你用
synchronized保护共享数据,觉得万无一失。结果线上突然卡死,
jstack一拉,发现 Thread-A 持有锁 X 等锁 Y,Thread-B 持有锁 Y 等锁 X。恭喜,你触发了并发编程的"头号悬案"------死锁(Deadlock) 。
它不是随机故障,而是四个条件"完美共振"的必然产物。
理解这四大条件,你就能从"被动排雷"变成"主动扫雷"。
大家好,我是 Evan ,一个在知识汇秒杀系统中被死锁"教育"过的 Java+AI 学生。
今天,我从操作系统的死锁四个必要条件 出发,用代码复现经典死锁现场,再用 jstack 亲手把它揪出来。最后给出两种最实用的预防方案。读完这篇,你写的每一个 synchronized 都会自带"防锁死"滤镜。

📌 写在前面
大二学 OS,老师讲"互斥、持有并等待、不可剥夺、循环等待",我觉得这像是银行家算法里的玄学。
直到我在写优惠券秒杀时,为了扣库存和减额度,顺手写了两个嵌套的 synchronized。压测一跑,前 1000 个请求正常,第 1001 个开始,整个服务像被按了暂停键。jstack 一看,清清楚楚:Thread-1 等着 Thread-2 放锁,Thread-2 等着 Thread-1 放锁。那一刻我才明白------死锁是程序员"锁"出来的因果报应。
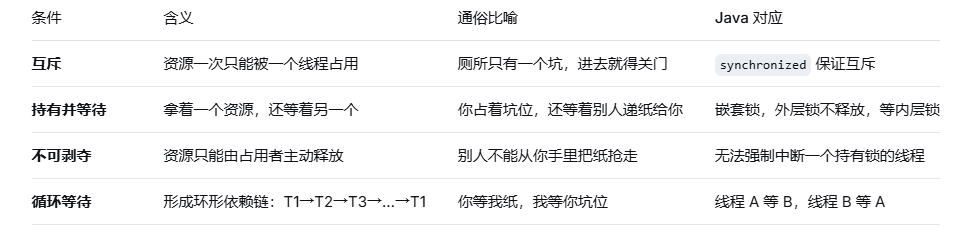
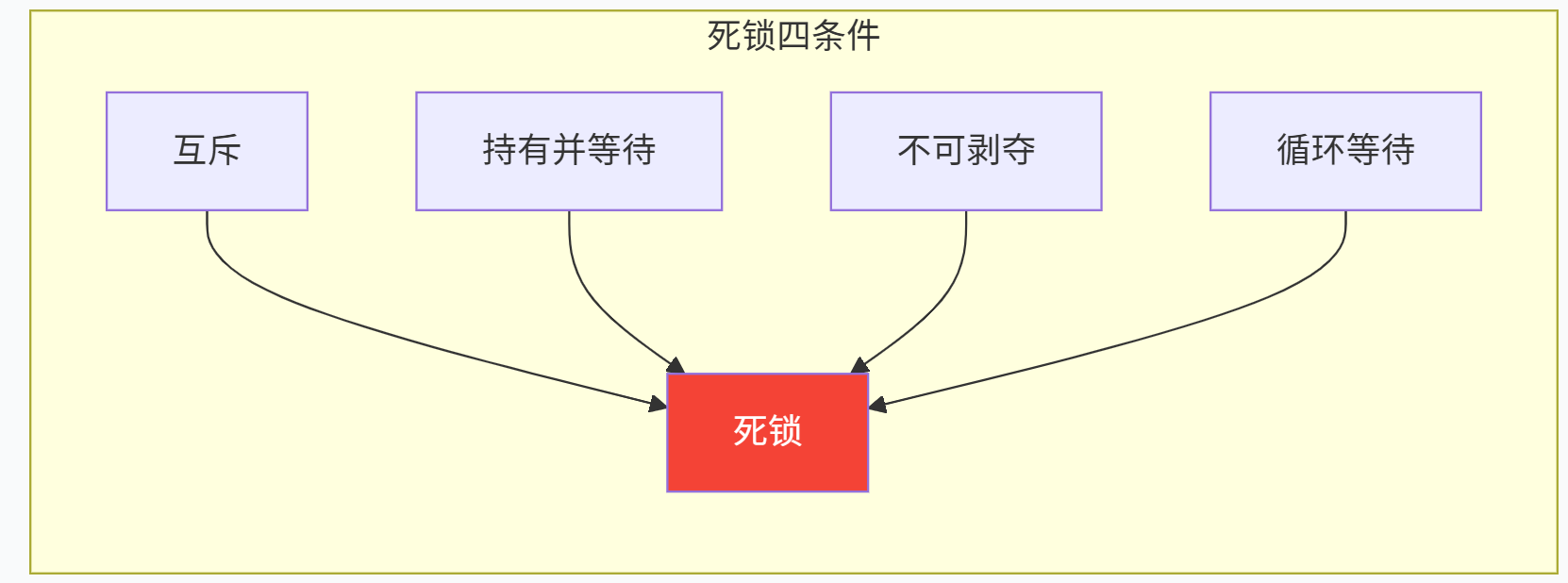
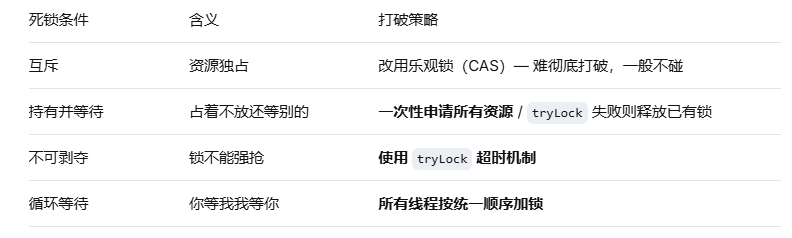
一、死锁的"四大金刚":缺一不可
死锁的发生,必须同时满足以下四个条件。就像四把锁同时锁住,才打不开门。
二、用 Java 代码还原一场"完美死锁"
java
public class DeadlockDemo {
private static final Object LOCK_A = new Object();
private static final Object LOCK_B = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
synchronized (LOCK_A) {
System.out.println("T1 持有 A,等待 B...");
sleep(100); // 让 T2 有机会锁住 B
synchronized (LOCK_B) {
System.out.println("T1 同时持有 A 和 B");
}
}
});
Thread t2 = new Thread(() -> {
synchronized (LOCK_B) {
System.out.println("T2 持有 B,等待 A...");
sleep(100);
synchronized (LOCK_A) {
System.out.println("T2 同时持有 B 和 A");
}
}
});
t1.start();
t2.start();
}
private static void sleep(int ms) {
