e-05
Epoch:20, Train_acc:60.78%, Train_loss:1.298, Test_acc:65.78%, Test_loss:0.859, LR:9.22e-05
Epoch:21, Train_acc:62.56%, Train_loss:1.253, Test_acc:66.67%, Test_loss:0.811, LR:9.22e-05
Epoch:22, Train_acc:62.22%, Train_loss:1.234, Test_acc:66.67%, Test_loss:1.016, LR:9.22e-05
Epoch:23, Train_acc:63.67%, Train_loss:1.257, Test_acc:64.00%, Test_loss:0.965, LR:9.22e-05
Epoch:24, Train_acc:64.56%, Train_loss:1.204, Test_acc:65.78%, Test_loss:0.927, LR:8.85e-05
Epoch:25, Train_acc:65.44%, Train_loss:1.188, Test_acc:69.78%, Test_loss:0.969, LR:8.85e-05
Epoch:26, Train_acc:67.33%, Train_loss:1.156, Test_acc:66.67%, Test_loss:0.774, LR:8.85e-05
Epoch:27, Train_acc:67.33%, Train_loss:1.152, Test_acc:72.00%, Test_loss:0.849, LR:8.85e-05
Epoch:28, Train_acc:67.56%, Train_loss:1.154, Test_acc:70.22%, Test_loss:0.820, LR:8.85e-05
Epoch:29, Train_acc:68.00%, Train_loss:1.114, Test_acc:69.33%, Test_loss:0.741, LR:8.85e-05
Epoch:30, Train_acc:69.00%, Train_loss:1.110, Test_acc:71.11%, Test_loss:0.864, LR:8.85e-05
训练完成!
最优测试准确率: 72.00%6. 结果可视化
from datetime import datetime
current_time = datetime.now()
actual_epochs = len(train_acc)
epochs_range = range(actual_epochs)
plt.figure(figsize=(14, 5))
# 准确率曲线
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy', marker='o', markersize=3)
plt.plot(epochs_range, test_acc, label='Test Accuracy', marker='s', markersize=3)
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)
plt.ylabel('Accuracy')
plt.grid(True, alpha=0.3)
# 损失曲线
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss', marker='o', markersize=3)
plt.plot(epochs_range, test_loss, label='Test Loss', marker='s', markersize=3)
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel(current_time)
plt.ylabel('Loss')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"最后 epoch 训练准确率: {train_acc[-1]*100:.2f}%")
print(f"最后 epoch 测试准确率: {test_acc[-1]*100:.2f}%")
print(f"最优测试准确率: {best_test_acc*100:.2f}%")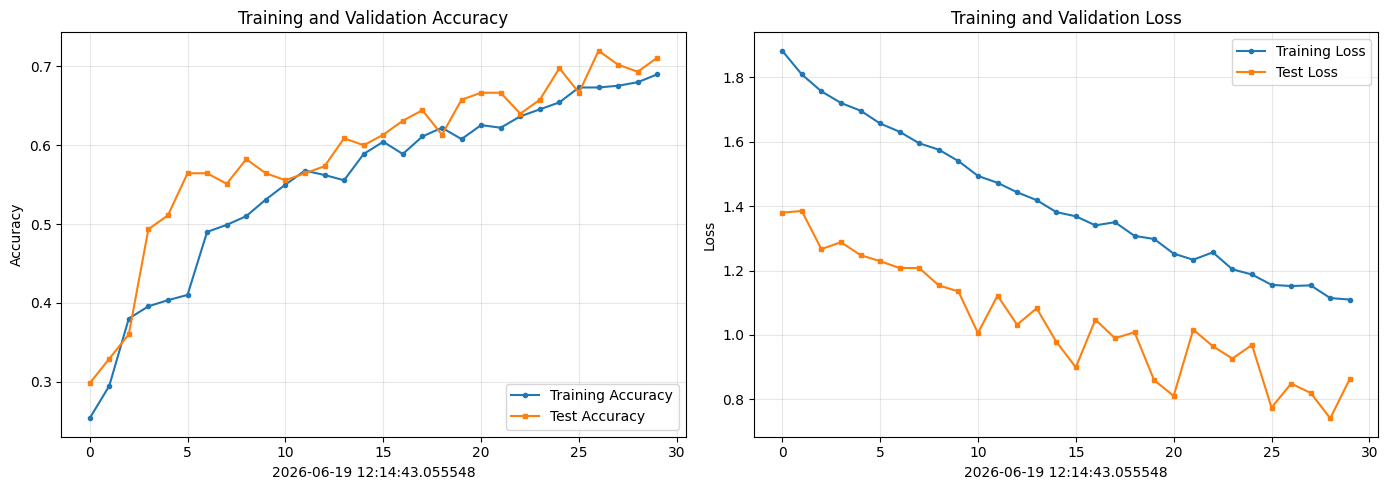
最后 epoch 训练准确率: 69.00%
最后 epoch 测试准确率: 71.11%
最优测试准确率: 72.00%7. 模型评估与预测
7.1 加载最优模型
# 加载保存的最优模型
best_model = InceptionV3(num_classes=4, aux_logits=True).to(device)
checkpoint = torch.load('model/J7_best_model.pth', map_location=device)
best_model.load_state_dict(checkpoint['model_state_dict'])
best_model.eval()
print(f"已加载最优模型 (epoch {checkpoint['epoch']}, acc {checkpoint['best_acc']*100:.2f}%)")
已加载最优模型 (epoch 27, acc 72.00%)7.2 在测试集上评估
import numpy as np
# 收集所有预测结果和真实标签
all_preds = []
all_labels = []
with torch.no_grad():
for imgs, labels in test_dl:
imgs = imgs.to(device)
outputs = best_model(imgs)
_, preds = torch.max(outputs, 1)
all_preds.extend(preds.cpu().numpy())
all_labels.extend(labels.numpy())
all_preds = np.array(all_preds)
all_labels = np.array(all_labels)
# ---- 手写分类报告 ----
print("分类报告:")
print(f"{'':>12s} {'precision':>10s} {'recall':>10s} {'f1-score':>10s} {'support':>8s}")
for i, name in enumerate(classeNames):
tp = np.sum((all_preds == i) & (all_labels == i))
fp = np.sum((all_preds == i) & (all_labels != i))
