
在工业、电力、交通、城市物联等场景,时序数据的压力往往不会在系统上线初期显现。系统刚上线时,接入点位少、数据留存周期短、查询逻辑简单,多数系统均可平稳运行。但随着设备持续接入、采样频率提升、历史数据不断沉淀,原本可控的数据流会逐步成为系统长期运行的顽疾。
这也是时序场景与普通业务系统的本质区别:普通业务数据来源于交易、订单、审批等单次明确操作;时序数据是设备状态持续上报,数据规模随采集点位呈指数级增长。电表遥测、风机参数、产线振动、车辆轨迹等场景,只要设备运转,数据就会源源不断生成。
因此,时序数据库面临的核心难点并非瞬时峰值写入,而是高频采集、长期留存、持续查询三者并存的复合挑战。
一、四大核心难题:性能瓶颈不止是"写得快"
随着系统长期运行,四类问题层层叠加,最终压垮大量看似高性能的时序系统:
-
写入压力
设备数量与采样频率同步增长后,系统需要长期承载高并发写入。写入流程包含内存调度、日志落盘、磁盘I/O、索引维护等全链路操作,当采集点位达到一定规模,单点资源极易长期满载。
-
索引压力
时序数据表面仅包含"时间+数值",但实际业务查询通常附带设备ID、指标类型、区域、业务标签等筛选条件。随着采集点与历史数据持续增加,索引体量爆炸式扩张。一旦B-Tree索引无法常驻内存,系统将大量触发磁盘随机I/O,读写性能同步下降。
-
冷热数据混杂冲突
工业业务同时存在实时监控与历史追溯需求:近几分钟数据支撑设备告警,近几日数据用于工况波动分析,数月乃至数年数据用于故障溯源、AI模型训练。若所有数据采用统一存储管理策略,实时业务与离线分析会互相抢占存储、算力资源。
-
扩展与运维压力
工业系统属于长期在线业务,新增设备、调高采样频率、延长数据留存周期属于常态化需求。若扩容需要停机迁移数据,或只能依靠升级单机硬件提升性能,系统长期运维会陷入被动。
二、金仓时序数据库:面向工业场景的工程化解决方案
针对时序系统长期运行的各类痛点,金仓时序数据库提供针对性落地实现方案:

1. 数据组织:自研二维分区算法
依托分布式超表与块级数据管理,基于时间、空间双维度实现内核级精密路由:
- 时间轴作为主分区:管控数据块与索引整体规模,避免热数据范围无限扩张;
- 空间轴作为次分区:基于设备ID等标签做哈希分区,将高并发写入均匀分散至各数据节点,消除单点过载,充分利用集群资源。
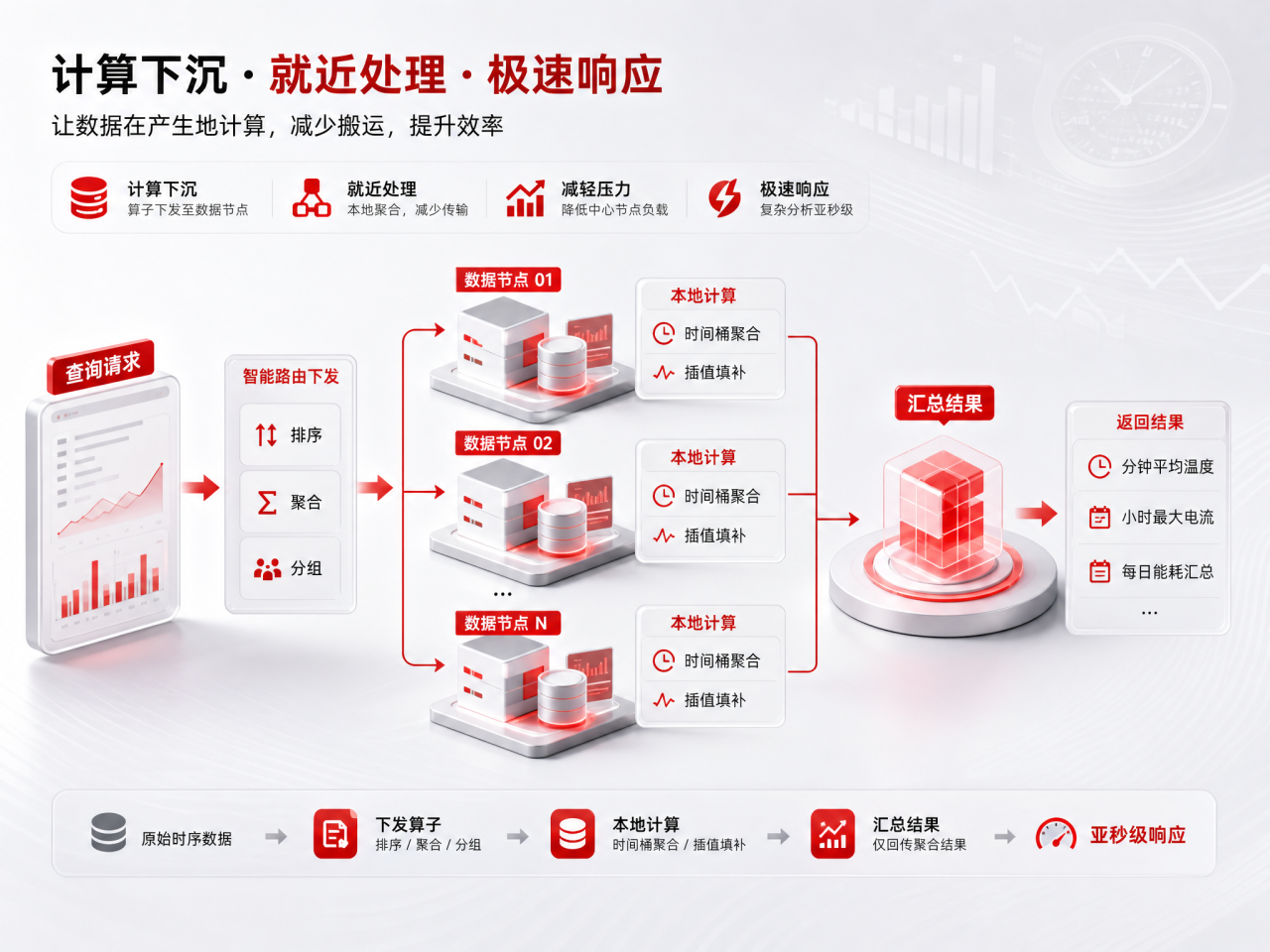
2. 查询计算:算子下推减少数据传输
通过访问节点智能元数据路由,将排序、聚合、分组等计算算子下发至对应数据节点,就近完成计算。
像分钟均值统计、小时峰值计算、日维度能耗汇总等场景,无需回传全量明细,仅汇总局部计算结果,大幅降低跨节点数据搬运与中心节点算力消耗。搭配内置插值填补、时间桶聚合能力,原本分钟级的复杂跨节点分析可缩短至亚秒级响应。
3. 长期留存:冷热分层+全生命周期管理
结合自适应压缩、冷热分区存储与完整数据生命周期体系控制存储成本:
- 热数据:承载实时告警、高频查询;
- 冷数据:用于趋势分析、故障追溯、模型训练。
该方案完整保留全量历史数据,同时区分存储介质,平衡查询性能与存储成本。
4. 可靠性:事务一致性+多副本高可用
电力监测、生产调度、交通管控等工业核心业务对数据一致性、业务连续性要求严苛。金仓时序数据库依靠事务一致性机制与多副本高可用架构,在节点故障、跨节点操作场景下,稳定保障系统可控运行。
三、时序数据库选型:切勿只看重瞬时写入峰值
时序设备采集数据无法独立支撑完整业务研判,分析工作需要关联设备档案、地理位置、业务分区、运维工单等多类数据。
金仓时序能力搭建在电科金仓新一代融合数据底座之上,可统一管理关系、文档、向量、GIS多类型数据,省去多系统数据同步、多平台数据拼接的复杂流程。
工业级时序数据库选型,不能只参考"每秒写入行数"这类纸面指标,核心考核四点:
- 数据规模持续增长时,系统能否稳定写入;
- 历史数据海量沉淀后,查询速度能否稳定;
- 设备持续扩容接入时,架构是否支持平滑扩展;
- 业务不断深化后,能否实现多类数据联合分析。
金仓数据库坚持创新务实思路,聚焦客户真实业务场景拆解各类核心挑战,提供落地可行的工程方案,切实解决时序系统长期运行的各类难题。