try { Thread.sleep(ms); } catch (InterruptedException e) {}
}
}运行输出(大概率卡死):
java
T1 持有 A,等待 B...
T2 持有 B,等待 A...
(然后进程永不退出)四个条件验证:
-
✅ 互斥:
synchronized保证 -
✅ 持有并等待:T1 拿着 A 等 B,T2 拿着 B 等 A
-
✅ 不可剥夺:JVM 不会强行收回锁
-
✅ 循环等待:T1 → B → T2 → A → T1

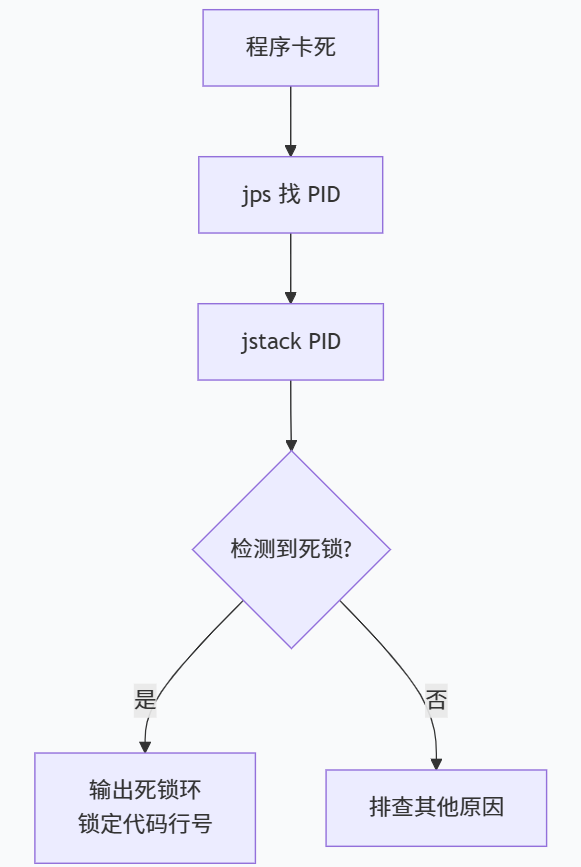
三、jstack 排雷:让死锁无处遁形
3.1 找到进程并打印堆栈
bash
jps -l # 找到 PID
jstack <PID> # 打印线程堆栈3.2 JVM 自动检测死锁
jstack 输出末尾会直接告诉你:
bash
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x00007f8c1400a500 (object 0x000000076b5a3b20, a java.lang.Object),
which is held by "Thread-2"
"Thread-2":
waiting to lock monitor 0x00007f8c1400a2e0 (object 0x000000076b5a3b10, a java.lang.Object),
which is held by "Thread-1"3.3 其他可视化工具
-
JConsole:连接进程 → "线程" → "检测死锁" 按钮
-
VisualVM:图形化展示死锁线程
四、开发中容易死锁的高危场景
4.1 嵌套 synchronized(最常见)
就是上面那个例子,锁顺序不一致。
4.2 数据库行锁 + 表锁
sql
-- 事务 1
UPDATE orders SET status=1 WHERE id=1; -- 锁行 1
UPDATE users SET balance=balance-10 WHERE id=1; -- 等行 1 的 users
-- 事务 2(锁顺序相反)
UPDATE users SET balance=balance+10 WHERE id=1; -- 锁行 1 的 users
UPDATE orders SET status=2 WHERE id=1; -- 等行 1 的 orders数据库 InnoDB 会自动检测并回滚其中一个事务(返回 Deadlock found when trying to get lock)。
4.3 线程池 + Future.get() 相互等待
线程池满时,任务 A 等待任务 B 的结果,任务 B 等待任务 A 的结果,池子耗尽直接死锁。
五、预防死锁的两种"武器"(打破任一条件即可)
武器一:固定锁顺序(打破"循环等待")
核心思想 :所有线程必须按照全局统一的顺序获取锁。
sql
java
// 规定:永远先锁 A,再锁 B