fn = np.sum((all_preds != i) & (all_labels == i))
precision = tp / (tp + fp) if (tp + fp) > 0 else 0.0
recall = tp / (tp + fn) if (tp + fn) > 0 else 0.0
f1 = 2 * precision * recall / (precision + recall) if (precision + recall) > 0 else 0.0
support = np.sum(all_labels == i)
print(f"{name:>12s} {precision:10.4f} {recall:10.4f} {f1:10.4f} {support:8d}")
# 宏平均
tp_total = 0
for i in range(len(classeNames)):
tp_total += np.sum((all_preds == i) & (all_labels == i))
overall_acc = tp_total / len(all_labels)
print(f"\n{'overall':>12s} {'accuracy':>10s} {len(all_labels):8d}")
print(f"{'':>12s} {overall_acc:10.4f}")
# ---- 混淆矩阵 ----
num_classes = len(classeNames)
cm = np.zeros((num_classes, num_classes), dtype=int)
for t, p in zip(all_labels, all_preds):
cm[t, p] += 1
print("\n混淆矩阵:")
print(cm)
# 可视化混淆矩阵
plt.figure(figsize=(6, 5))
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Confusion Matrix')
plt.colorbar()
tick_marks = np.arange(num_classes)
plt.xticks(tick_marks, classeNames, rotation=45)
plt.yticks(tick_marks, classeNames)
# 在每个格子内标注数值
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
plt.text(j, i, str(cm[i, j]),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.tight_layout()
plt.show()
分类报告:
precision recall f1-score support
cloudy 0.5437 0.8889 0.6747 63
rain 1.0000 0.0488 0.0930 41
shine 0.6222 0.5600 0.5895 50
sunrise 0.8800 0.9296 0.9041 71
overall accuracy 225
0.6756
混淆矩阵:
[[56 0 7 0]
[27 2 7 5]
[18 0 28 4]
[ 2 0 3 66]]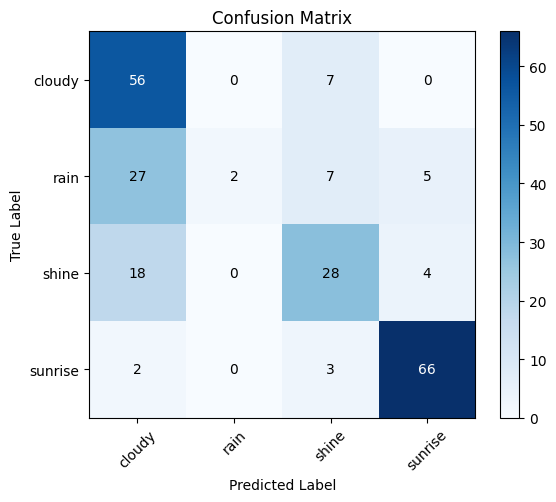
7.3 单张图片预测
# 预测函数
def predict(image_path, model, transforms_fn, class_names):
"""对单张图片进行预测"""
img = Image.open(image_path).convert('RGB')
img_tensor = transforms_fn(img).unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
output = model(img_tensor)
# 获取各类别的概率(softmax)
probabilities = F.softmax(output, dim=1).squeeze().cpu().numpy()
pred_idx = torch.argmax(output, dim=1).item()
# 打印结果
print(f"图片路径: {image_path}")
print(f"预测结果: {class_names[pred_idx]} (置信度: {probabilities[pred_idx]*100:.2f}%)")
print("-" * 40)
for i, name in enumerate(class_names):
print(f" {name}: {probabilities[i]*100:6.2f}%")
# 显示图片
plt.figure(figsize=(4, 4))
plt.imshow(img)
plt.title(f'预测: {class_names[pred_idx]} ({probabilities[pred_idx]*100:.2f}%)')
plt.axis('off')
plt.show()
return class_names[pred_idx]
# 如果有测试图片可以取消注释以下代码
result = predict('./data/J7-data/shine/shine5.jpg', best_model, test_transforms, classeNames)
图片路径: ./data/J7-data/shine/shine5.jpg
预测结果: shine (置信度: 36.47%)
----------------------------------------
cloudy: 27.15%
rain: 21.23%
shine: 36.47%
sunrise: 15.15%
8. 总结
8.1 Inception v3 关键改进
|-----------|--------------|-----------------|
| 特性 | Inception v1 | Inception v3 |
| 卷积分解 | 使用 5×5 卷积 | 5×5 → 两个 3×3 卷积 |
| 非对称分解 | 不支持 | n×n → 1×n + n×1 |
| 辅助分类器 | 1 个 | 1 个(在更深的层) |
| BatchNorm | 可选 | 每个卷积层后 |
| 优化器 | SGD | RMSProp |
| 输入尺寸 | 224×224 | 299×299 |
8.2 天气识别任务
- 数据集: 天气识别数据集(4 分类:cloudy, rain, shine, sunrise)
- 模型: Inception v3(从头训练)
- 数据增强: 随机裁剪、水平翻转、颜色抖动
- 优化策略: RMSProp + StepLR 学习率衰减 + 早停