synchronized (LOCK_A) {
synchronized (LOCK_B) {
// 安全
}
}如果锁对应的资源有自然 ID(如数据库主键),按 ID 升序加锁,是业界通用做法。
武器二:tryLock 超时放弃(打破"持有并等待"+"不可剥夺")
使用 ReentrantLock 替代 synchronized,支持超时尝试。
sql
java
ReentrantLock lockA = new ReentrantLock();
ReentrantLock lockB = new ReentrantLock();
public void transfer() {
while (true) {
boolean gotA = lockA.tryLock(100, TimeUnit.MILLISECONDS);
boolean gotB = lockB.tryLock(100, TimeUnit.MILLISECONDS);
if (gotA && gotB) {
try {
// 安全执行业务
break;
} finally {
if (gotB) lockB.unlock();
if (gotA) lockA.unlock();
}
} else {
// 释放已获得的锁(打破"持有并等待")
if (gotA) lockA.unlock();
if (gotB) lockB.unlock();
// 随机等待后重试,避免活锁
Thread.sleep( (long)(Math.random() * 50) );
}
}
}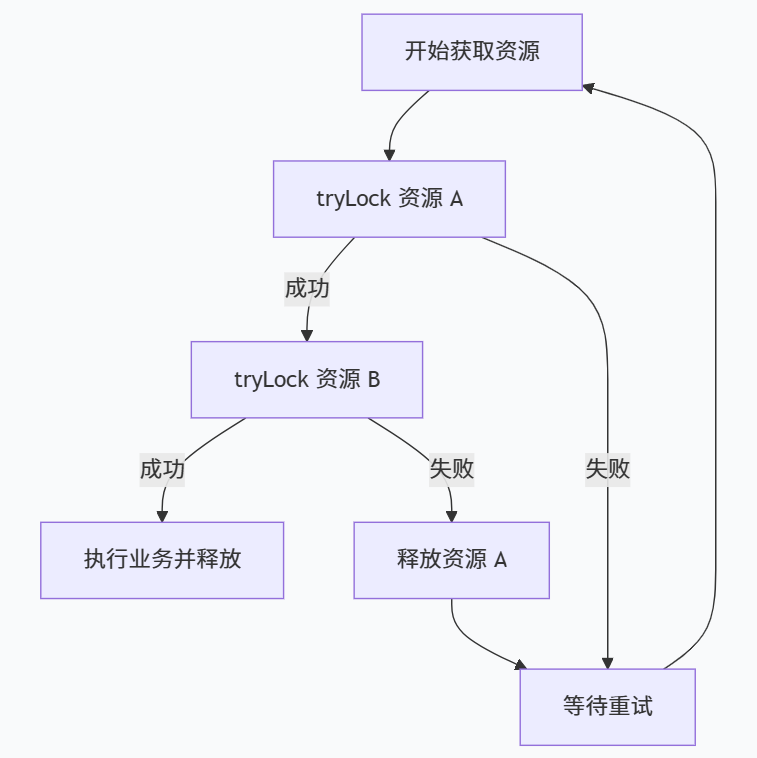
注意:业务有重试次数上限,避免无限自旋。
六、数据库死锁的特殊处理
Java 中捕获数据库死锁异常并重试:
java
try {
// 执行更新 SQL
} catch (DeadlockLoserDataAccessException e) {
// 被数据库选为"牺牲者",重试
retryCount++;
if (retryCount < 3) {
// 短暂等待后重试
}
}📝 总结
核心结论:
-
死锁是并发编程的"四重奏",缺一不可。
-
jstack是 Java 排死锁的"照妖镜"。 -
生产中优先使用 固定锁顺序 (简单高效),复杂场景配合
ReentrantLock.tryLock。 -
数据库死锁不可怕,引擎会回滚,你的代码做好重试即可。
🤔 思考题 :
你接手一个老项目,代码里到处是嵌套的 synchronized,锁顺序极度混乱。重构锁顺序成本极高,容易引入新 Bug。你不想把所有 synchronized 都替换成 ReentrantLock,但又想防止死锁。
问题 :有什么办法可以在 不修改业务代码 的前提下,让 JVM 在死锁发生时自动中断其中一个线程来恢复服务?(提示:考虑 JVM 参数或线程中断机制,以及 LockSupport 的底层)
欢迎在评论区留下你的方案 ------ 下一篇我会聊聊 "I/O 多路复用与 Agent 循环:epoll 如何支撑你上千个并发 Tool 调用"。